Blog
LLMエージェントは大規模言語モデル (LLM) を利用した自律的システムで、自然言語の指示に基づいてプランニングや外部ツールの呼び出しを行います。先日、PLaMo β版においても、LLMエージェントの実装を促進するFunction Calling機能のサポートを開始しました。
本記事は2024年度PFN夏季インターンシップで、LLMエージェントの能力向上に取り組まれた木澤翔太さんによる寄稿です。
背景と目的
まず、LLMエージェント[1]について説明します。LLMエージェントはかなり広い概念ですが、ここでは「自然言語を入力として外部のツールを利用しながら自律的に動作するエージェント」とし、以下のワークフロー[2]に従うものとします。
![図1. LLMエージェントのワークフロー[2]](https://tech.preferred.jp/wp-content/uploads/2024/10/image1-1.png)
図1. LLMエージェントのワークフロー[2]
LLMエージェントには、例えば旅行計画エージェント[3]やウェブ検索エージェント[4]等があり、多くの作業を自動化できる可能性を秘めているため、LLMエージェントの能力を向上させることは我々にとって重要なトピックです。私は本インターンで、PLaMoのLLMエージェントとしての能力の向上に取り組みました。その中でも特に、外部の環境と接続するための重要な能力である、ツール利用能力の向上を目指しました。
ツール利用能力の測り方
LLMエージェントのツール利用能力の向上に取り組む上では、まずエージェントのツール利用能力を測ることが重要です。このためのベンチマークは多数ありますが、タスクの網羅性やコミュニティへの普及度合いを踏まえて、本インターンではBerkeley Function-Calling Leaderboard (BFCL) V2 Benchmark[5]を用いました。
BFCL V2はおよそ2000個の質問、関数、回答の組からなるベンチマークです。関数はJSON形式で与えられます。以下に例を示します。
質問:
Find the area of a triangle with a base of 10 units and height of 5 units.
関数:
[{"name": "calculate_triangle_area", "description": "Calculate the area of a triangle given its base and height.", "parameters": {"type": "dict", "properties": {"base": {"type": "integer", "description": "The base of the triangle."}, "height": {"type": "integer", "description": "The height of the triangle."}, "unit": {"type": "string", "description": "The unit of measure (defaults to 'units' if not specified)"}].
回答:
[“calculate_triangle_area(base=10, height=5, periods=10)”]
この「質問」と「関数」をLLMに与え、LLMがどの程度「回答」に近い出力を出せるのかを測るベンチマークとなっています。
BFCL V2のタスクは、以下2つのカテゴリに分類できます。
- Pythonの文法で記述された関数を扱うケース
- Python以外の文法で記述された関数を扱うケース
この2つは、入力となる関数の命名規則やパラメータの型が違います。それぞれのカテゴリは以下のタスクを有しています。
- Pythonの文法で記述された関数を扱うケース
- simple_func: 1関数入力1関数出力
- multiple_func: 複数関数入力1関数出力
- parallel_func: 1関数入力複数関数出力(パラメータを変えて複数回呼び出す)
- parallel_multiple_func: multiple_funcとparallel_funcの組み合わせ
- Python以外の文法で記述された関数を扱うケース
- relevance: 複数関数入力0関数出力
- rest: REST API呼び出し
- java: Javaの文法で記述された関数を呼び出すケース、1関数入力1関数出力
- javascript: JavaScriptの文法で記述された関数を呼び出すケース、1関数入力1関数出力
2.1のrelevanceスコアは、ユーザーの質問と関連のない関数が与えられたときに、1つも関数を呼び出さずに「回答不可」と出力することができるかを評価するタスクです。これはハルシネーションのチェックに使われます。
これらのタスクは、以下の2通りで評価されます。
- AST Evaluation: 出力をAbstract Syntax Tree (AST)に変換して整合性を評価
- Executable Function Evaluation: 実際に関数を実行してその結果から評価
本インターンでは、AST Evaluationで正しいと評価されたときにExecutable Function Evaluationで間違っていると評価されることが稀であることから、簡単のため、AST Evaluationのみを使うこととします。
PLaMo-100B の現状のツール利用能力と考察
PLaMo-100B†¹のツール利用能力をBFCL V2を使って測りました。ベースラインとしてLlama 3.1 8Bを使いました。以下がその評価結果です。
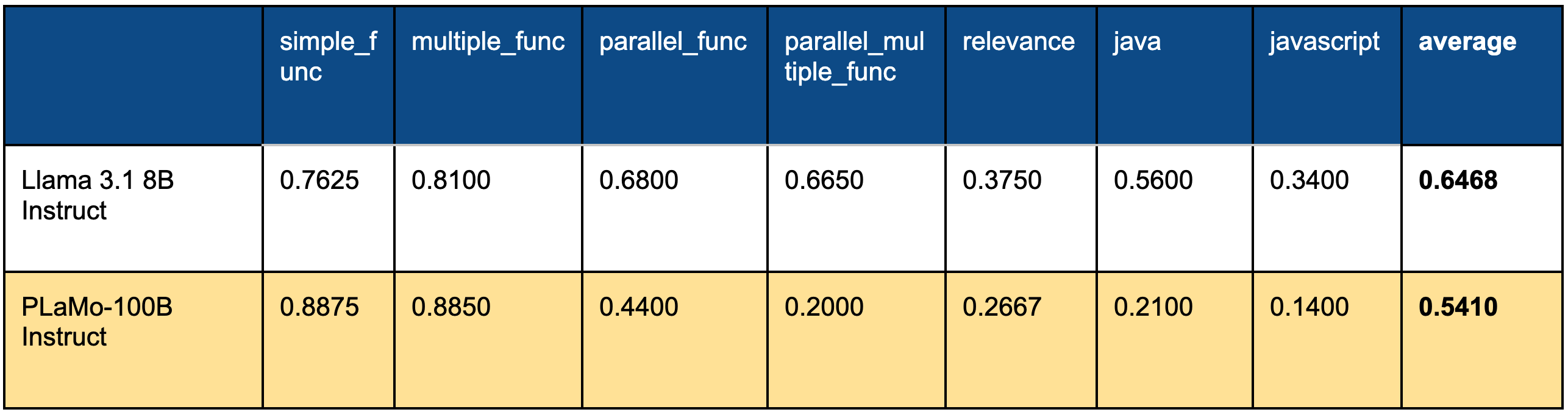
表1. BFCLの評価結果
評価結果を見ると、PLaMo-100Bがsimple_funcとmultiple_funcではLlama 3.1 8Bを上回る一方、それタスク以外ではLlama 3.1 8Bを下回っていることが分かります。下回ってしまった原因を分析するために、誤りの原因を調べました。以下がその結果です。
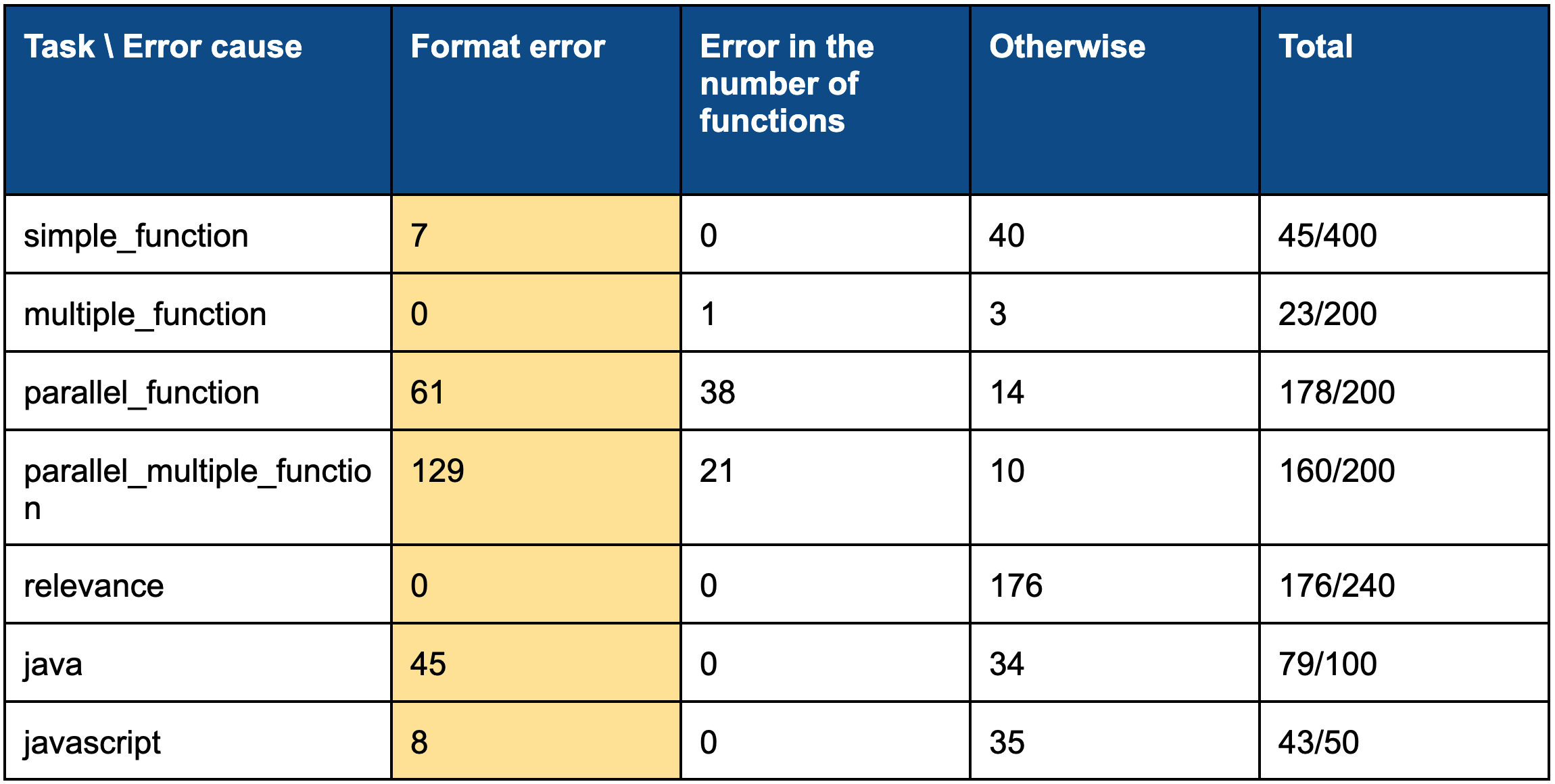
表2. タスクごとの誤り要因の内訳
この結果を見ると、フォーマットエラーがかなり多いことが分かります。つまり、プロンプトでフォーマットを指定しているにも関わらず、正しいフォーマットで出力してくれない、ということです。
このフォーマットエラーを解消するために、guided decoding[6]を使います。これはLLMが出力できるトークンを制限する手法です。具体的には、LLMのデコーダから各トークンの確率を受け、指定したフォーマット以外のトークンの確率を0にします。これにより、指定したフォーマットに必ず従うようになります。例えば、JSONを指定した場合、LLMのデコーダの最初の出力については、“[“ か “{” 以外のトークンの確率は0となります。その後、botトークンが出力されるまでこれを繰り返します。
以下がguided decodingを使った評価結果†²となります。
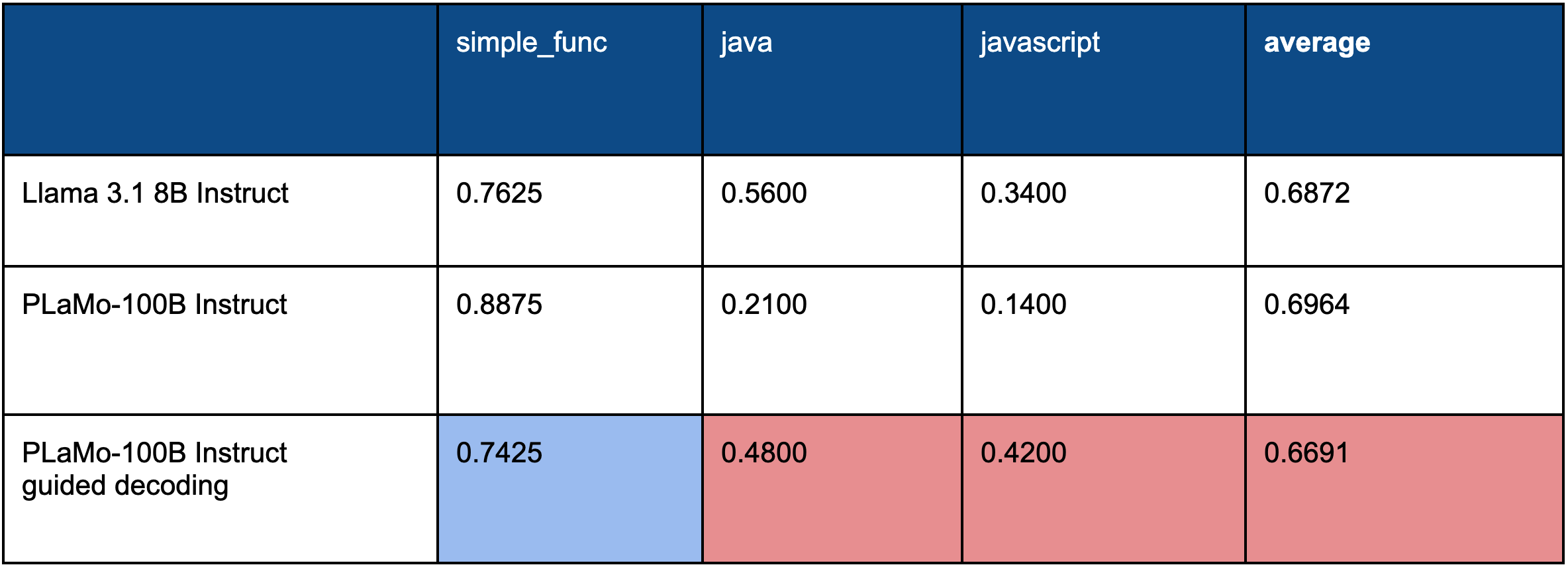
表3. Guided decodingを使用した際の評価結果
この結果を見ると、java、javascriptについては大きく精度を向上できていることが分かります。これはフォーマットの誤りが減ったのが一番の要因です。一方で、simple_funcについては精度が低下してしまいました。simple_funcの誤りを分析してみると、フォーマットのエラーは減りましたが、逆にフォーマット以外のエラーが増えていることが分かりました。
では、なぜguided decodingを使うとフォーマット以外のエラーが増えてしまうのでしょうか。先行研究では、フォーマットをデコーダレベルで強制すると推論能力が低下するからだと主張しています[7]。推論能力が低下する原因までは解明されていませんが、先行研究の実験結果から、学習済みモデルについては、推論能力とフォーマットに従う能力がトレードオフの関係にあることが示唆されます。つまり、フォーマットを強制し過ぎると推論能力が低下し、逆にプロンプトでフォーマットの自由度を与えるとフォーマットに従う能力が低下するということです。以上の議論より、ツール利用能力は大きく2つの能力に分類できることが分かります。
- (Tool Selection) ツール選択能力 (ツールのパラメータ選択も含む)
- (Following Format) 指示したフォーマットに従う能力
ツール利用能力の改善
それでは、上記2つの能力を高めるにはどうすれば良いでしょうか。fine-tuningできる場合、以下の2つの方法が考えられます。
- Supervised fine-tuning (SFT) for Specified Format: 呼び出すべき関数を指定したフォーマットで正しく出力させ、指定したフォーマット以外は出力しないようfine-tuningする。
- SFT for Hybrid Output: 最初は自由に出力させ、定めた特殊トークン、例えば<TOOL_CALLS>、が出た後のみ指定したフォーマットに沿って出力するようfine-tuningする。
1の方法については、単にプロンプトでユーザーの質問と呼び出せる関数を与え、呼び出すべき関数のリストのみを指定したフォーマットで出力できるように学習する、ということを意味します。つまりJSONを指定した場合、JSON以外は出力しないよう学習するということです。
2の方法については、CoTのような推論ステップを学習することで、単に指示とその結果だけを学習するよりもツール選択能力を上げられるのではないか、という仮説から考案しました。特殊トークンを追加して、特殊トークン前は自由に出力させ、特殊トークン後はguided decoding等を使って指定したフォーマットに沿って出力させようにします。
1. SFT for Specified Format
まず1について、PLaMo-100Bの代わりに軽量化されたモデルPLaMo-1B†³を用いて計算実験を行いました。ツール利用能力を高めるためのデータセットはいくつかありますが、本インターンでは ToolBench[8]というデータセットを用いました。ToolBenchは、およそ180,000の質問、関数、回答、関数の実行結果からなる会話形式のテキストからなるデータセットです。回答はCoT形式になっており、Thought…, Action…, Action Input…というテンプレートを用いています。以下に例を示します。
質問:
Find the area of a triangle with a base of 10 units and height of 5 units.
関数:
[{"name": "calculate_triangle_area", "description": "Calculate the area of a triangle given its base and height.", "parameters": {"type": "dict", "properties": {"base": {"type": "integer", "description": "The base of the triangle."}, "height": {"type": "integer", "description": "The height of the triangle."}, "unit": {"type": "string", "description": "The unit of measure (defaults to 'units' if not specified)"}]
回答:
\nThought: …(略) \nAction: calculate_triangle_area\nAction Input: {“base”: 10, “height”: 5, “periods”: 10}
関数の実行結果:
…(以下略)
ここでは、この回答部分をThought…, Action…, Action Input…というテンプレートではなく、以下のスキーマに従うJSONフォーマットに変換し、これを学習データとします。
{
"type": "array",
"items": {
"type": "object",
"required": ["name", "arguments"],
"properties": {
"name": {
"type": "string"
},
"arguments": {
"type": "object"
}
}
}
}
今回はデータセットやモデルのパラメータ数が大きいこともあり、時間の都合上LoRA[9]を使用します。LoRAは通常のfine-tuningよりも少数のパラメータで学習ができる手法です。もう少し具体的に説明します。まず、モデルの各層について、fine-tuningにおいて更新される重み行列の差分を\(\Delta W\)とおきます。その\(\Delta W\)について、低ランク行列\(A\), \(B\)を使って\(\Delta W = BA\)という分解を考えます。そして、実際のfine-tuningでは、重み行列を更新する代わりに低ランク行列\(A\), \(B\)を更新します。この操作により、更新対象のパラメータ数を減らすことができます。
![図2. LoRAの概要図[9]](https://tech.preferred.jp/wp-content/uploads/2024/10/image2-1.png)
図2. LoRAの概要図[9]
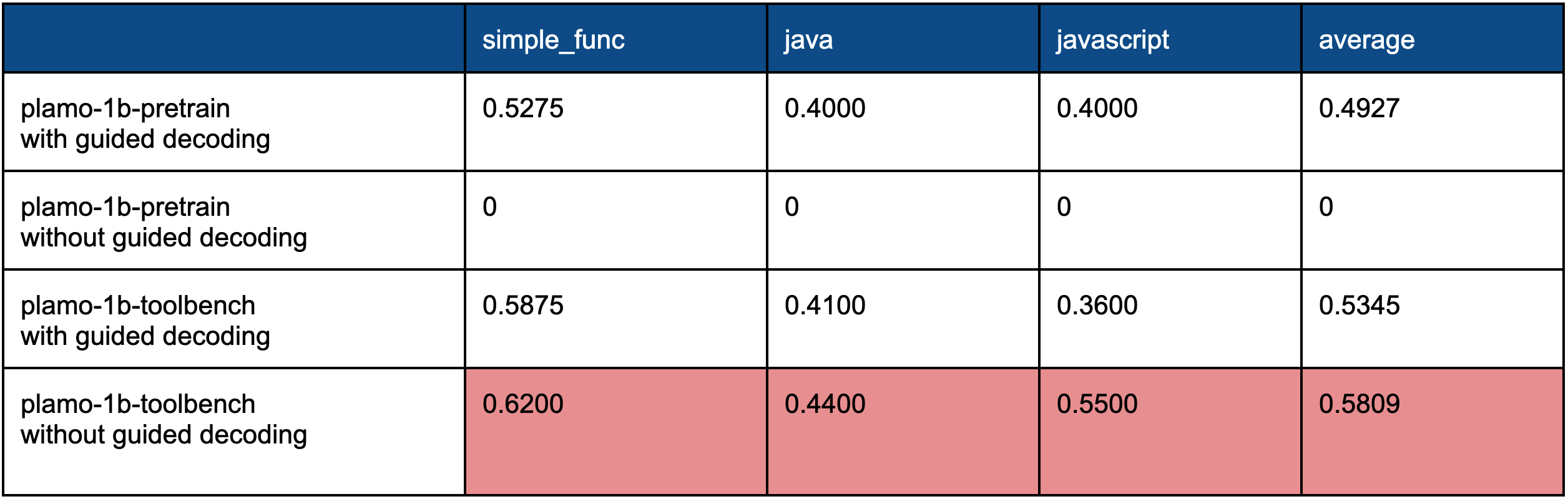
表4. 実験結果:SFT for Specified Format
“plamo-1b-pretrain with guided decoding”と“plamo-1b-toolbench without guided decoding”を比較すると、全体的にスコアが向上しているのが見て取れます。これは、パラメータの値ミスが減ったのが大きな要因です。つまり、ツール選択能力が向上したと言えます。また、“plamo-1b-pretrain without guided decoding”はフォーマットミスで性能が測れなかったにも関わらず、fine-tuning後の“plamo-1b-toolbench without guided decoding”を見ると、guided decodingを使わずとも正しいフォーマットで出力するようになりました。これは指示したフォーマットに従う能力が向上したと言えます。“plamo-1b-toolbench with guided decoding”と“plamo-1b-toolbench without guided decoding”を比較するとguided decodingを使わない方が精度が高いことが分かります。誤りの原因を分析すると、“plamo-1b-toolbench with guided decoding”の方がパラメータの値ミスが多く、ツール選択能力が低いことが分かりました。PLaMo-100Bで行った結果と同様、この結果からもフォーマットを強制しすぎると他の能力が落ちてしまっていることが示唆されます。
2. SFT for Hybrid Output
次に2について、1と同様にfine-tuningを行います。簡単のため、特殊トークンを定める代わりにThought…, Action,…というテンプレートを使います。Thought以降は自由に回答させ、Action以降はJSONに沿って出力させます。以下がその結果です。なお、Action以降についてguided decodingで制限するか否かで2通り実験しました。以下が実験結果となります。
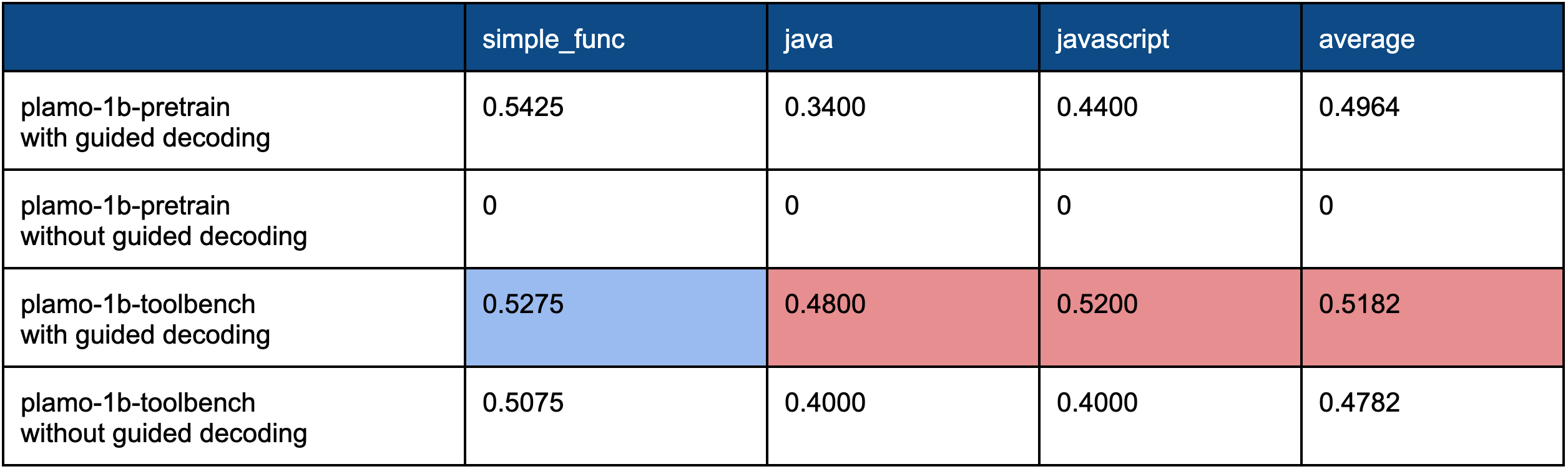
表5. 実験結果:SFT for Hybrid Output
“plamo-1b-pretrain with guided decoding”と“plamo-1b-toolbench with guided decoding”を比較すると、fine-tuning後のモデルの方がjava, javascriptタスクについて精度が向上していることが分かります。これは、フォーマットミス以外も含めて全体的に誤りが減ったことから、単純にツール利用能力が向上したと言えます。一方で、simple_funcタスクについては精度が落ちています。この原因を探るべく、誤りの原因を分析しました。その結果、以下2つのケースで精度が落ちていることが分かりました。
- 関数のパラメータが数値の場合
- Python独自の文法を使う場合
1は数値の桁数等を間違えやすくなったということです。例えば、関数のパラメータとして本来100と回答すべきところを、1000と回答してしまう、等です。この原因として、ToolBenchに数値を扱う関数を扱うデータが多く (およそ全体の10%) 、ToolBenchの回答に引っ張られていること、等が挙げられます。
2はやや稀なケースではありますが、lambda式を引数とする場合に間違えやすくなったということです。この原因は、ToolBenchにlambda式を引数とする関数が少ないためだと考えられます。
上記2つの誤りが、思考プロセスを入れることで顕著に現れてしまったのだと考えられます。この2つのケースの対応策として、データの適切なフィルタリングとPython独自の文法を使ったデータ作成が挙げられます。また、こちらの実験では自由回答とJSONを組み合わせた出力というフォーマットが難しかったためか、フォーマットに従う能力を向上させるguided decodingを使う方が使わない場合よりも全体的にスコアは高くなりました。
まとめ
ツール利用能力を分析していくと、ツール利用能力は大きく以下の2つの能力に分類できることが分かりました。
- (Tool Selection) ツール選択能力(ツールのパラメータ選択も含む)
- (Following Format) 指示したフォーマットに従う能力
また、学習済みモデルを使って推論する場合、この1、2の能力はトレードオフの傾向にあることが分かりました。
次に、fine-tuningをする場合に焦点を当て、1と2の能力を高めるべく、SFT for Specified Format、SFT for Hybrid Outputという手法を考案しました。これらの手法を用いて実験を行ったところ、SFT for Specified Formatについてはすべてのタスクで精度向上が見られました。また、特に重要な気づきとして、以下2点が挙げられます。
- 思考プロセスなしでJSON出力のみを学習させれば、ツール選択能力と指示したフォーマットに従う能力の両方の能力を向上させることができる。
- guided decodingを使うとフォーマットに従う能力は上がるが、他の能力が下がる傾向にある。指示したフォーマットに従う能力が十分に高い場合は、guided decodingを使わない方が精度が良い。
SFT for Hybrid Outputについては、javaとjavascriptタスクについては精度向上が見られましたが、simple_funcタスクについては逆に精度が低下しました。この原因として、思考プロセスを入れることで、数値を扱う関数を出力する場合に訓練データ (ToolBench) の回答に引っ張られるようになったこと、等が挙げられます。一方で、適切にデータをフィルタリングすればさらなる精度向上は十分可能だと思われます。
PFNでは本インターンで得られた成果を活かし、今後もPLaMoの改善に継続的に取り組んでいきます。
†¹ 本記事内および [4] で参照されてるPLaMo-100Bは、PLamo 1.0 Primeとは異なる開発用モデルを指します。PLaMo-100Bは、子会社のPreferred ElementsがNEDO(国立研究開発法人新エネルギー・産業技術総合開発機構)の助成事業「ポスト5G情報通信システム基盤強化研究開発事業」(JPNP20017) に採択され、日本の基盤モデル開発力向上を目指すGENIACプロジェクトで開発しました。
†² なお、本ブログ執筆時点でのPLaMo-100Bは、1つの関数を入力として、その1つの関数を出力するケースにしか対応できません。そのため、simple_func、 java、 javascript の3つのタスクに焦点を当てて評価しました。他のタスクについては今後の課題とします。
†³ 今回の実験で使用したPLaMo-1Bは、PLaMo Liteとは異なる社内開発用のモデルです。
謝辞
メンターの尾﨑さん、柳瀬さんには大変お世話になりました。また、佐野さん、中郷さん、片岡さん、岡田さん、島田さんには大変多くのアドバイスをいただきました。心よりお礼申し上げます。
参考文献
[1] Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, & Ji-Rong Wen. (2023). A Survey on Large Language Model based Autonomous Agents.
[2] Ota, Masato (2024). LLM Based AI Agents Overview. Speaker Deck, https://speakerdeck.com/masatoto/ai-agents-overview-what-why-how . Accessed 26 Sept. 2024.
[3] Xie, J., Zhang, K., Chen, J., Zhu, T., Lou, R., Tian, Y., Xiao, Y., & Su, Y. (2024). TravelPlanner: A Benchmark for Real-World Planning with Language Agents. In Forty-first International Conference on Machine Learning.
[4] Nakano R, Hilton J, Balaji S, Wu J, Ouyang L, Kim C, Hesse C, Jain S, Kosaraju V, Saunders W, others (2021). Webgpt: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332.
[5] Fanjia Yan, Huanzhi Mao, Charlie Cheng-Jie Ji, Tianjun Zhang, Shishir G. Patil, Ion Stoica, & Joseph E. Gonzalez. (2024). Berkeley Function Calling Leaderboard. Retrieved from https://gorilla.cs.berkeley.edu/blogs/8_berkeley_function_calling_leaderboard.html
[6] BT Willard, R Louf (2023). Efficient Guided Generation for Large Language Models. arXiv preprint arXiv:2307.09702
[7] Zhi Rui Tam, Cheng-Kuang Wu, Yi-Lin Tsai, Chieh-Yen Lin, Hung-yi Lee, Yun-Nung Chen (2024). Let Me Speak Freely? A Study on the Impact of Format Restrictions on Performance of Large Language Models. arXiv preprint arXiv:2408.02442.
[8] Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, dahai li, Zhiyuan Liu, & Maosong Sun (2024). ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs. In The Twelfth International Conference on Learning Representations.
[9] Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, & Weizhu Chen (2022). LoRA: Low-Rank Adaptation of Large Language Models. In International Conference on Learning Representations.
Area



