Blog
2024年夏季インターンの矢野一樹さんによる寄稿です。
はじめに
こんにちは!2024年度夏季インターンシップに参加させていただきました,東北大学修士2年の矢野一樹です.
今回のインターンシップでは,金融的な知識を,LLMがより活用できるようなデータセット設計について取り組みました.
背景
金融分野におけるLLMの活用は,日々必要とされる業務の更なる効率化に結びつく可能性があり,重要さを増しています.その流れを受け,金融分野に特化したLLMの開発が盛んです.
金融分野に特化したLLMが日々の業務で有効に活用されるためには,LLMが内部に金融的な専門知識を保持しながら,その知識を活用して推論する必要があります.金融的な知識を,継続事前学習をはじめとして,金融的な知識をLLM内部に保持させるような方法がある一方で,保持した知識をLLMが効果的に利用できるとは限りません.
今回のインターンでは,LLMがある知識を保持していいるという前提のもと,その知識を推論時に効果的に活用できるようになるにはどうすれば良いのか?というテーマの元,研究を進めました.
今回はLLMが内部に持つ知識を活用させる方法としてファインチューニングに着目します.なぜファインチューニングなのかというと,ファインチューニングでは「表層アラインメント仮説」と呼ばれる考え方がある程度支持されているためです.この仮説によれば,ファインチューニングの段階では,新しい知識が獲得されるのではなく,事前学習時に得た知識をより効果的に使用できるようにしているということになります.
ファインチューニングは,このようにLLM内部の知識をより有効的に活用させるように促しますが,学習を伴うため,その効果はデータセットの質に左右されます.よって,ファインチューニングを通じて,LLM内部にある知識をより効果的に活用させるためのデータセットについて焦点を移します.
タスク
今回のインターンではLLM内部にある金融的な専門知識として日本取引所グループ(JPX)による業種区分に着目しました.JPX は上場銘柄を 33 の業種に分類しており,この分類は必ずしも銘柄の現行の事業内容を直接的に反映するものではないものの,日本の金融市場における慣習的な分類として定着しています.この業種区分は,セクター分析やポートフォリオ構築において不可欠な情報となっており,金融分野に特化したLLMなら,まず学習する必要のある金融的な知識であり,実際に事前学習時において学習されていると考えられます.
方法
既存研究では,質問応答で表されるような文章が事前学習時に有効であったり,数学ドメインの学習では,同一の知識・事柄を多様な表現で言い換えることで,より頑健な知識獲得が可能になることがわかっています.これらの既存研究を受け,今回はある知識を多様な表現形式で記述した質問応答テンプレートの利用します.具体的には以下の4つのテンプレートを用いました.
- Q: 銘柄コード + 銘柄名 → A: 業種区分
- Q: 事業内容 + 業種区分 → A: 銘柄名・コード
- Q: 銘柄コード → A: 銘柄名
- Q: 銘柄名 → A: 銘柄コード
次にテンプレートに基づいた実際の学習文の生成方法について,今回はwebから実際にとったテキストをそのままテンプレート(ルール)に基づいて生成するルールベース生成と,LLMに基づいて生成するLLMベース生成を検証しました.ルールベース生成ではwebから実際に取得してきた銘柄情報を使用します.webに掲載されるような銘柄情報は投資家向けに情報を端的に伝達する必要があるため,簡素に書かれている場合が多いです.このようなテキストは通常のコーパスの分布と比べ,大きく異なっており,学習に影響を与える可能性があります.そこで通常のコーパスに近い分布になるようにLLMベース生成方法を用意します.LLMベースの生成ではPLaMo 1.0 Prime Betaを用いました.
注) PLaMoの出力は,通常はほかのモデルの学習に使用できませんが、今回はPFN社内の取り組みであるため、使用できています。
実験
業種区分に関する知識を効果的に抽出するためのファインチューニング用データセット設計について,以下の実験を通じて検証を行いました.
1. 予備実験として,既存の LLM の業種区分予測性能を比較.
2. ルールベースと LLM ベースのデータ合成方式を比較し,より効果的な知識活用のためのデータセットを検証.
3. 質問応答における双方向テンプレートの効果を検証し,多様な表現形式の有効性を評価.
4. 合成されたデータの品質をパープレキシティの観点から分析し,各データ合成方式の特徴を明らかにする.
5. ルールベースと LLM ベースのデータの混合比率を変化させた実験を通じて,データセット構築における示唆を提供する.
実験1: 既存モデルの業種区分予測性能の比較
まずは予備実験として既存のモデルの業種区分予測性能を比較します.使用した言語モデルとしは, Hugging face にて公開されているrinna/nekomata-14b とpfnet/nekomata-14b-pfn-qfinを用いました.pfnet/nekomata-14b-pfn-qfin はrinna/nekomata-14bに対して金融ドメインに特化したデータセットで継続
事前学習されたモデルです.加えて,API が提供されている GPT-4o(gpt-4o-2024-08-06),PLaMo 1.0 Prime Beta に対しても同様の実験を行いました.評価時のプロンプトは銘柄コード と 銘柄名を質問として与え,業種区分を回答させるようにしました.
| 正答率 | |
| rinna/nakomata-14b | 0.17 |
| pfnet/nekomata-14b-pfn-qfin | 0.30 |
| PLaMo-100B | 0.90 |
| GPT-4o | 0.84 |
上の表に既存モデルの業種区分予測性能を示します.PLaMo 1.0 Prime Beta は 90%の高精
度で予測が可能であり,GPT-4o を上回る性能を示しました.また,金融ドメインでの継続事前学習を実施したpfnet/nekomata-14b-pfn-qfin は,ベースモデルであるrinna/nekomata-14b と比較して予測精度の向上が見て取れます.しかし,pfnet/nekomata-14b-pfn-qfin は金融ドメインで追加学習されているのにも関わらず,正答率は 30%に留まっています.この結果は,事前学習時に獲得した業種区分に関する知識が十分に活用されていない可能性を示唆してます.このことから,事前学習時に獲得した知識を,より効果的に引き出すためのファインチューニング用データセットについて検証していきます.
実験2: 既存モデルの業種区分予測性能の比較
この実験では,ルールベースで生成したデータとLLMで生成したデータを用いて,どちらが業種区分に関する知識の活用を促せるのかを検証します.具体的には用意した全てのテンプレートに基づいたルールベース, LLM ベースのデータセットをそれぞれ
pfnet/nekomata-14b-pfn-qfin に対してファインチューニングを行い,業種区分予測性能を計測します.詳細な訓練設定は以下とおりです.
- GPU: A100 80GB 4枚
- 学習率:1e-6からスタートし、コサイン形に0に落としていく
- Epochs: 5
- バッチサイズ: 128
| 正答率 | |
| pfnet/nekomata-14b-pfn-qfin | 0.30 |
| + LLMによる生成データ | 0.52 |
| + ルールベースによる生成データ | 0.36 |
上の表に実験結果を示します.実験結果からはルールベース,LLMベースのデータセットによるファインチューニングにおいて予測正答率の向上が確認され,テンプレートに基づく学習データが効果的にモデルの知識抽出を促進することがわかります.また,LLM による合成データでは,ルールベースのデータと比較して,より顕著に性能向上しています.
この結果は,従来の Web データの直接利用と比較して,LLMによる合成データの活用がより効果的である可能性を示唆していると言えます.
実験3: 双方向テンプレートの効果検証
この実験では,複数のテンプレート形式によるデータ表現の多様性を確保したデータセットがモデルの知識活用に寄与するかどうかについて検証を行いました.
用いるテンプレートとして,業種区分を回答とするテンプレート1 に加え,逆に業種区分を質問文に含み,銘柄情報を回答とするテンプレート の効果を検証します
実験設定として以下の二つのものを用意します.
- 業種区分を回答とするテンプレートのみを使用し,4 エポックの訓練を行う条件(w/o reversing と呼びます.)
- 業種区分を回答とするテンプレート と 業種区分を質問文に含み,銘柄情報を回答とするテンプレート両方を使用し,それぞれ 2 エポックずつ訓練を行う条件(w/ reversing
両条件において正解データの観察回数を 4 回に統一し,双方向的な質問応答形式を訓練データに含めることの効果を適切に評価します.
| 正答率 | |
| LLM生成 w/ reversing | 0.37 |
| LLM生成 w/o reversing | 0.33 |
| ルールベース生成 w/ reversing | 0.33 |
| ルールベース生成 w/o reversing | 0.30 |
上の表に双方向テンプレートの有効性を検証した結果を示します.ルールベース及び LLM
ベースで合成されたいずれのデータを用いても,逆向きの形式であるテンプレート 2を加えた方が,加えない場合よりも良好な結果を示しました.本実験結果は,多様な表現形式を用いたアプローチが単一の表現形式と比較してより効果的である可能性を示しています.
実験4: データの品質分析
この実験では,ルールベースに基づくデータとLLMによるデータの業種区分予測性能が異なる原因を,モデルに対するテキストの損失値の観点から分析します.具体的には,事前学習済みモデルのpfnet/nekomata-14b-pfn-qfinに対して,全テンプレートのデータを含んだ各データセットのパープレキシティを計測します.
| Perplexity ↓ | |
| ルールベースによるデータ | 12.8 |
| LLMによって生成したデータ | 4.2 |
上の表に各データセットに対するPerplexityを示します.結果からわかるように,LLM ベースのデータは 4.2 という低いパープレキシティを示した一方で,ルールベースに基づくデータは 12.8 と高いパープレキシティを示しました.
このことから,Perplexityの低いデータがモデルのファインチューニング時に有効的に知識活用を促す可能性が示唆されます.
実験5: データ混合比率とPerplexityの関係性分析
本実験では,前の実験で確認されたデータ品質の違いを踏まえ,Perplexity の予測性能に対する影響を詳細に分析します.具体的にはLLM ベースデータとルールベースデータの混合比率を段階的に変化させ,Perplexity の異なるデータセットを作り,そのデータセットで訓練されたモデルの予測性能を分析します.
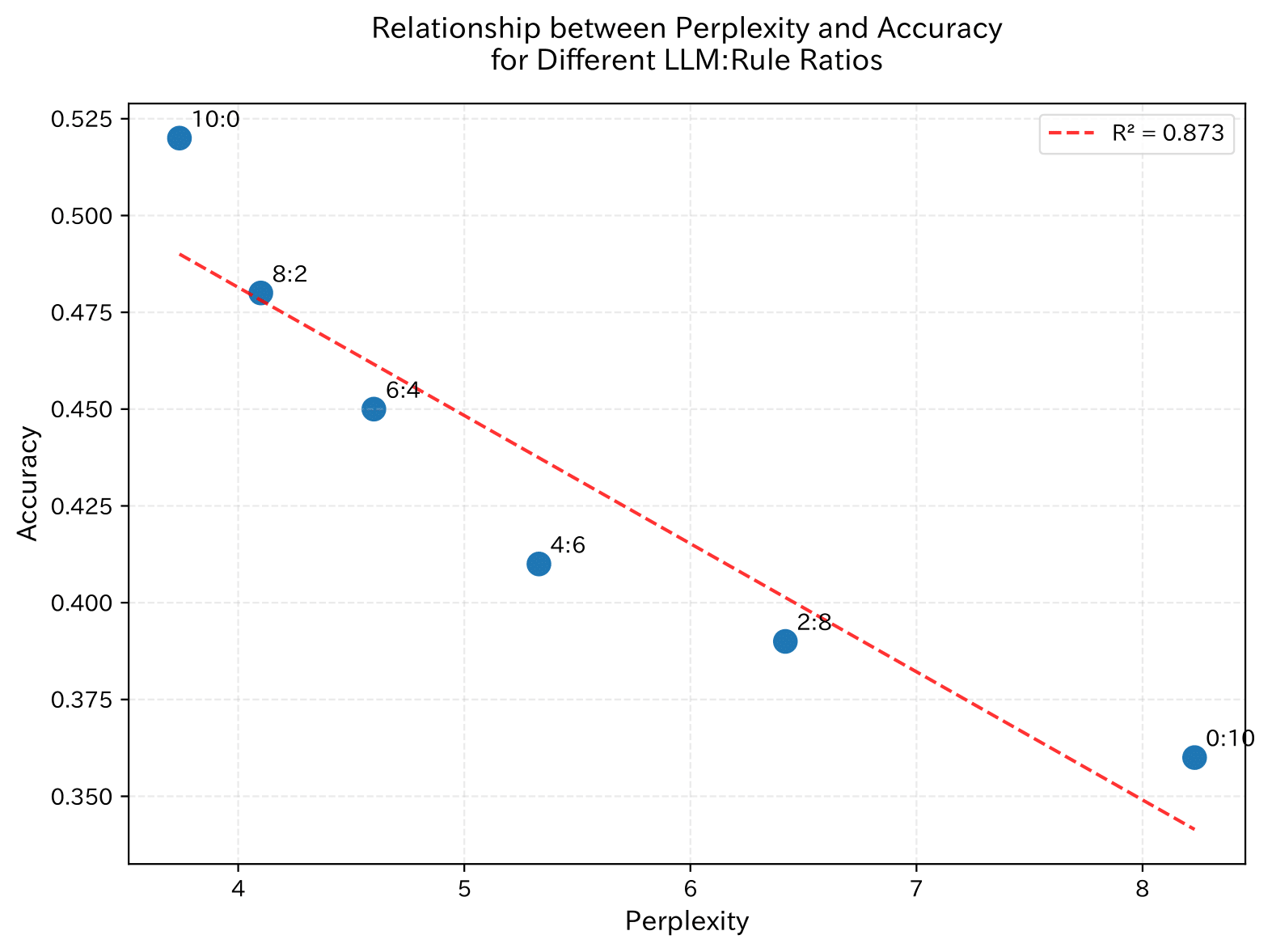
上の図はデータの混合比率を変化させた際のPerplexityと業種区分予測の正答率の関係を示しています.図の横軸はPerplexity,縦軸は正答率を表しており,各点のラベルは LLM ベースデータとルールベースデータの比率(LLM:Rule)を示しています.
この結果から,以下の3つのことがわかります.
- LLMベースデータの比率を下げるに連れて,Perplexity が単調に上昇すること
- Perplexityとaccuracyの間に強い負の相関がみられ,データの品質が予測性能に直接的な影響を与えること
この結果は,LLMベースデータを主体とした,低いPerplexityを示すデータセット構築が,業種区分に関する知識活用をより促す可能性を示唆しています.
結論
本インターンでは,金融ドメインにおける LLM の業種区分予測能力の向上を目的として,多様なテンプレートと合成データを用いたデータセットの設計方法の提案,および,その効果を検証しました.具体的には,4 つの質問応答テンプレートを設計し,ルールベース,およびLLM ベースの 2 つのデータ生成アプローチを比較検討しました.
上記の実験結果から,
- LLM ベースの合成データを用いた場合,ルールベースのデータと比較して性能が向上すること
- 知識表現の双方向テンプレートの活用により,知識の多様な表現が単一の表現方法と比較して,より予測精度に寄与すること
- データ品質の分析から,LLM ベースデータは事前学習済みモデルの分布により近い表現を形成しており,これは低いパープレキシティと高い予測正答率の相関関係として現れること
が確認できました.
これらの知見は,LLM の金融ドメインへの適用に対して,効果的なデータセット設計の指針を提供するものになります.
感想
「金融 x LLM」で面白いことをしてみたいという漠然とした動機で本インターンのテーマに取り組みましたが,メンターの皆様と毎日議論させていただくことで問題点や取り組むべき方向などをクリアにすることができました。
7週間という短い期間の中でしたが,優れた研究者・開発者の皆さんが集まる環境で行えたのは自身にとって、大変大きな経験となりました。アドバイスいただいた金融チームの方々、特にメンターの平野さん・imosさん、ありがとうございました!
Area