Blog
この記事は、パートタイムエンジニアとして勤務いただいていた大森功太郎さんによる寄稿です。
はじめに
こんにちは。2022年度から2023年12月までPreferred Networksでインターンおよびパートタイマーを務めさせていただいた、東京大学大学院 博士課程1年の大森功太郎です。大学ではヒューマンコンピュータインタラクションについて研究しており、PFNではHCI for MLに関する研究に携わらせていただきました。
PFNでは、インターンとパートタイムの期間を通じて、2次元のビデオ中の物体に対する3次元バウンディングボックスのアノテーションのためのインタフェースについて扱わせていただきました。インターン中の成果については、ACMの論文誌であるPACMHCIに掲載されています。詳細はOomori et al. (2023)[1]を参照ください。当該論文では、複数の視点から2次元のバウンディングボックスを手動でアノテーションすることにより、ビデオの2次元フレーム郡から自動で計算された物体のポイントクラウドを削り出し、3次元のバウンディングボックスをアノテートする手法について研究しました。
これに対し、このブログでは、パートタイムの後半の期間を通じて行っていた、Segment-Anything maskを用いて半自動で物体のマスクを計算し、このマスクによってポイントクラウドを削り出すことで3次元バウンディングボックスのアノテーションを行う手法について記載します。
背景:インターン中の成果
今回の研究およびOomori et al. (2023)では、物体の周りを周回するような起動で撮影された2次元ビデオを対象としています。このビデオからフレームを一定の間隔でサンプリングして入力としました。PACMHCIに
掲載された論文の段階では、この入力フレームからStructure from Motion (SfM)およびMulti-View Stereo (MVS)を用いて密な点群を再構成し、この点群をユーザ入力によって削り出すことでアノテーション対象の物体の点群を求め、最終的なバウンティングボックスを計算していました(図1)。この際、ユーザは入力となった複数視点のフレームに対し、物体を囲む2次元バウンディングボックスを描くことでアノテーションを行いました。物体は支持基底面に乗っている前提となっており、この支持基底面がバウンディングボックスの底面となっています。支持基底面は密な点群からRANSACアルゴリズムを用いて推定したものを使用しています。また、補助的な機能として、支持基底面以下の高さの点群を一括で削除する機能や、支持基底面とみなす平面の高さを調節する機能、細かい点群を除去するために入力矩形内の点群をカットする機能も実装しました。この手法はアノテーションの結果のグラウンドトゥルースと比較しての正確さと、アノテーションする人による結果のばらつきの少なさが、ベースライン(3次元インタフェースによるマニュアルの3次元ボックスアノテーション)よりも優位であることを示しました。
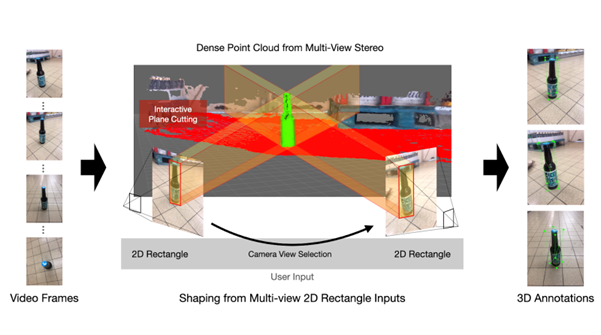
図1:2次元矩形をユーザ入力とした3次元バウンディングボックスのアノテーション (Oomori et al. 2023)
しかし、この手法ではアノテーションにかかる作業時間はベースラインとの間に差がなく、また一部の物体に対してかかる作業時間が長くなってしまうという課題がありました。
提案手法
これに対し、パートタイマー期間の後半では、ユーザの入力を「数点のプロンプト」のみに抑えることで、労力と作業時間を削減することを目指しました。Segment-Anythingモデル[2]は、画像中に数点のプロンプトを入力することで、そのプロンプトに該当する物体のマスクを作成することができます。本提案では、入力となるビデオフレーム全体で共通したマスクを求めるため、Track Anything[3]という、入力フレーム間で、あるフレームに対してマスクを作成したオブジェクトのトラッキングが可能な手法を用いました。これにより、ユーザがすべてのフレームに対してプロンプトを入力することなく、すべてのフレームに対する対象物体のマスクを作成することができます。このマスクを用いて、物体の点群の削り出しおよび3次元バウンディングボックスの計算を行います(図2)。点群切り出しは、Track Anythingを用いて作成したマスクを用いてShape from Shillouatte法[4]を用いて行っています。また、今回MVS適用後の密な点群だけでなく、SfMのみによって得られた疎な点群を削り出すことによるアノテーションについても検証しました。疎な点群についてはそのままRANSACアルゴリズムを適用しても支持基底面を推定することが困難であったため、支持基底面についてもTrack Anythingによってマスクを作成し、削りだされた床面の点群に対してRANSACアルゴリズムを適用して支持基底面の方程式を求めています。3次元バウンディングボックスの底面はOomori et al. (2023)の時と同じくこの支持基底面と一致するようになっています。
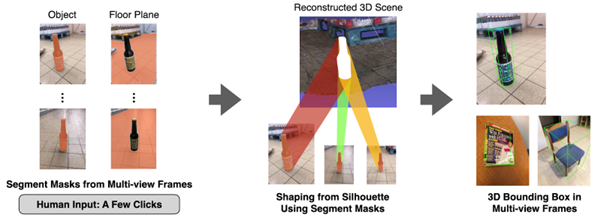
図2:数点のポイントプロンプトを入力とした3次元バウンティングボックスのアノテーション
予備的な検証
パートタイマー期間中に結果の精度について、予備的な検証を行いました。データセットとしてGoogleの公開しているObjectronデータセットを使用し、8種類のオブジェクトについて各2つずつ、合計16のデータについて検証を行いました。結果としては、Oomori et al. (2023)の際の実験でグラウンドトゥルースと比較しての3D IoUが平均86%、標準偏差0.06ほどであったのに対し、今回の手法では密な点群を用いた場合で平均83%、標準偏差0.14、疎な点群を用いた場合で平均65%、標準偏差0.26ほどの精度となりました。この結果はすべてのフレームでマスク領域に該当していた点群のみを残す方法で検証したものになります。また、今回の検証では求めた支持基底面以下の高さにある点群を消去する処理は行っておらず、点群のカットはすべてShape from Shillouatteで行っています。
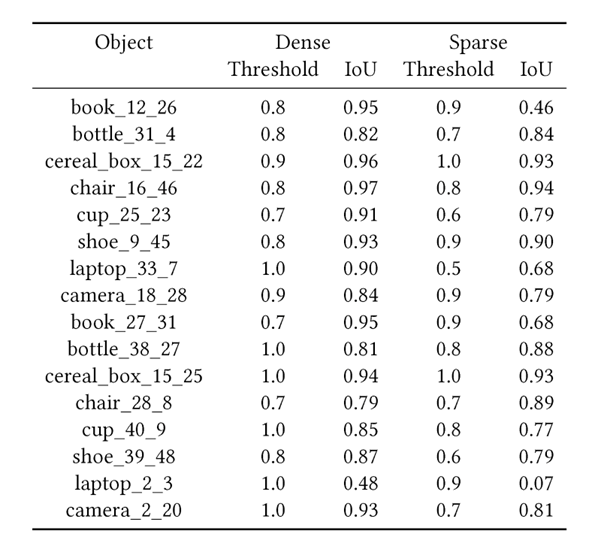
また、Shape from Shillouatteの適用時に、すべてのフレームでマスク領域に該当していた点群のみを残す方法だけでなく、何割の入力フレームで対象物体としてカウントされていたかを各点群についてカウントしておき[0.0-1.0]、閾値を設定してその閾値以上のカウントを持つ点群を残す方法についても検証しました。Objectronデータセットについて、ビデオの撮影時に物体の端が切れてしまうような方法で撮影されているデータが散見されました。端が切れているマスクを使用すると、本来削るべきでない点群まで削ってしまうことになります。これの対処として閾値を用いる方法についても検証しました。それぞれ1割刻みで閾値を設定した結果、もっとも精度が良かった閾値とその精度の組み合わせを示した表が以下になります(Denseが密な点群から切り出しを行った場合、Sparseが疎な点群から切り出しを行った場合)。リミテーションとして、支持基底面以下の点群を消去する処理を入れることで結果に影響がある可能性がありますが、今回はその検証は行えていません。
感想
今回の期間中には実際にかかる労力や時間がどうなるかという比較検証ができなかったことが悔やまれますが、この記事を読んだ誰かが後世に役立てていただければ冥利に尽きます。
まとめ
この記事では、インターン中に取り組んだ課題から発展して、ユーザの入力を「数点のプロンプト」のみに抑えた、2次元ビデオ中の物体への3次元バウンディングボックスのアノテーションについて記載しました。改めて約1年半という長い期間お世話になったPFNの方々、とりわけ主たるメンターとなっていただいた樋口啓太さんに感謝します。
Reference
- Kotaro Oomori, Wataru Kawabe, Fabrice Matulic, Takeo Igarashi, and Keita Higuchi. 2023. Interactive 3D Annotation of Objects in Moving Videos from Sparse Multi-view Frames. Proc. ACM Hum.-Comput. Interact. 7, ISS, Article 440 (December 2023), 18 pages. https://doi.org/10.1145/3626476
- Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick. 2023. Segment Anything. arXiv preprint arXiv:2304.02643.
- Jinyu Yang, Mingqi Gao, Zhe Li, Shang Gao, Fangjing Wang, and Feng Zheng. 2023. Track anything: Segment anything meets videos. arXiv preprint arXiv:2304.11968.
- Schneider, D.C. (2014). Shape from Silhouette. In: Ikeuchi, K. (eds) Computer Vision. Springer, Boston, MA. https://doi.org/10.1007/978-0-387-31439-6_206
