Blog
概要
Preferred Networks (以下PFN) ではPLaMoというLLM (Large Language Model、大規模言語モデル) の開発を行っています。今回、PLaMoをベースとしたテキスト埋め込みモデルPLaMo-Embedding-1Bを開発しました。
テキスト埋め込みモデルは、文章を数値ベクトルに変換することができるモデルで、意味的に近い文章は近いベクトルに、意味的に遠い文章は遠いベクトルになるように学習されています。この性質を利用して、数値ベクトルを介して文章同士の類似度を計測することができ、情報検索などの用途で広く用いられています。RAG (Retrieval Augmented Generation) の構築のためにも重要なモデルです。
今回開発したPLaMo-Embedding-1Bモデルは、日本語のテキスト埋め込みベンチマークであるJMTEBで、OpenAIのtext-embedding-3-largeなどを上回り、トップクラスの性能を達成しました。特に検索タスクで優れた性能を示しています。
このモデルの重みをHugging Faceで公開しました。 Apache v2.0ライセンスで公開されており、商用利用を含めて自由にお使い頂けます。
https://huggingface.co/pfnet/plamo-embedding-1b
本Tech Blogでは、このモデルの背後にある技術的詳細について説明します。
背景
テキスト埋め込みモデルは、文章を数値ベクトルに変換することができるモデルです。
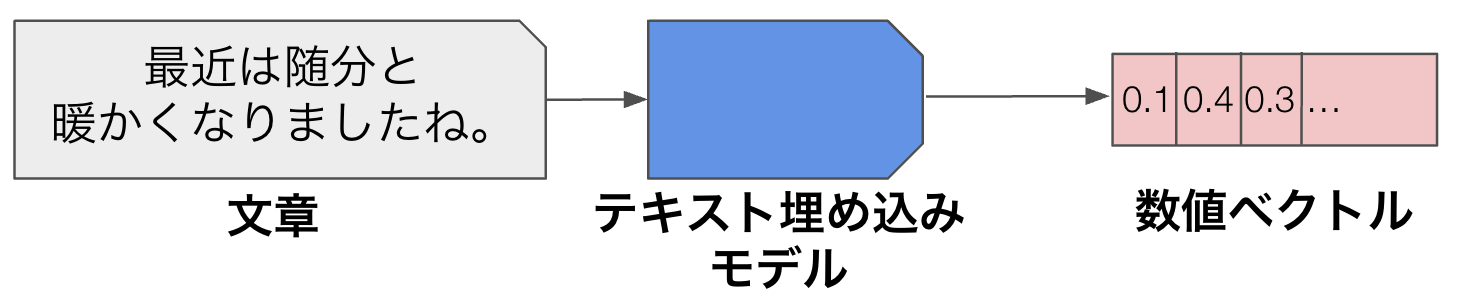
図1: テキスト埋め込みモデルの概念図
テキスト埋め込みモデルは基本的に、意味的に近い文章は近いベクトルに、意味的に遠い文章は遠いベクトルになるように学習されています。すなわち、意味的に近い文章同士のベクトルの類似度を計算すると高い値を取り、意味的に遠い文章同士のベクトルの類似度を計算すると低い値を取ります。
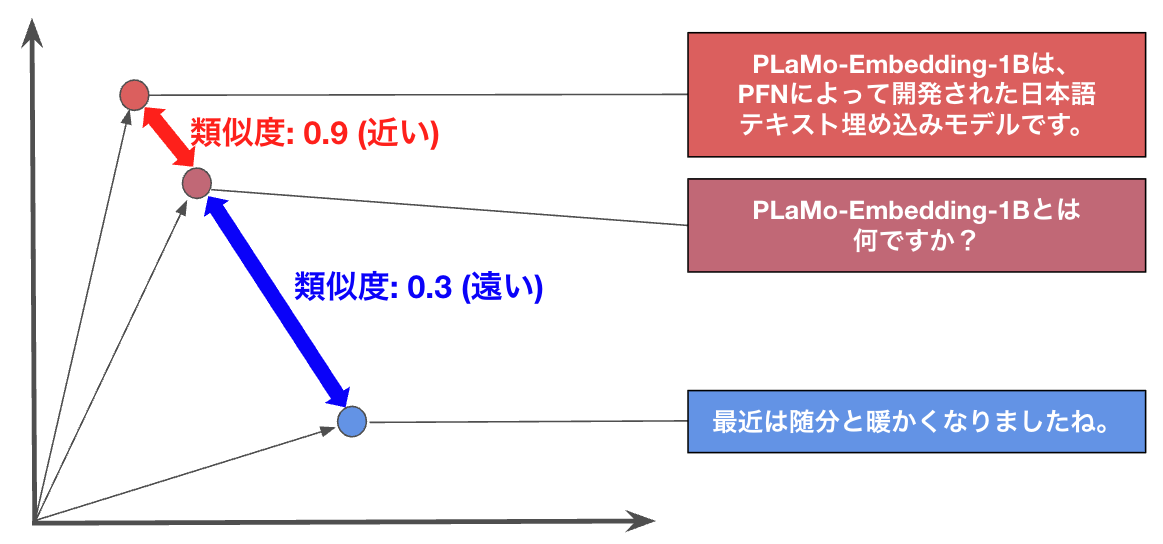
図2: テキスト埋め込みモデルの性質のイメージ (2次元ベクトルの場合の概念図)
テキスト埋め込みモデルは、この性質を利用して、情報検索、文章の分類、クラスタリングなどをはじめとした幅広い用途で用いることができます。中でも特に主要な用途と言えるのは情報検索で、RAGの背後にもこの技術が用いられています。事前に検索対象の文章のベクトルを計算しておき、ユーザーのクエリと最も類似度の高いベクトルを最近傍探索することで、膨大な文書集合の中から欲しい文章を検索することができます。
情報検索の文脈におけるテキスト埋め込みモデルの強みは、表記揺れに対して比較的強いことです。Okapi BM25などのいわゆる単語マッチング検索では、ユーザーの質問に含まれる単語と同じ単語が登場する文章を検索するため、表記揺れに弱いという課題があります。例えば、「ディープラーニング」と「深層学習」は概ね同じ意味で用いられますが、単語マッチング検索では前者で検索された場合に、後者を含む文章をヒットさせるのが困難です (類義語辞書を使うなどの対処法は存在しますが)。テキスト埋め込みモデルは、文章をベクトルに変換し、その間の類似度を計算するため、このベクトル表現がうまく学習されていれば、こういった表記揺れもうまく吸収して検索することができます (実際、PLaMo-Embedding-1Bで「ディープラーニング」と「深層学習」の両方をベクトルに変換し、cosine類似度を計算すると、0.9以上の高い値を取りました)。とはいえ単語がマッチしていればきちんとヒットする単語マッチング検索も非常に強力であるため、この両者を組み合わせて検索を実施することがより良い検索システムの構築におけるベストプラクティスの1つとなりつつあります (例: Azure AI Search: Outperforming vector search with hybrid retrieval and reranking)。
こうした背景の元、PFNでは2024年の夏インターンで「PLaMoをベースにしたテキスト埋め込みモデルの開発」に取り組んで頂きました。この時点での成果についてはTech Blogの当該記事をご参照ください。インターンさんの多大な頑張りもあり、この時点でOpenAIのモデルなどに迫る良い性能のモデルが得られたため、PLaMo-Embedding-1Bはそれをさらに発展させたものになります。インターンを通して得られた知見が、更なる成果に繋がったという意味でも意義深い取り組みになったと考えています。
評価
PLaMo-Embedding-1Bモデルの性能を、日本語のテキスト埋め込みベンチマークであるJMTEBで計測しました。
表1: PLaMo-Embedding-1BのJMTEBの結果
| モデル | 全体平均 | Retrieval | STS | Classification | Reranking | Clustering | PairClassification |
| intfloat/multilingual-e5-large | 70.90 | 70.98 | 79.70 | 72.89 | 92.96 | 51.24 | 62.15 |
| pkshatech/GLuCoSE-base-ja-v2 | 72.23 | 73.36 | 82.96 | 74.21 | 93.01 | 48.65 | 62.37 |
| OpenAI/text-embedding-3-large | 74.05 | 74.48 | 82.52 | 77.58 | 93.58 | 53.32 | 62.35 |
| cl-nagoya/ruri-large-v2 | 74.55 | 76.34 | 83.17 | 77.18 | 93.21 | 52.14 | 62.27 |
| SBIntuitions/Sarashina-Embedding-v1-1B | 75.50 | 77.61 | 82.71 | 78.37 | 93.74 | 53.86 | 62.00 |
| PLaMo-Embedding-1B (our model) (*) | 76.10 | 79.94 | 83.14 | 77.20 | 93.57 | 53.47 | 62.37 |
2025/04初頭時点で、OpenAIのtext-embedding-3-largeなどの他社モデルを上回り、日本語テキスト埋め込みモデルとしてトップのスコアを記録しています (**)。特にテキスト埋め込みモデルの主要な用途と言えるRetrieval (検索タスク) では既存のモデルの最高スコアから2ポイント以上の更新を達成しており、情報検索での利用に適したモデルであることを示唆していると言えます。
(*) コンテキスト長1024で計測 (以降も断りがなければ同様)。これは学習時に用いたコンテキスト長が1024までであるため。ただし、ベースモデルの最大コンテキスト長であり、PLaMo-Embedding-1Bのconfig上の最大コンテキスト長である4096で計測しても、そこまで性能が下落するわけではないことがわかっています (Appendix参照)。
(**) 2025/04/14にRuri-v3が公開されたため、現在は更新されています。
手法
学習の全体像
以下の図に、PLaMo-Embedding-1Bの学習の全体像を示します。
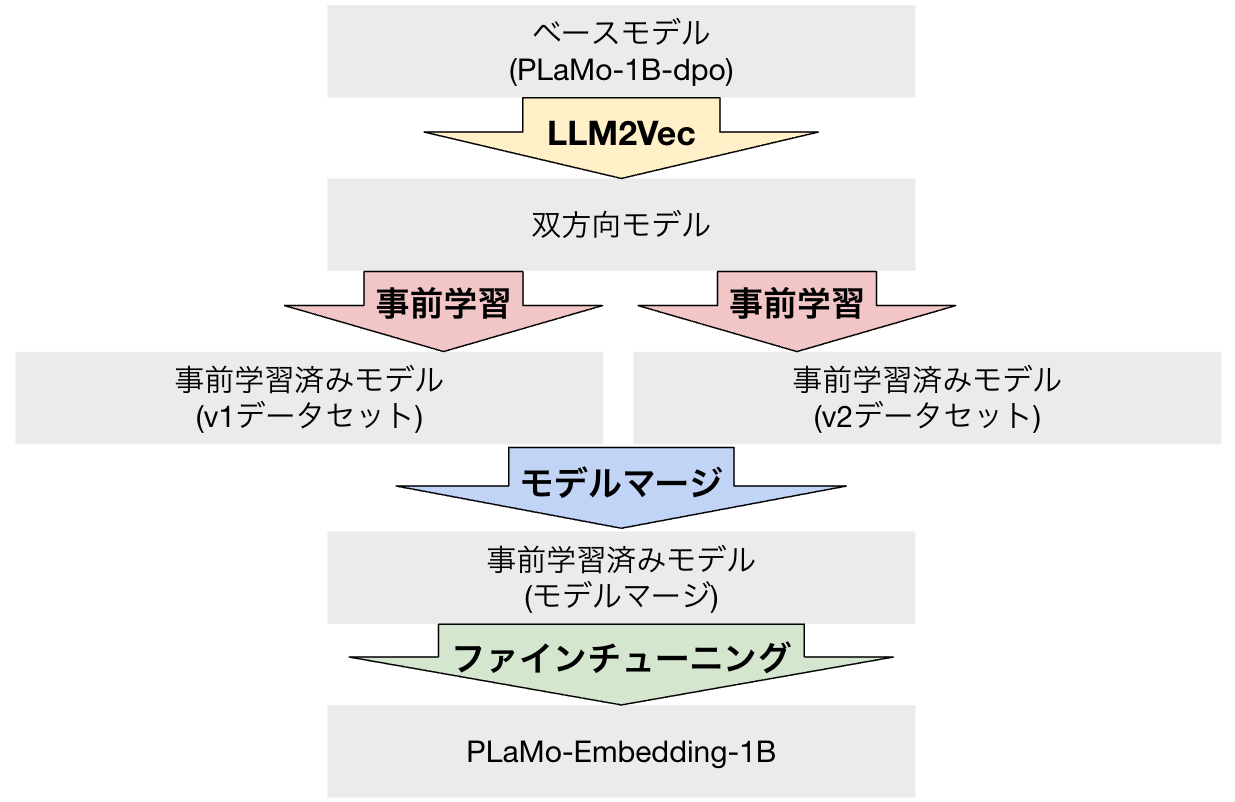
図3: PLaMo-Embedding-1Bの学習の全体像
ベースモデルとしてPLaMo-1B-dpoというモデルを用いています (*)。これは以前PFN内で学習された1BサイズのLLMで、指示学習 (SFT、Supervised Fine Tuning) とDPO (Direct Preference Optimization) を適用済みのモデルです。インターンでの検証結果から、事前学習のみを行った1Bモデル、SFT済みモデルと比較して、DPO済みモデルの結果が最も良かったため、これをベースに用いています。
このベースモデルに対して、以下の4つの工夫を加えることで、PLaMo-Embedding-1Bを構築しています。
- LLM2Vec
- 事前学習
- モデルマージ
- ファインチューニング
これらの工夫について、詳細を順に説明します。
(*) このPLaMo-1B-dpoモデルは、PLaMo Liteとは異なる社内開発用のモデルとなります
LLM2Vec
今回用いているベースモデルのPLaMo-1B-dpoを含めて、ほとんど全てのLLMはTransformerによって実装されており、中でも特にCausalモデルが用いられます。これは図4にあるように、あるステップでのトークンの予測のために、それ以前の、すなわち過去のトークンまでの情報のみを用いるモデルとなっています。LLMは言語の生成をする必要があるため、各ステップでのトークンの生成のために未来の情報を用いることはできません。具体例を挙げれば、「今日/は/良い/天気/です/ね」という文章を生成する際、「良い」を生成する時点でまだ生成されていない「天気」のトークンの情報を見ることはできません。このため、Causalモデルが用いられます。
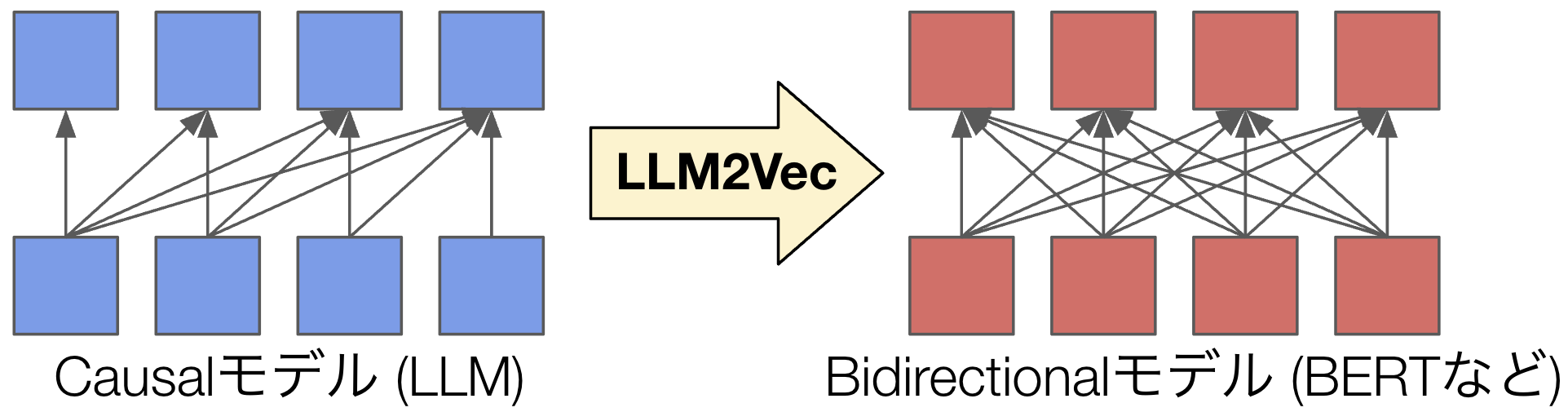 図4: LLM2Vecの概念図
図4: LLM2Vecの概念図
一方で、テキスト埋め込みモデルとしての主流はBidirectionalモデルです。これはBERTなどのLLM以前から存在したTransformerモデルのアーキテクチャです。テキスト埋め込みにおいては、言語の生成と異なり、未来の情報も含めて全てのトークンの情報を用いることができます。「今日/は/良い/天気/です/ね」という文章を生成するのではなく、すでにその文章全体は存在する前提で、そのテキスト埋め込みを計算するだけなら、「良い」に関連する埋め込みを考慮する時点で、未来の「天気」のトークンの情報を用いても構いません。一般には、より使える情報量が多いという意味で、モデルサイズが同じならBidirectionalモデルの方が優れた性能を示す可能性があると考えられます。
これらの事情から、LLMをベースモデルとして用いる場合のテキスト埋め込みモデルの構築方法として、LLM2Vecが考え出されました。これはシンプルにCausalモデルをBidirectionalモデルに変換する手法です。CausalモデルでもBidirectionalモデルでも全体のアーキテクチャは同一で、Causalモデルの場合は未来の情報に依存しないようにするためのマスクがかかっているだけなので、単にこれを外すだけで変換することができます。LLM2Vecの原著論文では、そこから更に “masked next token prediction” と “unsupervised contrastive learning” という学習を行いますが、PLaMo-Embedding-1Bでは、Bidirectionalモデルへの変換の実施後は、以下に説明するように異なる学習方式を用いています。
事前学習
近年のテキスト埋め込みモデルの学習においては、「大規模なデータセットによる事前学習」「より高品質なデータによるファインチューニング」という2段階の学習アプローチを取ることが一般的です。このアプローチはE5の論文に始まり、RuriやSarashina-Embedding-v1-1Bなどの近年の強力な日本語テキスト埋め込みモデルでも用いられています。PLaMo-Embedding-1Bの開発でも、全体としてこのアプローチに倣っています。
事前学習 (および後のファインチューニング) における学習は対照学習というアプローチで実施しています。これはある文章 (以下 “query” ) に対して、それと意味的に近い文章である “positive” と意味的に遠い文章である ”negative” の両方を準備し、queryとpositiveは近づけ、queryとnegativeは遠ざけるように学習する、という方式になります。そもそも意味的に近い文章が近いベクトルになるようなモデルを学習しようとしているので、これは直感的にもわかりやすい学習方式になっています。
具体的な損失関数としては、GTEと同じInfoNCE lossを用いています。損失関数の詳細についてはGTEの論文をご参照頂けると幸いですが、queryとpositiveを近づけ、queryとnegativeを遠ざけつつ、同一バッチ内に存在する異なるデータサンプルのquery同士や、positive、 negative同士も遠ざけるように学習することで、学習に活用できる勾配を増やしているような手法になります。イメージ的には、同一バッチ内であっても異なるデータサンプルであれば意味的には無関係、すなわち遠ざけて良い可能性が高いと考えられるので、それを損失に活用しているといった形になります。
また、少し細かい部分になりますが、学習時の各ミニバッチの構築時に、GTE、 InstructORに倣い、”task-homogeneous batching” と呼ばれる、同一バッチ内には同一のデータセットのみが含まれるようにする工夫を導入しています。これは、損失関数に同一バッチ内の異なるデータサンプルの文章同士を遠ざけるように学習する工夫が導入されている関係上、このタスクを極端に簡単にしすぎないように、ある程度近い傾向のデータでミニバッチを構成するという意図の工夫になっています。また、同一バッチ内のデータの長さがある程度揃いやすくなるので、極端に長い文章のために長くpaddingすることが少なくなり、学習効率にもやや寄与すると考えられます。
今回は2種類の学習データセットで事前学習を実施しました。以後それぞれを「v1データセット」「v2データセット」と呼びます。これは当初計画していたというよりは、元々v1データセットで学習を実施していたところ、開発の途中で新しいデータセットが利用可能になったためv2データセットを準備した、という流れになっています。
v1データセットの構成は以下のようになっています。
表2: v1データセット
| データセット名 | サンプル数 |
| auto-wiki-nli-triplet | 176,128 |
| auto-wiki-qa-dataset | 2,273,280 |
| auto-wiki-qa-nemotron-dataset | 151,552 |
| cc-news (ja) | 774,144 |
| jaquad-dataset | 28,672 |
| jrc | 12,288 |
| jsnli-triplet | 131,072 |
| jsquad-dataset | 57,344 |
| mqa | 4,272,128 |
| snow-triplet | 61,440 |
| wikipedia-abs-article | 1,384,448 |
| wikipedia-paragraphs-1 | 4,558,848 |
| wikipedia-paragraphs-3 | 5,300,224 |
| wikipedia-title-abs | 1,388,544 |
| 合計 | 20,570,112 |
v1データセットは、全体として、hpprc/embデータセットに非常に丁寧にテキスト埋め込みモデルの学習に使えるデータセットが整備されているので、こちらをベースに構成しています。
後述しますがより高品質なデータセットを構築するためのフィルタリングを実施しており、そのため元のデータセットのサンプル数とは一致しない数になっています (v2データセットにおいても同様)。また、task-homogeneous batchingの関係で、バッチサイズ (事前学習では4096) の定数倍から余った部分のデータサンプルは切り捨てられています (これもv2データセットにおいても同様)。
v2データセットの構成は以下のようになっています。
表3: v2データセット
| データセット名 | サンプル数 |
| aozora-yomi | 4,096 |
| auto-wiki-nli | 192,512 |
| cc-news | 753,664 |
| ihyoki | 606,208 |
| jaquad-dataset | 28,672 |
| jawiki-abst | 1,060,864 |
| jawiki-paragraphs1 | 4,419,584 |
| jawiki-paragraphs3 | 3,375,104 |
| jrc | 24,576 |
| jsnli | 163,840 |
| jsquad-dataset | 57,344 |
| llmjp-kaken | 2,244,608 |
| llm-japanese-dataset (subset) | 1,478,656 |
| mqa | 8,953,856 |
| snow | 61,440 |
| sudachi-dict | 53,248 |
| warp-html | 368,640 |
| wiki-qa | 21,880,832 |
| wordnet-ja-synonyms | 12,288 |
| PFN独自収集データ | 49,795,072 |
| 合計 | 95,535,104 |
v2データセットは、全体として、cl-nagoya/ruri-dataset-v2-pt データセットに非常に丁寧にテキスト埋め込みモデルの学習に使えるデータセットが整備されているので、こちらをベースに構成しています。一方で、PFN独自収集データもかなりの数を導入しています。これによりデータの数としては十分なものが確保できたので、cl-nagoya/ruri-dataset-v2-pt データセットのうち、LLMによる合成データセットなどを一部除外し、少しデータの数を圧縮しています。
これらのデータセットを用いて、事前学習を実施しました。バッチサイズは4096とし、A100 GPUを8枚用いて、v1データセットに関しては1日前後、v2データセットについては5日前後で学習が完了しました。ハイパーパラメータの詳細についてはAppendixをご参照ください。
事前学習時点でのJMTEBの結果を表4に示します。この時点で、OpenAIのモデルと比較して、Retrievalにおいては両方のモデルが、全体平均においてはv2データセットを用いたモデルはすでに上回っており、かなり優秀なスコアを記録していることが見て取れます。また、より多く、かつ多様なデータを導入したv2データセットが、特にRetrievalタスクで優れた性能を示していることが伺えます。
表4: 事前学習時点でのJMTEBの結果
| モデル | 全体平均 | Retrieval | STS | Classification | Reranking | Clustering | PairClassification |
| v1データセット | 73.88 | 75.44 | 81.31 | 75.98 | 93.50 | 53.71 | 62.06 |
| v2データセット | 74.77 | 77.52 | 83.21 | 75.47 | 93.56 | 53.38 | 62.54 |
モデルマージ
事前学習をv1、 v2の2つのデータセットで実施したため、やや異なる傾向の事前学習済みモデルが2種類できました。次はRuriの知見に倣い、これらのモデルをモデルマージすることで性能を向上できないかを検討しました。
モデルマージは、複数の異なるモデルのパラメータを1つにまとめることで、ある種の「良いとこどり」をできないかを狙う手法です。今回はシンプルに、”Linear” と呼ばれる2つのモデルのパラメータを単純に平均する方法を用いました。
モデルマージの結果を表5に示します。Transformerモデルのような複雑なパラメータを持つモデルについて、単にパラメータを平均化するだけで性能が向上するというのは驚きですが、実際に今回も性能の向上が確認できています。個別のタスクの結果を見ても、マージ元のモデルの性能の良いとこどりをするに留まらず、マージ元のモデルのどちらよりも良い性能に到達することさえあり、モデルマージの可能性の大きさがよく現れています。
表5: モデルマージを行った場合のJMTEBの結果
| モデル | 全体平均 | Retrieval | STS | Classification | Reranking | Clustering | PairClassification |
| v1データセット | 73.88 | 75.44 | 81.31 | 75.98 | 93.50 | 53.71 | 62.06 |
| v2データセット | 74.77 | 77.52 | 83.21 | 75.47 | 93.56 | 53.38 | 62.54 |
| モデルマージ | 75.77 | 78.46 | 83.27 | 76.02 | 93.72 | 57.39 | 62.39 |
ファインチューニング
2つの事前学習済みモデルをマージしたモデルを事前学習済みモデルとし、E5、Ruri、Sarashina-Embedding-v1-1Bに倣い、より高品質なデータでのファインチューニングを実施しました。ファインチューニングの学習時の損失関数やミニバッチ戦略などは事前学習時と同様ですが、更なる性能向上を狙うために、ファインチューニングにおいては以下の追加の工夫を導入しています。
- より高品質なデータの利用
- より多数のnegativeサンプルの利用
- Hard-negativeの活用
ファインチューニングにおいては、事前学習時からさらなる性能向上を狙うため、より高品質なデータを利用することが一般的です。今回はhpprc/reranker-scoresに含まれるデータセットを用いました。詳細なデータセットの構成は以下のようになっています。今回もより高品質なデータセットを構築するためのフィルタリングを実施しており、そのため元のデータセットのサンプル数とは一致しない数になっていることにご注意ください。また、task-homogeneous batchingの関係で、バッチサイズ (ファインチューニングでは256) の定数倍から余った部分のデータサンプルは切り捨てられています。
表6: ファインチューニング時のデータセット
| データセット名 | サンプル数 |
| auto-wiki-qa-nemotron | 155,392 |
| jaquad | 31,488 |
| jqara | 2,048 |
| jsquad | 62,208 |
| miracl | 3,328 |
| mkqa | 3,584 |
| mr-tydi | 3,584 |
| quiz-no-mori | 20,224 |
| quiz-works | 16,384 |
| 合計 | 298,240 |
事前学習時においては、各queryとそれに対応するpositiveデータ、negativeデータが1つずつでした。ファインチューニングにおいては、各queryに対して15個のnegativeデータを用いています。これもRuriの設定に倣ったものになっています。
また、ファインチューニングにおいては、negativeデータの選定にあたって、Hard-negativeと呼ばれるより難しいnegativeデータを用いています。これは一見意味的には近いように見えるが、ベクトルとしては遠くなって欲しいような「難しい」データサンプルを用いることで、モデルにより高難易度なタスクを与えて学習を促進することに相当します。今回は hpprc/reranker-scores のnegativeサンプルをそのまま用いました。一般には、BM25検索や他のテキスト埋め込みモデルで、queryに近い文章を文書集合から検索し、上位の文章をHard-negativeとして用いることが多いです。
表7にファインチューニングの結果を示します。これが最終的なPLaMo-Embedding-1Bモデルになります。事前学習モデルと比較して、特にRetrievalタスクで大きな性能向上ができていることが確認でき、より高品質なデータを用いたファインチューニングの重要性が伺えます。
表7: ファインチューニングを行った場合のJMTEBの結果
| モデル | 全体平均 | Retrieval | STS | Classification | Reranking | Clustering | PairClassification |
| 事前学習モデル (モデルマージ) | 75.77 | 78.46 | 83.27 | 76.02 | 93.72 | 57.39 | 62.39 |
| ファインチューニングモデル (PLaMo-Embeddding-1B) | 76.10 | 79.94 | 83.14 | 77.20 | 93.57 | 53.47 | 62.37 |
追加の工夫: リランカースコアによるデータフィルタリング
今回、更なるデータセットの品質向上のための工夫として、リランカースコアによるデータフィルタリングを実施しています。
リランカーは、テキスト埋め込みモデルと同じく2つの文章の間の類似度を計算することを目的とした深層学習モデルですが、テキスト埋め込みモデルと異なりベクトルを経由せず、直接2つの文章を入力に取り、類似度を出力します。このモデルはベクトルを一度算出して事前計算しておけないため、大量の文書集合がある場合の検索などには不向きですが、一度ベクトルを経由しない分類似度の計算精度が高いと言われており、テキスト埋め込みモデルなどによる検索結果を最後に並び替え、より関連度の高いものを上位に持ってくる場合 (リランキング) 時に用いられることが多いモデルです。
より類似度を高精度に計算することができるモデルということで、リランカーモデルによるスコアを用いることで、queryとpositiveペアについて類似度が低すぎるものは、「潜在的に品質の低いpositiveペア」として、queryとnegativeペアについて類似度が高すぎるものは、「意味が近すぎるため不適切なnegativeペア」として、フィルタリングすることができると考えられます。
事前学習においては、BAAI/bge-reranker-v2-m3を用いて事前学習時の全てのデータサンプルに類似度スコアを付与し、類似度が0.1以下のpositiveサンプル、および類似度が0.9以上のnegativeサンプルを除外しました。これにより、事前学習時のデータサンプルの数は2/3程度になり、学習の高速化に大きく寄与しました。今回は性能的にはフィルタリング前後であまり差は見られませんでしたが、より少ない計算時間で同等の性能に到達できたという意味で価値があったと考えています。
ファインチューニングにおいては、hpprc/reranker-scores に複数のリランカーによる類似度スコアが含まれているため、それらの類似度スコアの平均を用いてフィルタリングを実施しました。類似度が0.2以下のpositiveサンプル、および類似度が0.8以上のnegativeサンプルを除外しました。ファインチューニングは特に高品質なデータで行うことが重要と言われているため、フィルタリングを強めにかけています。
追加の工夫: prefixの導入
今回検索タスクでの性能改善のための工夫として、prefixの導入を実施しています。特に検索タスクにおいては、ユーザーの質問文のようなクエリ文と、検索対象になるドキュメント本文は、文章の長さをはじめとして、かなり分布が異なると考えられます。このため、これらの埋め込みに非対称性を導入することが重要と考えられており、クエリに対して ”query:”、ドキュメントに対して “document:” のようなprefixを付与することで非対称性を導入する試みが、E5の時代より行われてきました。
また、近年においてはそれをより発展させた、テキスト埋め込みモデルにおけるInstructionという概念が導入されつつあります。これは intfloat/multilingual-e5-large-instruct などで導入されている工夫で、LLMにおけるプロンプトのように、テキスト埋め込みにおける各タスク (検索、文書分類、クラスタリング等) に対する指示文章を最初に付与することで、タスクごとに異なる傾向の埋め込みを生成できるようにし、性能向上を狙ったものです。
今回はそれらのやや中間のような方式を導入しており、クエリに対してのみ「次の文章に対して、関連する文章を検索してください: 」という固定のprefixを付与しています。ドキュメント側にはprefixを付与していないので、検索タスクにおいての両者の埋め込みに非対称性を導入する効果があると考えられます。この導入方式は、intfloat/multilingual-e5-large-instruct のようにタスクごとにInstructionを考えるのは、利用時の手間が大きいため避けつつ、今回のベースモデルがDPO済みのLLMであるため、自然言語で説明されたprefixを付与した方が効果的かもしれないと考えた結果、prefixとinstructionの中間のような方式になっています。なお、このprefix自体は固定の文章なので、最終的な埋め込みの計算においては影響を与えないように実装されています (平均プーリング時に除外しています)。
prefixの導入前後での、v1データセットでの結果を表8に示します。全体平均はあまり変わりませんが、Retrievalタスクでの性能にある程度改善があり、クエリとドキュメントの間での非対称性の導入による効果が伺えます。なお、評価時においては、RetrievalおよびRerankingタスクの場合のみクエリに対応する文章に上記のprefixを付与しており、それ以外はprefixなしで評価しています。
表8: prefix導入前後でのJMTEBの結果
| モデル | 全体平均 | Retrieval | STS | Classification | Reranking | Clustering | PairClassification |
| v1データセット – prefix | 73.85 | 74.96 | 81.59 | 75.96 | 93.43 | 54.96 | 61.54 |
| v1データセット | 73.88 | 75.44 | 81.31 | 75.98 | 93.50 | 53.71 | 62.06 |
実際の利用にあたっては、検索タスクのクエリ文章に限って `encode_query` メソッドを、それ以外は `encode_document` メソッドを用いることで、検索タスクのクエリ文章の場合のみ自動的にモデル内部でprefixが付与されます (詳細はHugging Faceのページを参照してください)。
まとめ
LLM2Vec、事前学習、モデルマージ、ファインチューニングを用いた学習パイプラインと、2つの工夫の導入により、元はLLMであるPLaMo-1B-dpoを優れたテキスト埋め込みモデルとしてチューニングすることができました。結果として完成したPLaMo-Embedding-1Bは、JMTEBベンチマークでトップクラスの性能を達成し、特に検索タスクで優れた性能を示しています。
モデルの重みはHugging Faceで公開されています: https://huggingface.co/pfnet/plamo-embedding-1b
モデルはApache v2.0ライセンスで公開されており、商用利用を含めて自由にお使い頂けます。
PFN/PFEではこのようなLLMやそれに関連した研究開発を進めています。本取り組みで得られた知見・成果は今後PLaMoに取り入れていく予定です。
Appendix
事前学習、ファインチューニングにおける主要なハイパーパラメータを以下に示します。
表9: 学習時のハイパーパラメータ
| 事前学習 | ファインチューニング | |
| 学習率 | 5e-5 | 5e-6 |
| バッチサイズ | 4096 | 256 |
| エポック数 | 1 | 1 |
| 最大コンテキスト長 | 256 | 1024 |
| negativeサンプルの数 | 1 | 15 |
また、本モデルはconfig上の最大コンテキスト長は4096ですが、学習時のコンテキスト長が1024までだったため、ベンチマークスコアはコンテキスト長1024で計算しました。一方、以下の表に示すように、4096で計測しても、多少の性能劣化はあるにせよ十分な性能を維持できることがわかっています。
表10: コンテキスト長を変えて評価した場合のJMTEBの結果
| モデル | 全体平均 | Retrieval | STS | Classification | Reranking | Clustering | PairClassification |
| PLaMo-Embedding-1B (4096 tokens) | 75.51 | 77.95 | 83.14 | 77.20 | 93.59 | 54.73 | 62.37 |
| PLaMo-Embedding-1B (1024 tokens) | 76.10 | 79.94 | 83.14 | 77.20 | 93.57 | 53.47 | 62.37 |