Blog
この記事は、金融チームインターンの伊藤 辰都さんによる寄稿です。
はじめに
2025年度夏季インターンシップに参加させていただきました、北海道大学修士1年の伊藤辰都です。普段は大学で、特定のタスクに特化したLLMモデルの精度向上に関する研究に取り組んでいます。
今回のインターンでは、投資家の方が業界全体を直感的に把握できる「業界マッピングWebアプリケーション」を開発しました。このツールには主に2つの機能を備えています。以下にデモ動画を示します。
1. 選択したテーマを可視化
- 可視化デモ
- 選択したテーマ(AI, ゲーム関連, 半導体)の可視化結果
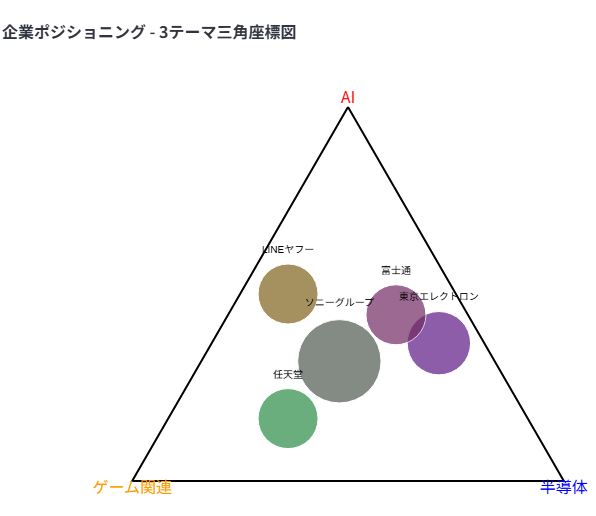
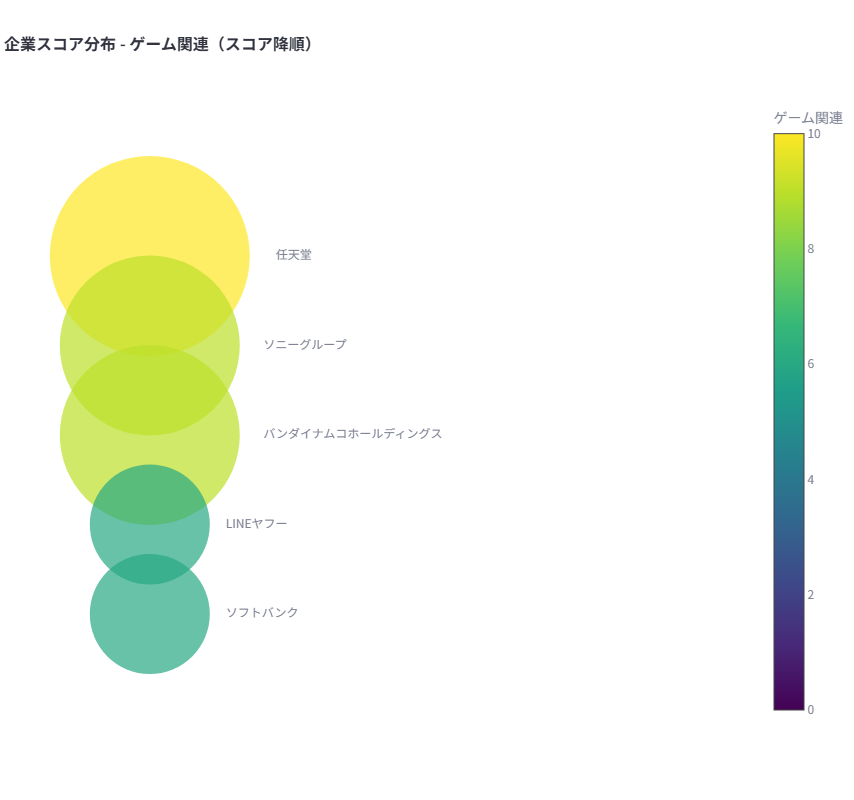
- 「半導体」では東京エレクトロン、「ゲーム関連」では任天堂が関連度が高い企業として表示されています。
- ※今回の分析対象はTOPIX100に含まれる企業に限定しています
2. テーマを追加
- テーマ追加デモ
- テーマ(ゲーム関連)追加後の結果
- デモではテーマである「ゲーム関連」と関連度の高い企業が表示されています。今回は、任天堂が最も関連度が高い企業となっています。
- これにより、ユーザは自由に新しいテーマを追加することができ、既存データに存在しない業界やキーワードについても分析可能になります。
背景
経済や企業活動において、投資は成長や競争力強化のために必要不可欠です。例えば、将来性のある分野や企業に資金を投入することで、企業の成長とともに資産を増やすことができます。それでは、投資判断を行う際、どのような情報が必要となるでしょうか。例えば、次のようなものがあります。
- 投資したい分野に取り組んでいる企業の情報
- 投資先企業の競合状況
- 各企業の売上や利益など財務面の健全性
こうした情報は、東洋経済新報社が発行する「会社四季報 業界地図」などで直感的かつ体系的に整理されています。本書は、情報通信・自動車・生活・公共サービスなどの多様な業界に対して有力な企業や市場動向を詳しく解説しており、投資家のバイブルとも呼ばれる存在となっています。このほかにも「業界地図」や「投資情報」をまとめた本やWebサイトが数多く存在します。では今回なぜ、新たに業界マッピングアプリを開発するに至ったのでしょうか。
理由の一つは、既存の情報源の多くが人手によるテーマと企業の関連付け作業に依存している点です。この方法は、アノテーションコストが高く、情報の網羅性に限界があるだけでなく、企業や市場の状況が日々変化する現実に対して柔軟に対応することが難しいという課題があります。結果として、一度作成した企業マップも短期間で陳腐化し、継続的な更新作業が必要となります。さらに、マイナーな分野や新興のテーマについては、既存の企業リストやレポートが存在しない場合も少なくありません。この場合、従来の情報源では十分な分析が困難です。
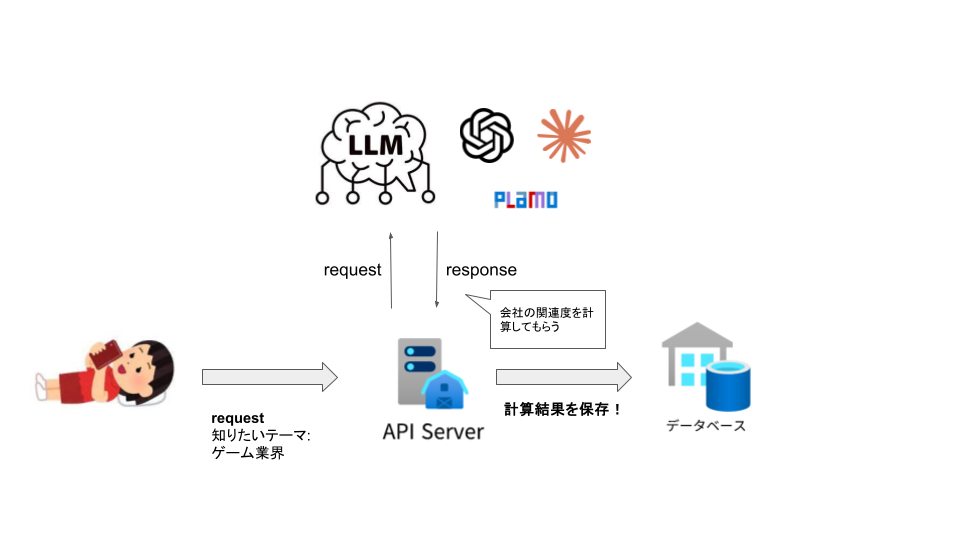
これらの課題を解決するため、今回のインターンではLLMを活用し、企業とテーマの関連度を自動推論する仕組みを実装しました。その結果をもとに、テーマごとの企業情報を可視化できる業界マッピングWebアプリケーションを開発しました。
Webアプリの機能紹介
今回開発したWebアプリの全体像について説明します。アプリ内では次の可視化手順を繰り返すことで、テーマと企業の関連マップを充実させていきます。
手順
1. 既存データの可視化
データベースをもとにテーマと企業の関係を、業界マッピングやクラスタリングで可視化
2. ユーザによるテーマ追加
例えば、「自動運転」「宇宙開発」など、自由に新しいテーマを登録可能
3. LLMによる関連度推論
バックエンドで全企業との関連度を0~10のスコアで推論し、テーマとの結びつきを評価
4. 結果の反映
推論結果をデータベースに追加し、可視化マップを更新。手順1に戻る
手順過程のイメージ図
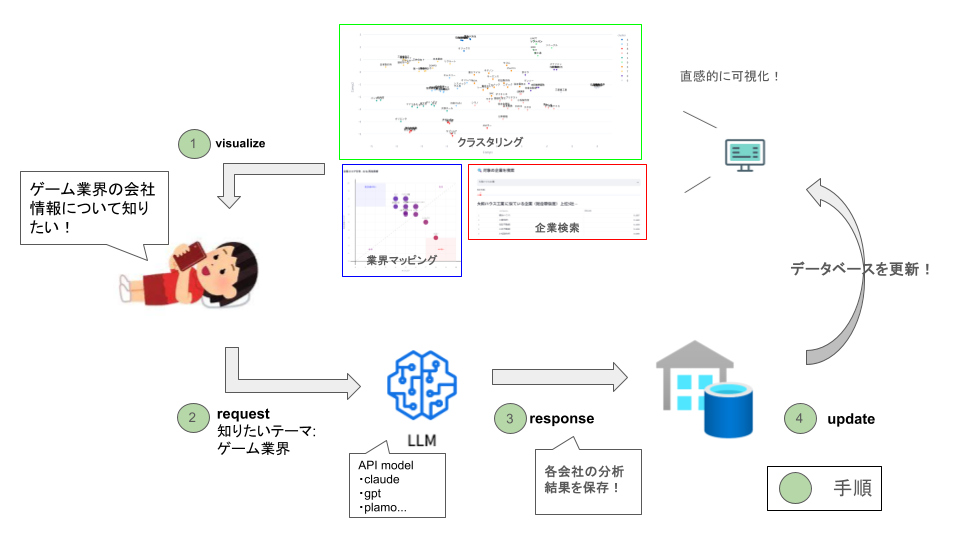
それでは、Webアプリ内に実装されている 業界マッピング機能、テーマ追加機能、クラスタリング機能の3つについて順に説明します。
業界マッピング
この機能は、複数のテーマに対する企業の関連度を数値化して分析できる機能です。たとえば、ある企業が「AI」と「医療」の両方に関わっているかを調べたい場合、単に関連の有無だけでは、「どちらの分野により注力しているか」や「両分野を含め最も関連度が高い企業」が分かりません。そこで今回の実装では、LLMが各テーマとの関連度を0~10の10段階スコアで評価し、「AIは関連度8、医療は関連度3」といった形で数値として比較できるようにしました。このアプローチにより、ユーザが関心の高いテーマに強く関連する企業群を効率的に抽出できます。
可視化に利用できるテーマ数
現在の可視化は最大3テーマに対応しています。テーマの可視化方法は以下の通りです。
- 1テーマ
- 関連度(10段階評価)を色の濃淡で表現
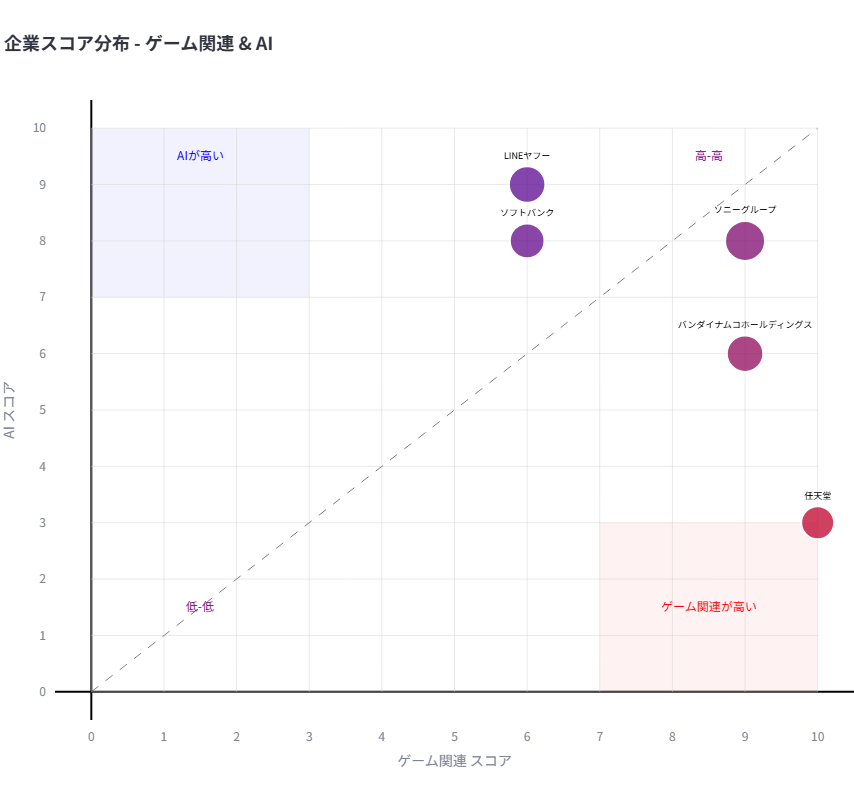
- 2テーマ
- X軸とY軸にテーマを割り当てた2Dプロット
- 色は赤と青を混色して両テーマの強弱を表示
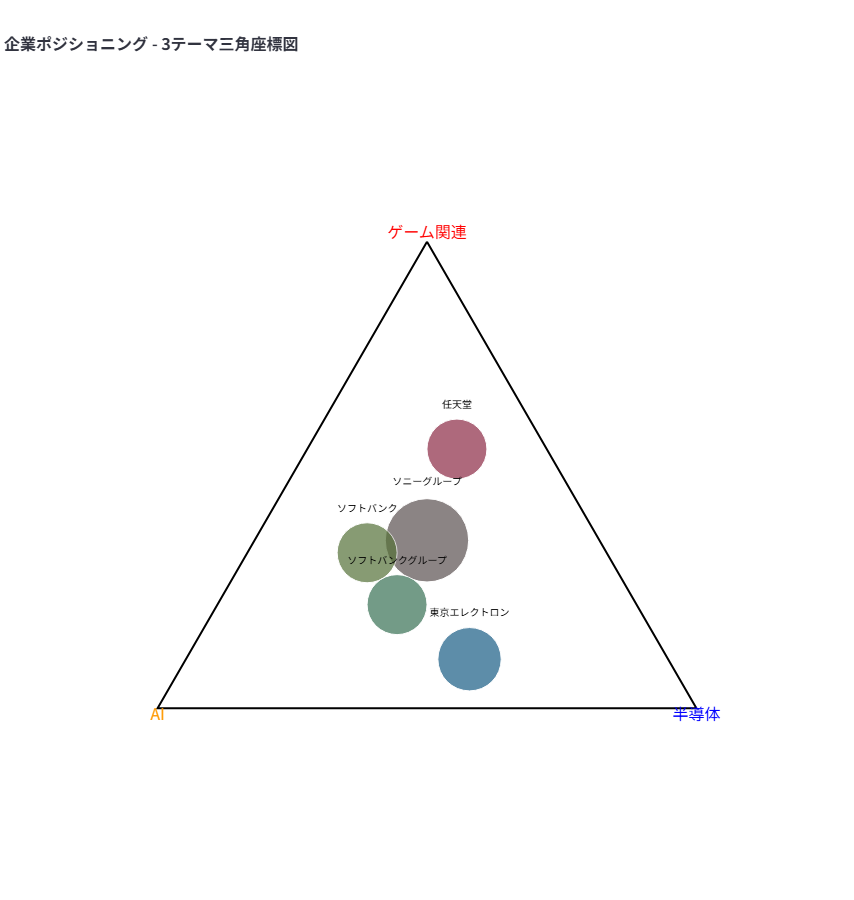
- 3テーマ
- 色空間(赤・青・黄)を利用した三角座標可視化
- 混色で関連度の組み合わせを表現
テーマ数に応じた可視化(上: 1テーマ, 中央: 2テーマ, 下: 3テーマ)
これらの可視化手法により、3テーマまでは問題なく可視化することできました。しかし、4テーマ以上になると4次元以上のデータを扱う必要があり、現実的に分かりやすい表示が困難になります。そのため、今回は見やすさを優先して3テーマまでに制限することにしました。
テーマ追加・分類機能
テーマ追加
業界マッピング機能では、既存テーマを効果的に可視化できますが、利用可能なテーマ以外にも自分の興味がある分野を調べたい場合があります。そこで本アプリには、ユーザが自由にテーマを追加できる機構を実装しました。ユーザがテーマを入力すると、そのテーマと各企業の関連度をバックエンド側でAPIモデルが推論し、結果をデータベースに自動的に追加・更新します。この機能により、元々存在しなかったテーマでも、登録直後から業界マップに反映されます。
テーマ分類
ユーザが自由にテーマを追加できるということは、将来的にテーマ数は膨大な数になることが予測されます。全テーマを単純に箇条書きで表示すると、目的のテーマを探しづらくなることからカテゴリ別分類機能を実装しました。具体的には、複数のカテゴリ(例:「技術」「情報技術」など)の文書ベクトルと、追加されたテーマのベクトルとの類似度を計算します。この類似度計算にはSentence-BERTを利用し、軽量ながら高精度なQwenモデル (Qwen/Qwen3-Embedding-0.6B) を採用しました。アプリ内の分類カテゴリは「製造・産業」「インフラ・エネルギー」「テクノロジー・エネルギー」「テクノロジー・通信」「商業・サービス」「金融・不動産」の6種類で分類するようにしました。なお、Sentence-BERTを利用しているため、カテゴリ数のスケール拡大にも対応可能であり、将来的により多くのカテゴリを追加しても問題がありません。
クラスタリング
この機能では、データベースに保存されているテーマと各企業の関連度情報をもとに、企業のクラスタリングを行います。関連度データはあらかじめJSON形式で保存しており、構造化された形で可視化や分析に利用できます。各企業にはテーマごとに0~10の関連度スコアが含まれており、次のような構造で格納されています。
出力データ形式 (.json)
[
{
"company": "company_name_1",
"code": "company_code_1",
"scores": {
"証券": score_1
}
},
{
"company": "company_name_2",
"code": "company_code_2",
"scores": {
"証券": score_2
}
}
…
{
"company": "company_name_n",
"code": "company_code_n",
"scores": {
"証券": score_n
}
}
]
このスコア構造により、各企業は下記のような数値ベクトルとして扱えます。
各企業のスコアベクトル
company_1 = [テーマ1のスコア, テーマ2のスコア, テーマ3のスコア,...,] company_2 = [テーマ1のスコア, テーマ2のスコア, テーマ3のスコア,...,] … company_n = [テーマ1のスコア, テーマ2のスコア, テーマ3のスコア,...,]
テーマごとのスコアが業界を特徴付けるのに有効かどうかを検証するため、企業の数値ベクトルを使ってクラスタリングを行いました。
使用するパラメータ
- 使用テーマ数: 61
- LLMモデル: gpt-5-chat-latest
- 次元圧縮: PCA(主成分分析)で2次元に変換
- クラスタリング手法: k-meansを利用し可視化
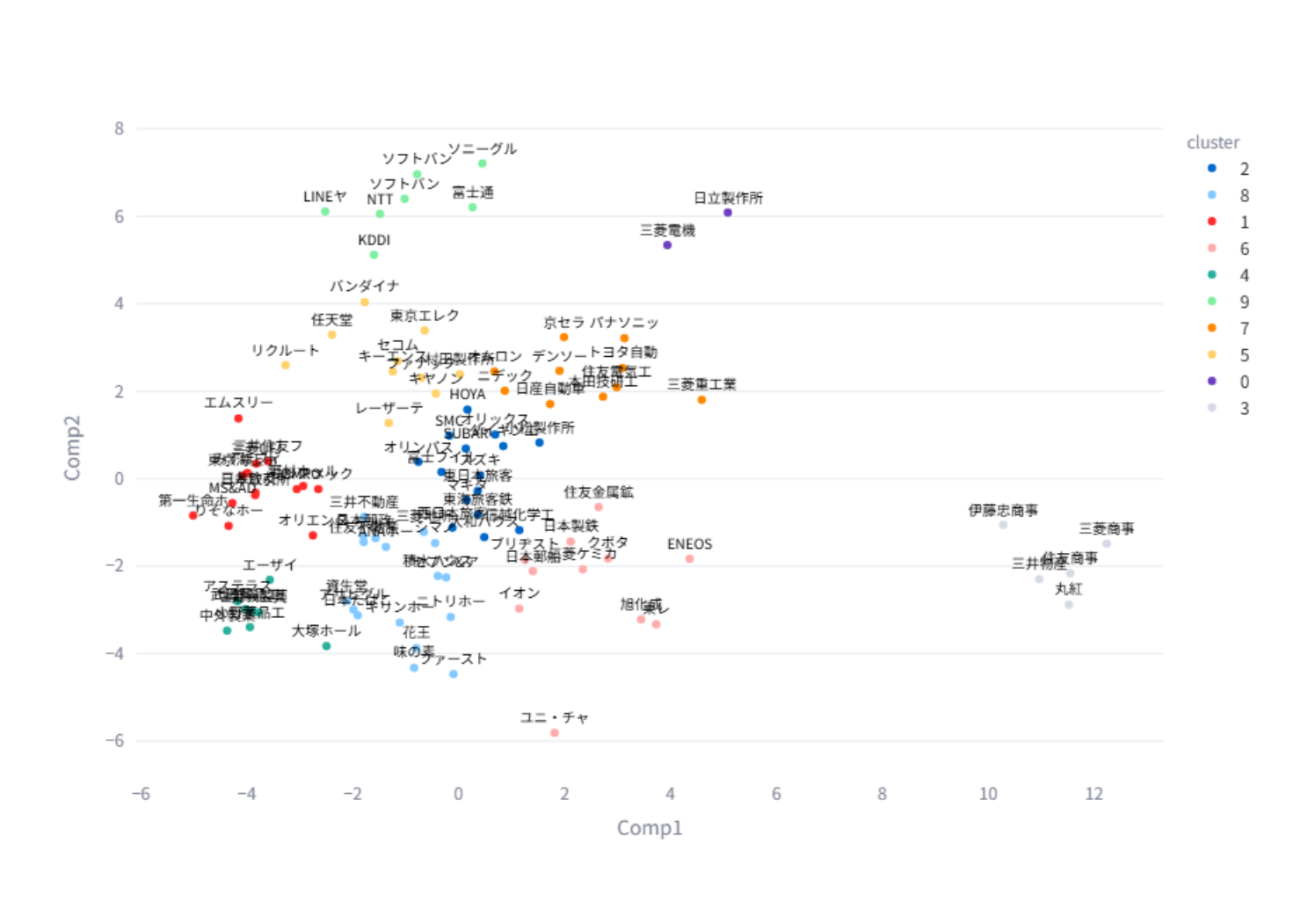
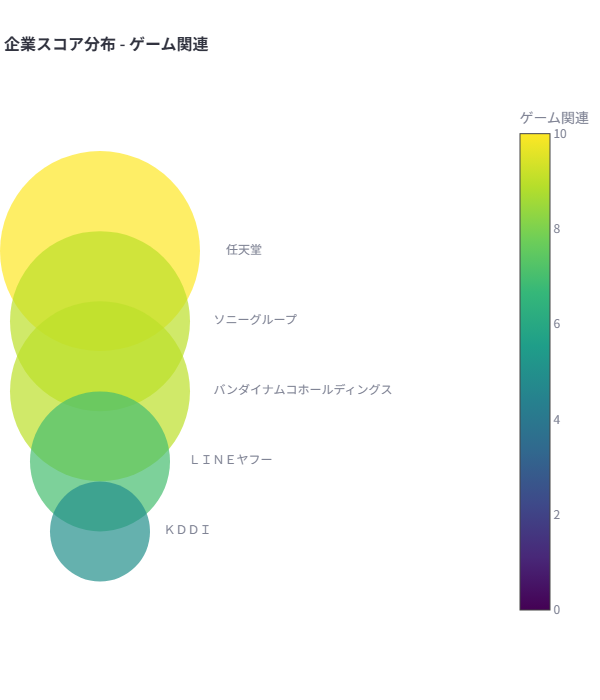
会社が100社あるためプロット上ではラベルが見づらい部分もありますが、以下のような傾向を確認することができます。
- 右上
- 日立製作所、三菱重工業などの重工業系企業
- 左上
- LINE、KDDI、ソフトバンクなどの通信企業
- 任天堂、バンダイナムコなどのエンターテイメント企業
- 左下
- 三井住友銀行やりそなホールディングなどの金融企業
- 武田薬品やアステラス製薬などの薬品系
- 右下
- 伊藤忠商事や三菱商事などの商社
商社が離れた位置にいる理由はいくつか考えられますが、一般的な会社は特定の分野に対して関連度が高いのに対し、商社は多くのテーマで高いスコアを持つため、スコア分布の性質が異なった結果と考えられます。APIモデルに関しては他にもclaude-3-7-latest, plamo-2.0-primeで実験を行いましたが、いずれも似たような結果が得られました。
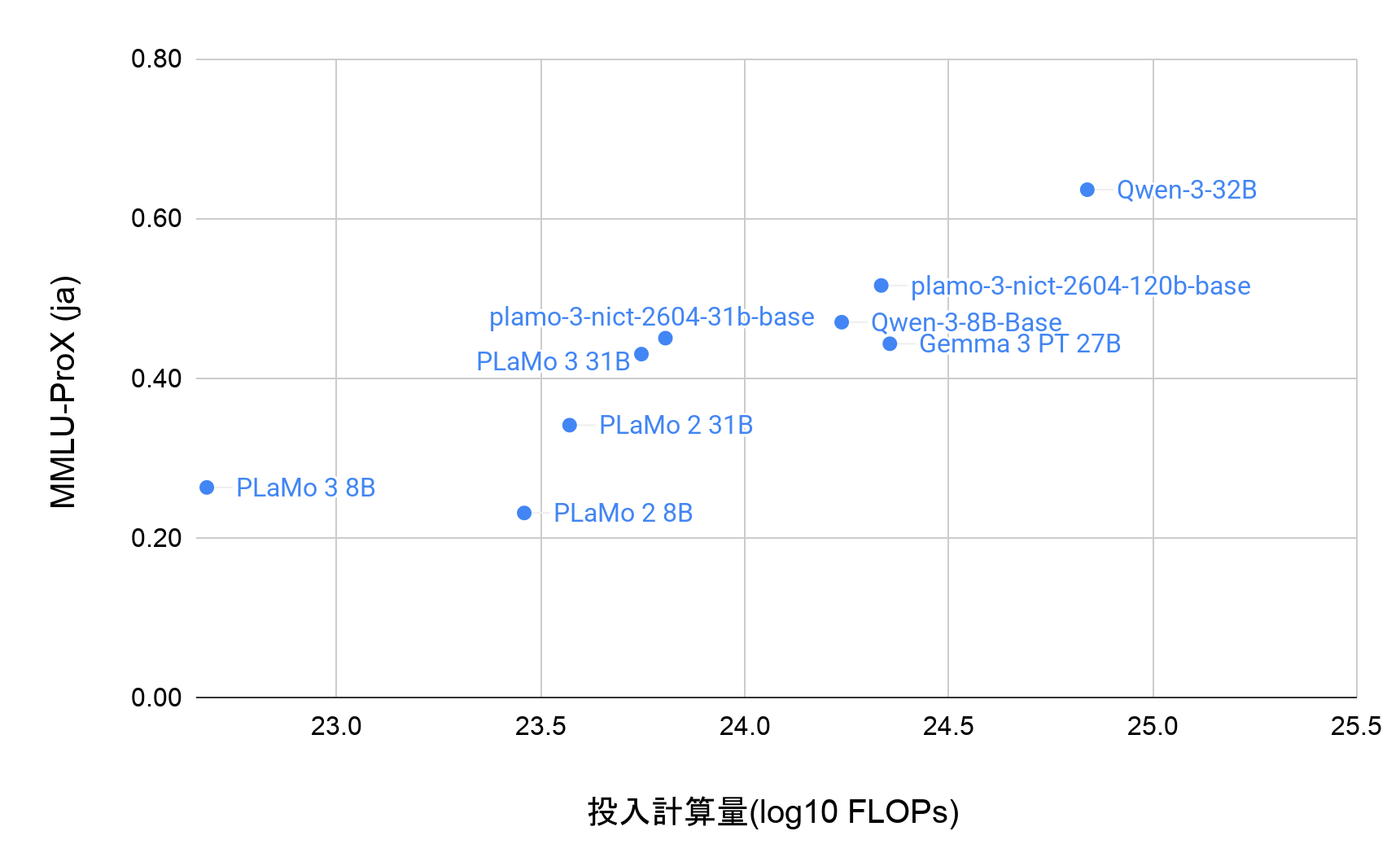
利用したLLMの性能に関する実験(補足)
目的
業界マッピングWebアプリケーションで利用されているLLMがTOPIX100の企業に対する金融知識を有しているかを確認することを目的としています。評価ではTop-N評価により企業業種分類タスクを定量評価しています。
実験設定
TOPIX100の会社に対しては次のように分類を行って実験しています。使用するLLMモデルが各会社に対して、東証33業種のそれぞれに関連度スコアを10段階で出力させ、スコアが高い順に並べて業種を予測を行います。評価指標はTopN評価で、上位N件の予測の中に正解業種が含まれている割合を計算します。
出力形式はJSONを指定していましたが、plamo-2.1-8b-cptモデルにおいてのみ通常のスクリプトでは形式が崩れてエラーが発生するケースが存在しました。そのため、vLLMのjson_guid機能を利用し、JSON形式を強制した状態で実行しています。
データ
- 企業:TOPIX100に含まれる企業
- ラベル:東証33業種区分(金融庁のEDINETから取得)
評価対象LLMモデル
- クローズド(API)モデル
- gpt-5-chat-latestw_
- claude-3.7-latest
- PLaMo-2.0-Prime
- オープン(ローカル)モデル
- gpt-oss-120b
- plamo-2.1-8b-cpt-pfml
- plamo-2.1-8b-cpt-general
ここで、東証33業種とは証券コード協議会が策定した業種別分類制度のことです。東証に上場している企業を、総務省が定める日本標準産業分類に準拠した基準に基づき、33の業種に分類しています。また、投資利便性を高めるために、これらの業種は「TOPIX-17」などの分類体系を用いて17分類にまとめられることもあります。33業種の例としては、「食料品」「化学」「銀行業」などが挙げられます。
各モデルのTop-1, Top-5評価
| モデル | Top-1 | Top-5 |
| gpt-5-chat-latest | 0.869 | 0.970 |
| claude-3.7-latest | 0.869 | 0.990 |
| PLaMo-2.0-Prime | 0.616 | 0.970 |
| gpt-oss-120b | 0.760 | 0.969 |
| plamo-2.1-8b-cpt-pfml | 0.798 | 0.808 |
| plamo-2.1-8b-cpt-general | 0.677 | 0.700 |
各モデルのTop-N評価のグラフ
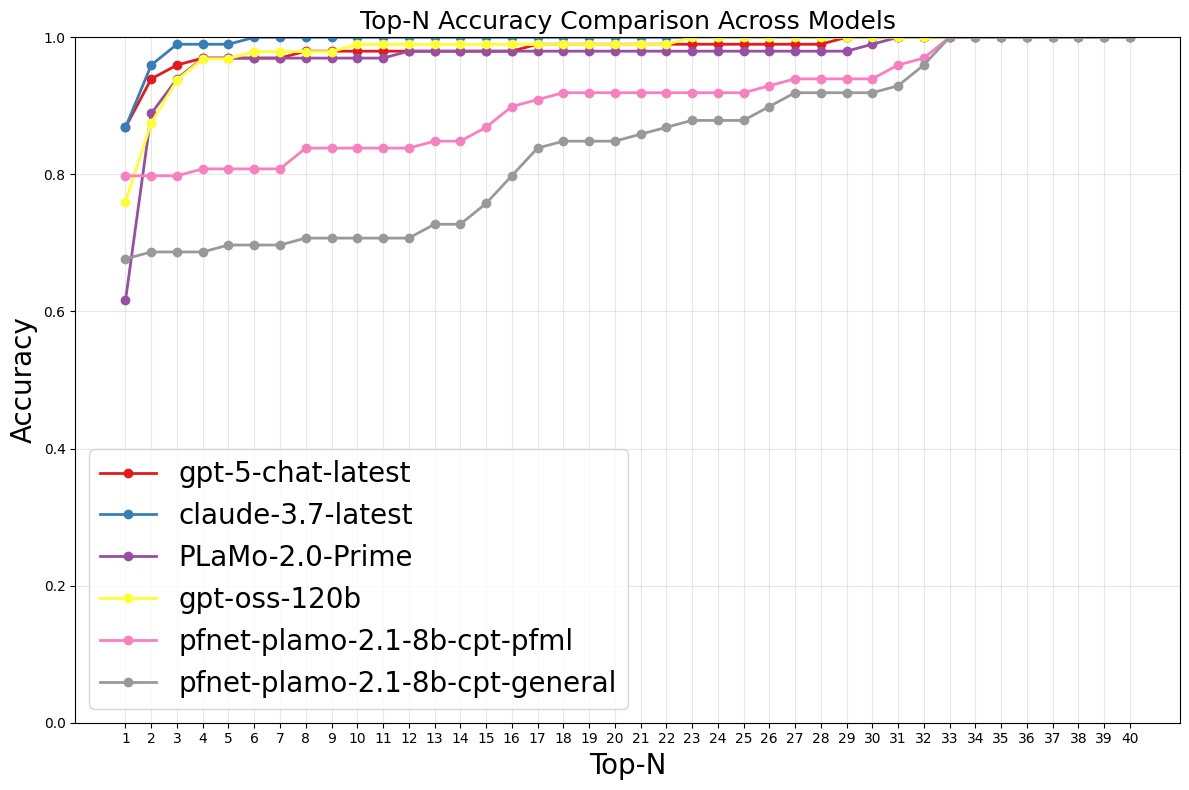
実験結果・考察
実験の結果、APIモデル(GPT系・Claude系)は全体的に高い精度を示しました。一方で、PLaMo-2.0-PrimeはTop1精度がやや低く、Top5で大きく改善する傾向が見られました。これは、多くのモデルが特定業種のみ、スコアを極端に高く出すのに対してPLaMo-2.0-Primeはスコア分布にグラデーションがあり、複数業種に均等な関連度を付ける傾向があるためと考えられます。
ローカルLLMでは、plamo-2.1-8b-cptのみを評価対象としました。このモデルでは、以下の2つのプロンプト形式があります。
- plamo-2.1-8b-cpt-general:通常プロンプト形式
- plamo-2.1-8b-cpt-pfml:PFML2形式(Preferred Markup Language 2)
PFML2は、入力と出力を構造化して提供する独自フォーマットであり、OpenAI社の<|im_start|>のような特殊トークンを含む形式に類似しています。評価の結果、タスク明示の有無で性能差が大きく、小規模LLMではタスク理解が精度に直結することが示唆されます。特にPFML2形式ではTop1精度が一部のクローズドモデルを上回ることもありましたが、Top5評価では大きく差が付く結果となりました。plamo-2.1-8b-cptモデルの出力を確認すると関連度がほとんど0か10の2値となっており、1社に1業種という単純なラベリングになる傾向がありました。これは、「東証33業種区分予測」というタスクを明示したことで、モデルが「最も関連がある業種1つのみをスコア10にする」という戦略を取ったため、Top1で頭打ちになったと考えられます。
結論・展望
今回のインターンでは、投資家が業界全体を直感的に把握できる業界マッピングWebアプリケーションを開発しました。LLMを活用することで、従来の人間の主観に依存した関連度評価から離れ、客観的なスコアリングを実現できた点、人手のアノテーションコスト削減が可能となった点は、本アプリの強みになっています。
現状、バックエンドで動いているモデルはAPIモデルに限定しているため、その出力はLLMの学習知識に依存しています。今後の改善に向けて、以下のような方向性が考えられます。
- Web検索など外部情報を組み合わせ、より正確な関連度評価
- TOPIX100に限らない、その他の上場企業や非上場企業に対応
- APIモデルの推論時間の増加をローカルLLMの活用によって改善
感想
webアプリケーションをゼロから開発するのは初めてでしたが、ユーザの視点に立って必要な機能を設計し、使いやすいUIを構築することができたのは、大変有意義な学びとなりました。インターン期間中には、メンターの方にモデル実装や評価に関する技術的アドバイス、UIにおける可視化方法など多岐にわたる議論を交わすことができました。その結果、7週間という限られた時間の中で、構想から実装までを完成させることができました。
改めて、交流してくださったインターン生の皆様、そして貴重なアドバイスをくださったメンターの尾崎さん・平野さん・imosさん、並びに金融チームの方々、本当にありがとうございました!