Blog
In this post, we discuss a common pitfall faced in applying Deep Reinforcement Learning in the real world such as to robotics- its need for an inordinate number of trials before the desired behaviour is learnt. We discuss the idea of State Representation Learning as a potential way to alleviate this difficulty, even under difficult learning settings, and present some sources of self-supervision that may be used to learn these representations.
Deep Reinforcement Learning (DRL) has seen increasing interest by the research community, reaching formidable levels of competency in games (ATARI [1], Go [2, 3], Starcraft [4], Dota [5]), robotics [6, 7] and a number of other sequential decision-making tasks. Despite these reports of success, most applications of DRL require a staggering amount of trials to achieve competitive results.
Recent results from OpenAI [8] that scale DRL to attempt to solve a Rubik’s cube with a single robotic arm show it being able to compensate for an impressive number of perturbations that were not encountered during training, such as tying the robot’s fingers together, wearing gloves or using objects to poke the cube while the robot attempts to solve it. The computational cost required to achieve these results, as mentioned in the report [8], are as follows:
“For the Rubik’s cube task, we use 8 × 8 = 64 NVIDIA V100 GPUs and 8 × 115 = 920 worker machines with 32 CPU cores each.”
…
“The cumulative amount of experience over that period used for training on the Rubik’s cube is roughly 13 thousand years.”
While the number might seem glaring, a recurring theme in modern Machine Learning is improved capability due to increasingly available computation. To quote Richard Sutton, one of the founding fathers of computational reinforcement learning:
“One thing that should be learned from the bitter lesson is the great power of general purpose methods, of methods that continue to scale with increased computation even as the available computation becomes very great. The two methods that seem to scale arbitrarily in this way are search and learning.” [14]
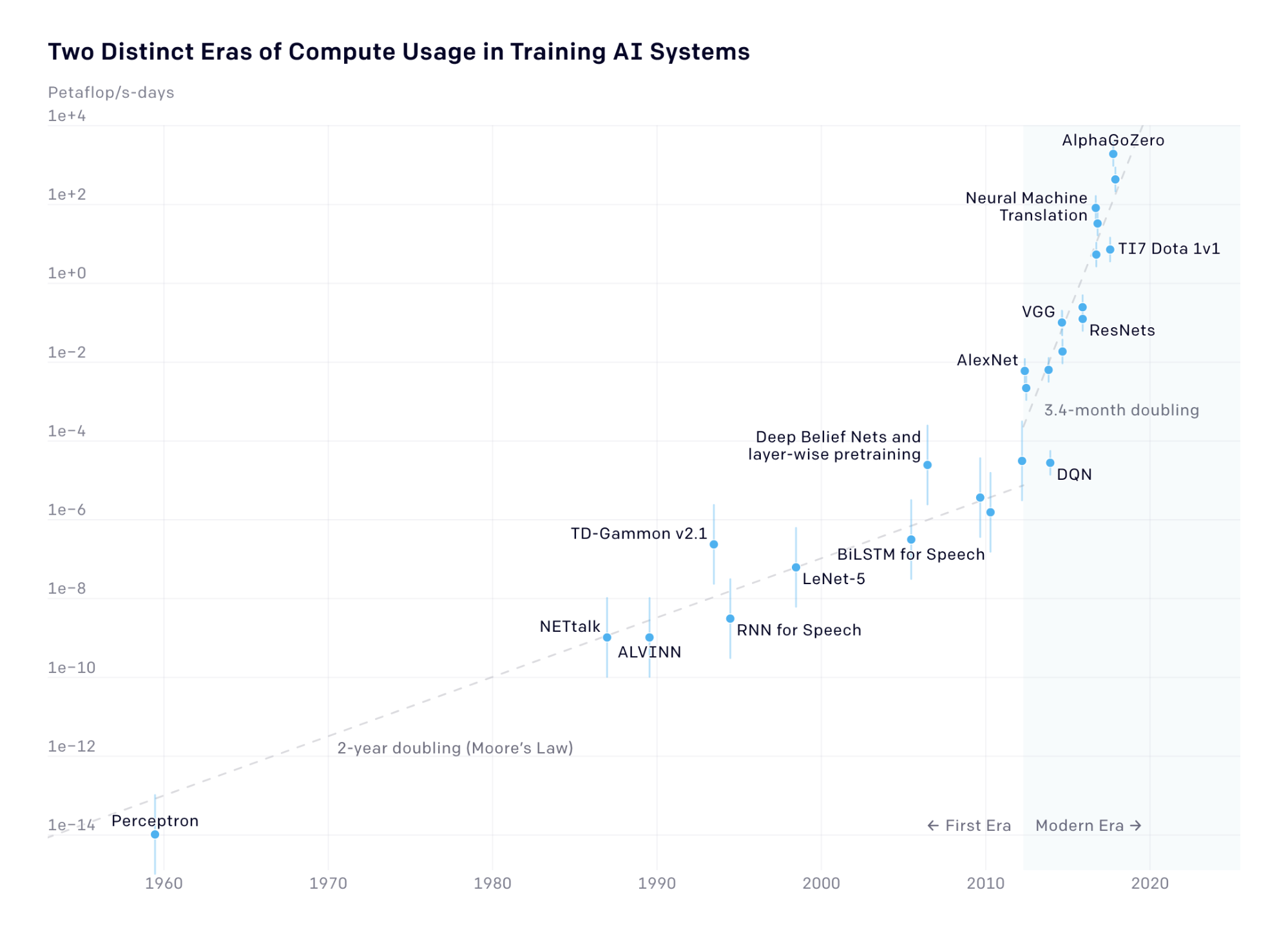
Source: https://openai.com/blog/ai-and-compute/
The access to resources of this scale to do research in the intersection of DRL and Robotics often constrains research to large academic labs and companies such as Preferred Networks (PFN). That is why at PFN, we invest heavily in our entire computing stack from hardware to software. As of mid-2019, PFN owns and operates three sets of supercomputers, totalling 2,560 GPUs with the aggregated performance of 200 petaflops.
While this may suggest that DRL could be applied to any task as long as we have the appropriate computational resources, it ignores the consideration of the cost. While the cost of computation per unit dollar continues to fall at a steady rate [15], it does not account for tasks that require interaction with the physical world such as robotics where data acquisition is slow and incurs additional operating costs including accidental damage and failure from wear and tear. This prevents more complex controllers from being learnt on robots through increasing computational scale. To circumvent this bottleneck, most DRL systems for robotics are first learnt in simulation, where they can perform orders of magnitudes more trials, and then deployed on real robots where they may optionally be fine-tuned to compensate for inaccuracies in simulation.
Robotics requires perception using multiple sensors depending on the robot and task at hand. Deep Learning (DL) has proven to be successful at learning to extract useful features from complex, high-dimensional, multi-modal inputs. Applications of DL in a supervised learning setting have class labels or targets to provide rich, constant feedback. DRL, on the other hand, typically relies on using reward functions in some form which may be infrequent, unreliable and indirect. This significantly increases the number of trials required to learn the desired behaviour that makes it prohibitively expensive to apply to real robots.
While prior work has shown that it is possible to learn controllers directly from raw high-dimensional visual data [1] using Deep Learning, RL can directly use low-dimensional state representations instead of raw observations to solve tasks more efficiently. While the use of Deep Learning allows for these state representations to be learnt during training, the dependence on the reward signal for learning feedback stifles efficiency which is critical in robotics where performing an action is a costly operation.
In robotics, feature engineering for control tasks requires a considerable amount of manual effort. Learning these features or learning to extract them with as little supervision as possible is, therefore, an instrumental problem to work on. The goal of State Representation Learning, an instance of representation learning for interactive tasks, is to find a mapping from observations or a history of interactions to states that allow the agent to make a better decision.
This mapping of raw observations to states can be learnt either beforehand or be integrated into the DRL algorithm in the form of auxiliary tasks [13], where the deep network, in addition to its typical output, is made to learn some aspect of the environment or task thereby exploiting the substantial knowledge about their environment. The addition of auxiliary tasks aid in encoding prior knowledge about the environment or task and help regularize the learned representation. Since the learning of the state representation is detached from the RL algorithm, it allows the network to extract useful information from the state even in the absence of usable reward function.
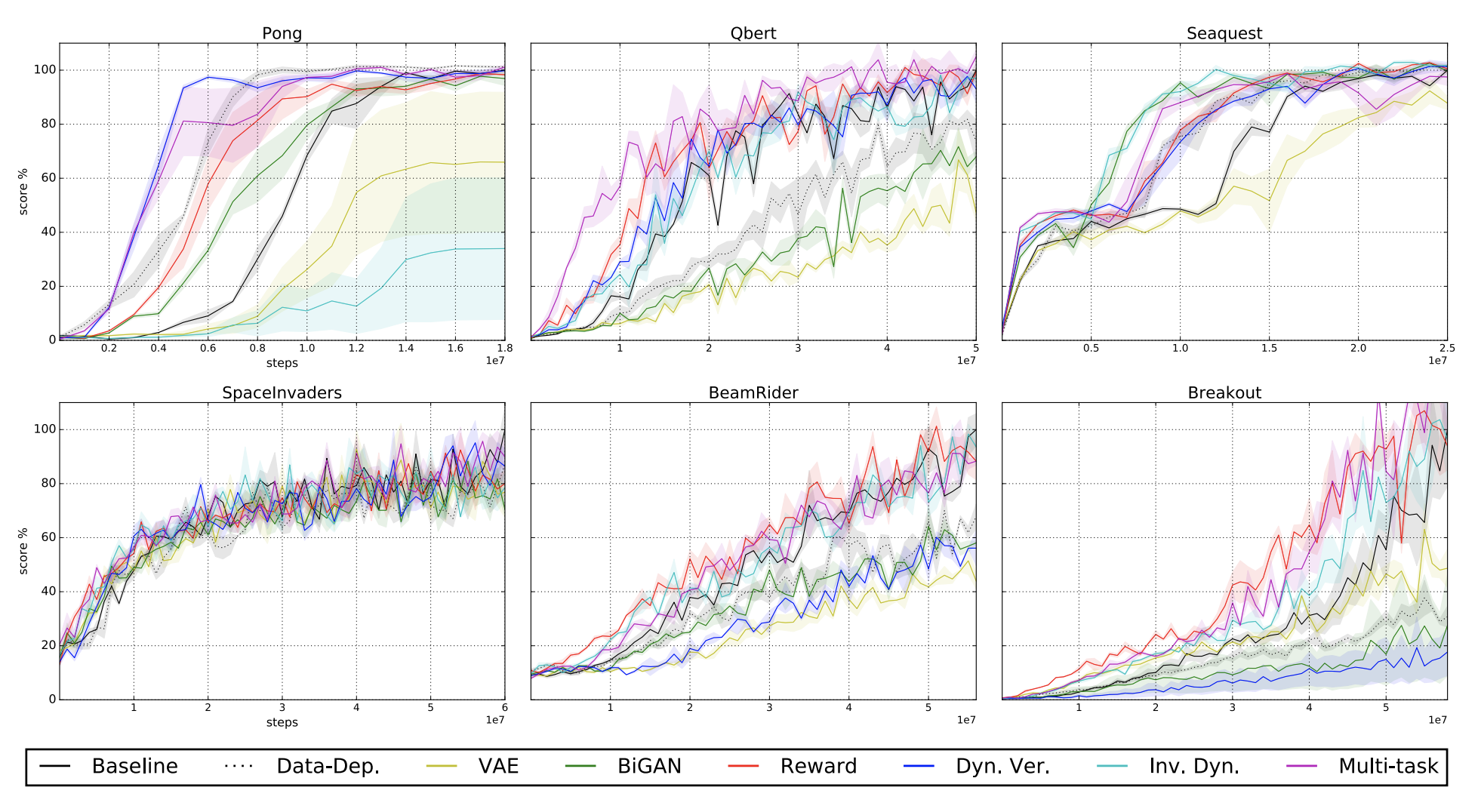
Percentage improvement over baseline on ATARI games from self-supervised pretraining
Source: [16]
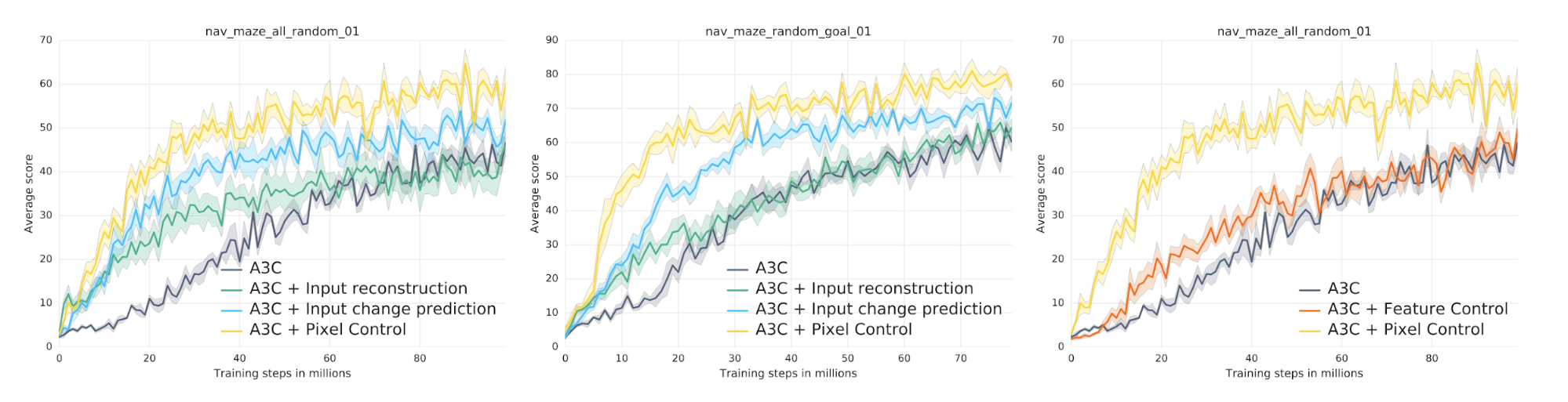
Scores of Auxiliary Tasks for random maze navigation tasks
Source: [13]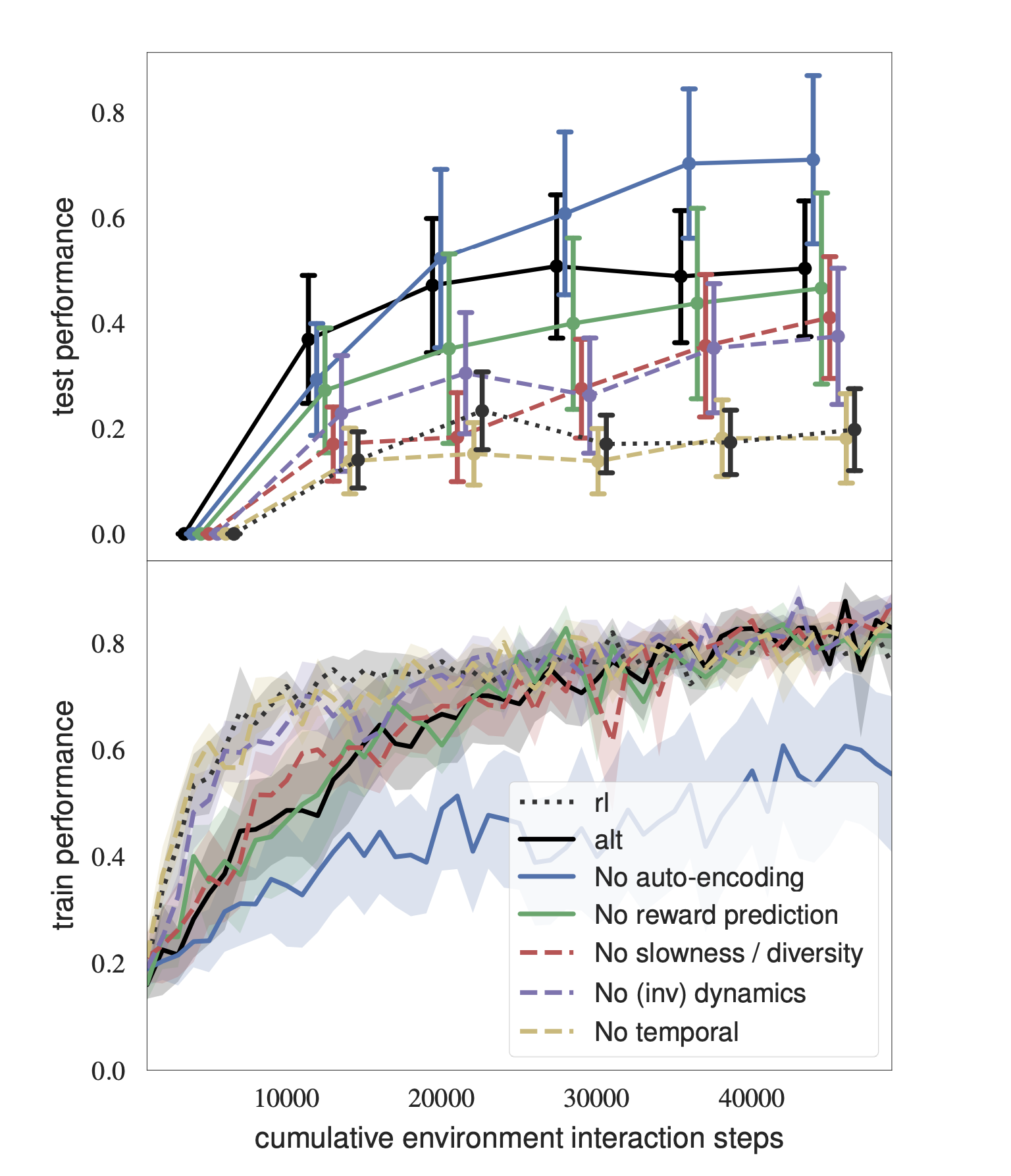
Ablation study of state representation learning losses in an autonomous racing car simulator
Source: [17]
There exist a number of potential auxiliary tasks that may be applied that make use of the interaction between the agent and the environment (Input Reconstruction, Forward/Inverse models, Reward Prediction), incorporate prior knowledge in the form of Observational Cues or ones that aim to regularize by using common-sense robotic priors. We list a few of them below:
Auxiliary Tasks |
Source |
|
| Input Reconstruction | ||
| AutoEncoder (AE), VAE, BiGAN | https://arxiv.org/abs/1612.07307 | |
| β-VAE / Deterministic (RAE) | https://arxiv.org/abs/1910.01741 | |
| Forward Model | ||
| Action-Conditioned Forward Model (s, a, s’) | https://arxiv.org/abs/1705.05363 | |
| (Latent Space) Forward Model (s, s’) | https://arxiv.org/abs/1809.04506 | |
| Dynamics Verification (Identify out-of-order observation in a sequence ot0…otk) |
https://arxiv.org/abs/1705.05363 | |
| Inverse Model | Action-Predicting Inverse Model SxS → A | https://arxiv.org/abs/1705.05363 https://arxiv.org/abs/1612.07307 |
| Reward Prediction | Intermediate reward prediction | https://arxiv.org/abs/1611.05397 https://arxiv.org/abs/1612.07307 https://arxiv.org/abs/1809.04506 |
| Observation Cues | ||
| Depth Prediction | https://arxiv.org/abs/1611.03673 | |
| Game Features (Presence of enemy, health, weapon, etc) | https://arxiv.org/abs/1609.05521 | |
| Loop Closure (Use SLAM to identify loop in navigation) | https://arxiv.org/abs/1611.03673 | |
| Pixel Changes | https://arxiv.org/abs/1611.05397 | |
| Network Features | https://arxiv.org/abs/1611.05397 | |
| Optical Flow | https://arxiv.org/abs/1812.07760 | |
| Image Segmentation | https://arxiv.org/abs/1812.07760 | |
| Episode Terminal Prediction | https://arxiv.org/abs/1907.10827 | |
| Goal Conditional | Steps to goal/Reachability | http://citeseerx.ist.psu.edu/….. |
| Robotic Priors | Simplicity Prior, Temporal Coherence, Proportionality, Causality, Repeatability | http://www.robotics.tu-berlin.de/….. |
Further reading:
[17] de Bruin, Tim, et al. “Integrating state representation learning into deep reinforcement learning.” IEEE Robotics and Automation Letters 3.3 (2018): 1394-1401.
[18] Lesort, Timothée, et al. “State representation learning for control: An overview.” Neural Networks 108 (2018): 379-392.
References:
[1] Mnih, Volodymyr, et al. “Human-level control through deep reinforcement learning.” Nature 518.7540 (2015): 529.
[2] Silver, David, et al. “Mastering the game of Go with deep neural networks and tree search.” nature 529.7587 (2016): 484.
[3] Silver, David, et al. “Mastering the game of go without human knowledge.” Nature 550.7676 (2017): 354.
[4] Vinyals, O., Babuschkin, I., Czarnecki, W.M. et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature (2019) doi:10.1038/s41586-019-1724-z
[5] https://openai.com/five/
[6] Kalashnikov, Dmitry, et al. “Qt-opt: Scalable deep reinforcement learning for vision-based robotic manipulation.” arXiv preprint arXiv:1806.10293 (2018).
[7] Andrychowicz, Marcin, et al. “Learning dexterous in-hand manipulation.” arXiv preprint arXiv:1808.00177 (2018).
[8] Akkaya, Ilge, et al. “Solving Rubik’s Cube with a Robot Hand.” arXiv preprint arXiv:1910.07113 (2019).
[9] Strubell, Emma, Ananya Ganesh, and Andrew McCallum. “Energy and Policy Considerations for Deep Learning in NLP.” arXiv preprint arXiv:1906.02243 (2019).
[10] Todorov, Emanuel, Tom Erez, and Yuval Tassa. “Mujoco: A physics engine for model-based control.” 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2012.
[11] Coumans, Erwin, and Yunfei Bai. “Pybullet, a python module for physics simulation in robotics, games and machine learning.”
[12] https://openai.com/blog/faulty-reward-functions/
[13] Jaderberg, Max, et al. “Reinforcement learning with unsupervised auxiliary tasks.” arXiv preprint arXiv:1611.05397 (2016).
[14] http://www.incompleteideas.net/IncIdeas/BitterLesson.html
[15] http://people.idsia.ch/~juergen/raw.html
[16] Shelhamer, Evan, et al. “Loss is its own reward: Self-supervision for reinforcement learning.” arXiv preprint arXiv:1612.07307 (2016).
