Blog
![]()
Optuna, a hyperparameter optimization (HPO) framework designed for machine learning written in Python, is seeing its first major version release. It is a new framework that aims to make HPO more accessible as well as scalable for experienced and new practitioners alike. This GitHub project has grown to accommodate a community of developers by providing state-of-the-art algorithms, and we are proud to see the number of users increasing. We now feel that the API is stable and ready for many real-world applications.
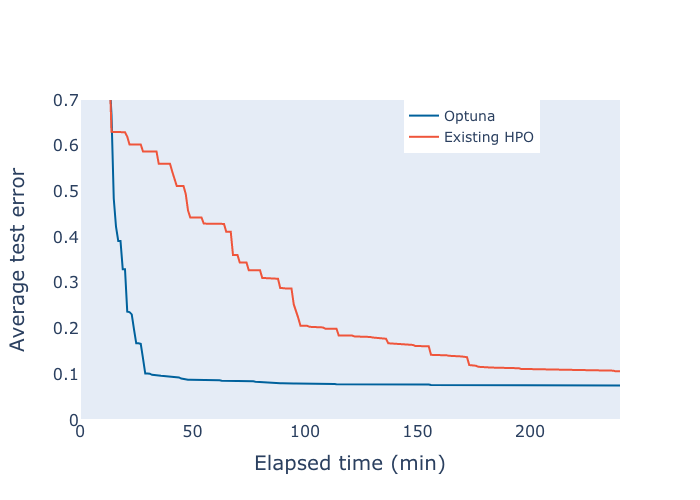
A comparison of the test error over time measured in minutes between hyperparameter configurations obtained by Optuna and an existing framework, both training a simplified AlexNet on the SVHN dataset [1]. The error decreases significantly faster using Optuna.
Concept
Hyperparameters in machine learning are parameters that are fixed before training, unlike the parameters of a model. They could define the architecture of a model or constitute parts of the training algorithm, including the data augmentation pipeline and can greatly impact the performance of a model. While crucial in this aspect and in terms of evaluation of such models and algorithms, they require careful tuning, which can take days of work. Optuna simplifies this task by automating the configuration of such hyperparameters. It makes it easy with the following features.
- Eager dynamic search spaces: Pythonic search spaces using Python conditionals and loops without the need for domain-specific languages (DSLs)
- Efficient sampling and pruning algorithms: State-of-the-art algorithms to efficiently explore large search spaces and prune unpromising trials to save computational resources
- Integrations: Modules for popular machine learning libraries such as PyTorch, TensorFlow, Keras, FastAI, scikit-learn, LightGBM, and XGBoost
- Visualizations: Customizable visualizations of optimizations with a single function call
- Distributed optimization: Optimizations that are parallelizable among threads or processes without having its code modified
- Lightweight: Simple installation with few requirements
Try it out on Google Colab
To get a sense of how Optuna can be applied to your code, a Jupyter notebook is available on Google Colab to demonstrate some of the above features. Try it out here.
Looking back
The development of Optuna started back in 2018 to tune hyperparameters in deep neural networks. We wrote it in Python, to make it easy to use with the most popular machine learning frameworks. Although there existed other HPO frameworks in Python, they required learning separate languages, DSLs, outside the Python programming language to define complex hyperparameter search spaces. The idea behind Optuna was to be Pythonic, not introducing any DSLs, without sacrificing performance.
Existing frameworks were also often not updated to the more recent algorithms. We started by implementing random search and the Tree-structured Parzen Estimator (TPE) [2] which are both known to be performant hyperparameter sampling algorithms. Later that year, we used this TPE implementation in the first Google AI Open Images challenge on Kaggle and took second place, losing to the first place competitor by a mere 0.04% difference.
The increasing popularity of machine learning emphasized the need for a well designed HPO framework, so in December of 2018, we made Optuna public on GitHub.
In the following year, we participated in multiple conferences, starting with SciPy2019 in July which is a conference for the scientific Python community. You can check out the video for our presentation here. In August, we presented Optuna at the Knowledge Discovery and Data Mining conference (KDD) and introduced the ability for users to define their own algorithms and pruning criteria. We were proud to receive 5th place out of over 160 competitors in the AutoML competition. More recently in October, we presented Optuna at the Open Data Science Conference (ODSC) West 2019, a large data science conference.
What’s ahead
Optuna is not finished. We will continue implementing new algorithms and improvements as they are developed, like Hyperband [3]. As we hear of frameworks or tasks that benefit from HPO, we will add additional integrations to make using Optuna with those frameworks easier. At the same time, we are reserving ourselves for additional goals for the next milestone based on feedback from the community. Do not hesitate to reach out as we are happy to see the community grow, if you have any questions, would like to report issues, request features, or send pull requests.
Visit GitHub for more details. For an in depth explanation of the features of Optuna, please head over to the documentation or our paper [1]. We also have Gitter chat rooms for interactive discussions which you can join here.
Contributors
The release of Optuna 1.0 is a milestone that would not have been possible without careful design decisions and fruitful discussions among contributors.
A03ki, AnesBenmerzoug, Crissman, HideakiImamura, Muragaruhae, Rishav1, RossyWhite, Y-oHr-N, c-bata, cafeal, chris-chris, crcrpar, d1vanloon, djKooks, dwiel, g-votte, harupy, henry0312, higumachan, hvy, iwiwi, momijiame, mottodora, nmasahiro, oda, okapies, okdshin, r-soga, scouvreur, sfujiwara, sile, smly, suecharo, tadan18, tanapiyo, tohmae, toshihikoyanase, upura and yutayamazaki.
Our thanks to those who have contributed code, issues, or feedback on Optuna!
References
[1] Akiba, Takuya, et al. “Optuna: A Next-generation Hyperparameter Optimization Framework” arXiv preprint arXiv:1907.10902 (2019).
[2] James Bergstra, Rémi Bardenet, Yoshua Bengio, and Balázs Kégl. Algorithms for hyper-parameter optimization. In NIPS, pages 2546–2554, 2011.
[3] Li, Lisha, et al. “Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization” arXiv preprint arXiv:1603.06560 (2016).
Tag