Blog
Preferred Networks, as a research-oriented AI startup, participates every year in NeurIPS, the world’s biggest machine learning conference. This post highlights our accomplishments and activities at NeurIPS 2019. We are very excited to be a part of it & looking forward to seeing top ML researchers from all over the world there!
NeurIPS Conference Papers
This year, four papers from Preferred Networks have been accepted for poster presentation. Three of them are based on ex-intern’s work and we are very proud of their dedication and high-quality research.
Please stop by our posters & talk to PFN members to share your thoughts.
“Robustness to Adversarial Perturbations in Learning from Incomplete Data” (paper, poster)
Amir Najafi (intern) · Shin-ichi Maeda · Masanori Koyama · Takeru Miyato
Tue Dec 10th 05:30 — 07:30 PM @ East Exhibition Hall B + C #225
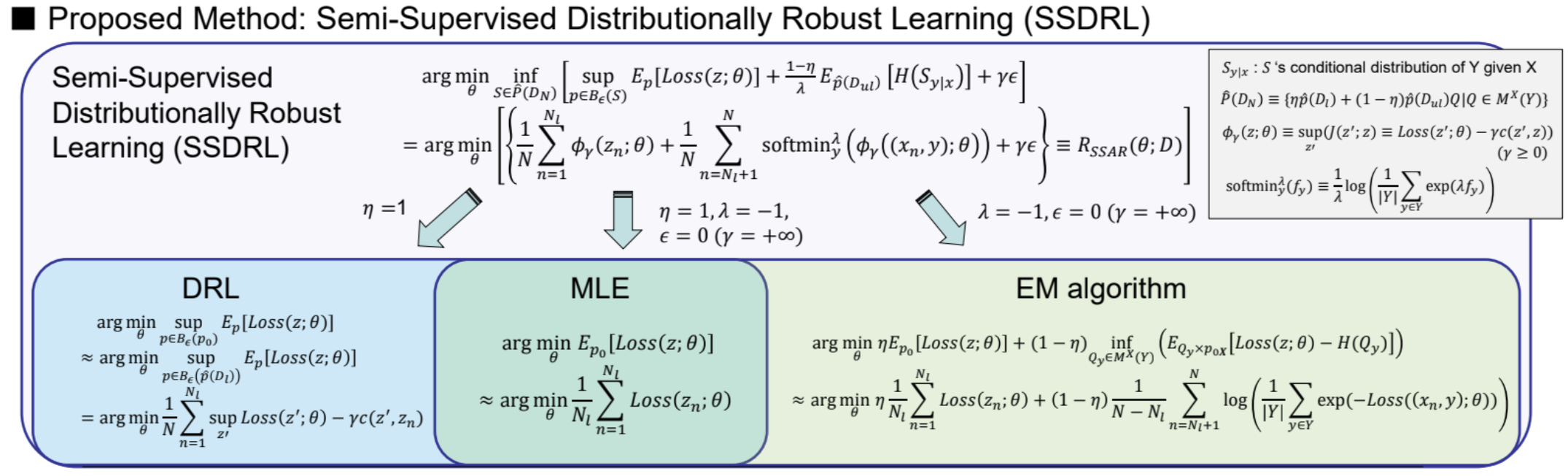
In this study, we propose a general algorithm for semi-supervised distributionally robust learning (SSDRL) that takes advantage of both semi-supervised learning and DRL. Our approach encompasses DRL, Maximum Likelihood Estimation (MLE) and the EM algorithm as its special cases. Moreover, we perform a theoretical analysis to answer the question when unlabeled data is useful for the generalization.
“A Graph Theoretic Framework of Recomputation Algorithms for Memory-Efficient Backpropagation” (paper, poster)
Mitsuru Kusumoto · Takuya Inoue (intern) · Gentaro Watanabe · Takuya Akiba · Masanori Koyama
Thu Dec 12th 10:45 AM — 12:45 PM @ East Exhibition Hall B + C #153
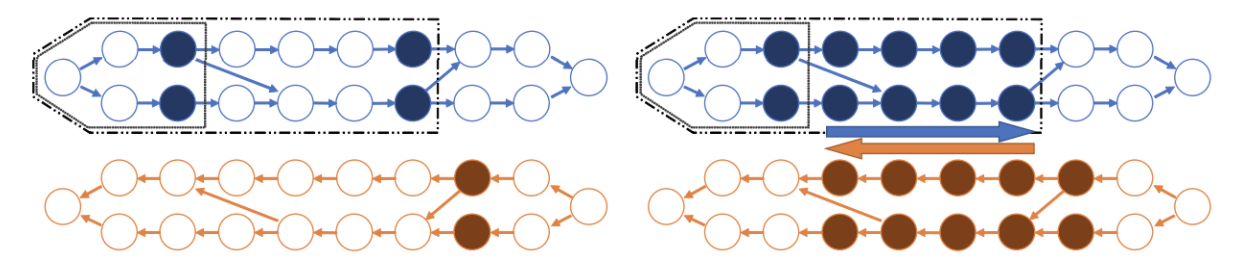
Recomputation algorithms collectively refer to a family of methods that aims to reduce the memory consumption of the backpropagation by selectively discarding the intermediate results of the forward propagation and recomputing the discarded results as needed. In this paper, we will propose a novel and efficient recomputation method that can be applied to a wider range of neural nets than previous methods. Our method can reduce the peak memory consumption on various benchmark networks by 36%~81%, which outperforms the reduction achieved by other methods.
“Exploring Unexplored Tensor Network Decompositions for Convolutional Neural Networks” (paper, poster)
Kohei Hayashi · Taiki Yamaguchi (intern) · Yohei Sugawara · Shin-ichi Maeda
Thu Dec 12th 10:45 AM — 12:45 PM @ East Exhibition Hall B + C #139
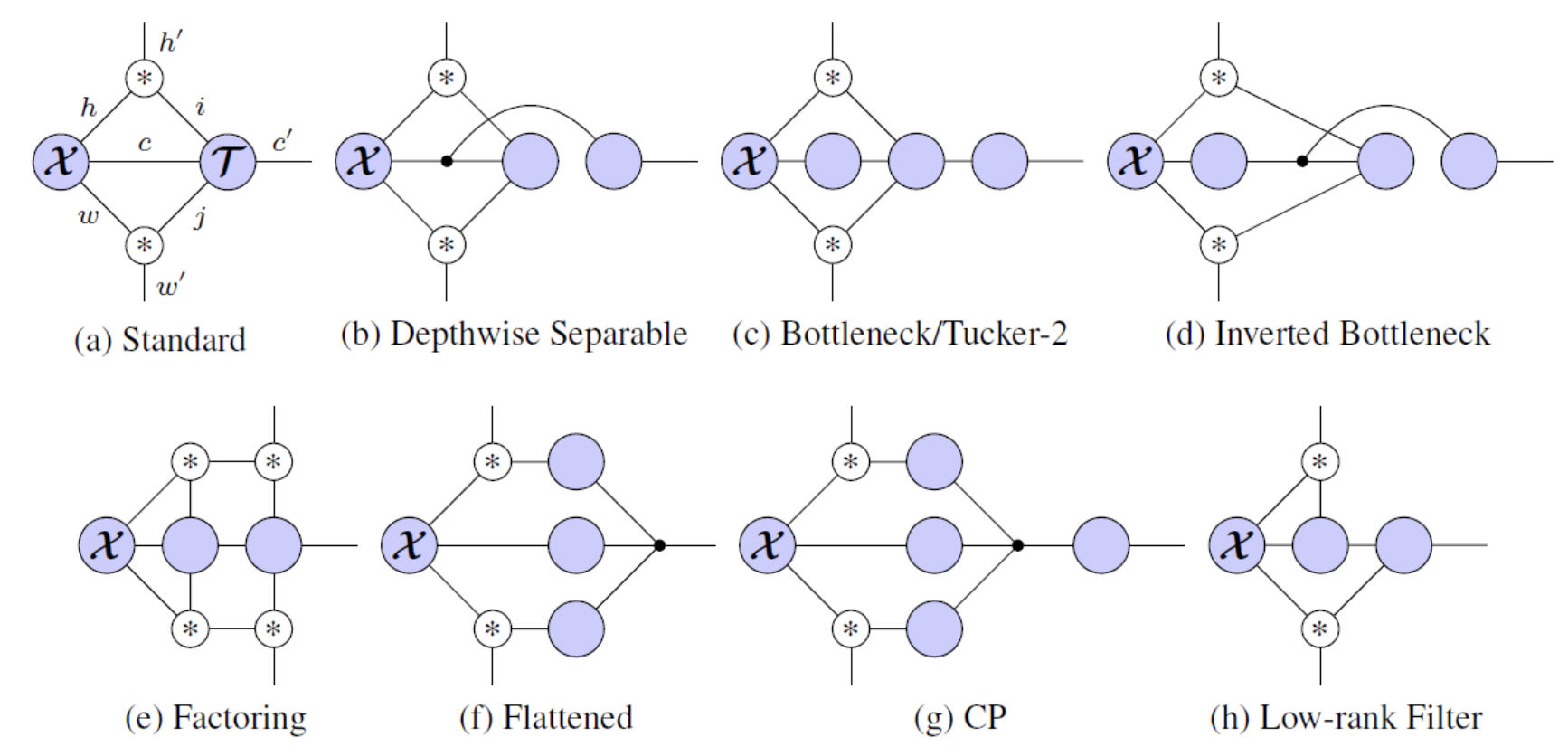
For high prediction performance, CNNs demand huge resources such as model size and FLOPs. To reduce them, a lot of efficient building blocks (e.g. bottleneck layers in ResNet) have been handcrafted. However, there has been no systematic way to understand or generate them. In this study, we propose a graphical model for CNNs based on tensor network and show its wide representability and usefulness for architecture search.
“Semi-flat minima and saddle points by embedding neural networks to overparameterization
” (paper, poster)
Kenji Fukumizu · Shoichiro Yamaguchi · Yoh-ichi Mototake · Mirai Tanaka
Thu Dec 12th 05:00 — 07:00 PM @ East Exhibition Hall B + C #216
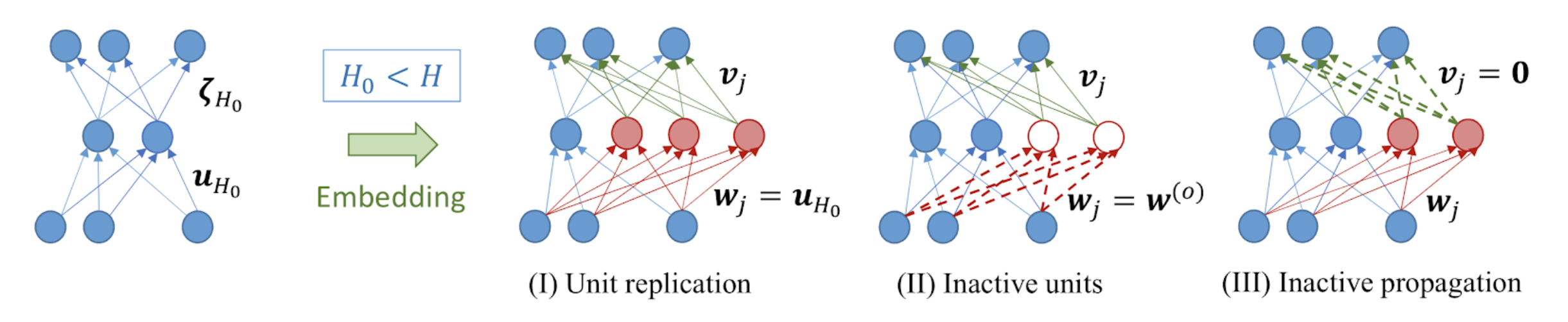
Recently, over-parametrized neural network is drawing much attention in the study of the generalization ability of neural networks. In this study, we study the landscape of the training loss of the over-parametrized neural networks using three ways to embed a given network into a wider network. We show that the partially flat landscapes around the embedding point differs in nature when using activations with different functional properties (smooth vs ReLU). We also discuss their difference in terms of generalization ability as well.
NeurIPS Workshop Papers
“Safe Reinforcement Learning with Adversarial Threat Functions”
Wesley Chung (intern), Shin-ichi Maeda, and Yasuhiro Fujita
Sat Dec 13th at NeurIPS2019 Workshop on Safety and Robustness in Decision Making
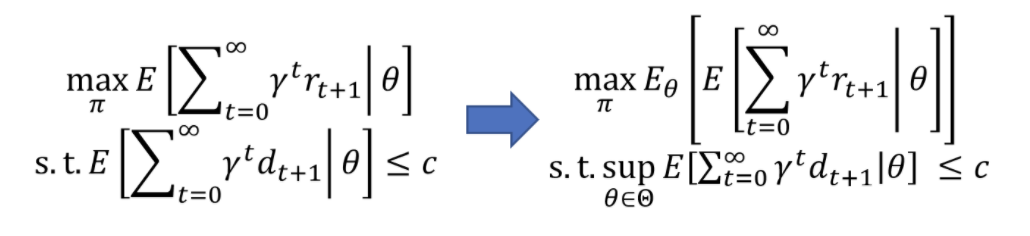
In this study, we consider to solve a variation of the constrained Markov Decision Process (CMDP) problem for safe reinforcement learning. In some cases, the environment parameter θ cannot be determined uniquely but may have some uncertainty. For example, we do not know the exact other drivers’ policies in the traffic. To guarantee safety in such a scenario, we consider the formulation on the right side. The resulting algorithm naturally considers the adversarial environment, e.g., adversarial drivers, which leads to the learning of an adversarial threat function.
“Learning from Observation-Only Demonstration for Task-Oriented Language Grounding via Self-Examination” (paper)
Tsu-Jui Fu, Yuta Tsuboi; Sosuke Kobayashi, Yuta Kikuchi
Sat Dec 13th at NeurIPS2019 Workshop on Visually Grounded Interaction and Language (ViGIL)
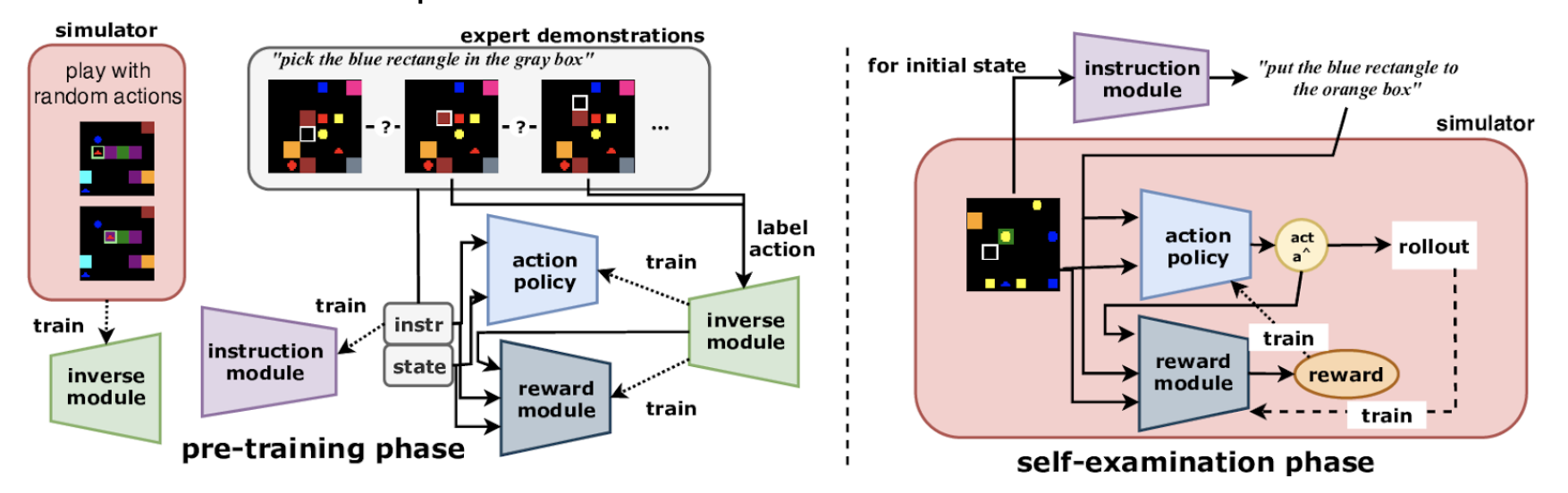
Humans are able to learn quickly in new environments by observing others. From another point of view, humans can communicate their objectives to others by not only demonstrating but also describing them.
Thus, we focus on combining observation-only imitation learning with natural language instruction. We propose a method that initially pre-trains modules to capture the inverse dynamics of the world and learns how to describe the demonstration in natural language. In the second phase, these modules are used to generate additional training instances that can be explored self-examination.
“ChainerRL: A Deep Reinforcement Learning Library” (paper)
Yasuhiro Fujita, Toshiki Kataoka, Prabhat Nagarajan, and Takahiro Ishikawa
Sun Dec 14th at NeurIPS2019 Deep Reinforcement Learning Workshop
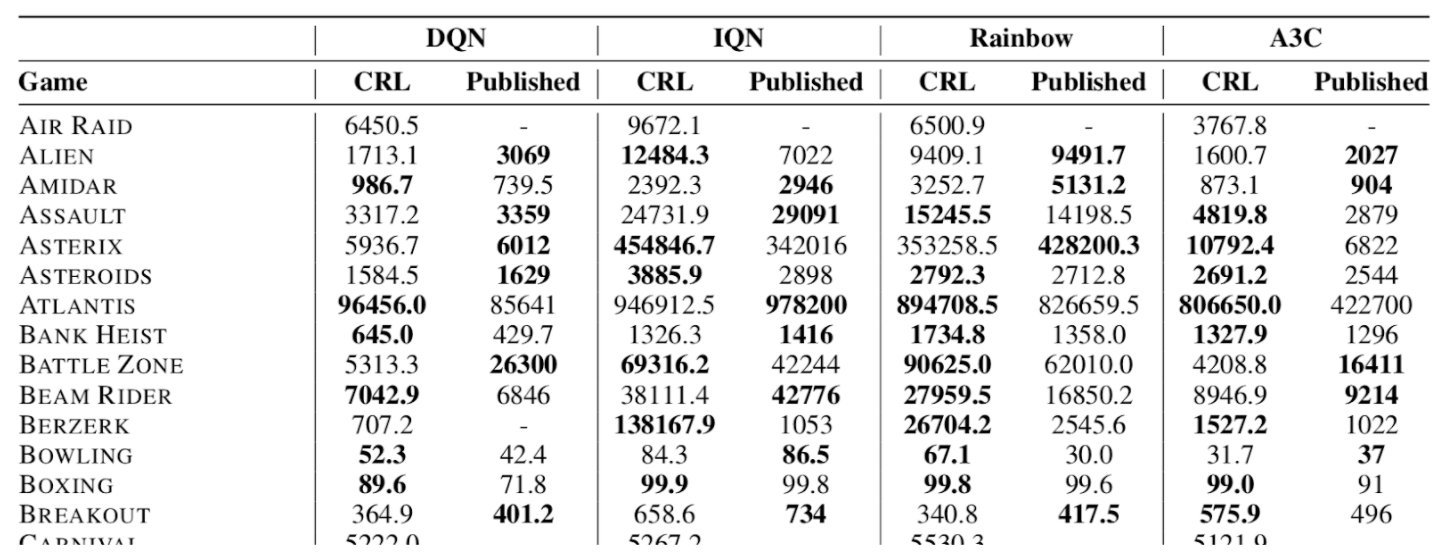
In this paper, we introduce ChainerRL, an open-source Deep Reinforcement Learning (DRL) library built using Python and the Chainer deep learning framework. ChainerRL implements a comprehensive set of DRL algorithms and techniques drawn from the state-of-the-art research in the field. To foster reproducible research, and for instructional purposes, ChainerRL provides scripts that closely replicate the original papers’ experimental settings and reproduce published benchmark results for several algorithms. Lastly, ChainerRL offers a visualization tool that enables the qualitative inspection of trained agents.
“Learning Latent State Spaces for Planning through Reward Prediction”
Aaron Havens (intern), Yi Ouyang, Prabhat Nagarajan, and Yasuhiro Fujita
Sun Dec 14th at NeurIPS2019 Deep Reinforcement Learning Workshop
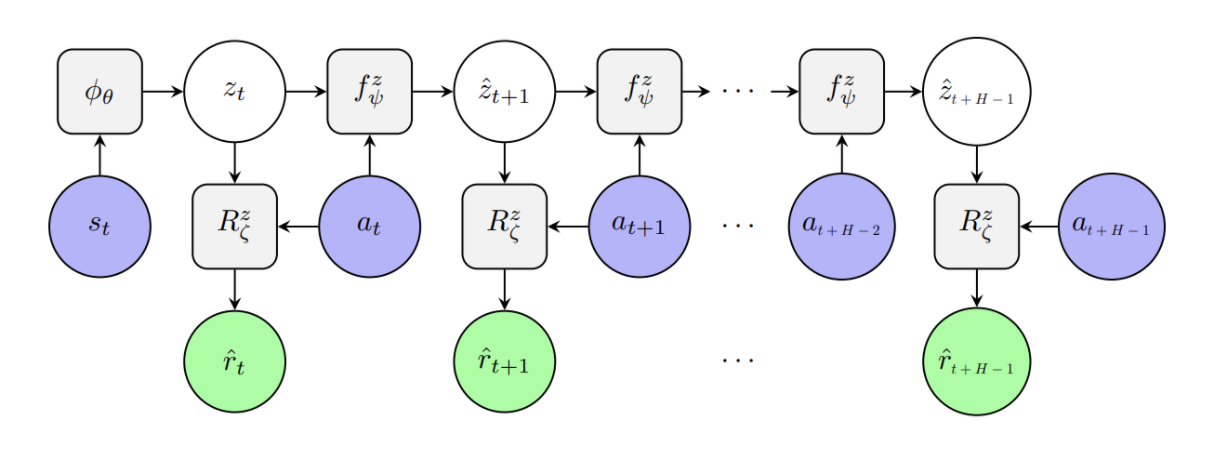
Model-based reinforcement learning methods typically learn models for high-dimensional state spaces by aiming to reconstruct and predict the original observations. However, drawing inspiration from model-free reinforcement learning, we propose learning a latent dynamics model directly from rewards. The latent representation is learned exclusively from multi-step reward prediction which we show to be the only necessary information for successful planning. With this framework, we are able to benefit from the concise model-free representation, while still enjoying the data-efficiency of model-based algorithms. We demonstrate our framework in multi-pendulum and multi-cheetah environments where several pendulums or cheetahs are shown to the agent but only one of which produces rewards. Planning in the learned latent state-space shows strong performance and high sample efficiency over model-free and model-based baselines.
“Swarm-inspired Reinforcement Learning via Collaborative Inter-agent Knowledge Distillation”
Zhang-Wei Hong (intern), Prabhat Nagarajan, and Guilherme Maeda
Sun Dec 14th at NeurIPS2019 Deep Reinforcement Learning Workshop
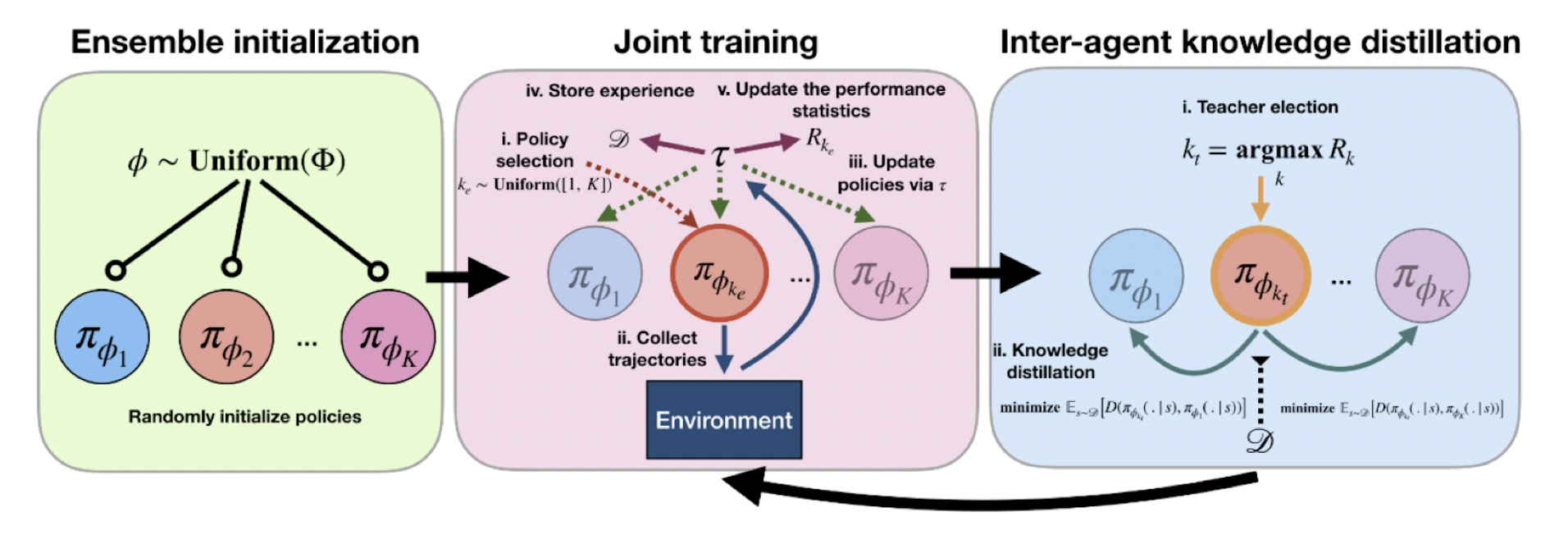
Reinforcement Learning (RL) has demonstrated promising results across several sequential decision-making tasks. However, RL struggles to learn efficiently, thus limiting its pervasive application to several challenging problems. A typical RL agent learns solely from its own trial-and-error experiences, requiring many experiences to learn a successful policy. To alleviate this problem, this paper proposes collaborative inter-agent knowledge distillation (CIKD). CIKD is a learning framework that uses an ensemble of RL agents to execute different policies in the environment while sharing knowledge amongst agents in the ensemble. Our experiments demonstrate that CIKD improves upon state-of-the-art RL methods in sample efficiency and performance on several challenging MuJoCo benchmark tasks. Additionally, we present an in-depth investigation on how CIKD leads to performance improvements. CIKD operates quite simply. An ensemble of agents take turns acting in the environment, and use the experiences of other members of the ensemble to train off-policy. However, periodically, we introduce a distillation phase where we take the best agent in the ensemble and distill its knowledge to the other members of the ensemble.
“Emergent Communication with World Models” (paper)
Alexander I. Cowen-Rivers (intern), Jason Naradowsky
Sun Dec 14th at NeurIPS2019 Workshop on Emergent Communication
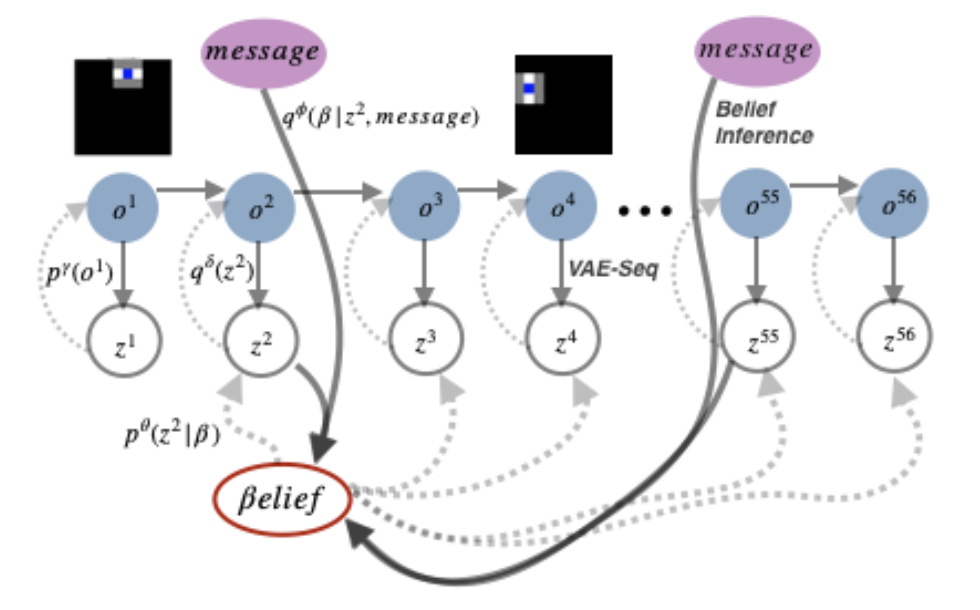
We introduce the Language World Model, a language-conditional generative model that interprets language by predicting latent codes of future observations. This provides a visual grounding of the message, similar to an enhanced observation of the world, which may include objects outside of the listening agent’s field-of-view. We incorporate this into a persistent memory state, and allow the listening agents policy to condition on it, akin to the relationship between memory and controller in a World Model. We show this improves effective communication and task success in 2D grid world speaker-listener navigation tasks. In addition, we develop two losses framed specifically for our model-based formulation, to promote positive signaling and positive listening. Finally, because messages are interpreted in a generative model, we can visualize the model beliefs to gain intuition about how the communication channel is utilized.
MineRL Competition
Preferred Networks proudly served as a co-organizer of the MineRL competition at NeurIPS 2019 in collaboration with CMU, Microsoft Research, and AIcrowd. The competition uses Minecraft as its environment to advance the cutting-edge techniques in sample-efficient reinforcement learning.
PFN provided baseline implementations based on ChanerRL, a deep RL learning on top of Chainer, so that the participants can immediately play with the competition environment and focus on their solutions.
The winners will be announced later this week followed by by their presentations in Competition Track Day 2 workshop on Saturday. Stay tuned!
2020 Summer-Autumn Internship in Tokyo
Following the successful programs in previous years, Preferred Networks is planning to host internship program for international students starting August next year in Tokyo. This time, we carefully selected the following five topics for the internship. Please find the detailed information on our pre-registration form.
- Next-generation chip architecture for deep learning
- SLAM, SfM, and depth estimation
- NN-based fast physics simulation
- Machine learning models with inter-domain transferability
- High-performance data communication network for distributed deep learning
Note that there are some modifications to the internship period and requirements for application due to the 2020 Olympic Games in Tokyo. The application will start this month. We are looking forward to seeing your applications!
Sponsor Booth
This year, PFN is a gold sponsor of the conference and has a booth in the Exhibition area in Ballroom B & C of the Convention Centre. We display a video that summarizes company introduction, our business, and research activities. Please stop by our booth during breaks. PFN members always welcome you and are happy to talk with you on hiring opportunity at PFN in Tokyo, internship program, or generally the future of deep learning applications. Please go straight from the entrance and you will see our booth behind the coffee break area.
We hope that all of the attendees enjoy NeurIPS here in Vancouver.
