Blog
Why Apache Ozone?
To address increasing data needs and new use cases in Preferred Networks, PFN, we have been seeking a new storage system that scales out pseudo-infinitely. The amount of data usage has increased far more than expected due to the strategic focus on simulation and AI [1], making the storage system more important than ever.

Although the basic requirements described in our article (ja) Hadoop in Preferred Networks Hadoop – Preferred Networks Research haven’t changed much and are still crucial for us since then [2], Hadoop (HDFS) clusters we are currently running have several operational issues. For example, the largest one of our Hadoop clusters, which has ~10PB capacity, is still running on Ubuntu 16.04. As we have no knowledge or experience of an in-place upgrade of a large cluster including the upgrade of operating systems, and the lifecycle of Ubuntu 16.04 has been extended [3], we have given up on doing a system upgrade and have been seeking new software to replace HDFS. We have built our plan to choose replacement storage software, set up a new cluster, and to gradually migrate our data.
Upgrading the underlying operating system is only one of the issues we stand to face. There are several others stemming from our use cases which do not fit typical HDFS usage. However, due to its stability and operational ease, we compromised and worked around them. Here is the list:
- Small Files Problem [4]: An increase in the number of files leads to the increase of metadata. The load of NameNode depends on metadata, a set of files and the list of block locations of the files. The number of files increases more rapidly if the average file size is smaller than standard block size. Particularly, metadata loading from the disk after a NameNode restart takes significant time.
To work around this problem, we store a set of small files into a single large ZIP archive on HDFS, and read files directly from ZIP (without deflating the archive) using libraries like PFIO. - High Density Disk Servers: While the cost performance per disk capacity becomes better as more hard disk drives are contained in a single node. On the other hand, longer time for Full Block Report (FBR) in DataNode affects data durability and availability. For example, Cloudera, one of the most popular Hadoop distribution providers, does not support DataNodes which have a capacity more than 100TB and hard disk drives with capacity more than 8TB. In comparison, some of our DataNodes at PFN are equipped with 36 HDDs with 14TB capacity.
- Better Affinity with Python Runtime: The standard way to access HDFS from Python is to read and write data over the Java Hadoop client in JNI using libhdfs2. The complex stack of softwares imposes various constraints and makes it hard to use HDFS. The hardest example is PyTorch DataLoader, which forks many processes in parallel to load data faster. To run DataLoader correctly with a JVM aside, a lot of care in the code is required to prevent forking the launched JVM, by launching the JVM only after the fork.
- Classic Authentication: Although a Kerberos-based authentication system is reliable and mature, its authentication method of taking a token via kinit(1) does not suit well with execution in Kubernetes Pods because it needs additional tools for authentication. In PFN, we usually run kinit in initContainer before running the main containers, using a keytab file stored as a Kubernetes secret. Simpler authentication methods such as just requiring secrets in preliminary environment variables would make our manifests much simpler.
- NameNode Scalability: To scale out metadata management in HDFS, many systems such as HDFS Federation have been released. They mostly involve an increase in the number of NameNodes, e.g. more moving parts in the system, which increases complexity in the overall system management.
While these issues have been making administrators very weary, they also have been the source of complaint for system users. Hadoop developers surely have been aware of them and thus Apache Ozone has been derived from Hadoop as the resolution to those issues. How Apache Ozone solves those problems follows:
- Small Files Problem: In Ozone, those responsibilities for managing metadata and block locations that used to belong to NameNode are divided to Ozone Manager (OM) and Storage Container Manager (SCM), respectively. A new unit set of blocks called “container” is defined, and the SCM manages only containers, as well as their replication and locations. This split also makes the increase of metadata only proportional to the number of files, and only affects the memory size of file tables in OM. Directory tree access has become faster because the file tables are stored in a more efficient database, RocksDB.
- High Density Disk Servers: FBR has become much faster because of the design change. DataNodes only need to report containers to SCM. A container can store up to 2^64 blocks – by controlling the average number of blocks in containers, we can control the overall load of SCM.
- Better Affinity with Python Runtime: New API endpoint has been added. It is compatible with AWS S3. Its ecosystem is so huge that not only its SDKs are provided in various languages, but a lot of software has an abstraction over AWS S3 (and compatible object storage systems) to read and write data instead of a local filesystem.
- Classic Authentication: To keep compatibility with HDFS API, it has authentication systems depending on Kerberos. As a secret access key to access AWS S3 API is only enough to access the data, users don’t have to set up Kerberos clients by installing required packages.
- NameNode Scalability: As NameNode responsibilities are divided and transferred to the OM and SCM, and the underlying datastore is migrated to RocksDB, the performance of metadata scan and update has been improved a lot. We cannot say we don’t need a scale-out gimmick like HDFS federation any more, but a fairly large cluster can be managed by the current design. Cloudera tested Ozone with 10 billion objects inserted [5].
Right after I published the blog article last year [2], we started testing Apache Ozone as a next-generation object storage system and have had it in operation for several months.
While during the process of testing I discovered and reported CVE-2020-17517 [6], there have not been any severe or critical issues that deserve a blocker. We opened the service to internal users as an alpha service, and moved on to the step of continuously adding knowledge. The range API coverage is far from the full feature of AWS S3, but we think that we can contribute important features and fixes to the community, because the community has been very active.
Cluster Configuration & Setup
We have installed OM and SCM to one management server and DataNode to 4 storage servers in MN-2 [7]. Physical specifications of them are depicted in Table 1 and Table 2. Table 1 is for DataNode; 36 hard disk drives are all formatted as ext4 partitions (1 partition per 1 drive) and used as JBOD by Ozone.
Table 1: Server specification of DataNode
| Type | Amount | |
| CPU | Intel(R) Xeon(R) Silver 4114 | 1 |
| Memory | 32GB DDR4 | 12 ※1 |
| HDD | 14TB SATA 6GB/s 7200rpm | 36 |
| Network | Mellanox ConnectX-6 (100GbE) | 2 |
Table 2 is a specification of a management server that runs OM and SCM. To durably save metadata, it is equipped with four 15TB NVMe SSDs, which are bundled as a raidz partition. We chose ZFS as we have some experience in OpenZFS and it has a simple and consistent set of CLIs which is easy to understand. In that partition, OM and SCM store their metadata. This configuration survives up to single failure of the SSD.
Table 2: Server specification of Ozone Manager and Storage Container Manager
| Type | Amount | |
| CPU | Intel(R) Xeon(R) Silver 4114 | 1 |
| Memory | 32GB DDR4 | 12 ※1 |
| NVMe | 15TB PCIe Gen3 | 4 |
| Network | Mellanox ConnectX-6 (100GbE) | 2 |
※1 Memory will be extended to 512GB per node at a later date, by adding four 32GB sticks.
The operating system is Ubuntu 18.04, which was installed when we set up physical servers in the MN-2 cluster. We installed a Linux 5.4.0 HWE kernel to the metadata server because of prior experience of NVMe SSD administration in another server. We re-used Oracle JDK 8u162 which we installed when we built the MN-2 cluster as well.
We built a secure cluster from these servers with Apache Ozone 1.0.0.
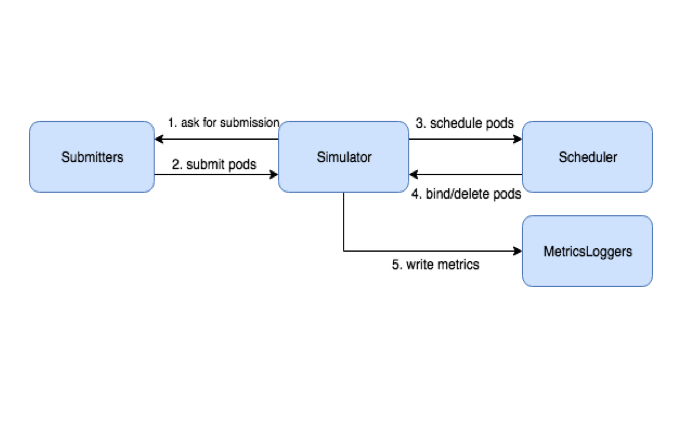
Figure 1 depicts simple configuration of the Ozone cluster. In the storage servers, DataNode and S3Gateway are running. In the metadata server, OM and SCM are running. S3Gateway is a gateway process that converts S3 API access to Ozone Native API. S3Gateway processes are exposed as an HTTP API server. The access from clients is distributed across the gateway processes by DNS round robin. We did not use reverse-proxy processes such as HAProxy to remove any single point of potential bottleneck from HDDs to the memory space of client processes. In Ozone 1.0.0, OM already had a high availability (HA) feature generally available, but it would introduce some operational complexity and SPoF (single point of failures) could not be removed because SCM didn’t have HA. Thus we did not use the HA feature of OM.
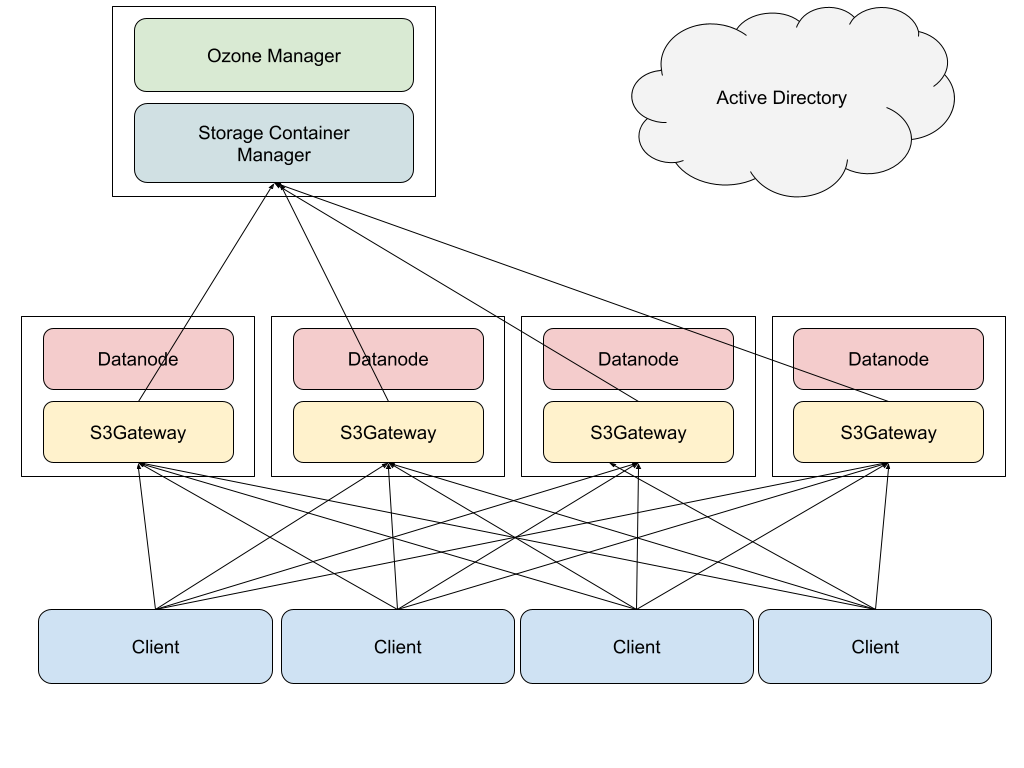 Figure 1: simplified picture of processes
Figure 1: simplified picture of processes
We ran a simple benchmark of accessing a file with size of ~200GB. We built a benchmark script of parallel read, deployed it as several client Pods in our Kubernetes cluster and measured its performance while changing the amount of concurrency. Figure 2 depicts the total throughput of all clients. The maximum throughput was a little less than 4GB/s when the amount of concurrency was 128. The potentially maximum throughput would be obtained by some point of parallelism in clients between 64 and 256. The fact that the size of target data was less than the size of total disk cache capacity, the fact that we had 4 nodes with 20 core CPUs (=80 cores processed requests from all clients in total), and the fact that total CPU usage of DataNodes saturated around 100%, indicates that the bottleneck was in the server side.
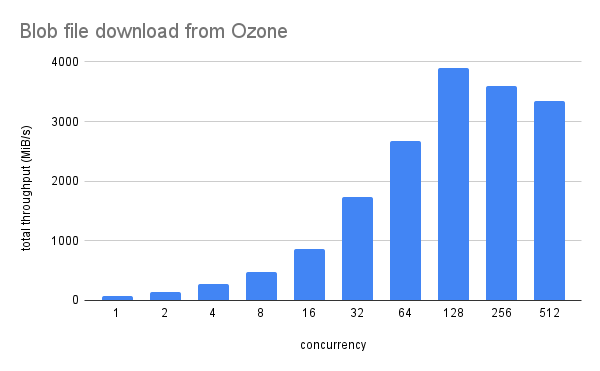 Figure 2: performance of parallel download of a blob file
Figure 2: performance of parallel download of a blob file
After this benchmark, we opened the service for internal use. Several months later, we now have several internal use cases e.g. machine learning and backup. Originally, I thought I could share some of them here in detail, but it turned out that most of them are not that different from standard workloads in deep learning.
History & Current Status
After we built the cluster in early 2021, Ozone 1.1.0 was released in April. We upgraded the cluster right after the release.
Not because of the new version, but the cluster had an unbalanced pipeline (the unit of multi-Raft instance) distribution. We expected 4 nodes with 36 hard drives – expecting 36*4 / 3 = 48 pipelines created by SCM. But it didn’t work; only 36 pipelines were created by the SCM and we didn’t make full use of 144 HDDs and only 108 had data stored. Later, we added two other storage servers as DataNodes, 72 pipelines were created in 6 DataNodes in total, and we made full use of all HDDs, finally. If you want to know more about pipelines, please refer to the blog ariticle by Cloudera [8].
We have been running Apache Ozone for months. It has all components with HTTPS listening /prom endpoints and exposes various metrics in Prometheus Exposition format. We collect those metrics using Prometheus and visualize with Grafana. Also, we set up Alertmanager to get notifications in case of some irregularities. As of today, it has more than 30 million objects and more than 400 buckets. Figure 3 depicts the recent increase of the amount of data.
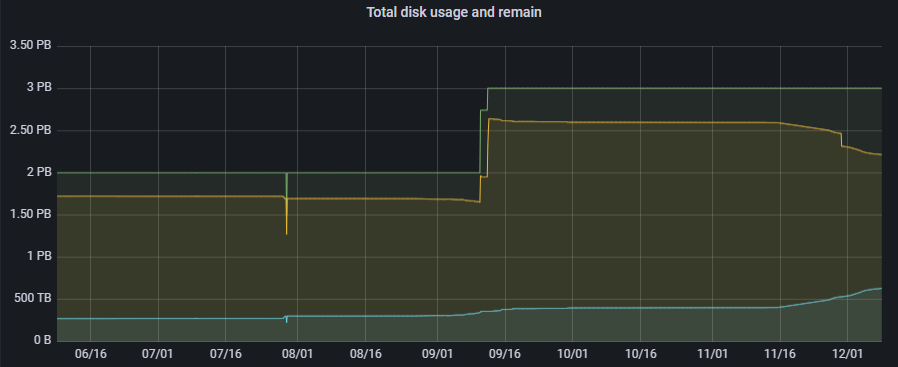
Figure 3: Historical and total disk usage and capacity of our Ozone cluster (physical)
After setup, we did several upstream contributions to address issues found during the operation. We have already reported CVE-2020-17517 for 1.1. Major contributions to the 1.2 are as follows:
- HDDS-5197 (patch)
- HDDS-5620 (patch)
- HDDS-5893 (patch)
- HDDS-4856 (report)
- HDDS-5005 (report)
- HDDS-5393 (report)
There are several other contributions merged to 1.3.0 or still in progress. Descriptions of these issues would be long and will follow in separate blog articles. Aside from the upstream contribution, we cherry-picked HDDS-5472 and applied it to the cluster in September. This patch improved the OM performance drastically and the cluster became very stable. In October, we switched to OpenJDK 1.8.0. Ubuntu 18.04 provides patchlevel 1.8.0-292, which includes TLS processing performance on the server side.
In November, 1.2.0 was released with several fixes against vulnerabilities in past versions. We upgraded right after the release and it went very well without any major issues. We irrefutably have a lot of future work to do, in three major categories..
High Availability in OM and SCM
In the current setup, metadata in OM and SCM is replicated over multiple disks using ZFS. But we still have several single points of failure in the service itself. For example, if the machine that runs OM and SCM fails, those processes will definitely go down and thus the service will all be down. Ozone 1.2.0 has HA features that replicate those services over Raft, which runs three replicated processes and lets the service failover in case of single node failure. The availability of the service would improve a lot, and lower the bar to adopt Apache Ozone for broader use cases of real workloads in PFN.
Cluster Extension of Ozone and Migration from HDFS
As of today, HDFS clusters store ~9PB of data in total while the amount of data in Ozone is still around 200TB. Basically, we want all of the data in HDFS migrated to Ozone. In addition, new data generated from our business workload will be newly stored in Ozone. More capacity is absolutely needed – we do have a plan to gradually move HDFS DataNodes to Ozone as the data migration progresses, but we will have little prospect on how many nodes can be moved from HDFS until full-scale migration actually starts. I did remember that the amount of data in some past storage systems did not decrease even right before the end of its life, and we helplessly and manually cleaned up that data.
There would be several methods and paths to migrate the data. Between clusters with the same KDC (Key Distribution Center for Kerberos, we have multiple of them), we will be able to run distcp among them. In case between them with different KDCs, distcp is said to work with s3a protocol and seems feasible. But one issue is that HDFS does not have a limit in the size of files, S3 API has maximum file size as 5TB. And we do have several files more than 5TB in HDFS.
New Features and Upstream Contribution
No software is perfect and thus we will likely find several shortcomings as we continue to use it. We’ll not only wait for the community to improve or address them, but attempt to do it by ourselves. We’ll continue our effort of sending out patches. We already have some of them; some of important patches and proposal follows:
- HDDS-5656 – Multipart Upload optimization
- HDDS-5905 – Potential data loss
- HDDS-5975 – ListObjects bugfix
Conclusion
In PFN, migration from Apache Hadoop to Apache Ozone has been in progress. We described its background, actual setup and benchmark. We anticipate that the data will increase continuously and we’ll expand our cluster. We also try to keep sending our feedback and contribution to the community during the operations.
Acknowledgement: I appreciate Kiyoshi Mizumaru, Kohei Sugihara, Yusuke Doi, Tommi Kerola and Avinash Ummadisingu for helping me a lot to improve this article.
Reference
- [1] 《日経Robotics》AIによるシミュレーションの進化 :PFN岡野原氏連載 第56回
- [2] Preferred Networks におけるHadoop – Preferred Networks Research
- [3] Ubuntu 14.04 and 16.04 lifecycle extended to ten years
- [4] The Small Files Problem
- [5] Future of Data Meetup: Apache Ozone – Breaking the 10 billion object barrier
- [6] NVD – CVE-2020-17517
- [7] PFN’s Supercomputers – Preferred Networks
- [8] Multi-Raft – Boost up write performance for Apache Hadoop-Ozone
- [9] HDFS | CDP Private Cloud
Area
Tag