Blog
Introduction
PFRL has been under development as the successor of ChainerRL. We also continue the research of distributed reinforcement learning in PFN. In this blog, we introduce our design, practice, and results achieved in distributed reinforcement learning via an example of a real-world application.
What is reinforcement learning and why is distributed reinforcement learning necessary?
Reinforcement learning (RL) is one of the major components in the major machine learning techniques along with supervised learning and unsupervised learning. In RL, an agent explores in an environment and trains the model using the experiences. Unlike supervised learning, RL does not require explicit labels on the target dataset and explores the search space dynamically. In other words, RL generates a dataset while training the dataset simultaneously.
When one applies machine learning algorithms to difficult or complex tasks, an effective option is to increase computing resources (i.e. scaling) to accelerate the training process.
Due to the nature of RL, there are two major challenges in scaling the training.
The first challenge is to scale the model training part. It is often the case that the target task is so difficult that long training time is required to achieve good accuracy. This is similar to other deep learning applications, such as image classification or segmentation for large datasets.
The second challenge is to scale the environment. RL is often applied to complex real-world tasks. One typical example is robot manipulation. In such applications, the environments are physics-based simulators, which are complex and often computationally heavy. Thus it may take longer to produce necessary experience data and the training process. In this case, the GPUs that are allocated for deep learning training iteration are idle for a long time. In most cases GPUs are one of the most expensive components in computing systems. Since it is often the case that simulators are complex applications and only run on CPUs, one may want to increase the number of CPUs for simulators to feed the GPUs and take the best balance of computing resources.
History of developing and scaling reinforcement learning efforts in PFN
PFN has been tackling real-world robot manipulation tasks in both academic community and industrial applications.We published a paper “Distributed Reinforcement Learning of Targeted Grasping with Active Vision for Mobile Manipulators” [1] in IROS 2020, where we demonstrated scaling the RL application up to 128 GPUs and 1024 CPU cores.
Another important contribution to the community by us is developing deep learning frameworks. PFN developed Chainer, a Python-based flexible deep learning library based on the defined-by-run concept. The demonstrations and the IROS 2020 paper [1] mentioned above were based on ChainerRL, an RL library based on Chainer.
At the end of 2019, PFN decided to shut down the Chainer development and join the PyTorch community. The ChainerRL components were ported to PyTorch and it was named PFRL. The library is designed to enable reproducible research, to support a comprehensive set of algorithms and features, and to be modular and flexible.
For more details on PFRL, see our blog post: Introducing PFRL: A PyTorch-based Deep RL Library | by Prabhat Nagarajan | PyTorch
In the rest of this blog post, we show how we port the components used in the IROS 2020 paper, which were based on ChainerRL, to PyTorch-based PFRL and scale an RL application on our in-house computing infrastructure using PFRL.
Design & Implementation
Motivations
Unlike the conventional machine learning, where all the data can be read from existing files, reinforcement learning learns while generating the experience for the next learning epoch. Such a feature adds a new possible bottleneck to reinforcement learning in addition to the learning process itself. Currently, we observe the following two big performance challenges in reinforcement learning:
Slow acting: For some heavy environments, generating experience can be quite slow, e.g. heavy physical simulations.
Slow learning: The learning time increases as we have more experiences generated or have a bigger model.
While researchers focus more on the slow learning, and much work is published to resolve the slow learning by using multiple learners (e.g. DistributedDataParallel for pytorch. However, few work has considered the slow acting challenge. A slow actor results in a bigger interval between each learning epoch and a longer overall learning time. Learners have to wait for enough experiences generated before they can start the next learning epoch. Moreover, since most actors run on CPU, the computational power divergence between CPU and GPU makes it more difficult for such heavy environments to catch up to the learning. Hence, in this experiment, we focus more on resolving the slow acting issue via actor parallelism.
Actor parallelism
In this section, we explain the details of our actor parallelism to resolve the slow acting challenge. Similar to distributing the learning workload to multiple GPUs, we tackle the slow acting challenge by adding more actors. In our system, the number of actors or the ratio of actors per learner can be increased when the acting is the bottleneck of the system.
While unlike adding GPUs, adding actors is not straightforward. In traditional reinforcement learning architectures, the actors and learners sit on the same node, so that the experience can be transferred from actors to learners via memory. However, such architectures add limitations on the number of actors that can be created, the maximum number of actors are limited by the computational resources on one node, in most cases CPU core counts. As the GPUs outperform the CPUs in computation, a large number of CPUs might be needed to generate data fast enough to feed a GPU with a heavy environment, which can cause CPU shortage on nodes with multiple GPUs.
We introduce the remote actors to resolve the issue. In contrast to traditional local actors, which sit on the same node with the learner, remote actors are actors created on different nodes. The remote actors connect to the learners with grpc for two kinds of communications:
Periodically receive updated model from learner
Send the generated experiences to learner
By having the remote actors, we are able to scale the number of actors without the limitation of single node resources. In our system, both remote and local actors are supported.
Overview of PFN distributed reinforcement learning
In this section, we introduce the overview of distributed reinforcement learning in PFN. In PFN, we manage our computation resources with kubernetes, hence, we built our distributed reinforcement learning environment on kubernetes and docker. The following is an overview of our distributed reinforcement learning system:
In our system, there are three different kinds of processes:
Actors: run on CPU, generate experiences from the given environment and model. There are two types of actors: the local actors, which locate on the same pod as the learners and connect with learners via pipes; remote actors, which locate on seperate CPU pods and connect with learners/controllers via grpc.
Learners: collect the experience from actors and update the model from the experience. In case of distributed data parallel learning, all the learners connected through torch DistributedDataParallel.
Controllers: serve as the gateway of each GPU pod for remote actors to connect to. controllers also help to balance the workload when there are multiple learners on the same GPU pod.
Application performance evaluation case study
Molecular graph generation task
Designing molecular structure that has desired properties is a critical task in drug discovery and material science. RL is an important approach to the problem since there are several tough challenges in the application: the search space (i.e. the total number of valid molecular graphs) is huge (estimated to be more than 1023 [32]) and discrete. One of the prior work is “Graph Convolutional Policy Network for Goal-Directed Molecular Graph Generation” , which applies PPO algorithm to the molecular graph generation task.
We extend their work and implement the algorithm on PFRL and test the scalability of our implementation
Experiment
In this section, we conduct a set of experiments to show the effectiveness of actor parallelism. We run the experiments on our internal cluster mn2 (Learner jobs) and mn3a (remote actor jobs) with the specifications shown in following Table
| cluster name | mn2 |
| CPU | Intel(R) Xeon(R) Gold 6254 CPU @ 3.10GHz 36 cores |
| Memory | <376G/td> |
| GPU | Nvidia Tesla V100 SXM2 x 8 |
| Network | 100GbE x 4 |
| cluster name | mn3a |
| CPU | Intel(R) Xeon(R) Platinum 8260M CPU @ 2.40GHz 48 cores |
| Memory | 376G |
| Network | 100GbE x 4 |
We modify the original implementation of our molecular graph generation PPO application to support the distributed learning, and we run all the experiments using exactly the same parameters of the original implementation. We confirm that all experiments achieve good accuracy compared to the original implementation within acceptable error range.
Scalability results
Sclaing out the actors
In the experiment, we demonstrate the effectiveness of actor parallelism. We show how adding more actors can reduce the runtime of the reinforcement learning. As we stated in the previous section, our target application implements PPO, which is an on-policy algorithm. Thus, actors cannot run parallelly with learners. In other words, the learner has to wait for actors to generate necessary experiences and fill the queue and the actors have to wait until the learner runs the training process and updates the model to ensure that all experiences are generated from the latest model. However, adding more actors can help to speed up filling the experience queue after each model update, and therefore, reduce the interval between updates and shorten the overall run time. We run learners on a single GPUs, and scale out the number of actors. We assume each actor occupies a CPU core, when the number of actors exceeds the CPU count on a single node, we move additional actors to remote nodes as remote actors.
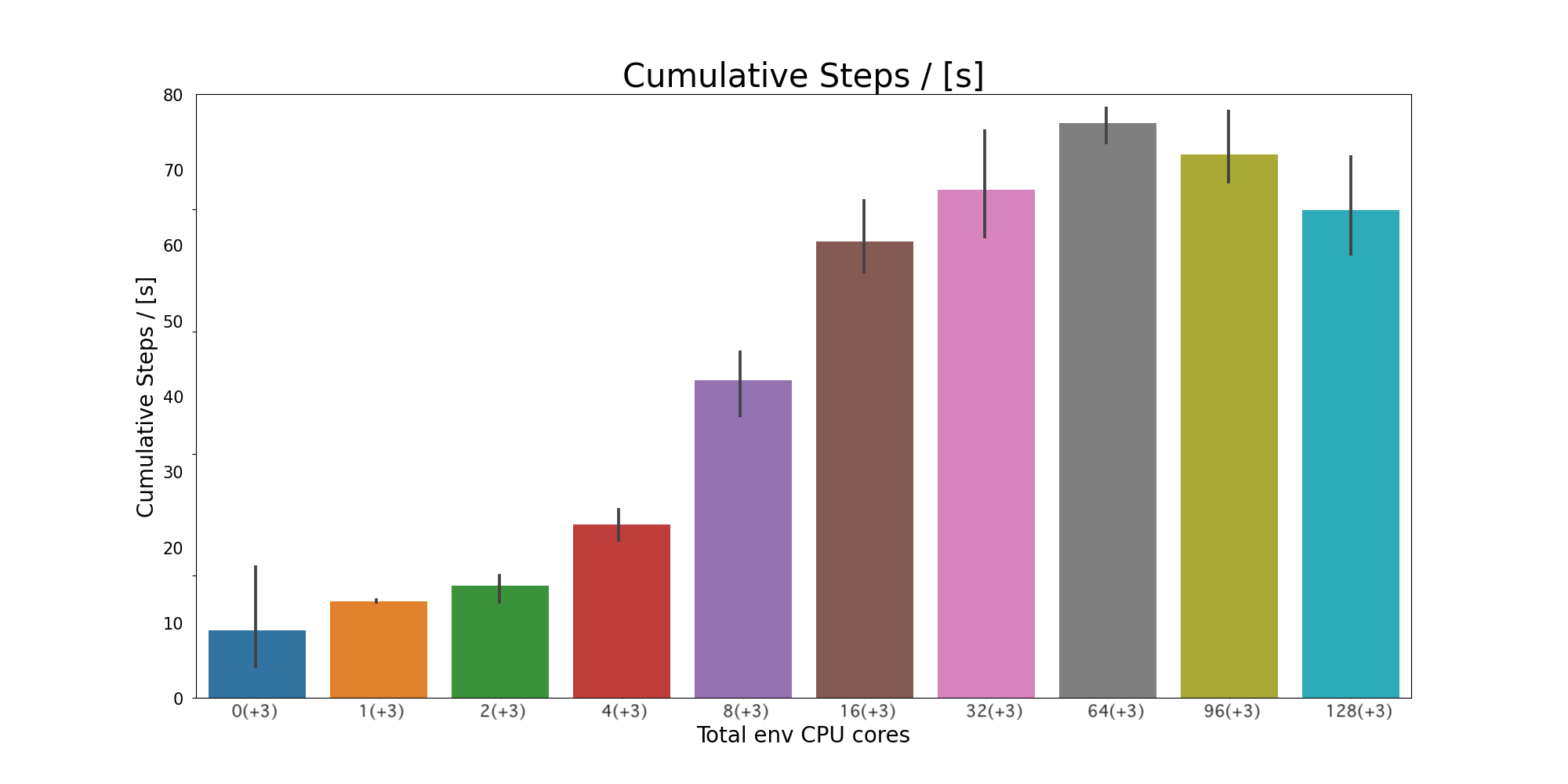
The figure above shows the performance and scaling of the implementation. The Y axis shows “Cumulative steps per second”, where the higher is better, and the X axis shows the number of CPU cores. The learner process runs actors locally with 3 CPU cores, and we increased CPU cores for actors additionally. Thus, for example, “16 (+3)” means we used 16 CPU cores for remote actors along with 3 cores for the learner process.
We have confirmed that the parallel efficiencies are great from “0 (+3)” to “16 (+3)”, and it goes down after that. In addition, from the figure, we can see that the “cumulative steps per second” descrases after “64(+3)”. Since adding remote actors only shortens the experience-generation time between the learner’s training steps. According to Amdahl’s law, adding even more actors does not contribute to shortening the training time and there is higher runtime overhead. The “best point” highly depends on the application’s performance characteristics.
Conclusion
We described PFN’s effort of scaling reinforcement learning applications. We combined our RL framework (ChainerRL and PFRL) and gRPC communication technology and scaled RL application where actor (or env) simulators are relatively computationally heavy. We published a paper in IROS 2020 [1] and demonstrated the large-scale parallelization of off-policy DQN for a robot manipulation application. Another case-study we showed in this blog article was an on-policy PPO for molecular graph generation application.
References:
- [1] “Distributed Reinforcement Learning of Targeted Grasping with Active Vision for Mobile Manipulators” https://arxiv.org/abs/2007.08082
- [2] “Graph Convolutional Policy Network for Goal-Directed Molecular Graph Generation” https://arxiv.org/abs/1806.02473
- [3] “Decentralized Distributed PPO” http://learningsys.org/neurips19/assets/papers/25_CameraReadySubmission_ddppo_neurips_sysml_cr.pdf
- [4] “DD-PPO: LEARNING NEAR-PERFECT POINTGOAL
NAVIGATORS FROM 2.5 BILLION FRAMES” https://openreview.net/pdf?id=H1gX8C4YPr - [5] “Massively Large-Scale Distributed Reinforcement Learning with Menger ”https://ai.googleblog.com/2020/10/massively-large-scale-distributed.html
- [6] Introducing PFRL: A PyTorch-based Deep RL Library | by Prabhat Nagarajan | PyTorch
