Blog
Introduction
Research and development of deep learning based applications requires significant computational resources. PFN developed MN-Core, a highly specialized deep learning accelerator to speed up its R&D processes. MN-Core has been deployed in our supercomputer MN-3.
This article provides an overview of MN-Core, its compiler and performance evaluations for several deep learning workloads putting PFN’s MN-Core compiler to the test.
Overview of MN-Core
MN-Core (https://www.preferred.jp/en/projects/mn-core/) is an accelerator specialized for deep learning workloads. To accelerate convolutional operations, which are frequently used in deep learning, MN-Core has a hierarchical structure consisting of many highly efficient matrix operation units. Between each hierarchical level, MN-Core can perform collective communication, which is commonly used in deep learning workloads, such as distribution/broadcast transfer.
From an architectural perspective, MN-Core possesses the following attributes
- Purely SIMD: Employing a SIMD (Single Instruction Multiple Data) model, only a single instruction is executed at once
- Fully deterministic: Programmers can control local memory access and data paths between compute units directly
These architectural attributes allow MN-Core to integrate a large number of processing elements on a single chip compared to other accelerators, resulting in overwhelmingly high performance levels.
On the other hand, being a huge SIMD processor that expects all memory accesses and data transfers to be explicitly specified requires additional efforts to be fully utilized. .
As PFN’s R&D covers a wide range of workloads it is not practical to expect every developer to use MN-Core with a deep understanding of the MN-Core architecture and to make an effort to achieve the best performance for each workload. Therefore, we have been developing a compiler to provide a way to use MN-Core easily and efficiently.
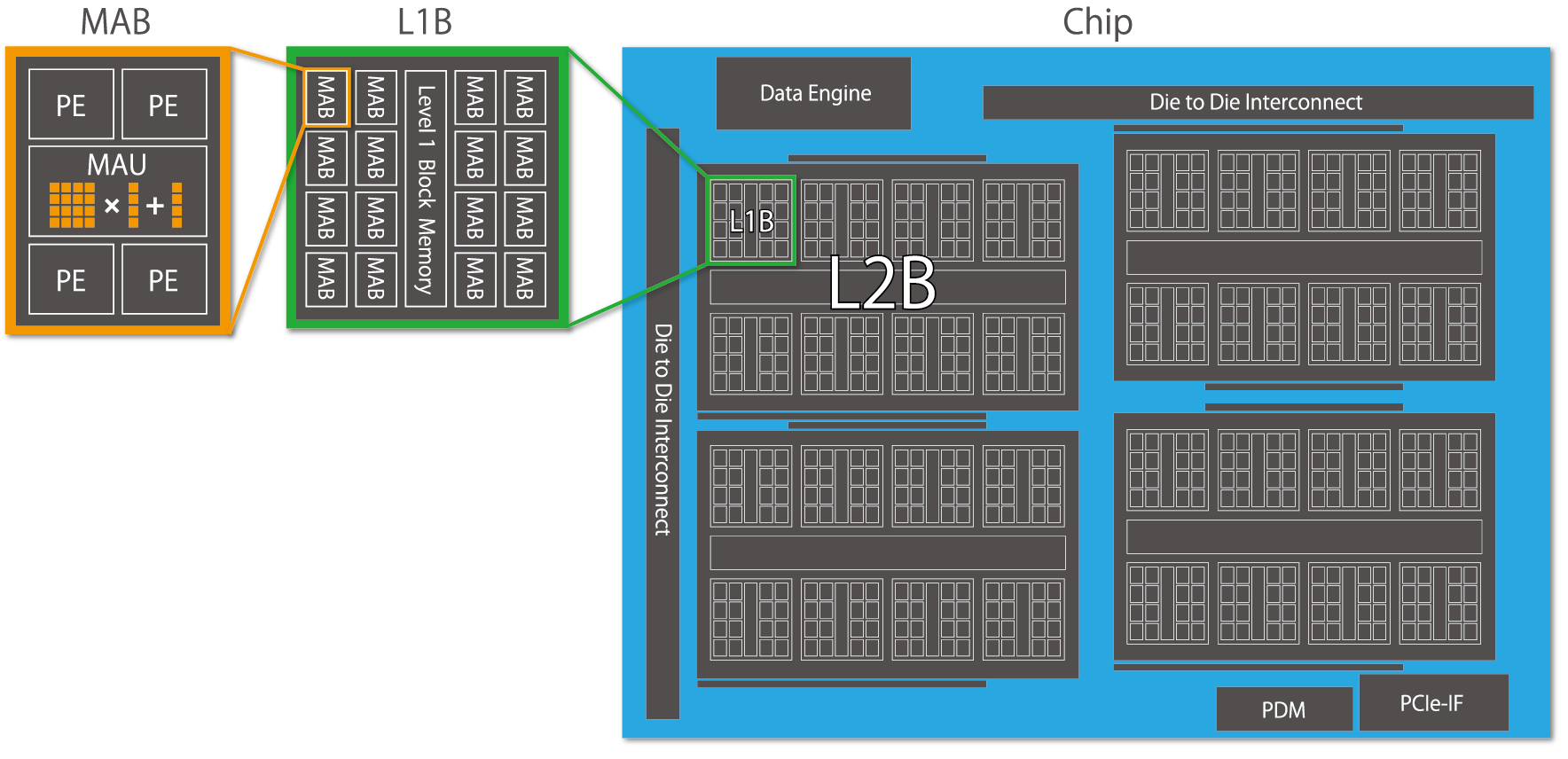
Fig.1 MN-Core Overview
Overview of MN-Core Compiler
Figure 2 shows an overview of the MN-Core compiler.
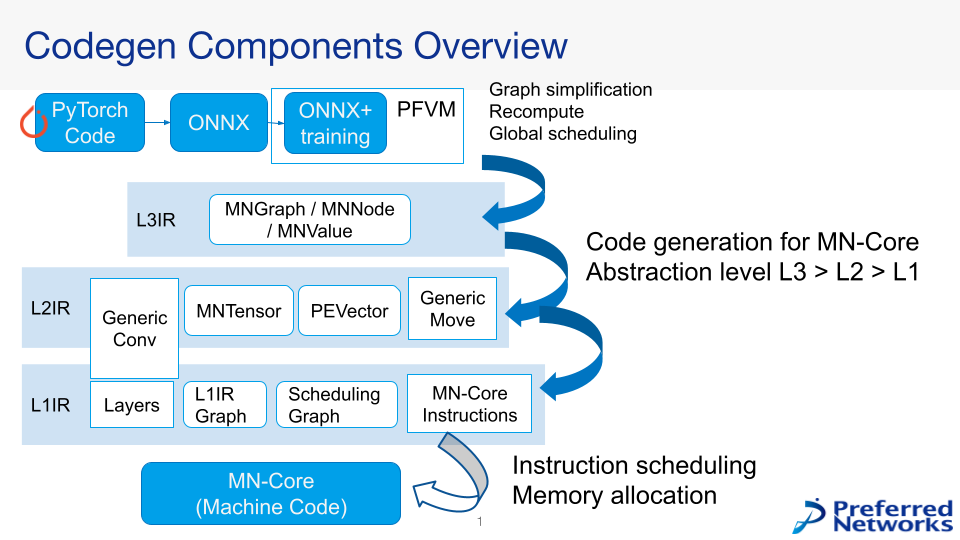
Fig.2 MN-Core Compiler Overview
For the compiler development we defined two primary goals:
- Minimizing the need for modifications to existing PyTorch based user code as much as possible
- Making full use of MN-Core’s effective performance
The first point is to provide an “as is” user experience for PyTorch-based user code as much as possible.
At PFN, many of our users are currently using PyTorch as a framework for deep learning accelerated on GPUs for their R&D activities. Since many of our R&D assets are based on PyTorch, we need to ensure that MN-Core requires as few modifications to the existing PyTorch code as possible.
To meet this requirement, we have chosen ONNX as a framework-independent representation of deep learning models as input to the MN-Core compiler. Using ONNX, we can minimize the need to rewrite existing code to support MN-Core (the compiler requires that user code is exportable to ONNX with some constraints).
In addition, we’re developing a trainer framework that can be used for both GPU and MN-Core. The trainer provides a unified interface for training deep learning models (incl. data loader and monitoring of training progress). The framework will be part of pytorch-pfn-extras (https://github.com/pfnet/pytorch-pfn-extras) in the future.
The second point is that the compiler has to take full advantage of MN-Core’s performance.
Since MN-Core is a huge SIMD processor, it is essential to maintain a steady data supply so that the achieved performance gets as close as possible to the theoretical peak performance. Since MN-Core has a hierarchy of compute units and certain constraints on the transfer patterns between each layer, it is necessary to carefully consider how the computations are mapped to each compute unit. On the other hand, the mapping policy itself has many degrees of freedom, and it is difficult for compiler developers to properly manage the global scheduling of computations as well as the data movement patterns/layouts between each layer. For this reason, the MN-Core compiler divides the problem according to the level of abstraction and thus consists of components that make it easy to make improvements at the respective level. For example, while the global layout and recomputation strategy are decided based on the ONNX graph provided by the component called L3IR in Figure 2, the component does not consider the order of operations in each layer.
On the other hand, the components called ‘Layer’ and ‘Generic Conv’ in Figure 2 are responsible for defining each op unit’s computation order in ONNX, but they do not consider the global strategy. By carefully designing the commonly used components/abstraction layers (ex. numpy-like tensor for MN-Core) while appropriately partitioning the problem in this way, we can achieve highly efficient execution on MN-Core.
Performance evaluation
In this section we cover the performance evaluation of our compiler by comparing attained real-world performance on MN-Core for actual deep learning workloads.
All evaluations shown here were performed under the following conditions
- Comparing MN-2 (using GPUs) and MN-3a (using MN-Core), using one accelerator board each.
- Workloads executed on MN-Core are compiled by the MN-Core compiler
Workloads for evaluation
- Instance segmentation / Object detection using CNN-based models
- Physics simulation using GCN-based models
- Neural architecture search (NAS)
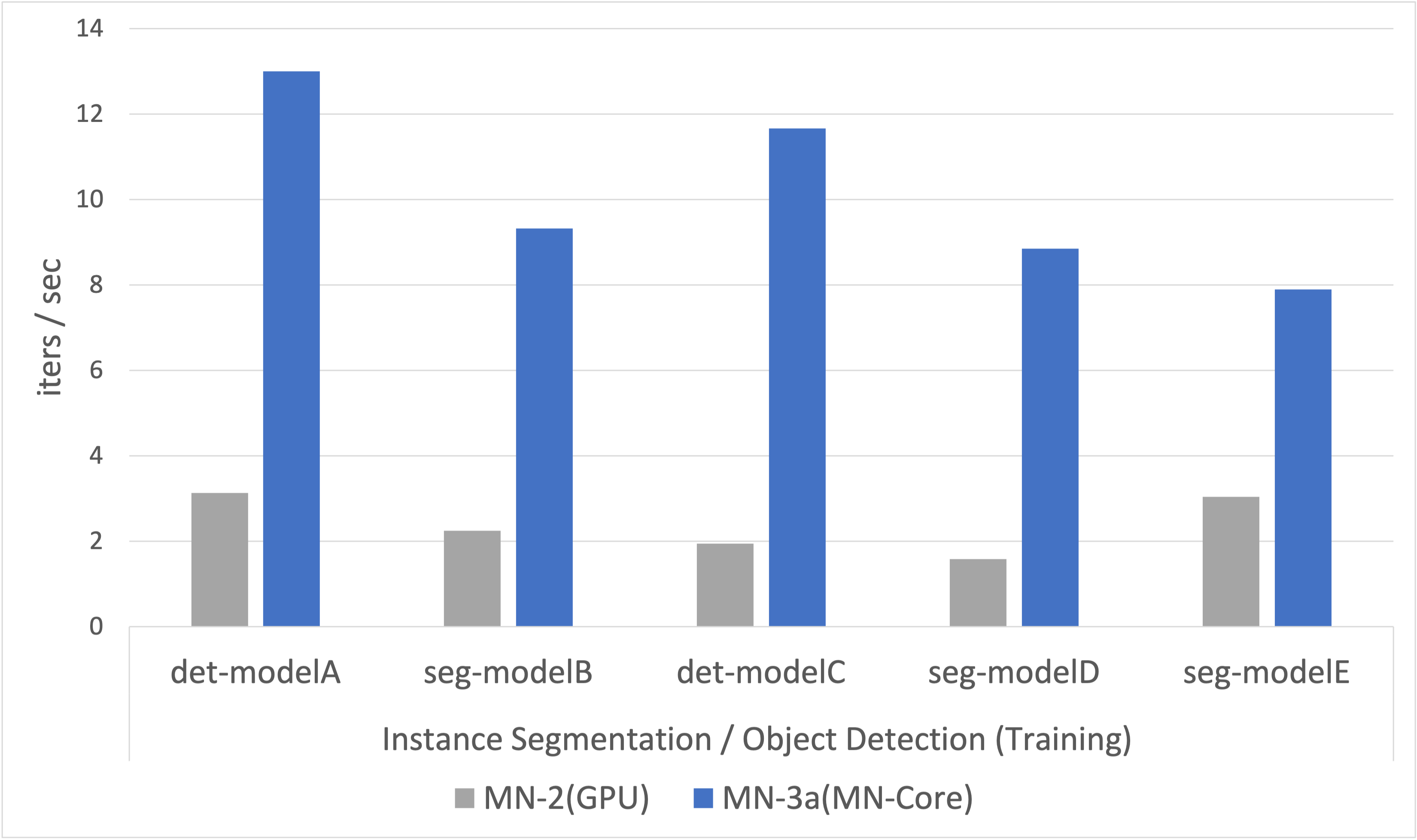
Fig.3 Performance Evaluation (Instance Segmentation / Object Detection, MN2 vs MN3)
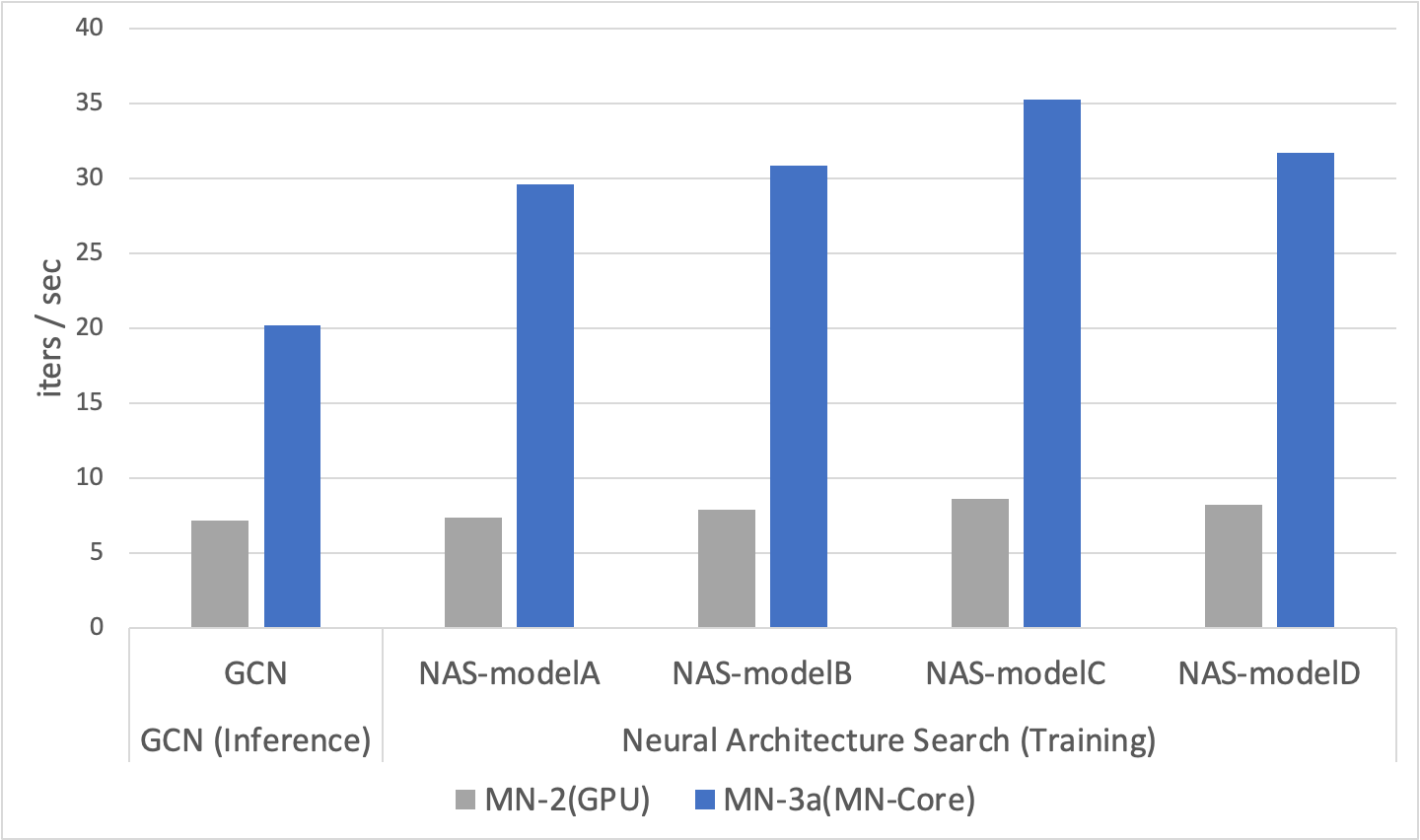
Fig.4 Performance Evaluation (GCN + NAS, MN2 vs MN-3a)
Instance Segmentation / Object Detection with CNN-based models
CV (Computer Vision) is an essential application of deep learning.
In this evaluation, we use several instance segmentation and object detection models used in PFN as a typical CV application.
Details of the models are not described, but all of the models are CNN-based.
Fig. 3 shows that MN-Core significantly improves the training speed of these models on average, and up to 6 times in best case compared to the existing infrastructure.
Although the speed depends on the network structure, the type of layers required, and the experimental setup, the result proves MN-Core has the capability to speed up the training processes compared to the existing infrastructure considerably.
In addition, the fact that MN-Core can speed up the training of these models suggests that it can also be used to train other CV workloads such as Semantic Segmentation and Image Classification, which are considered simpler problems settings.
Physics Simulation with GCN-based Models
The next application we evaluated is based on the Graph Convolutional Network (GCN).
GCN is a deep learning model that uses Graph Convolution, which is a convolution of graph structures.
The model is widely used for data that can be represented by graph structures.
In this evaluation, we considered the inference speed of GCN-based physics simulations.
As depicted in Fig. 4, the GCN inference workload achieves a x3 speed-up. The GCN-based physics simulation workload that we evaluated is very different from regular CNNs as it requires a large amount of derivative computations similar to those used in error backpropagation as well as irregular memory accesses. Despite this stark difference, the results show that the MN-Core compiler achieves significant speed-ups on MN-Core.
Neural Architecture Search (NAS)
The last application of our evaluation is Neural Architecture Search (NAS).
Neural architecture search is a semi-automatic design method for deep learning models. It uses a multi-objective approach to navigate in the search space, taking into account simple accuracy and various characteristics important in actual deployments, such as inference speed and memory usage. (For more information on NAS, please refer to our blog – https://tech.preferred.jp/ja/blog/nas-semseg/)
The process of searching for a suitable network using NAS requires training of a lot of models with different parameters generated according to the search space defined in NAS. Therefore, the compiler needs to be robust with regards to a plethora of parameters and ranges, which cannot be realized through simple parameter tweaks.
In this evaluation, we ran a MobileNetV2-based architecture search workload on both MN-3 and MN-2. The objective is to find some models that are optimized for accuracy and latency in inference devices.
Using this experiment, we not only confirmed that MN-Core can perform the workload, but also that MN-Core outperformed its GPU counterpart by a considerable margin.
The right hand side of Figure 4 shows the training performance of several explored architectures on the Pareto front.
This result indicates a considerable speedup in training of models during NAS optimized for inference devices on MN-Core on average compared to MN-2.
Conclusion
This article gave an overview of MN-Core and the MN-Core compiler.
While the compiler is still under development, we can conclude from the experiments that MN-Core not only can execute relevant workloads efficiently, but also that it outperforms our previous infrastructure. Furthermore, as CNN and GCN like networks cover a huge array of applications, we are confident that MN-Core and its compiler approach provide a general method to efficiently run deep learning workloads on MN-Core.
PFN will continue to develop the MN-Core compiler to accelerate our R&D.
Area