Blog
Preferred Networks (PFN) attended the International Conference on Machine Learning (ICML) in Sydney, Australia. The first ICML was held in 1980 in Pittsburgh, last year’s conference was in New York, and the 2018 ICML will be held in Stockholm. ICML is one of the largest machine learning conferences, with approximately 2400 people attending this year. There were 434 accepted submissions spanning nearly all areas of machine learning.
As we can see in the following figure, the single most popular area by a large margin was Neural Networks and Deep Learning, but there were a significant number of submissions from the other areas as well.
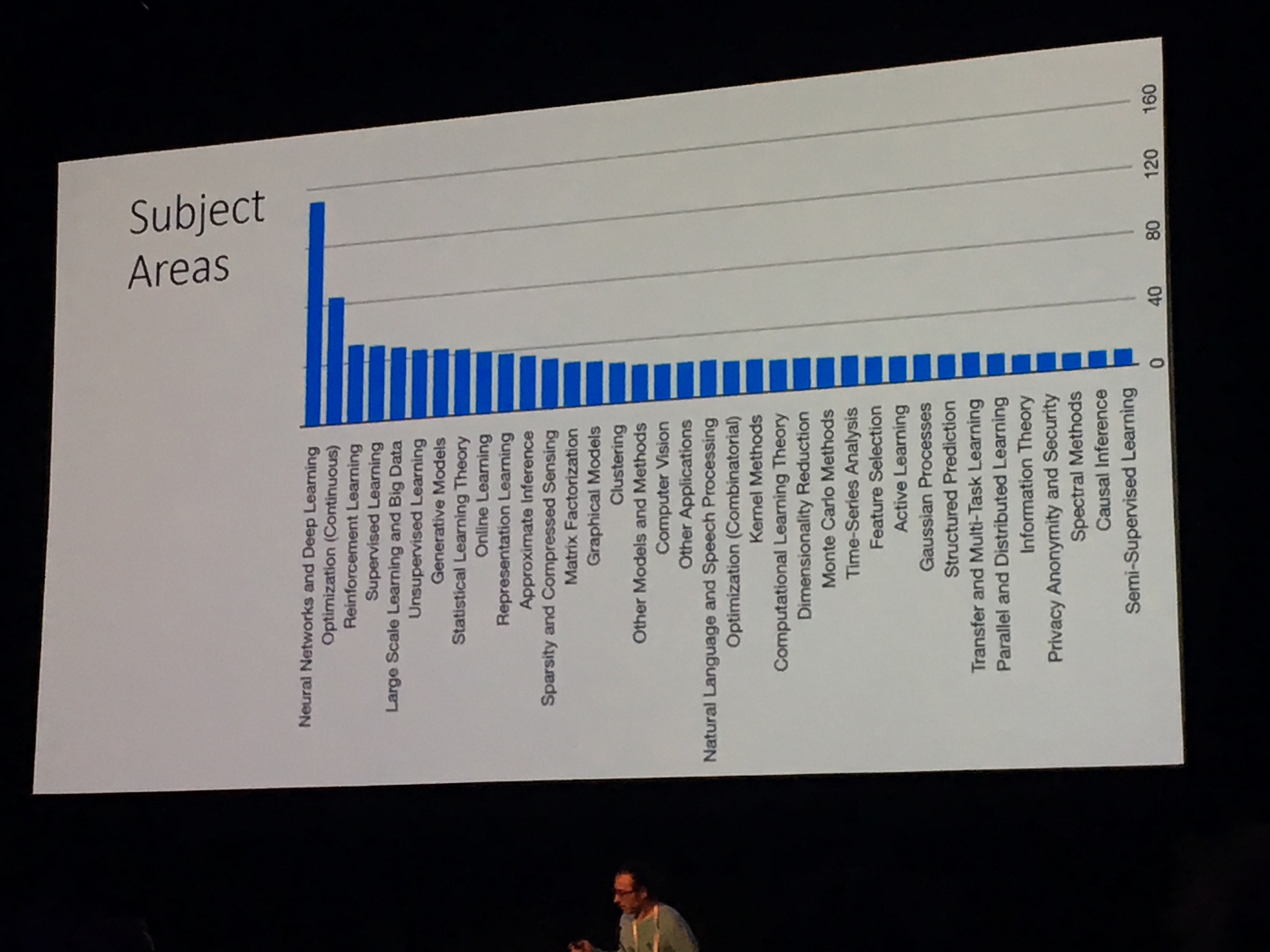 (Subject area representation this year)
(Subject area representation this year)
 (View of Darling Harbour and downtown Sydney from the convention center. A boat show was also going on during the first two days of ICML. None of the boats were self-navigating (as far as I know))
(View of Darling Harbour and downtown Sydney from the convention center. A boat show was also going on during the first two days of ICML. None of the boats were self-navigating (as far as I know))
We attended the conference to learn more about the latest research results and recent advancements in machine learning and to connect with other researchers, engineers, and students. We expect that what we learned will be useful in our future research activities. For example, we had interesting discussions with other researchers on their experiences using deep learning frameworks including PFN’s own Chainer framework. Some of our members attended tutorials to learn more about recent developments in other deep learning frameworks such as MXNet. This kind of information and feedback helps us to make future versions of Chainer even better.
 (Several companies such as NVIDIA, Facebook, Intel, and Netflix also had booths at the conference)
(Several companies such as NVIDIA, Facebook, Intel, and Netflix also had booths at the conference)
Since most subject areas of machine learning are represented at ICML, there was likely to be something of interest to all of the participants. For example, there were tutorials focused on diverse topics such as health care applications, autonomous vehicles, interpretable machine learning, and distributed deep learning. There were also many workshops on a wide variety of topics such as video game ML, natural language generation, computational biology, IoT and low-power ML, secure ML, and music discovery.
This year’s Best Paper Award went to “Understanding Black-box Predictions via Influence Functions” by Pang Wei Koh and Percy Liang. This paper makes contributions to improving model interpretability, which is one of the important current challenges in deep learning. We found many other papers to be interesting as well. However, since the topic coverage is so broad at ICML, rather than trying to list all of the interesting papers here, we suggest to have a look through the list of accepted papers and check those that look potentially interesting in more detail.
Two conference papers and a workshop paper were presented by PFN members. Below is a quick summary of their work.
- Evaluating the Variance of Likelihood-Ratio Gradient Estimators. S. Tokui (This work is solely done as a Ph.D. student at Univ. of Tokyo) and I. Sato (Univ. of Tokyo). This paper introduces a novel gradient estimation framework that generalizes most of the common gradient estimators. This framework can serve as a bridge between the likelihood-ratio method and the reparameterization trick. We show that it can provide a natural derivation of the optimal estimator so that we can use it to evaluate optimal degree of each practical baseline technique.
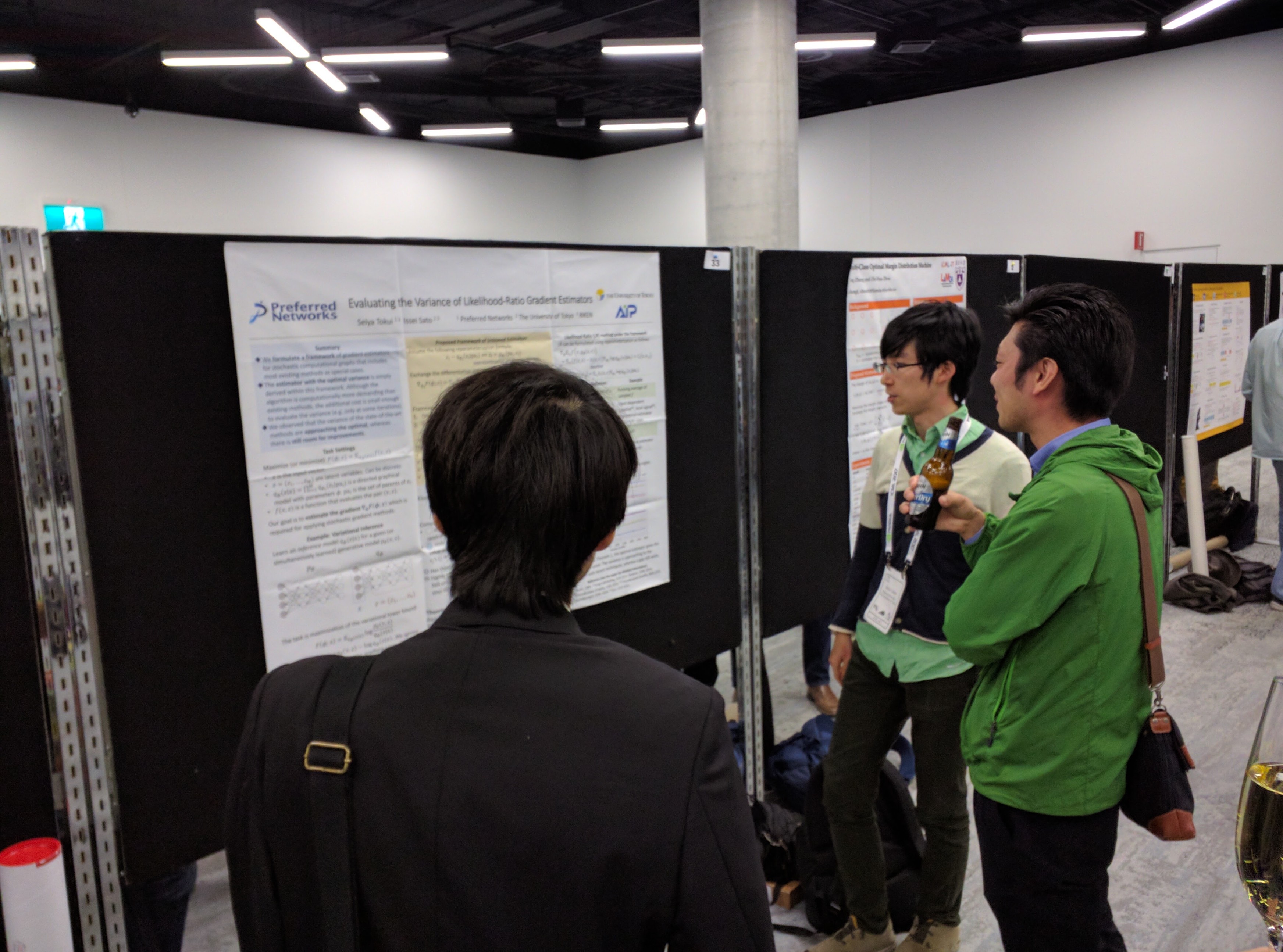 (Seiya Tokui at his poster)
(Seiya Tokui at his poster)
- Learning Discrete Representations via Information Maximizing Self-Augmented Training. W. Hu (Univ. of Tokyo), T. Miyato, S. Tokui, E. Matsumoto and M. Sugiyama (Univ. of Tokyo). This paper was written by Weihua Hu for his summer internship project at PFN. We were able to achieve state of the art performance on both clustering and hash learning in many benchmark datasets.
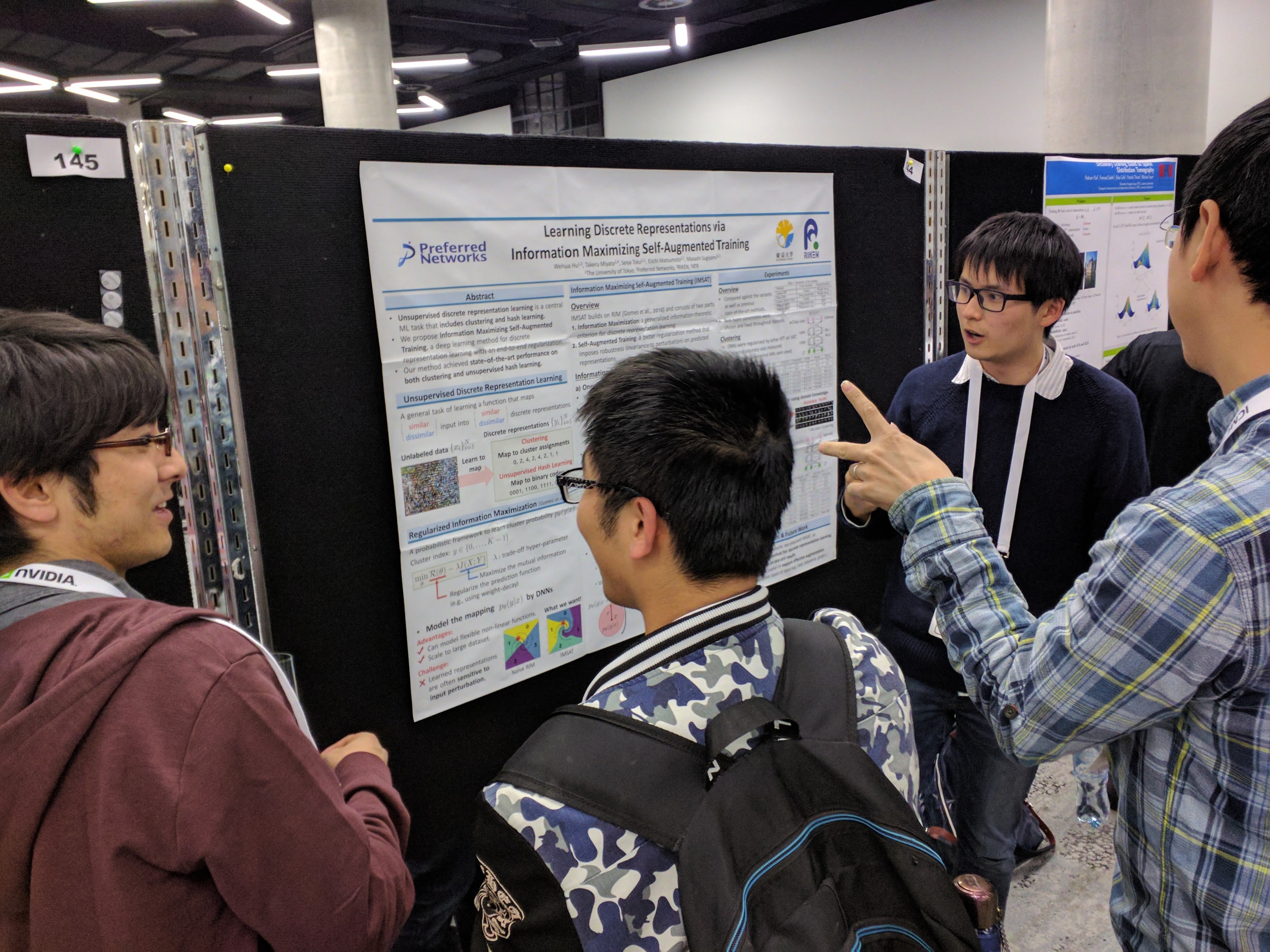 (Takeru Miyato and Weihua Hu at their poster)
(Takeru Miyato and Weihua Hu at their poster)
- Spectral Normalization for Generative Adversarial Networks. (ICML 2017 Workshop on Implicit Models) T. Miyato, T. Kataoka, M. Koyama (Ritsumeikan Univ.) and Y. Yoshida (NII). This paper proposes a new normalization method that makes it easier to train GANs by improving stability. It is also easy to modify existing implementations to use this new method.
 (Takeru Miyato at his poster)
(Takeru Miyato at his poster)
We are planning to write more detailed blogs on some of these papers soon, so please stay tuned!