Blog
This is a guest blog from an ex-intern, Nontawat Charoenphakdee.
About me
I am Nontawat Charoenphakdee from Bangkok, Thailand. I am currently a second-year PhD student (starting from Sep 2018) working on machine learning at the Sugiyama-Sato-Honda lab in the University of Tokyo. I graduated with a master’s degree from my current lab. My hobbies are listening to music, karaoke, and playing games. More information about me can be found here: https://nolfwin.github.io/.This blog entry introduces my work during the summer internship (Aug-Sep 2019) at PFN.
Introduction: a system that can recognize you by your voice

Speaking is a natural way for humans to communicate. As we can see from recent developments in speech technology, the way we communicate with robots is getting closer and closer to the way we talk to people [1, 2, 3, 4]. For example, PFN’s interactive robot can receive voice commands from humans and follow their orders (see PFN’s ICRA-2018 paper and Autonomous Tidying-up Robot System at CEATEC2018 for more information).
Currently, several voice assistant applications are focusing on understanding the voice command without verifying the identity of speakers [2]. It is known that being able to know a speaker’s identity can enhance the security of an application. Intuitively, we definitely do not want anyone to be able to give an order to any robots, especially in a critical application (for example, see “Amazon’s Alexa started ordering people dollhouses after hearing its name on TV” and “How A Few Words To Apple’s Siri Unlocked A Man’s Front Door“).
Not only security issues, we believe that being able to recognize a speaker’s identity will lead to more exciting and useful applications of the current technology we have. Two examples are given as follows.
First, a robot can provide an appropriate response for each speaker. For example, a robot teacher may adjust an explanation according to the student or a personal robot may interact with its owner and their friends differently according to the robot’s knowledge about each user. Another example is we can design a permission level for each user to use a robot. This can also prevent a robot to receive a command from an unknown speaker who wants to use a robot in an inappropriate way.
Second, we can communicate with a robot more naturally. Consider a scenario such as a person says “Take my cup” behind the robot. Although a robot cannot see that person, a robot can associate the word “my” with the speech identity of the speaker and perform a command accordingly. It would be less natural to say “Take [person_name]’s cup” when the context is clear. Intuitively, knowing who you are talking to will give you a better understanding on the current context of the conversation.
For these reasons, being able to recognize a speaker allows a personal robot to support a wider range of applications. Thus, this study aims to explore the possibility of using speaker identification under the situation where we only have a few training data for our target speakers (few-shot). The main motivation is that we do not want our customers/users to spend too much time teaching our robots. Moreover, for safety reasons, the system should be able to detect unknown speakers that are not in the training data in the test phase (open-set). So that we can avoid any potential damages that may cause by them. As a result, we created an application and tested it using real-world few-shot speech data (which are collected from PFN members and interns, thank you for your cooperation!).
Problem setting: Open-set Few-shot Speaker Identification
Without any prior knowledge of the task, it would be difficult to use machine learning when the number of data is very few (e.g., two data points per class) because it is prone to overfitting. In our speaker identification task, we are working on human speech information. Therefore, in addition to a small dataset of our target speakers (target data), we may consider incorporating a large labeled speech dataset even though such data are not from our target speakers (source data). Our problem setting can be informally explained as follows:
Given:
- A large labeled data (speech-speaker pairs) from benchmark datasets.
- A small labeled data (speech-speaker pairs) from target speakers
Goal:
Learn a classifier that can classify well from given new speech input, whether it comes from which target speaker or it is not from any target speakers at all. To evaluate the performance of a classifier, we use the following three evaluation metrics: accuracy (ACC), balanced accuracy (BAC, i.e. averaged accuracy), and F1-measure (F1) (see [5] for more information on each metric).
Source data
We used the LibriSpeech dataset [6] as the source data. It is a famous freely available speech data consists of more than 1000 hours of English speech. There are almost 2500 speakers in this dataset.
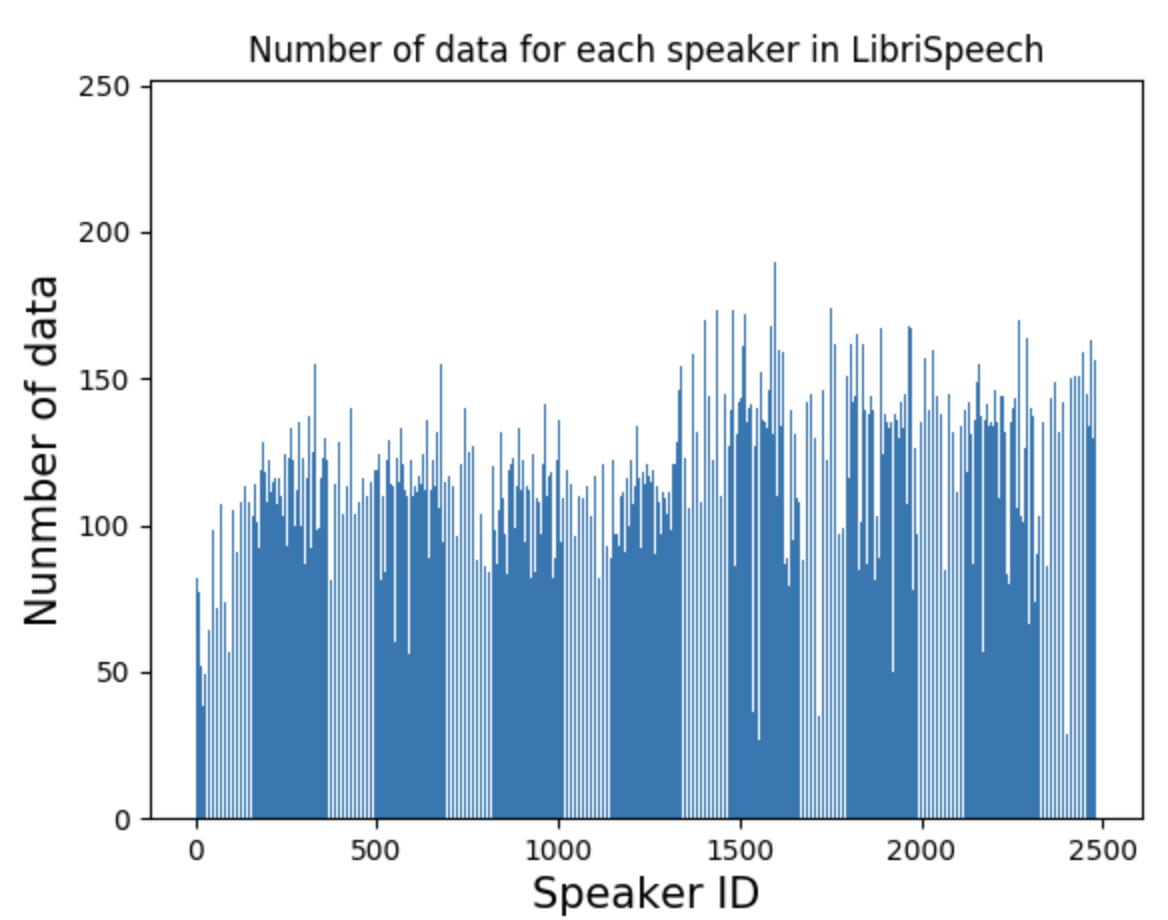
Figure 1: Statistics of LibriSpeech dataset
Target data

Figure 2: An invitation to join this project used in the interim presentation

Figure 3: An instruction for collecting target speaker data
In this internship program, we collected two datasets from PFN members. The first dataset is a 4-speaker dataset recorded in “Banana” room in PFN (we call this dataset PFN-banana). Banana is a meeting room for up to 10 people. The recording environment was clean, i.e., without noise. The other dataset is a 14-speaker dataset recorded in PFN’s cafe (we call this dataset PFN-Cafe), which is a large room that can be used to hold a party for more than 100 people. Since we recorded the data during the interim poster presentation for PFN-Cafe, there were many people speaking (e.g., other presenters were presenting their work next to my poster). As a result, the collected data were quite noisy. Furthermore, because I was worried that data could be too noisy, I asked the speakers to speak loudly and found that it was too loud and the record was clipped (audio clipping is a type of waveform distortion).

Figure 4: Audio clipping issue in PFN-Cafe dataset
We also exclude one folder of LibriSpeech (test-other) as target data with 33 speakers.
Method
Data preprocessing
We used 16,000 Hz as a sampling rate. An audio file is trimmed to start from speech information. Then we extracted a log filterbank feature (n_filter = 24) from given speech. Next, we stacked 5 adjacent filterbank features together (n_dim=n_filter x 5 = 120). Note that we are using variable-length data (each speech input data do not need to have the same dimension). For one speech input, we order these stacked filterbank features up to 80 stacked filterbank features for each input. As a result, the possible dimensions of inputs are from (1,120) to (80, 120). This preprocessing idea is quite similar to the preprocessing of X-vector but not exactly the same (see [7] for more information), because we found our preprocessing scheme empirically works better in our experiment.
The model choice for training a feature extractor
We used a very simple LSTM for our experiment. We used Chainer [8] to implement all methods. We used LSTM (chainer.links.NStepLSTM) as our model. We used 10% dropout [13] for regularization. For the optimization algorithm, we used AdamW [14] with 1e-4 as a weight decay rate. One may try a more complicated model to get better performance. We also implemented X-vector [7], but found that it takes a long time to run and we couldn’t do many trial-and-error. d-vector [9] is another choice but it cannot support the variable-length data. i-vector [10] is also another alternative to deal with speaker identification, which is well-known and highly-used before the popularity of deep neural networks. Although we used a relatively small network (one-layer LSTM) that can be trained in such a short time (within a day using 1 GPU), we still obtained a good performance on the source data. Table 5 shows the performance on source unseen data (but seen 2451 speakers).
Simple yet the best method in my experiment
We have attempted several methods but we found that this highly simple approach achieves the best performance and we used it in our demo for the final poster presentation.
- Using source data: learn a neural network to classify source data effectively using cross-entropy loss
- Remove the final linear layer and the last softmax layer and use the remaining network as a feature extractor
- For dealing with the open-set scenario, we simply used unseen LibriSpeech data (test-other folder) as a background class.
- Learn a new linear layer and a softmax layer on target data and a background class data
(Optional) for 4, we may also fine-tune the feature extractor for our target speakers, however, we have to be careful to avoid overfitting since we have very few target data. We also did a fine-tune with a few epochs and we observed a small improvement.
One interesting but still explainable thing is we found that using one-layer LSTM and 200 number of units, the performance is the best in our experiments. Although the performance on the source is not as good as when using two-layer LSTM with the same number of units, In a preliminary experiment, we found the best model in the source suffers from overfitting in the few-shot setting. Figure 6 shows the difference in the performance of one-layer LSTM and two-layer LSTM with the same number of units (200). One-layer LSTM outperformed two-layer LSTM in the few-shot learning scenario although two-layer LSTM is better when evaluating on the source (see Table 5 for the performance on the source data). Note that this method discards the final linear layer and the last softmax layer after finishing training the source domain. In our opinion, it is interesting to explore the possibility to incorporate this information to improve the performance of few-shot learning for future work.
Table 5: We can achieve 99 percent test accuracy on 2451-speaker classification (unseen test points, but seen 2451-speaker) for LibriSpeech dataset using our preprocessing method and simply ran it with cross-entropy loss (200 epochs).
| LSTM layers | Number of units | Test accuracy on source data with 2451 classes (%) |
| 1 | 50 | 84.60 |
| 1 | 100 | 96.23 |
| 1 | 200 | 97.75 |
| 2 | 100 | 97.1 |
| 2 | 200 | 99.04 |
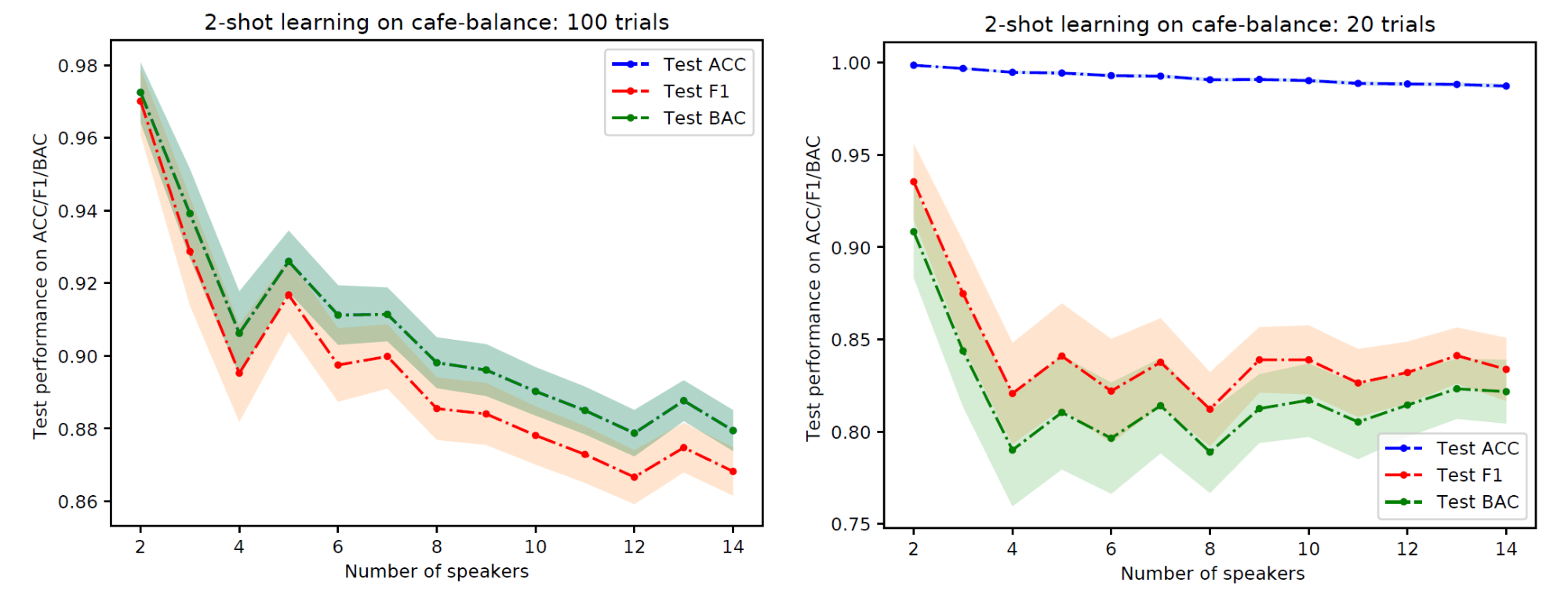
Figure 6: Performance of 2-shot learning on PFN-Cafe without open-set scenario as the number of target speakers increases. Left: one-layer, 200 number of units LSTM. Right: two-layer, 200 number of units LSTM.
Related work
Baseline++
In the paper: A closer look at Few-shot learning [11] proposed a simple method that can perform well in their experiment (Baseline++), which is based on cosine-similarity. However, we found that this method did not work well when the number of pre-trained classes is large (2451 in our case). We found that the implementation of this method is not that straightforward and the author introduced the scale factor, which needs to be adjusted appropriately depending on the task (see the code from the original paper). We also tried to adjust this scale factor and improve the performance but it still did not work well when we have 1000+ of classes (2451 in our case).
Prototypical network
We also tried a famous prototypical network [12] for our problem. However, it did not work well in our preliminary experiments and it is not straightforward to extend a prototypical network to support the open-set classification. It is one interesting research direction to make this happens.
Results
We presented our results on three datasets. First, the benchmark dataset (LibriSpeech). Second, PFN-Banana datasets, which are speech recorded without noise from four PFN members. Third, PFN-Cafe, which are speech recorded in the café during the interim presentation. Figure 7 shows an overview of how we evaluate the result.
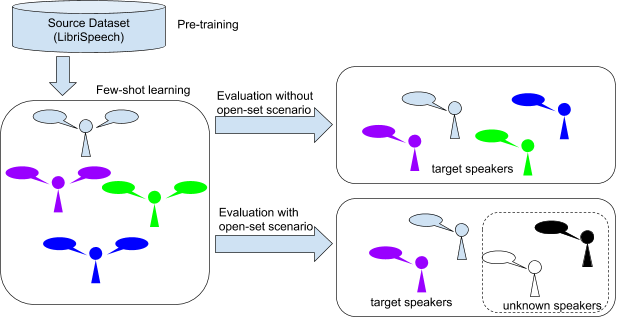
Figure 7: An overview of the evaluation procedure.
Result on few-shot learning in LibriSpeech
We exclude the test-other folder from the pre-training set (source) and because we will use it for evaluating the performance of the few-shot learning. Note that target speakers are not given in the source data. Experiments show that we can achieve over 99% ACC/F1/BAC for 10-shot learning with 33 target speakers.
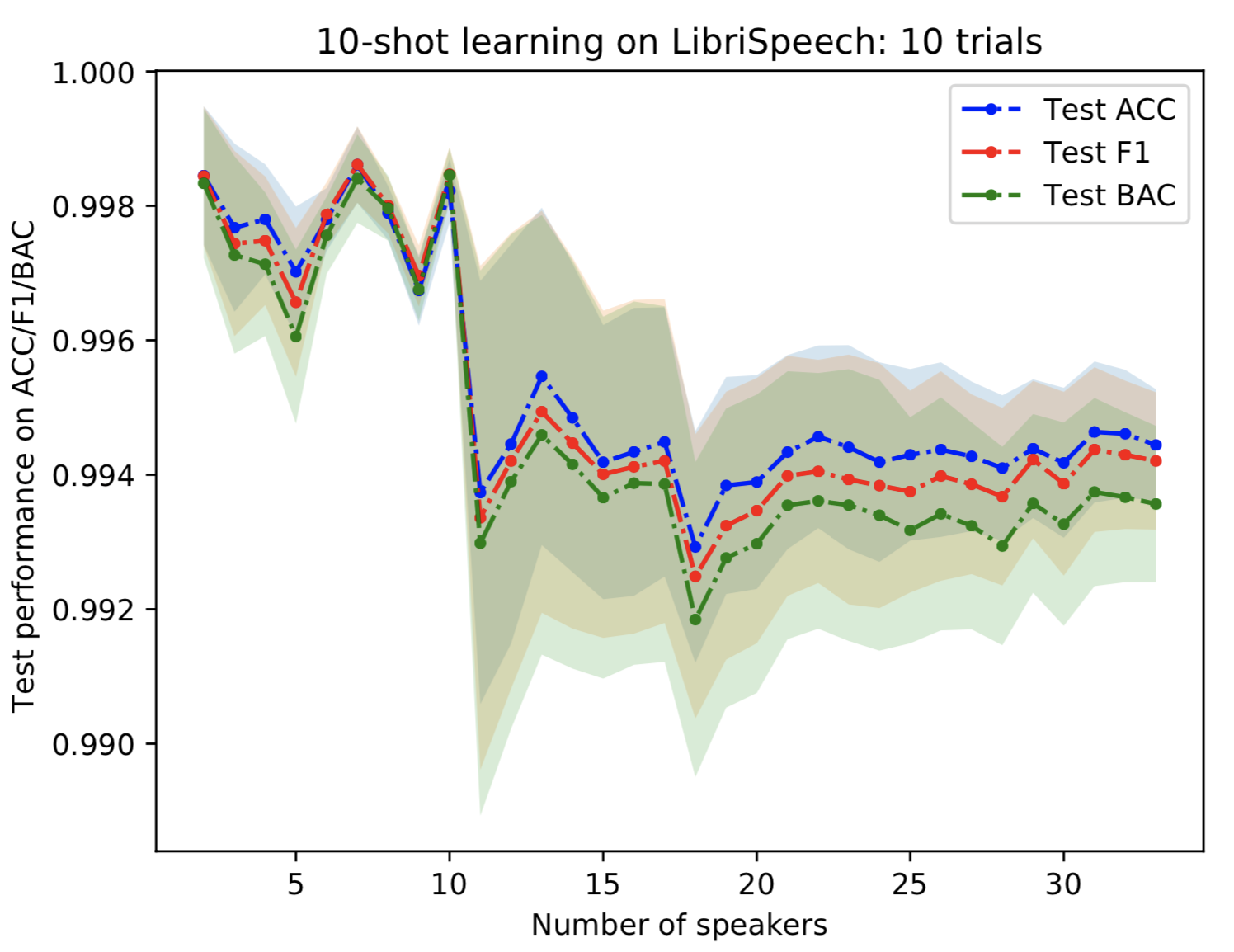
Figure 8: Performance of 10-shot learning on LibriSpeech without open-set scenario as the number of target speakers increases.
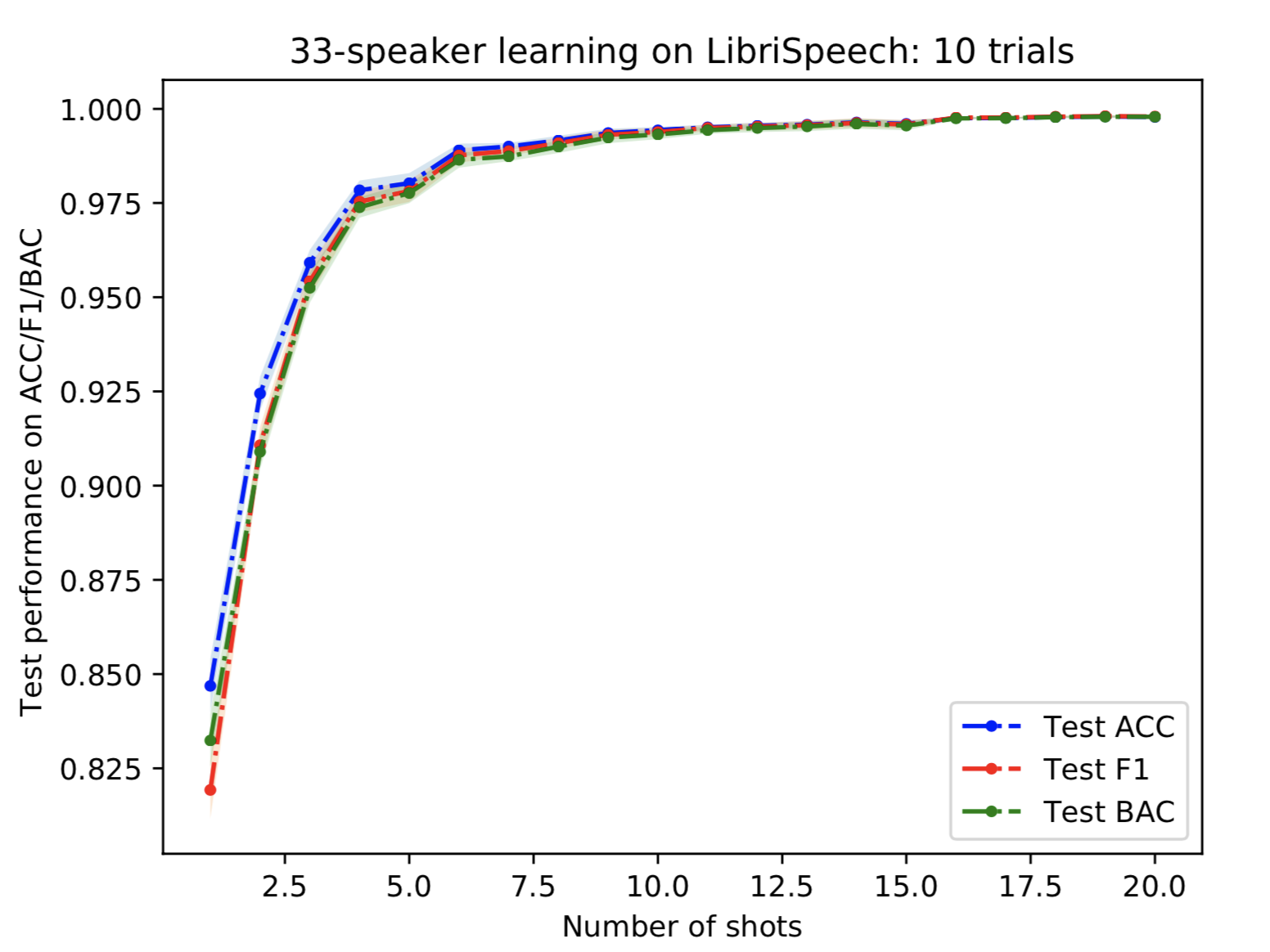
Figure 9: Performance of 33-speaker learning on LibriSpeech without open-set scenario as the number of shots increases.
Although we have never observed 33 speakers before in the pre-training phase. We can obtain highly accurate predictions in the few-shot learning scenario. This suggests that our simple pre-training method can extract useful information to identify a speaker identity to some extent. However, one may argue that it is still the same dataset collected under similar environments, and it may not work when we use a different dataset. Motivated by this argument, we collect real-world data and test it on completely different environments (PFN-Banana, PFN-Cafe).
PFN-Banana
Figure 10 shows the performance of our method for PFN-Banana dataset. For the closed-set scenario (the scenario without open-set scenario), we can achieve over 90 percent for this dataset. For the open-set scenario, the performance dropped (around 6-7%). It is not surprising that accuracy is very high in the open-set scenario because we add a lot of open-set data in the test phase, which caused the data to be highly imbalanced between in-distribution and out-distribution data.
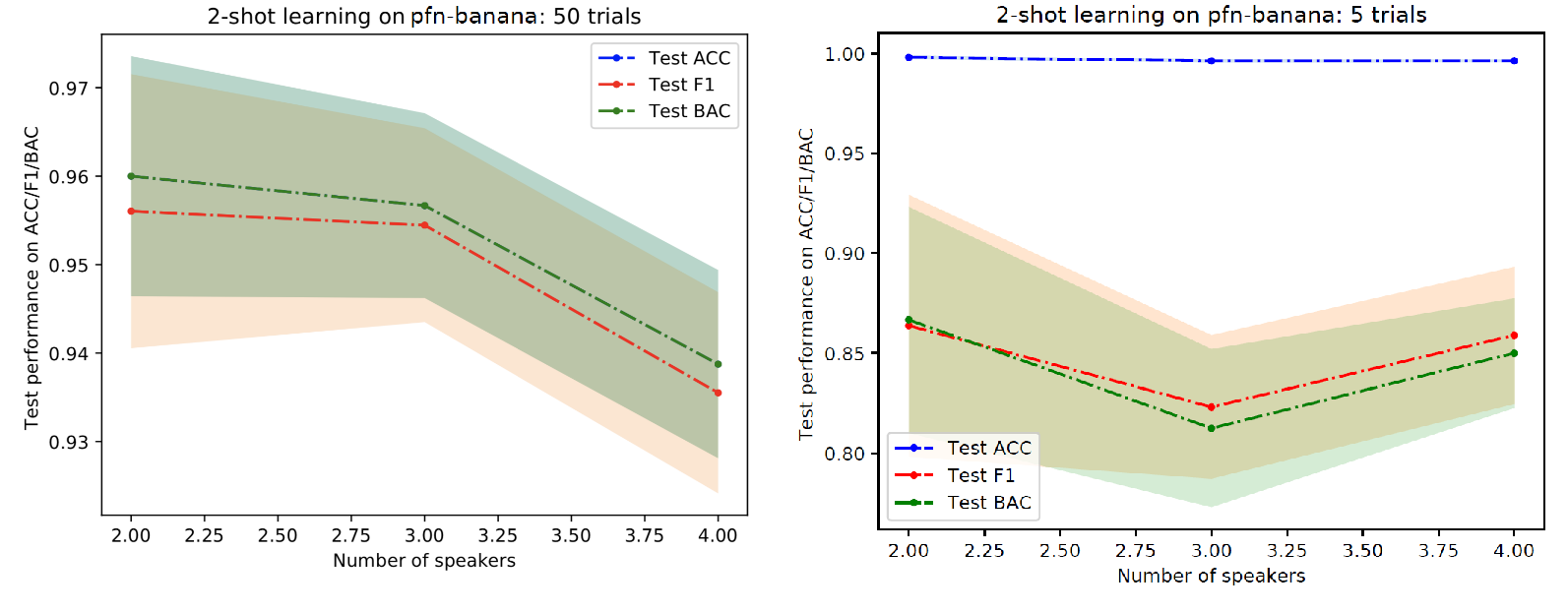
Figure 10: Performance of 2-shot learning on PFN-Banana as the number of target speakers increases. Left: Closed-set scenario. Right: Open-set scenario.
PFN-Cafe
We report the performance on PFN-Cafe dataset, which we conducted similarly to our experiment on PFN-Banana dataset, in Figure 10. Although the data is quite noisy and the audio amplitude is clipped, our method still performed reasonably well on PFN-Cafe dataset.
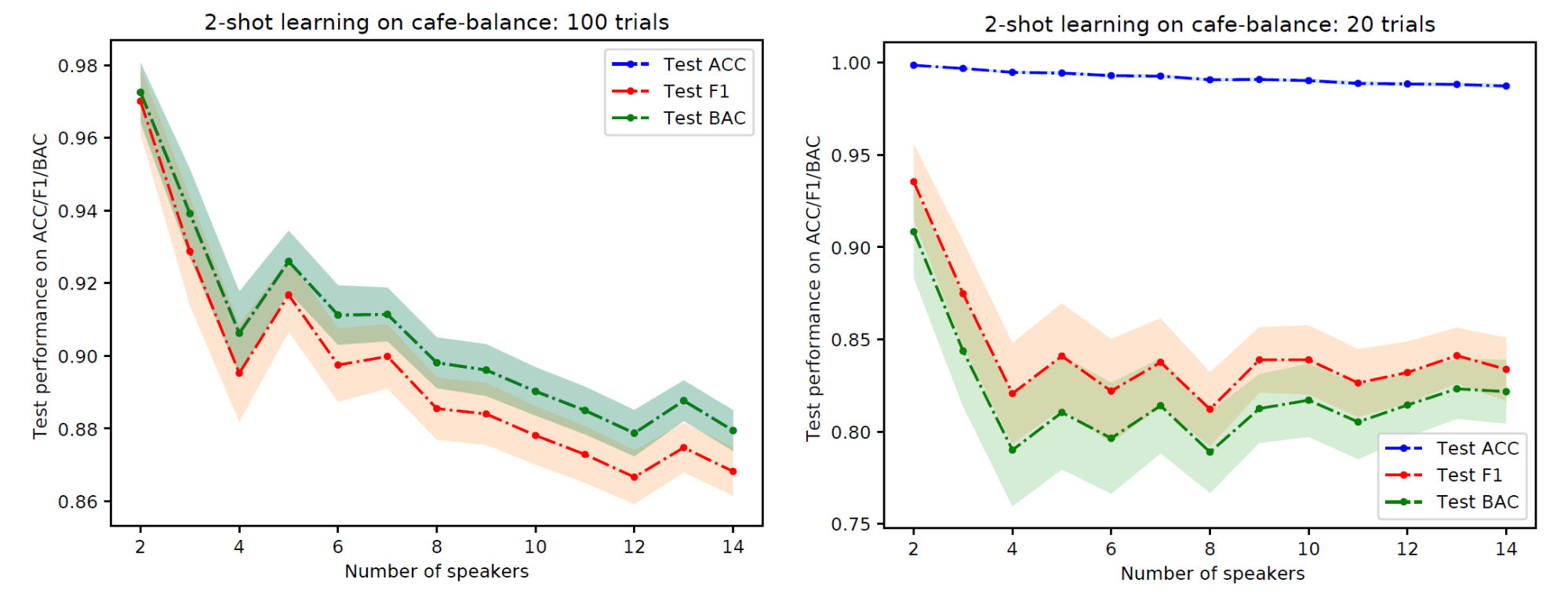
Figure 11: Performance of 2-shot learning on PFN-Cafe as the number of target speakers increases. Left: Closed-set scenario. Right: Open-set scenario.
Demo (final presentation):
The final presentation was done in the room “Forest”, which we have never collected the data in this room. Nevertheless, our simple method can classify reasonably well. Unfortunately, we did not record the exact performance of our method on the day. We found that it can classify many target speakers very accurately. But at the same time, there was one target speaker that our classifier almost always failed to recognize. Our method could detect unknown speakers pretty well although there were also a few misclassifications to target speakers. We also found that the first prediction result users see really affects the first impression towards our application, which is reasonable and developers should keep this in mind.

Figure 12: An invitation to test our system in the final lightning talk

Figure 13: Testing a demo (Yuya Unno (left), Nontawat Charoenphakdee (right))
Discussion
It is important to know the limitation of this technology. For example, if a target speaker is sick and his/her voice sounds different from usual, can the system still detect that person accurately? Is there a good and cheap data augmentation method to alleviate this problem because it is impractical to record one’s voice in every condition? Moreover, in practice, we may incorporate visual information to handle this problem. But sometimes only visual information is insufficient since we may not see everything in the range. For example, we may not be able to see something behind us or there might be something that blocks our vision. In such a case, the hearing will be very helpful.
Acknowledgment
My mentors are Yuta Tsuboi (main) and Katsuhiko Ishiguro (sub). I received tremendous support from them. Also, I would like to thank Toru Taniguchi for teaching me a lot especially during the first week: from preprocessing the speech data to introducing several interesting state-of-the-art papers in the field of speech processing. Moreover, I would like to thank Takashi Masuko, who actively attended my weekly meeting and gave me useful comments. Finally, I would like to thank people from Human-robot interface team, Intelligent information processing team, and everyone who provided data for this project.
References
[1] Fong, T., Nourbakhsh, I., & Dautenhahn, K. (2003). A survey of socially interactive robots. Robotics and autonomous systems, 42(3-4), 143-166.
[2] Hoy, M. B. (2018). Alexa, Siri, Cortana, and more: an introduction to voice assistants. Medical reference services quarterly, 37(1), 81-88.
[3] Kepuska, V., & Bohouta, G. (2018). Next-generation of virtual personal assistants (microsoft cortana, apple siri, amazon alexa and google home). In 2018 IEEE 8th Annual Computing and Communication Workshop and Conference (CCWC) (pp. 99-103). IEEE.
[4] Hatori, J., Kikuchi, Y., Kobayashi, S., Takahashi, K., Tsuboi, Y., Unno, Y., Ko, W. & Tan, J. (2018). Interactively picking real-world objects with unconstrained spoken language instructions. In 2018 IEEE International Conference on Robotics and Automation (ICRA) (pp. 3774-3781). IEEE.
[5] Hossin, M., & Sulaiman, M. N. (2015). A review on evaluation metrics for data classification evaluations. International Journal of Data Mining & Knowledge Management Process, 5(2), 1.
[6] Panayotov, V., Chen, G., Povey, D., & Khudanpur, S. (2015). Librispeech: an ASR corpus based on public domain audio books. In 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 5206-5210). IEEE.
[7] Snyder, D., Garcia-Romero, D., Sell, G., Povey, D., & Khudanpur, S. (2018). X-vectors: Robust dnn embeddings for speaker recognition. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 5329-5333). IEEE.
[8] Tokui, S., Okuta, R., Akiba, T., Niitani, Y., Ogawa, T., Saito, S., Suzuki, S., Uenishi, K., Vogel, B. & Yamazaki Vincent, H. (2019). Chainer: A deep learning framework for accelerating the research cycle. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (SIGKDD) (pp. 2002-2011). ACM.
[9] Variani, E., Lei, X., McDermott, E., Moreno, I. L., & Gonzalez-Dominguez, J. (2014). Deep neural networks for small footprint text-dependent speaker verification. In 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 4052-4056). IEEE.
[10] Dehak, N., Kenny, P. J., Dehak, R., Dumouchel, P., & Ouellet, P. (2010). Front-end factor analysis for speaker verification. IEEE Transactions on Audio, Speech, and Language Processing, 19(4), 788-798.
[11] Chen, W. Y., Liu , Y. C., Kira, Z., Wang, Y. C. F. & Huang, J. B. (2019). A Closer Look at Few-shot Classification. In Proceedings of International Conference on Learning Representations (ICLR).
[12] Snell, J., Swersky, K., & Zemel, R. (2017). Prototypical networks for few-shot learning. In Advances in Neural Information Processing Systems (NeurIPS) (pp. 4077-4087).
[13] Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research, 15(1), 1929-1958.
[14] Loshchilov, I., & Hutter, F. (2019). Decoupled weight decay regularization. In Proceedings of International Conference on Learning Representations (ICLR).
Area
