Blog
Preferred Networks (PFN) は、金融知識を強化した大規模言語モデル (LLM) である「PLaMo Fin Prime」をリリースしました。このモデルは、日本語能力の高いPLaMoをベースとして、金融に特化したコーパスを追加学習することで構築が行われており、日本語能力の高さと金融能力の高さを兼ね備えたドメインに特化したモデルとなっています。
また、今回の開発ノウハウを生かして、個社独自のデータを用いた専用モデルを構築するサービスについても提供開始をしました。
今回の記事では、この詳細について紹介します。
LLM分野におけるPLaMo Fin Primeの位置づけ
PLaMoはPreferred Networksグループが開発している大規模言語モデル(LLM)です。
一般的なLLMの構築手法ではまず初めに、非常に多くの文書を学習させて文の続きを書くという能力を身につけた事前学習モデルを作成します。この事前学習の過程で、LLMは様々な知識を身につけます。そのうえで、ユーザーの質問にうまく回答したり、安全性を高めるような、事後学習(アライメント学習)を行うのが一般的です。
すでに公開されている、一般向けのPLaMo 1.0 Primeや2.0 Primeは、この事前学習を汎用コーパス(文書)で実施したのちに、汎用向けの事後学習を行ったモデルとなっています。
では、このモデルをドメインに特化させる、つまり、金融に特化させるとなった時に、どのような取り組みを行うべきかということについて考えてみます。
一般に、「金融に特化する」といったときに、最も重要になるのは金融知識ではないかと思います。
その場合、まずは知識を増強するところから始める必要があります。
知識を増強するとなると、前述の通り、事前学習の過程に戻る必要がでてきます。
そこで、我々は、金融分野に特化したコーパスを作成し、それを用いた追加学習を実施しました。
その結果としてできたモデルが、今年の1月に発表した、PLaMo Fin Base となります。
しかしながら、このPLaMo Fin Baseは、事後学習をおこなっていないモデルであり、安全性や指示追従性には改善の余地がありました。
そこで、事後学習をおこなったモデルが、PLaMo Fin Primeとなります。
なお、事後学習では、コンテクスト長が伸び、1万6千トークンまで入るようになりました。
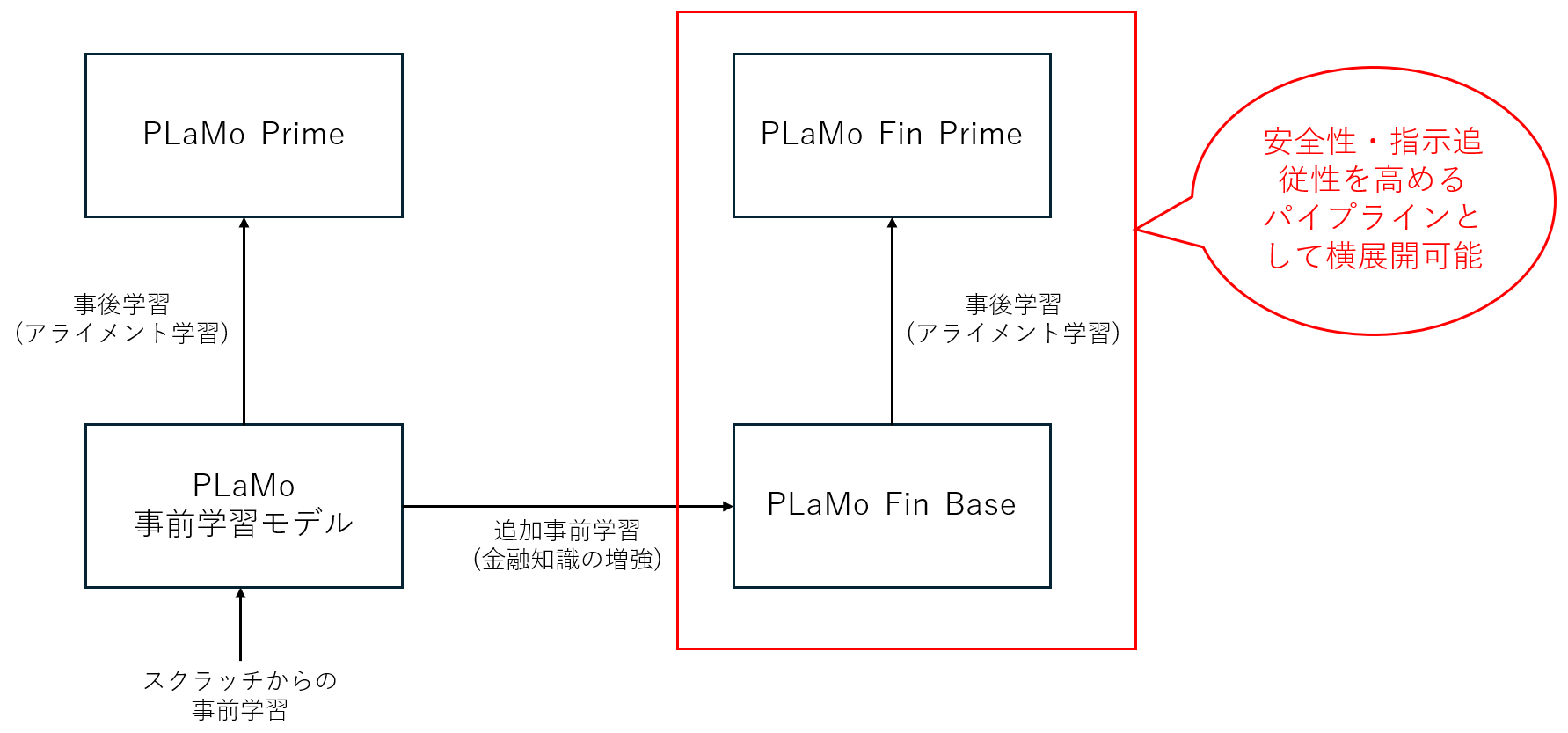
図: PLaMo Fin Primeまでのモデル構築手順と手法
これらの流れを図にすると、上記のようになります。今回、追加事前学習に組み合わせて利用できる事後学習パイプラインの構築に成功したため、このノウハウは、様々な追加事前学習と組み合わせて利用することができるようになります。これにより、金融以外の様々なドメインへの適用や、個社別のモデル構築など、LLMへの知識の追加と合わせて安全性・指示追従性を高めることが可能となります。
PLaMo Fin Primeの強み
すでにプレスリリースで公表している通り、PLaMo Fin Primeは、従来のPLaMo Primeや、PLaMo Fin Baseと比較して、高い金融の知識性能を発揮していることがわかります。OpenAI社のGPT-4oにはベンチマーク値でこそかなわないものの、特定のユースケースでは強みが出るほか、それ以外の場合でも匹敵する性能を発揮しています。また、金融に関連する応答性能についても、PLaMo Fin Baseと比較して高い性能を発揮しています。
| Overall | chabsa | cma_basics | cpa_audit | fp2 | security_sales_1 | |
| PLaMo 1.0 Fin Prime* | 62.4 | 93.0 | 65.8 | 35.9 | 52.2 | 64.9 |
| PLaMo 1.0 Fin Base* | 59.0 | 91.8 | 57.9 | 34.4 | 51.0 | 59.7 |
| PLaMo 1.0 Prime* | 53.9 | 88.9 | 52.6 | 23.1 | 41.7 | 63.2 |
| PLaMo 2.0 Prime (参考) | 56.2 | 91.7 | 63.2 | 31.7 | 40.0 | 54.4 |
| GPT-4o (参考) | 65.2 | 90.9 | 76.3 | 53.0 | 39.4 | 66.7 |
表1: Japanese Language Model Financial Evaluation Harnessによる計測
PFNで整備した、日本語かつ金融分野に特化したベンチマーク。金融分野における感情分析タスク(chabsa)、証券分析における基礎知識タスク(cma_basics)、公認会計士試験における監査に関するタスク(cpa_audit)、ファイナンシャルプランナー試験の選択肢問題のタスク(fp2)、証券外務員試験の模擬試験タスク(security_sales_1)の5つのベンチマークタスクで構成されています。参考: 言語モデル性能評価のための日本語金融ベンチマーク構築と 各モデルのパフォーマンス動向
*オンプレミス環境で尤度(もっともらしさ)に基づいた計測を実施
| Overall (明細は割愛) | |
| PLaMo 1.0 Fin Prime | 8.41 |
| PLaMo 1.0 Fin Base | 7.08 |
| PLaMo 1.0 Prime | 8.13 |
| PLaMo 2.0 Prime (参考) | 8.88 |
| GPT-4o (参考) | 8.99 |
表2: Preferred Multi-turn Benchmark for Finance in Japaneseによる計測
PFNで整備した、日本語かつ金融分野に特化した応答性能を見るベンチマーク。12種類のタスクからなる360件の対話データで構成されており、執筆、ロールプレイ、知識応答タスク、情報抽出、推論、数学、コーディング、アイデア生成、翻訳、倫理的判断、信頼性評価、およびESG関連タスクが含まれています。10段階評価の平均点としてベンチマーキングされます。このベンチマークにより、日本語による金融関連の対話におけるLLMの応答性能を評価することができます。参考:金融分野に特化した複数ターン日本語生成ベンチマークの構築
プレスリリースで示したベンチマークは、金融に関する一般的な知識や特定のタスクに関する質問応答の性能を問うものであり、実際の日本企業の間の関係や事業内容に関する知識を問うものではないです。そのため、使い方によっては、PLaMo Fin Primeの強みが生きる場合もあります。
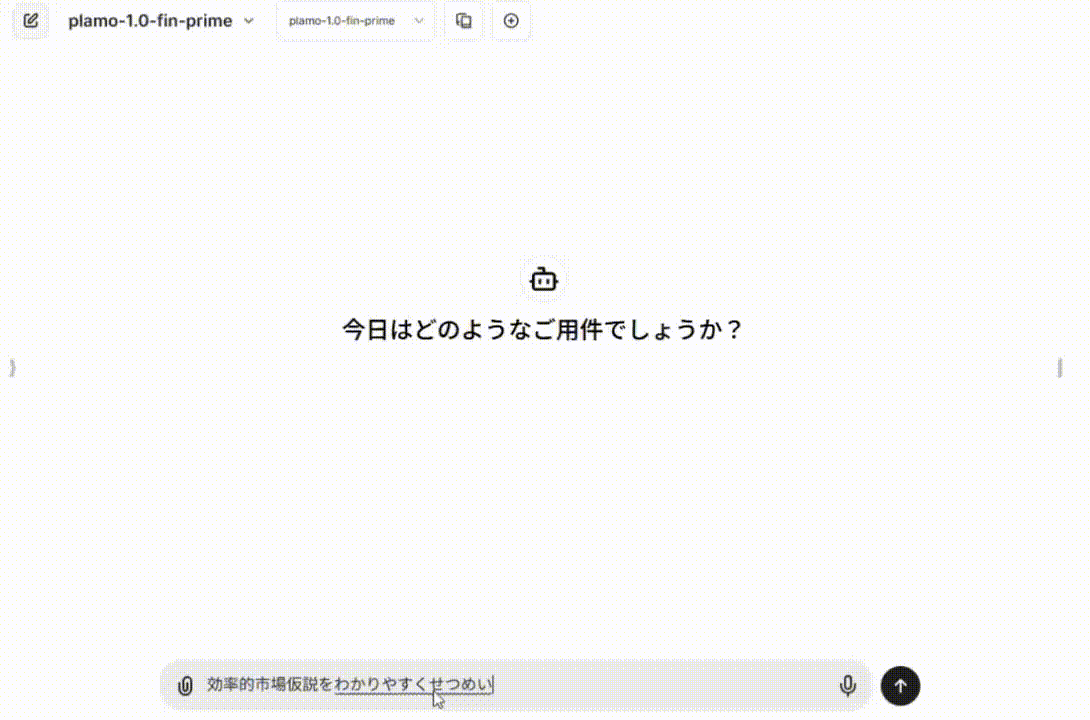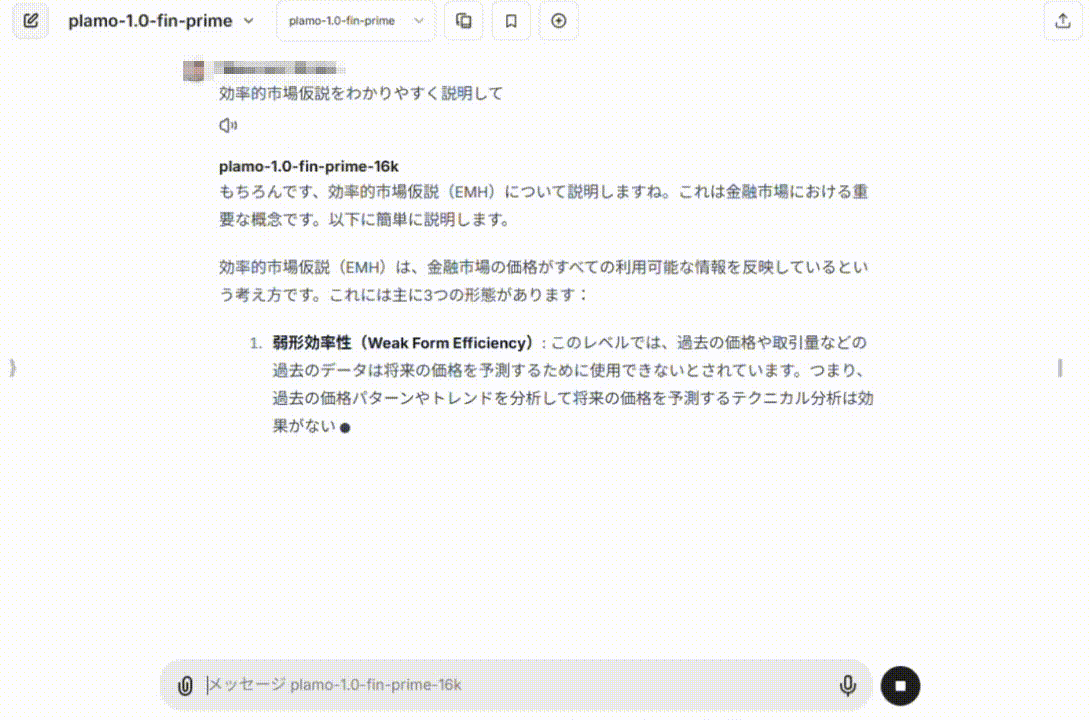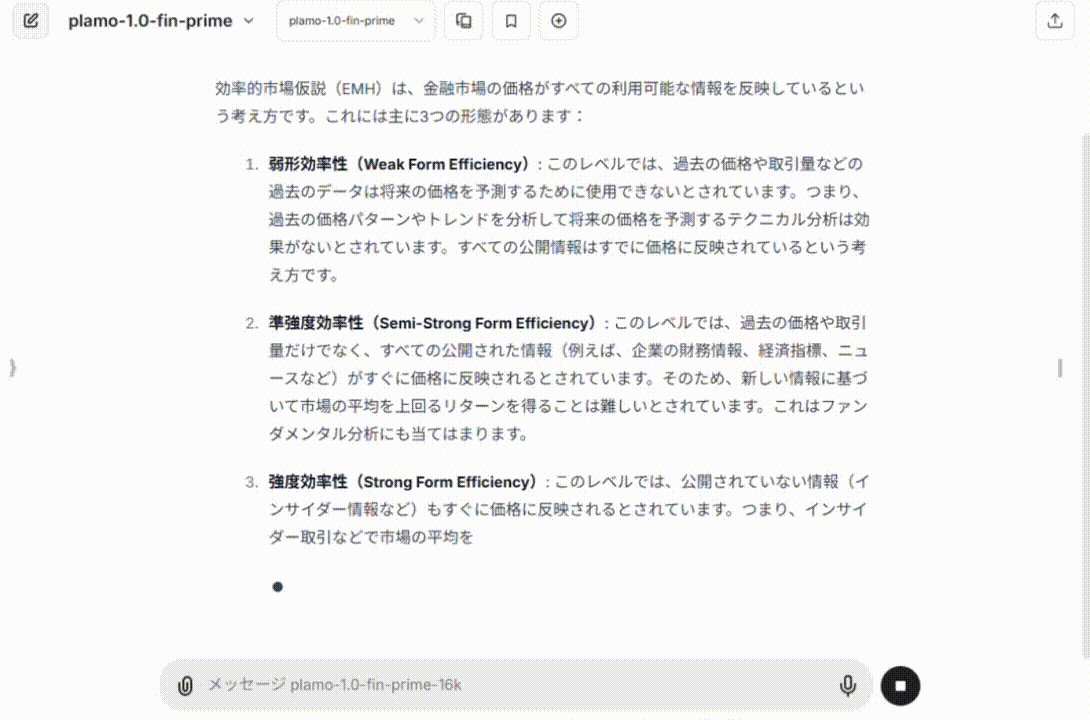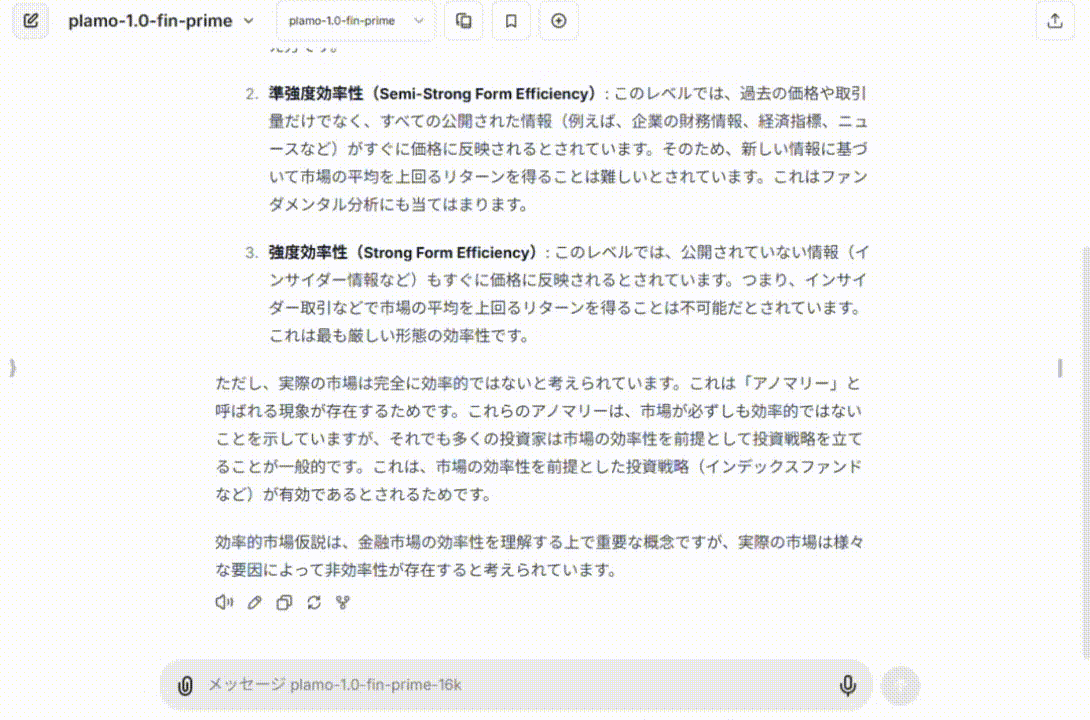
例えば、日本企業の事業や個社名については良く知っているため、そういった回答が想定される質問においては強みを発揮する場合もあります。GPT-4oなどのモデルだと、上場銘柄を聞いていても、上場していない大企業をあげてしまうなど、うまく答えられない一方で、PLaMo Fin Primeが良くこたえられるといったケースがあります。こういった実際の知識に関してはベンチマークでは評価されていないところであり、我々はPLaMo Fin Primeが実務上有用なものとなると判断し、リリースをきめました。

※具体的な銘柄及び銘柄コードはモザイクしていますが、実際の出力ではご覧いただけます。乱数シード等により、同じ出力が出ない場合もあります。
また、「ベータ」の様に、汎用語であるものの、金融の文脈においては特定の意味を持つワードに関しては、その点を考慮して回答することが可能です。

このように、特定のユースケースにおいては、金融の知識を増強させた成果が強く染み出る結果が出てきています。
実際に、このような感じでデモが動いています(1倍速)。
技術的に何が難しかったのか?
さて、ここで、もう少し技術的な観点についても触れておきたいと思います。
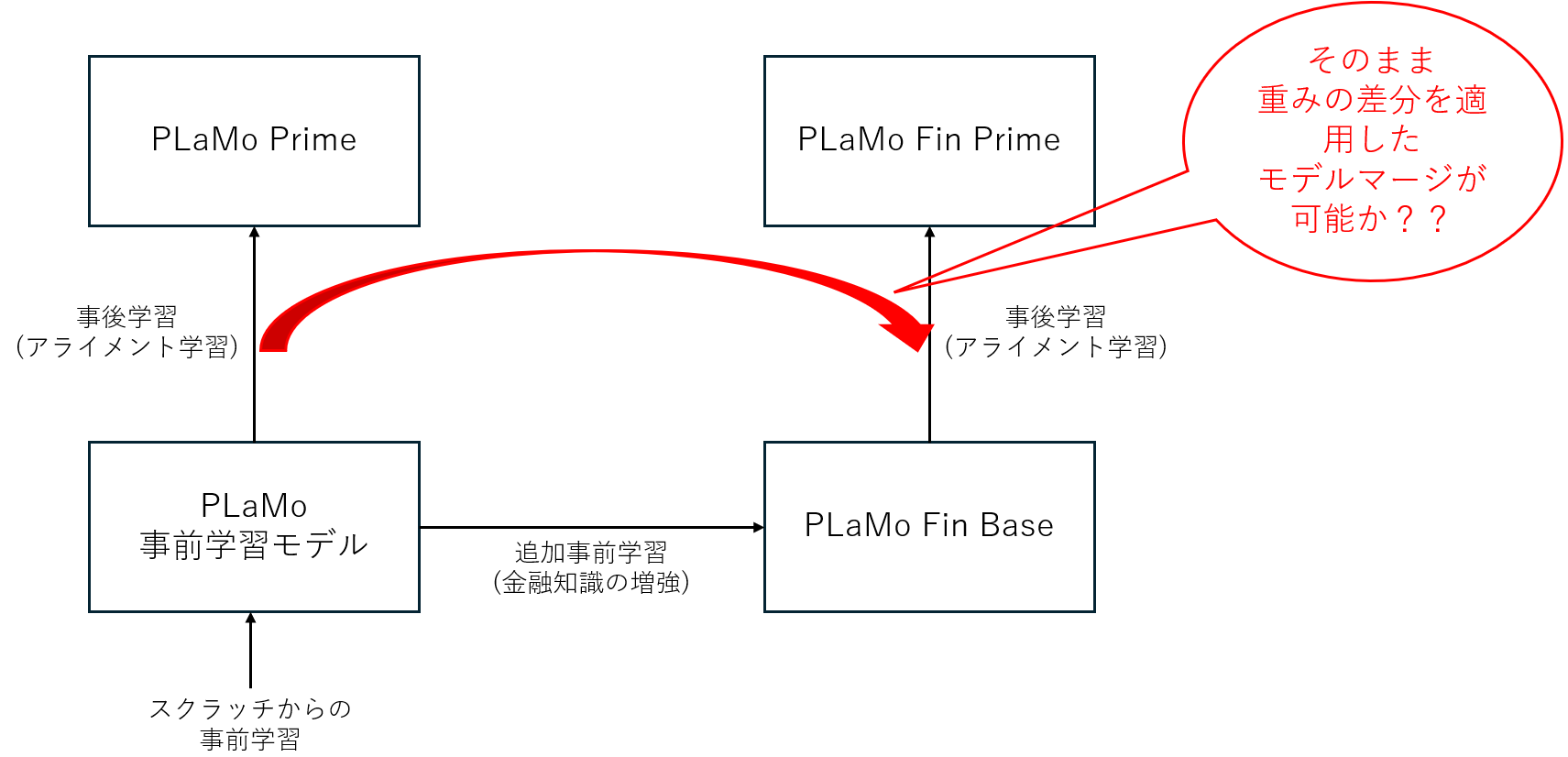
追加事前学習後の事後学習を考えた時に、事後学習の差分が同じであれば、モデルの重みの差分をそのまま適用する「モデルマージ」ができる可能性があります。
実際、弊社が2024/4に公開しているオープンなモデルにおいては、このモデルマージを適用することでアライメント対応させた実績があります。
しかしながら、このモデルマージによる手法には限界もあります。今回もモデルマージの適用は試みたうえで、一定のレベルで機能することは確認できたものの、モデルの挙動の不安定性も確認できたため、モデルマージを採用しないという結論を出しました。
弊社の事後学習では複数の目的を持った複数のステップからなる事後学習方策を採用しています。ここで重要になるのはLong-context対応です。
現在のLLMは標準的には4k contextで学習をおこないます。PLaMoの事前学習も同様に4k contextで学習がおこなわれています。
しかしながら、実務的なシーンにおいては4kでは足りず、16k以上のコンテクスト対応をおこなうプロセスをどこかではさむ必要があります。(5月に発表したPLaMo 2.0 Primeでは32kまで対応しています。)
このコンテクスト長対応を追加事前学習の前にはさむのか後にはさむのかは議論の余地があります。
今回、追加事前学習で使用しているコーパスは、4kを超えるような長い文章の量には限界があり、ロングコンテクスト対応は追加事前学習の後におこなう必要がありました。
そのため、挙動の不安定性に加え、ロングコンテクスト対応は、モデルマージで対応することは困難と考えたため、モデルマージの適用を見送ることとしました。
追加事前学習後の事後学習の課題は他にもありました。
事後学習において、金融に特化したコーパスを用意しなければならないのか、という問題があります。
この点に関しては、今回は金融に特化したコーパスを用意しないという方針で取り組みました。
事後学習用のデータセットを構築することは非常にコストがかかるため、様々な分野で特化モデルを作るためには、事後学習での特化コーパスを用意しないで済む技術が必用であると考えました。
詳細については割愛しますが、一般的な事後学習の手法であっても、適切にパラメータ設定をおこなうことで、追加事前学習時に習得した能力を失うことなく、アライメントができるということがわかりました。
追加事前学習後に事後学習をおこなう場合、追加事前学習の内容に対応する事後学習用コーパスを構築したほうが良い性能を発揮するかどうかについては、学術的にはまだ答えが出ていないと認識をしていますし、今回の取り組みでもアブレーションをしたわけではないので答えをだすことはできていません。
しかしながら、PLaMo Fin Primeは、PLaMo Fin Baseと同等の金融知識性能を持っていることがベンチマークから明らかになったため、少なくとも性能劣化は防ぐことができているのではないかと言えます。
金融特化モデル・ドメイン特化モデルのこれから
今回、ドメイン特化モデルのリリースを初めておこなうことができました。国内で見ても非常に特殊な事例ではないかと考えています。
性能面ではまだグローバルなモデルを追い越すことができるところまでは少しありますが、今後、PLaMo 2や後続のモデルをベースにさらなる特化モデルを構築していくことで、特定のドメイン領域においてはグローバルなモデルを追い越す性能を発揮できる可能性は十分にあると思います。
また、今回の技術は、個社モデルなどの特殊なニーズに答えることができる技術となっており、今後の日本でのLLMの活用のスタート地点にできるのではないかと考えています。
今後、様々な取り組みを拡大していければと考えています。
仲間募集中
PFNでは、今後も積極的にLLMの開発を継続していきます。今回紹介したドメイン特化型LLMだけでなく、様々な課題に取り組んでいますので、ビジネスを一緒に進めていく会社の方、PFNで一緒に挑戦していく仲間を募集しています。
ぜひ、お問い合わせいただけますと幸いです。
企業向けお問い合わせ:https://www.preferred.jp/ja/contact/
キャリアサイト:https://www.preferred.jp/ja/careers/
(new!) PFN金融チームご紹介:https://speakerdeck.com/pfn/qfin
Area



