Blog
本記事は、2024年夏季インターンシッププログラムで勤務された佐藤 蒼馬さんの寄稿です。
はじめに
2024年度夏季インターンシップに参加した名古屋大学大学院情報学研究科の佐藤 蒼馬と申します。今回のインターンシップでは、「1-token predictionを用いたFinewebのアノテーション」に取り組みました。
背景
大規模言語モデルの性能は、事前学習データセットの品質とサイズに強く依存し、様々な方法で品質を高める試みが行われています。
1つの例としては教育的価値が注目されており、「Textbooks Are All You Need」ではコードデータセットの教育的価値をLLMで評価し、より少ない学習トークン数で性能の高いコード特化モデルを構築しています。また、 Fineweb-eduでは汎用ウェブデータから構築したテキストデータセットから教育的価値の高いデータをLLMを使って評価・抽出し、複雑タスクであるMMLUのスコア向上に貢献しています。
LLMを駆使した指標分類は高品質データセットの構築に大きく貢献すると期待されますが、LLMによる評価プロンプトの作成とアノテーションしたデータを用いた分類モデルの開発が必要です。加えて、実装したデータセットを組み込んだLLMの学習と評価も含むと、1回の試行に必要なターンアラウンドタイムが非常に長くなります。
以上のことから、高品質データセット開発の試行時間短縮は、高性能LLMの開発において大きな壁と言えそうです。
他方、PFNでは大量の分類タスクを既存LLMで高速に処理する技術として1-token predicion/Preference APIを開発しています。
指標の作成を1つの分類タスクとみなすことで、エンジニアによる作業を要する時間を短縮し、高品質データセットをより短い期間で作れるのではないかと期待しています。
目的
本研究では、高品質データセットの試行時間を短縮するため、アノテーションデータセットとモデル構築を1-token prediction/Preference APIで代替可能か検証します。
オープンデータセットであるFineweb-eduの再現実験を行い、元データセットのFinewebに対し1-token prediction/Preference APIで教育的価値を元のアノテーションモデルと同等の採点が可能か評価します。
これにより、事前学習データのアノテーション効率を向上させるとともに、1-token prediction/Preference APIの幅広い応用可能性を検証します。
Fineweb / Fineweb-edu
Finewebは104の CommonCrawl スナップショット(1スナップショットあたり60~90TiB)から構成された、15兆トークン (44TB) の大規模データセットで、他のオープンな事前学習データセットよりも優れたパフォーマンスのLLMを構築可能と説明しています。
Fineweb-eduは先述の通り、Finewebデータセットについて教育的価値を評価し、スコアが高いものについて取り出したサブセットです。図1にFineweb-eduサブセット構築のワークフローを示します。
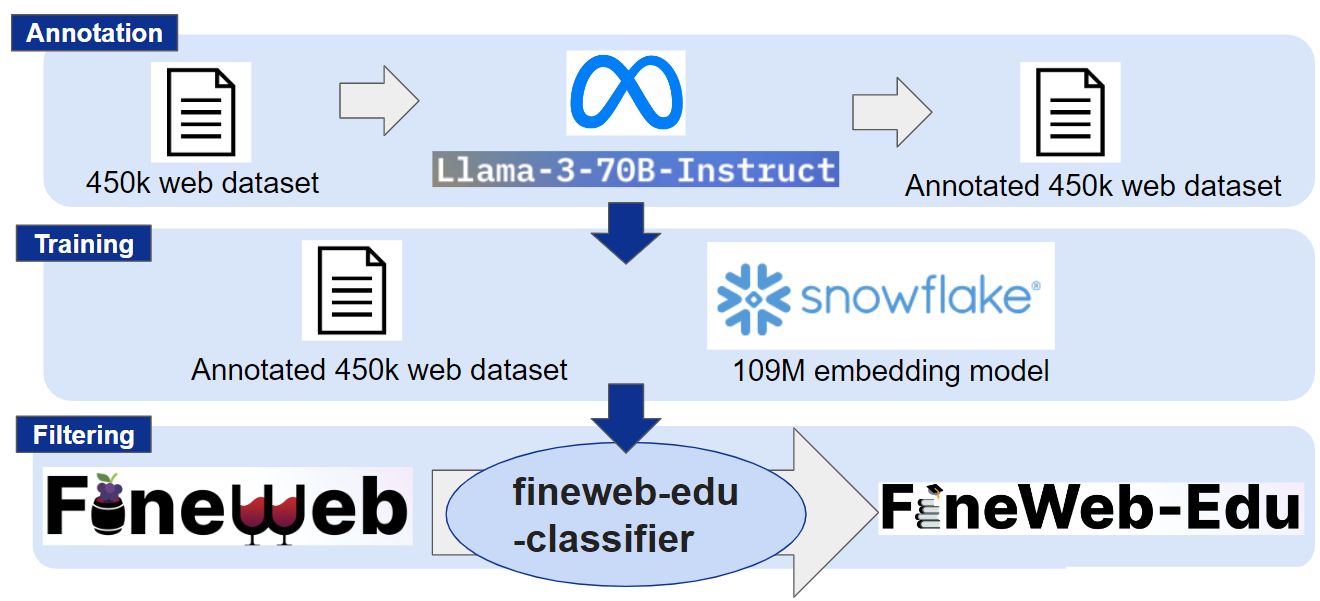
図1 Fineweb-eduの生成ワークフロー
Fineweb-eduはLlama-3-70B-Instructによって教育的な価値の観点からスコアリングされた450kのWebデータセットを用いて埋め込みモデルを学習させます。学習した埋め込みモデルを分類器として教育的価値を5段階のスコアに分類、スコアが3以上であるか否かのフィルタリングを行います。
Fineweb-eduのように高品質なサブセットを用意することで、より効率的なLLMの学習が可能となります。
しかし、我々がFineweb-eduのワークフローを再現する場合、埋め込みモデルに学習させるデータの準備や、学習プロセス自体が煩雑であり、実行には多くの労力が必要です。
そのため1-token prediction/Preference APIで代替することで開発コスト、すなわち試行に必要な時間を削減できるのではないかと期待しています。
本研究では教育データのアノテーションを行っていますが、このアプローチはプログラミング言語や数式など、さまざまなドメインの事前学習データのアノテーション効率を向上させる可能性があります。
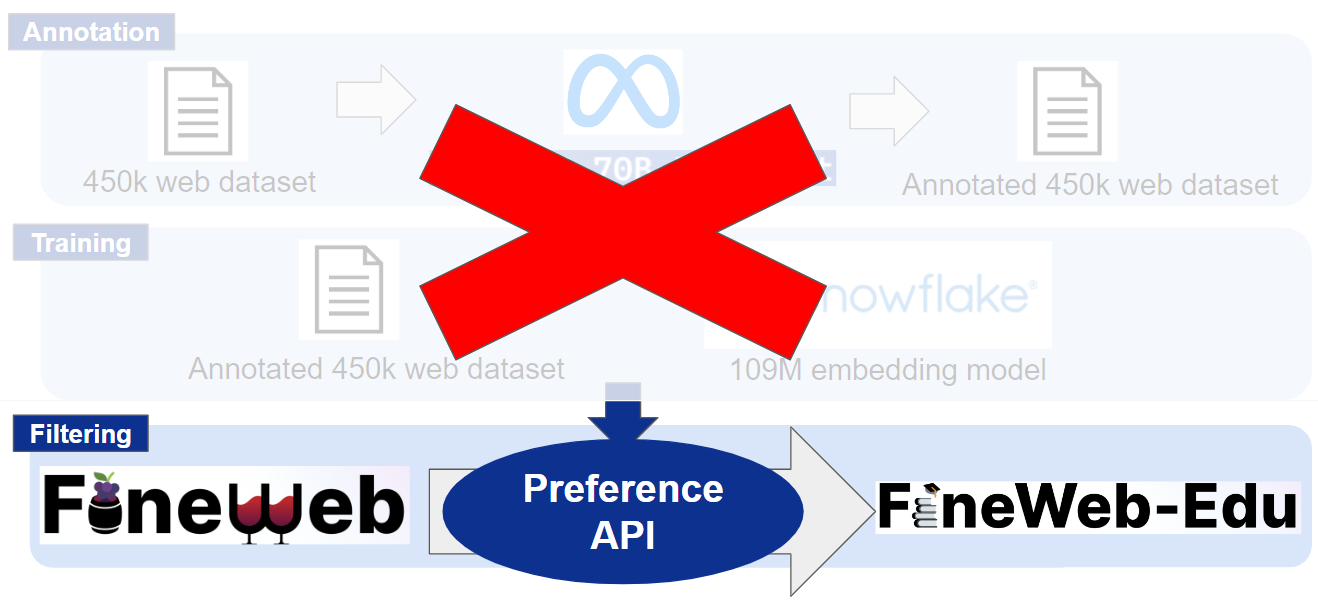
図2 1-token prediction (Preference API) によるアノテーション処理の代替
1-token prediction/Preference API
1-token prediction/Preference APIとは、PFNが開発したLLMを使った大量の分類タスクを簡単かつ高速に実行できる技術およびそのAPIです。分類するための選択肢を与えると分類結果としてそれぞれのlogitを返します。Preference APIで推論に使用するLLM(以下バックエンドモデル)は、セルフホスティングにより任意のモデルを利用できます。
今回の実験では、Swallow-70B-instruct-v0.1およびFineweb-eduのアノテーション処理で使用されているLlama3-70B-instructの2つをバックエンドモデルとします。
データの分析
Preference APIで100件のデータのアノテーションを行いました。Finewebの論文に記載されている指示文では分類に適していないので、以下のような指示文により分類を指示し、分類クラスとしてGrade A~F を定義しました。

図3 Finewebで利用されているプロンプトと本実験で用いたプロンプト
全体としては指示文、例文、入力を繋げたものを入力としました。マークダウン形式で記入し、GradeがA,C,Fであるものを例示しました。
また、Preference APIでlogitが最も高かったGradeをそのままスコアとして用いると、スコアが高めにつく傾向があるため、logitにsoftmax関数をかけて重み付け和を取り、その値に応じてスコアを決めました。
閾値3の混合行列
Preference APIとFineweb-eduでスコアが3以上であるか否かの混合行列を作りました。
バックエンドモデルがSwallow-70B-instructの場合のF値は0.26である一方、Llama3-70B-instructの場合のF値は0.42でした。
今回のデータは全て英語であるため、日本語に適用するよう追加学習されたSwallow-70B-instructよりも最新で英語のみ学習したLlama3-70B-instructのほうが、今回の実験においては優れていることが示唆されました。
この結果から、以降の実験ではLlama3-70B-instructをPreference APIのバックエンドモデルに用いました。
表1-1 Preference APIとFineweb-eduのスコア傾向 (Swallow-70B-instruct)
| Score 3 or above in Preference API | Score less than 3 on Preference API | |
| Score 3 or above on Fineweb-edu | 3 | 6 |
| Score less than 3 on Fineweb-edu | 11 | 80 |
(precision = 0.21, recall = 0.33, F measure = 0.26)
表1-2 Preference APIとFineweb-eduのスコア傾向 (Llama3-70B-instruct)
| Score 3 or above in Preference API | Score less than 3 on Preference API | |
| Score 3 or above on Fineweb-edu | 7 | 2 |
| Score less than 3 on Fineweb-edu | 17 | 74 |
(precision = 0.29, recall = 0.78, F measure = 0.42)
スコア差の頻度分布
下記の分布はPreference APIでアノテーションしたスコアからFineweb-eduのスコアを引いた値を表しています。
正の値が多いほどPreference APIが高くつける傾向にあるということなので、少しPreference APIがスコアを高くつけていることが分かりますが、0が一番多く概ねFineweb-eduと同様のスコアリングができていることが分かります。
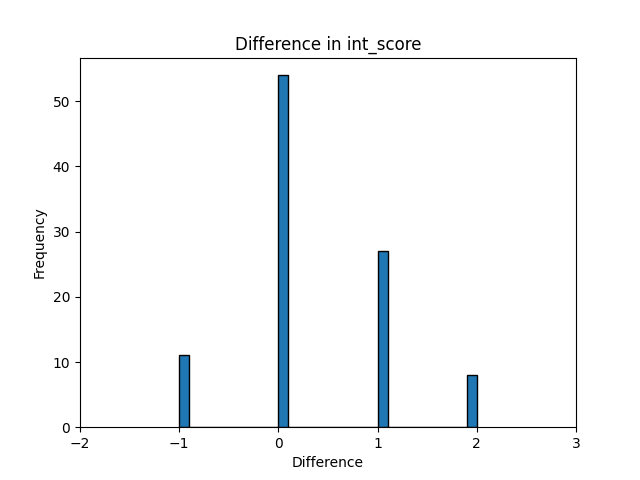
図4 Fineweb-eduとの差で正規化したPreference APIスコアの頻度分布
Grade Aのlogit
Grade Aのlogitが高い物を上から10,15,20件抽出して、スコアの平均を見ました。結果として、100件全体のデータのスコアの平均は1.38であるのに対して、上位10,15,20件の平均スコアはそれぞれ2.20, 2.00, 2.10となりました。
このことからAのlogitが高い物を上から抽出した場合でも教育的価値の高いデータを抽出できることが分かりました。
表2 抽出したGrade Aのlogit平均
| Data | Average int_score |
| Overall Data | 1.38 |
| Top 10 | 2.20 |
| Top 15 | 2.00 |
| Top 20 | 2.10 |
学習・評価
実験設定
データの分析で導出した重み付け和とlogitの高い事例上位10%を抽出したデータ(以降ではそれぞれweightとtop10と呼ぶ)とFinewebおよびFineweb-eduで学習したモデルの比較を行いました。
100Mパラメータのモデルでフィルタリングした最小のデータ数に合わせて71880事例で学習し、次に示す6つの常識推論タスクで評価を行いました。
評価タスク
ARC-Easy
- AI2(Allen Institute for AI)が提案した自然言語理解(NLU)タスクの一部で、比較的簡単な科学問題に焦点を当てています。このデータセットは、標準的な4択の選択問題形式で構成されており、小中学校の科学カリキュラムに基づいています。
- 例題「水の氷点は何度ですか?」
- 0度
- 100度
- -18度
- 50度
ARC-Challenge
- AI2が提供するタスクで、ARC-Easyよりも難しい科学問題を含んでいます。これらの問題は、より高度な理解と推論を必要とし、従来のモデルでは高い性能を達成しにくいものです。
- 例題「地球の核は主に次のどの物質で構成されているか?」
- 玄武岩
- 鉄
- マグマ
- クオーツ
OpenBookQA
- AI2がリリースした別のNLPタスクで、開かれた形式の科学問題に基づいています。このデータセットは、学生が持っている基礎的な知識を使って質問に答える能力をテストします。
- 例題「植物が太陽の光を利用してエネルギーを作り出すプロセスは何と呼ばれていますか?」
- 光合成
- 細胞分裂
- 発酵
- 呼吸
Winogrande
- Winograd Schema Challengeをベースに、人間の常識的な推論(commonsense reasoning)をテストするために設計された大規模データセットです。当初のWinograd Schemaの形式を拡張し、モデルが複数の選択肢から適切な文を選ぶ能力を評価します。
- 例題「テーブルの上にプレートがあり、ケーキがその上にある。プレートは何の上にありますか?」
- ケーキ
- テーブル
PIQA
- 日常生活に関する物理的推論を含む問題に焦点を当てたデータセットです。このタスクは、物理的な直感や日常的な知識を必要とし、モデルが現実世界での物理法則や常識を理解しているかをテストします。
- 例題「テーブルの脚をしっかりと固定するためにはどのような工具が最適か?」
- ハンマー
- ドライバー
HellaSwag
- 自然言語生成と解釈を組み合わせた難易度の高いタスクで、テキストの次の文を予測するモデルの性能を評価します。このデータセットは、常識的な推論と物語理解を必要とします。
- 例題「彼女はギターを手に取り、曲を演奏し始めた。」
- 曲が終了するまで演奏を続けた。
- 突然ギターを地面に投げつけた。
- 部屋を出て行った。
- ギターを弾くのをやめてテレビを見た
表3 各ベンチマークの評価結果(Accurasy, high than better)
| Fineweb | Fineweb-edu | Annotate Fineweb (weight) | Annotate Fineweb (top10) | |
| ARC-Easy | 0.3058 | 0.3900 | 0.3598 | 0.3716 |
| OpenBookQA | 0.1453 | 0.1600 | 0.1767 | 0.1667 |
| PIQA | 0.5722 | 0.5792 | 0.5908 | 0.5876 |
| HellaSwag | 0.2734 | 0.2784 | 0.2802 | 0.2843 |
実験結果
結果は表3の通りです。ARC-ChallengeとWinograndeはどのデータセットで学習した場合もランダムな正答率だったため、省略しています。
今回のPromptは小中学生向けの教育的なテキストになっている程高得点であり、ARC-Easyが小中学生向けの平易な知識を問う四択問題であるので、ARC-Easyが高いと綺麗なフィルタリングが出来ていると考えられます。
ARC-Easyが一番高いのはFineweb-eduであり0.39である一方、Annotate Fineweb (weight,top)も0.3598, 0.3716とFinewebの0.3058と比較すると高い数値でありPreference APIでもフィルタリング出来ていることが分かります。
その他の評価に関してはPreference APIが高い傾向で、これはFineweb-eduよりもフィルタリングが簡易的な分、有害なデータは除去しつつもデータに多様性が生まれ、一般的な常識推論タスクは解きやすいように学習できたのではと考察しています。
表4 スコアリングの概算処理速度(各モデルの学習時間やデータセット構築など実行に必要な前処理時間を含まない)
| モデルサイズ | GPU | 台数 | 実行時間 | |
| Fineweb-edu-classifier | 109M | A30 | 1 | 8m |
| Preference API | 70B | A100 | 2 | 60h |
まとめ・展望
1-token prediction/Preference APIを用いたFinewebのアノテーションに取り組みました。
結論としては1-token predictionでのアノテーションは可能であるが、classifierを学習して利用する場合と比べ高いスコアが得られやすいとわかりました。
また、汎用モデルを用いたアノテーションにはかなりのコストがかかり適切に使い分ける必要があることが示唆されました。
今回、既存のフレームワークをすべてPreference APIで置き換えることを目標としましたが、学習データを作成するためのアノテーション部分のみをPreference APIに置き換えるのもコストの観点から有用であると考えられます。
その他の展望としては、よりデータ数の少ないチューニング用のデータのフィルタリングやPreference APIのためのプロンプト探索の自動化、コストの観点からGPUを用いないFastTextを用いたフィルタリングの検証などが考えられます。
終わりに
大学ではpretrainまで経験することは計算環境の都合上難しいので、非常に良い経験が出来ました。LLMが大流行している今現在、データをどのように扱うかは幅広いドメインにおいて重要な要素であり、今回のインターンで学んだことを忘れずに今後の研究に励みたいと思います。
最後になりましたが、メンター・サブメンターをしていただいた廣川さん・徐さん、そしてpretrainチームの皆さんには沢山のことを教えていただき、大変お世話になりました。この場を借りて御礼申し上げます。



