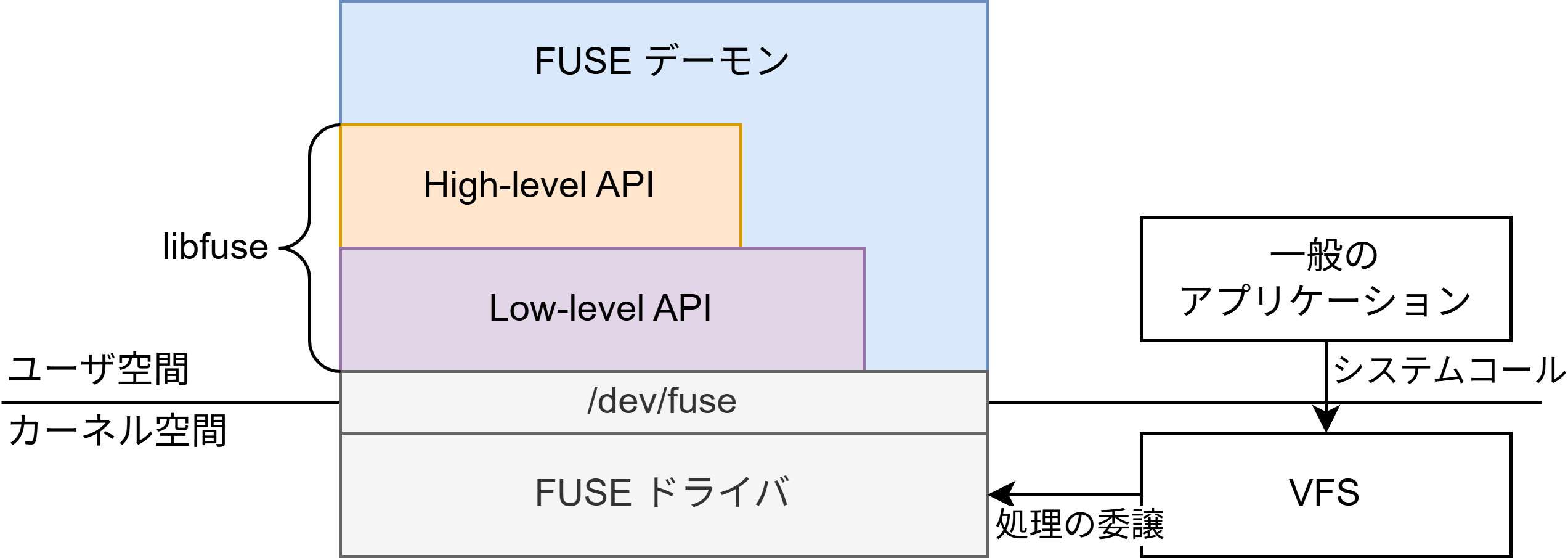
Blog
Why Apache Ozone?
これまでPFNでは増え続けるデータやユースケースに対応するために、スケールアウト可能なストレージシステムをずっと模索し続けてきました。シミュレーションを基軸とした戦略を採用した[1]ことによりデータ量はさらに増加し、データ保管システムの重要性は高まっています。

Preferred Networks におけるHadoop – Preferred Networks Research で解説した基本的な要件は今でも変わっていませんが[2]、現在メインのシステムとして運用している Hadoop (HDFS) にはいくつかのシステム運用上の課題があります。たとえば、一番大きなHadoopクラスタは現時点で物理的に10PB近くのディスク容量を持っていますが、Ubuntu 16.04で動作しています。OSのバージョンアップを伴うクラスタのIn-placeなアップグレードは前例と知見がなく、OSのサポートも延長が発表されたこともあり[3]、既存のHadoopクラスタをこのまま拡張し続けることは諦め、代替システムとなるシステムを模索してきました。そして、代替システムを選定し別のクラスタを立ててデータを段階的に移していくという計画を立てました。
OSのバージョンアップは一例で、他にも我々のユースケースではHDFSにマッチしない問題がいくつかあります。HDFSそのものの運用性の高さから妥協してきましたが、ここで改めて列挙します。
- Small Files Problem [4]: ファイル数が増えるとメタデータ数が増加し、データ量に比してNameNodeの負荷が高まる。特に再起動後のNameNodeメタデータの読み出しに要する時間が大幅に長くなる。
このため社内ではデータをなるべくZip等のアーカイブに格納してHDFSに保存し、PFIOのようなライブラリを用いてZip内のファイルを直接読み出すことを推奨してきた。 - High Density Disk Servers: オンプレミスのサーバーはノードあたりのHDD格納数が高いほど容量単価を下げることができる一方で、HDFSにおけるFull Block Report (FBR)の長期化はデータの永続性と可用性に影響する。DataNodeが保持するBlockが多いと、FBRに要する時間が大幅に長くなる。たとえば、Clouderaは100TB以上のDataNodeはサポートしないし、8TB以上のHDDはサポートしないと明言している[9]。それに対して、PFNのDataNodeで最大のものは14TBのHDDを36本装備している。
- Better Affinity with Python Runtime: HDFSにアクセスするためには、Java の Hadoopクライアントをlibhdfs2経由でJNIで実行してデータをやり取りする方法がスタンダードである。このためPythonの実行に様々な制約が課され、Pythonからの利用が難しい。代表的な例はPyTorchのDataLoaderがプロセスをforkして並列実行するため、JVMそのものをforkしてしまわないような設計が必要となる。
- Classic Authentication: Kerberosベースの認証システムは安定しており信頼性が高いが、kinit(1) を用いてトークンを取得する方法はKubernetes Pod上での実行と相性がよくない。PFNではkeytabをsecretとして登録し initContainer で kinit するようなワークアラウンドが用いられているが、環境変数だけで済むような、もっと利用しやすい認証方式がほしかった。
- NameNode Scalability: HDFSのメタデータ管理をスケールさせるための方法としてHDFS Federationなどがリリースされているが、NameNodeの数を増やすというアプローチのため運用の複雑化が避けられない。
こういった問題は、Hadoopを運用する面々には疲労となり、アプリケーションを開発するユーザーには不満となってずっと燻り続けました。こういった問題はHadoopの開発陣ももちろん認識しており、これらを解決するソリューションとしてHadoopからApache Ozoneというプロジェクトが派生しました。具体的にどのように解決するかを列挙します。
- Small Files Problem: それまでNNが一括して管理していたメタデータとブロック配置情報をそれぞれOzone Manager (OM), Storage Container Manager (SCM) にそれぞれ責務を分担させた。複数のBlockをまとめて管理するContainerという単位を新たに作り、SCMはその単位でデータ配置を管理することとした。この分割によってファイル数の増加はOMのみに影響することとなり、RocksDBによって管理することによりディレクトリツリーの管理効率も改善した。
- High Density Disk Servers: FBRの設計は変更され、DataNodeが管理するコンテナだけをSCMに報告すればよくなったため、実行時間も短縮された。ひとつのコンテナが格納できる最大のBlockは 2^64 個であるため、コンテナあたりのBlock数を適度にコントロールすることによって、SCMの負荷を制御することができるようになる。
- Better Affinity with Python Runtime: 新たにAWS S3互換のAPIのエンドポイントが追加された。AWS S3のエコシステムは広大で、GoやPythonなどさまざまな処理系のSDKが提供されているだけでなく、メジャーなソフトウェアの多くがローカルファイルシステムの代わりにS3(互換APIを持ったオブジェクトストレージシステム)を利用できるようになっている。
- Classic Authentication: HDFSの互換APIを維持するために、Kerberosベースの認証機構はそのまま引き継いでいるが、AWS S3互換のAPIエンドポイントに使うSecretさえ取得して記憶しておけば十分であるため、 keytab を保管したり krb5 関連のパッケージを管理しなくてよくなった。
- NameNode Scalability: NameNodeが持っていた責務をOMとSCMに分割しデータ構造をRocksDBベースのものに改善したため書き込みやスキャンの性能が向上した。HDFS Federationのような仕組みが不要になるとは断言できないが、現時点ではかなり大きなクラスタでも十分対応できる。Clouderaは100億オブジェクトでテストしている[5]。
昨年のブログ記事[2]を書いた後から、Apache Ozoneを次期オブジェクトストレージとして検証し、社内で1年ほど運用しました。
検証の過程でCVE-2020-17517を発見し報告しましたが[6]、それ以外にはブロッカーになるようなクリティカルな問題はなく、一旦クラスタを試用版という位置づけで運用してユーザーに開放し、知見を蓄積するステップへと進むことにしました。AWS S3 API は膨大な機能があるため、十分な数のAPIを実装しているとはいえない状態でしたが、開発コミュニティが活発であることから、必要な機能や修正はPFNから貢献していけばよいと判断しました。
Cluster Configuration & Setup
MN-2を構成するストレージサーバーのうち [7]、4台をDataNodeにし、管理系のサーバーにOMとSCMをインストールしました。それぞれ物理的な構成は以下のようになります。表1はDataNodeの仕様です。36個あるHDDをすべてそのまま ext4 でフォーマットして、JBODとしてそのままOzoneに利用させます。
表1: DataNode用サーバー仕様
| 仕様 | 数 | |
| CPU | Intel(R) Xeon(R) Silver 4114 | 1 |
| Memory | 32GB DDR4 | 12 ※1 |
| HDD | 14TB SATA 6GB/s 7200rpm | 36 |
| Network | Mellanox ConnectX-6 (100GbE) | 2 |
また、表2はOMとSCMが動作するメタデータサーバーの仕様です。メタデータを保護しつつ容量を確保するために、15TBのNVMe SSDを4本、raidz で束ねています。ZFSを利用したのは他のサーバーで利用実績があったこと、コマンド体系が整理されていて扱いやすいためです。ZFSのパーティション上に、OMとSCMのデータを保管します。この構成によって、単一のSSDが故障してもデータを失わないようにします。
表2: Ozone Manager 及び Storage Container Manager 用サーバー仕様
| 仕様 | 数 | |
| CPU | Intel(R) Xeon(R) Silver 4114 | 1 |
| Memory | 32GB DDR4 | 12 ※1 |
| NVMe | 15TB PCIe Gen3 | 4 |
| Network | Mellanox ConnectX-6 (100GbE) | 2 |
※1 メモリは後日32GBのものをノードあたり4本ずつ追加し、ノードあたり512GBとなりました。
OSはMN-2構築時にインストールしてあった Ubuntu 18.04 をそのまま利用しました。以前別のサーバーでNVMe SSDを運用したときに安定しなかったので、メタデータサーバーだけはHWEカーネルをインストールし、Linux 5.4.0 が動作しています。また同様にJavaはMN-2構築時にインストールしてあった Oracle JDK 8u162をそのまま利用しました。
これらのサーバーにApache Ozone 1.0.0をSecure Clusterとして構築しました。
図1は、Ozoneクラスタの簡単な構成図です。ストレージサーバーではDataNodeとS3Gatewayが動作し、メタデータサーバーではOMとSCMが動作しています。S3Gatewayは、AWS S3 APIで受け付けたクライアントからのリクエストをOzone Native APIといわれるAPIに変換するプロセスです。S3Gatewayは外向けにはHTTP APIサーバーとして動作しますから、それに対するアクセスを分散するためにDNSラウンドロビンで負荷を分散するようにしています。HDDからクライアントのメモリに届く経路上で特定のNICがボトルネックにならないようにするために、HAProxy等のリバースプロキシをなるべく用いない構成にしました。また、Ozone 1.0.0の時点でOMの冗長化機能(High Availability, HA)はリリースされていましたが、難易度の高い機能であること、SCMも同様に冗長化しない限り運用上は大して楽にならないこともあって採用しませんでした。
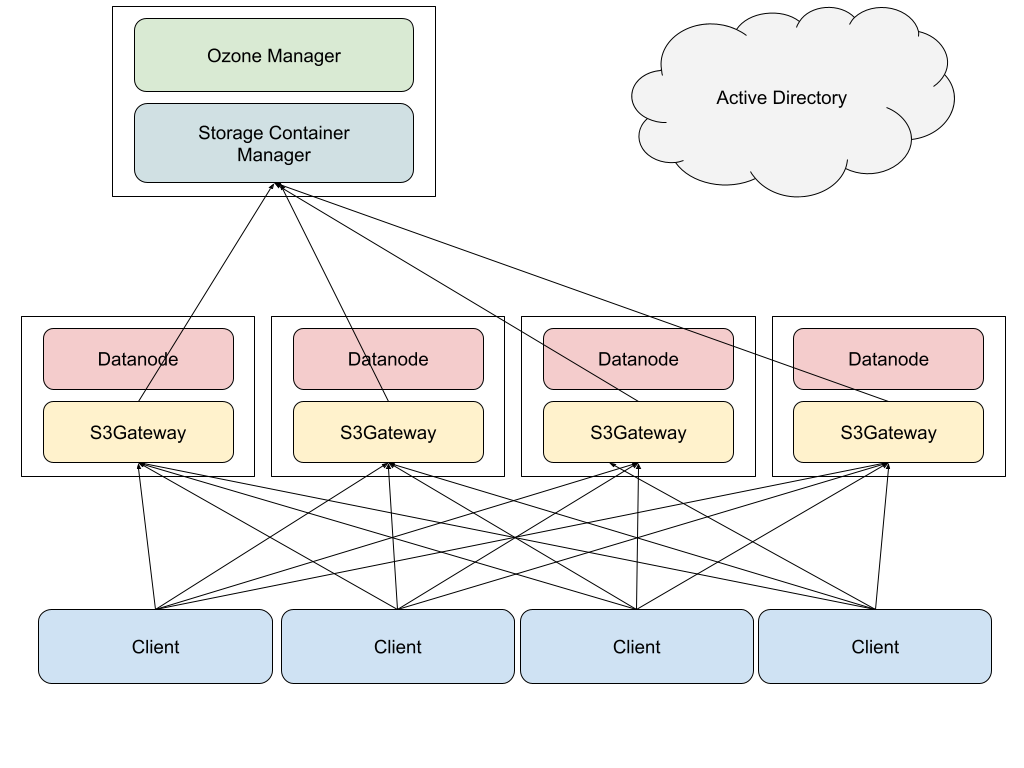
図1: 単純化したプロセス構成
この構成で、 200GB程度のファイルに対するアクセス性能をベンチマークしました。簡単な並列読み出しのベンチマークスクリプトを作成し、Kubernetes上に複数のクライアントPodを起動して並列で読み出しを行ってスループットを測定しました。結果は図2のように、クライアント側の並列数が128のときにスループットが4GB/s弱で最大となりました。本当のピークをだすクライアント側の並列数はおそらく64~256の間のどこかにあると思われます。データ量がディスクキャッシュに乗るサイズであること、20コアのCPUが4ノードあった(=全部で80コアがクライアントのリクエストを処理した)こと、ベンチマーク中のCPU使用率が100%近くに張り付いていたことなどから、サーバー側のCPUの処理性能がボトルネックになっていたと考えられます。
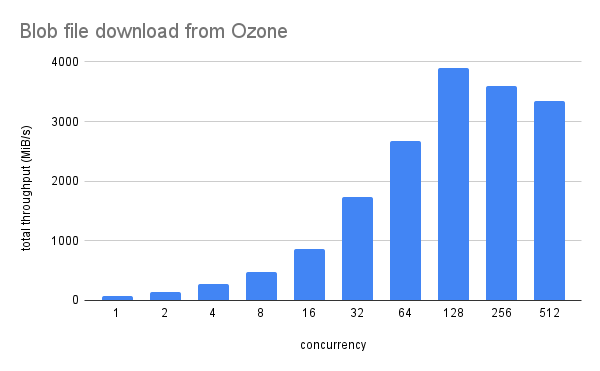
図2: blobファイルの並列ダウンロード性能
このクラスタはベンチマークをしたあと、社内で運用を開始して業務で使えるようにしました。数ヶ月運用して、これを機械学習などの業務で運用しているプロジェクトがいくつかあります。もともとこの記事でユースケースを紹介する予定でしたが、思っていたよりスタンダードなワークロードばかりだったので、ここでの紹介は省略することにします。
History & Current Status
構築を2021年のはじめ頃に済ませたあと、Ozone 1.1.0が春ごろにリリースされました。これはすぐにアップグレードしました。パイプライン(Pipeline)の配置がうまくいかず、4台で36ドライブずつであればパイプライン(Raftによるレプリケーションが実行される単位)が36*4/3=48個作られてほしかったのですが、どうしても36個しか作られなかったため、144枚あるはずのHDDが108しか稼働していませんでした。後日ストレージノードを2台追加したところ、パイプラインが無事72個作成され、すべてのHDDにデータが書き込まれるようになりました。パイプラインの解説については、Cloudera のブログ記事が詳しいです[8]。
その後一年近くOzoneを運用してきました。Apache Ozone はデフォルトで全てのコンポーネントがHTTPSで /prom というエンドポイントを持っており、Prometheus Exposition format で各種メトリクスを観測することができます。これをPrometheusで収集しGrafanaで可視化できるようにしてあります。また、異常があった場合には Alertmanager を通じて気付けるようにしています。現時点でオブジェクト数は 3000万、 Bucket は400以上あるようです。図3のように、この半年でデータ量も徐々に増えてきました。
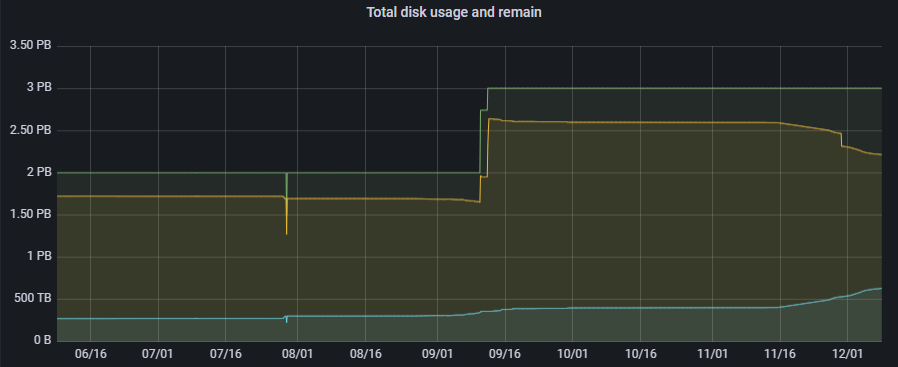
図3: Ozoneクラスタのディスク総容量と使用量(物理)の変遷
その後、運用の過程でいくつかのアップストリーム貢献をすることができました。CVE-2020-17517 はすでに挙げましたが、1.2.0に含まれる代表的なものは以下のとおりです。
- HDDS-5197 (パッチ)
- HDDS-5620 (パッチ)
- HDDS-5893 (パッチ)
- HDDS-4856 (報告のみ)
- HDDS-5005 (報告のみ)
- HDDS-5393 (報告のみ)
他にも1.3.0にマージされたものや、いくつか進行中のものがあります。これらの解説は長くなるので、また別の記事で詳しく解説したいと思います。コミュニティ活動とは別に、9月にはHDDS-5472のパッチを1.1.0にcherry-pickしてデプロイしていました。これによってOMの性能がかなり向上して安定運用できるようになりました。また、10月にはOpenJDK 1.8.0 に切り替えました。Ubuntu 18.04 では現在は 1.8.0-292 のようです。これによってTLSの処理性能が向上しました。
11月に1.2.0がリリースされ、同時にいくつかの脆弱性が公開されました。PFNでもすぐに1.2.0へのアップデートを行いました。1.2.0のアップデートは思っていたよりもスムーズに終わりました。
今後の予定は主に3つの方向性があります。
OM & SCMの高可用化
現状の構成では、OMとSCMのメタデータをZFSで冗長化しているとはいえ、サーバー自体が冗長化されたわけではありません。たとえばOMとSCMが動作しているマシンのマザーボードが故障するとサービスがOMもSCMも落ちるので、サービスが全断します。Ozone 1.2.0 からはこれらのメタデータサービスをRaftを使って冗長化できるようになりました。OMやSCMのプロセスを3重に冗長化して、一台が故障してもフェイルオーバーできるようになります。これによって、可用性がさらに上がるので、社内の重要な業務でも利用しやすくなることが期待されます。
システムのさらなる拡張とHDFSからのデータ移行
現在、HDFSには9PBほどのデータがあり、Ozoneはまだ200TB程度です。このデータを基本的に全部移していきたいと思っています。また業務で使われることが増えるに従ってデータが増えていきますから、OzoneのクラスタにDataNodeを適宜追加してく必要があります。一部はHDFSのデータが減った分のDataNodeを減らした分を転用する計画ですが、実際どれくらい減らせるかは本格的に移行が進まないと見えてこないでしょう。他のストレージを廃棄してきたときもデータがなかなか減らなくて結局データを管理者が削除することが多かったので、今から戦々恐々です。
いくつかの移行手順とパスがあります。同じKDC (Key Distribution Center, Kerberos用語) を使えるクラスタではdistcpを使ってコピーできるようです。認証系が異なる場合でも、 distcp は s3a にも対応しているのでコピーできそうです。ただ、 S3 API の最大ファイルサイズは5TBですが、HDFS上には 5TB を越えるファイルがいくつかあるので、それをどうするかが課題ではあります。
機能改善とアップストリーム貢献
どんなソフトウェアも完璧ではありませんし、自分で運用しているうちに不便を感じるところが多くでてくるものです。そういった改善をコミュニティ任せにするのではなく、必要なものから自分たちでパッチを送って取り込んでもらう活動を続けていきたいと思います。現在提案中で重要なものだと、以下のようなものがあります。
- HDDS-5656 – MPUの最適化
- HDDS-5905 – Delete のデータロス防止
- HDDS-5975 – ListObjects のバグ修正
Conclusion
PFNではApache HadoopからApache Ozoneへの移行を進めてきました。その背景と、実際のクラスタ構成について解説しました。今後もデータ量が増えるため、さらにクラスタを拡張していきつつ、コミュニティに貢献していくつもりです。
Acknowledgement: この文章に執筆を大いに助けてくれた同僚の土井氏、水丸氏、杉原氏に感謝します。
Reference
- [1] 《日経Robotics》AIによるシミュレーションの進化 :PFN岡野原氏連載 第56回
- [2] Preferred Networks におけるHadoop – Preferred Networks Research
- [3] Ubuntu 14.04 and 16.04 lifecycle extended to ten years
- [4] The Small Files Problem
- [5] Future of Data Meetup: Apache Ozone – Breaking the 10 billion object barrier
- [6] NVD – CVE-2020-17517
- [7] PFN’s Supercomputers – Preferred Networks
- [8] Multi-Raft – Boost up write performance for Apache Hadoop-Ozone
- [9] HDFS | CDP Private Cloud
Area
Tag