Blog
本記事は、2024年夏季インターンシッププログラムに参加された仲野力さんによる寄稿です。
こんにちは、2024年のPFN夏季インターンシップに参加した東京大学修士1年の仲野力です。大学では杉山・横矢・石田研究室にて、音響イベントの検出や分離手法を研究しています。
今回のインターンシップでは、「音声理解機能を持つ大規模言語モデルの開発」というテーマで研究開発を行いました。具体的には、小さい言語モデルを組み込んだ音声認識モデルを開発することで認識精度を向上させつつ、推論コストの削減が目的でした。
背景
音声認識とは、音声信号を入力としてそれを発話の通りにテキストに変換するタスクです。これにはハンズフリーなデバイスの操作や字幕生成などの様々な応用があり、益々重要性を増しています。
深層学習による音声認識は、畳み込みニューラルネットワークやリカレントニューラルネットワークを用いて行われてきました。それ以前は、隠れマルコフモデル等を用いて音素列から単語に変換する手法などがありました。しかし近年、Transformer [1] の登場を経て、Transformerベースの音声認識モデル Whisper [2] が登場し、音声認識の標準を塗り替えました。
Whisperのモデルアーキテクチャは、典型的なEncoder-decoder型のTransformerでした。このようなモデルを1から学習するのにはコストがかかります。そこで、新たな方向性として、事前学習済みの大規模言語モデル (LLM) を音声認識モデルに組み込む手法に注目が集まっています [Sec. 2.4, 3] 。この手法では、組み込まれたモデルが事前学習済みであることから、学習にかかるコストの低減が見込めるのに加え、LLMがコンテキストを考慮することによる認識精度の向上が期待できます。
より具体的には、この手法による音声認識モデルはEncoder部分とDecoder部分から構成され、Encoder部分には音声の特徴量をトークン埋め込みに変換するモデルを、Decoder部分には事前学習されたDecoder-onlyなLLMを用います。

図1:LLMを組み込んだ音声認識モデルの概要
先行したプロジェクトとして、WhisperのEncoderとPFNで開発したLLMであるPLaMo-100B*を用いた音声認識モデルの開発が行われていました [4]。しかし、100Bサイズのモデルの推論には最低でも80GBの潤沢なGPUメモリを必要とし、計算コストがかかる問題がありました。
同研究においては、Swallow-7B [5] という小規模のモデルでもWhisperを超える日本語の音声認識性能が報告されていました。さらに、Whisper-large-v3のモデルサイズは全体で1.6B程度です。以上のことを踏まえて、より小さいPLaMo-1B**というモデルのDecoderで100B/7B サイズの Decoder と同等の音声認識性能を達成できるかどうかを検証しました。
* 本記事内および [4] で参照されてるPLaMo-100Bは、PLamo 1.0 Primeとは異なる開発用モデルを指します。PLaMo-100Bは、子会社のPreferred ElementsがNEDO(国立研究開発法人新エネルギー・産業技術総合開発機構)の助成事業「ポスト5G情報通信システム基盤強化研究開発事業」(JPNP20017) に採択され、日本の基盤モデル開発力向上を目指すGENIACプロジェクトで開発しました。
** 今回の実験で使用したPLaMo-1Bは、PLaMo Liteとは異なる社内開発用のモデルです。
学習の詳細
モデルアーキテクチャ
今回用いた音声認識モデルのアーキテクチャは、PLaMo-100Bを用いたモデル [3] と同じく次のような構成になっています:
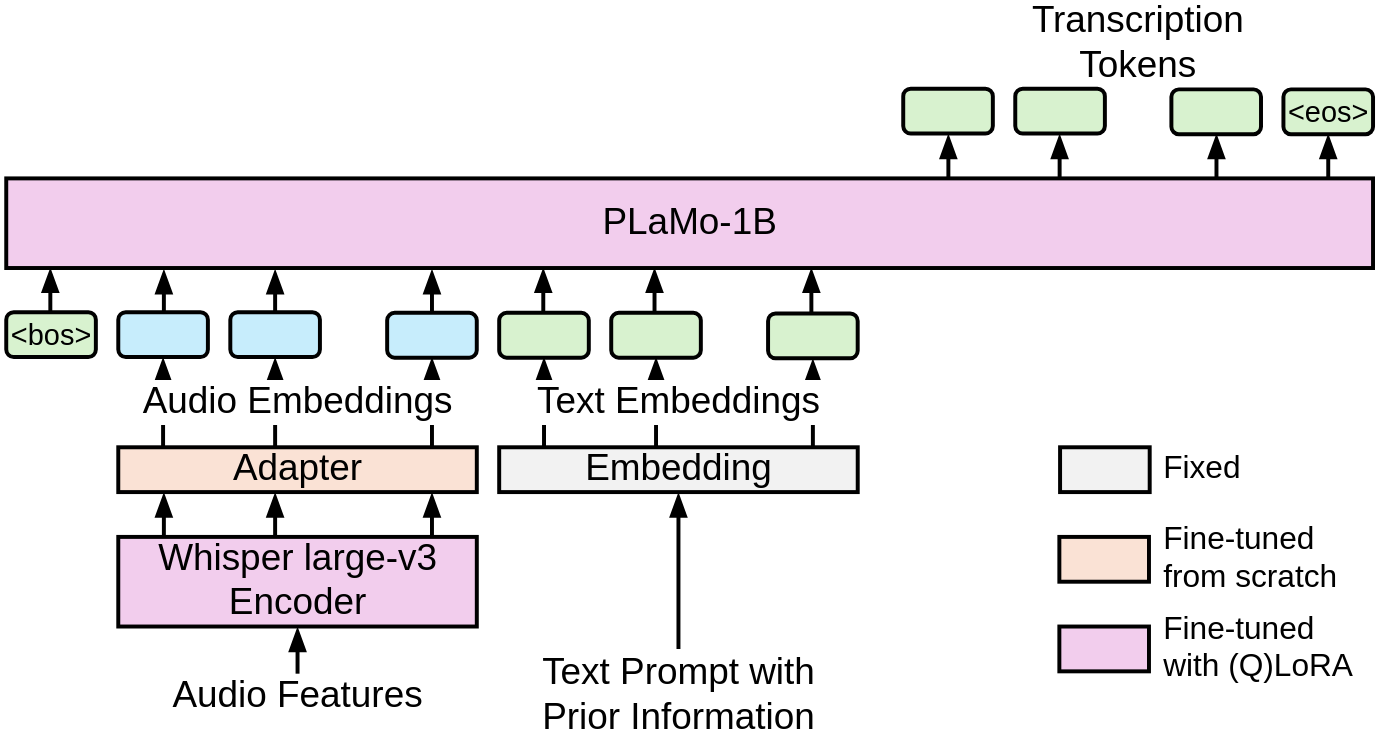
図2: 用いた音声認識モデルのアーキテクチャ。図は [3] より引用(一部改変)。
Encoder部分には学習済みのWhisper-large-v3のEncoderを使用します。Decoder部分にはPLaMo-1Bという小規模な事前学習済みのLLMを用います。
本来のWhisperでは、EncoderからDecoderへの情報の受け渡しはクロスアテンションを用いて行われます。LLMをDecoderとして用いる場合は、Encoderの出力をAdapterと呼ばれる単純な線形層などに通し、トークン埋め込みに変換してDecoderのLLMの入力の一部として渡します。
プロンプトのフォーマット
DecoderのLLMに受け渡されるプロンプトの構成は以下のようになっています:

図3: Decoderに入力されるプロンプトのフォーマット
Begin of Sentence (<BOS>) の直後にAdapterの出力である音声信号のトークン埋め込みが続き、その後言語情報:en, ja, or na (それぞれ英語、日本語、言語情報なしを表す) が与えられます。そしてキーワードの情報が与えられ、書き起こしが続きます。なお、[keywords] にはカンマ区切りの単語等のリストが、 [ text ] には音声の書き起こしが入ります。
ここでキーワードの役割を説明します。音声信号のみを入力とする音声認識では、同音異義語や、特に人名や地名などでは多数の同音異表記が存在するため、入力音声だけからでは正確に書き起こすことができません。また、英単語で書き起こされることが望ましい場合に、それをカタカナ表記で認識してしまうケースもあります(例:「Preferred Networks」と「プリファードネットワークス」)。そこで、プロンプトにそのような単語をキーワードとして含めることで、固有名詞などの正確な書き起こしや表記揺れの削減が期待できます。
データセットと評価指標
PLaMo-1Bを用いた音声認識モデルの学習および評価には、PLaMo-100Bの実験と同様に、以下の4つのデータセットを用いました:
- LibriSpeech [6]: 英語の音声認識用の標準的なデータセットです。今回用いた唯一の英語のデータセットとなっています。
- CommonVoice v8.0/v16.1 [7]: Mozillaの音声データ収集プロジェクトによって作成されたデータセットです。日本語のサブセットを主に評価のために用いています。
- ReazonSpeech [8]: 日本のTV番組から作成されたデータセットです。学習データの8割以上を占めています。
- YODAS [9]: YouTubeの字幕付き動画から作成されています。唯一キーワードを付与してあります。
データセット全体のサンプル数は約1300万サンプル、合計時間は約2万時間となっています。
英語のデータセットであるLibriSpeechを用いた評価については、指標として Word Error Rate (WER) を用いました。それ以外の日本語のデータセットについては Character Error Rate (CER) を用いました。さらに、キーワードが付与されているYODASを用いた評価では、指定したキーワードの認識性能を確認するためにKeyword Error Rate (KWER) も測定しました。KWERは次の式で定義されます:
\[\mathrm{KWER} = \left(1 – \frac{T}{N} \right) \times 100, \]
ただし、\(N\)はレファレンスデータ中のキーワード数、\(T\)は正しく認識されたキーワード数です。これらの指標が低いほど音声認識の性能が高いです。
ファインチューニングの手法
PLaMo-100Bを用いたファインチューニングでは、モデルを1枚のGPUのメモリ上に載せるためにEncoderとDecoderに4bit量子化 [10] を使用していました。しかし、PLaMo-1Bを用いる場合は量子化を行わなくてもGPU1枚で学習できるため、認識性能改善を確認するために4bit量子化を行う場合と行わない場合を比較しました。ファインチューニングに際しては、LoRA [11] を用いました。量子化を行う場合はQLoRA [10] に相当します。
ハイパーパラメータの調整については、量子化の有無の他、学習率を変化させました。その他にも多数のハイパーパラメータがあるのですが、事前実験によりそれらの重要性は低いと思われたため決め打ちとしました。よりパラメータ数の近いSwallow-7Bのハイパーパラメータを踏襲しましたが、バッチサイズはGPUメモリに載せられる最大の値に取りました。また、PLaMo-100Bでは学習率のwarmupを行っていましたが、学習を速める目的で今回はwarmupを用いませんでした。その他の違いとしては、LoRAのDropout (5%) を導入しています。
なお、1回の学習はNvidia H100 GPUを8個用いて、DistributedDataParallelによるデータ分散で行っています。
実験と結果
以下に挙げる表では、全てLibriSpeechについてはWERの値を、その他のデータセットについてはCERの値を記載しています。また、YODASに関して書き起こしを生成する際にキーワードを付与せずに生成した結果を w/o keyword、キーワードを付与した結果を w/ keywordと呼んでいます。評価は学習終了時点のモデルで行っています。
QLoRAとLoRAの比較
上述の通り、量子化によってベースモデルの性能が劣化すると考えられることから、QLoRAとLoRAの比較を行いました。
| Method | Common Voice v8.0 | Common Voice v16.1 | LibriSpeech | YODAS w/o keyword | YODAS w/ keyword | |||||
| Dev | Test | Dev | Test | Dev | Test | Dev | Test | Dev | Test | |
| QLoRA | 6.22 | 8.16 | 11.44 | 15.09 | 4.88 | 5.18 | 14.83 | 11.90 | 13.25 | 10.81 |
| LoRA | 5.63 | 7.43 | 10.79 | 14.40 | 4.48 | 4.65 | 13.83 | 12.07 | 13.41 | 10.50 |
表1より、一部逆転している部分はあるものの、全体としてはLoRAの場合の方がQLoRAの場合より性能が良くなっています。
Epoch数の増加
次に、PLaMo-100Bでは計算資源の制約により1 epochしか学習が行われていませんでしたが、Epoch数を増加させることによる性能向上が見込まれるため、これを検証しました。
| Epoch | Common Voice v8.0 | Common Voice v16.1 | LibriSpeech | YODAS w/o keyword | YODAS w/ keyword | |||||
| Dev | Test | Dev | Test | Dev | Test | Dev | Test | Dev | Test | |
| 1 epoch | 5.63 | 7.43 | 10.79 | 14.40 | 4.48 | 4.65 | 13.83 | 12.07 | 13.41 | 10.50 |
| 2 epoch | 5.21 | 7.04 | 10.66 | 14.18 | 4.57 | 4.64 | 13.66 | 11.33 | 12.22 | 10.06 |
表2より、全体としてはEpoch数が2の場合の方が性能が良くなっています。
学習率の調整
事前実験により学習率を 1.0e-4、5.9e-5 とした場合では学習が安定しないことが分かっていたため、上記の実験では学習率として 3.6e-5 (以下、3e-5と略記) を採用していました。しかし、この場合も学習初期に長めのSpikeが見られたため、もう一段階小さい 2.1e-5 (以下、2e-5と略記) との比較を行いました。なお、このような学習率の候補は 1.0e-6 – 1.0e-4 を対数軸上で10分割することによって決めました。
以下に比較の結果を示します:
| Learning Rate | Common Voice v8.0 | Common Voice v16.1 | LibriSpeech | YODAS w/o keyword | YODAS w/ keyword | |||||
| Dev | Test | Dev | Test | Dev | Test | Dev | Test | Dev | Test | |
| 3e-5 | 5.21 | 7.04 | 10.66 | 14.18 | 4.57 | 4.64 | 13.66 | 11.33 | 12.22 | 10.06 |
| 2e-5 | 4.94 | 6.67 | 10.48 | 14.19 | 4.37 | 4.62 | 13.53 | 11.19 | 12.05 | 9.74 |
表3より、学習率が2e-5の場合の方が性能が良くなっています。したがって、これよりさらに一段階小さい学習率での評価が欲しくなるところですが、これは時間の制約により今後の課題としました。
100B/7Bとの比較
これまでの実験で最も結果の良かったPLaMo-1Bのモデル (LoRA、2 epoch、lr=2e-5) と文献 [3] のPLaMo-100B/Swallow-7BのモデルおよびWhisperとの比較結果を示します:
| モデル | Common Voice v8.0 | Common Voice v16.1 | LibriSpeech | YODAS w/o keyword | YODAS w/ keyword | |||||
| Dev | Test | Dev | Test | Dev | Test | Dev | Test | Dev | Test | |
| Whisper | 6.60 | 8.55 | 11.92 | 15.24 | 2.89 | 2.95 | 16.88 | 13.50 | – | – |
| PLaMo-100B | 4.24 | 5.63 | 9.70 | 13.67 | 4.16 | 4.38 | 12.93 | 11.29 | 11.47 | 9.48 |
| Swallow-7B | 5.05 | 7.24 | 10.32 | 13.85 | 4.39 | 4.41 | 13.05 | 11.06 | 11.37 | 9.54 |
| PLaMo-1B | 4.94 | 6.67 | 10.48 | 14.19 | 4.37 | 4.62 | 13.53 | 11.19 | 12.05 | 9.74 |
全体を俯瞰すると、英語の評価セットである LibriSpeech を除いて日本語の評価セットでは PLaMo-1Bを用いたモデルはWhisperの認識精度を上回っています。また、より大規模なモデルであるPLaMo-100B、Swallow-7Bと比較すると、サイズ比に対して性能劣化が大きくないことも特筆に値します。
キーワードの効果
次に、キーワードの有無による変化について述べます。今回用いているどのデータセットにも元々キーワードは付されていないので、YODASにLLMを用いて付与したキーワードで評価を行いました。
表4の YODAS w/o keyword と YODAS w/ keyword を比較すると、キーワードを与えた場合に精度が向上しています。また、以下の表5にYODASにおけるKWERの比較を示します。
| Model | Dev | Test | ||
| w/o keyword | w/ keyword | w/o keyword | w/ keyword | |
| Whisper | 71.66 | – | 61.69 | – |
| PLaMo-100B | 64.17 | 24.29 | 58.21 | 10.45 |
| Swallow-7B | 65.99 | 21.46 | 57.71 | 10.95 |
| PLaMo-1B | 68.02 | 29.75 | 56.47 | 12.19 |
キーワードを与える機構のないWhisperに比べ、LLMを用いた音声認識モデルでは与えられたキーワードに沿った出力ができ、キーワードの認識精度が大幅に向上しています。以下は、キーワードを与えた場合と与えない場合の違いを示す例です:
[プロンプト] 言語:ja;キーワード:なし;書き起こし: [書き起こし] プリファードネットワークスの子会社プリファードlメンツでは2月より1000億パラメーター規模のllmプラモ100 bの開発を行ってきました
例2-1:キーワードを与えなかった場合の推論結果。Preferred Networks、Preferred Elements、PLaMo-100Bといった固有名詞がカタカナになっている他、LLMが小文字になっており望ましくない。
[プロンプト] 言語:ja;キーワード:Preferred Networks、Preferred Elements、LLM、PLaMo-100B;書き起こし: [書き起こし] Preferred Networksの子会社Preferred Elementsでは2月より1000億パラメーター規模のLLM PLaMo-100Bの開発を行ってきました
例2-2:キーワードを与えた場合の推論結果
「プリファードネットワークス」が「Preferred Networks」に変化している等、キーワードを与えることで認識が改善しています。
その他やりたかった事
今後の課題としてインターンの期間中にやり残したことについて述べたいと思います。
まず、上の結果から分かるとおり、1 epochの場合は学習率=3e-5の場合の方が性能が良かったのに対し、2 epochの場合は学習率=2e-5の場合の方が性能が良くなりました。もう少し時間があれば、さらに調整を進めることでSwallow-7Bの結果を超えることも出来たかも知れません。
また、フルパラメータチューニングも行いたかったことの一つです。時間的に厳しかったことや、QLoRA / LoRA で十分性能が出たことから着手するには至りませんでしたが、LoRAによる学習の性能を超える可能性は大いにあると思います。
現在トレーニング可能なパラメータ数は全体の約1%であるため、もしフルパラメータチューニングをやるとなると、モデル分散にする必要があるかも知れません。その際にはDeepSpeedやMegatron-LMなどを用いて、より大規模な学習を行うことになります。私にとってこれらは非常に興味深く、是非試してみたい技術です。
あとは、データセットを多言語化することでモデルをマルチリンガル化しようという構想もありました。モデルサイズの観点からは、1.6BサイズのWhisperが非常に多様な言語を認識できることを考えると我々のモデルにもそのポテンシャルはあると思います。しかし、PLaMoの事前学習が日本語と英語を中心に行われていることや、Whisperの学習データが我々の用いたものよりも遥かに大きいことを考えると、学習データの抜本的な見直しが必要になりそうです。
感想
今回のインターンでは、LLMを用いてWhisperの日本語認識性能を超える音声認識モデルを開発しました。Whisperは別件で以前から使っていましたが、この性能を超えることは難しいだろうと思っていたので、今回このような結果が得られたことやそのための手順を知ることが出来たことは私の殻を破る素晴らしい経験となりました。
また、普段の研究ではLLMには触っていなかったのですが、本インターンでの開発や強者揃いのインターン生の方々との交流を通して一気にLLM事情に詳しくなることが出来ました。同時に、モチベーションの面でも大きな刺激を受けました。
このような大変貴重な場に招いて下さった事に深く感謝申し上げます。また、私をあらゆる面で強力にサポートして下さったメンターの野沢さん、益子さん、谷口さん、大変お世話になりました。本当にありがとうございました。
メンターから
仲野さんのメンターを務めました、PFNの野沢です。今回使用した手法の位置付けを簡単に補足します。今回のようにdecoder-only LLMを音声系のタスクに転用する手法 [Sec. 2.4, 3] は、事前学習済みモデルの高い言語処理能力の恩恵を受けれるため、fine-tuning時に少ないデータと計算資源でdownstream task (今回であれば音声認識)を解きやすいと考えられています。実装面でも既存のdecoder-onlyモデルの入力に音声特徴量系列をトークンの特徴量系列とみなして渡すだけでモデルファイルを変更しない実装が容易です。
参考文献
- https://arxiv.org/abs/1706.03762
- https://arxiv.org/abs/2212.04356
- https://arxiv.org/abs/2308.12792
- https://arxiv.org/abs/2408.08027
- https://arxiv.org/abs/2404.17790
- https://ieeexplore.ieee.org/abstract/document/7178964
- https://arxiv.org/abs/1912.06670
- https://www.anlp.jp/proceedings/annual_meeting/2023/pdf_dir/A5-3.pdf
- https://arxiv.org/abs/2406.00899
- https://arxiv.org/abs/2305.14314
- https://arxiv.org/abs/2106.09685
Area