Blog
本記事は、2020年インターンシップで勤務した高橋芽生さんによる寄稿です。
はじめに
2020年度PFN夏季インターン生の高橋芽生です。
今回のインターンではメタヒューリスティクスライブラリの開発を行いました。
コードはこちらで公開しています。
メタヒューリスティクス
メタヒューリスティクスという用語には様々な意味がありますが、本稿では個々の問題に依存しない連続的な最適化のための一般的なフレームワークを指すものとします。これは関数の形が陽に与えられていない場合の最適化手法であるブラックボックス最適化の一つです。ブラックボックス最適化には、機械学習のハイパーパラメータチューニングや、音声認識システム [1]、結晶構造の解析 [2]、ソーシャルゲームの難易度・バランス調整 [3]などの応用先が知られています。多くのメタヒューリスティクスの手法では、同じバッチのスコアは互いに影響しないため、複数のスコアをまとめて受け取り、新しい複数の入力xを提案することができます。この性質を利用すると、目的関数fに複数の入力xをバッチで計算させることによる高速化が可能です。
既存ライブラリ: mealpy
Pythonで実装されたメタヒューリスティクスの既存ライブラリとして、mealpy [4]というソフトウェアが存在します。mealpyには60以上ものメタヒューリスティクスアルゴリズムが実装されています。今回のインターンでは、mealpyを基に、バッチ処理やnumpyの関数を用いた高速化を行い、より汎用的で使いやすく高速なライブラリの開発を行いました。
デザイン
ライブラリのデザインは以下のようにask-tellインターフェースを採用しました。ask()は次に評価される点を返し、tell()は目的関数の結果をoptimizerに伝える役割をしています。非常に一般化されたインターフェースなので、ほとんど全てのアルゴリズムがこの形で書くことができます。そのため、新しいアルゴリズムを実装することやメンテナンスが容易になります。また、このように設計をすることで、Optunaのような他のライブラリと連携することも視野に入ります。
class BaseOptimizer:
def __init__(self):
# initatization
def ask(self) -> Solutions:
raise NotImplementedError
def tell(self, population: Solutions, fitness: np.ndarray) -> None:
raise NotImplementedError
def optimize(
self, objective_function: Callable[[np.ndarray], np.ndarray]
) -> Result:
for epoch in range(n_epochs):
new_position_list = self.ask()
new_fitness = self.objective_function(new_position_list)
self.tell(new_position_list, new_fitness)
return Result(self.g_best_pos, self.g_best_fit, self.loss_train)
実装
今回実装したライブラリは、20以上のメタヒューリスティクスアルゴリズムに対応しています。このライブラリの主な特徴を以下に示します。
並列化
mealpyでは、以下のようにfor文の中で乱数生成やスコア計算が行われており、スコアの計算を1イテレーション毎に実行する必要があります。
def train(self):
pop = [self._create_solution__() for _ in range(self.pop_size)]
g_best = self._get_global_best__(pop=pop, id_fitness=self.ID_FIT, \
id_best=self.ID_MIN_PROB)
for epoch in range(self.epoch):
a = 2 - 2 * epoch / (self.epoch - 1) # linearly decreased from 2 to 0
for i in range(self.pop_size):
l = uniform(-1, 1)
...
new_position = self._amend_solution_faster__(new_position)
fit = self._fitness_model__(new_position)
pop[i] = [new_position, fit]
...
以下の様に、for文の外にこれらの処理を移動することで、並列処理による高速化が期待できます。 一部のアルゴリズムではfor文の外に乱数生成やスコア計算を移動させることが不可能であったため、そのようなケースは対象外としました。
def optimize(self):
for _ in range(self.epoch):
...
lotate = np.random.uniform(-1, 1, self.pop_size)
...
for i in range(self.pop_size):
if np.random.uniform() < p:
...
new_position_list = np.vstack(new_position_list)
new_position_list = np.clip(
new_position_list,
self.domain_range[0],
self.domain_range[1],
)
new_fitness = self.objective_func(new_position_list)
評価
精度
今回はmealpyという既存のライブラリが存在しているため、mealpyとの比較によって、新しいライブラリが正しく動いているかを評価しました。比較には2次元から30次元までの様々なベンチマーク関数を使用しました。
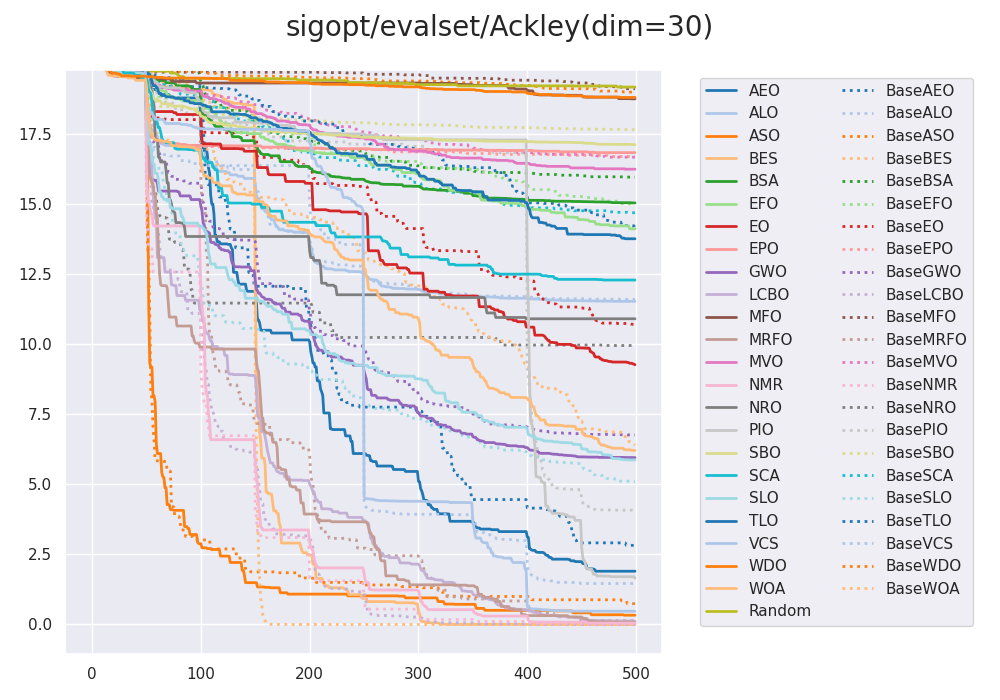
以下のグラフは次元を30に設定し、Ackleyというベンチマーク関数を使用した際の、新しいライブラリとmealpyとの比較を行ったものです。実線が新しいライブラリ、点線がmealpyの結果を表します。横軸はepoch数で縦軸はスコアです。グラフより、実線と点線はおおよそ同じ挙動をしており、デグレーションは起こっていないことがわかります。実線と点線は完全に一致しているわけではありませんが、これはメタヒューリスティクスの挙動が乱数に依存するためです。
実行速度
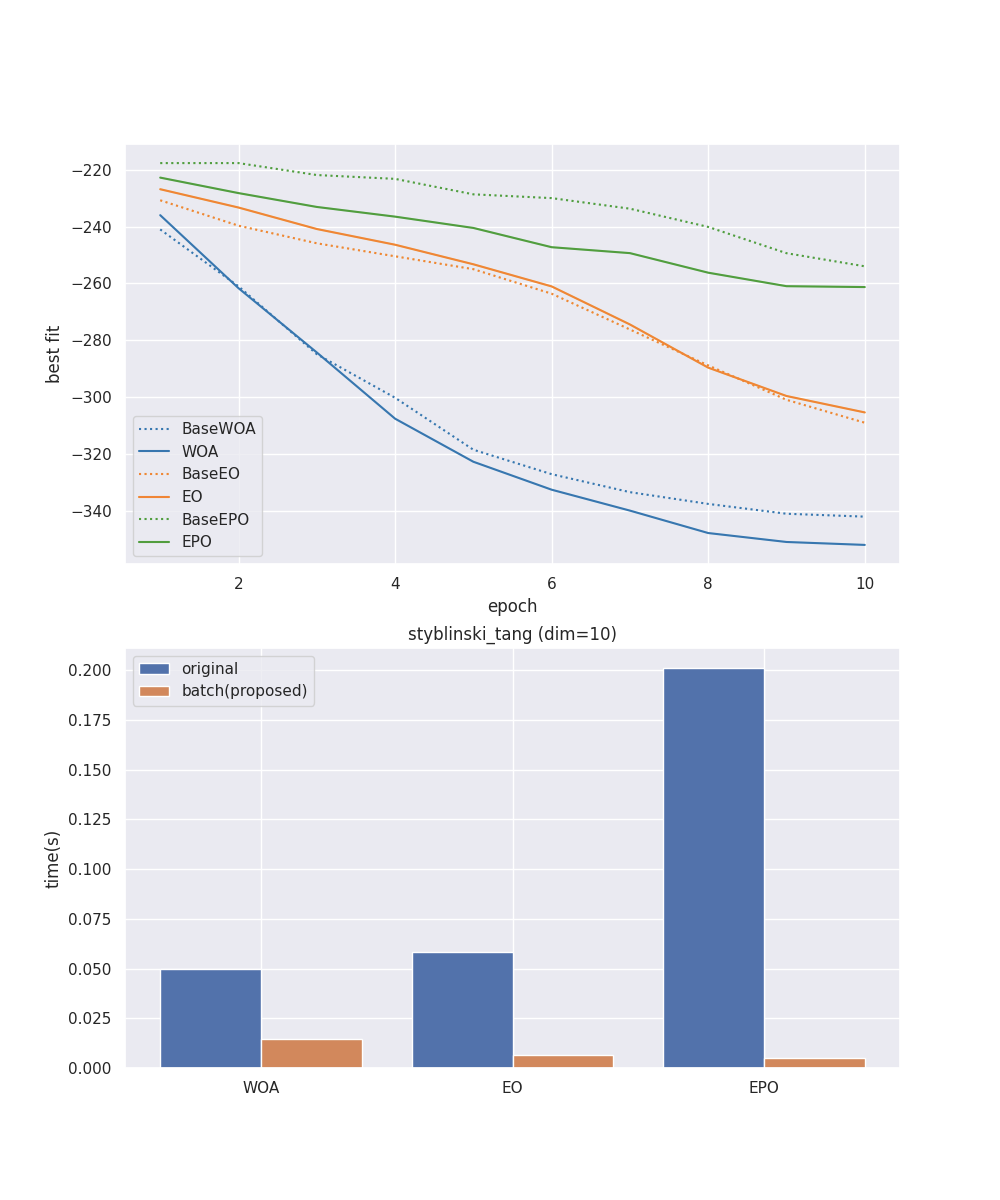
Whale Optimization Algorithm、Equiriblim Optimizer、Emperor Penguin Optimizationの3つのアルゴリズムについてmealpyと新しいライブラリの実行速度を比較しました。
上のグラフは精度についてのグラフです。点線がmealpy、実線が新しいライブラリの結果です。点線と実線がほとんど同じ挙動を示していることより、デグレーションが起こっていないことがわかります。
下のグラフは速度について比較したグラフです。青がmealpyでオレンジが新しいライブラリの結果を示しています。どのアルゴリズムも処理速度が早くなっており、新しいライブラリは精度を落とさずに処理速度の向上に成功していることがわかります。今回はnumpyのベクトル演算を用いて並列処理を行いました。
むすび
このライブラリを用いることで、ある問題に対して多くのアルゴリズムを一度に比較することができます。今後の課題としては、様々な問題においてどのアルゴリズムがうまく機能するのか、そこに傾向はあるのか、などの問題が考えられるでしょう。
また、高速化のために並列処理への対応を行いましたが、一部のアルゴリズムでは困難なケースも存在しました。元々のアルゴリズムとは異なる処理を行うことで無理やり並列化に対応させることも可能ですが、その場合、どの程度のデグレーションが起きうるのか、という点についても興味深いと思いました。
ライブラリ開発は初めての経験で、機械学習もほとんど知識のない状態であり、学ぶことが非常に多く、充実したインターンでした。ライブラリ開発ではライブラリの質を担保しつつ、拡張しやすいものにするためには、良いデザインを決めたり、テストをきちんと書くということを早めの段階で行うことが重要であるということを、実際に開発する中で再認識できました。
今年はリモートでのインターンだったため、最初は不安もありましたが、メンターの秋田さん、阿部さんが常時オーラルコミュニケーションで質問ができるような体制を整えてくださったおかげで、スムーズに進めることができました。改めてサポートしていただき、ありがとうございました。また、その他の社員の方々もリモート開催で機会が少ない中でも、声をかけてくださったり、アドバイスをくださったりしました。インターン期間中にお世話になったすべての方に心より感謝申し上げます。
[1] https://www.jstage.jst.go.jp/article/jasj/72/10/72_644/_pdf
[2] https://academist-cf.com/journal/?p=13774
[3] https://cedil.cesa.or.jp/cedil_sessions/view/1655
[4] https://pypi.org/project/mealpy
