Blog
ゲートを用いたマルチモーダル学習
リサーチャーの高橋城志(Takahashi Kuniyuki)です.
元インターン&アルバイトの安齋智紀(Tomoki Anzai)さんとの共著をIROS2020で発表しましたので,論文を紹介をします.論文と動画は下記から閲覧できます.
論文タイトル:Deep Gated Multi-modal Learning: In-hand Object Pose Changes Estimation using Tactile and Image Data
論文のリンク:https://arxiv.org/abs/1909.12494
論文の動画:https://www.youtube.com/watch?v=2OPQxQIcSxY&feature=youtu.be
視触覚を用いた把持物体の姿勢推定
ロボットによるマニピュレーションタスク,特にインハンドマニピュレーションにおいて,物体を自由に操作するためには物体の位置と姿勢を推定することが重要です.インハンドマニピュレーションとはハンドの中で物体の位置や姿勢を変化させる操作です.しかしながら,インハンドマニピュレーションではハンドや把持している物体自身によって把持している物体が隠れてしまう(オクルージョン)ため,高精度な物体の姿勢推定を行うのに画像情報だけでは不十分です.この問題を解決するシンプルな方法として,複数のセンサ(モダリティ)を組み合わせる方法が考えられます.複数のモダリティを使うことの強みは,オクルージョン,ノイズ,センサの不具合に対して,もう一方のモダリティで情報を補える点です.複数のモダリティを使う場合,状況に応じて,どちらのモダリティをどの程度優先するかが重要になりますが,人手でそれを設計することは難しいです.例として,Fig. 1に物体を把持しているときの画像と触覚センサの画像を示します.画像だけでは物体が見えにくいが,触覚センサの画像には特徴的な情報が現れているもの,あるいは,画像にも触覚センサにも特徴があまり現れていないものがあります.そこで,本研究では複数のモダリティを使用し,各モダリティの信頼性をネットワークが自己判断するend-to-end深層学習を用いたdeep gated multi-modal learning (DGML)を提案します.

Fig. 1 視触覚を用いた把持物体の姿勢推定
関連研究
複数のセンサからの入力がある場合,入力されたモダリティに対してどこに注意(attention)するか,どのように複数のモダリティを扱う(multi-modal learning)かの関連研究は次の3つに大別できます.1) 全てのモダリティに対して均等に注意:各モダリティから特徴量抽出するためにそれぞれのニューラルネットワークに入力され,獲得された特徴量を単純に結合することで把持位置やロボットの動作の推定に使われます.NNにおける注意とは,特定の情報だけを選択し,残りをフィルタリングする操作です.2) 各モダリティ中での注意:与えられたモダリティに対して重要な部分のみ使います.入力されたモダリティに対して,ネットワーク自身で注目するべき部分が抽出されます.3) 関与しないモダリティを無視:重要なモダリティのみを使い,他のモダリティを無視します.
提案するモデルは上記3つのどれにも属していない新しいアプローチで,入力されたモダリティからそれぞれの寄与率をネットワークが判断して,その寄与率を使用して各モダリティをスケールします.
Deep Gated Multi-modal Learning (DGML)
Fig. 2にdeep gated multi-modal learning(DGML)の概略図を示しています.DGMLは3つのコンポーネントから構成されています.画像と触覚から特徴量を抽出するユニット,書くモダリティの信頼値を計算するユニット,物体の時系列姿勢変化量を予測するユニットです.
画像と触覚から特徴量を抽出するユニットにはCNNを用いており,時刻tにおける入力画像Iimg (t)と入力触覚画像Itac (t)から画像特徴量ximg (t)と触覚特徴量xtac (t)をそれぞれ抽出しています.そして,時刻tにおける信頼値α(t)はGateから下記の数式で計算されます.
α(t) = Gate( ximg (t), xtac (t)) = Sigmoid (FCimg (ximg (t)) + FCtac (xtac (t)) )
FCは全結合層です.Gateは全てのモダリティの情報から,相対的にそれぞれのモダリティの信頼度合いを自己判断します.このgateの値(信頼値)は教師なしであり,全てのgateの値を足すと1になるようにしています(α(t) + β(t) = 1).この信頼値が画像特徴量と触覚特徴量をスケールするものとなります.そのため,各モダリティが0に近いほど,そのモダリティの信頼性が低く,出力への寄与が小さくなり,一方1に近い場合は,そのモダリティの信頼性が高く,出力の寄与が大きくなります.スケールされた値を用いて,姿勢変化量を予測するユニットのLSTMで姿勢変化量を予測します.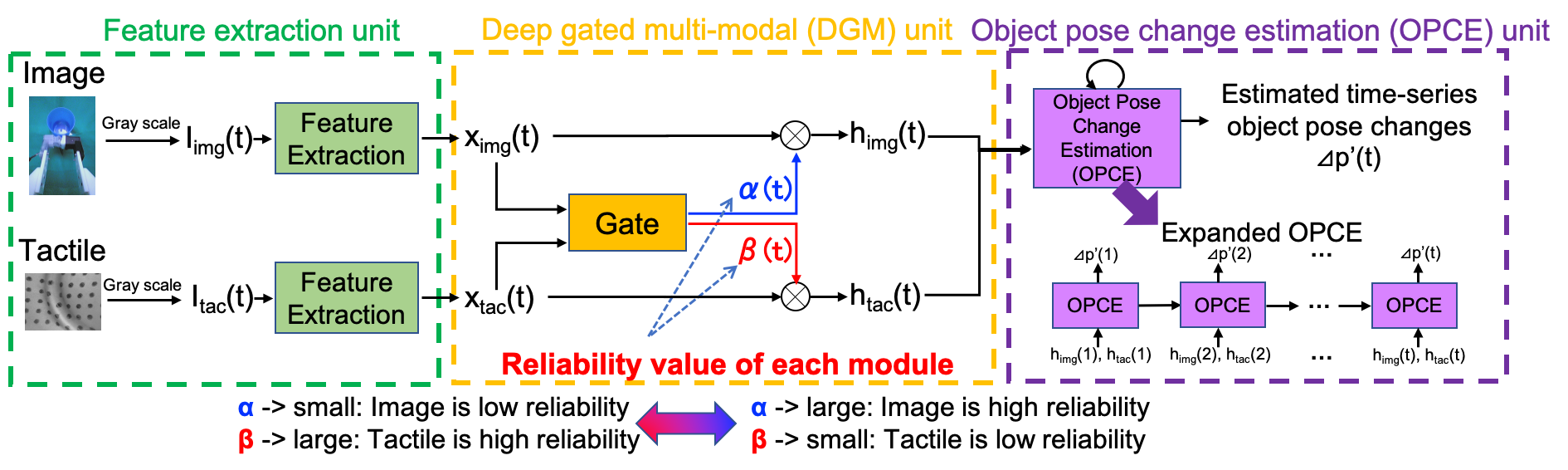
Fig. 2 Deep Gated Multi-modal Learning
データセットの作成
モデルの評価のため,色,大きさ,形状の異なる15種類の物体を用いて,新たなデータセットを作成しました.実験には,Sawyerと呼ばれる7自由度の腕を持ったロボット,及び,その手先にウェブカメラとGelSightと呼ばれる光学式触覚センサを取り付けたものを使用しました.強力な両面テープで机に固定された物体をロボットに把持させ,Sawyerを並進,及び,回転移動させたときのカメラ画像,触覚情報,把持開始時点からの姿勢変化量を取得しています.データセットの作成の様子はこちらの動画からみることができます.https://youtu.be/2OPQxQIcSxY?t=30
 Fig. 3 データセット作成
Fig. 3 データセット作成
評価実験:物体の信頼値
Fig. 4に画像の信頼値αのヒストグラムを示しています.赤枠で囲まれた物体は学習に用いたもの,青枠で囲まれた物体が学習に用いていない物体です.それぞれの物体の画像の比率は実際の物体のサイズの比率に合わせています.ヒストグラムのピークは0.5より小さいことから,触覚情報をより信頼していることが分ります.信頼値0~0.2にあるテープ,レンチ,コップを把持しているときには触覚特徴量が顕著である一方.信頼値0.4~0.6にある箱や缶は表面が平らであるために触覚特徴量が小さくなるため,画像情報も使おうとしています.表面が平らな物体の中でも,画像の信頼値が比較的小さいものがあり,それらは物体が大きすぎるために画像からはみ出したオクルージョンが生じているためです.
以上のように,物体の形状,大きや,オクルージョンによって信頼値が切り替わっていることが分ります.
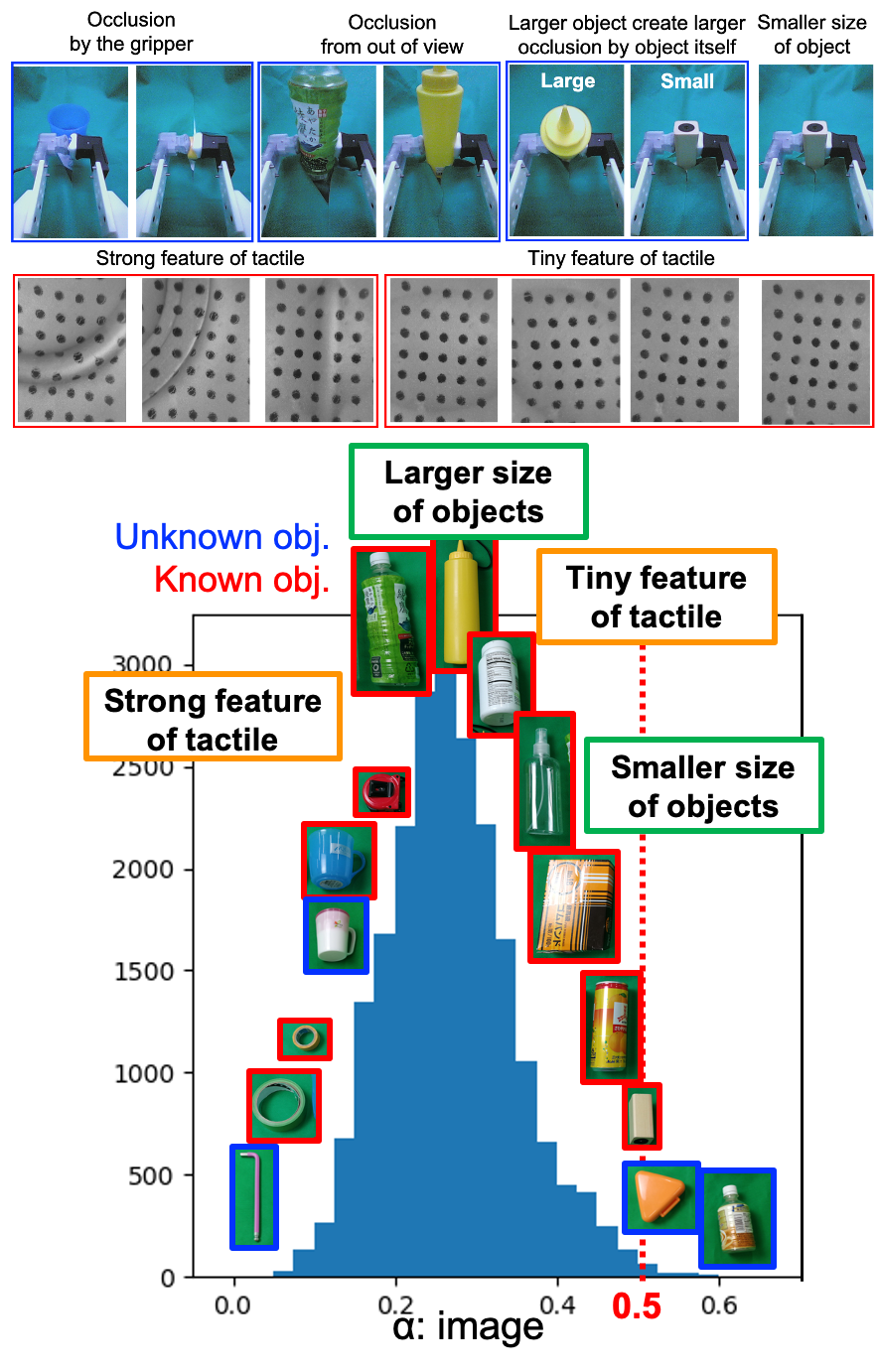
Fig. 4 信頼値αのヒストグラム
評価実験:把持物体の姿勢推定結果
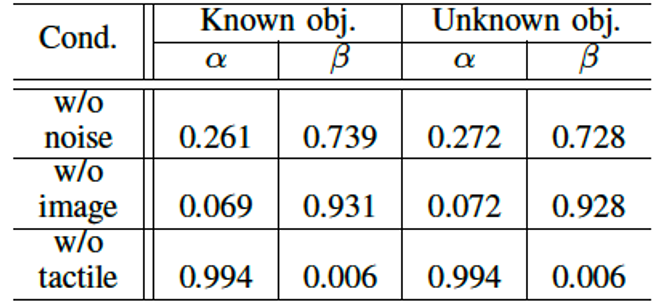
Table 1に画像と触覚のノイズの有無の条件下で,画像だけ,触覚だけ,gateなしで画像と触覚を使う,提案手法の比較した結果を示しています.w/o noiseでの精度から触覚情報が必要であることが分ります.ノイズがない状態ではゲートの有無での性能の差はありません.しかし,片方のモダリティが欠如した状況になると,提案手法の性能が良いことが分ります.Table 2は信頼値の値を示していますが,片方のモダリティが欠如した場合の信頼値が0に近づき,モダリティの入力をほとんど無視していることが分ります.
Table 1 把持物体の姿勢推定の精度
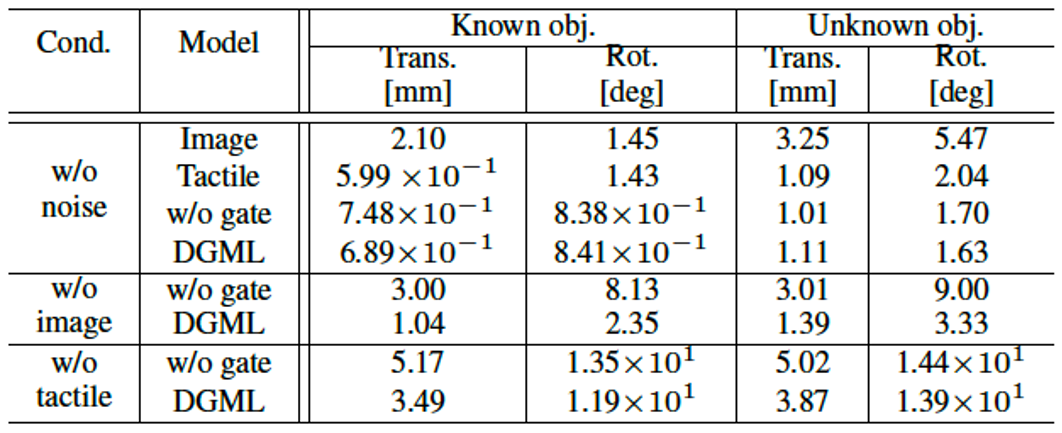 Table 2 信頼値の平均
Table 2 信頼値の平均
まとめ
本研究では把持物体の姿勢推定の実現のため,視覚と触覚を用い,各モダリティの信頼性をネットワークが自己判断する深層学習モデルであるDeep Gated Multi-modal learningを提案しました.このモデルを用いることで,信頼値が物体や状況に応じて変化することが確認できました.
論文に書かれていない裏話:
<データ収集の失敗談>
最初にデータ収集したとき,ARマーカーが取り付けてあるアクリル性の棒を物体にとりつけて,棒を人手で並進回転させたときのARマーカーの姿勢を計測する方法で行っていました.しかし,人手で並進回転をさせるためにデータが安定しなくて,学習は失敗していました.そのため,物体を机に固定させて,ロボットを動かすという方法を行っています.
<触覚センサ>
今回の論文では触覚センサとしてGelSightを利用していますが,当初は他の触覚センサで実験していました.実験では把持している物体の並進回転を行っているために,触覚センサの基板の負荷が大きく.セルが除々に壊れてデータを取得できなくなってしまいました.そのため,光学式のGelSightを使っています.GelSightはカメラを使っているために,分解能が高く,今回の微細な情報を取得するのに適していました.
Area
