Blog
Preferred Networks では、大規模言語モデル PLaMo の開発を継続して行っています。
LLM を開発するうえで、モデルの能力を適切に測定するベンチマークは重要です。英語ではさまざまなベンチマークが日々公開されており、日本語のベンチマークも数多く公開されています。また、私たち自身も新しいベンチマークの構築にさまざまな形で取り組んでいます (pfgen-bench、bbh-ja、Japanese SimpleQA、JFBench)。
最近のベンチマークの多くは、事後学習済みのLLM (以下 aligned model)、特に reasoning model を主な対象にしています。これに対して、pretrained model (以下 base model) を評価するベンチマークの更新はあまり活発ではありません。2025 年 12 月公開の Nemotron 3 Nano の technical report を見ると、base model の評価に使われたベンチマークの大半は 2021 年以前に公開されたもので、最新のものでも 2024 年公開の MMLU-Pro です。一方で、aligned model 向けの評価ベンチマークでは、最も古いものでも 2023 年の SWE-Bench であり、2025 年公開のものも IFBench と AIME25 の 2 件があります。base modelの評価ベンチマークは、LLMという非常に進化の速い分野でありながら、1 年近く新しいベンチマークがほとんど追加されていない状況にあります。
base model 向けベンチマークの更新が少ない背景には、LLM に求められる能力の変化があると考えています。
近年の LLM に求められる能力として、高度な reasoning 能力と、外部ツールを利用するなどして agent として振る舞う能力の 2 つが挙げられます。こうした能力は base model のままでは発揮しにくく、事後学習を経てはじめて性能評価が可能になることが多いです。
しかし、base model の能力測定は依然として重要です。近年の研究では、reasoning 能力の多くは base model の時点で主に獲得されていることが示されています (例)。事後学習後に目標性能に到達できるかを考えるうえで、base model の段階でどの程度の素地があるかを知ることは欠かせません。
現在のところ、base model の能力は次の3つの方法で計測されています。
- 事後学習を行ったうえで、通常のベンチマークを測定する
- few-shot 設定を用いて、base model に reasoning タスクなどを解かせる
- 測りたい能力に関連すると考えられる、既存の base model 向けベンチマークで代用する
1 は最も素直な方法ですが、大きな計算資源と学習時間が必要になることが最大の問題です。また、性能が伸びない原因が事前学習にあるのか、事後学習にあるのかを切り分ける必要があるという問題もあります。
2 は MMLU-Pro のような一部の reasoning ベンチマークでは使われていますが、agent ベンチマークのように few-shot 化が難しいタスクでは適用できません。
3 はそもそも本当に関連する能力を測れているのかが曖昧であり、適切な代替ベンチマークが存在するとも限らないことが問題です。
今回の方針: aligned model向けベンチマークを使ったQ&A生成
今回、aligned model 向けに設計されたベンチマークを、base model の評価に使える Q&A ベンチマークへ変換することで、base model の能力を評価する手法を実験、検証しました。これができれば、毎回事後学習を行わなくとも、base model の時点で将来のベンチマーク性能をある程度見積もれるようになります。
この方向性に近いものとして、APTBenchという論文・ベンチマークがあります。これはbase modelのreasoning や agent 能力を測定する Q&A ベンチマークを構築するフレームワークを提案したものです。APTBench では、以下の手順でQ&A ベンチマークを構築します。
- 測りたい能力に対応するタスクを用意
- LLM がそのタスクをうまく解いたときの思考過程を得る
- 思考過程をもとに Q&A を構成する
APTBench の考え方は非常に有望ですが、
- 測りたい能力に対応するタスクを設計する
- LLM に実際にタスクを解かせて、成功した思考過程を集める
- 思考過程をどのような Q&A に落とし込むか決める
といった部分は、ベンチマークを構築する側に大きく委ねられています。そのぶん高品質なベンチマークを作り込める余地がある一方、ベンチマークごとの構築コストは重くなります。現在の LLM に求められる能力は多岐にわたるため、それら全てに対して作り込みを毎回行うのは現実的ではないと考えています。
そこで、APTBench の手法を踏まえつつ、aligned model 向けにすでに存在しているベンチマークからbase model 向け Q&A ベンチマークをより軽量に作る方法を検討し、実験しました。基本方針は、ベンチマーク構築をできるだけ定型化し、個別対応が必要な部分を限定することです。
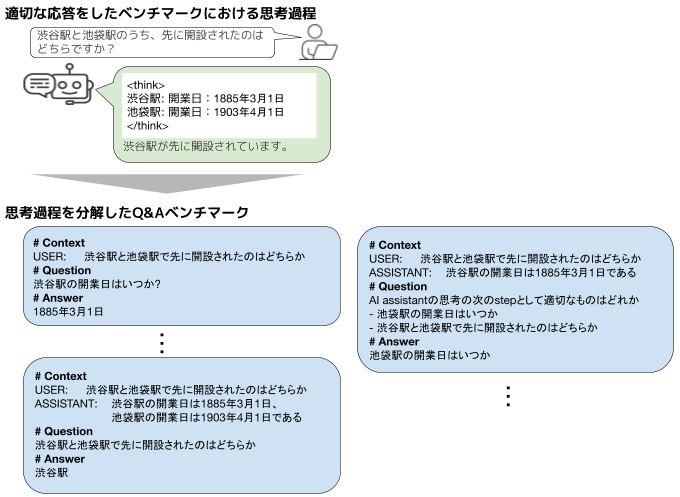
図1: 今回のQ&Aベンチマークの生成手法のイメージ。ユーザクエリはJEMHopQAの問題を参考に作成。
今回のベンチマーク構築の手順は次の通りです。
- 評価したい aligned model 向けベンチマークを決める
- そのベンチマークにおいて、タスクに成功した思考過程を集める
- 思考過程を Q&A ベンチマークに変換する
- base model を few-shot 設定の Q&A ベンチマークで測定する
この方針では、人手が必要なのは「1 でベンチマークを決めること」と「2 で成功した思考過程を得ること」です。とはいえ、もともとのベンチマーク自体を評価する作業や、成功・失敗を判定する作業は、aligned model の評価においていずれにしても必要です。したがって、base model 向け Q&A ベンチマークの追加コストとしては、成功した思考過程を保存する部分が中心になります。
これによって作られた Q&A ベンチマークは、aligned model 向けベンチマークのプロキシとして働くことを期待しています。すなわち、base model 時点で評価した結果やスコアによって、aligned model におけるベンチマーク性能を予測・比較できるようにすることを目指しています。
3 の Q&A 化の具体的な手順を説明します。Q&A化では、思考過程に対して、a) 思考過程を複数のステップに分解する、b) 各ステップをQ&Aの形式に変換する、c) 直前までのuserとの応答や思考過程を要約する、の3つの作業を行います。これにより、思考過程を分解したQ&A (step-level Q&A)を生成できます。このQ&Aは、LLM による answer matching を用いて採点することとしました。
さらに、「次に考えるべきquestionを選ぶ」という問題を作ることで、APT-Benchにおけるplanning能力を測る問題 (planning Q&A)も生成することとしました。planning では、明確な正解を定めにくいため、4 択の選択式問題として Q&A 化しました。
以下では、reasoning タスクとして GPQA diamond を、agent タスクとして tau^2 Bench Telecom を取り上げ、この方法の有効性を調べた結果を紹介します。
実験
実験設定
評価対象のモデルとしては、Qwen3、Llama 3 系列、OLMo 3 系列など、主に 1B から 8B クラスのモデルを用いました。今回の目的は base model の性能比較にあるため、base model が公開されており、比較しやすいモデルサイズを選んでいます。
評価では、作成した Q&A ベンチマークを base model に解かせた結果と、対応する instruction model が元のベンチマークで示す性能との関係を見ました。見たいのは絶対値の一致ではなく、
- 同じモデル系列の中で、より強いモデルほど Q&Aベンチマークのスコアも高くなるか
- モデルをまたいだ比較でも、ある程度妥当な順序になるか
という点です。
結果 1: GPQA diamond
まず、reasoning ベンチマークとして GPQA diamond を見ます。今回の実験では、データセットに含まれる explanation を思考過程として利用し、Q&A 化を行いました。
表1にGPQA diamondのスコアを示します。
| model | aligned model | base model | planning Q&A | step-level Q&A |
| Qwen3-0.6B | 0.283 | 0.268 | 0.312 | 0.548 |
| Qwen3-1.7B | 0.278 | 0.333 | 0.362 | 0.664 |
| Qwen3-8B | 0.480 | 0.333 | 0.362 | 0.804 |
| Llama 3.2 1B | 0.167 | 0.273 | 0.321 | 0.401 |
| Llama 3.1 8B | 0.268 | 0.237 | 0.351 | 0.719 |
| OLMo3 7B | 0.364 | 0.278 | 0.330 | 0.721 |
元の GPQA diamond は、aligned model の評価にはよく使われるベンチマークですが、base model を few-shot でそのまま測るとモデル間の差が見えにくいことがあります。特に、小さめのモデルでは chance rate (0.25) 付近の性能となるため、順位の解釈が難しくなります。実際、今回の測定でも base model のスコアはすべて chance rate 付近であり、信頼できる評価スコアとは言い難い状況でした。
これに対して、思考過程から作った step-level Q&A を用いると、Qwen3-8B や OLMo3 7B が高く、Llama 3.2 1B が低いといった大まかな順序を再現できました。一方、planning Q&Aのほうはどのモデルも0.3〜0.35程度のスコアで、指標としては使いづらいという結果となりました。
この結果から、GPQA diamond のような reasoning task では、長い reasoning をそのまま要求するよりも、思考過程を短い Q&A に分解した Q&A ベンチマークのほうが、base model の比較指標として扱いやすいことがわかります。一方で、モデルをまたいだ厳密な順位付けにはまだ難しさが残っています。原因としては、生成したQ&Aベンチマークに関わるものと、事後学習の差によるものの2つがあると考えています。
違うモデルは事後学習に用いた手法、データセットが異なるため、base modelとaligned modelで傾向が変わる可能性があります。そのため、本来は異なるbase modelに対して同じ手法・データセットで事後学習を行ってから元のベンチマークを評価するべきですが、今回はそこまで実験できておりません。
結果 2: tau^2 Bench Telecom
次に、agent ベンチマークとして tau^2 Bench Telecom を見ます。agent ベンチマークは few-shot 化が難しく、base model の能力をそのまま測るのが特に難しい領域です。今回の実験では、タスク遂行に成功した Qwen3-235B-A22B-Thinking-2507 と gpt-oss-120b の思考過程を保存し、これを用いて Q&A 化を行いました。
表2にtau^2 Bench Telecom での結果を示します。
| model | aligned model | planning Q&A | step-level Q&A |
| Qwen3-0.6B | 15 | 0.310 | 0.822 |
| Qwen3-1.7B | 22 | 0.311 | 0.880 |
| Qwen3-8B | 25 | 0.298 | 0.909 |
| Llama 3.2 1B | 0 | 0.285 | 0.669 |
| Llama 3.1 8B | 16 | 0.292 | 0.872 |
| OLMo3 7B | 13 | 0.297 | 0.870 |
その結果、元の tau^2 Bench Telecomでは Qwen3-8B が最も高く、Llama 3.2 1B が最も低いという大まかな傾向が、今回の step-level Q&A ベンチマークでも再現できました。しかし、GPQA diamondと同様、planning Q&Aはどれも0.3前後のスコアであまり意味のない指標となってしまっています。
一方で、Qwen 3 0.6BとOLMo3 7Bの順序が元のベンチマークとstep-level Q&Aで入れ替わるなど、順序の入れ替わりも見られます。この原因も、GPQA diamondと同様にQ&Aベンチマークそのものに関わるもの、事後学習の違いによるもの、があると考えています。
とはいえ、base model のままではほとんど比較不能だった agent 能力について、定量的なスコアとして比較できるようになった点は重要だと考えています。
まとめ: 事前学習モデルの評価に向けて
本記事では、instruction model 向けのベンチマークと成功した思考過程を利用して、base model 向けの Q&A ベンチマークを構築する方法を紹介しました。APTBench の考え方を土台にしつつ、思考過程の収集以外の部分を定型化することで、reasoning や agent のような現在重要な能力についても、base model 段階で評価できる可能性が見えてきました。
実験・検証結果からは、
- 人による介在・作り込みほぼ無しにaligned model向けの ベンチマークからbase model向けのQ&Aベンチマークを作ることができる
- 生成したQ&Aベンチマークを使うことで、元のベンチマークを base model にそのまま解かせるよりは意味のある評価を行える
ということが言えます。特にagent taskに対する能力について、base modelの時点で定量的なスコアを用いて学習手法やデータセットの良し悪しを議論できるようになったことは重要と考えています。
一方で、生成したQ&Aベンチマークの評価結果を全面的に信用できるか、というとそこまではまだわかりません。特に、今回の評価では、aligned modelにおける事後学習の手法・データセットが異なっているため、base model時点での性能差と事後学習の差を切り分けることができていません。この点を含め、今後の開発の中で知見をためていく必要があると考えています。
仲間募集中
PFNでは今後もLLMの開発を継続して行っていきます。開発は今回紹介した以外にも多岐にわたります。我々はこれらの課題に情熱をもって挑戦していく仲間を募集しています。
これらの仕事に興味がある方はぜひご応募よろしくお願いします。
Area
