Blog
本記事は、2025年夏季インターンシッププログラムで勤務された秋葉凌羽さんによる寄稿です。
はじめに
東京科学大学生命理工学院学士課程3年の秋葉凌羽と申します。PFN の2025年夏インターンシッププログラムに参加し、実験科学分野における AI for Science のためのエージェントワークフローに関する研究に取り組みました。
背景
近年、人工知能(AI)の研究は飛躍的に進展し、その応用範囲は基礎科学から産業まで急速に拡大しています。特に Google の AI Co-Scientist [1] や SakanaAI の AI Scientist v2 [2] などは、科学研究そのものを加速させることを目的としたAIを用いたエージェントワークフローシステムであり、研究のあり方を大きく変える可能性を示しています。
AI の活用は計算機上の解析やシミュレーションにとどまらず、実験科学にも広がりつつあり、さらには仮説を自律的に生成するエージェント [3] や、ロボティクスを用いた自動実験システム [4, 5]など、研究の計画から実行までにAIが直接関与する事例が増えています。
このような動向の中で、新たな技術的課題として「予期せぬ実験結果が得られた際の原因究明の自動化」が浮上しています。従来、研究者は経験と知識に基づいてトラブルシューティングを行い、実験プロトコル上の誤りや改善点を特定してきました。しかし、AI 主導の自動実験システムでは、人間の介入を最小限に抑える必要があり、そのためエラー診断プロセス自体も AI が自動で実施できることが求められます。
AI を用いたトラブルシューティングの重要性は指摘されています[6] が、特化したシステムの構築は行われていません。そこで Laurent らは、プロトコル上のエラー診断能力を評価するためのベンチマークとして ProtocolQA を開発しました [7]。
まず本研究が対象とする「実験プロトコル」について簡単に説明します。生命科学における実験プロトコルとは、試薬の準備から測定までの一連の手順を自然言語で記述した文書のことです。研究者はこの文章を参照して実験を再現しますが、パラメータのわずかな差異(濃度、温度、時間設定など)が結果に大きく影響します。そのため、プロトコルは生命科学分野における再現性を確保するために重要な役割を果たしており、protocols.io [8] などのプラットフォームで共有されています。
本研究では、大規模言語モデル(LLM)を用いたエージェントワークフローを構築し、実験プロトコルを対象としてエラー診断の自動化に取り組みました。これにより、実験科学におけるAI活用による研究の効率性と再現性の向上を目指しました。
方法
データセット
本研究では、前述の ProtocolQA ベンチマーク [7]を使用しました。このベンチマークでは、意図的にエラーを導入した実験プロトコルと、そのエラーによって生じた仮想的な実験結果が提示されます。モデルにはこの状況下でエラーの原因を特定し、適切な修正方法を提案する能力が求められます(サンプルの例を表1に示します)。
| Protocol | Experimental results | Question | Options | Ideal | LLM answer |
| Step 1: Prepare Tricine buffer solution
Step 2: Prepare salt solution using 0.085g NaCl + 50ml water Step 3-7: Blood collection, dilution, and density gradient separation Step 8: Centrifuge at 2000g for 30 minutes to isolate PBMCs Step 9-11: PBMC recovery and washing Step 12-13: Resuspend in storage solution and gradually freeze-store at -80°C |
PBMC count significantly lower than expected | What should be modified to resolve this issue? | A) Change the NaCl quantity to 0.85g in Step 2
B) Do not use any NaCl in Step 2 C) Increase the centrifugation force from 2000g to 5000g in Step 8 D) Store at refrigeration temperature instead of gradual freezing in Step 13 |
A | Selected Option
A + Reason |
表1. ProtocolQA のサンプル例とLLMによる回答例
ProtocolQAの各サンプルは、実験手順を操作単位(ステップ)ごとに分割した構造を持ちます。各ステップは自然言語で記述され、試薬の調製、培養条件の設定、測定などの個別操作を表します。この構成により、モデルはプロトコル全体を逐次的な処理として理解し、特定の手順に注目して推論を行うことが可能です。
まず、GPT-5-mini [9] を用いてベースライン評価を実施し、Laurent らのデータ [7]と合わせて図1 に示す結果を得ました。
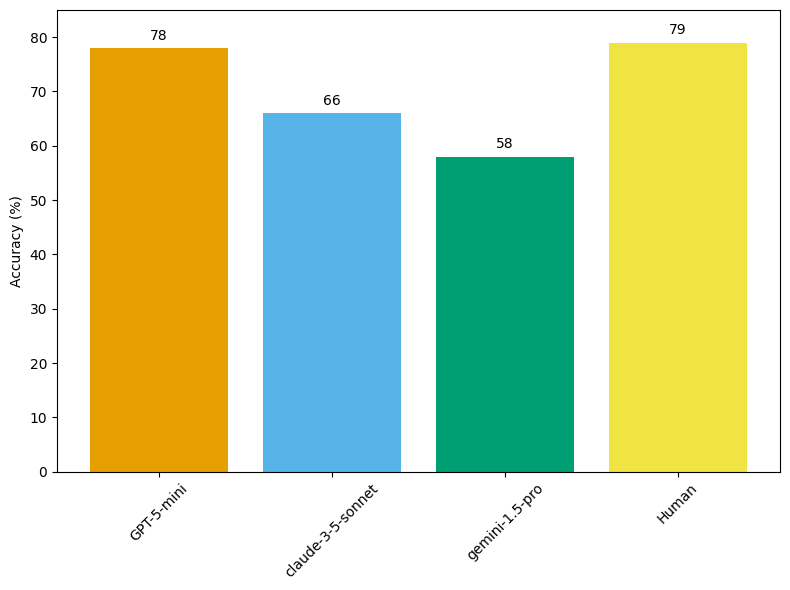
図1. ProtocolQAの各モデルでのAccuracy Score
この結果から GPT-5-mini の回答の Accuracy は Human の専門家の回答と同程度であることがわかり、このタスク上では GPT-5-mini の持つ実験知識が専門家に匹敵することが示唆されています。
データセットの改変
元のベンチマークの問題点
ProtocolQA ベンチマークは専門家によって作成され、問題文や解答は高品質です。しかし、選択肢形式で回答する設計となっており、モデルはあらかじめ提示されたエラー候補の中から正解を選択する形式でした。一方、実際の研究現場では、エラー箇所が事前に限定されることはなく、研究者はプロトコル全体から原因を推論し、該当箇所を特定しなければいけません。このベンチマーク設定と実際の場面との間には乖離がありました。
本研究での変更内容
より実践的な評価を実現するため、本研究では選択肢を撤廃し、モデルがプロトコル全体から直接エラー箇所を特定する形式へとタスクを変更しました(表2参照)。具体的には、システムは全ステップを入力として受け取り、エラーの原因となっている可能性のあるステップを、確信度の高い順にランキング形式で複数提示します。この変更によりタスクの難易度は向上しますが、実際の研究現場の状況をより忠実に反映した評価が可能となります。
将来的には「なぜそのステップが誤りなのか」「どのように修正すべきか」といった説明を含む自由記述形式への拡張も考えられますが、現段階では評価の客観性と定量性を保つため、エラーステップの特定という中間的な形式で実験を行いました。
| Protocol | Experimental results | Ideal step | LLM answer |
| Step 1: Prepare Tricine buffer solution
Step 2: Prepare salt solution using 0.085g NaCl + 50ml water Step 3-7: Blood collection, dilution, and density gradient separation Step 8: Centrifuge at 2000g for 30 minutes to isolate PBMCs Step 9-11: PBMC recovery and washing Step 12-13: Resuspend in storage solution and gradually freeze-store at -80°C |
PBMC count significantly lower than expected | 2 | Selected Option
[2,10,3,4] + Reason |
表2. 改変した ProtocolQA のサンプル例と LLM による回答例
提案エージェントワークフロー
本研究で構築したエージェントワークフローは、実験プロトコルに含まれるエラー要因を特定し、それらの重要度を評価し、ランキングするものです。プロセス全体は、仮説生成、構造化、外部情報による検証、検証結果の評価、ランキング生成の5段階から構成しました。(図2)
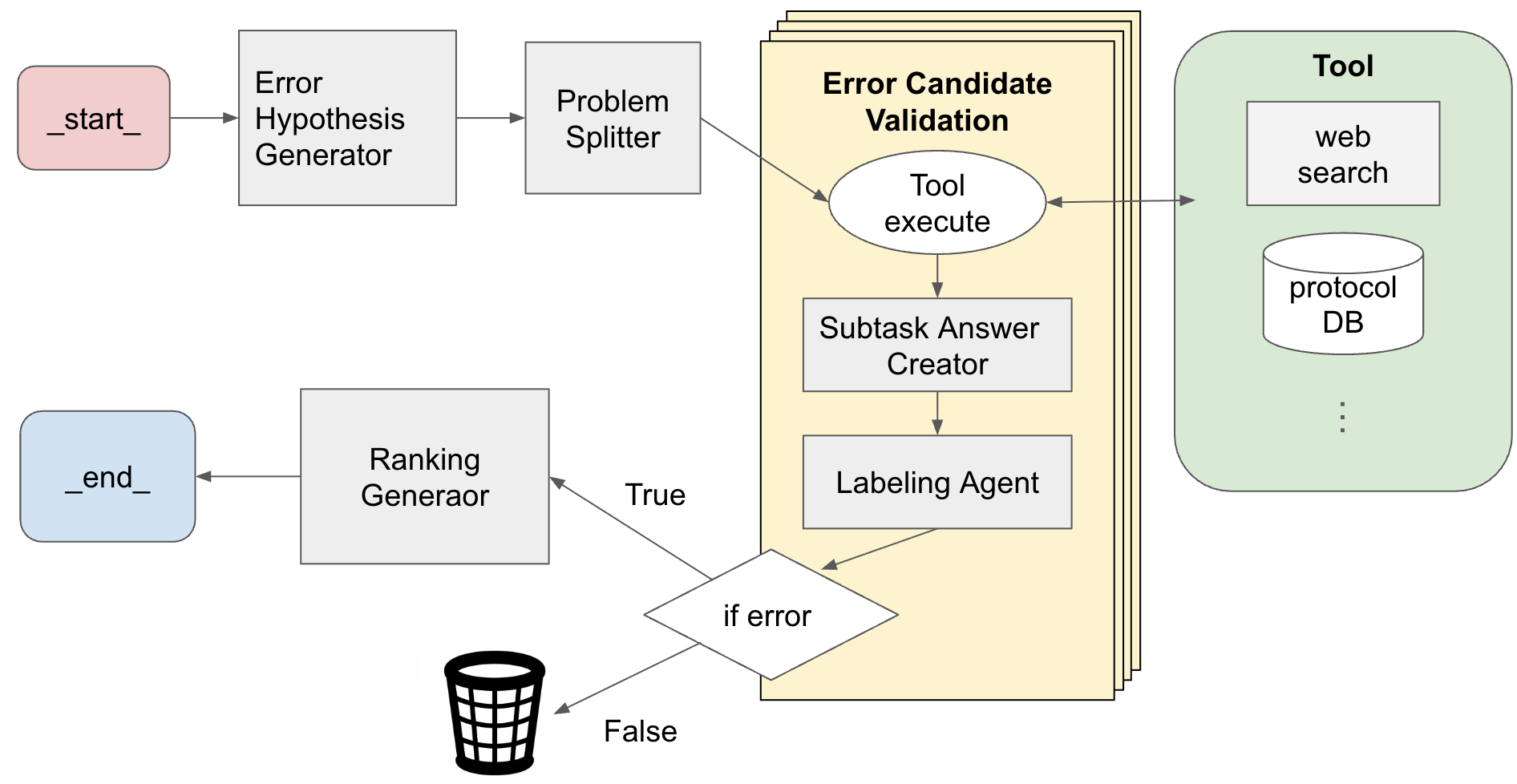
図2. Agents System の概要図
仮説生成: Error Hypothesis Generator
入力として与えられた自然言語の実験プロトコルと実験結果に対して、最初に「Error Hypothesis Generator」が複数のエラー要因候補を生成します。各仮説は、プロトコル内の具体的なステップを指定して「何が」「なぜ」問題であるかを記述する形式としました。
構造化: Problem Splitter
続いて「Problem Splitter」が、各仮説を構造化データに変換します。具体的には、以下の3要素に分解します(表3):
- 対象ステップ (Step)
- 指摘された異常操作 (Original expression)
- 仮説の根拠 (Reason)
この構造化により、問題を個別の検証可能な単位に切り分け、後続のプロセスでは各仮説を並列に検証しました。
| Step | Original expression | Reason |
| 2 | Dissolve 0.085g NaCl in 50 ml water | The instructions specify using only 0.085g NaCl per 100 ml of final solution B. This results in a hypotonic buffered saline solution compared to approximately 150mM NaCl under physiological conditions. This low osmolarity causes hemolysis, reducing the number of recoverable PBMCs. |
表3. 構造化された形式例
外部情報による検証: Tool Execute
構造化された各仮説に対して、「Tool Execute」が外部ツールを用いて検証を行いました。使用ツールは以下の2種類のツールを使用し、各ツール単独での実験と、両方を併用した実験を行っています。
- Vector Search:Protocols.io から作られた BioProBench [10]のプロトコルデータセットを使用しました。各プロトコルを OpenAI の text-embedding-3-small モデル [11]によりベクトル化し、エラー仮説候補とのベクトル検索を実行することで、類似した実験プロトコルを取得します。
- Web Search:OpenAI の組み込みWeb検索ツール[12]を使用しました。Web Search によってサンプルのソース元を確認できないように、プロトコル全文は入力せず、エラー仮説とその根拠のみをクエリとして、判断の裏付けとなる情報を取得することを目指しました。
検証結果の評価: Subtask Answer Creator
Subtask Answer Creator は、「Tool Execute」により取得した外部情報と、元の実験プロトコル全文を参照します。LLM はこれらを基に、各エラー仮説が指摘する操作や条件を検討します。さらに、Vector Search により得られた類似実験条件と比較して実験パラメータの逸脱度を評価し、加えて Web 検索などで取得した文献・知識情報を用いて仮説の妥当性を検証します。
これらの分析を踏まえ、LLM は各仮説に対して、妥当性とエラー原因としての可能性を整理したレポートを生成します。
仮説に対するラベリング: Labelling Agent
「Labelling Agent」は、各エラー仮説を以下の4カテゴリのいずれかに分類します。
- オーダーレベルの誤差
- 数倍レベルの誤差
- 判断不可能
- エラーとは無関係
分類時には、カテゴリ選定の理由を明示し、根拠とともに出力します。
仮説のランキング生成: Ranking Generator
「Ranking Generator」は、ラベリングの結果、エラーとは無関係と判断されたもの以外を対象とし、各仮説をランキング付けして出力します。
Self Mixture-of-Agents
本システムでは、同一構成のエージェントワークフローを実行しても出力にばらつきが生じました。特に仮説生成段階の差異が最終ランキングに影響しています。GPT-5系列は現時点(2025/10時点)で Temperature パラメータの制御が未実装で、出力の安定化が難しいです。
実行ごとに多様な結果が生成される場合には、複数回の出力を統合して安定性と網羅性を高めるSelf Mixture-of-Agents(MoA)[13] が有効です。本研究では、同一構成のエージェントワークフローを3回実行し、その結果を統合しました。
各実行で得られた仮説とラベルを結合し、3回分のエラー仮説分析結果を統合してからRanking Generator を1回だけ適用しました。
評価
本研究では、モデルが出力するエラー候補リストの正確性と出力特性を評価することを目的とし、2つの指標を設定しました。エラー特定タスクでは、単一の回答ではなく、モデルによって確信度順にランキングして複数のステップを出力します。そのため、出力の上位に正解が含まれるかどうかを評価する指標が必要となります。また、モデルが過剰に多くの候補を提示する場合、実用的なエラー診断としての価値は低下します。したがって、出力リストの長さも考慮する必要があります。
以上の観点から、以下の指標を採用しました。
- Hit@N:出力リストの上位N件以内に正解が含まれる割合
- AveListLen:モデルが出力する候補リストの平均的な長さ
Hit@N は精度的側面を、平均リスト長は実用性の側面をそれぞれ評価するものです。この2つの指標を併用することで、モデルの正確さと実用的妥当性を評価できます。
記号の定義
評価対象のデータセットは、全体でM件のサンプルから構成されているとして、各サンプル\(i \in \{1, \ldots, M\}\)に対して、次のように定義します。
- \(y_i \in N\)
正解ステップの整数値 - サンプル i に対するエージェントワークフローの出力であるエラーリストを、
\(Li = (l_{i,1}, l_{i,2},…l_{i,k_i})\)
として、出力された順位付きのエラーリストを表ます。(各\(l_{i,j} \in N\)) - \(k_i = |L_i|\)
リスト\(L_i\)の長さ
Hit@N
Hit@N は、各出力のリスト\(L_i \)の先頭N件以内(ただし、\(k_i < N \)の場合は全件)に正解ラベル\(y_i \)が含まれているかどうかを判定し、それが真であるサンプルの割合として定義します。
各サンプルについて、上位N件を以下のように表記します。
\[ Top(L_i, N) = {l_{i,1}, l_{i,2},…,l_{i,min(N,k_i)}} \]
これを用いて、Hit@N を定義します。
\[ Hit@N = \frac{1}{M} \sum_{i=1}^M \mathbb{1}(y_i \in Top(L_i, N)) \]
ここで、\(\mathbb{1}(\cdot) \)は、条件が真であれば1、偽であれば0を返す指示関数です。
AveListLen
出力リストの \( k_i\) のリスト長の平均を次のように定式化します。
\[ AveListLen = \frac{1}{M} \sum_{i=1}^M k_i \]
例外応答のための多数決統合
提案エージェントワークフローでは、各サブエージェントが要求フォーマットに従わない応答(例:要素の欠落、または倫理的理由による回答拒否)を返す場合が確認されました。これらの無効応答をすべて不正解として扱うと、ZeroShot 実行との性能差はほとんど見られませんでした。しかし、形式的に有効な応答のみを抽出して評価すると、提案ワークフローの方が一貫して高い正答率を示す傾向が確認され、無効応答を返すサンプルでも、同一ワークフローを複数回実行すると有効出力が得られる場合が多く、出力の安定性には反復実行による改善余地があることが分かりました。
以上を踏まえ、同一条件下でワークフローを複数回実行し、各試行で得られた有効出力を多数決的に統合することで最終結果を機械的に算出しました。なお、比較対象として用いた ZeroShot の回答についても、同一の手法で処理を行っています。
ワークフローを用いない ZeroShot 実行では例外応答はほとんど発生しませんでしたが、提案エージェントワークフローの実行では1回の実行あたり約2%(1/52)から43%(35/52)の回答で無効な応答が生成されました。ただし、3回の試行内で有効な応答が一度も得られなかったケースは約2%(1/52)にとどまったため、多数決統合、MoA の結果に対する議論への影響は少ないと判断しました。
現時点では詳細な検証は行っていませんが、構造化出力を用いることで形式的な例外応答の多くは抑制できると考えています。一方で、評価指標に影響を与える可能性もあるため、これについては今後の検証課題としました。
結果
今回の実験では、全ての実行に GPT-5-mini を使用しました。
まず、ベースラインとする数値を得るために GPT-5-mini を単体で用いた結果を表4に示します。ZeroShot 実行(GPT-5-mini)と、Vector Search を利用した構成(GPT-5-mini-VectorSearch)で評価を行いました。Web Search を利用した実行は、単純な実装では検索時に正解がリークする可能性を考慮して行いませんでした。また、その応答結果を多数決で統合したものを表5 に示します。
| 条件 | 使用ツール | Hit@1 (Std) | Hit@2 (Std) | Hit@3 (Std) | AveListLen |
| GPT-5-mini | 未使用 | 0.37 (0.08) |
0.49 (0.04) |
0.57 (0.02) |
6.69 |
| GPT-5-mini- VectorSearch |
Vector Search | 0.39 (0.01) |
0.57 (0.01) |
0.61 (0.03) |
6.58 |
表4. ベースライン実行結果: ProtocolQA の実行結果を示しています。いずれもエージェントワークフローを用いずに GPT-5-mini で実行しました。GPT-5-mini は ZeroShot 実行、GPT-5-mini-VectorSearch は Vector Search を用いて回答しました。括弧内は標準偏差を表します。
GPT-5-mini の単体実行では分散が大きく、出力が安定していませんが、Vector Search を使用すると標準偏差の値が比較的小さくなりました。
次にこの結果を多数決統合した結果を表5に示します。
| 条件 | 使用ツール | Hit@1 | Hit@2 | Hit@3 | AveListLen |
| GPT-5-mini- Vote |
未使用 | 0.40 | 0.52 | 0.58 | 10.10 |
| GPT-5-mini- VectorSearch- Vote |
Vector Search | 0.42 | 0.54 | 0.65 | 7.67 |
表5. ベースライン結果の多数決統合: ProtocolQA の実行結果を示しています。いずれもエージェントワークフローを用いずに GPT-5-mini で実行した結果を多数決で統合したものです。
多数決統合により、全体的に指標は向上し、傾向は維持されました。
次に、提案したエージェントワークフローを適用した結果を表6–8および図3–5に示します。図3は単体実行、図4は多数決統合、図5はMoA構成の結果である。これにより、エージェントワークフロー、外部情報追加、統合方式の違いが性能に与える影響を考えます。
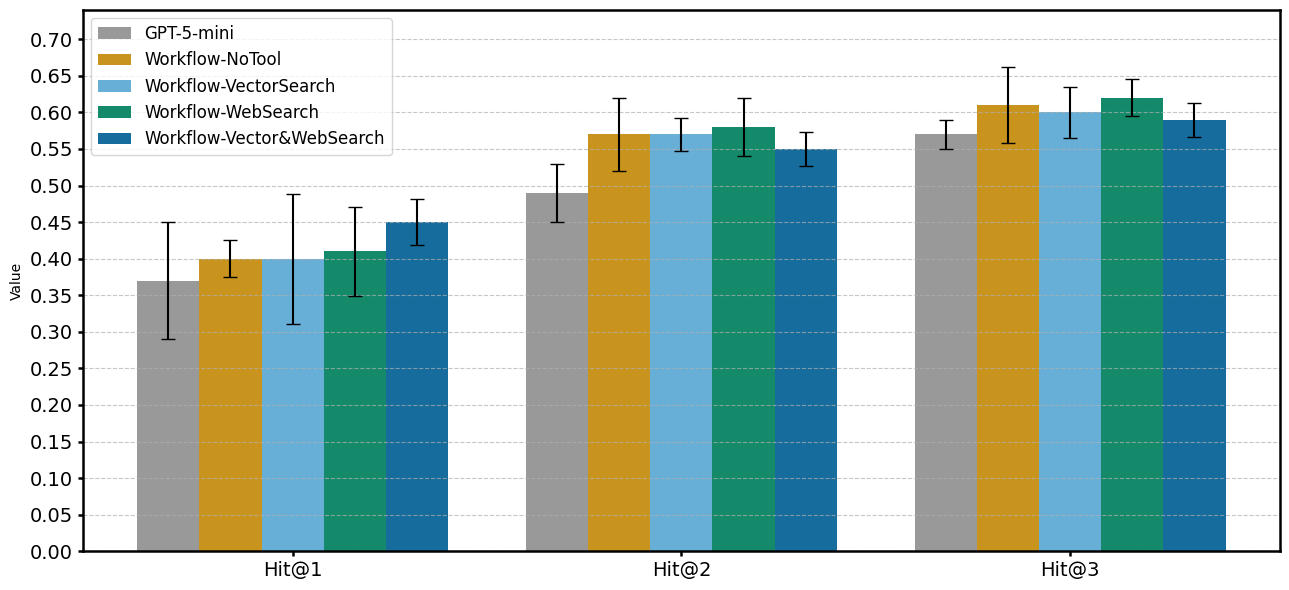
図3. 単体実行の実行結果比較
単体実行(図3)では全条件で Hit@N 中央値は GPT-5-mini を上回ったが、例外応答を不正解として扱っているため、改善幅は限定的でした。
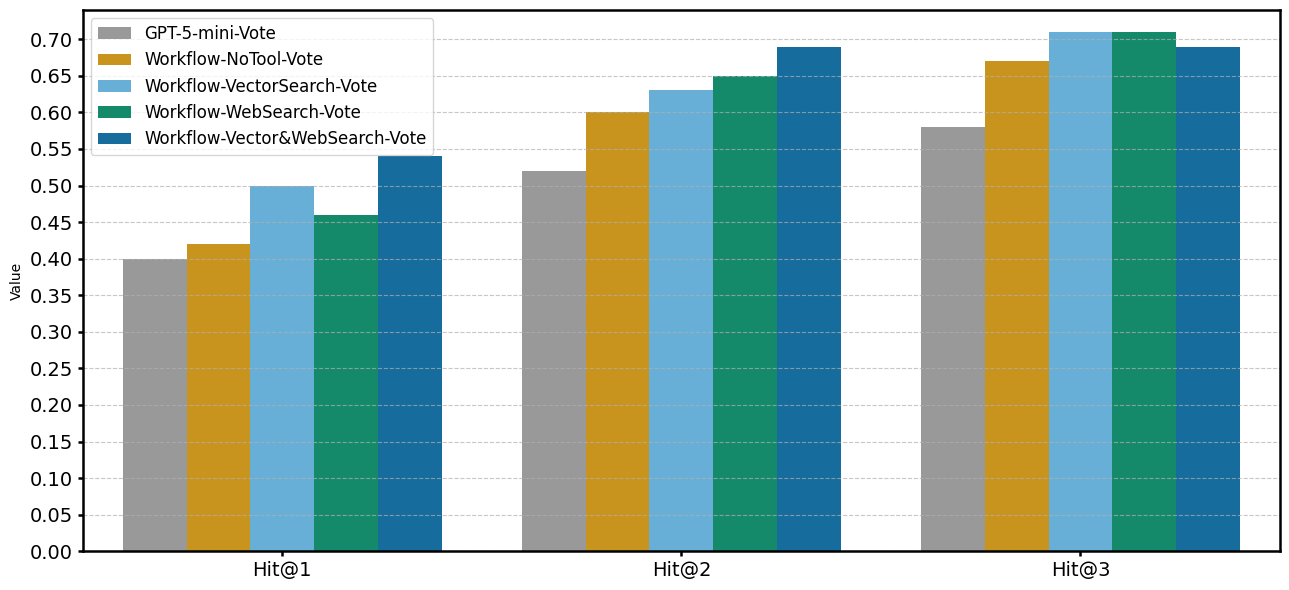
図4. 多数決統合の実行結果比較
多数決統合(図4)では、単体実行と比較して、エージェントワークフローによる結果全体的に Hit@N が上昇しました。特に Hit@2, Hit@3 の指標でエージェントワークフローでの実行がベースライン(GPT-5-mini-Vote)よりも明確に高い性能を示しました。
エージェントワークフロー間での結果を比較すると、Hit@3 では他の指標に比べてツール間の差がほとんどなく、ツールの単独使用の構成がツール併用構成を僅かに上回りました。
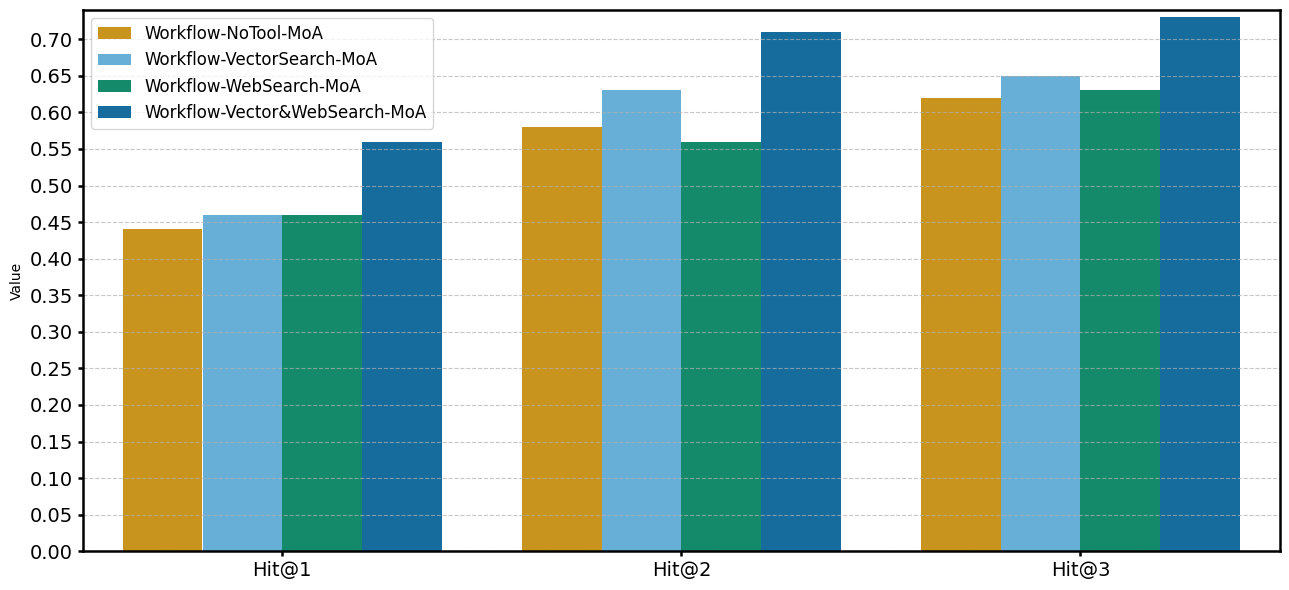
図5. MoAの実行結果
MoAでは、ツールを併用した場合に最高の Hit@N を示しました。 特にWorkflow-Vector&WebSearch-MoA が Hit@N の指標においては全体で最も高い性能を示していました。
それ以外の構成では、多数決統合よりも低い結果が得られました。また、Hit@2 では Web Search 構成がツール未使用構成を下回る結果が見られ、MoA における情報統合が一部の条件で不安定に働いた可能性があります。
考察
本研究で提案したエージェントワークフローは、ベースラインである GPT-5-mini の ZeroShot 実行の結果(GPT-5-mini Hit@1: 0.37, Hit@2: 0.49, Hit@3: 0.57, AveListLen: 6.69)と比較して、一貫して高い精度を示しました。特に、最高性能であった Vector Search と Web Search を併用した MoA 構成(Workflow-Vector&WebSearch-MoA)では、Hit@1 で0.56、Hit@2 で0.71、Hit@3 で0.73に向上し、また AveListLen も4.18まで減少させることができました
この結果は単一モデルによる出力よりも、LLM を用いたエージェントワークフローによってエラー候補を明確に切り出し、外部知識を根拠として再検証するエージェントワークフローが有効に機能したことを示唆しています。
エージェントワークフロー導入による基礎性能の向上
まず、ベースラインである GPT-5-mini-Vote と、外部情報を使わずにエージェントワークフローのみを導入した Workflow-NoTool-Vote を比較すると、Hit@3 は0.58から0.67へと上昇しました。プロトコルのエラー発見を一度に処理させるよりも、仮説生成、検証、評価といった段階を明示的に設けて分割することで、個々の推論タスクの複雑度が低減され、外部知識の導入がなくとも結果として全体の精度向上につながったと考えられます。
しかし Hit@1 では大きな改善は見られず、一つのみの答えを選ぶようなタスクでの精度はこのように知識追加がないワークフローでの向上は困難であることがわかりました。
外部情報利用の効果
外部情報の活用方法においても、エージェントワークフローの優位性が示されました。
RAG を用いた単純な実装(GPT-5-mini-VectorSearch)では、プロトコル全体に対して類似文書を検索し、その情報を参照しながら回答を生成します。一方の提案手法では、まずエラー候補となる特定の操作を抽出し、その操作単位で類似プロトコルを検索するというタスクの分割を意識して実装しました。
GPT-5-mini-VectorSearch-Vote と Workflow-VectorSearch-Vote を比較すると、全ての指標でワークフローを導入したものが上回りました。問題となる操作を切り出してから関連情報を検索することで、より精度の高い類似事例の取得が可能になったことが示唆されます。
また、Vector Search単独でも明確な性能向上が見られましたが、Web Searchとの併用構成(Workflow-Vector&WebSearch)でより良い性能を達成しました。これにより、Vector SearchとWeb Searchの相補的な効果が示唆さました。図 6では各ツールが対応可能な問題に差異があることを示しており、ツールを併用することで解決可能な問題数が増加していることが確認できました。
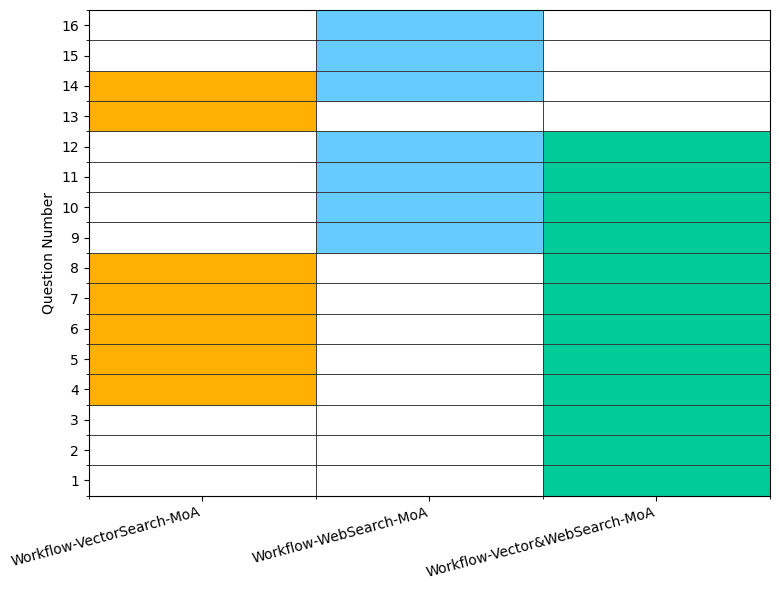
図6 ツール間で正解する問題の比較: MoA の構成で \(Top(L_i, 1) \)の結果に差異があったものを示しています。
また、特に多数決的統合では Hit@3 の時点で各ツール間での精度差がかなり小さくなっており、更なる向上のためにはその他の情報源や既存のツールの使用方法が必要であると考えられます。
MoA による安定化
MoA 構成は、機械的に行う出力の平均化ではなく、各エージェントワークフローの結果を保持したうえで、LLM によって統合を行う手法として設計しました。ここでは多数決統合との比較により、MoA の効果を評価しました。
ツール構成によって結果は大きく異なりました。まず、外部ツールを使用しない Workflow-NoTool や、Web Search、Vector Search を単独で利用する構成では、単体実行との差はあまり見られず、一部ではHit@Nが低下し、多数決統合の方が一貫して高い精度を示しました。これらの理由として、ツールを単体で使用する場合、各実行が類似した情報を入力として処理するため、出力の多様性が得られにくく、その結果、同質的な出力を統合することで推論が曖昧化し、精度低下を引き起こした可能性が考えられます。
一方で、Vector Search と Web Search を併用した Workflow-Vector&WebSearch-MoA では、全体で最も高い性能が得られました。複数の情報源を併用することで、各実行間に十分な出力の多様性が生じ、MoA による統合が効果的に働いたと考えられます。
この結果から、MoA 構成の有効性は入力多様性に依存している可能性があり、必ずしも安定化をもたらさず、むしろ性能を劣化させることがあるとわかりました。ただし、本研究では各実行間の入力内容や出力分布を定量的に分析しておらず、精度変動の要因を明確に特定していません。
Self Mixture-of-Agents の項で述べたとおり、本研究の初期の実験での出力の多様化からMoA の実装を決定しましたが、最終的に実装したタスクを分割するエージェントワークフローや、ツールの効果から出力の多様性が減少し、MoA が有効に機能していないことが考えられます。しかし、Workflow-Vector&WebSearch-MoA で見られた顕著な向上から、多様な情報源を前提とする条件下では本手法が有効に機能することが示唆されており、異なる外部ツールや GPT-5-mini 以外のモデルを組み合わせ、出力の多様性を向上させることで、MoAの統合効果を最大化できる可能性があります。
出力効率と実用性
提案ワークフローでは精度を保ちながら候補リストを短縮できており、過剰な出力を抑制しつつ、実験者が確認するべき候補を効率的に提示できることを確認しました。特にこのベンチマークにおいては、上位2つまでエラー候補の検討によって70%以上の確率で原因の特定が可能なことを示しました。
課題
実験リソースとコスト
提案ワークフローは精度向上に寄与しましたが、処理時間とコストが増大しました。ZeroShot 実行では1問あたり約1分、約0.005ドルであったのに対し、エージェントワークフローでは外部検索を除いて約3分、約0.1ドル、Web Search を含む構成では約0.7ドル必要であった。さらに多数決統合やMoAでは各試行を3回行うため、総コストは約3倍に増加した。研究規模の拡大に向けては、ワークフローの効率化や軽量モデルの仕様が必要であると考えられます。
ベンチマーク設計上の限界
使用した ProtocolQA ベンチマークは生命科学実験の一部領域に限定されており、網羅性には限界があります。また、本研究ではエラーを含むステップの特定のみを正解指標としており、理由の妥当性までは検証していません。詳細な分析のためには専門家による評価や、 LLM-as-a-judge[14] の導入が必要であります。
出力多様性の不足
本研究ではすべての段階で GPT-5-mini を用いました。そのため、異なるアーキテクチャや学習データを持つモデルを組み合わせることで、仮説生成や検証過程の多様性を高め、MoA 構成における統合効果をさらに強化できると考えられます。
例外応答の制御
例外応答の対応の項で述べたとおり、1度の実行では有効な回答の生成ができない場合があり、例外の発生を防止するために構造化出力が有効であると考えています。
エージェントワークフローの改善
現行システムでは、初期の仮説生成段階で有効な仮説を出力できない場合、以降の検証過程に進めず精度が著しく低下します。この問題を軽減するためには、仮説生成時に外部知識を動的に参照する仕組み、またはワークフロー完結後に仮説の生成に戻る生成プロセスが有効であると考えています。
結論
本研究では、実験プロトコルにおけるエラー要因の自動特定を目的としたエージェントワークフローを構築し、その有効性を示しました。仮説生成、外部情報による検証、ラベリング、ランキングからなるエージェントワークフローを導入することで、単一モデルによるZeroShot の推論よりも安定して高精度な結果が得られました。
参考文献
[1]: Towards an AI co-scientist, Gottweis et al., 2025, arXiv, https://arxiv.org/abs/2502.18864
[2]: The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search, Yamada et al., 2025, arXiv, https://arxiv.org/abs/2504.08066
[3]: Robin: A multi-agent system for automating scientific discovery, arXiv, Ghareeb et al., 2025, https://arxiv.org/abs/2505.13400
[4]: BioMARS: A Multi-Agent Robotic System for Autonomous Biological Experiments, Qiu et al., 2024, arXiv, https://arxiv.org/abs/2507.01485
[5]: Robotic search for optimal cell culture in regenerative medicine, Kanda et al., 2022, eLife 11:e77007
[6]: Automating care by self-maintainability for full laboratory automation, Ochiai et al., Digital Discovery, 2025, 4, 10.1039/D5DD00151J
[7]: LAB-Bench: Measuring Capabilities of Language Models for Biology Research, Laurent et al., 2024, arXiv, https://arxiv.org/abs/2407.10362
[8]: protocols.io, https://www.protocols.io/
[9]: GPT-5 System Card, OpenAI, https://openai.com/ja-JP/index/gpt-5-system-card/
[10] BioProBench: Comprehensive Dataset and Benchmark in Biological Protocol Understanding and Reasoning, Liu et al., 2025, arXiv, https://arxiv.org/abs/2505.07889
[11]: text-embedding-3-small, OpenAI, https://platform.openai.com/docs/models/text-embedding-3-small
[12]: Web search, OpenAI, https://platform.openai.com/docs/guides/tools-web-search?api-mode=responses
[13] Rethinking Mixture-of-Agents: Is Mixing Different Large Language Models Beneficial?, Li et al., 2025, arXiv, https://arxiv.org/abs/2502.00674
[14]: Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena, Zheng et al., 2023, https://arxiv.org/abs/2306.05685
Appendix
| 条件 | 使用ツール | MoA | 多数決統合 | 単体実行 |
| Workflow-NoTool | 未使用 | 7.12 | 8.55 | 5.88 |
| Workflow- VectorSearch |
Vector Search | 4.48 | 6.12 | 4.26 |
| Workflow- WebSearch |
Web Search | 4.40 | 6.10 | 4.08 |
| Workflow- Vector&WebSearch |
Vector Search, Web Search |
4.18 | 5.82 | 4.20 |
表6 AveListLenの比較: 各条件における平均リスト長(AveListLen)を示しています。縦軸のラベルは外部ツール構成を表します。横軸のラベルはエージェントワークフローの統合方式を示す。MoA:Self-Mixture-of-Agents 構成。3回の独立実行を統合。多数決:3回の実行結果を多数決的に統合。単体実行:3回の単独エージェントワークフローの平均値。
| 条件 | 使用システム | 使用ツール | Hit@1 (Std) | Hit@2 (Std) | Hit@3 (Std) |
| Workflow- NoTool |
単体実行 | 未使用 | 0.397 (0.025) | 0.567 (0.050) | 0.610 (0.052) |
| Workflow- VectorSearch |
単体実行 | Vector Search | 0.400 (0.089) | 0.573 (0.023) | 0.597 (0.035) |
| Workflow- WebSearch |
単体実行 | Web Search | 0.410 (0.061) | 0.580 (0.040) | 0.623 (0.025) |
| Workflow- Vector&WebSearch |
単体実行 | Vector Search, Web Search | 0.453 (0.031) | 0.553 (0.023) | 0.587 (0.023) |
表7 Hit@Nの比較: 単体実行における各条件における Hit@N (N=1,2,3) を示しています。
| 条件 | 使用システム | 使用ツール | Hit@1 | Hit@2 | Hit@3 |
| Workflow– NoTool–MoA |
MoA | 未使用 | 0.44 | 0.58 | 0.62 |
| Workflow- NoTool-Vote |
多数決 | 未使用 | 0.42 | 0.56 | 0.67 |
| Workflow- VectorSearch-MoA |
MoA | Vector Search | 0.46 | 0.63 | 0.65 |
| Workflow- VectorSearch-Vote |
多数決 | Vector Search | 0.46 | 0.63 | 0.69 |
| Workflow- WebSearch-MoA |
MoA | Web Search | 0.46 | 0.56 | 0.63 |
| Workflow- WebSearch-Vote |
多数決 | Web Search | 0.46 | 0.67 | 0.71 |
| Workflow- Vector&WebSearch- MoA |
MoA | Vector Search, Web Search | 0.56 | 0.71 | 0.73 |
| Workflow- Vector&WebSearch- Vote |
多数決 | Vector Search, Web Search | 0.54 | 0.69 | 0.69 |
表8 Hit@N の比較: 多数決統合と MoA の各条件におけるHit@N (1,2,3) を示しています。MoA:Self-Mixture-of-Agents 構成。3回の独立実行を統合。多数決:3回の実行結果を多数決的に統合。単体実行:3回の単独エージェントワークフローの結果。
