Blog
本記事は、2023年夏季インターンシッププログラムで勤務された上原祐輝さんによる寄稿です。
背景
商品の購入数予測は重要
近年、小売業界ではDXが進み、多くのビジネスプロセスが効率化されています。その中で、特に購入数予測は企業の競争力を左右する重要な要素となっています。購入数予測とは、過去のデータやトレンドを元に、将来の商品の購入数や需要を予測することを指します。正確な購入数予測は、在庫の無駄を削減し、商品の売り切れリスクを減少させるだけでなく、適切な価格設定を可能にし、利益の最大化に寄与します。
PFNにおいても購入数予測に取り組んでいますが、これまでのモデルでは商品間の需要の食い合いを捉えられていませんでした。そこで、本インターンシップでは需要の食い合いを考慮した商品の購入数予測モデルの開発に取り組みました。
既存モデルの問題点
購入数の予測において、最も基本的なアプローチの一つが各店舗や商品を独立した単位としてモデル化する独立モデルです。このモデルでは、異なる店舗や商品間で購入数に相関関係が存在しないと仮定します。すなわち、ある商品の購入数が多いからといって、別の店舗で別の商品が売れるわけではないという考え方です。
しかし、この仮定には2つの問題点があります。
第一に、実際の小売業界においては店舗や商品間で相関が存在する場合が少なくありません。例えば、ある地域でのイベントや季節の変わり目によって、複数の店舗で同じカテゴリの商品が同時に売れることが考えられます。このような関連性を無視することで、モデルの予測精度が低下する可能性があります。
第二の問題点として、各店舗・商品ごとに独立したモデルを構築することで、利用可能な学習データの量が限られてしまうことが挙げられます。特に、販売実績の少ない新商品やニッチな商品の場合、十分なデータを集めることが困難です。実際に、PFNにおける既存の独立モデルでは、学習データが10件以下の商品が全体の20%を占めており、学習が難しい状況となっています。
この問題を解決するためには、店舗や商品間の独立性を仮定しないモデルを考慮する必要があります。似た特性を持つ他の店舗や商品のデータを活用して学習を行うことで、データの量を増やし、予測精度の向上を図ることができます。このアプローチにより、相関関係を考慮し、データの少ない商品や店舗に対して、予測精度の向上が期待できます。
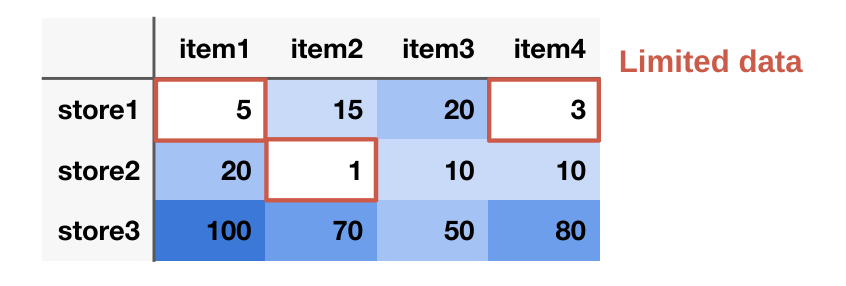
店舗間のデータ共有の難しさ
しかし、店舗間でのデータ共有は容易ではありません。その理由は、店舗ごとの品揃えの違いが顧客の選択肢や購入傾向に影響を及ぼし、結果として売上に大きな差が出るからです。例として、おにぎりの品揃えについて考えてみます。店舗Aでは、鮭のおにぎりのみ一種類しか取り扱っていないのに対し、店舗Bでは鮭、梅、塩の三種類のおにぎりがあります。店舗Aではおにぎりの選択肢が鮭しかないため、需要が集中して売上が大きくなることが予想されます。一方、店舗Bでは鮭のおにぎりの売上が、他のおにぎりとの競合により低下することが予想されます。データを店舗間で共有する際には、このような、売り切れや店舗の違いによる品揃えの違いが売上に及ぼす影響を考慮することが求められます。
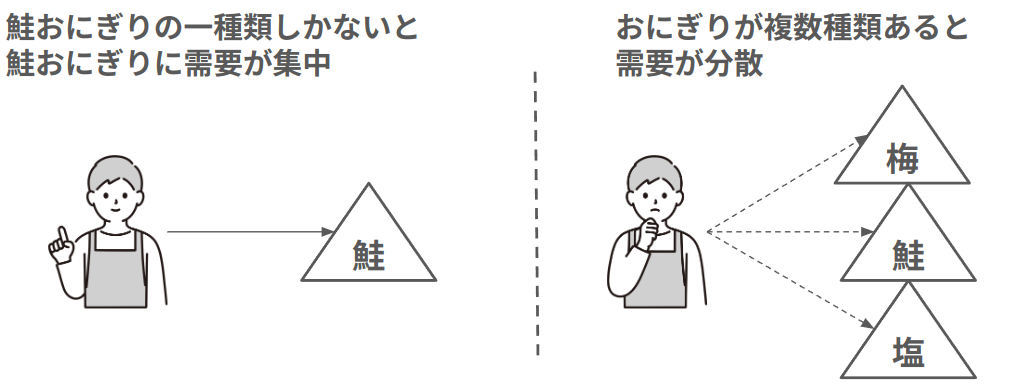
ここまでの議論を踏まえ、本インターンシップでは以下の2つの仮説を立てました。
- 商品には「商品が売り切れていると類似商品を購入する」、「商品が増えると別の商品に需要が流出する」といった食い合いの相関関係がある。
- 商品間の相関関係は店舗によって変化しない。
そしてこれら2つの仮説をもとに、商品間の需要の食い合いを確率モデルで表現し、店舗間でデータを共有することで精度向上を図るという取り組みを行いました。
提案手法
商品同士の需要の食い合いをモデル化

商品間の食い合いを考慮した購入数予測モデルを提案しました。このモデルは熱拡散モデルを元にしており、その特性を反映して「HeatDiffusion」と名付けました。
このモデルでは、Mは流入流出行列を示し、その各要素は、ある商品から別の商品への流出割合を表現しています。λは商品が1つのみ存在する場合の1人当たりの購入数を示すパラメータです。特定の商品が値引きされた影響をMを考慮することが可能です。 また、モデルの入力は在庫がある商品についての割引率と特徴量となっており、これによって品揃えの違いを考慮した予測が可能となっています。モデルの主な特徴として、商品間の相互作用を機能バイアスとして明確に組み込んでいる点が挙げられます。これにより、特定の商品の市場への影響や、商品間の関係性を直観的に理解することが可能となります。 このような部分的な構造を有するモデルは「グレーボックスモデル」として知られており、データが限られた状況下でも汎化された予測を可能とします。
仮定
以下にHeatDiffusionの仮定を明示します。
- リアルタイムの在庫情報: モデルはリアルタイムの在庫情報を利用します。これにより、品切れの商品に対しては流入が0とされ、その結果として他の商品への流出が増加すると予測されます。
- 商品の相関関係の店舗間共有: 各店舗は商品間の相関関係を共有しています。これにより、一つの店舗での学習結果が他の店舗の予測にも役立てられると考えられます。
- 店舗間の違い: それぞれの店舗における違いは、主に来客数や来店者特性から生じると仮定します。
- ポアソン分布に基づく推定: 商品の購入数はポアソン分布に従うと仮定し、この分布の期待値を利用します。
具体例
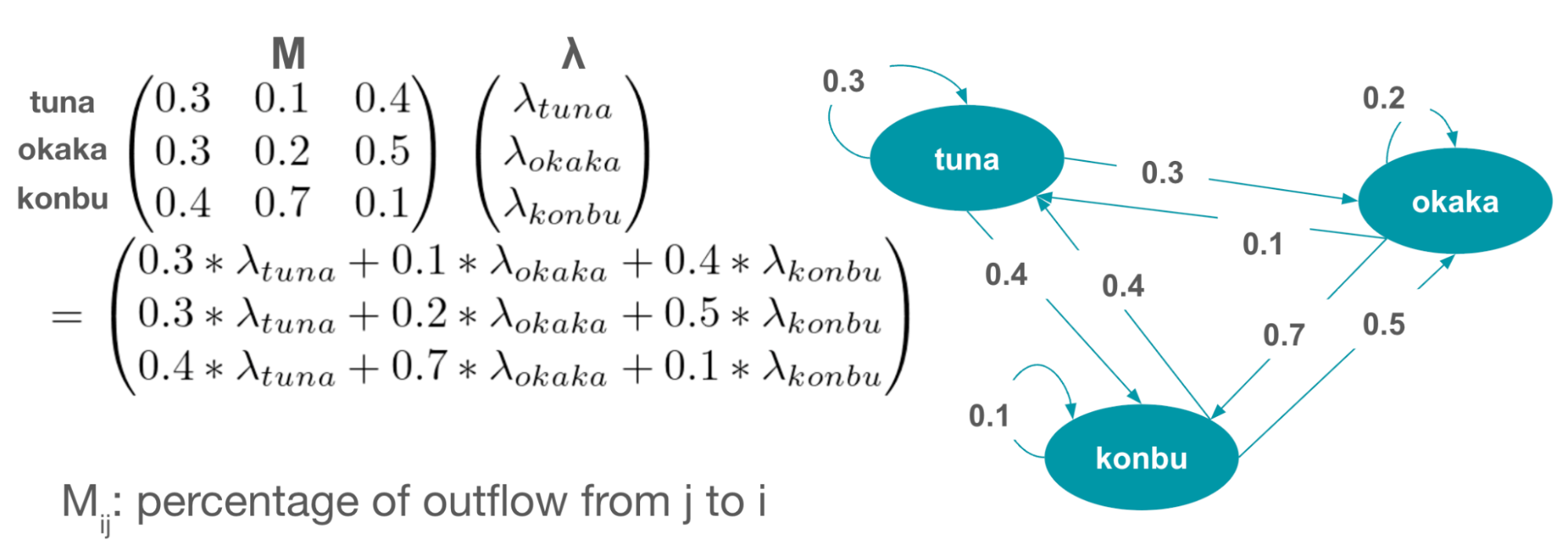
具体例を用いて予測値の計算方法を説明します。Mλの結果を見ると、商品の購入数の一部が他の商品に流出している様子が確認できます。例えば、tunaの場合、自身の一人当たり購入数の30%が残り、それに加えてokaka、konbuの一人当たり購入数が流出してきています。(okakaから10%、konbuから40%)
実験
実験設定
- データ: パートナー企業のPOSデータを利用
- 予測対象: 14店舗の購入数の多かった30商品の一人当たり購入数
- 比較手法:
- Baseline: 値引き率補正済の店舗・商品毎の平均値。この手法は店舗ごと、商品ごとに予測を行うため、店舗間の商品集合の違いや商品間の需要の食い合いを考慮していません。
- Transformer: 商品の食い合いを考慮しない単純なTransformer。この手法は店舗間の商品集合の違いは考慮していますが、商品間の需要の食い合いを明示的には考慮していません。
- HeatDiffusion:提案手法。店舗間の商品集合の違いを考慮し、商品間の食い合いも考慮しています。
- 特徴量: vanilla(商品id, 割引率)
次に実験の詳細に関して説明します。
実験はパートナー企業のPOSデータをもとに行いました。14店舗の30種類の主要商品の一人当たり購入数に関する予測精度を検証しました。使用した比較手法はBaseline、Transformer、そして提案手法であるHeatDiffusionの3つです。ここで、HeatDiffusionにおけるMとλはニューラルネットワークを用いてモデル化をしており、いくつかの構造を検討し最も良かったものを採用しました。ここではその詳細は割愛します。
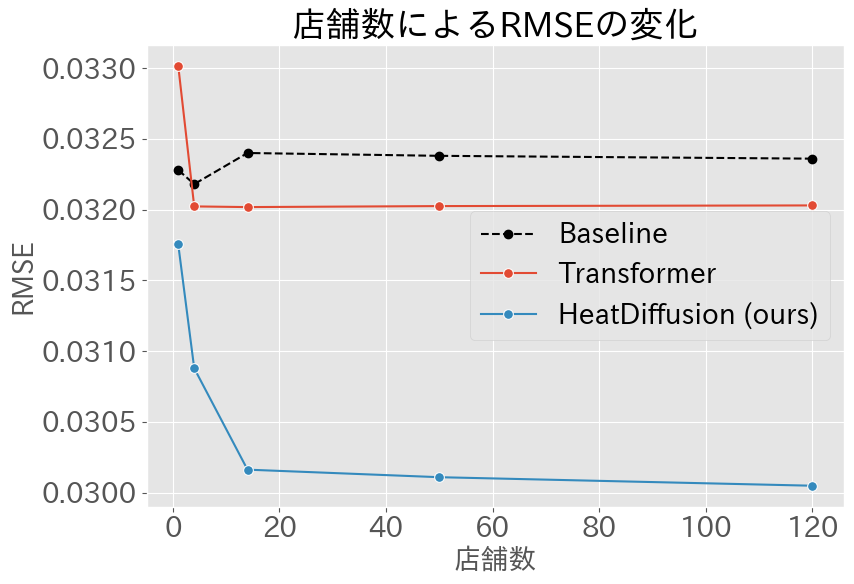
店舗数による精度変化
下図は、使用される店舗数の変化に伴う、各手法のRMSE(Root Mean Square Error)の変動を示しています。
HeatDiffusionでは、店舗数の増加に伴い予測精度が顕著に向上しています。一方で、Baselineの場合、店舗数が増えたとしても予測精度に大きな変動は見られません。これは、Baselineが店舗ごとの商品集合の違いを考慮していないためと思われます。HeatDiffusionは商品集合の違いを適切に取り扱い、他の店舗のデータを効果的に利用して予測を行うことができるため、結果的に予測精度が向上していると考えられます。これらの結果から、商品群の違いによる購入数の変動は無視できないほど大きな影響を持っていると言えます。
また、TransformerとHeatDiffusionとの間にも性能の顕著な差が見られます。この結果から、HeatDiffusionが商品間の需要の食い合いを明示的にモデル化することにより、より高い性能を発揮していると解釈できます。
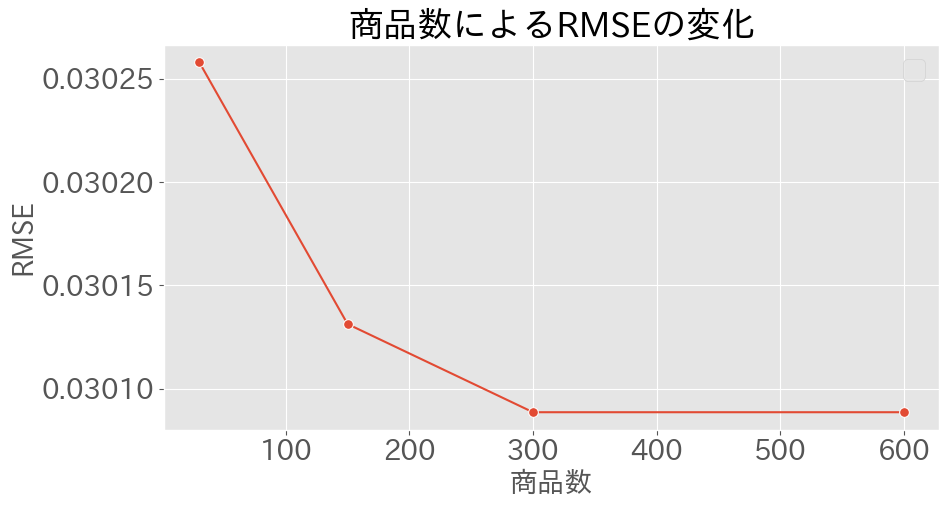
商品数による精度変化
下図は、HeatDiffusionに関して、学習に使用した商品の種類数とRMSE(Root Mean Square Error)の関係を示すグラフを示しています。
学習に用いる商品の種類数を増加させることで、予測の精度がわずかに改善されることが確認できます。そのため、商品の種類数が少ない場合でも、精度が大きく低下することはないということが分かります。
特徴量
下表は、HeatDiffusionにおいて、異なる特徴量を取り入れた場合の予測精度を示しています。各特徴量を追加することでの精度向上は0.02-0.07%の範囲内となっており、これら全ての特徴量を組み合わせて使用すると、2%程度の精度向上が確認できます。
| Feature | RMSE | RMSE rate for vanilla |
| vanilla + time + store id + price + item text | 0.0297 | 0.981 |
| vanilla + time | 0.0300 | 0.993 |
| vanilla + store id | 0.0301 | 0.995 |
| vanilla + stock + price | 0.0301 | 0.996 |
| vanilla + item text | 0.0302 | 0.998 |
| vanilla(item id, discount rate) | 0.0303 | 1 |
使用された特徴量の詳細
- time:月、時間、休日
- store:店舗ID
- stock:商品のその時点での在庫数
- price:商品の売値
- item text:BERTを用いて生成した商品名の埋め込み表現
実験まとめ
実験の結果、提案したいくつかの工夫を組み合わせることで、Baselineと比較して、RMSEで約10%の改善が達成されました。
今後、この予測モデルを在庫管理や値下げの最適化など、さまざまな意思決定の場面での活用を検討しています。
| baseline | heat_difussion | heat_difussion | heat_diffusion | heat_diffusion | |
| demand competition modeling | ✅ | ✅ | ✅ | ✅ | |
| Greater number of stores | ✅ | ✅ | |||
| Greater number of shohins | ✅ | ✅ | |||
| More features | ✅ | ||||
| RMSE | 0.0321 | 0.0317 | 0.0300 | 0.0316 | 0.0290 |
さらなる考察
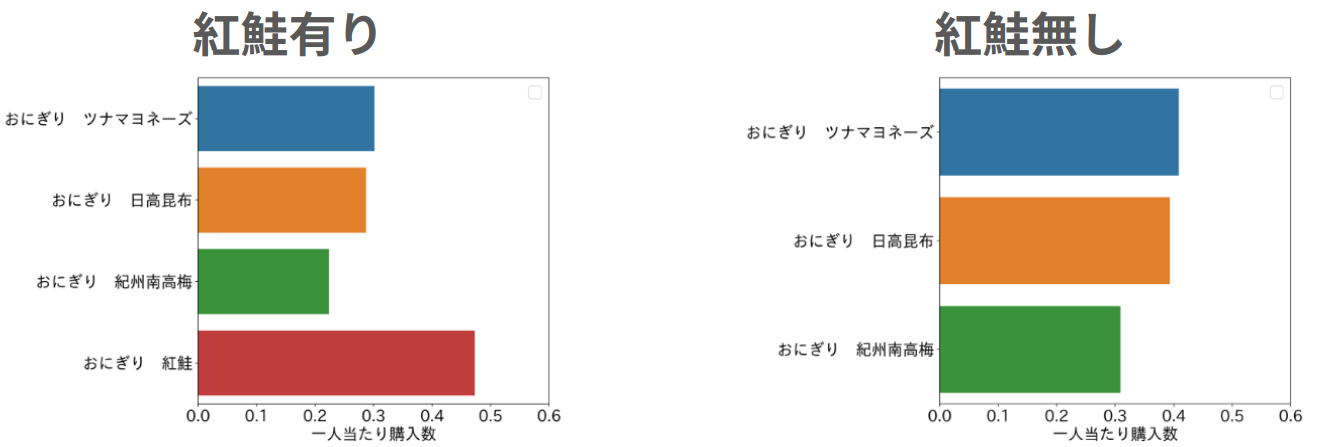
品揃えの変化による予測値の変化
下図は、紅鮭があった場合と無かった場合における予測値を表しています。
紅鮭があった場合と無かった場合の予測値を比較すると、他の商品の予測値は0.1程度大きくなっています。この結果から、紅鮭を買う予定だった顧客が、紅鮭が無かった場合には他の商品に流れるという解釈ができます。
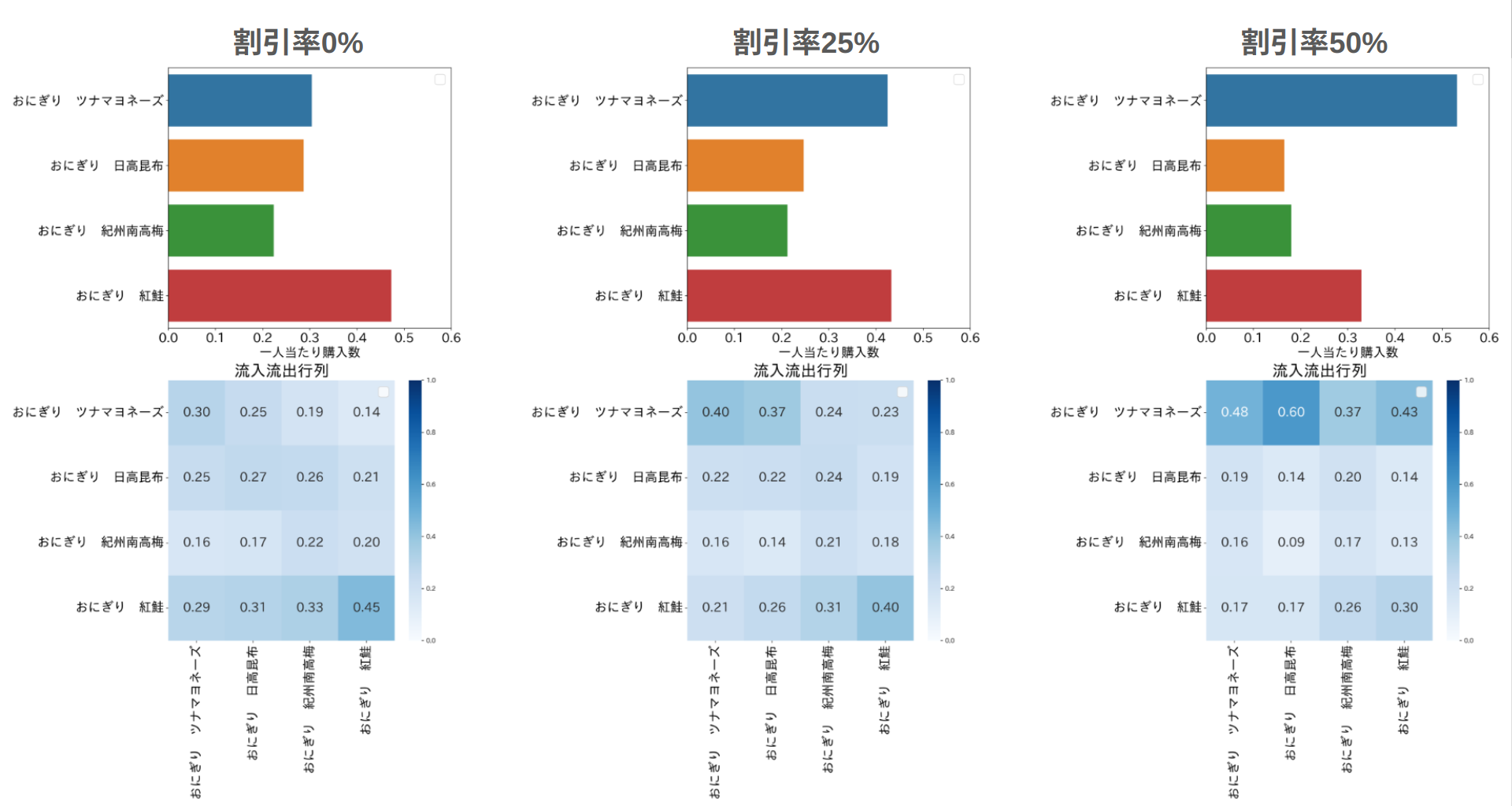
価格変化による予測値と相関関係の変化
下図は、おにぎり ツナマヨネーズ(ツナマヨ)の割引率が0%、25%、50%の場合における一人あたり購入数の予測値と、商品間の流入流出を示す行列Mを表しています。
ツナマヨの割引率が変わることによって、購入数がどのように変化するのか、予測値と行列Mで分析することができます。具体的には、ツナマヨの割引率が増えると、他の商品の予測値が小さくなりツナマヨの予測値が大きくなっています。このことは、ツナマヨの価格が下がると、顧客は他の商品よりもツナマヨを選ぶ傾向が高まるという結果を示しています。加えて、行列Mを通じて、どの商品からツナマヨへの移行が最も多いかを特定することができます。日高昆布からツナマヨへの流出率が高いことから、価格が下がった場合、日高昆布を選ぶ予定だった顧客がツナマヨを選ぶ傾向が強くなることが読み取れます。
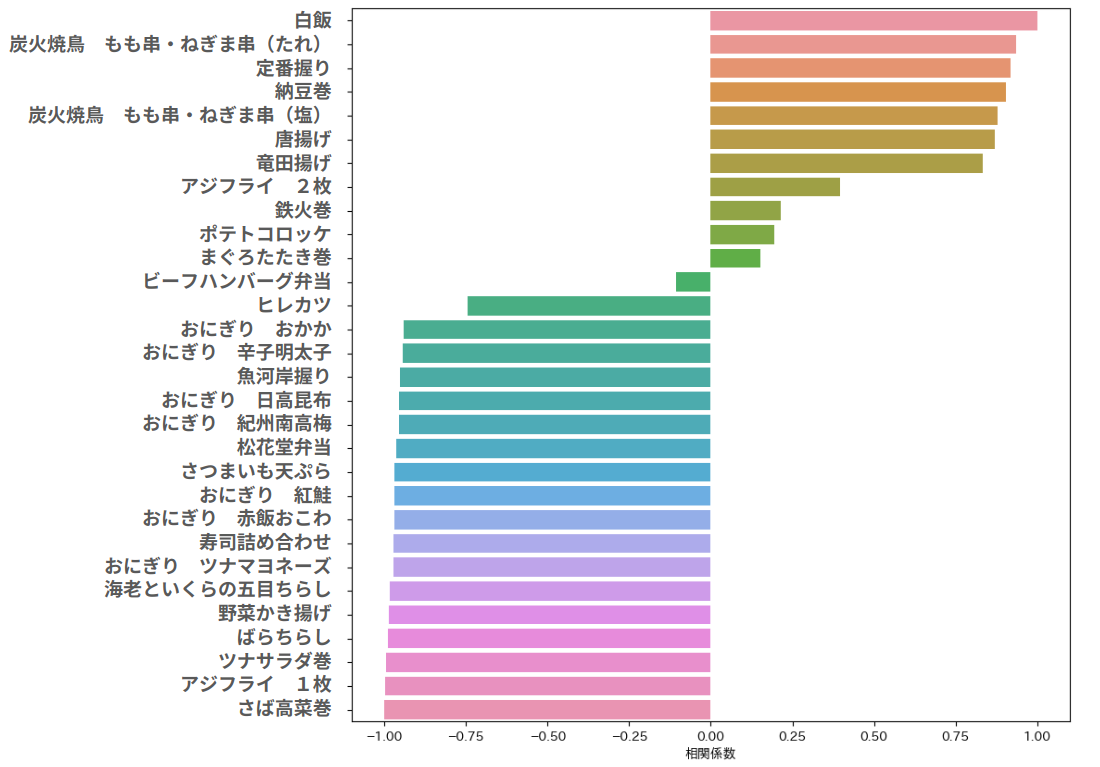
併売の関係
下図は、白飯の割引率を0%から50%に変化させた際の、各商品の予測値と白飯の予測値の相関係数が示されています。
白飯との相関が高い商品は、白飯の価格を下げることで一人当たりの購入数が増加する商品と推測されます。これは、白飯の価格引き下げに伴い、同時に購入される可能性が高い商品、すなわち併売される商品と解釈できます。一方で、相関係数が低い商品は、白飯の価格を下げることで購入数が減少する傾向のある商品であり、これは白飯と競合する商品、特に他のご飯類と推測されます。具体的に相関係数が高い商品を詳しく見ると、併売されると予想されるおかず類の商品が目立ちます。逆に、相関係数が低い商品の中には、白飯と競合するであろうご飯類が多くあります。
具体的に相関係数が高い商品を詳しく見ると、併売が考えられるおかず類の商品が多いです。対照的に、相関係数が低い商品には、白飯と競合しそうなご飯類の商品が多く含まれています。
これらの結果から、HeatDiffusionは商品間の食い合いだけでなく、商品間の併売関係も捉えられていることが示唆されます。
これらの結果を考慮すると、提案モデルは単なる予測モデルを超えて、商品間の相関関係や価格戦略の変動が顧客の購買行動にどのように影響するかを解釈するモデルとして活用できると考えられます。
まとめ
本インターンシップでは、需要の食い合いを考慮した商品の購入数予測モデルを開発しました。食い合いをモデルに組み込むことで、複数の店舗間でデータを共有することが可能となり、予測精度の向上を達成しました。加えて、提案したモデルは商品同士の相互関係を可視化することができるため、予測以外への応用も可能です。具体的には、競合商品との関係を避けた新商品の提案や、売上を最大化する品揃えの決定、代替商品の提案など、多岐にわたる用途での活用が考えられます。
今後の取り組みとしては、在庫切れ情報のリアルタイム取得に関する問題への対応、割引率の変化に対する予測値の単調性の確保、そして併売現象をより詳細に捉えるモデルの開発などが重要な課題として挙げられます。
謝辞
インターンシップ期間中、阿部さんと小山さんをはじめとする皆さまから多くのアドバイスと議論の時間をいただきました。このおかげで、普段の研究以上に、データの生成過程に深く着目したモデリングを実施することができ、非常に楽しい経験となりました。さらに、インターンシップを通じてこれまで触れたことのない多くの新しい分野に接することができ、とても刺激的でした。最後になりますが、このような大変貴重な機会を提供いただいたこと、深く感謝申し上げます。ありがとうございました。
