Blog
本記事は2023年度PFN夏季インターンシップで勤務された仲吉朝洋さんによる寄稿です。
はじめに
こんにちは!PFNの2023年夏季インターンシップに参加させていただいた東京大学修士1年の仲吉です。大学院ではオンラインアルゴリズムについて研究しています。
今回のインターンシップでは、拡散モデルによる金融時系列生成について取り組んでいました。
背景
金融分野において、現実的な金融時系列を生成できると取引戦略の学習やポートフォリオの構築のように多くの応用があります。ここでいう金融時系列とは金融資産の価格変化のことを指しています。
金融時系列生成の先行研究には「Quant GANs: Deep Generation of Financial Time Series」や「Modeling financial time-series with generative adversarial networks」等があり、多くは GAN を用いています。今回のインターンでは、使ってみたかったということもあり拡散モデルによる時系列生成を行うことにしました。拡散モデルによる時系列補間の先行研究として CSDI というものがあります。著者の方による発表スライド内で株価時系列生成の例が紹介されており、相関を捉えている例もあります。相関はポートフォリオを構築する際に非常に重要であり、相関を再現したリアルな時系列を大量に生成することができればその時系列上でポートフォリオを評価して構築することもできるといったメリットがあります。
やったこと
一般に金融時系列予測は難しいため、現実的な金融時系列を生成すること、そして銘柄間の相関などの特徴も捉えられているかを確認することを目標としました。
実装が公開されているためモデルは CSDI をほとんどそのまま使用し、実験データには量の多さから分足の為替データを用いています。含まれている通貨ペアは AUDUSD、EURUSD、GBPUSD、NZDUSD、USDCAD、USDCHF、USDJPY で、学習には 2008年から2017 年、テストには 2018年から2020 年を用いました。
拡散モデルの入力(条件)は64分、出力は128分の価格変化率です。実験データから切り出してきた128分の前半を条件としてモデルに与え、全体を生成させます。正規化をしているため、後半のスケールを合わせたりするために前半部分も生成させています。ただし、以降の分布や相関係数の計算では後半64分を用いて実データと比較しています。
結果
生成された金融時系列の質を定量的に評価するのは難しいため、複数の面から定性的に評価していきます。
価格変化率の分布
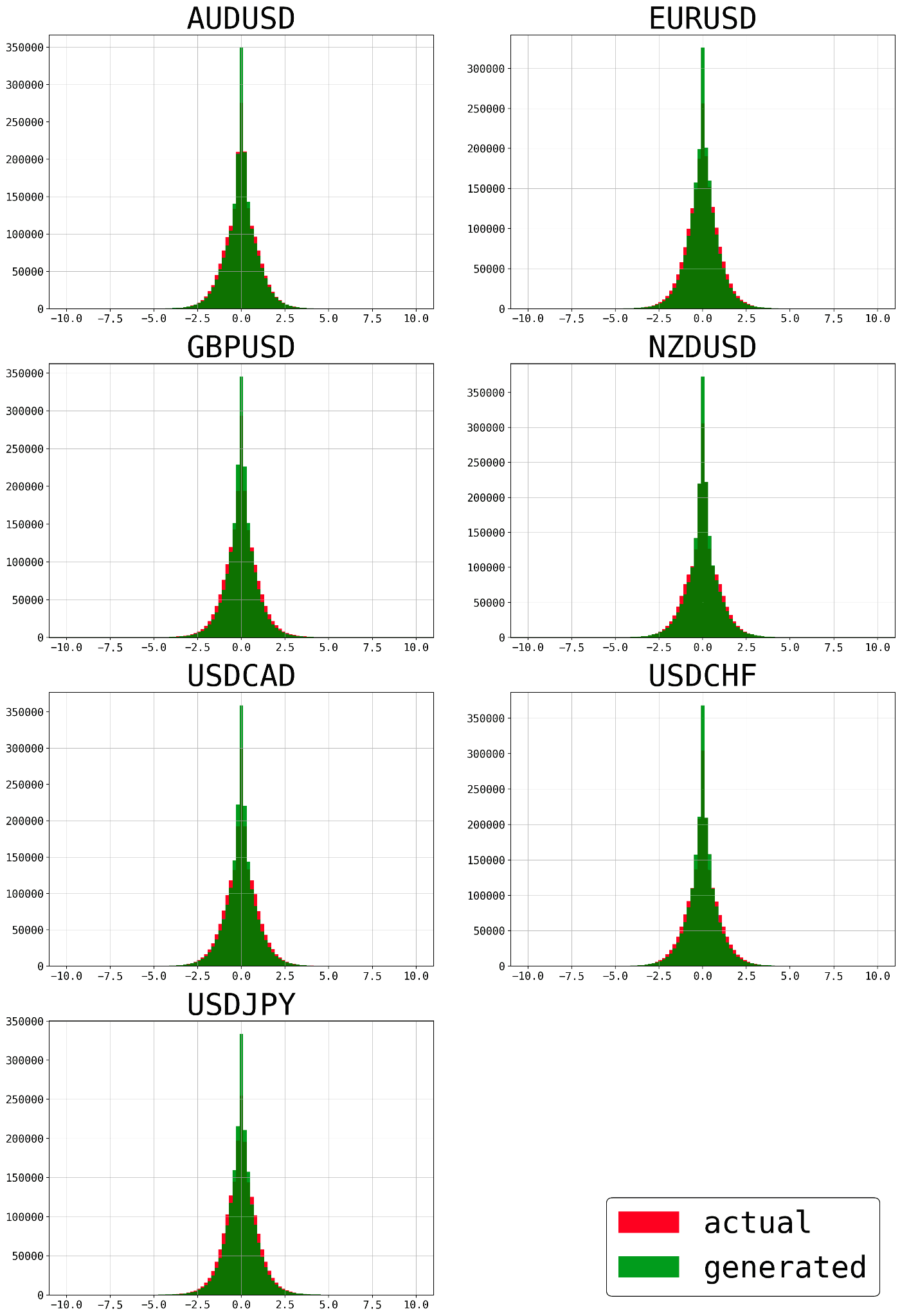
金融データの価格変化率は正規分布に従わないことが知られています。次図の赤が実データ、緑が生成データの価格変化率ですが、どちらも正規分布よりも尖った形をしていてほとんど一致しています。尖度の7通貨ペア平均は実データで約 6.36、生成データで約 11.3 です。少し離れていますが、どちらも正規分布の尖度の 3 よりも大きくなっています。
価格変化率の通貨ペア間相関
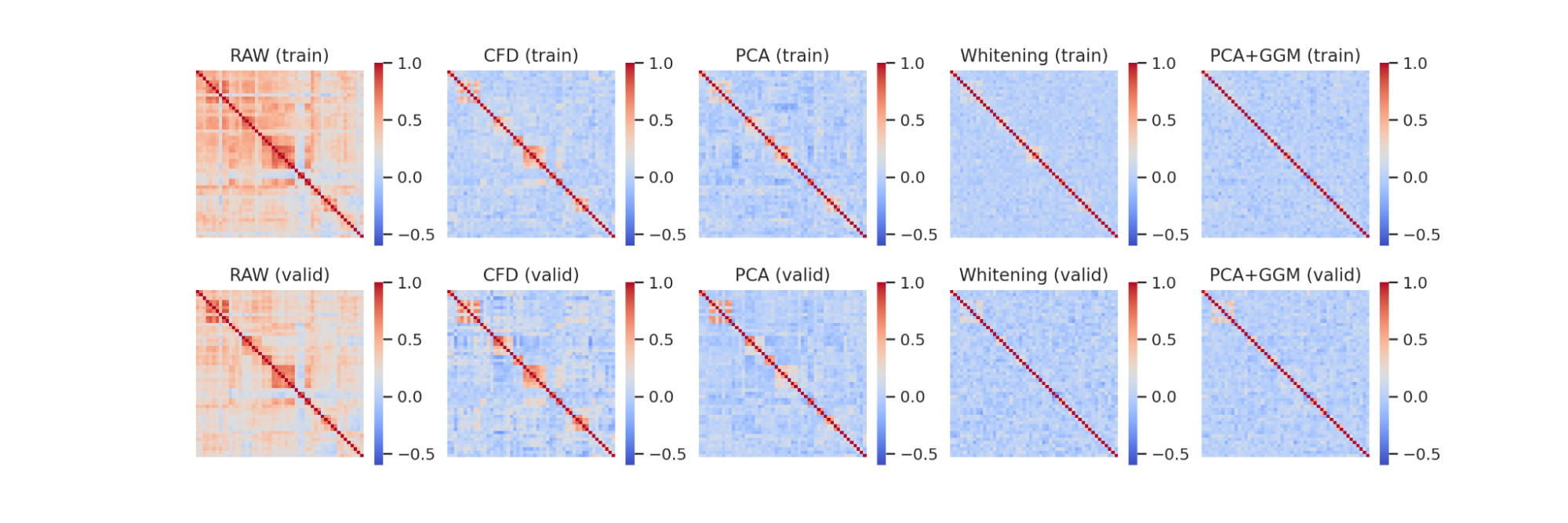
次図は通貨ペア同士の価格変化率の相関係数をヒストグラムとして表示したものです。対角成分は単なる価格変化率のヒストグラムで先ほどの図と同じものです。
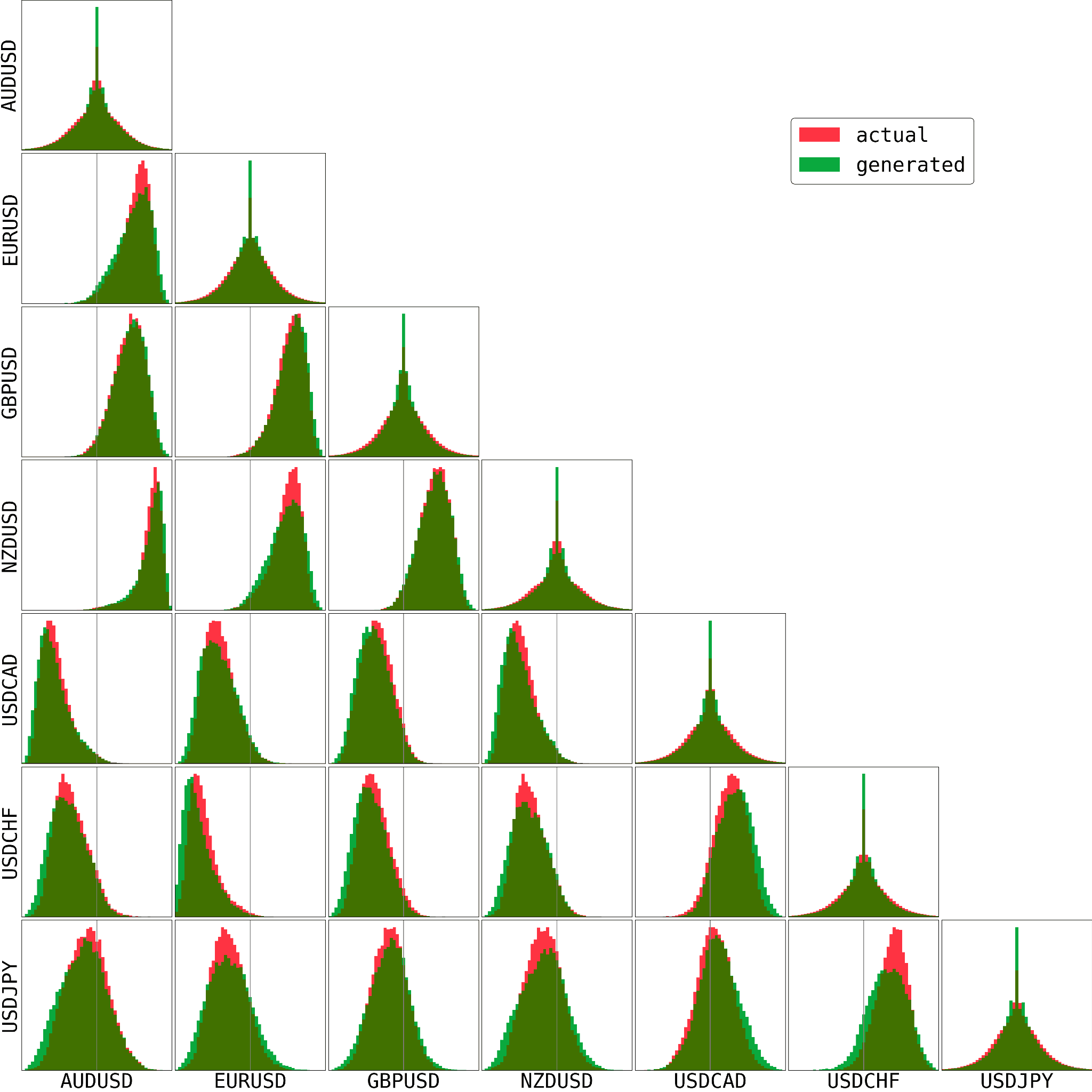
今回は全ての通貨ペアが USD を含んでいるため実データでも明確に相関が生まれています。また、USD が基軸通貨か決済通貨かが一緒かどうかによって相関係数の正負が変化しています。USDJPY の行(一番下)あたりを見ると少しズレが大きいようには見えますが、傾向自体はおおよそつかめています。
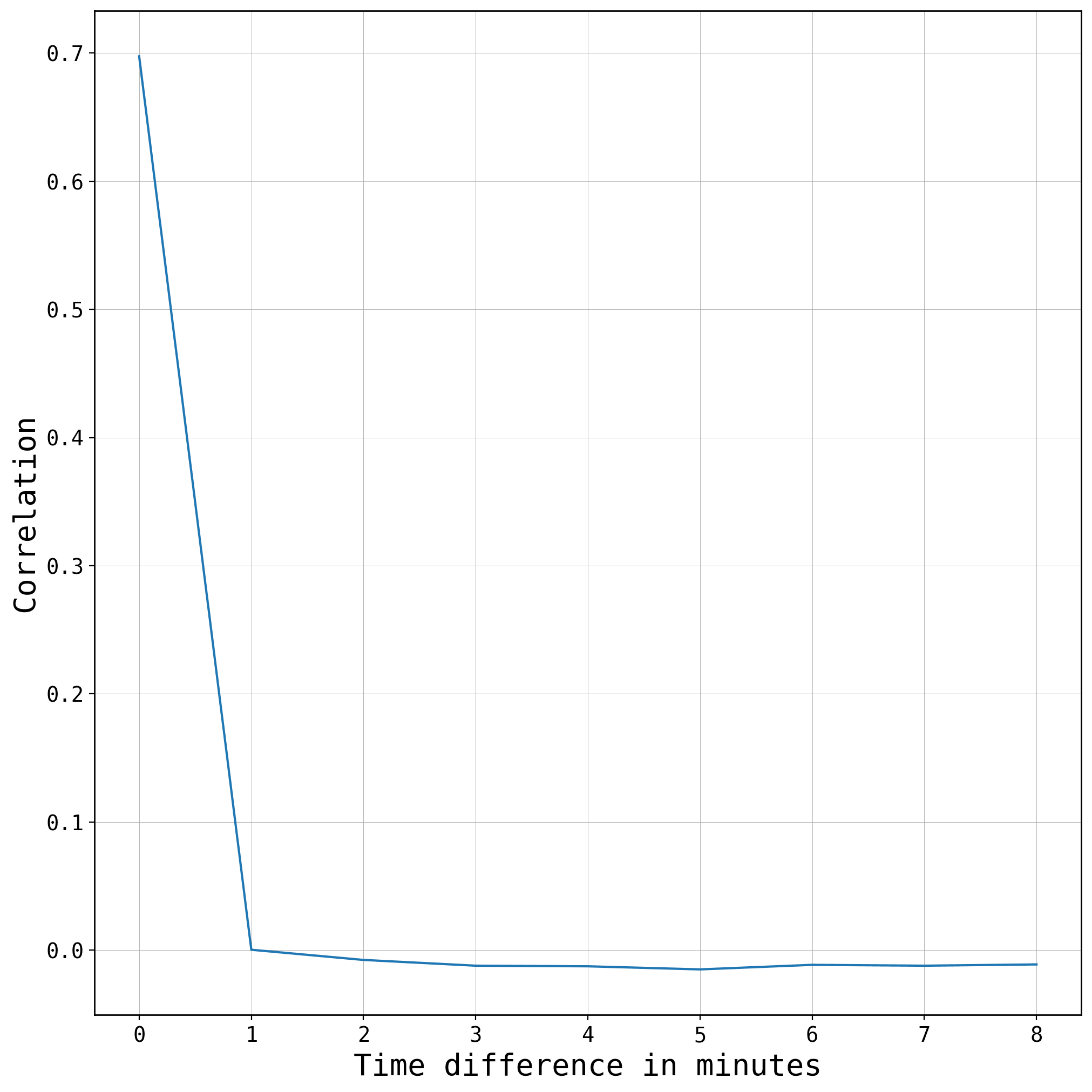
通貨ペア間の相関係数は64分間の価格変化率の列同士からそのまま計算しています。金融時系列ではある資産の価格が変化して少し遅れてから他の資産の価格も影響を受けるリード・ラグ効果が発生することがあります。ただし、今回用いている為替データの場合は1分あれば他の通貨への影響は伝わります。次の図は AUDUSD と NZDUSD の実データでの相互相関をプロットしたものですが、1分ずらした時点で相関係数はほとんど 0 になっていることがわかります。よって今回は時間をずらさずに同じ時間同士の相関係数で計算しています。
前半64分の条件による影響
ここまで紹介した価格変化率と通貨ペア間の相関は、学習データから分布さえ学習してしまえば前半64分を条件として与えずに生成させても再現できます。ここでは条件部が生成結果に影響を与えているかを確認します。
ここでは、前半での価格の下落幅と上昇幅が大きいデータ上位1割をそれぞれ取ってきて、後半64分での価格変化に差が生まれるかどうかを見ます。次図は左が実データ、右が生成データでの結果です。生成データについては実データと同じケースから10サンプルずつ生成しています。
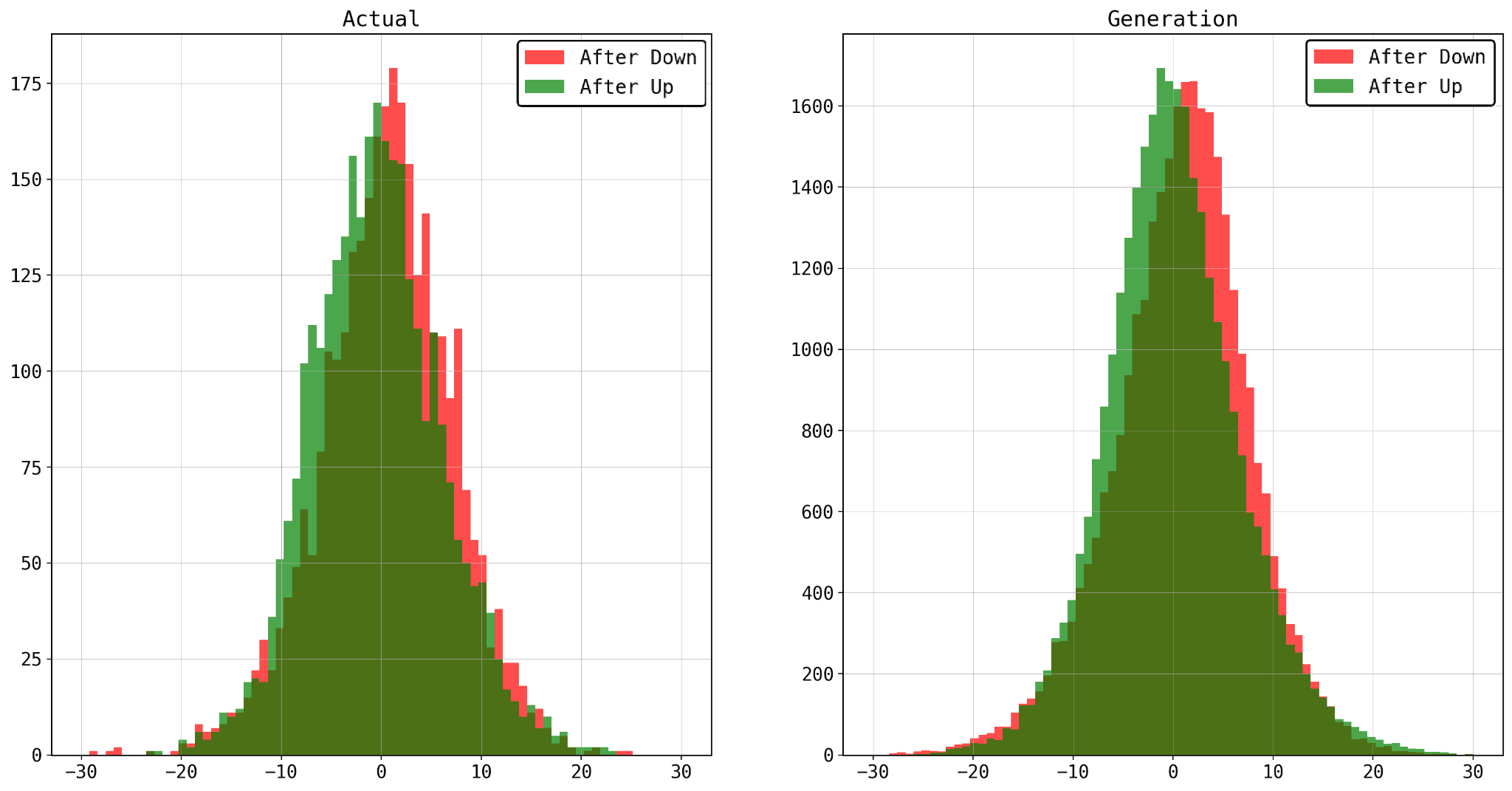
赤色のヒストグラムが前半で価格が落ちたとき、緑色のヒストグラムが前半で価格が上がったときの後半での価格変化を表しています。赤の分布が少し右に、緑の分布が少し左に寄っています。この図から反発のような値動きが起こっていそうなことがわかり、実データと生成データで同じような傾向が見えています。
また、実データではデータ数が少なくわかりにくいですが、生成データの方を見ると赤は左の裾が、緑は右の裾が重くなっていることが少し見えやすくなっています。このように、限られたデータ数では観察しにくい傾向も、生成モデルによって大量に生成することで明らかになる可能性もあります。
実際に生成された時系列の例
生成された価格変化率について和を取れば擬似的価格列のような形になるので、それをプロットしたのが次図です。後半の動きを比較したいため、累積和は64分時点から左右に向かって取っています。モデルは全体で正規化された出力を行うので、後半の変化量によっては前半のスケールが実データからはズレることがありますが、今回はスケールを合わせずにそのまま可視化しています。
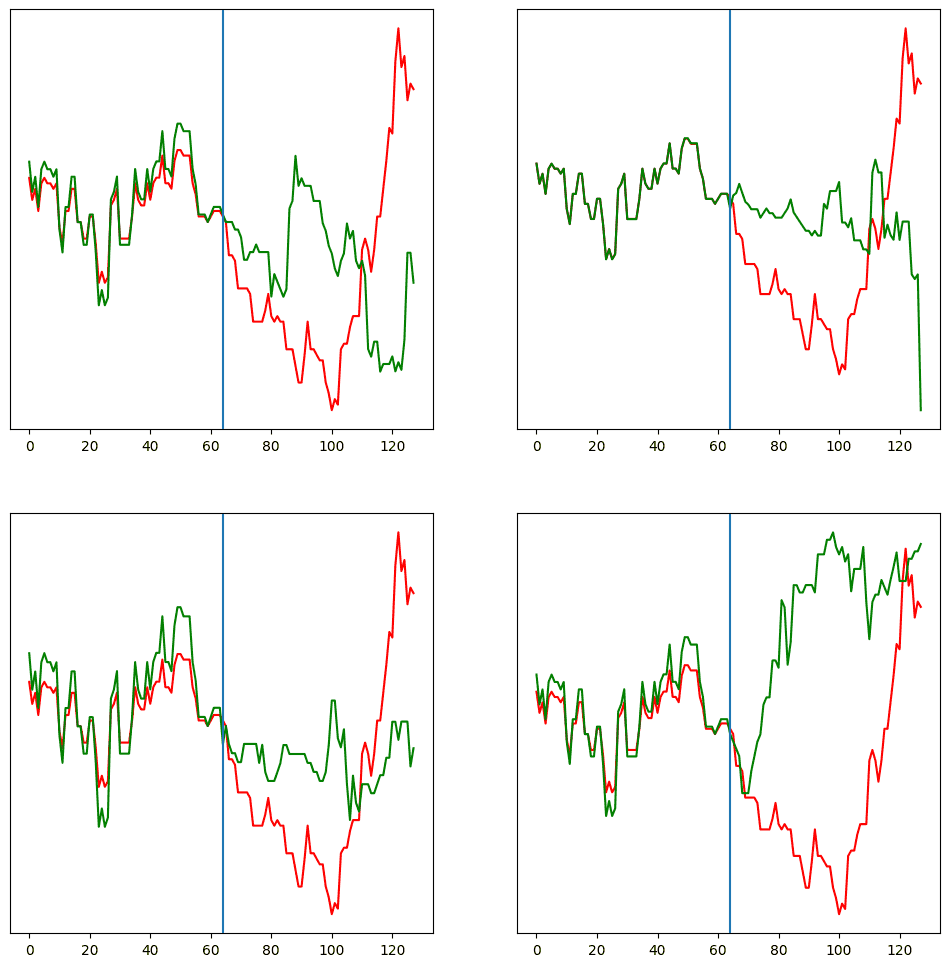
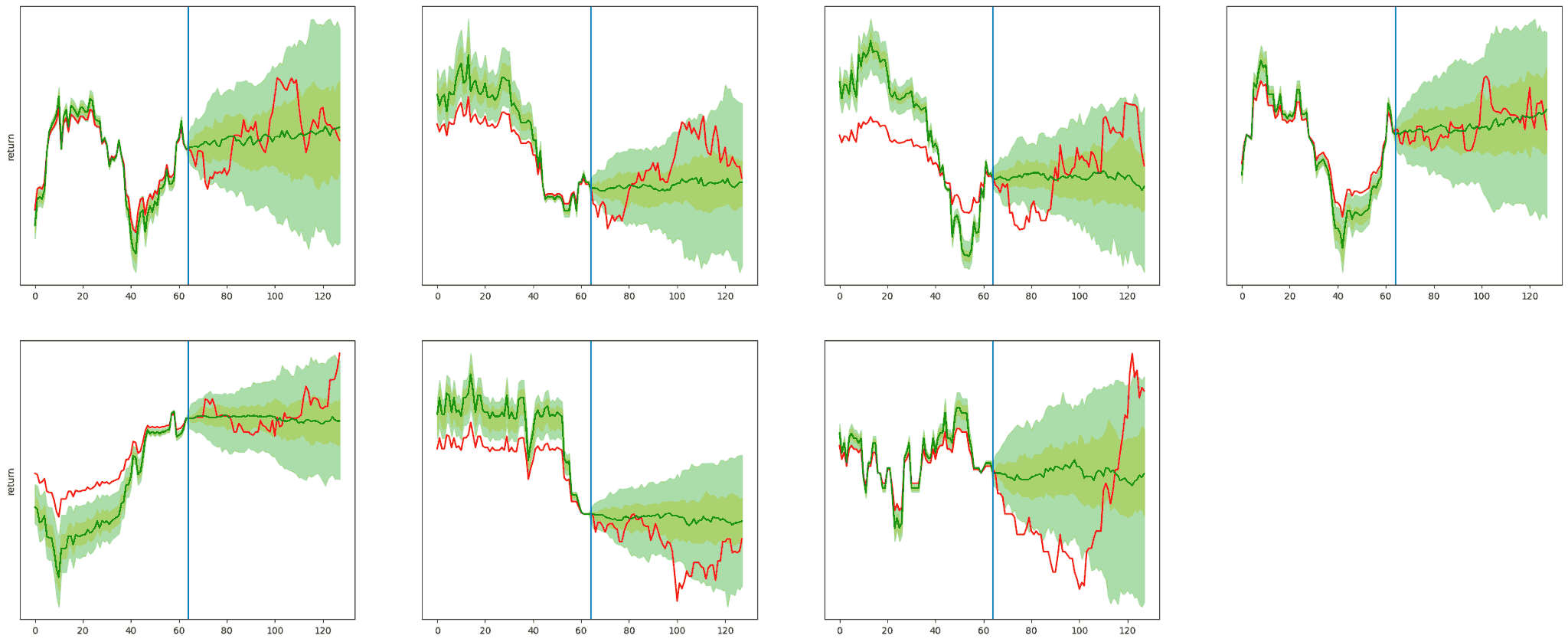
生成された前半の時系列のスケールが実データのスケールと若干のズレがありますが、ここではそのスケールは補正せず、同じ前半の時系列を与えて後半部の時系列にどれぐらい多様性が生まれるかをみるために、同じ前半の時系列データから100回サンプルを生成し、7銘柄それぞれについて 10%-90% 範囲と 30%-70% 範囲を可視化したのが次の図です。銘柄ごとに前半部分の分散やスケールのズレに差がありますが、後半の 10%-90% 範囲と 30%-70% 範囲への影響はあまりないように見えます。後半もある程度範囲に入っているとはいえ 10%-90% 範囲の幅が非常に広くなってしまっており、金融時系列のランダム性の強さが示唆されます。仮に予測に使うのであれば、普通は範囲が徐々に広がっていく中で歪んでいる箇所を利用するという方向性が考えられます。
まとめ・今後の課題
条件付き拡散モデルを用いることで、実データに現れている分布や相関、反発のような特徴を捉えた為替データの生成ができることが確認できました。今回は定性的な評価になってしまっていますが、生成したデータでシミュレーションを行うことでポートフォリオを評価・構築し、実データでの性能を測定するといった定量的な評価を行うことや、そもそもポートフォリオ構築に有用なのかを確認したいです。
また、現在は7銘柄128分のデータをそのままモデルに与えているだけですが、時刻の情報やテクニカル指標を追加の情報として与えることによる性能向上や、他の金融資産への適用も今後の課題です。
感想
金融も機械学習も専攻分野ではない中で興味があるという理由だけでこのテーマに応募し、面白そうという理由だけで拡散モデルでの時系列生成をやることにしました。うまくいっていても生成されるものがノイズのような見た目になるので、生成できた気がする!と思い Slack で上げると「違和感がありますね」という指摘を受けて実装のミスに気づいたり、金融時系列っぽさをどう見るかがわからなかったりと金融知識や直感の足りなさを実感していました。ただ、メンター・副メンターの今城さん、的矢さんと南さんのサポートやアドバイスのおかげで無事インターンを終えることができ、本当に感謝しています。
6週間という短い期間でしたが、インターン期間中のイベントで社員の方々や他のインターン生との交流もでき、非常に良い経験になりました。金融チームの方々、そしてインターン期間中にお世話になったPFNの皆さん、ありがとうございました!