Blog
本記事は、2019年夏のインターンシップに参加された島田直治さんによる寄稿です。
PFNの2019年夏季インターンシップに参加させていただいた東京大学大学院・情報理工学系研究科・修士2年の島田直治 (http://ut25252.starfree.jp/) です。大学ではCG (コンピューター・グラフィックス) 関連の研究をしています。インターンでの研究テーマとして、CGとの関わりも深い「微分可能レンダラーを用いた3D再構成」を選びました。研究としては、3D表現としてニューラルネット関数を用いることを着想し、これに対する新たな微分可能なレンダリング方法を考案、実装して数値実験を行い3D再構成の精度を先行研究と比較評価しました。
研究内容に関するまとめスライドをこちらに公開しています。このスライドの内容について、以下で解説していきます。
また、作成したプログラムはこちらで公開しています。
微分可能レンダラーを用いた3D再構成
CV (コンピューター・ビジョン) の分野で現在精力的に研究が行われているテーマの一つに、たった1枚の画像が与えられた場合にそこに写っている物体や景色の3D構造を把握しようという “single-view 3D reconstruction” があります。
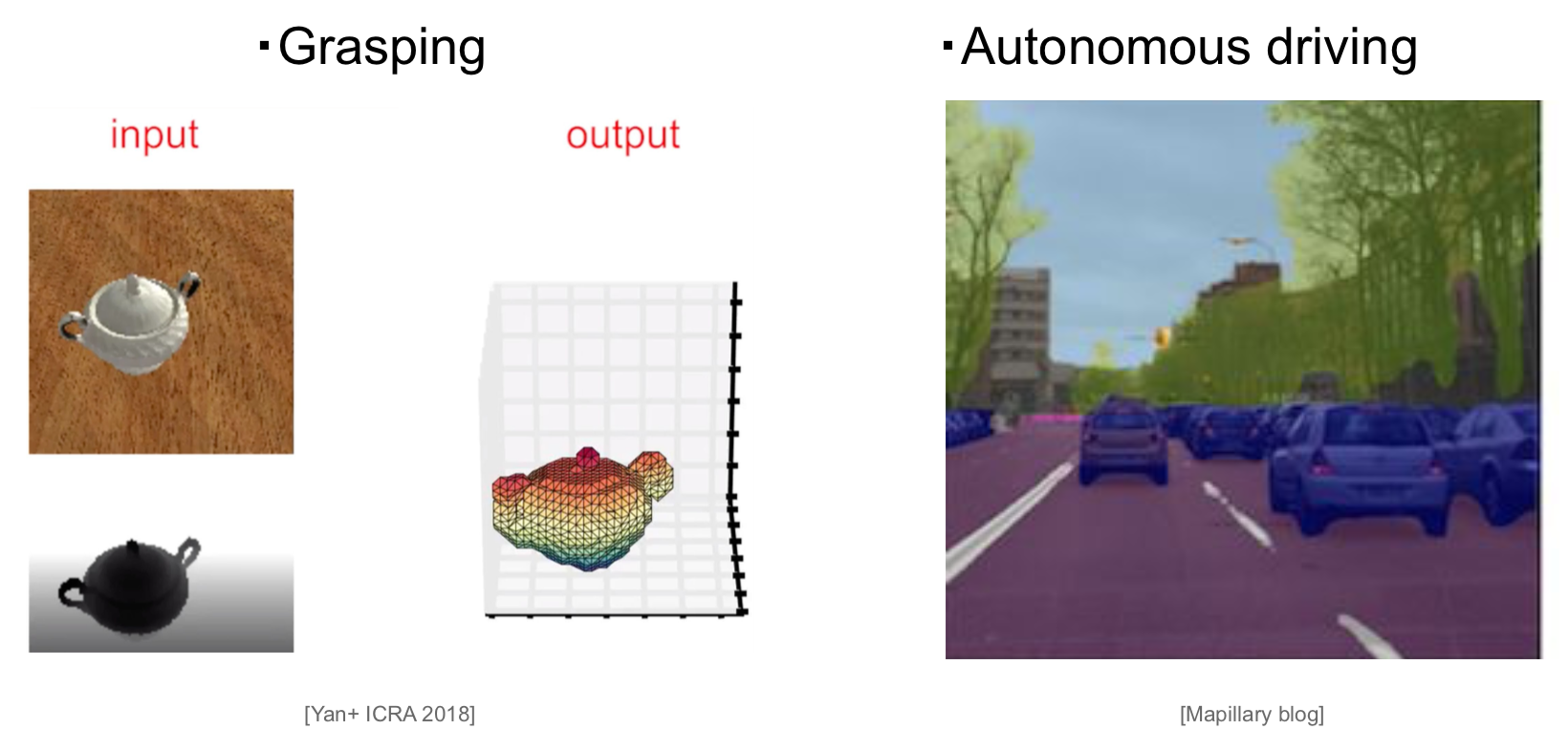
これは、例えばロボットが目の前にある物体を掴む動作(グラスピングと呼ばれる)を行う場合や、自動運転車が歩行者や障害物を把握して回避する場合などに応用が見込まれます。
問題点として、1枚画像からの3D再構成という課題は明らかに条件不足な不良設定問題であり、他の情報を使わない限りは解くことが出来ないということが挙げられます。我々が日常生活において視覚情報からある程度3D構造を把握できるのは、これまでの人生経験で「学習した常識」を使って形状を「予測」しているからです。パソコンに3D再構成を行わせる場合にも、同様に常識を学習させて予測させる手法が考えられます。
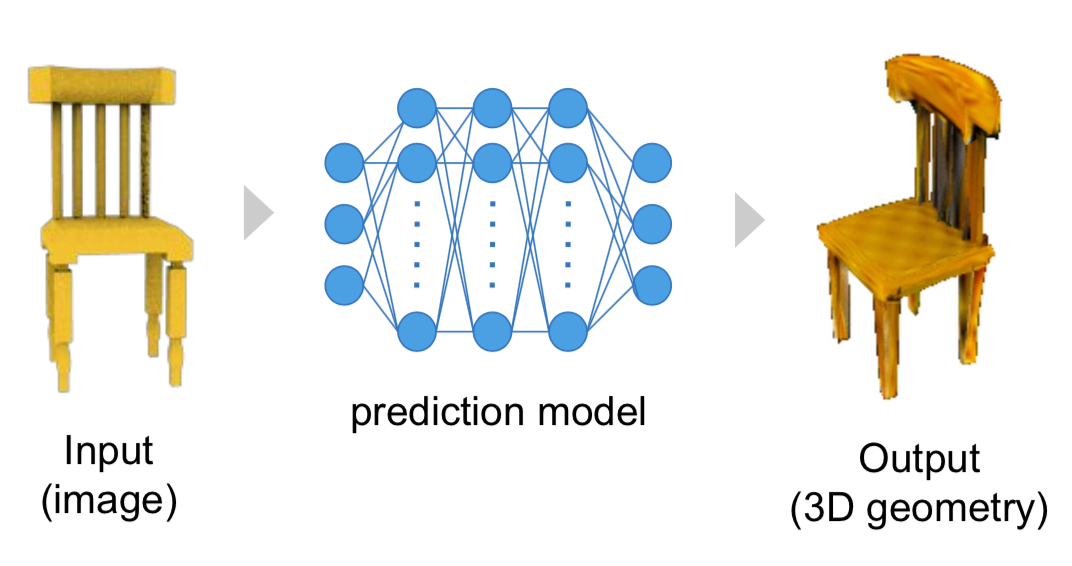
3D supervisionによる学習 [2]
画像を入力とし、3D構造を出力とするような予測モデルをニューラルネットワークで表現し、教師3D構造データとの差分を用いて最適化学習すれば出来そうです。実際数多くの研究が行われています[5-10]。このように3D構造を教師データとして用いる学習を3D supervisionと呼びます。
3D supervisionによる学習の問題点としては、教師データとなる3Dデータを大量に必要とすることです。現状では3Dの教師データを大量に用意するというのはあまり現実的な選択肢ではありません。そこで、画像のみを用いて予測モデルを学習させる、2D supervisionな学習方法が模索されています [1-4]。
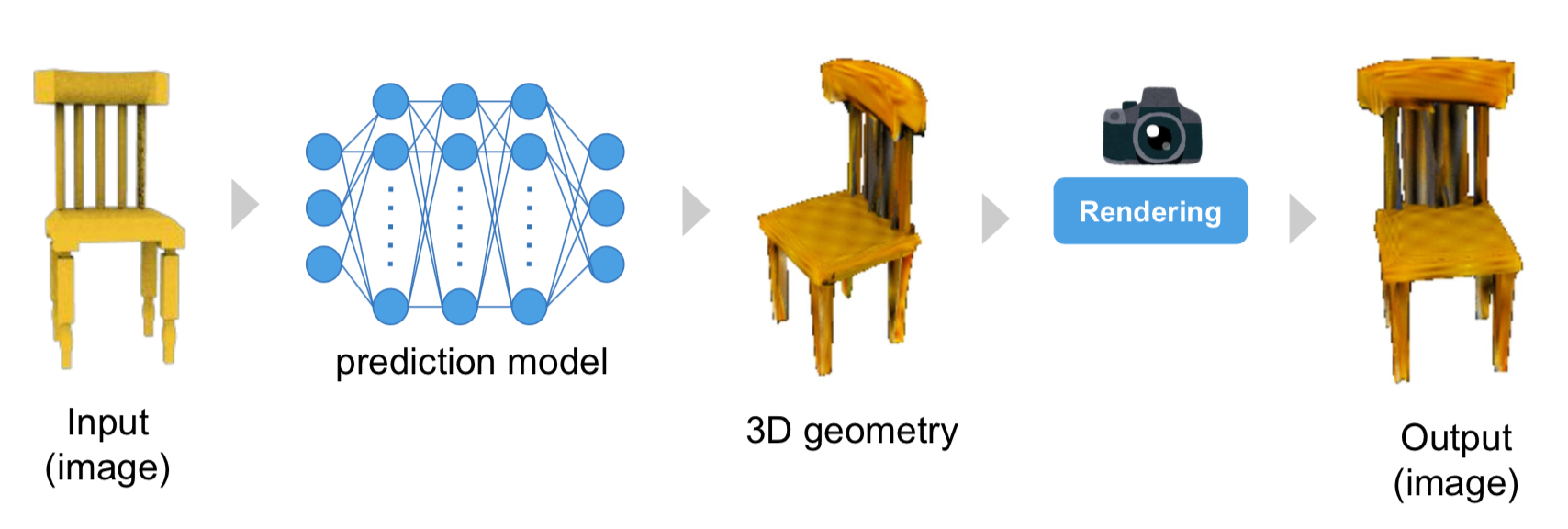
2D supervisionによる学習 [2]
予測モデルの出力した3D構造から、2Dの画像を生成する (レンダリングと呼ばれる) ことは容易であり、その生成画像と教師データ画像との差分を計算することができます (この場合、教師画像データはどの位置・方向から撮影されたものであるかというカメラパラメータがわかっているものとし、レンダリングの際にはその位置・方向と同じような仮想カメラを設定して画像生成することになります)。出力画像における差分を誤差逆伝播させて、予測モデルのニューラルネットを学習させることになりますが、この時レンダリング部分が微分可能でないと誤差を逆伝播させることが出来なません (直感的には、3D構造を少し変化させた場合に、それに応じて出力画像がなめらかに変化することが要求されます。例えば、三角形メッシュで表現された3D構造をラスタライズの手法によりレンダリングする場合、ピクセル中央にメッシュが入るか入らないかで不連続にピクセル値が変化してしまいます。メッシュの位置変化に対して出力がなめらかに変化しないので、このままでは微分可能ではありません [1])。このように、2D supervisionな学習には微分可能なレンダラーの開発が必要となります。
3D表現と微分可能レンダラー
3D構造の表現方法にはボクセル、点群、メッシュ、ニューラルネットなどがあります。

各3D表現を可視化した図 [8]
それぞれの3D表現(点群以外)について微分可能レンダラーが提案されています。代表的な手法とその利点欠点を以下の表にまとめています。
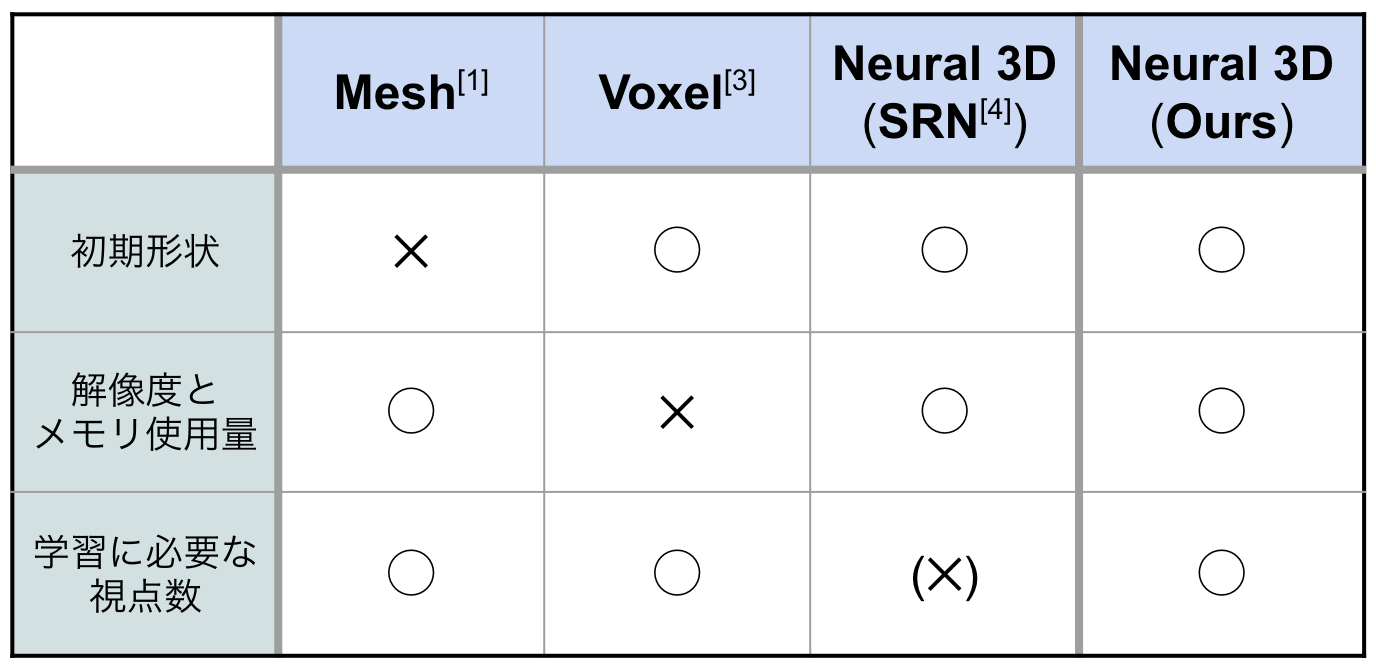
メッシュ表現を用いる場合 [1][2]は、何らかの初期形状を仮定して、これを変形させることで3D構造の再構成を行うアプローチが主流です (例えば最初に球を仮定してメッシュ構造を作り、目的のティーポットなどに連続的に変形させていきます)。この場合、トポロジー的にことなる物体(穴が空いていたり、複数であったり)を再構成することが難しいという欠点があります。メッシュ表現のもう一つの難点としては、頂点と面からなる複雑な構造のデータを深層学習のフレームワークでうまく扱うことは容易でないことが挙げられます。また、ボクセル表現を用いたDRC [3]では、解像度を上げるにつれて必要なメモリ容量が解像度の3乗で増大するという欠点があります。さらに、ニューラルネット3D表現を用いたSRN [4]では、上2つの欠点を克服しているが、レンダラー部分までニューラルネットで表現することで微分可能レンダラーとしており、その分学習が大変になっているという欠点があります(1つの物体に対して50視点分もの画像を必要としています)。
今回のインターンでは、これらの欠点をすべて克服するような、ニューラルネット3D表現に対する微分可能レンダラーを開発することを目的としました。SRNのようなレンダラー部分をニューラルネットによるものにするではなく、より直接的に行うようなレンダラーを微分可能な形で実現することで達成出来るはずです。これにはボクセル表現のDRCを参考にして拡張することを考えました。まずはDRCについての簡単な解説を行います。
Differentiable Ray Consistency (DRC) [3]
DRCでは、以下のようなパイプラインで3D再構成とレンダリングを行っています。簡単のため、教師データとして白黒のmask画像を用いる場合に限定します。
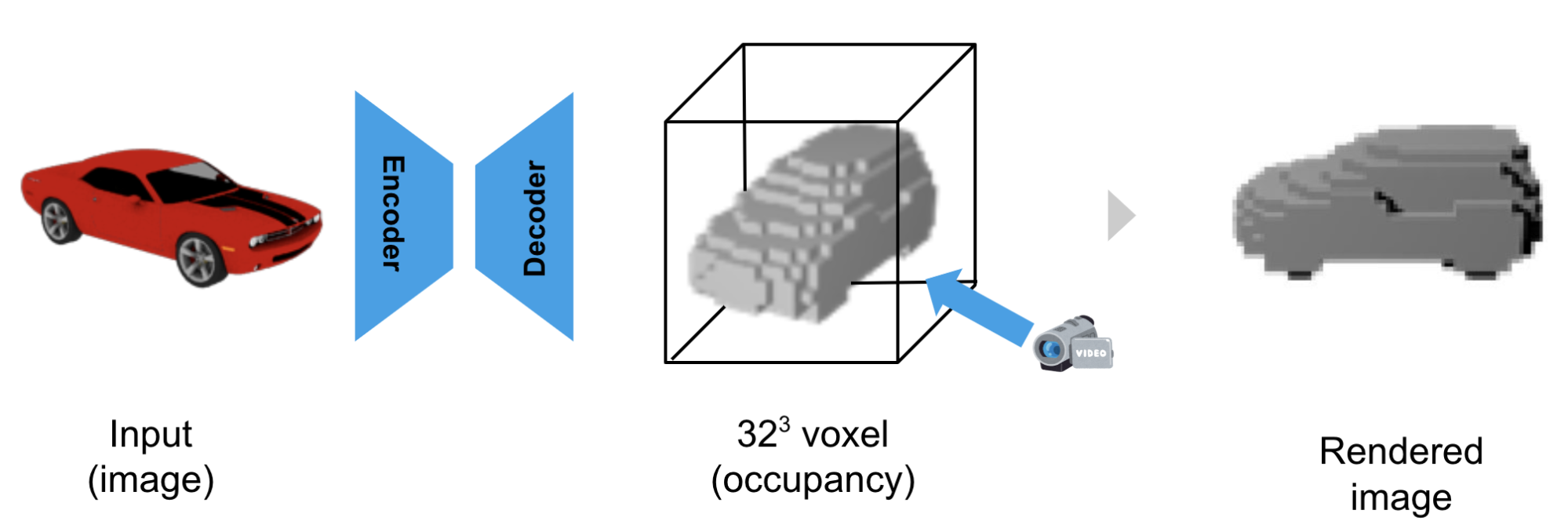
3D再構成のパイプライン [3]
まず、RGBの画像 (64×64 ピクセル) をEncoder-DecoderによりVoxel 3D表現 (32×32×32) に変換します。次にカメラから見てレイの通り道にVoxelが存在すれば黒、しなければ白といった形でレンダリングします。
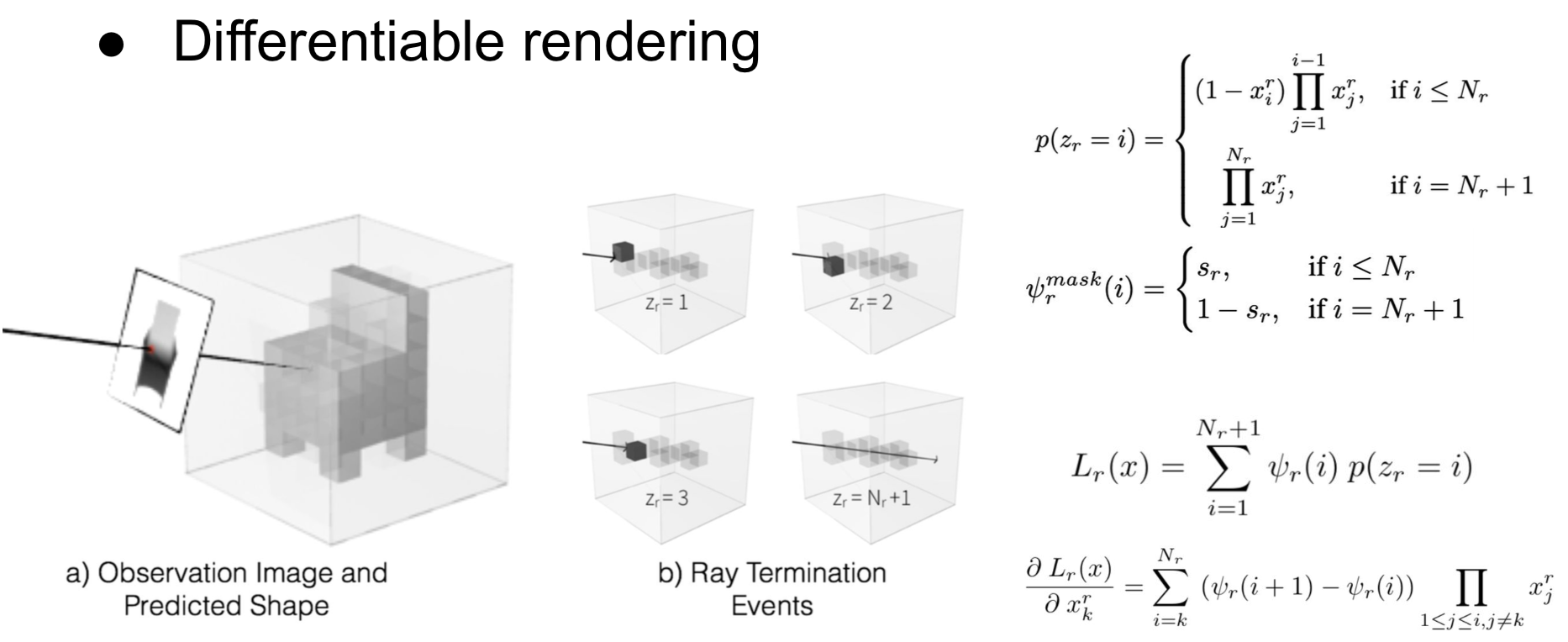
微分可能レンダリングとLoss関数 [3]
ただし、Voxelが存在するかしないかという2値表現では微分可能なレンダリングにはなりません。そこで、Voxelには曖昧な中間状態を許すことにし、[0,1]の実数値でレイの透過確率を表すものと定義します。つまり、レンダリング画像の各ピクセルには、レイが通過する全voxelの透過確率をかけ合わせた値が出てくることになります。ここで、Loss関数を教師画像と出力画像の各ピクセル値の絶対値差分の合計値と定義すると、各voxel値について微分可能であることが示されます(論文参照)。つまり、微分可能レンダラーとなっており、Encoder-Decoderのネットワークを学習させて3D再構成を行うことができます(上図参照)。

DRCによる3D再構成の例 [3]
実際に学習したモデルで3D再構成を行った結果はこのようになります(上左図)。また、教師データとしてmask画像だけでなくRGB画像を用いる場合にもLoss関数を拡張することで対応出来ます(上右図)。
Our algorithm (DRS)
DRCでの3D表現をvoxelからニューラルネットに置き換えることを考えます。
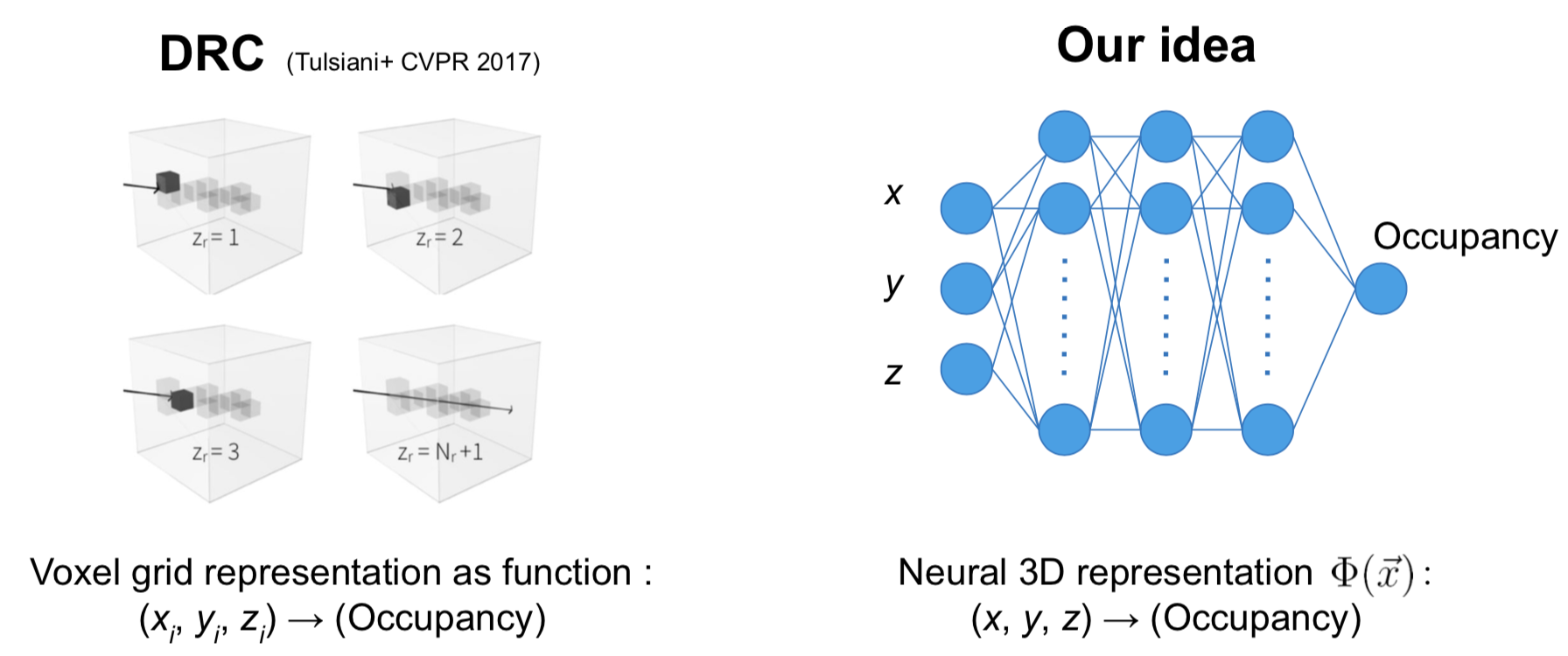
voxel表現というのは、323のメモリにそれぞれ一つの実数が格納されていて、(x,y,z)のindex値を指定するとそれに対応する値が一つ返ってくるようなものと考えることができます。これは一つの関数とみなすことが出来るため、上右図のような3入力-1出力のニューラルネットによる非線形関数で置き換えることが可能です。ニューラルネット表現に置き換えることで、一つ一つの値を保持するvoxelよりメモリ効率が大幅に改善することが見込まれます。さらに、入力のx,y,zには連続的な座標の実数値を直接使うことが出来るようになることで学習やレンダリングの自由度が高まり、またデータ点間が関数の滑らかさにより自動的に補完されるため、表面形状が綺麗に再現されるというメリットがあります。これらの特徴は、3D supervisionでの文脈で近年盛んに行われているニューラルネット表現の研究において確認されています [8-10]。
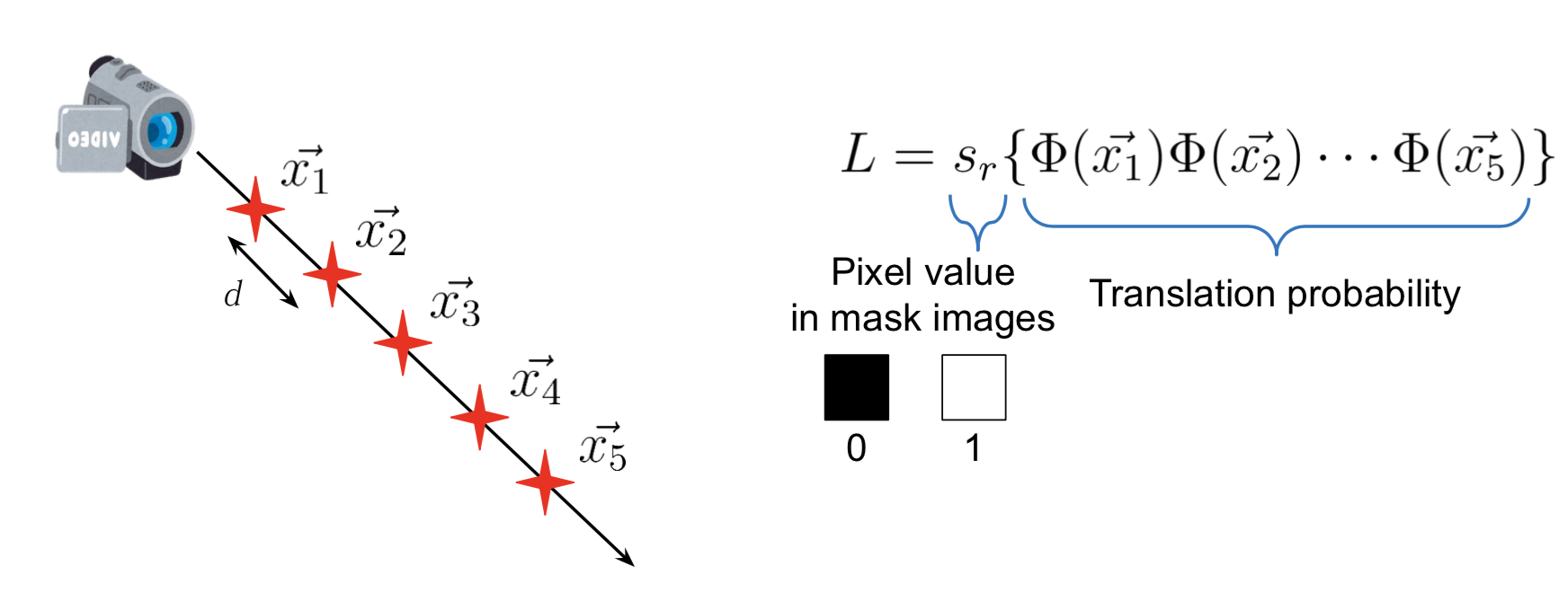
レンダリングについては、カメラから出たレイを適当な間隔で区切ってサンプリングし、サンプリング点の座標をニューラルネット3D関数に入力することで、その点でのレイ透過確率を計算します。これをかけ合わせた値をピクセル値として扱い、Loss関数はDRCの場合と同じように定義することで微分可能となります (上図)。
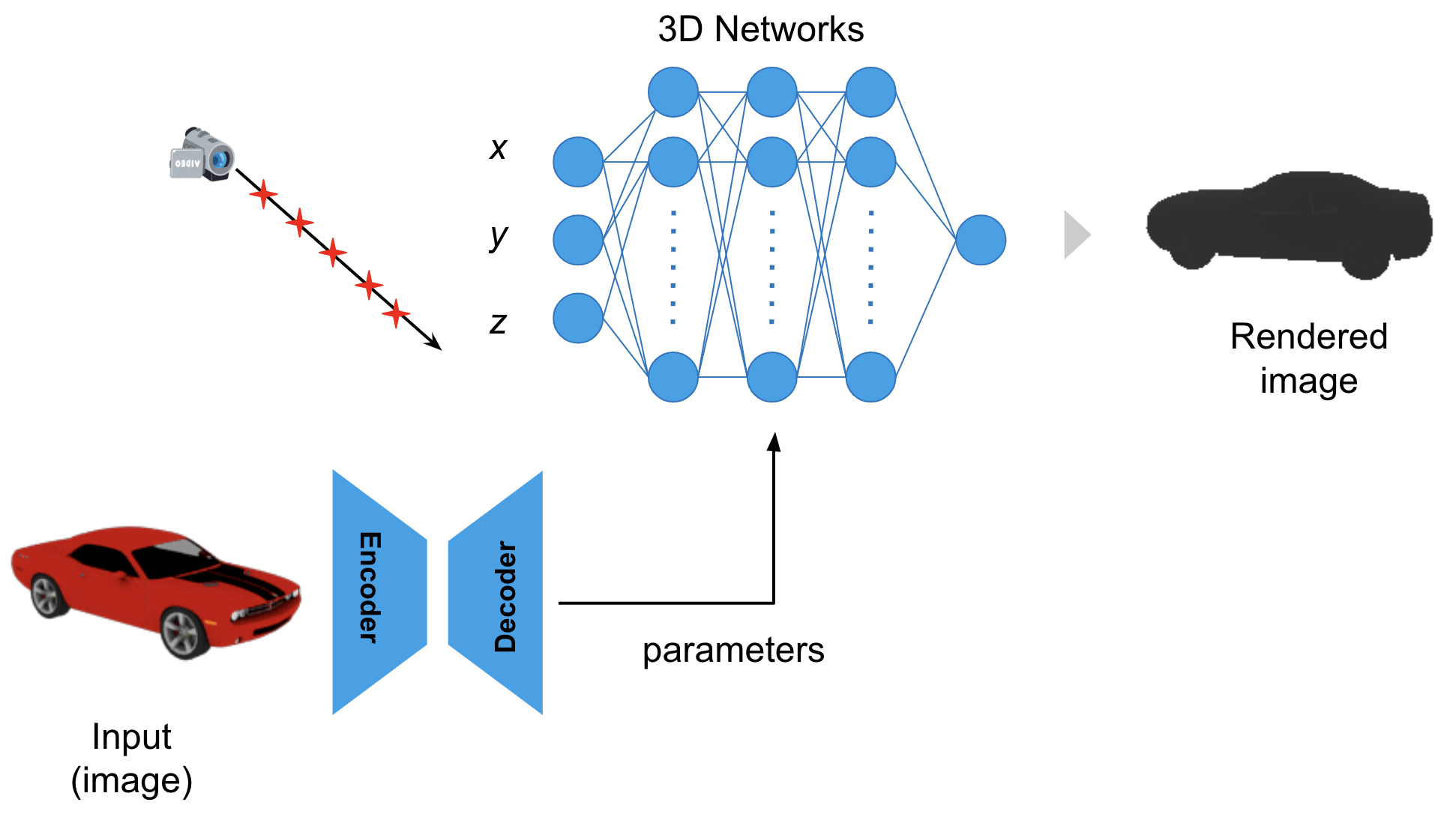
全体のパイプラインとしては上図のようになり、Encoder-Decoderはニューラルネット3Dの重みパラメータを出力するようになっています。
Results
学習条件をDRCと同様な設定で行いました。データセットにはshapenet V1を用い、car (chair)クラスについては、全7000 (5000) instancesをおよそ7:1:2の比率でTrain,Valid,Testに分け、教師データとしては各instanceにつきレンダリング画像5枚を使用します。
まずは、ニューラルネットによる3Dの学習および表現力をテストする目的で、1 instanceのみの学習を行いました。つまり、ある特定の1物体に限定して、その物体を様々な角度から見たRGB画像およびシルエット画像を用いてネットワークを学習し、学習データには含まれないような未知視点からの画像を再現出来るかどうかをテストします。
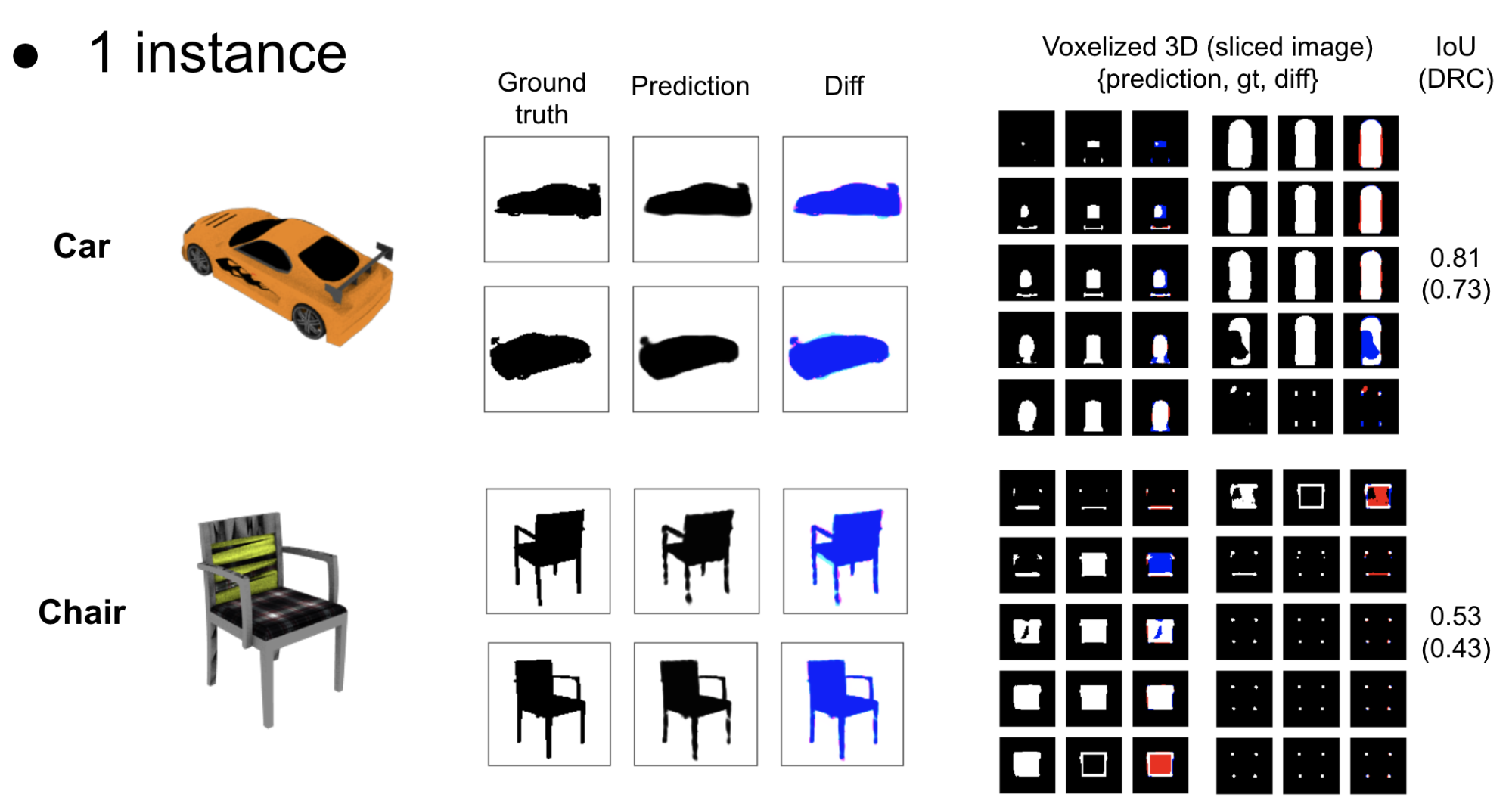
左から順に、InputのRGB画像、学習後に未知視点からのレンダリングを行った結果(Gt, 出力, 差分)、3D構造をスライスして可視化した図(ニューラルネット3Dを一定のthreshold値でvoxel化, 教師3Dデータ, 差分)、3D再構成の精度(voxel IoU)を表しています。DRCと比べても十分な精度が出ています。
次に、複数instanceでの学習を行いました。
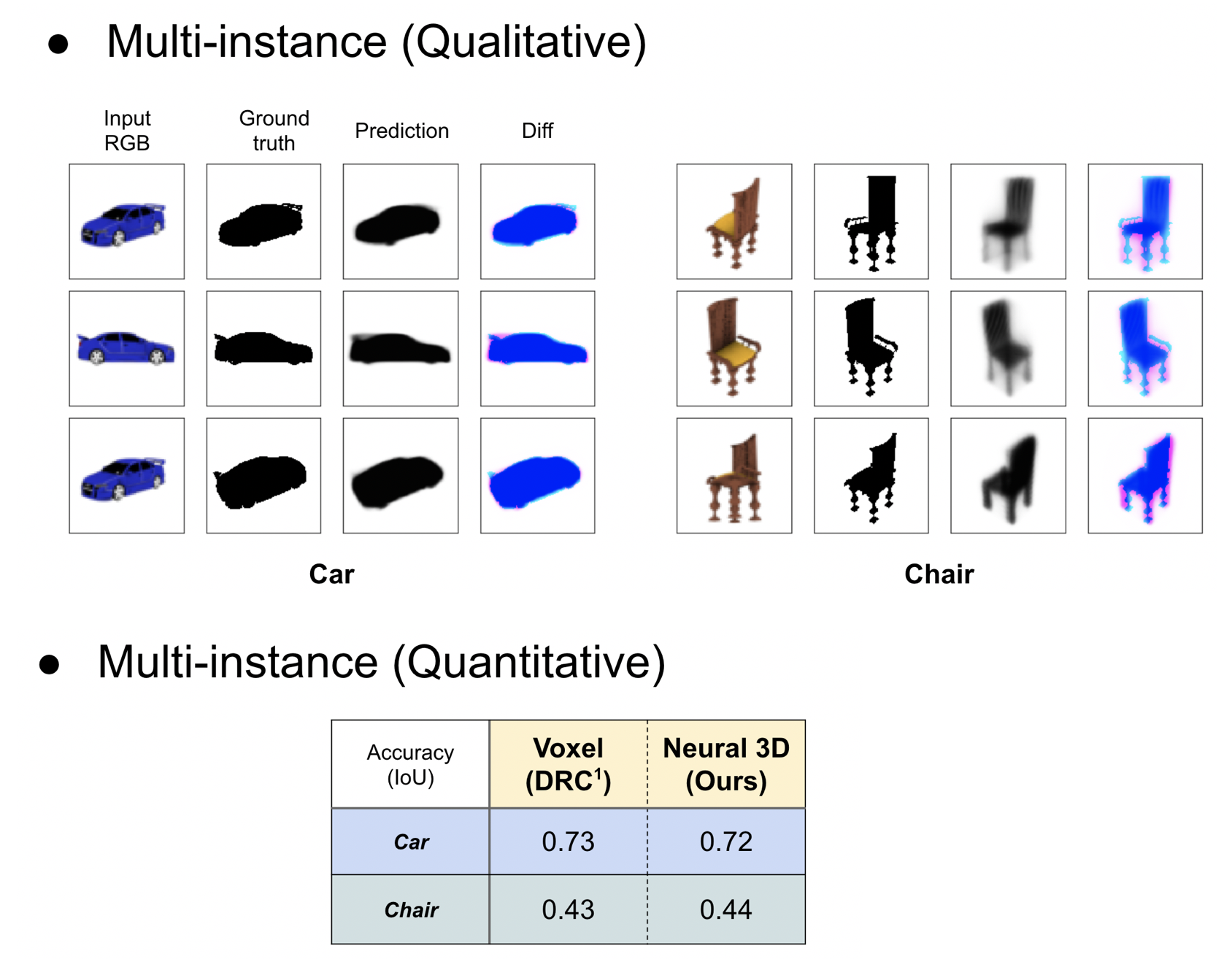
3D再構成のQualitativeな結果 (見た目)とQuantitativeな結果 (平均精度) を示しています。DRCと同等の精度が得られました。つまり、ボクセルの予測と同等の精度を保ちつつ、メモリ使用量の問題を解決したことになります。さらに、同じくニューラルネット表現を用いたSRN [4]と比べても、学習に必要な視点数(1つの物体あたりに用いることが出来る画像数)が50→5枚へと大幅に削減することに成功しました (SRNでは3D再構成の精度を計測することが困難であるため、精度の比較に関しては行っていません)。
今後の課題
今後の課題としては、
- 3D再構成の精度を上げる。
- メモリ使用量の比較。
- RGB画像での3D再構成実験。
- DRC以外の先行研究と同条件での比較。
などが考えられます。
引用文献
微分可能レンダラー (2D supervision)
[1] “Neural 3D Mesh Renderer” (Kato+ CVPR 2018)
[2] “Learning View Priors for Single-view 3D Reconstruction” (Kato and Harada CVPR 2019)
[3] “Multi-view Supervision for Single-view Reconstruction via Differentiable Ray Consistency” (Tulsiani+ CVPR 2019)
[4] “Scene Representation Networks: Continuous 3D-Structure-Aware Neural Scene Representations” (Sitzmann+ NIPS 2019)
3D supervision (メッシュ、ボクセル、点群)
[5] “PM-GANs: Discriminative Representation Learning for Action Recognition Using Partial-modalities” (Wang+ ECCV 2018)
[6] “Octree Generating Networks: Efficient Convolutional Architectures for High-Resolution 3D Outputs” (Tatarchenko+ ICCV 2017)
[7] “A Point Set Generation Network for 3D Object Reconstruction From a Single Image” (Fan+ CVPR 2017)
3D supervision (ニューラルネット関数)
[8] “Occupancy Networks: Learning 3D Reconstruction in Function Space” (Mescheder+ CVPR 2019)
[9] “DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation” (Park+ CVPR 2019)
[10] “Learning Implicit Fields for Generative Shape Modeling” (Chen and Zhang CVPR 2019)
メンターからのコメント
メンターを担当したPFNの加藤と安藤です。CGのスキルを活かしつつ深層学習のスキルを高めたい、という希望をもとに両者が交差するテーマである新規な微分可能レンダラーの開発を担当していただきました。自ら関連研究をサーベイし読み込み手法を開発してゆく能力が高く、本人の主軸とする分野から少し離れるにも関わらずメンターとしてのサポートは最小限で済み、さすがと思わせられました。
ニューラルネットワークによる3D形状の表現は近年急速にホットになりつつあるトピックですが [8, 9, 10]、そのレンダリングと深層学習との接続に関してはほとんど前例がない状況です。その中で、素直なアルゴリズムによって、複雑な学習 [4] を用いずともボクセルによる先行例 [3] と同等程度の性能が出せるという発見は大きな意味があると考えています。一方で、インターンは一ヶ月と少しという短い期間であったため細部の調整は十分ではなく、数値性能の向上や色の扱いなどまだまだ発展の余地があり、もっと長期間取り組めばさらに面白いものが見られたのでは、という無念さも残るインターンでした。
