Blog
エンジニアの上野です。Cluster Servicesチームという、PFNのKubernetesベースの機械学習基盤を開発・運用するチームに所属して、基盤の改善や新機能の開発に務めています。本記事では、深層学習における学習データセット読み込み速度の改善を目指して開発し、現在もKubernetes上で運用中の分散キャッシュシステムを紹介します。
PFNの機械学習基盤については、ブログ「2022年のPFNの機械学習基盤」もご参照ください。
深層学習における学習データセット読み込み
深層学習を高速化するため、深層学習に向いたアクセラレータの開発が日々続けられています。PFNで開発しているMN-Coreシリーズや、NVIDIA社製GPUもそのひとつです。これらのアクセラレータは高速に行列演算を行うことができ、深層学習の1イテレーションにかかる時間を高速化、ひいては深層学習を活用する研究開発全体を加速させることができます。これに伴い、アクセラレータに学習データを高速に供給できるようにして、アクセラレータがデータ待ちで遊ばないようにする必要があります。
PFNでは3種類の特性の異なるストレージを運用しています。学習データを一時的に保管して高速に読み込んだり深層学習モデルのスナップショットを保存するために構築された、複数のNVMe SSDを束ねたNFSサーバ(Hot NFS)、データを保管するためのHDDベースのNFS(Archive NFS)、そしてオブジェクトストレージのOzoneです。Hot NFSは学習データセット読み込みには十分なスループットを持っています。しかし、拡大を続けるPFNのクラスタにとっては性能面でも容量面でもスケールアウトできないことが課題となっており、過負荷による性能の問題が発生したり、定期的なデータのクリーンアップが必要でした。Archive NFSやOzoneはHDDベースの永続ストレージですので、学習データセットを直接ランダムに読み込む用途では性能が低く、GPUやMN-Coreノードのローカルストレージにデータをキャッシュしつつ利用されていました。
しかし、ローカルストレージのキャッシュは、Kubernetesクラスタを高い利用効率かつフェアに保つために行う定期的なPodの削除(プリエンプション)と相性が悪いです。プリエンプションされた深層学習Podが別のノードに再度スケジュールされた場合、先のノードのローカルストレージにあるキャッシュデータにはアクセスできなくなります。そのため、再度HDDベースの永続ストレージから学習データセットを読み込んでキャッシュを作り直す必要がありました。また、扱えるデータセットのサイズもノードのローカルストレージの容量に制約されるため、せいぜい数TBのデータセットしか扱うことができません。
さらに、データ並列型分散深層学習や、ハイパーパラメータサーチや深層学習モデル改善などの研究開発の場合は、同一の学習データセットを何度も読み込む必要があります。よって、Podのライフサイクルをまたがってキャッシュが生存できれば何度もそのキャッシュを利用でき、HDDベースの永続ストレージから学習データセットを読み込む回数を削減できます。
これらの課題や要件をまとめると、クラスタ内のすべてのノードから読み込める共有ストレージであって、スケールアウト可能で、高速なストレージが必要とされていました。また、すでにArchive NFSやオブジェクトストレージのOzoneが運用されているため、永続ストレージとしての機能は不要です。そこで、Podのライフサイクルをまたがって利用できる分散キャッシュシステムを開発しました。
分散キャッシュシステムの設計
以下に開発した分散キャッシュシステムの構成を示します。システム全体はKubernetes上にデプロイされています。
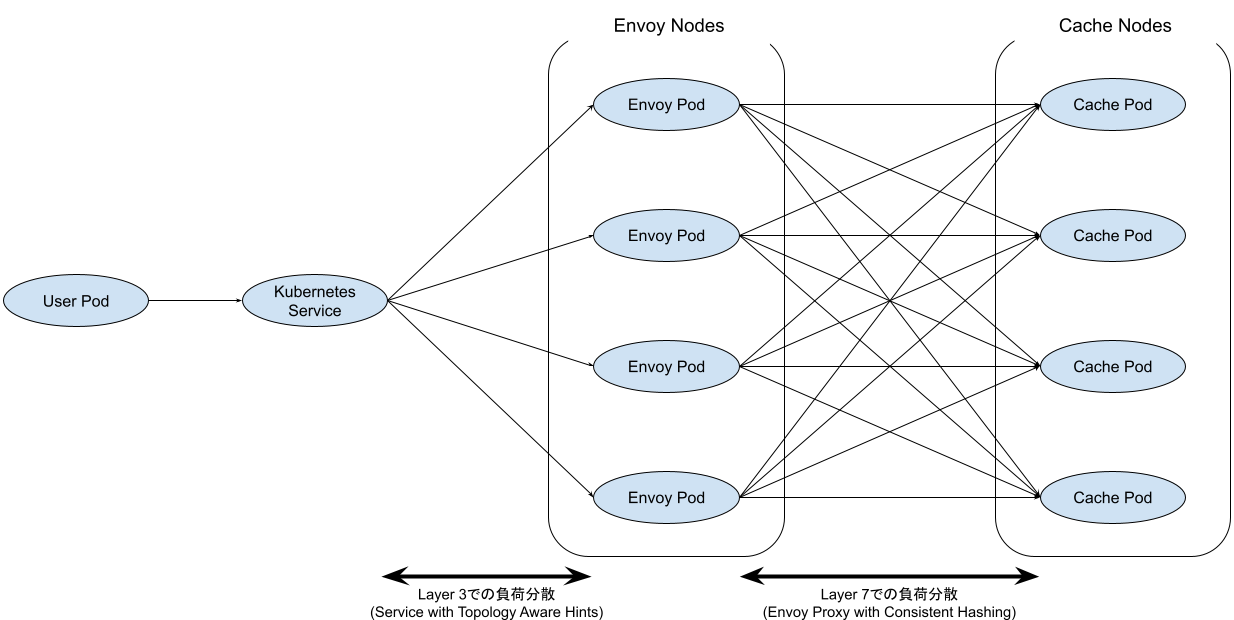
分散キャッシュシステムのユーザーPodは、HTTPを使って分散キャッシュシステムに接続し、PUTによってキャッシュしたいBlob(キャッシュデータ)を保存し、GETによってそのキャッシュデータを取得できます。キャッシュデータはバケットにまとめられていて、バケットと名前によってキャッシュデータにアクセスできます。ユーザーPodは、そのPodが実行されているNamespaceに基づいてバケット単位で認可されます。
システムには、Layer 3 での負荷分散を実現する Kubernetes Service (Topology Aware Hints 有効) 、Layer 7 での負荷分散を実現する Envoy Pod (バケットと名前に基づくConsistent Hashing)、そしてキャッシュデータをローカルストレージに保持して配信するキャッシュPodがあります。
通信の流れとコンポーネントの役割
各コンポーネントの役割を通信の流れ(ユーザーPodからキャッシュPod)に従って説明します。
ユーザーPod
PFNではPFIO [1] という深層学習向けのI/O抽象化ライブラリを開発しています。これはオブジェクトストレージであるOzoneやPOSIX filesystemを抽象化して同一のAPIで扱えるようにしつつ、ユーザーランドでキャッシュを提供するライブラリです。これまでは、ノードのローカルストレージを使ったキャッシュの利用が中心でした。しかし、前述したようにノードローカルストレージはPodのプリエンプションで揮発しますし、キャッシュできる最大量も計算ノードに搭載されたストレージの容量で制約されてしまいます。今回開発した分散キャッシュをPFIOから利用して、プリエンプションで揮発せず、ローカルストレージに制約されない大容量なキャッシュを実現できます。
分散キャッシュを利用したいKubernetes Podは、アクセスしたいキャッシュデータのバケット名と名前をパスとして、HTTPリクエストを送信します。このときに、Authorization ヘッダにBearer トークンを付与しておきます。このトークンは、Kubernetes Bound Service Account Token [2] を利用して、のちほど TokenReview APIを使って送信元のKubernetes Namespaceを判別できます。
Envoy Pod (リバースプロキシ) へ
HTTPリクエストは、Layer 3 での負荷分散を行える Kubernetes Service を利用してリバースプロキシにルーティングされます。このときにTopology Aware Hints [3] を利用しています。これは、Kubernetes ノードにあらかじめ設定しておいたゾーンラベルを使って、送信元の Pod と「できるだけ」同じゾーンの Endpoint にトラフィックがルーティングされるようにします。これによって、ゾーンをまたぐようなトラフィックを減らすことができます。
PFNのクラスタではCLOSネットワークトポロジを採用しています。リーフスイッチと呼ばれる末端のスイッチに複数のノードが収容されていて、スパインスイッチが複数のリーフスイッチを収容する構成になっています。本稿でゾーンと呼んでいるのは、同一のリーフスイッチに収容されたノード群のことで、Topology Aware Hints を使用して、リーフ・ノード間に比べて oversubscribe されているリーフ・スパイン間のトラフィックを節約できます。
Envoy Pod から キャッシュPod まで
負荷分散のポリシーは Consistent Hashing を利用しています。Consistent Hashing は、リクエストごとに定義された Key が同一の場合に同一の Endpoint (キャッシュPod) にルーティングする負荷分散手法です。Key と Endpoint の対応として表の代わりにハッシュ関数を利用して、表を管理せずにどの Envoy Pod に同じ Key を持つリクエストが到達したとしても一貫して同じ Endpoint にトラフィックをルーティングできます。また、あるKeyに対応する Endpoint が利用できない状態になったとき、ハッシュ関数を利用して別の Endpoint への対応を自動的に作ることができ、またそのときに更新されるKeyとEndpointの対応の数が少なくなるように工夫されています。
この負荷分散を実現するために、本システムではリバースプロキシとしてよく知られた Envoy を利用しています。Envoy は、利用可能なEndpointの情報をプログラマブルに更新できる EDS (Endpoint Discovery Service) という機能を持っています。Kubernetes 上にデプロイされたキャッシュPod の情報(IPアドレス、スケジュールされたノードの名前、健全性など)を Kubernetes Informer 経由でリアルタイムに取得して、EDS で Envoy に伝えるコンポーネントを実装しました。これにより、キャッシュPodを追加したり、何らかの理由でキャッシュPodが再作成されてPod IPが変更になったり、ノード障害で一部のキャッシュPodを実行できないような状況になった場合に、その情報が Kubernetes の Informer から通知され、それを EDS で Envoy にリアルタイムで流し込むことで、分散キャッシュシステムとしては問題なく動作し続けることができます。キャッシュPodが利用できなくなった場合には、そのPodが管理していたキャッシュデータは失われてしまいますが、本稿で目的としているキャッシュシステムの観点からは問題がありません。
キャッシュPod
キャッシュPodは、Envoy Podから転送されてきたHTTPリクエストに結果を返して良いか判断するために、TokenReview APIを使ってどのKubernetes namespaceからきたリクエストかを確認します。namespace名が分かったら、どのバケットを利用してよいのかの認可を行います。認可されれば、SQLiteに保存されたメタデータを読み出して、キャッシュデータの実体をローカルにフラットに保存されたファイルから読み出して送信します。このとき、sendfile(2) システムコールを使って効率的な転送を実現しています。また、ローカルディスクの容量には上限があるので、ユーザーがアップロードしたキャッシュデータの総量が上限を超えてしまうときは、LRU (Least Recent Used)で最近使用されていないオブジェクトから順に自動で削除しています。この場合もキャッシュデータが失われますが、本稿で目的としているキャッシュシステムの観点からは問題がありません。
ルーティングの具体例
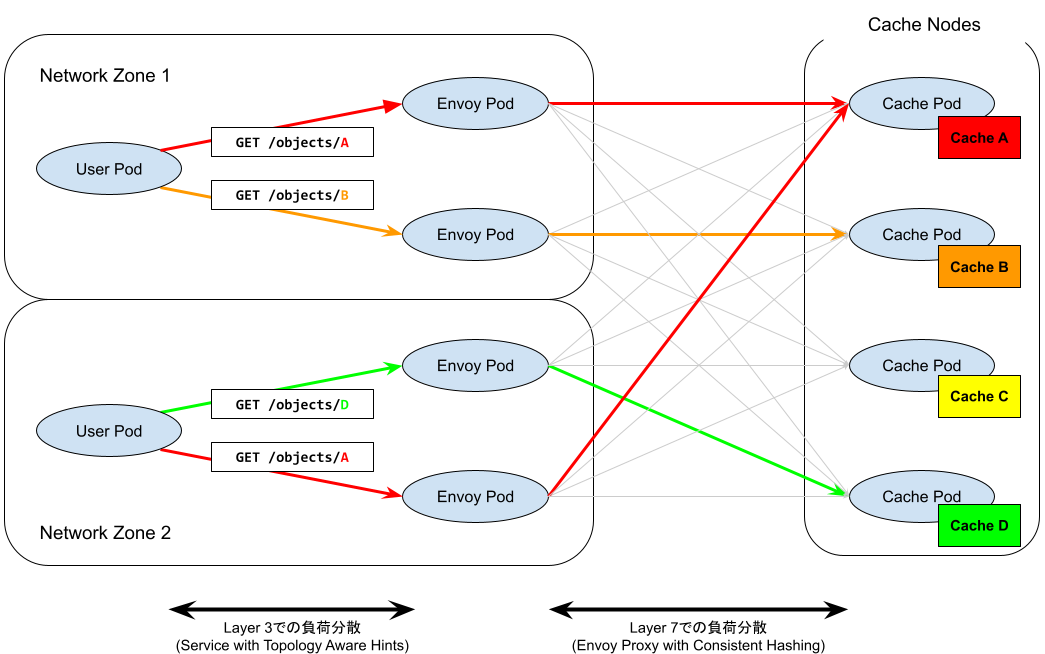
上図に2つのユーザーPodがキャッシュデータA, B, Dにアクセスする場合のルーティングの具体例を示しました。それぞれのユーザーPodからのHTTPリクエストは、同じネットワークゾーン内のEnvoy Podにルーティングされます。そして、それぞれのEnvoy Pod(リバースプロキシ)は、アクセスしたいキャッシュデータに対応するキャッシュPodを Consistent Hashing を用いて解決し、そのキャッシュPodにルーティングします。異なるユーザーPodが同一のキャッシュデータを利用したい場合(本図では、それぞれのユーザーPodが送信するキャッシュデータAのリクエスト)は、異なるEnvoy Podがリバースプロキシを担当する場合でも、Consistent Hashingを用いることで一貫したキャッシュPod(本図では、一番上のキャッシュPod)にルーティングされます。
うまくいった点
Consistent Hashingを利用したことで、システム全体でメタデータ、たとえばどのキャッシュPodにどのオブジェクトが保存されているかや、オブジェクトがいつアップロードされたかなどの情報を集中的に管理する必要がなくなりました。これを中央管理するコンポーネントがあるアーキテクチャの場合、このコンポーネントが失われるとシステム全体が停止してしまったり、性能の劣化がシステム全体の性能劣化に直結します。代わりにConsistent Hashingを利用してメタデータを分散させて、それぞれのキャッシュPodで管理することで、スケールアウトしやすく壊れづらいアーキテクチャを目指しました。また、ユーザーPodから利用するときのプロトコルとしてHTTPを採用したことで、さまざまな言語からでも利用しやすいシステムになったと考えています。
既知の問題点
既知の問題点としては、キャッシュPodが一時的に利用できなかったが後に復活したような場合に、オブジェクトが一時的に見えなくなったり内容がロールバックしてしまう可能性があり、一貫性を担保できていません。この問題に対処するため、キャッシュデータの更新時には別の名前で新しく追加してもらうことにしています。実用上は、学習用データセットの内容を一部だけ更新したいことは少ないですし、しばらくアクセスのない古いオブジェクトはLRUで自動削除されるので、特に問題にはなっていません。
運用を続けてきて
PFNでは、この分散キャッシュシステムを昨年の10月ごろから運用しています。運用を続けていく中で発生した課題について紹介します。
キャッシュが急増して寿命が短くなりすぎる
この分散キャッシュシステムでは、LRUによって最近利用されていないキャッシュデータは自動で削除されるようになっています。キャッシュデータが急増したときに、分散キャッシュシステムの容量を適切にスケールできない場合、キャッシュデータの寿命が短くなってしまいます。寿命があまりに短い場合は、スラッシングのような現象が起こり、誰もキャッシュによる高速化が得られなくなります。今回のキャッシュシステムの場合では、LRUによってキャッシュが揮発するまでの最短時間を監視し、しきい値を下回った場合はアラートを発報するようにしました。
キャッシュPodの負荷とオブジェクト数が偏る
運用を開始した当初は、Consistent Hashing の実装として Envoy の RING_HASH というアルゴリズムを利用していました。この方法は、Keyのハッシュ値とEndpointのハッシュ値を計算し、近いハッシュ値どうしで対応付けるものです。理論的にはうまくいく方法ですが、計算されたハッシュ値をそのまま使うため、十分なKey数やEndpoint数がないような現実の環境では対応が偏ることがあります。我々の環境でも、実際にEndpointによって2倍近く負荷とオブジェクト数が偏り、さらにEndpointによってキャッシュデータの寿命が異なるようになりました。スケールアウトによって容量を拡張することでキャッシュデータの寿命を長くすることができますが、このように偏りがある場合はその効果が弱くなります。
この問題は、Envoy が実装している別の負荷分散アルゴリズム MAGLEV [4, 5] を採用して解決しました。MAGLEV は、ハッシュを使うものの偏りがないようにその結果を決定的な方法で再配分するアルゴリズムです。Endpointが更新された時に、KeyとEndpointの更新される対応の量は RING_HASH に比べて若干増えてしまいますが、ロードインバランスによるEndpointごとのキャッシュデータの寿命の差や負荷の方よりの方が重要な課題だったため、MAGLEVを採用することにしました。しかし、事前の検証でEnvoy の MAGLEV実装が決定的な振る舞いをしておらず、Envoy Podによってルーティング先が異なる場合があることがあったため、PR [6] を出して修正してもらいました。
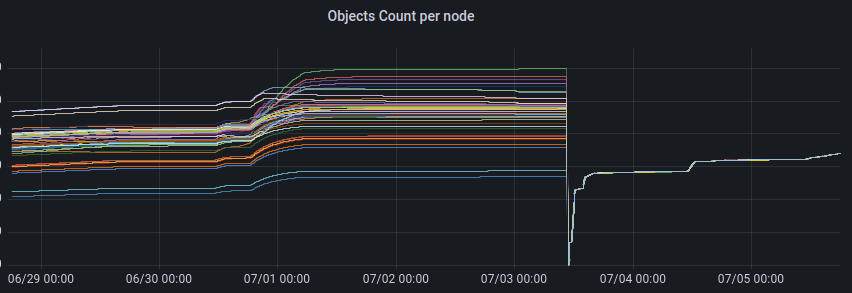
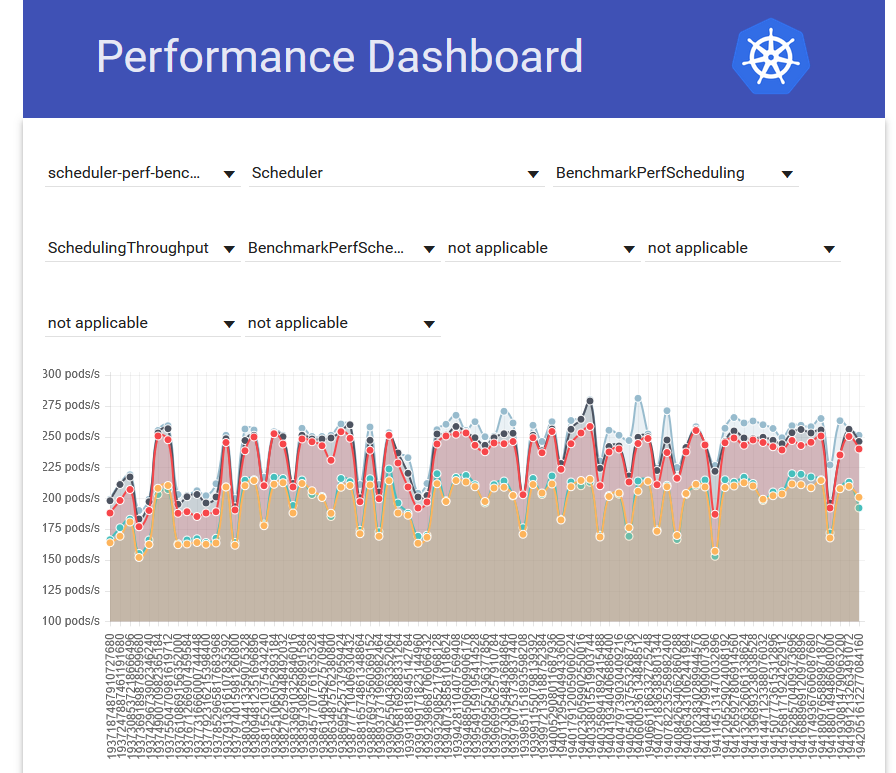
上図は、キャッシュPodごとにアップロードされたオブジェクトの数の時間変化を示しています。7/3にConsistent Hashingのアルゴリズム変更をデプロイし、オブジェクト数の偏りを解消できました。
同一のリクエストに対するレイテンシが安定しない
同じキャッシュデータを取得するリクエストに対するレイテンシが安定しない、というやっかいな課題もありました。調査を行った結果、同じ物理ノードにリバースプロキシの Envoyとほかの深層学習ワークロードの混載を許しているたために、CPUヘビーな深層学習ワークロードが同居した場合に tail latency が劣化する、という現象が起きていたことが分かりました。分散キャッシュシステムを作った当初は、Topology Aware Hints ではなく 、internalTrafficPolicy [7] を使うことで、ローカルホストの Envoy のみを利用するようにしており、Envoy までの負荷分散が十分ではなかった、ということもその一因でした。Topology Aware Hints を利用して同一 Zone 内までのネットワークコストを抑えた負荷分散を実現しつつ、より適切なリソース要求への見直しを行うことで、性能が安定しました。
まとめ
本記事では、深層学習のデータセット読み込みを高速化するための分散キャッシュシステムを紹介しました。ボトルネックになりやすく単一障害点になりやすいメタデータを集中管理するコンポーネントの導入を避け、スケールアウトするようなアーキテクチャを目指し、Consistent Hashingを採用しました。分散キャッシュシステムはすでに多くの社内プロジェクトで採用されています。今後の課題として、さらなる高速化とアクセラレータへの直接データ読み込みを目指したRDMA化の検討、社内外のストレージと組み合わせたキャッシュの透過的な利用などがあります。
We are hiring!
PFNは自社の機械学習基盤を開発運用しつつ、将来的には外部へ計算資源を提供したいと考えています。Kubernetesの知識がある方はもちろん、機械学習の実践経験やHPC、性能最適化・高速化に興味がある(この記事がおもしろいと感じた方も!)方を募集しています。もしご興味がある方、我こそはという方がいらっしゃいましたら、Careers ページの Job Openings からご応募いただくか、お近くのPFN 社員にお声がけください。
References
- [1]: pfnet/pfio: IO library to access various filesystems with unified API
- [2]: Managing Service Accounts | Kubernetes
- [3]: KEP-2433. Topology Aware Hints
- [4]: Eisenbud, Daniel E., et al. “Maglev: A fast and reliable software network load balancer.” 13th USENIX Symposium on Networked Systems Design and Implementation (NSDI 16). 2016.
- [5]: Supported load balancers — envoy 1.27.0-dev-ad3c1c documentation
- [6]: maglev: fix maglev stability by sorting host_weights beforehand by y1r · Pull Request #28055 · envoyproxy/envoy
- [7]: KEP-2086. Service Internal Traffic Policy
Area