Blog
本記事は、2022年夏季インターンシッププログラムで勤務された矢田宙生さんによる寄稿です。
はじめまして!PFNの2022年の夏インターンに参加した早稲田大学・山名研究室所属の矢田宙生です。普段研究室では、機械学習を活用したWeb上の悪質なUI/UXの自動検出に関する研究をしています。
今回の夏インターンでは、アクティブラーニングの手法を活用した物体認識(セマンティックセグメンテーション)における効率的なアノテーションツールの開発に取り組んでいました。本記事では、開発したツールの概要と技術的背景に関する説明、インターンの感想などについて紹介を行います。
1.はじめに
現在、PFNの社内では、製造業やロボティクス等をはじめとするプロジェクトに関連して、様々な画像認識の研究開発が行われています。機械学習(深層学習)で画像認識に取り組む際に、避けて通れない作業が大量の画像データに対するアノテーションです。
多くの機械学習エンジニア・リサーチャーの頭を悩ませる作業であるアノテーション。今回対象にしたタスクであるセマンティックセグメンテーションのためのアノテーションは、単なる画像に対するラベル付けではありません。画像を特定の領域やピクセルといった単位で分割し、それぞれに対するラベル付けが必要です。そのためセマンティックセグメンテーションに対するアノテーションは画像のアノテーションの中でも、特にコストがかかると考えられます。
あくまで参考値ですが、セマンティックセグメンテーションの代表的なデータセットの一つであるCityscapesのアノテーションには一画像あたり、90分程度要するとも言われています[1]
そこで、本インターンでは、訓練済みモデルとアクティブラーニングの手法の一つであるRIPUという計算を活用したアノテーション補助機能を搭載したアノテーションツール「VeloxLabel」を開発しました。
2.VeloxLabelの紹介
早速デモを見ていきましょう。以下が今回開発したVeloxLabelになります。
VeloxLabelでは、右上の「AIアノテーション」ボタンをクリックすることで、画像の一部に対して、自動アノテーションが施すことが可能です(アノテーション補助機能)。ユーザであるアノテータは、左側にあるパレットから色を選択し、自動アノテーションの結果を修正することによって、最終的なアノテーションを作成します。なお、デモ動画では、「AIアノテーション」のための深層学習モデルの推論をCPU(ローカルPC)上で実行している、という背景もあり、15 ~ 25秒程度を要します。
正確な検証はできていませんが、このようなアノテーション補助機能を導入することで、ゼロからのアノテーションと比較し、より短い時間でアノテーションを完了できることが期待されます。
なお、VeloxLabelのVeloxにはラテン語で「速い、迅速な」といった意味があります。本ツールを利用することによって、アノテータが迅速にアノテーション作業ができるようになって欲しい。そんな想いに因んでVeloxLabelと命名しました。
以下では、このVeloxLabelを支える理論・技術に関する説明を行います。
3.RIPUに関する解説
3.1 概要
ここでは、2022年6月、コンピュータビジョン分野のトップカンファレンスであるCVPRのOralで発表された”Towards Fewer Annotations: Active Learning via Region Impurity and Prediction Uncertainty for Domain Adaptive Semantic Segmentation” [2] に関する紹介を行います。本論文で発表されたRIPUという計算は、VeloxLabelのコアとなる手法です。
以下は論文の概要になります。
- セマンティックセグメンテーションのための画像データに対するアノテーションコストを減らすことを目的としたアクティブラーニングの手法を提案
- 画像から、アノテーションする領域をRIPUという計算によって一部抽出し、その領域のみを人手でアノテーションする
- 本論文が提案した「RIPUを活用したアクティブラーニングにより学習されたモデル」を評価した結果、「全てアノテーションされた実画像により学習されたモデル」に迫るパフォーマンス(mIoU)が得られた
3.2 アクティブラーニング
まず、背景知識となるアクティブラーニングについて簡単に説明を行います。
既に述べた通り、モデルの学習に用いるデータ全てに対して、手作業でアノテーションを施すのは非常にコストがかかります。できることであれば、データセットのアノテーションに必要なコストを減らしつつ、高い精度のモデルを作成したいものです。
それを実現する代表的な手法として自己学習(self-training)があります。自己学習では、まずデータの一部(ラベリング済み)もしくはラベリング済みの別ドメインのデータ等を用いてモデルの学習を行います。そのモデルを用いて、ラベルなしデータを推論し、推論結果を擬似的な正解ラベルとして付与し、再度学習を行います。具体例としては、本論文で用いているデータのように、ラベリング済みのCG画像(ラベリング済みの別ドメインのデータ)で学習されたモデルを用いて、ラベルなしの実世界の画像(ラベルなし)を推論、などが挙げられます。
しかし、自己学習は、ラベルなしデータに対する擬似的な正解ラベルが既にあるラベリング済みデータの偏りに強い影響を受けてしまうという難点があります。そのため、自己学習のみでは十分な精度が出ません。
そこで、アクティブラーニングでは、ラベルなしデータから学習効果の高いデータを抽出し、抽出したデータのみを人手でアノテーションすることで精度を改善します。データ全体にアノテーションを施す必要がなくなる分、アノテーションにかかるコストを小さくすることが可能です。
画像認識の文脈でのアクティブラーニングではラベルなしの画像データから「アノテーションする画像」もしくは「各画像におけるアノテーションする領域」を抽出します。本論文では、「各画像におけるアノテーションする領域」(後者)を抽出することによってアノテーションのコストを小さくしています。
ここで肝となるのが、「各画像におけるアノテーションする領域」すなわち「学習に効果的とされる画像の領域」をどのようにして抽出するのか?という点です。本論文では、その方法としてRIPUという手法を提案しました。
3.3 RIPU
本論文が提案した手法では、ラベルつきのCG画像と擬似ラベルを付与した実画像によって自己学習されたモデルを用いて、ラベル無しの実画像を推論した結果に対し、RIPUという計算を施します。
RIPUは”Region Impurity and Prediction Uncertainly”の頭文字をとって命名されており、セマンティックセグメンテーションモデルの推論結果に対して、”Region Impurity”と”Prediction Uncertainly”という2つの値を算出します
まずは、Region Impurityについてです。計算式は以下になります。
\[ p^{(i,j)} = – \sum_{c=1}^{C}\frac{|N_k^c(i,j)|}{|N_k(i,j)|}\log \frac{|N_k^c(i,j)|}{|N_k(i,j)|} \]
\[ C : セマンティックセグメンテーションのクラス数 \]
\[ N_k(i,j) : ピクセル(i,j)を中心とした、辺の長さが2k+1の正方形の形状をした画像内の領域 \]
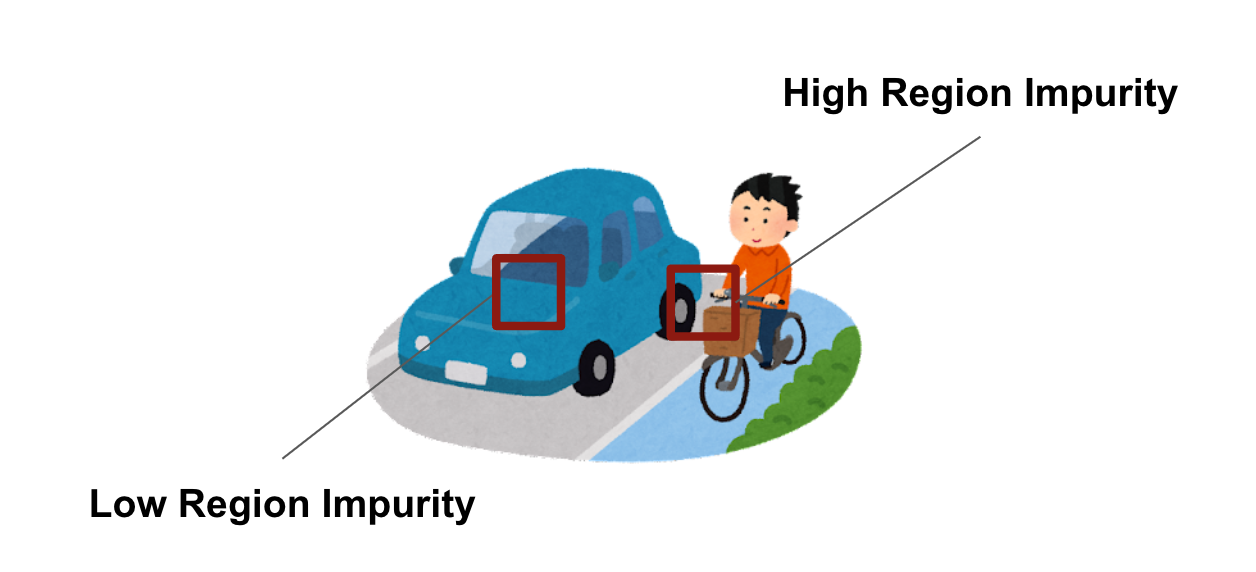
Region Impurityは、推論結果における多数のクラスが密集しているような領域すなわち物体と物体の境界にあたる領域が高い値になるような計算です。直感的な理解がしやすいように、成果発表の際、Region Impurityの説明に用いた図を以下に掲載します。
次に、Prediction Uncertainlyです。計算式は以下になります。
\[ u^{(i,j)} = H \]
\[ H^{(i,j)} = – \sum_{c=1}^{C} P^{(i,j,c)}_{t} \log P^{(i,j,c)}_{t} \]
\[ P^{(i,j,c)}_{t}: 推論結果に対し、ピクセル(i,j)がクラスcに該当する確率 \]
こちらについては非常にシンプルで推論結果のエントロピーすなわち予測の曖昧度を各ピクセルに対して計算します。
RIPUはこの2つの値の各ピクセルごとの積(\(\odot\))を取ることにより算出されます。
\[ A(I_t;\Theta^n) = p \odot u \]
学習時点でのモデルによる推論結果に対して、RIPUの計算結果の値が高いような領域というのは、特に予測の曖昧度が高く、たくさんの物体が存在するような領域であると言えます。そのような領域を中心に人手でアノテーションすることでアクティブラーニングを実行するというのが本論文が提案した手法です。
3.4 再現実験
さて、ここまでで簡単にではありますが、論文の提案手法に関する説明を行いました。本論文の提案手法であるRIPUを用いたアクティブラーニングの実験用コードは著者により一般公開されています。今回は、このコードを用いて、提案手法の手法の再現実験を行いました。
必要となるデータセットであるGTAV[3] とCityscapes[1] をダウンロードし、検証を行います。セマンティックセグメンテーションのためのモデルとしては、DeepLab v2 [4] とDeepLab v3+ [5] を用いています。RIPU により抽出される人手でアノテーションされる領域を40 px,(画像全体の)2.2%,5.0%と変化させ、アクティブラーニングによるモデルの学習・検証を行いました。
実験結果は以下の通りとなりました。
| Model + Annotated region | mIoU |
|---|---|
| Deeplab-v2 + 40 pixel | 65.5 |
| Deeplab-v2 + 2.2% | 69.6 |
| Deeplab-v3plus + 5.0% | 71.2 |
| Fully Supervised | 71.9 |
実験結果から分かるように、「RIPUで抽出された領域のみを人手でアノテーションした実画像により学習されたモデル」は、「全て人手でアノテーションされた実画像により学習されたモデル(Fully Supervised)」に迫る精度を出していることがわかります。
定性的な評価として、検証データに対する推論結果(Deeplab-v2 + 40pixel)とGround Truthを比較してみます。
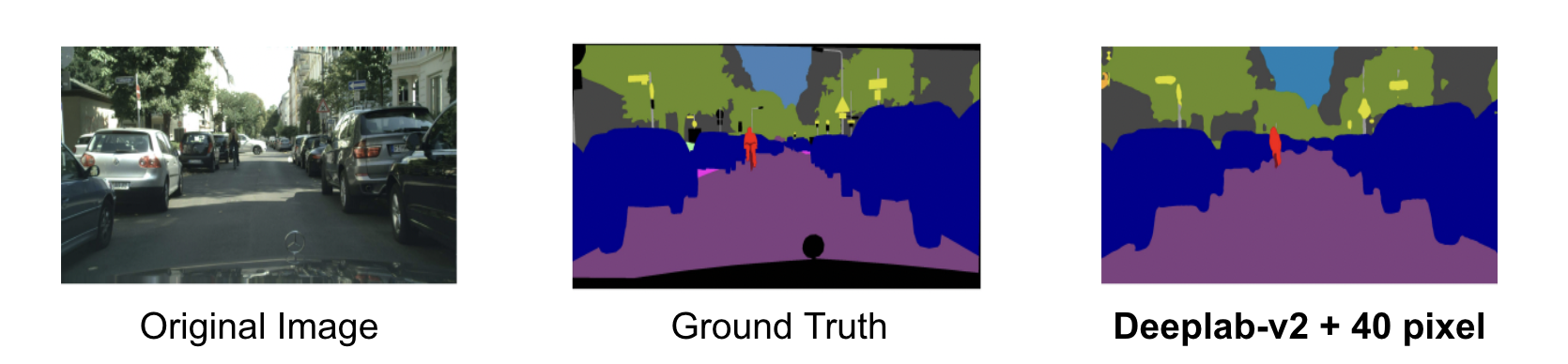
Ground Truthに近いような推論結果が得られていることがわかります。
また、おまけとして、PFNのオフィスが存在する大手町の画像についても推論してみた結果が以下となります。
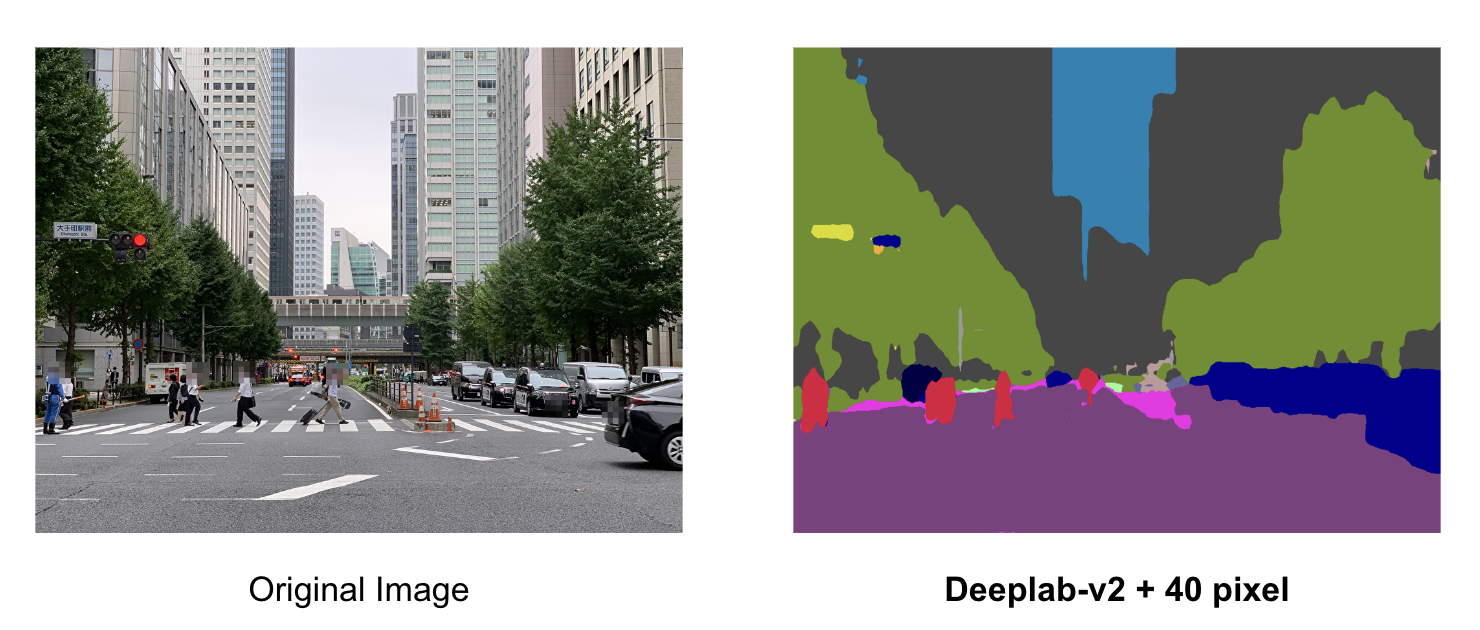
3.5 論文のまとめ
以上が”Towards Fewer Annotations: Active Learning via Region Impurity and Prediction Uncertainty for Domain Adaptive Semantic Segmentation”の内容とその再現実験に関する紹介です。まとめると、本論文とその再現実験を通して以下のような知見を得ることができました。
- RIPUを利用したアクティブラーニングにより学習されたモデルは、実画像のみで学習されたモデルに迫る高い精度を出すことができる
- RIPUはセマンティックセグメンテーションの推論結果に対して、「複数の物体が存在する領域(物体と物体の境界)」「予測結果の曖昧度が高い領域」を抽出する上で優れた手法である
ここでは、今回実装したアノテーションツール・VeloxLabelのコアとなるアクティブラーニングの手法であるRIPUの論文内容と再現実験に関する紹介を行いました。次章では、このRIPUを活用した事前アノテーション機能を説明していきます。
4.訓練済みセマンティックセグメンテーションモデルとRIPUを用いたアノテーションツール
今回の手法では、まず、これからアノテーションしたい実画像に対する、
- ラベルありの別ドメインの画像データ(CG画像等)
- 一定枚数以上の、既にアノテーション済み(ラベルあり)の実画像のデータ
のいずれか、もしくは両方が存在することを仮定します(自己学習・アクティブラーニングにおける前提条件と同様)。前提として存在する画像データを用いて、セマンティックセグメンテーションモデルを訓練することが可能です。
ここで考えられるアノテーション補助として、そうして作成したモデルをバックエンドに配置し、それを用いた推論により画像全体に事前アノテーションを施す、という方法です。しかし、その方法では、推論が間違っている領域に対して、アノテータによる塗り直しの作業が生じます。間違っている領域が広範に渡っていた場合、「塗り直しの作業にかかる時間」の方が「ゼロからアノテーションをする時間」より長いという事態になりかねません。
そこで「複数の物体が存在する領域(物体と物体の境界)」や「予測結果の曖昧度が高い領域」といった推論が間違っている可能性が高い領域に関しては事前アノテーションをせず、それ以外の領域のみ事前アノテーションを行う、というアノテーション補助機能を考案しました。「複数の物体が存在する領域(物体と物体の境界)」や「予測結果の曖昧度が高い領域」の抽出に、前章で説明したRIPUを用いています。
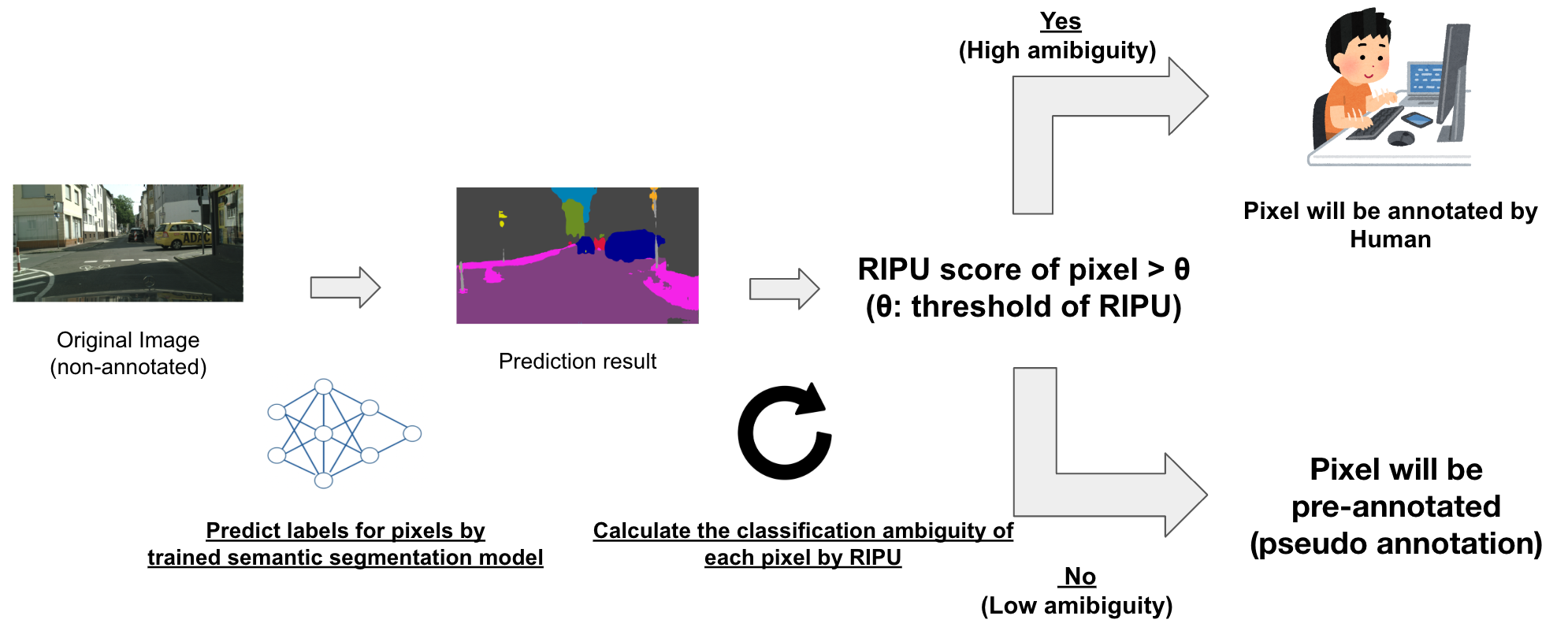
具体的には、まずアノテーションしたい画像に対して、訓練済みモデルを用いた推論を実行します。次に、推論結果から各ピクセルに対するRIPUを計算します。そして、RIPUの閾値\(\theta\)を事前に設定しておき、
- \(\theta\)を超えない領域(Pixel) ⇨ 推論結果に基づき事前アノテーション
- \(\theta\)を超える領域(Pixel) ⇨ 人手でアノテーション(事前アノテーションしない)
という手法になります。以下は手法の概要図です。
また当然ですが、アノテータが作業を進めていくことで、アノテーション済みの実画像(ラベル付き実画像)が増えていきます。したがって、それらのアノテーション済みの実画像を用いて、事前アノテーションに用いるモデルを再学習することが可能です。そのような再学習用の基盤を実装すれば、アノテーション作業を進めるに連れ、事前アノテーションの精度が向上していくと考えられます。
今回はそのような再学習の基盤を実装するには至りませんでした。しかし、代わりに「CG画像のみで学習されたモデル」と「そのモデルをラベル付き実画像N枚で再学習したモデル」のそれぞれによる事前アノテーションを定性的に評価する実験を行っています。(5章)
以上が今回実装した「訓練済みセマンティックセグメンテーションモデルとRIPUを用いたアノテーションツール」の概要になります。次章以降では事前アノテーションに関する実験やアプリケーションの実装を説明していきます。
5.事前アノテーションに関する実験
事前アノテーションの手法を考案した後、
- アプリケーションに用いるモデルの作成
- 事前アノテーションのクオリティを定性的に評価
という2点を目的に、前章で説明した手法による事前アノテーションに関する実験を行いました。セマンティックセグメンテーションのモデルとしてはDeepLab v3[6] 、データセットとしては先に紹介した論文と同様、別ドメインのデータ・CG画像としてGTAV、目的となる実画像のデータとしてCityscapesを用いています。
それでは、「CG画像で事前学習⇨実画像2975枚で再学習したモデル」と「RIPU」による事前アノテーションの結果を見てみましょう。なお、ここでは、RIPUの閾値\(\theta\)にはRIPUの計算結果の平均値を採用しました。
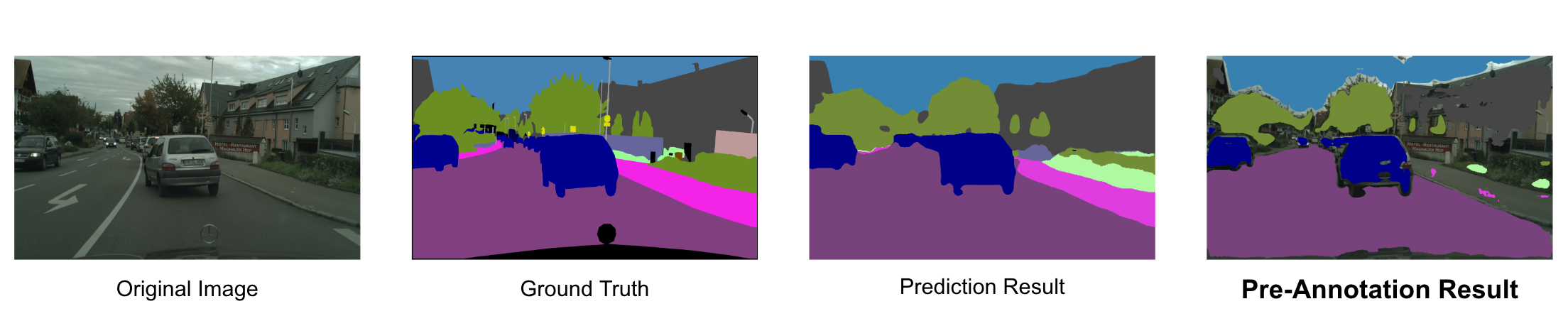
アノテーション結果を示す画像(Pre-Annotation Result)の色が塗られている領域がRIPUの値が閾値\(\theta\)よりも小さい領域、一方でそうでない領域は、RIPUの値が閾値\(\theta\)よりも大きい領域です。物体と物体の境界をはじめとするRIPUの計算結果が高くなりそうな領域には色が塗られていない(事前アノテーションが施されない)という直感に合った結果を得ることができました。
上の結果は「実画像 2975枚で再学習したモデル」であるため、人手による2975枚のアノテーション作業が完了したことを想定した事前アノテーションの結果になります。参考として、再学習に用いる画像の枚数を変えた時の事前アノテーションの比較結果が以下になります。(RIPUの閾値\(\theta\)は計算結果の平均値)
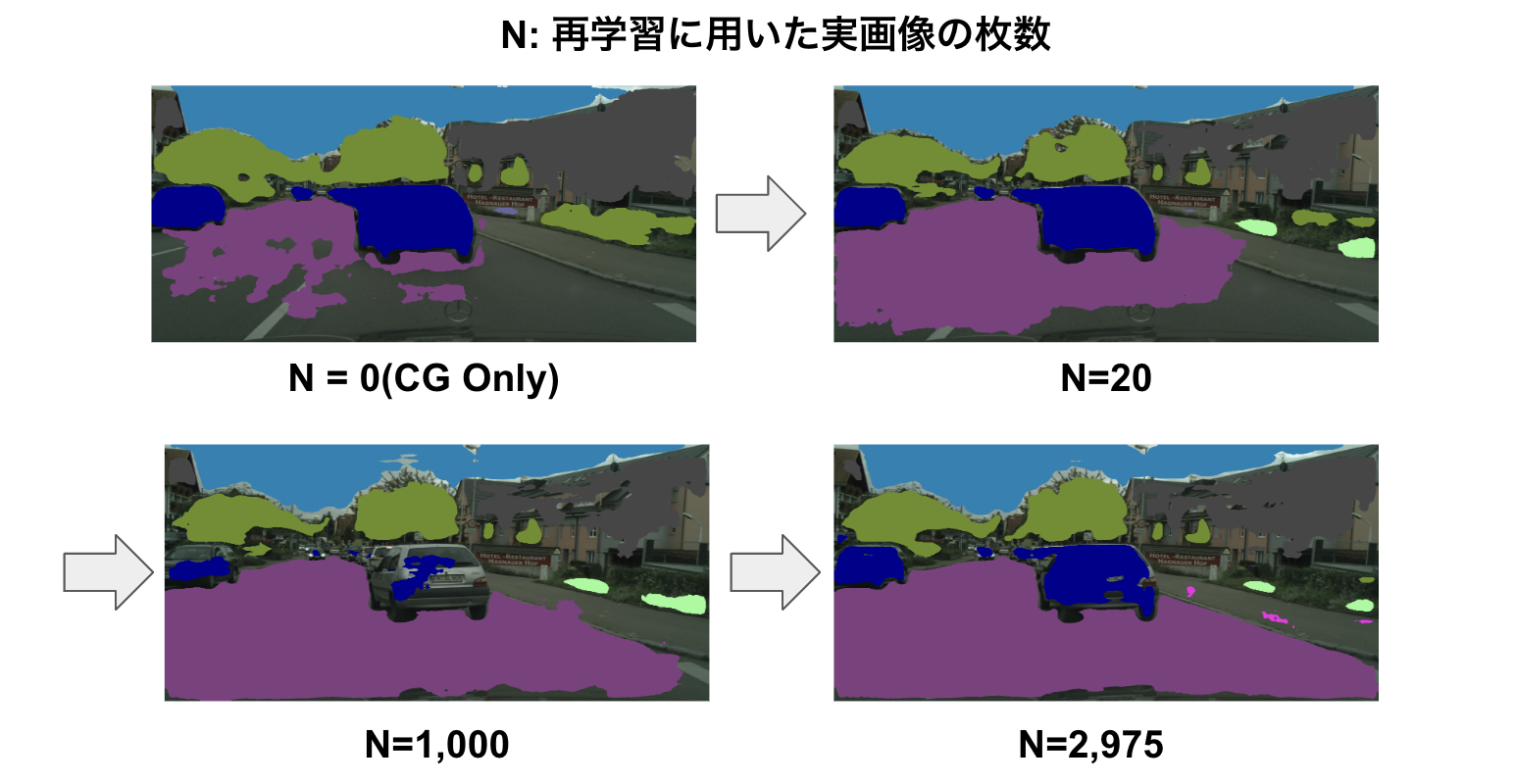
再学習に用いた実画像が少ない(0枚,20枚)モデルによる事前アノテーションは、比較的事前アノテーションされている領域が小さいような印象を受けます。しかし、再学習に用いた実画像が少ないモデルでも(アノテーション済みの実画像が少ない段階でも)、RIPUの効果によって、事前アノテーションが施されている領域に関しては正しいアノテーションができているように見受けられます。
以上が事前アノテーションに関する実験の説明です。この実験から、定性的な評価ではありますが、訓練済みセマンティックセグメンテーションモデルとRIPUによって、想定するような事前アノテーションが得られるということがわかりました。この結果を踏まえて、アプリケーションの実装を見ていきましょう。
6.アプリケーションの実装
本章では、ここまでで説明した手法によるアノテーション補助機能が搭載されたアノテーションツール・VeloxLabelのアプリケーション実装について、実際のコードなども見ながら、説明していきます。VeloxLabelでは、アプリケーションのバックエンドにはFastAPI, フロントエンドはReactを採用しました。それぞれについて見ていきましょう。
6.1 FastAPIによるバックエンド
6.1.1 技術選定
バックエンドはFastAPI(Python),Dockerで構築しています。VeloxLabelのバックエンドでは、PyTorchによる推論処理を実行できるようにする必要があります。そのため、Pythonの採用は必須でした。
そして、今回実装するのは「アップロードされた画像に対して、事前アノテーション結果を返す」というシンプルなAPIです。そのため、API構築に必要な最小限のツールのみが搭載された軽量なWebフレームワークであり、それでいて、「高速性」や「API Docsの自動生成」といった特徴を持つFastAPIを採用することにしました。
6.1.2 訓練済みモデルとRIPUによるアノテーションAPIの実装
今回実装したアノテーションAPIでは、アップロードされた画像に対するアノテーション結果を以下のような構造のJSONでレスポンスします。
{
"annotation_items": [
{
"label": { // ラベルに関する情報
"class_id": 13,
"name": "car",
"color": [0,0,142] // (r,g,b)
},
"coordinates": [[324,15],[325,15]...] // 事前アノテーションの座標情報(x,y)
},
... // 各ラベルごとのアノテーション結果(座標情報)
]
}
それでは実際に、訓練済みモデルとRIPUを活用した事前アノテーションの実装を見てみましょう。
from typing import Dict, List, Tuple
import torch
from cruds.const.dataset.cityscapes import TRAIN_ID_TO_COLOR, TRAIN_ID_TO_NAME
from cruds.const.image_net import IMAGE_NET_PIXEL_MEAN, IMAGE_NET_PIXEL_STD
from PIL import Image
from schemas.Annotation import Annotation
from torchvision.transforms import functional as F
from .ripu.PixelBasedRIPU import PixelBasedRIPU
def pseudo_annotation_by_pixel_based_ripu(
image: Image, # 元画像
net: torch.nn.Module, # 訓練済みのセマンティックセグメンテーションモデル
class_num: int,
region_size: int = 3,
) -> Annotation:
image_tensor = F.to_tensor(image).unsqueeze(0) # (1,3,h,w)
"""
1. 訓練済みのモデルを用いた推論
"""
net.eval()
input_tensor = F.normalize(
image_tensor, mean=IMAGE_NET_PIXEL_MEAN, std=IMAGE_NET_PIXEL_STD
)
with torch.no_grad():
pred = net(input_tensor) # (1,class_num,h,w)
pred = pred.squeeze(0) # (class_num,h,w)
pred = torch.softmax(pred, dim=0)
"""
2. 推論結果からRIPUの計算を実行する
"""
pixel_based_ripu = PixelBasedRIPU(class_num=class_num, region_size=region_size)
pixel_based_ripu_score = pixel_based_ripu.score(pred)
"""
3. RIPUの計算結果と推論結果に基づき、事前アノテーション
"""
image_tensor = image_tensor.squeeze(0)
image_tensor = image_tensor.permute(1, 2, 0)
h, w, _ = image_tensor.shape
ripu_threshold = float(torch.mean(pixel_based_ripu_score)) # RIPUの閾値. 今回は平均値を採用.
pseudo_annotation_map = pixel_based_ripu_score < ripu_threshold # 閾値を超えない領域のみアノテーション
.
pred_label = pred.cpu().argmax(0)
class_id_to_coordinates: Dict[int, List[Tuple[int, int]]] = {}
for y in range(h):
for x in range(w):
if pseudo_annotation_map[y][x]:
class_id = int(pred_label[y][x])
if class_id in class_id_to_coordinates:
class_id_to_coordinates[class_id].append((x, y))
else:
class_id_to_coordinates[class_id] = [(x, y)]
annotation: Dict[str, List] = {"annotation_items": []}
for id, coordinates in class_id_to_coordinates.items():
annotation["annotation_items"].append(
{
"label": {
"name": TRAIN_ID_TO_NAME[id],
"class_id": id,
"color": TRAIN_ID_TO_COLOR[id],
},
"coordinates": coordinates,
}
)
return Annotation(**annotation)
上の実装が参照しているRIPUの計算を担うPixelBasedRIPUクラスの実装は以下の通りです。
import torch
import torch.nn.functional as F
from torch import nn
class PixelBasedRIPU:
"""PixelBasedRIPU
Calculate PixelBasedRIPU score for all pixels from prediction.
ref:
github: https://github.com/BIT-DA/RIPU
arxiv: https://arxiv.org/abs/2111.12940
"""
def __init__(self, class_num: int, region_size: int) -> None:
self.__class_num = class_num
self.__region_impurity_conv = nn.Conv2d(
in_channels=class_num,
out_channels=class_num,
kernel_size=region_size,
stride=1,
padding=region_size // 2,
bias=False,
padding_mode="zeros",
groups=class_num,
)
conv_weight = torch.ones(
(class_num, 1, region_size, region_size), dtype=torch.float32
)
self.__region_impurity_conv.weight = nn.Parameter(conv_weight)
self.__region_impurity_conv.requires_grad_(False)
def score(self, pred: torch.Tensor) -> torch.Tensor:
return self.prediction_uncertainly(pred) * self.region_impurity(pred)
def prediction_uncertainly(
self, pred: torch.Tensor, eps: float = 1e-6
) -> torch.Tensor:
assert len(pred.shape) == 3 # pred.shape : [ class_num , h , w ]
prediction_uncertainly = torch.sum(
torch.special.xlogy(-pred, pred), dim=0
) # [ h , w ]
return prediction_uncertainly
def region_impurity(self, pred: torch.Tensor, eps: float = 1e-6) -> torch.Tensor:
assert len(pred.shape) == 3 # pred.shape : [ class_num , h , w ]
pseudo_label = torch.argmax(pred, dim=0) # [ h , w ]
one_hot = F.one_hot(
pseudo_label, num_classes=self.__class_num
).float() # [ h , w , class_num]
one_hot = one_hot.permute((2, 0, 1)).unsqueeze(dim=0) # [ class_num, h , w ]
output = self.__region_impurity_conv(one_hot) # 1(batch_size), class_num , h, w
count = torch.sum(output, dim=1, keepdim=True) # 1(batch_size), 1 , h, w
dist = output / count # 1(batch_size), class_num , h, w
region_impurity = torch.sum(
torch.special.xlogy(-dist, dist), dim=1, keepdim=True
) # 1(batch_size), 1 , h, w
return region_impurity.squeeze(0).squeeze(0)
以上がバックエンドの実装の説明になります。
6.2 Reactによるフロントエンドの実装
6.2.1 技術選定
VeloxLabelのフロントエンドはReact,TypescriptによるSPAで構築されています。VeloxLabelは
- OGPやSEOなどの必要性が低い(不要)
- ホスティングの選定を容易にすべく、静的なHTML/CSS/JSのみでフロントエンドを構築したい
- 現時点ではルーティング等も不要(必要になったタイミングでreact-routerやreact-locationを追加する、で十分)
などの背景から、Next.jsは少しオーバースペックであると考え、ピュアなSPAを採用しました。なお、ビルドツールとしては、Viteを採用しています。
そして、そのほかの周辺ツールについてですが、以下を採用しています。
- CSS in JS: emotion
- UI Library: Ant Design
- グローバルな状態管理: Recoil
6.2.2 事前アノテーションの実装
ここではバックエンドから取得したアノテーション結果をフロントエンドに表示する部分の実装を紹介します。
以下は事前アノテーション結果を格納するrecoilのatomとそれに関連した処理の実装になります。
import { Annotation } from '../../../entities'
import { atom, useSetRecoilState } from 'recoil'
import api from '../../api/annotation'
import { useCallback } from 'react'
import { RecoilAtomKeys } from '../recoilKeys'
export const pseudoAnntationState = atom<Annotation>({
key: RecoilAtomKeys.PSEUDO_ANNOTATION_STATE,
default: { annotationItems: [] },
})
export const pseudoAnntationActions = {
useFetchPseudoAnntation: () => {
const setPseudoAnnotationState =
useSetRecoilState<Annotation>(pseudoAnntationState)
return useCallback(
async (imageData: FormData) => {
// 事前アノテーションをバックエンドから取得
const responseAnnotation = await api.pseudoAnnotation(imageData)
// 事前アノテーション結果をグローバルステートにsetする。
setPseudoAnnotationState(new Annotation(responseAnnotation))
},
[setPseudoAnnotationState]
)
},
}
コンポーネントから、pseudoAnntationActions.useFetchPseudoAnntation() を呼び出すことによって、「アップロードした画像に対する事前アノテーション⇨アノテーション結果をatomに格納」という一連の処理が実行可能な関数(fetchPseudoAnnotation)を取得することが可能です。(useFetchPseudoAnntation()を呼び出すことで、処理が実行されるわけではない点に注意)
今回、recoilには初めて触れましたが、この辺りの設計はこちらの記事が大変参考になりました。
このようにしてバックエンドから取得したアノテーションデータを、アノテーション作業を行うCanvasに以下のような実装で描画することで、事前アノテーションを実現しました。
import React, { useEffect , useRef } from 'react'
import { useRecoilValue } from 'recoil'
...
export const AnnotationCanvas = () => {
...
const pseudoAnnotation = useRecoilValue(pseudoAnntationState)
const canvasRef = useRef<HTMLCanvasElement>(null)
const ctxRef = useRef<CanvasRenderingContext2D | null>(null)
...
useEffect(() => {
const canvas = canvasRef.current!
const ctx = canvas.getContext('2d')!
const imageData = ctx.createImageData(
IMAGE_SIZE.width,
IMAGE_SIZE.height
)
for (const annotationItem of pseudoAnnotation.annotationItems) {
const [r, g, b] = annotationItem.label.color
for (const coordinate of annotationItem.coordinates) {
const [x, y] = coordinate
const idx = (y * IMAGE_SIZE.width + x - 1) * 4
imageData.data[idx + 0] = r
imageData.data[idx + 1] = g
imageData.data[idx + 2] = b
imageData.data[idx + 3] = ALPHA
}
}
ctx.putImageData(imageData, 0, 0)
ctxRef.current = ctx
}, [pseudoAnnotation.annotationItems])
return (
...
<canvas
ref={canvasRef}
...
/>
...
)
以上がフロントエンドの実装の説明になります。
7.まとめ
長くなりましたが、以上が本インターンで取り組んだ内容になります。
当初、私はフロントエンドエンジニアとしての採用でした。しかし、「深層学習に関連したR&Dにも取り組んでみたい」という旨を面談でお話ししたところ、柔軟に聞き入れてくださり、結果として非常に充実した5週間を過ごすことができました。
画像認識やアクティブラーニングなど、初めて触る領域も多くありましたが、社内のEngineer・Researcherの方々が丁寧に質問に答えてくださったおかげで、スムーズにキャッチアップできました。
被験者実験や未実装な機能など心残りもありますが、今回のインターンを通して得た経験は今後の人生において、非常に有意義であったと思います。
PFNの皆さん、本当にありがとうございました!!
参考文献
[1] M.Cordts, M.Omran, S.Ramos, T.Rehfeld, M.Enzweiler, R.Benenson, U.Franke, S.Roth, and B.Schiele. The cityscapes dataset for semantic urban scene understanding. In CVPR, 3213–3223, 2016.(https://arxiv.org/abs/1604.01685)
[2] Xie, Binhui and Yuan, Longhui and Li, Shuang and Liu, Chi Harold and Cheng, Xinjing. Towards Fewer Annotations: Active Learning via Region Impurity and Prediction Uncertainty for Domain Adaptive Semantic Segmentation. In CVPR, 8068-8078, 2022.(https://arxiv.org/abs/2111.12940)
[3] S.Richter, V.Vineet, S.Roth, and V.Koltun. Playing for data: Ground truth from computer games. In ECCV, 102–118, 2016.(https://arxiv.org/pdf/1608.02192.pdf)
[4] L.Chen, G.Papandreou, I.Kokkinos, K.Murphy, and A.Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell., 834–848, 2018.(https://arxiv.org/abs/1606.00915)
[5] L.Chen, Y.Zhu, G.Papandreou, F.Schroff, and H.Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In ECCV, 833–851, 2018.(https://arxiv.org/pdf/1802.02611.pdf)
[6] L.Chen, G.Papandreou, F.Schroff, and H.Adam. 2017. Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587, 2017. (https://arxiv.org/abs/1706.05587)
