Blog
PFN では HDFS から Apache Ozone への移行を進めています。Ozone クラスタは順調に社内のプロジェクトで採用が進んでデータが増加しており、これまでの 2 年間は数度にわたってクラスタを拡張しました。ところが、段階的にクラスタを拡張したことでデータノード間でのディスク使用量の不均衡が問題になってきました。例えば、全てのディスクが 8 割埋まっている Ozone クラスタにまったく空のデータノードを追加すると、データ使用量に大きな不均衡が生じます。新規追加した空のサーバにデータを移動することをリバランスといいますが、運用しやすいようにリバランスを実装する方法は自明ではありません。HDFS ではノード単位でディスク使用量を規定の範囲内に均すように移動する Balancer やデータノード内のディスクを同様に移動する Disk Balancer があります。一方で Ozone 1.2 ではまだ実装が始まったばかりの若い機能であり、最初はリバランスがうまく動作しないように見えました。そこで、今回は緊急メンテナンスとして手動でリバランスをすることにしましたので、その全容を紹介します。
※ これまでの Ozone クラスタ構築に関する取り組みは 2021 年のブログ記事「Apache Ozoneをやっていた一年」も併せてご一読ください。
PFN の計算基盤におけるストレージシステムの役割は、研究開発活動で必要なデータを永続化して必要なタイミングで高速に読み出せる場所を提供することです。「必要なデータ」にはデータセットやプログラムの実行結果、ジョブの中間ファイルなど様々なものがあります。特に最近社内では CG やシミュレーションを駆使して計算によってデータを生成して学習を行うユースケース [1][2][3][4] が増えており、何もないところからデータが増加し続けています。我々はディスクの利用実績に基づいて需要を予測しサーバの調達・構築を進めてきましたが、特にここ最近は予測が難しく、予想を上回るペースでディスクが埋まっていく現状がありました。
実際にサーバやディスク機材を買うとしても、発注してから実際に動作するには時間がかかります。空き容量が少なくなった段階での調達ではデータ増加のペースに追いつけなくなっていました。サーバー機材を買って追加するのと並行して、HDFS クラスタの縮小を進めて少しずつサーバを切り出して Ozone クラスタに転用する作業を繰り返し行いました。
HDFS も Ozone もありがたいことにデータノードの追加や除去を簡単にやってくれます。しかしながら、先述の通りハードウェアの準備や調達の都合・空き容量推移の予測が難しいといった要因から、小さい単位でのノード追加を幾度となく実施することになりました。図 1 に示すのは、過去一年の Ozone クラスタの物理容量 (橙) と実際のディスク使用量 (青) をプロットしたグラフです。データノード追加を何度も繰り返している一方でディスクはそれよりも速いペースで埋まっていく様子を示していると思います。我々はシステム全体の使用量が 80% 以下になることを目指してシステム拡張を計画していますが、特にここ数ヶ月は余裕がない状況を迎えていました。
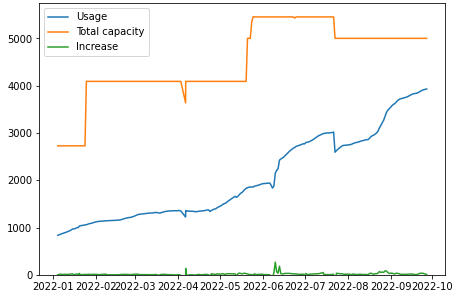
図 1: Ozone クラスタの物理容量と実際のデータ使用量 (単位: TB)
ノード間のディスク使用量偏りの発生
クラスタ全体の空き容量に余裕がない一方で、さらにデータノード毎のディスク使用量の偏りが問題となっていました。図 2 に示すのは Ozone の各データノードにおけるディスク使用量 (物理) です。ディスク使用量が多いノードは古くからあるデータノード、反対にディスク使用量が少ないノードは新しく追加したノードです。ディスク使用量の偏りは I/O 負荷の分散の観点でなるべく均一にすることが望ましいです。また、ディスク使用量が多いデータノードにおいてはディスクフルの懸念があります。
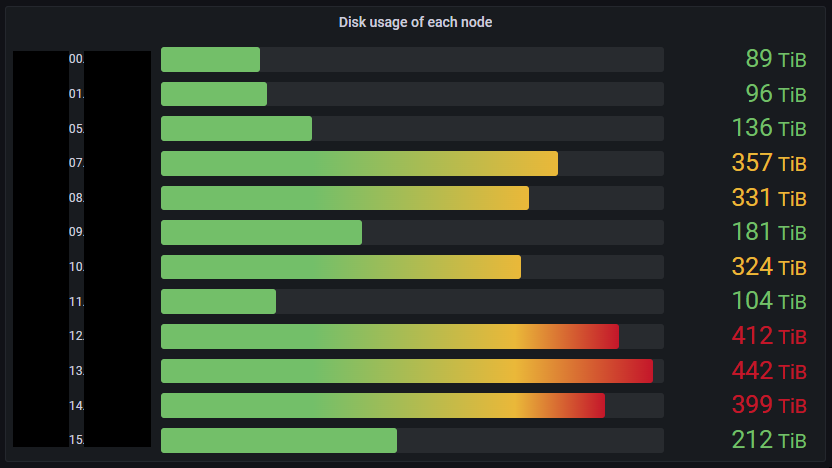
図 2: Ozone クラスタの各データノードのディスク使用量が偏った状態
この時点でのデータノードの構成を表 1 に示します:
| ソフトウェア | Apache Ozone 1.2.0 ベースのカスタム版 |
| CPU | Intel(R) Xeon(R) Silver 4114 x1 20c |
| RAM | 32GB DDR4 x16 |
| HDD | 14TB SATA 6GB/s 7200rpm x36 |
| ネットワーク | Mellanox ConnectX-6 (100GbE) x2 |
Apache Ozone や Hadoop はノードを追加しても自動でディスク使用量を平準化するような機能はありません。HDFS であれば Balancer があり、これは起動するとデータノード間でデータを移動して平準化してくれます。Ozone では Container Balancer と呼ばれるコンポーネントがあり、HDFS と同様にデータノード間でデータを再バランスする機能が存在しますが、残念ながら Ozone 1.2 ではサポートされていないため今回は利用できませんでした。
その間、データノード間のディスク使用量は偏ったままディスク使用量が多いノードも少ないノードも同じペースでディスクが埋まっていきました。一部のデータノードではディスク使用率が 90% を超え、100% が近くなっていました。ディスクフルとなってしまった場合のデータノードの挙動について、この時点で我々には知見がありませんでした。運用上の影響が予測できないディスクフルを避けるため、ディスクフルが近づいたデータノードを緊急退避する目的でデコミッションを試すことにしました。
デコミッションはデータノードを安全にクラスタから取り除く操作で、当該データノード上の全データを別のデータノードにコピーしたのちにクラスタから削除します。クラスタ全体の空き容量に余裕がある場合、ディスク使用率が高いノードをデコミッションすればディスクフルを未然に防ぐだけでなく、他のノードのディスク使用量が均一になるようデータが書き込まれることも期待できます。データノードのディスク容量は一本あたり 14 TBでワイヤレートは十分高速であるため、HDD であることを考慮しても数日あればコピーが完了できる想定でデコミッションを開始しました。ところが当初予想した期間では終わらず、ノードの状態が DECOMISSIONING のまま二ヶ月が経過してしまいました。デコミッションの進捗状況を確認できる CLI は現時点で未実装なので SCM の Replication Manager のログを直接読む必要がありますが、ログを見るとコピーがあるタイミングでスタックしていることがわかりました。ノード削除とそれによるデータ再配置でのリバランスを我々は断念しました。
一部ノードでのディスクフルの発生
バランサーやデコミッションではうまく解決には至らないまま時間が経ってしまい、とうとう一部のノードでディスクフルが発生してしまいました。使用率が 100 %に達したディスクでは図 3 のようにコンテナがオープンできなくなりました。Ozone におけるコンテナ [5] とは、ブロックを 5 GB まで [6] のひとまとまりにした管理単位です。Ozone は HDFS のように直接ブロックを管理するのではなく、コンテナ毎にデータノードの配置や複製数を管理する構造になっています。
Ozone はコンテナを開く際にメタデータを記録している RocksDB を常に書き込みモードでオープンするため、ディスクフルでは RocksDB のオープンに必要なログ [7] の書き込みが失敗してしまうようです。これによってディスクフルノードにあるコンテナは読み取り不能になります。
2022-09-07 15:36:24,555 [grpc-default-executor-8298] ERROR org.apache.hadoop.ozone.container.common.utils.ContainerCache: Error opening DB. Container:150916 ContainerPath:/data/21/ozone/hdds/CID-xxx/current/containerDir38/150916/metadata/150916-dn-container.db
java.io.IOException: Failed init RocksDB, db path : /data/21/ozone/hdds/CID-xxx/current/containerDir38/150916/metadata/150916-dn-container.db, exception :org.rocksdb.RocksDBException While appending to file: /data/21/ozone/hdds/CID-xxx/current/containerDir38/150916/metadata/150916-dn-container.db/MANIFEST-001861: No space left on device; status : IOError(NoSpace); message : While appending to file: /data/21/ozone/hdds/CID-xxx/current/containerDir38/150916/metadata/150916-dn-container.db/MANIFEST-001861: No space left on device
図 3: RocksDB のオープンに失敗する様子
Ozone は一部でディスクフルが発生しても、そこにあるデータの複製が読めなくなるという影響があるだけで他のノードにある複製を読むことはできるので、書き込みには影響がありません。 ディスクフルが発生している間も PFN では日々大量のデータが生成され、Ozone に書き込まれていました。数日後にはさらに数台ほどディスクフルのノードが発生しました。ディスクフルによって同じデータに対する複製が規定数を満たせなくなると、そのデータは読み出せなくなります。このタイミングで実際に社内の利用者から Ozone の一部データにアクセスできなくなった旨の報告を受けるようになりました。
9 月 12 日時点で、ディスクフルのデータノードは 12 台中の 5 台になり、Ozone クラスタの半数近くがディスクフルになっていました。Ozone 1.3.0 のリリースまで待つことができれば Container Balancer による解決が期待されますが、社内の研究開発フローへの影響を解決するためにも解決を急ぐ必要がありました。
手動リバランスの試み
一般に、ファイルシステムやデータベースなどのステートフルなアプリケーションにおいて手動操作は禁忌とされます。その理由は整合性はシステムが自動で管理するべきものであり、手動操作はシステムが保証した整合性を単純なヒューマンエラーによって復旧不能な形で破壊する可能性が高いからです。基本的に管理上必要な操作は全て付属のツール群として提供されます。様々なトラブルを未然に防ぐために手順や作業品質を統一するための枠組みです。
しかしながら、今回のディスクフルは現時点の Ozone の標準機能では解決できない問題であったこと、標準機能による解決を模索するよりも手動操作でリバランスする方がディスクフルを解決できる見込みがあったことから、手動でリバランスを行う方向性で Ozone クラスタの復旧を試みることにしました。というのも、我々は Ozone のデータ構造をよく知っていたので手動オペレーションができる見込みがありました。こういったときのために定期的に集まって Ozone のソースコードを読む会を開催していた時期があったこと、また、疑わしい動作や分からないことがあったら動作しているバージョンのソースコードを確認することを習慣付けていたことが今回役に立ちました。手動リバランスで実際にどのデータを移したのか、簡単に解説します。
Ozone 1.2 時点でのデータノード内部のデータ構造は、図 4 に示す Container Layout V2 に従います。Container Layout V2 はブロックのメタデータが格納された RocksDB とブロックファイルを各コンテナごとのディレクトリに格納するフォーマットです。それぞれのディレクトリはコンテナディレクトリと呼ばれます。コンテナディレクトリはメタデータ (RocksDB, YAML) とブロック (Blob) からなります。
Ozone のデータノードは hddsVolume を持ち、各ボリュームには SCM の管理対象であるコンテナがコンテナ ID ごとにコンテナディレクトリとして配置されます。コンテナ ID は連番で SCM が採番します。PFN では JBOD 構成をとっており、ひとつの HDD にひとつの hddsVolume が対応します。原理的にはコンテナは単なるディレクトリなので、このディレクトリ構造を壊さずに他のノードに運搬してしまえばレプリケーションや自動リバランスと同じことができるはずです。

図 4: Container Layout V2 による HddsVolume の表現
しかし、まだひとつ疑問があります。コンテナの配置を自由に変更できたとして整合性は問題ないのでしょうか?データノードは起動時にローカルディスクにあるデータをスキャンし、読み出せたコンテナの配置情報を ContainerReport として SCM に報告します。HDFS でいう BlockReport に相当します。我々は Ozone を全停止した状態であればコンテナの位置を移動しても問題ないと推測しました。そして実際に一部のデータノードを停止して小規模な実験を行った結果、成功することを確認できたので上記の内部構成を利用してディスク使用量の手動リバランスを行うことにしました。同じタイミングで HDFS からデータノードを 7 台切り出すことができそうだったので、同時にノードを追加して Ozone クラスタを拡張することにしました。方針としては:
- 同一構成 (ディスク枚数、ディスク容量) の新しいデータノードを用意する
- ディスク使用率の高いデータノード (旧) からデータノード (新) にコンテナを半分だけコピーする
- データノード (旧) のコピー先となるデータノード (新) は排他的で一意に定まるようにペアを作る (コピー先に同一コンテナが複数存在することを防ぐため)
- コピー元とコピー先ではディレクトリ構成を揃える
- コピーが終われば古いノードからコンテナを削除する
- 安全のためにメンテナンスは Ozone クラスタを全停止して行う
- クラスタの半数以上のデータノードが機能不全になった状態を復旧するので妥当な選択肢
- メンテナンス期間中はクラスタに全くアクセスできなくなること、重要度の高いメンテナンスであることは利用者に十分に説明する
今回はクラスタを全停止したオフラインメンテナンスとするので、スケジュールと作業項目を細かく準備することにしました。
オフラインメンテナンス計画と実施
スケジュールの策定
作業時間に関しては、データコピーを十分に並列化すればデータノードの物理ディスクの半分 14 TB / 2 = 7 TB の転送時間と考えられること、クラスタは 100GbE のネットワークに接続されていることを踏まえると、コピー作業は HDD のスループットでも一日あれば十分に完了できるものと考えました。そのうえで予備日を設定し、最長二日間停止する計画としました。十分な準備期間を確保するために、利用者へのアナウンスから実施日までは二週間以上空けることにしました。
重要なデータの先行サルベージ
メンテナンス実施までは期間があるため、急ぎで読めなくなっているデータを必要とするユーザーに別途対処する必要があります。メンテナンスが完了するまでは実際に要望に応じてサルベージも行いました。正常系では OM からメタデータ情報を、SCM からブロックの位置情報を入手することでデータノードを特定し、データノード上にあるコンテナからブロックを収集して元のファイルを構成します。ディスクフルの状況下ではデータノードにデータが存在しているにもかかわらずコンテナをオープンできないため、正常系で読み取ることができません。サルベージでは Ozone のメタデータ読み取りとブロックのダウンロード、再構成といった一連の操作を Ozone を介さずに外部から行えるようにしました。この作業は手動で行うにはかなり煩雑な手順になるため、自動化を進めました。
データ転送手順の準備と検証
メンテナンス当日に予定した作業は以下です:
- Ozone の全プロセスを停止する
- 新しいデータノードを追加する
- データノード (旧) から データノード (新) にデータを半分だけ転送する
- データノード (旧) からコピーが完了したコンテナを削除する
- Ozone を起動する
コピーはコンテナごとに実施しますが、内容は単なるディレクトリのサーバ間コピーなので rsync を使用することにしました。今回はコンテナを半分だけ転送したいので偶数番号のコンテナだけ転送します。コピー対象リストを引数で受けることができるのも rsync を選定したポイントのひとつです。図 5 は rsync を用いたコンテナの転送例です。実際にはデータノードには HDD が 36 台ありますので、これをディスク本数分・サーバ台数分繰り返すことになりますが、十分に並列化できるので転送時間はディスク一台分で済みます。

図 5: Container Layout V2 におけるコピー対象ディレクトリの選択と rsync による転送例
今回のメンテナンスは Ozone のサービス停止を伴う作業なので、データ転送が時間内に終了するかどうかを事前に検証しておくことにしました。検証の結果、事前実験で行ったフルコピーでは 7 TB の転送に最長で 5 日かかることが分かりました。これはディレクトリのエントリ数が多く、スループットが出にくいディレクトリ構造であったことが原因のようです。そこで予備作業と当日作業の二種類に分け、当日作業では差分コピーを使う方法にしました。フルコピーは予備作業としてメンテナンス日までに実施しておきます。最終的に行う手順は以下のようになりました:
- 予備作業: 転送対象のコンテナリストを作っておく
- 予備作業: データノード (旧) からデータノード (新) にフルコピーを作っておく
- 当日作業: Ozone の全プロセスを停止する
- 当日作業: データノード (旧) から データノード (新) に差分コピーを実施する
- 当日作業: データノード (旧) からコピーが完了したコンテナを削除する
- 当日作業: データノード (新) からフルコピー後に削除されたコンテナを削除する
- 当日作業: Ozone を起動する
メンテナンスのアナウンスから二週間、ディスクフルになったノードがさらに 3 台増えてしまいました。当時の様子を図 6 に示します。追加可能なノードは 7 台なので、コピー対象を工夫することで 2 台分を 1 台にコピーするように急遽計画を変更し、後からディスクフルになったノードに関してもフルコピーを開始しました。
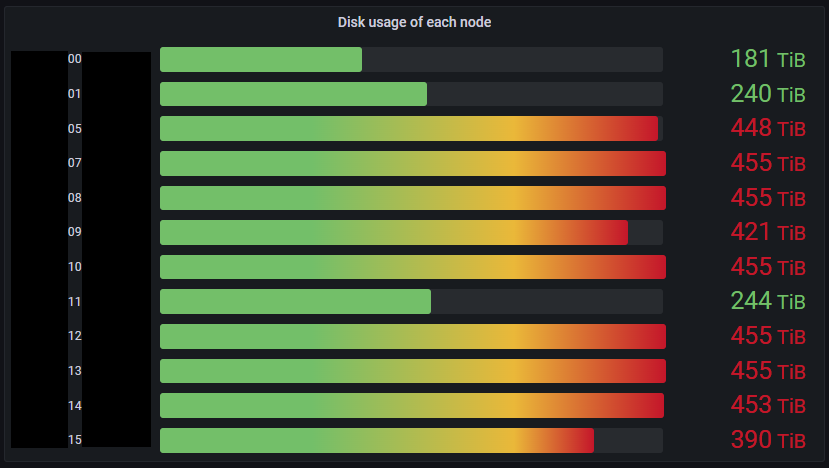
図 6: メンテナンス日直前の Ozone クラスタの各データノードのディスク使用量
メンテナンス当日
新しくディスクフルになったノードが発生したものの予備作業の事前コピーは無事に完了していたので、当日はクラスタの停止と差分コピーを実施しました。rsync の差分コピーにはタイムスタンプを参照する方法とチェックサムを考慮する方法がありますが、今回は時間短縮のためにタイムスタンプを比較する方法をとりました。チェックサムを使う方法では全てのファイルのチェックサムを計算することになり、今回のケースでは転送スループットが出にくくなるのが理由です。
メンテナンスはスケジュール通りに完了できました。今回のメンテナンスでは手動リバランスによってディスクフルのノードを 8 台から 0 台に、データノード追加によってクラスタ全体のディスク使用率を 85% から 69% まで改善できました。メンテナンス完了後のディスク使用量レポートを図 7 に示します。第五カラムの Storage Capacity は各データノードのディスク使用率が表示されます。Ozone が使用している領域は緑になるのですが、この緑のバーがデータノード間でおおよそ均一に、ディスクフルのノードは 0 台になっていることがわかります。
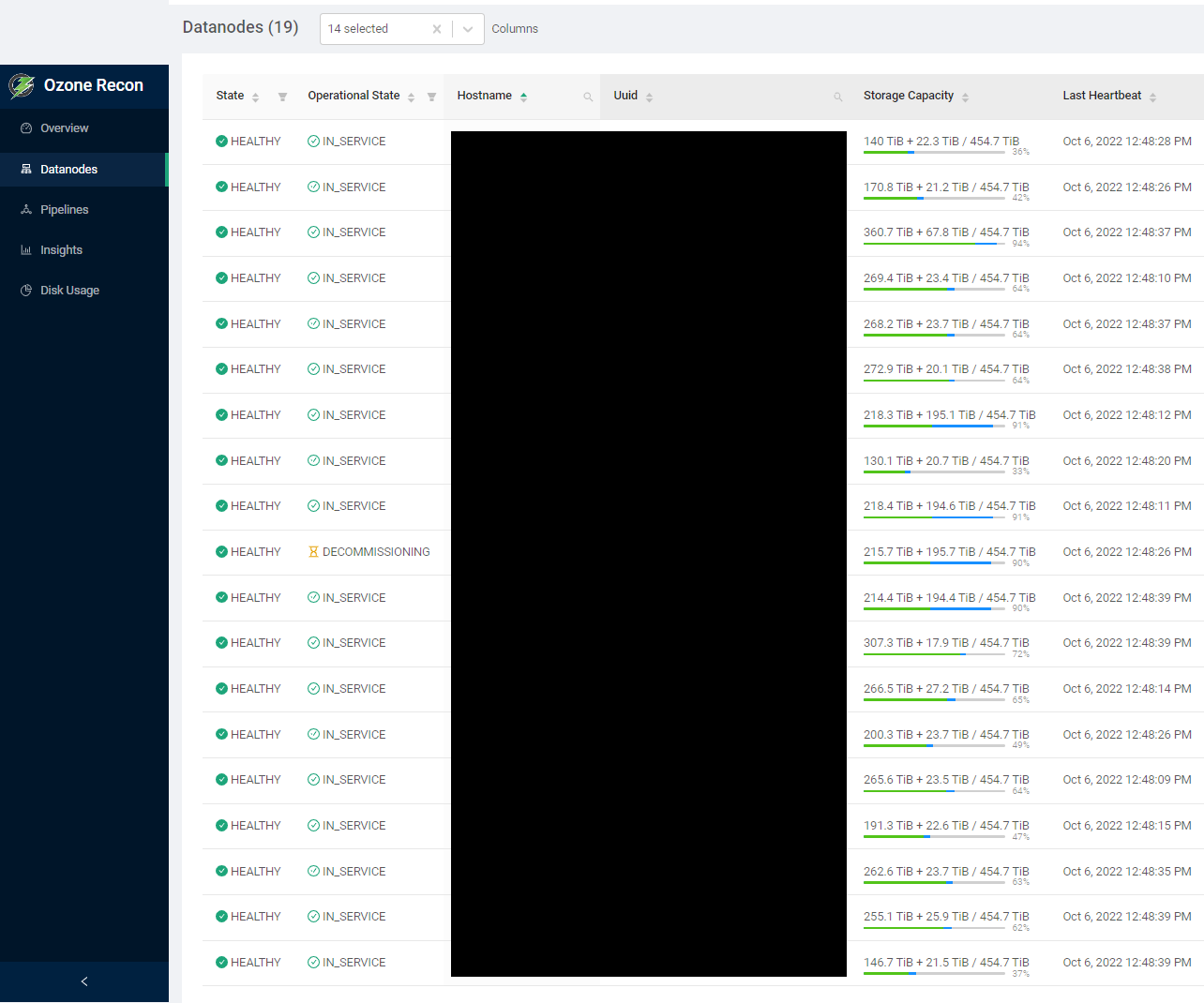
図 7: 手動リバランスメンテナンス終了後のディスク使用量レポート
手動リバランスとその後
今回のメンテナンスは 9 月 28 日に実施しました。それからひと月経ちましたが、ディスクリバランス作業が原因と思われる問題は発生していません。一方で、いくつかクラスタ構成に問題があったので修正しています。
レプリケーションの一部が停止していた
データノードの証明書が有効期限切れになっていたことが後で判明しました。この証明書はデータノード同士が特定のレプリケーション操作で通信する際に使用するもので、それぞれのデータノードの初回起動時に自動でインストールされます。Ozone RPC では Kerberos で認証しますが、一部のレプリケーション操作ではそれとは別に SCM が発行した自己署名証明書を使った認証を用いる実装になっています。証明書の有効期限は 1 年間ですが、Ozone 1.2 では自動更新機能は未実装です。したがって、長らく運用している一部のデータノードではすでに有効期限が切れてしまっていました。
今回は証明書を手動で更新する必要がありましたが、証明書を更新するとレプリケーションが正常に稼働するようになりました。証明書更新後もデコミッションは未だ進行中ですが、当初存在したデコミッションがスタックした原因は証明書の期限切れであった可能性も考えられます。
ContainerPlacementPolicy の変更
引き続きデータ書き込みに関してディスク増加量の不均衡が続いています。これは ContainerPlacementPolicy と PipelineChoosingPolicy、LeaderChoosePolicy のそれぞれのパラメータの調整による改善を図っていきます。特にコンテナの配置方法を決定する ContainerPlacementPolicy ではディスクの空き容量を考慮する Capacity-aware なポリシを採用するように変更しました。このポリシは Ozone 1.2.0 現在のコードベースでは不具合がある (HDDS-5804 で修正済) ので社内用にはバックポートして使用することにしました。
今後の展望
Ozone はまだまだ発展途上のソフトウェアですが、コミュニティは非常に活発です。今回 PFN で遭遇した問題は Ozone 1.2 のリリース版に含まれる内容ですが、コミュニティでは次期バージョンやそれ以降に向けて既にパッチが提案されているので紹介します。PFN では Ozone 1.2 系と 1.3.0 リリースを見据えた master HEAD 系のクラスタを稼働させており、必要に応じて最新のパッチをバックポートしながら運用していきます。
証明書の自動更新 (HDDS-7453)
今回は証明書を手動で更新しましたが、コミュニティでは証明書更新を自動化する提案が出されています。今後は運用省力化が期待できそうです。
デコミッションの可観測性向上 (HDDS-2642)
デコミッションの進捗状況をメトリクスとして出力する提案が出されています。現在はデータノードの State と SCM のログが唯一の状況確認手段ですが、この変更によってデコミッションにおける可観測性の向上を期待できます。
予約領域の設定 (HDDS-6577 & HDDS-6901)
HddsVolume に予約領域を確保できるようになります。これによって Ozone が利用可能な領域を事前に制限できるようになり、ディスクフルによるメタデータ操作失敗の確率軽減が期待できます。
コンテナバランサーの実装 (HDDS-4656)
コンテナバランサーが実装されます。これによって今回のような手動リバランス作業が不要になることが期待されます。運用上重要になる機能であるため、PFN では引き続きクラスタでの検証を進めていきます。
まとめ
PFN の Ozone クラスタでは段階的なクラスタの拡張を行った背景からディスク使用率が不均衡になり、一部のノードでディスクフルが発生しました。それに伴って一部のデータの読み出しができなくなってしまいました。今回の記事ではその解決法として手動でリバランスを実施した経緯を紹介し、Ozone のデータ構造を踏まえつつその手順を簡単に紹介しました。メンテナンスはディスクフルとなったノード数がクラスタの半数を占めたことから Ozone クラスタを停止するオフラインでのメンテナンスとし、社内の利用者への影響を最小限にするように丁寧に計画を立案しました。
今回のメンテナンスではまず Ozone クラスタに 7 台のデータノードを追加したうえで、ディスクフルになった 8 台のノードからコンテナを半分選んで新しいデータノードに手動で移動しました。メンテナンスでは Ozone の実装やデータ構造を深く知っておく必要がありましたが、大きなトラブルもなく無事に完了でき、一ヶ月以上リバランスに由来した問題は発生は無く正常に稼働し続けています。
We are hiring!
PFN ではオブジェクトストレージを中心に複数のストレージシステム (Apache Ozone、HDFS、NFS) の運用などを自社で行っています。単にシステムを運用するだけでなく、サーバーの調達やキャパシティプランニングなどの設計、Kubernetes との繋ぎ込み、ユーザサポートも行っています。もしご興味がある方、我こそは!という方がいらっしゃいましたら、Careers ページの Job Openings からご応募いただくか、お近くの PFN 社員にお声がけください。
また、11 月 15 日 (火) 19 時~より、PFN Open House #4 として機械学習プラットフォーム領域をメインとした採用イベントを Zoom ウェビナーにて開催します。Kubernetes や Ozone など、機械学習プラットフォームの基盤となるソフトウェアの運用をメインとする領域にフォーカスし、業務内容や仕事のやりがいをご紹介する内容になる予定です。PFN での計算基盤運用にご興味がある方はぜひ connpass ページよりお気軽にご参加ください。
参考文献
- [1] 材料探索のためのユニバーサルなニューラルネットワークポテンシャル, PFN Tech Blog, 2022
- [2] 深層学習を用いた物理探査技術の研究開発, PFN Tech Blog, 2021
- [3] 機械学習を用いた地震波解析, PFN Tech Blog, 2022
- [4] 数値シミュレーションデータの低次元潜在空間における時間発展ダイナミクスの学習, 2022
- [5] Containers, Documentations for Apache Ozone, 2021
- [6] Storage Container Manager, Documentations for Apache Ozone, 2021
- [7] MANIFEST, RocksDB Wiki, 2022
Acknowledgement: この文章の執筆を大いに助けてくださった上西氏、水丸氏、土井氏に感謝します。
Area
Tag