Blog
本記事は、2025年度PFN夏期インターンシップで勤務された亀田圭さんによる寄稿です。
PFN 2025 夏季インターンシップに参加した大阪大学 工学研究科 修士1年 の 亀田 圭 と申します。今回のインターンでは、「PreferredAI プロダクトの新機能開発」というテーマで開発に取り組みました。なお、ここで掲載するシステムの動作例すべてにおいて、書かれている内容は架空の企業を対象にした情報であり、PFN及びその他の企業とは一切関係ありません。

概要
本プロジェクトの概要は以下のとおりです。
- Embedding に依存しない RAG 手法 にフォーカスし、既存の検索 API と LLM を組み合わせることで、運用コストを抑えながら更新頻度の多い会話ドメインにフィットする仕組みを実装
- LLMのクエリ生成→検索実行→スレッド/前後文脈の追加取得→充足度チェック(不足なら再探索)→統合生成というループ型フローを中核に据えて、会話ログに強い回答生成を実現
- Mock Q&Aで最新性・周辺文脈・チャンネル横断の有効性を確認し、回答には必ずソースリンクを付与してユーザーによる検証可能性を担保
背景
生成AIと外部データを組み合わせる RAG(Retrieval-Augmented Generation) は、より正確で信頼性の高い回答を実現できる技術として注目されています。2025年現在では Embedding を使ったベクトル検索を組み込む手法が主流ですが、再計算や専用基盤の維持に運用コストがかかる、最新データの反映に弱いといった課題も存在します。
特に社内チャットのようにハイコンテクストなやり取りが連続する場面では、時系列情報や周辺メッセージとの文脈的つながりが重要になります。しかし従来の RAG は意味的な近さを優先します。また、社内チャットは閲覧権限やセキュリティの兼ね合いで、ベクトル検索のために全データをダンプしストレージに保存することがそもそも難しいケースなども考えられます。
そこで本プロジェクトでは、Embedding に依存しない RAG 手法 に注目しました。既存の検索とLLMを組み合わせ活用することで、運用コストを抑えつつ、変化の速いビジネス環境や会話型シナリオに適した仕組みの構築に取り組みました。
アプリケーション紹介
今回開発したのは、Slack上の会話ログを対象にしたQ&Aシステムです。
会話ログにおいては「発言や話題の時系列」と「周囲の文脈」が非常に重要です。本システムは、これらの情報を適切に組み込んだ回答を生成させることを目標に開発しました。
システムアーキテクチャ
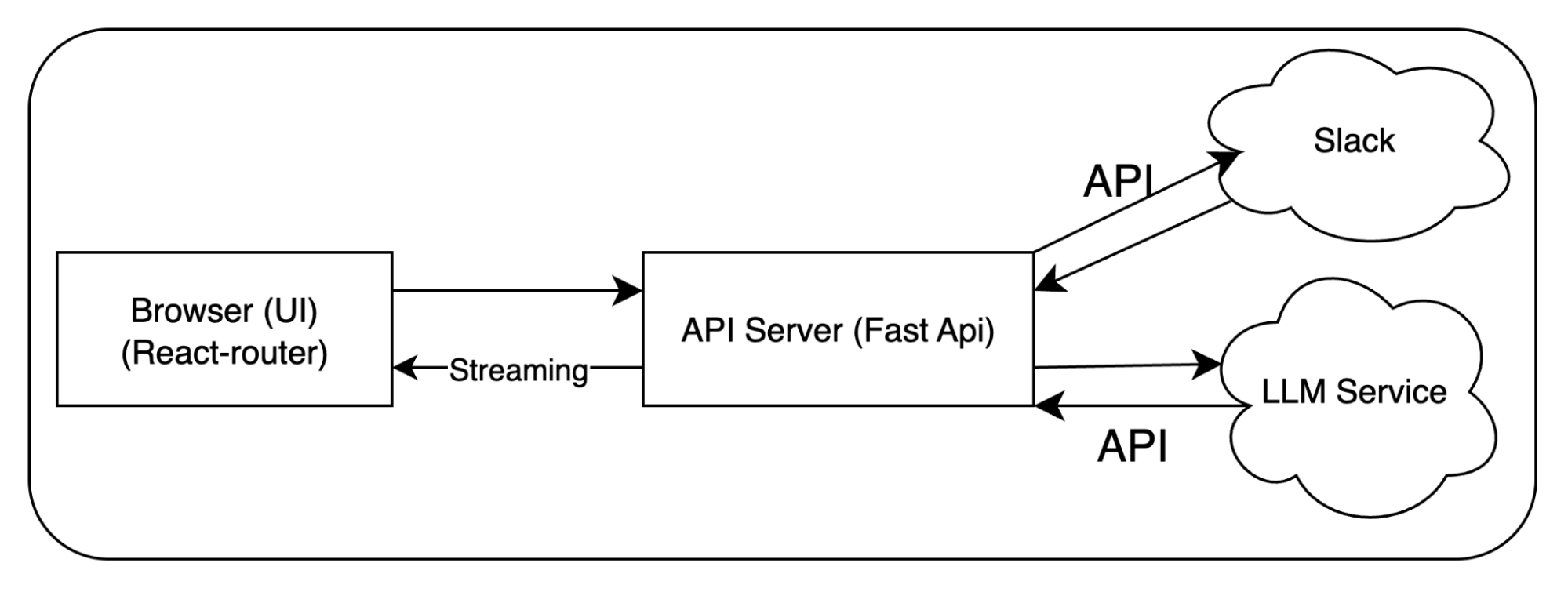
技術スタック
- バックエンド: FastAPI
- RAGパイプライン、ストリーミングレスポンス
- フロントエンド: React Router
- ストリーミング表示、推論過程の可視化
ストリーミングレスポンスの型の統合
回答はSSE(Server-Sent Events)によってストリーミングされます。
ストリームに含まれる主な情報は以下です:
- 回答生成フローにおける現在のステップ
- 生成された検索クエリ
- 検索結果
- 最終的な回答
ストリーミングレスポンスに Pydantic で厳格な型を定義し、FastAPI のOpenAPIスキーマ自動生成機能と連携しています。さらに TypeScript(openapi-typescript) と自動で型共有されるため、フロントとバックの整合性を維持しながら、複雑なデータ構造が text/event-stream で送信される状況に対応しています。
Retrieval & Augment のフロー
本アプリのコアは検索・補強のプロセスです。以下はユーザーの質問を受け取ってから、回答生成までのプロセスのフローの図です。
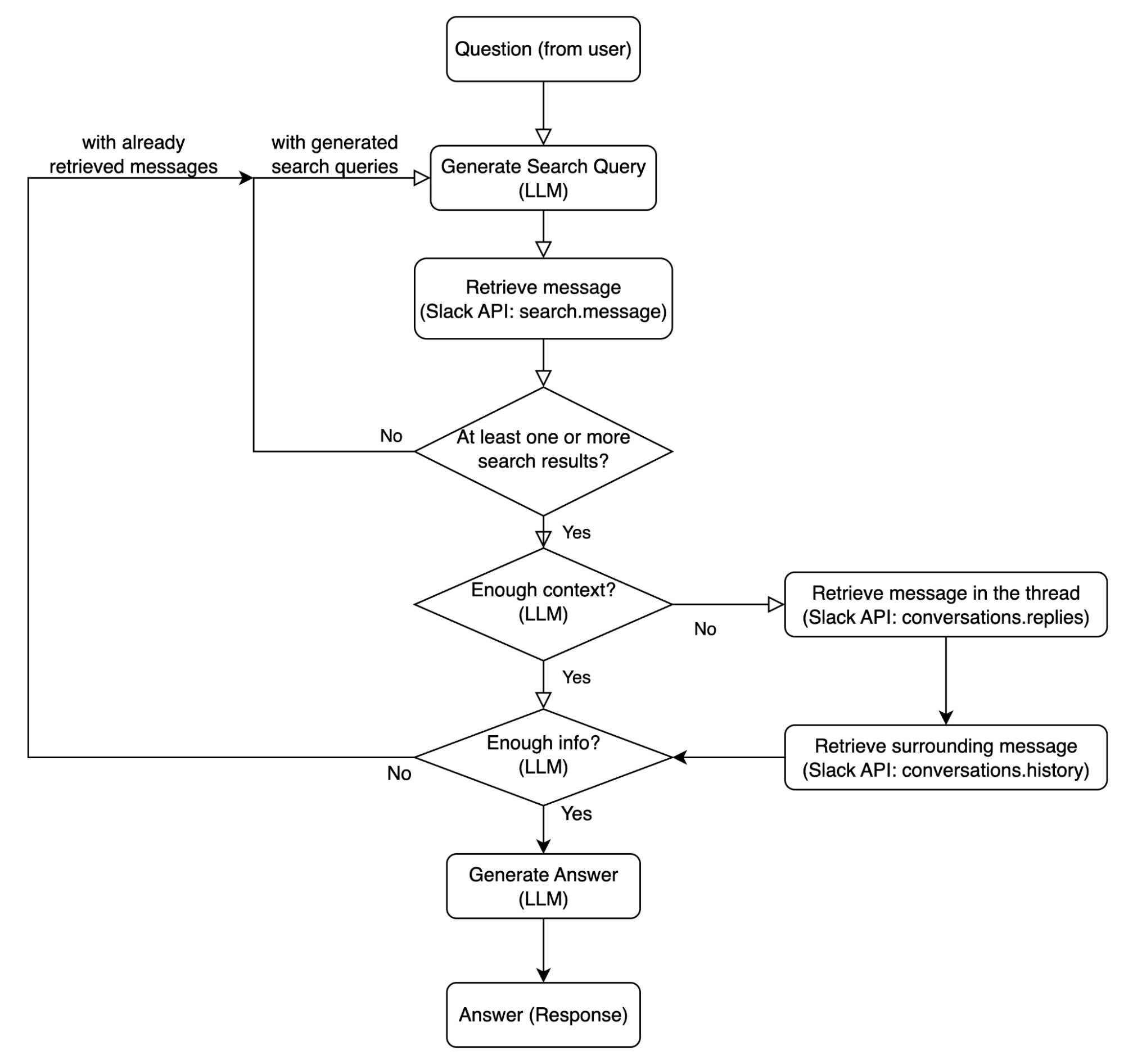
- 検索クエリ生成と検索実行
ユーザーの質問から、Slack の検索 API を使って関連するメッセージを取得します。基本的には、必ず1件以上はヒットするようなフローになっています。
- LLM が質問から検索クエリを複数生成
- Slack の search.messages API でクエリを実行
- ヒット数が0の場合、すでに利用したクエリを与えつつ代替クエリを生成して再試行(最大5回)
- 周辺文脈の取得
検索で取得したメッセージだけでは文脈を十分に理解できないので、周辺のメッセージを取得します。
- 回答生成のために重要であったり、周囲の文脈が必要なメッセージをLLMが複数選択
- 同じスレッド内のメッセージを取得 (conversations.replies API)
- 同じチャンネル内の前後メッセージを取得 (conversations.history API)
- 結果の充足度チェック
ここまでのフローで取得したメッセージから、ユーザーの質問に回答できるかを LLM が判定します。判定には、簡単で小さい判定タスクを複数用意し、それらの判定で一つでも当てはまらないものがあれば「情報が十分でない」と判定させるようなプロンプトにしています。具体的には、以下を判定タスクとしています。情報が不十分と判定されれば再度 1. からループします。
- 質問が具体的な情報(例:数値、日付、名前、決定事項、場所、リンク/添付ファイルの内容)を必要とし、それらの情報がメッセージ内に存在するかどうか
- 質問が曖昧でも、メッセージから少なくとも1つの合理的な解釈が回答ができるか
- 回答生成
情報が十分と判定できたら、LLMで回答を生成して返します。
- 検索結果と周辺文脈を統合
- 回答には必ずソースメッセージへのリンクを付与
Mock Q&A による検証
検証にあたっては、セキュリティ等の理由から、実際のslackのデータではなく、自動で生成したダミーデータ (これを Mock Q&A と呼ぶことにしました) を使いました。一般的な企業の Slack で行われているやり取りをLLMを用いて再現し、Slack の API を使って自動でワークスペースにチャンネルやメッセージを作成するスクリプトを実装しました。大量のやり取りを一度に生成させるとあまり品質の良い会話が生成されないので、100件程度ずつ生成しました。また、会話のリアリティを高めるための手法として、まず会話のタネ(1件目となるメッセージ)を生成させ、それを基準に返信を生成していくという方法を用いました。これにより、Slack上の会話を再現することだけを指示したプロンプトを使う場合に比べ、よりリアリティのある会話を生成できています。
主に検証したい要素・観点は以下の通りです:
- 時系列情報を失わない(最新データを用いる)
- 周辺メッセージとの文脈的つながり(同チャンネルやスレッドの文脈を用いる)
- 複数チャンネルを跨いだ情報照合
単純なQ&Aではなく、現実の会話ログに近い、かつ質問と質問に答えるために必要なメッセージ情報の対応が単純ではないような設計を行うことで、実際の利用を想定した精度検証が可能になっています。以下に検証に利用したQ&Aをいくつか示します。
時系列情報を間違えない
同じチャンネルで過去に何度も似たようなやり取りが繰り返されているような状況を想定します。コーヒー好きが集まって、コーヒー豆を毎月共同購入していて、月ごとに異なる豆を買っているチャンネルがあります。ユーザーが直近に購入された(=最新の購入報告メッセージに記載されている)コーヒー豆の種類を知りたがっています。この時、アプリケーションは適切に最新の情報だけを参照し回答する能力を有する必要があります。以下が実際の動作例です。

この回答は、正しく最新の情報を参照し回答することができています。また、その根拠となるSlackのメッセージのリンクを示しているので、ユーザーはこの回答の真偽を容易に確認することができます。
周囲の文脈を読み取れる
Slackをはじめとしたチャットの履歴は、1件のメッセージからでは、正確な情報を得られないことが多々あります。そのような状況の時、周囲のメッセージ(同じチャンネルのタイムライン上のメッセージや、返信・返信元メッセージ)を参照し、周囲の文脈を正しく理解する必要があります。ここでは、社内イベントの告知メッセージがあり、同じチャンネル内でそれに関する質問が投稿されています。質問に対する回答となるメッセージは、告知メッセージのスレッド内で返信されているという状況です。

この時、ユーザーがイベントに関する質問をします。ユーザーの質問に回答するには、上記のメッセージを3件とも取得し、その上で同じ話題の、ただし回答生成には必要のない他のメッセージに引っ張られない必要があります。以下が実際の動作例です。

正確に回答することができています。また、告知メッセージのあるスレッドのリンクが添付されており、ユーザーはこのイベントが会社貸与PCのみ利用可能であることが即座に確認できます。
チャンネル横断で情報を集められる
次に、より複雑で人間が手で行うのも難しいタスクについても検証しました。
話題によっては、複数のチャンネルを跨って同一の話題が同時に展開されることがしばしばあります。例えば、インシデント対応などにおいては、開発チームのチャンネル、カスタマーサービスのチャンネル、アナウンスチャンネルなどでそれぞれ活発にやり取りが交わされるようなケースが想定できます。また、時系列情報においても複雑性があります。「(今から)Aの対応を開始します」といったような、投稿時刻=時刻情報となるメッセージと、「◯時◯分にBの障害が発生しました」といったような投稿時刻≠時刻情報となるようなメッセージが混ざっています。加えて、同じチャンネル内で「障害原因として考えられるA」の話題と、「障害原因として考えられるB」の話題のような、細かく分類すると異なる話題が並行して繰り広げられているケースがあります。これは、周囲の文脈が必要なパターンのうち、必ずしも前後でやり取りが並んでいるわけではないというかなり文脈理解が難しい状況です。
このような状況で、ユーザーが過去の特定の障害に関するタイムラインの提示と、原因や防止策のまとめを指示したときの実際の動作例です。

ユーザーのすべての指示に、複数のチャンネルから取得した情報を適切に統合して、正確に答えられています。また、不足している部分を推論するのではなく、どういった情報が不足しているのかをまとめて提示できています。これは、社内ドキュメント等と比べ、必ずしも情報が網羅的にまとまっているとは限らないチャットのログを情報ソースにする場合において、非常に重要です。
今後の課題
今後の課題として、キャッシュ戦略や Slack API における rate limit への対応があります。現状、search.meesages API のレート制限はかなり厳しく、課金などによっても制限は変わりません。Slack の API は ワークスペースと API の種類あたりにレート制限が課されているので、システムがスケールした場合、何らかの対策を考える必要があります。
他には、トークン効率の改善とレイテンシ削減も大きなテーマです。事前要約の導入や動的カットオフの適用、候補メッセージを段階的に絞り込む手法などが考えられます。
加えて、ハイブリッド検索やリランキングを活用した場合の性能検証なども試してみる価値があると考えています。これにより検索の精度や応答品質を向上させるヒントが得られることが期待されます。
なお、本アプローチは Slack 固有のものではなく、会話形式で API を提供しているプラットフォームであれば一般的に汎用的に適用可能です。他のプラットフォームでも実装を試し、比較しながら設計をブラッシュアップしていくことも考えられます。
感想
やりがいのあるプロジェクトに2ヶ月間取り組むことができ、とても楽しく、学びの多いインターンでした。メンターの加藤さんと西田さんをはじめ、多くの社員の方々に温かいサポートをいただいたおかげで、2ヶ月間で形に残る成果をなんとか完成させることができました。本当にありがとうございました。
PFNのインターンでは、他のインターンの学生やさまざまなチームの社員の方々と交流を深められるイベントや機会も多くありました。特に PFN Day やインターン成果発表会は、自分にとって非常に学びが多く、大きな刺激を受けました。社員の方もインターンの方も、みなさんユニークで興味深い発表ばかりで、この環境のレベルの高さを強く実感しました。
2ヶ月間、大変お世話になりました。とても有意義な時間を過ごすことができ、心から感謝しています。ありがとうございました!



