Blog
本記事は、PFN2024 夏季インターンシッププログラムにご参加くださった窪田瑛拓さんによる寄稿です。インターンシップでは商品分類の改善検討をテーマに、実在の商品画像の分類精度改善を目指した研究開発に取り組んでいただきました。本取り組みで得られた知見・成果は今後、MiseMise等のリテールソリューションへ活用してまいります。
はじめに
2024年度夏季インターンシップに参加させていただきました、京都大学大学院情報学研究科知能情報学コース1年の窪田瑛拓です。今回のインターンシップでは、商品画像の分類精度を向上させるというプロジェクトに取り組みました。拡散モデルから得られる特徴量(Diffusion 特徴量)を利用する手法を検討し、実写画像に対する few-shot 学習の精度面で、提案手法がベースラインに迫る精度を示すことを確認することができました。
背景
リテールチームでは、商品の種類を画像から推論する商品分類モデルを作成しています。商品分類モデルの学習には、3Dスキャンした対象商品を架空の商品棚に陳列し、レンダリングして得た大量のアノテーション付きCG商品画像を用いています。これにより、商品の実写画像を大量に収集してアノテーションする手間を省きつつ、高精度な商品の分類を実現しています。

図1 商品のCG画像と実写画像の例
しかし、日々発売される新商品を全て3Dスキャンすることは非現実的であるため、商品の3Dスキャンなしで分類精度を上げる手法が、特に数枚の商品画像のみを用いたfew-shotでの商品分類の実現が求められています。
画像分類を行う手法は、分類モデルを学習する手法と、特徴量計算モデルを学習し、特徴量空間で最近傍探索を行う手法の二つに大別されます。新商品の発売に伴って分類クラス数が日々増加するという商品画像分類タスクの性質を考慮すると、新商品の追加に伴って分類モデルを学習し直すことは非効率である一方で、特徴量計算モデルを用いる手法は、基本的に学習済みモデルを用いて参照データを追加するだけでよいため、新商品への適応のしやすさという観点で後者の方が適していると考えられます。これを踏まえ、本インターンでは特徴量計算モデルによる分類手法を検討しました。また、特徴量の計算には拡散モデルを利用しました。
拡散モデル
拡散モデルとは、データに微小なガウシアンノイズを加算する操作を繰り返すと最終的に完全なガウシアンノイズになるという仮定の下で、その逆過程を学習することで、ノイズからデータを生成することができるモデルです。本インターンでは、画像生成モデルとして有名な拡散モデルの一つである Stable Diffusion[1] を、画像生成モデルとしてではなく、画像特徴量を取り出すためのモデルとして利用します。先行研究[2]により、拡散モデルは画像特徴量を抽出するモデルとしても有用であることが示されています。これに基づき、拡散モデルを用いて抽出した画像の特徴量をもとに商品画像の分類を行うことを検討しました。
拡散モデルによる特徴量抽出
先行研究[2]を参考に、拡散モデルを用いて商品画像から画像特徴量を以下の手順で計算します。各クラスの Diffusion 特徴量がクラスごとに密なクラスターを形成するように、拡散モデルから取り出したU-Net特徴量を統合することを意図しています。
- 拡散モデルのノイズ推定部分である U-Net の中間特徴量を取得する。
- 深さごとに異なるサイズを持つ U-Net 特徴量を固定長のベクトルに変換する
- 学習可能な重みを用いて加重平均を計算し、Diffusion 特徴量とする
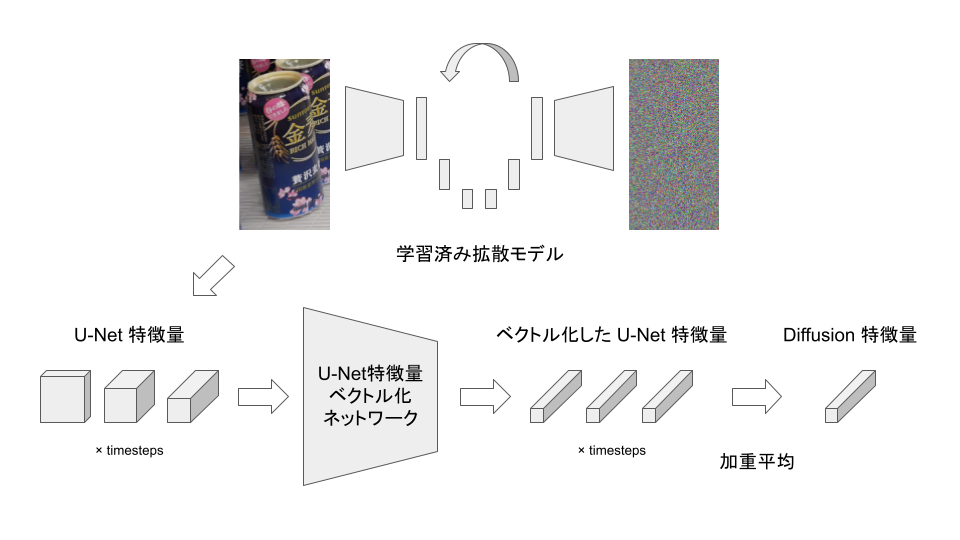
図2 拡散モデルを用いた画像特徴量抽出の流れ
モデルは、ラベルが既知のCG画像から抽出したU-Net特徴量を入力として、クラスラベルに対応するone-hotベクトルを出力するように学習しました。ベクトル化されたU-Net特徴量として用いるのは、このモデルのlogit部分、すなわち全結合層に入力されるベクトルです。
実験
実験では、未知の商品クラスをone-shot学習した場合における提案手法の性能を評価します。すなわち、既知の商品クラスを用いて学習したモデルを用いて未知の商品クラスをone-shot学習し、その分類精度を計算します。未知の商品クラスは、データセット中にある商品クラスの一部を学習に使用しないことで表現しました。
ベースライン手法として、CG画像を入力として商品クラスのone-hotベクトルを推定するVision Transformer(ViT)を採用しました。今回利用したViTは、事前学習済みのvit_base_patch16_clip_224.laion2bです。推論時は、ViTの全結合層に入力されるベクトルを特徴量ベクトルとして利用します。さらに、特徴量抽出に用いる拡散モデルには、Stable Diffusion version 2.1を、U-Net特徴量ベクトル化ネットワークにはResNetとViTを採用しました。
集合Aを学習に使用する商品クラスの集合、集合Bを学習には使用しない商品クラスの集合とします。集合Aに属する商品クラスA1~AnのCG画像を用いて、U-Net特徴量ベクトル化ネットワークとその後の加重平均の係数を学習します。学習後、集合Bに属する商品クラスB1~Bmのデータを用いて、次の4つの実験条件下での分類精度を調べます。なお、参照データとする画像の枚数はいずれの条件でも各クラスで1枚とし、one-shot学習による精度を評価します。また、集合Aの商品クラス数nは80、集合Bの商品クラス数mは79です。
① 集合Bに属する商品クラスB1~BmのCG画像を、商品クラスごとに参照データと推論データに分割し、参照データの特徴量ベクトルをモデルにより計算して特徴量空間に配置する。推論データの商品クラスを最近傍探索により推論し、その精度を調べる。
② 集合Bに属する商品クラスB1~BmのCG画像を参照データとして特徴量ベクトルをモデルにより計算し、特徴量空間に配置する。同クラスに属する実画像を推論データとしてクラスを最近傍探索により推論し、その精度を調べる。
③ 集合Bに属する商品クラスB1~Bmの実画像を参照データとして特徴量ベクトルをモデルにより計算し、特徴量空間に配置する。同クラスに属するCG画像を推論データとしてクラスを最近傍探索により推論し、その精度を調べる。
④ 集合Bに属する商品クラスB1~Bmの実画像を、商品クラスごとに参照データと推論データに分割し、参照データを特徴量ベクトルをモデルにより計算して特徴量空間に配置する。推論データの商品クラスを最近傍探索により推論し、その精度を調べる。
実験結果・考察
実験結果は下の表および図のようになりました。なお、表中の数値は10 runの平均±標準偏差(%)を表しており、図中のエラーバーは標準偏差を表しています。
表1 各手法におけるone-shot未知商品分類精度の比較
提案手法1: ResNet + Diffusion
| 参照 \ 推論 | 未使用 CG(79クラス) | 未使用 実写(29クラス) |
| 未使用 CG(79クラス) | ① 49.853±2.857 | ② 32.215±3.448 |
| 未使用 実写(29クラス) | ③ 26.972±0.979 | ④ 85.968±4.108 |
提案手法2: ViT + Diffusion
| 参照 \ 推論 | 未使用 CG(79クラス) | 未使用 実写(29クラス) |
| 未使用 CG(79クラス) | ① 54.462±2.402 | ② 27.721±2.799 |
| 未使用 実写(29クラス) | ③ 25.854±1.197 | ④ 80.155±3.504 |
ベースライン
| 参照 \ 推論 | 未使用 CG(79クラス) | 未使用 実写(29クラス) |
| 未使用 CG(79クラス) | ① 55.928±1.970 | ② 30.443±4.706 |
| 未使用 実写(29クラス) | ③ 24.631±1.844 | ④ 85.116±4.609 |
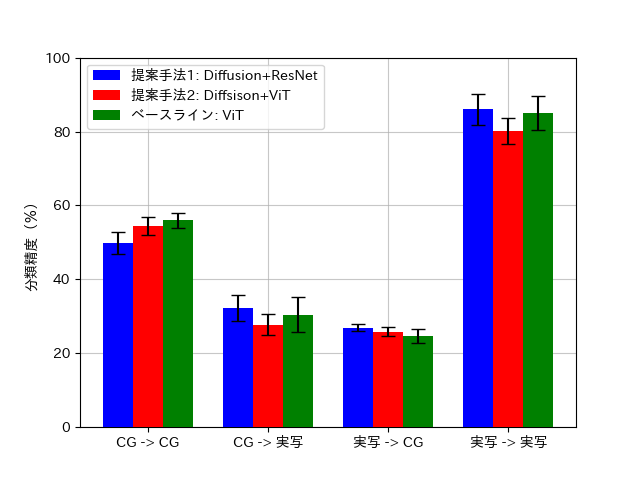
図3 各手法におけるone-shot未知商品分類精度の比較
(「X -> Y」はX画像を参照データとしてY画像の商品クラスを推論することを意味する)
図3より、提案手法1は参照画像も推論画像もCGである場合にベースラインに劣り、その他の場合ではベースラインと同等であるという結果が読み取れます。また、提案手法2は参照画像が実写で推論画像がCGである場合にベースラインと同等であり、その他の場合ではベースラインに劣るという結果が読み取れます。few-shotでの商品画像分類という実用上の問題と最も近い条件である、実写から得られた特徴量ベクトルを参照データとし、実写画像の推論を行う場合では、提案手法1がベースラインと同等の精度を示しており、提案手法1が実用上有用である可能性が高いことを示唆しています。
いずれの手法を用いた場合でも、参照データと推論データがともにCG画像である場合より、ともに実画像である場合の方が分類精度がよいという結果が得られました。これは、モデルが事前学習に実画像を用いているためだと考えられます。提案手法においては、U-Net特徴量ベクトル化ネットワークはCG画像のみを用いて学習を行っていますが、特徴量の抽出に用いたStable Diffusionは実画像のみで学習を行っています。ベースラインとして利用したViTも、事前学習には実画像を用いています。このため、実画像から得られる特徴量はCG画像に比べて密に分布しており、それが精度の差につながったと考えられます。
結論
今回の実験で、Diffusion 特徴量を用いることが、未知商品クラスの実写画像の few-shot 学習に有効である可能性を確認することができました。新商品が追加されたとき、本手法による学習済みモデルを用いて数枚の実画像から得られる特徴量を参照データに追加するだけで、高い精度で新商品の画像を分類できるようになります。新商品の追加の度に分類モデルを学習し直したり、3DスキャンをしてCGデータを大量に取得するコストを省くことができるので、この性質は実用上役に立つものであるといえます。
今後の展望
今回利用した拡散モデルは、公開されている学習後のパラメータを使用しており、商品画像は学習データに入っていないため、高品質な商品画像を生成できるとは限りません。商品画像も生成できるように追加学習することで、より高品質な特徴量を抽出することができ、結果として分類精度が上昇することが期待されます。また、今回特徴量抽出に利用したStable Diffusionはテキストプロンプトの使用も可能なため、これを追加することで同様に高品質な特徴量を抽出できると考えています。これらの工夫を追加で実装することで、ベースラインの精度を上回ることが期待できます。
感想
今回のインターンでは、商品画像分類の精度向上を目的として、拡散モデルから得られる特徴量を利用する手法の検討を行いました。インターン期間中盤で、実験がうまくいかず進捗に遅れが生じ、結果として当初予定していた実験の一部に取り組めなかった点に悔いは残りますが、社員の方々から様々なアドバイスをいただいて問題の解決に取り組んだり、工夫を施したりしながらプロジェクトに取り組むことができ、非常に実のある期間を過ごすことができました。さらに、非常にレベルの高い環境に身を置いたことで刺激を受け、新たな技術や知識を吸収する意欲が高まりました。
最後になりましたが、インターン生と社員の方々、特に主メンターの山田さん、副メンターの武田さんを始めとする、リテールチームの皆さんには大変お世話になりました。この場を借りて感謝申し上げます。
- Hugging Face, https://huggingface.co/stabilityai/stable-diffusion-2-1
- Grace Luo, Lisa Dunlap, Dong Huk Park, Aleksander Holynski, Trevor Darrell, Diffusion Hyperfeatures: Searching Through Time and Space for Semantic Correspondence, NeurIPS 2023
