Blog
本記事は、2022年夏季インターンシッププログラムで勤務された早川知志さんによる寄稿です。
はじめまして。2022年度のPFN夏季インターンに参加した早川知志です。普段はオックスフォード大学で数学(確率論・数値解析)の博士学生をしており、確率測度の離散化やそれにまつわる理論や応用に興味があります。
今回は、大学でやっていることとは趣旨を変えて、深層学習のエンターテインメント応用として二次元キャラクターの学習・生成タスクに取り組みました。
学んだキャラクターのCLIP embeddingを用いた生成例
1. Motivation
オリジナルのキャラクターを描くときに角度や表情を微調整するのには途轍もない労力が必要です。筆者はイギリスでのロックダウン以来趣味でイラストや漫画を描こうとすることが増えたのですが、その過程でこのことに気付きました。生成モデルの力を借りて今までに描いたことのない構図で自分のキャラクターが生成できれば、想像力を補完することができ、漫画などを完成させるハードルが下がるのではないかと考えました。
少し調べた結果、画像などから「アイデンティティー(被写体、特に人物を特定するような情報)を抽出すること」が生成モデルにとって必ずしも得意なタスクではないことを知り、PFNのインターンで是非取り組んでみたいと思い、このテーマで応募しました。
注意:本ブログは技術的な内容が中心なので数学的な解説がある程度続きますが、結局どういうものが生成できるようになったのか手っ取り早く知りたいという方は、図11やGalleryのセクションを先に見てもらっても良いかと思います。
2. Diffusion Model
文章から画像を生成するサービスはここ数ヶ月 (2022年夏のことです) 大衆化がめざましく、Twitterなどで話題になっているものだけでもDALL-E 2, Midjourney, Stable Diffusion, ERNIE-ViLGなどが登場してきました。このうち少なくともDALL-E 2とStable DiffusionはDiffusion Model (拡散モデル) と呼ばれる同系統のモデルに基づいています [1, 2]。Midjourneyについてもそう推測されますが、現時点ではモデルや実装などは公開されていなさそうです。GANやAutoregressive Model等他にも重要なモデルはありますが、ここでは主にDiffusion Modelに絞って解説していきます。
Diffusion Modelに通底する発想は至ってシンプルで「画像にノイズを加える過程を逆向きに解く」ということをしているだけです。もう少し数学的に言えば、「データ全体」を初期分布にもつ確率変数 \(x_0\)(ランダムな画像だと思ってください) からスタートして、時刻 \(t\)に応じて独立に少しずつノイズを加えていきます。そうしてある時刻 \(T\)で元の画像の情報が失われ \(x_T\)の分布が「完全なノイズ」になったとすれば、今度は任意のノイズからこの逆の操作を取れば「データにありそうな画像」が生成されるという仕組みです。
もちろん、特定のノイズの実現値 \(x_T\)から逆向きに解くプロセスは非自明で、現在のノイズ \(x_t\)の実現値に加えて例えば \(x_t\)の密度関数 \(q_t\)の対数勾配 \(\nabla_x \log q_t(x_t)\)の値が必要になります。ただしこの値は \(x_0\)の分布が与えられれば定まるので、この値を深層学習によって近似しにいっていることになります。数学の知識がある人には「確率微分方程式を時間反転して解きにいっている」という説明が伝わりやすいと思います [3]。

図1:CVPR 2022 Diffusion Model Tutorial [4] のスライドより
図1のように、逆向きに解くプロセスは、現在使われているモデルでは \(x_t\)を「デノイズ」して \(x_{t-1}\)を生成する分布の平均値 \(\mu_\theta(x_t, t)\)を学習することになります (\(\beta_t\), \(\sigma_t\)は決定論的なパラメータ)。詳細は省きますが、これは \(x_t\)に乗っているノイズ \(\epsilon\)を学習可能なネットワーク \(\epsilon_\theta(x_t, t)\)によって近似することと等価な作業です (例えば [2, Section B] 参照)。添字の \(\theta\)は学習可能なネットワークであることを示しており、結果的には次のようなロス関数の最小化を深層学習によって行うことになります:
L_{\mathrm{dm}} := \mathbb{E}_{x_0,\, \epsilon\sim{N}(0,\mathrm{I}_d),\, t}
\left[||
\epsilon –
\epsilon_\theta(x_t, t)
||^2\right].
\]
ただし、\(t\)は \([0, T]\)の適当な分布から生成、\(d\)は画像空間の次元、また詳細は省きますが \(x_t\)は \(x_0\)と \(\epsilon\)から定まります。
このように一旦学習が済んでしまえば、あとは図1のプロセスに従ってノイズ \(x_T\)をステップを刻んで少しずつデノイズしていくことで生成画像が得られます。
注意:我々が用いたモデルはLatent Diffusion [2] と呼ばれるモデル (Stable Diffusionはその重みのチューニングを行なったものの名称です) に基づいており、厳密には画像空間ではなくそれをエンコードした画像ライクな少し低次元の潜在空間で物事が進むのですが、混乱を避けるために本ブログ内では画像空間でのDiffusion Modelだと思って説明を進めます。気になる人は論文を参照してください。
2.1 Text-to-image generation
上ではランダムな画像 \(x_0\)と同じ分布の画像を生成するためのプロセスを解説しましたが、これは生成モデルの分野では “unconditional generation” と呼ばれるものです。実際にはテキストなどで指示を加えて生成画像をコントロールできるモデル、つまり “conditional generation” の方が親しみがあるかと思います。
これをunconditional generationの文脈で解釈すれば、コンディション \(y\)によって \(x_0\)の分布が変わる (例えば\(y\)が “cat” である場合\(x_0\)はランダムな猫の画像ということになります) という風にも考えられますが、実際のDiffusion Model の学習では、データセットはランダムな画像とコンディション (キャプション等) のペア \((x_0, y)\)であり、次のようなロス関数を最小化すると考えればよいでしょう:
L_{\mathrm{cdm}} := \mathbb{E}_{(x_0, y),\, \epsilon\sim{N}(0,\mathrm{I}_d),\, t}
\left[ ||
\epsilon –
\epsilon_\theta(x_t, t,
c_\theta(y))
||^2\right].
\]
ただし\(c_\theta\)はコンディションを何らかのベクトルに変換する写像で、テキストであれば BERT や CLIP などのような学習済みモデルを使うことが多いです。
2.2 Additional applications
Diffusion Modelには「ノイジーな画像からノイズを推定して少しずつ取り除く」という性質上次のような機能が (追加の学習等をする必要なく) 基本的に備わっており、画像生成の応用可能性が広がります。
2.2.1 Image-to-image generation
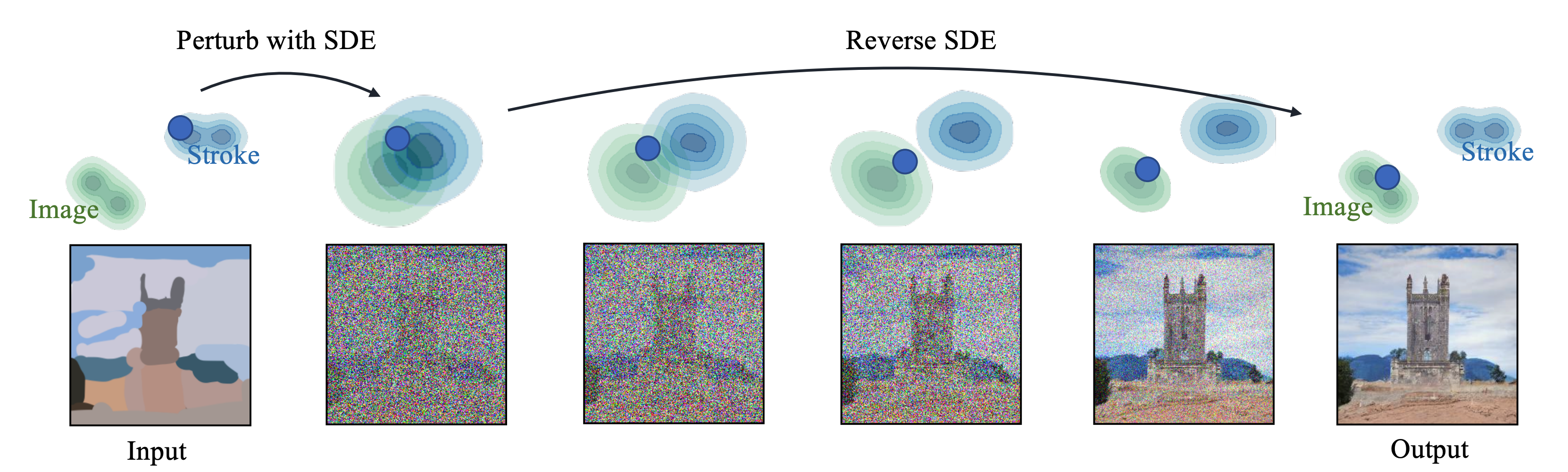
図2:SDEdit論文 [5, Fig 2] より
生成過程において、完全なノイズ \(x_T\)からスタートするのではなく、別画像から生成した「中途半端」なノイズ \(\tilde{x}_t\)(\(t\)は大体 \(0.4T\)から \(0.6T\)) をデノイズすることで、ラフなスケッチの粗い特徴を保ったまま高品質な画像生成を行うことができます (図2参照)。
2.2.2 Composition

図3: Compositional Diffusion論文 [6, Fig 3] より、一部改変
Diffusion Modelのconditional generationでは生成時にはノイズの近似を \(\epsilon_\theta(x_t, t, y)\)ではなく、unconditionalの \(\epsilon_\theta(x_t, t, \emptyset)\)を用いて
\epsilon_\theta(x_t, t, \emptyset) + \lambda (\epsilon_\theta(x_t, t, y)
-\epsilon_\theta(x_t, t, \emptyset))
\]
によって行うと性能が向上するという報告 (classifier-free guidance [7]) があり、これは最新手法でも取り入れられています。直感的な説明をすれば「無条件にデノイズする場合に比べてどの向きに寄せてノイズを解釈するか」ということになるのですが、Compositional Diffusion [6] 論文ではこの向き \(\epsilon_\theta(x_t, t, y)
-\epsilon_\theta(x_t, t, \emptyset)\)に別条件のものの線型結合を用いれば複数の条件を「合成」できるということを報告しています。つまり、条件 \(y_1,\ldots, y_n\)があれば、ノイズの近似を
\epsilon_\theta(x_t, t, \emptyset) + \sum_{i=1}^n \lambda_i(\epsilon_\theta(x_t, t, y_i)
-\epsilon_\theta(x_t, t, \emptyset))
\]
にすることで、元々のDiffusion Modelを活用しつつ合成ができることになります。図3ではベースモデルでAND部分をそのまま繋げて長い文章を渡した場合とこの「合成」方法を用いた場合の比較が行われています。
3. Learning identities
キャラクターや物体などのアイデンティティを学習してそのバリエーションを生成する技術は、いくつかの限定的なアプローチこそあれ、インターン開始前の時点では世に有効な研究成果があるとは言い難い状況でした。いくつかの関連研究を紹介します。
3.1 GAN-based approach
まず近いものとして挙げられるのはGANにおけるsematic manipulationでしょう。ざっくり言ってしまえば、潜在空間内で特定方向に移動することで、色、表情、年齢、顔の向きなどをコントロールすることが可能です (GANSpace [8]、InterfaceGAN [9] やPFNのsurrogate gradient field [10] など)。ただし、顔の向きをいじっている間に髪型が変わってしまったりと、必ずしもアイデンティティを保って操作できるとは限りません。
人間の顔に特化したものになりますが、FaceID-GAN [11] は顔画像生成のロジックに顔認証のネットワークを加えて3-player gameにしたもので、顔中心の切り抜き画像という限定的な設定ですが、人のアイデンティティを保ったまま画像にバリエーションをもたせることに成功しています。
また、昨年末に発表されたFreeStyleGAN [12] では、静止した人物の10-25点程度の視点からの顔写真から、任意視点からの顔画像に対応する潜在ベクトルを学習し、実際に生成に成功しています。
3.2 Textual inversion
前節、特にその後半で挙げた二つの研究はアイデンティティを保つことを目的の一つに掲げていますが、人間の顔であることが本質的であるパート (顔認証・3Dモデル) を含んでおり、キャラクターの学習に対してそのまま使えるものではありませんでした。
そんな中、8月前半にarXivに投稿された論文 “An Image is Worth One Word” [13] は前述のDiffusion Modelにおいて「新しい固有名詞を学習する」という斬新なアプローチで一気に多様なモノのアイデンティティの学習を可能にしました。 8月後半に投稿されたGoogleのDreamBooth [14] もほぼ同様のアプローチを取っていますが、まず前者の文献に基づいて解説します。これらのアプローチはtextual inversionと呼ばれています。
Text-to-image generationやより一般の自然言語処理において、BERTやCLIPなどの主流のモデルでは、まず与えられた文章を「辞書」に照らし合わせて既知の単語の列に分解し、対応する (辞書) における番号を割り当てます。これが図2におけるTokenizerと呼ばれる部分の役割であり、これにより入力した文章は数の列に変換されます。次に、学習済みモデルによってそれぞれの単語に対応するベクトルの列に変換します (embedding)。最後にベクトルの列をTransformerなどのベクトル列を扱うモデルに渡し、最終的なコンディションを表すベクトルに変換することになります。
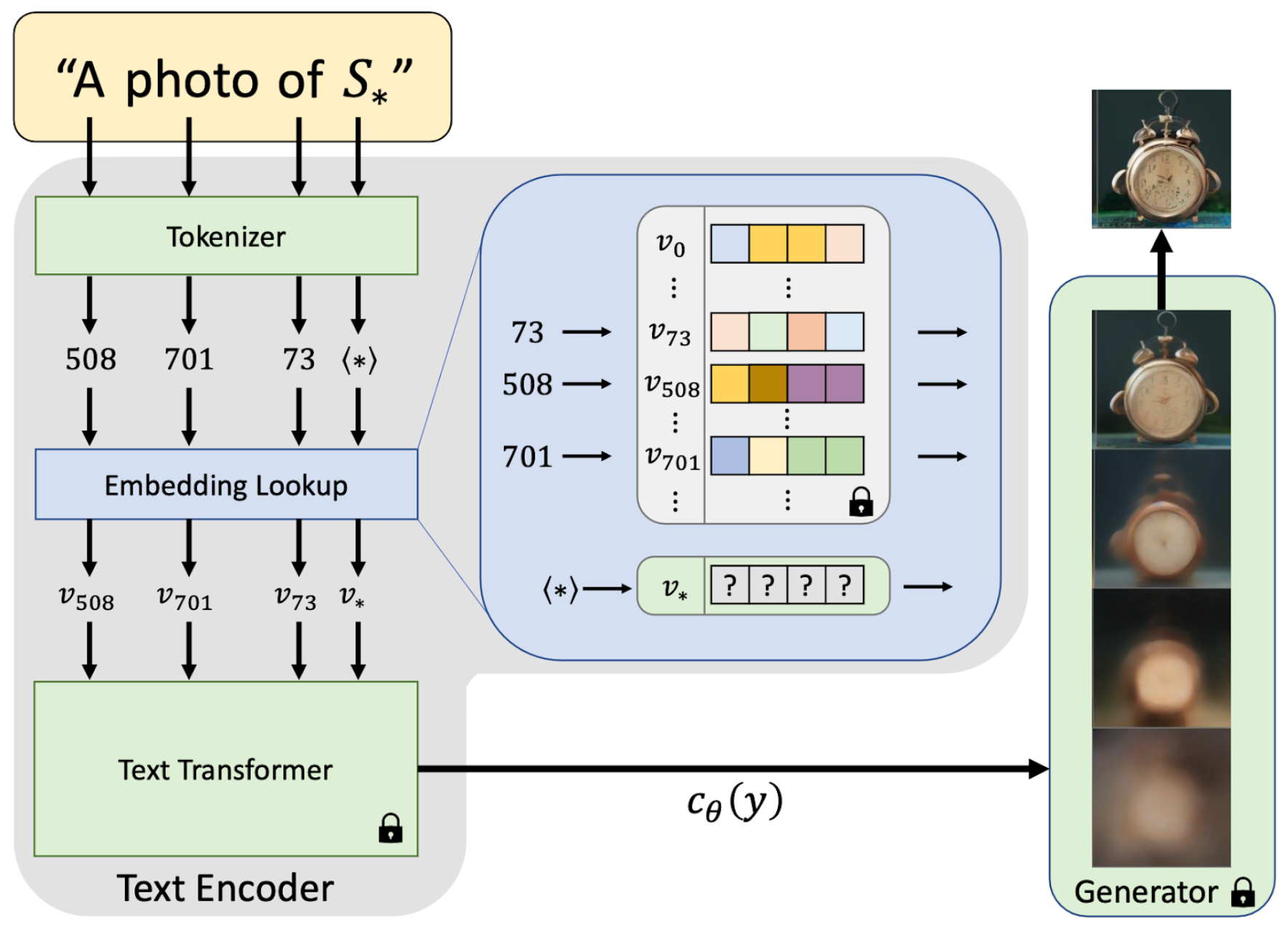
図4:”An Image is Worth One Word” 論文 [13, Fig 2] より、一部改変
Diffusion Modelのところで使った記号を用いれば\(y\)が文章 (単語の列)、この文章を最終的にTokenizer, embedding, Transformerに通して得られるベクトルが \(c_\theta(y)\)です (図4参照)。この写像 \(c_\theta\)はBERTやCLIP等の学習済みモデルを使うことが多く、Diffusion Modelの学習時には基本的にパラメータを固定しておきます。
図4を既に見た方は \(S_*\)という「単語もどき」が登場していることにお気づきでしょうか。上で説明した文章処理のプロセスを思い返してみると、別に自然言語ではなくembedding後のベクトルの列を途中で渡してもいいことになります。Textual inversionの発想は、一言で言ってしまえば「存在しない固有名詞に対応する埋め込みベクトル \(v_*\)を学習する」ということになります。JapanやElon Muskに対応する埋め込みが存在するのだから、名前がついていないだけで自作のキャラクターに対応する埋め込みもあってよい、というと分かりやすいかもしれません。
このtextual inversionの学習プロセスはDiffusion Modelが学習できる環境にあれば比較的単純で、例えば \(y(v)\)を “A photo of \(S_*\)” の \(S_*\)に対応するベクトルとして \(v\)を代入したものだとすれば\(v_*\)は次の最適化問題を (近似的に) 解いて決定されます:
v_* \in \mathop{\arg \min}\limits_v \,\mathbb{E}_{x_0,\, \epsilon\sim{N}(0,\mathrm{I}_d),\, t}
\left[ ||
\epsilon –
\epsilon_\theta(x_t, t,
c_\theta(y(v)))
||^2\right].
\]
ただし、ここで \(x_0\)はもちろん “A photo of \(S_*\)” に該当するような (ランダム) 画像でなければなりません。経験的には、数枚 (3~5枚) の画像で十分であることがわかっています。元論文では2台のV100 GPUを用いて約2時間の最適化を行なったとのことです。
DreamBooth [14] は名詞ではなく形容詞の学習を行う、モデル全体のファインチューニングを加える、などの違いがありますが、発想自体はほぼ同じです。図5に両手法の比較を載せておきました。DreamBoothの方が明らかに忠実度が高いですが、元となっているモデルのクオリティが違う (DreamBoothはGoogleのImagenという非公開モデルを使っている) ことやファインチューニングの有無での比較が論文内で行われていないこと等を考慮に入れる必要はあるでしょう。DreamBoothについてはまた、計算時間の長さに加え、モデルに対して並列にコンセプトを追加することができないのは大きな欠点であるように思えます。
どちらの手法においても、獲得した埋め込みは別の文章に入れていじることもできるので、応用可能性が広がります。

図5:DreamBooth論文 [14] より、両textual inversion手法の比較
4. What we did
ではこれらのtextual inversion手法はキャラクターの学習に対して使えるのでしょうか。まずは公開されているStable Diffusionに対してこれらを再実装して適用してみた結果を紹介します。キャラクターの学習例としてはPFNの論文内で自動生成+視点変更が施されている図6のキャラクターを使いました。

図6:SGF論文 [10, Fig 16] より
一番右の画像では耳の色が少し変わっていますが、これが関連研究のところで述べたGAN-basedの手法における副作用の一例です。今回の実験においては大きな影響はない (同一のキャラクターとみなせる) と考えました。以降の実験は、全て1台のA100を使用して行なっています。
4.1 Multiple vectors
実験をする上ですぐに分かったことは、ベクトル1つの埋め込みを最適化するだけではなかなかうまく学習してくれないということです。例えば “A painting of \(S_*\)” とする場合\(S_*\)にベクトル1つ (=1単語) を割り当てるのではなく、より多く、例えば10個 (=10単語) を割り当てた方が学習が早く、クオリティが向上するということが観察されました。このベクトルの個数による計算時間の増加は学習過程全体において支配的ではないので、1個で回しても10個で回してもほとんど変わりません。図7(a, b)に約2時間最適化した際のキャラクター生成結果を載せておきます (バッチサイズ20・Adamで学習率\(10^{-2}\)・512イテレーション)。 ベクトルの本数を増やした方が圧倒的に忠実度が上がっていることがわかると思います。

図7:Stable Diffusionでのキャラクター学習の例
図7(c, d) はDreamBoothとTextual Inversionのハイブリッドでモデルのファインチューニング・埋め込みベクトルの最適化共に学習率\(10^{-4}\)(モデルのoptimizerは元モデル学習時に準拠してAdamW) で行なったもので、class-preservation lossというモデルの過学習を避けるための計算が生じるので実行時間は約4時間になっています。ここではDreamBooth側の学習率が低くやや不公平ですが、モデルに比べてベクトルの学習率を上げた実験においてもやはり収束の遅さが際立っていました。
それぞれある程度のキャラクターの学習はできている様子ですが、やはり元のモデルがこういったイラストに特化しているわけではないため、元のキャラクターを学習するにはモデル自体の改善が必要そうです。また、学習したベクトルを文章中に入れて操作することも限定的にしかできませんでした。
4.2 Fine-tuned model
さて、インターン中盤にStable Diffusionが公開されて以後、私のメンターの方がStable Diffusionのイラスト向けファインチューニングを行っていました。詳細についてここでは触れませんが、Stable Diffusionにおける条件付けを変更して画像のCLIP embeddingとテキストのCLIP embedding (図4で言えば \(c_\theta(y)\)のところに相当します) をいずれも受け取れるように学習し直されており、例えば図6の4枚の画像のCLIP embeddingの平均からは図8のような画像が出力されます:

図8:ファインチューンされたモデルのCLIP embeddingからの出力例
まずはこのモデルにおいて図6のキャラクターを学習させてみました。それぞれ埋め込みベクトルの本数が1, 3, 10, 30本の場合を図9に示します。

図9:ファインチューンされたモデルでのキャラクター学習例
この時点でベクトルの本数を増やせばこの時点でも非常に忠実度が高く、そもそものモデルの表現力が重要であることがわかります。さらにこの時点で計算をFP32からFP16に置き換えており、それによるパフォーマンスの低下も特に見られなかったため、約1時間の学習でこのクオリティに到達するようになりました。
ベクトルの本数を増やすと過学習をしてしまって汎化性能が失われるかと思いきやどうやらそうとも限らず、むしろimage-to-imageによるラフスケッチからの生成であれば30本の方が1本よりもきちんと生成してくれるという傾向が観察されました (図10参照。1 vector の場合は崩れた画像が多かったので、見映えの良いものををチェリーピックしました)。

図10:学んだキャラクターのimage-to-image生成例
図10ではラフスケッチから学んだキャラクターの生成に成功しており、この時点で実用可能性の期待が大きく持てるものですが、依然として二つの問題点がありました。
- キャラクターの学習に1時間かかるのは長すぎる
- 学習したキャラクターを文章中に入れてもうまく要素を反映してくれない (あるいは過度のprompt engineeringが必要)
まず問題点1を解決すべく、キャラクターを単語 (列) として学習するのを一旦諦めることにしました。
4.3 Direct optimization in the CLIP space
キャラクターを単語として学習するのを諦める、とはどういう話かというと、図4における \(v_*\)に対する最適化ではなく別のもの\(c_\theta(y)\)に相当する部分を最適化しようということです。ここで使われているファインチューンされたバージョンのStable Diffusionモデルでは、テキスト入力 \(y\)を \(c_\theta(y)\)として、また画像入力 \(z\)を \(c^{\text{img}}_\theta(z)\)として同じCLIP embeddingの空間 (ここでは 77×768 次元) に取り込むことが出来ます。
この性質を用いて、インプット画像 (\(z_1,\ldots,z_N\)とするがここでは図6の4枚) に対してCLIP embeddingの平均
\(w_0 = \frac{1}{N} \sum_{i=1}^N c^{\text{img}}_\theta(z_i)\)を計算し\(w_0\)を初期値としてキャラクターを表すCLIP embeddingを最適化しにいくことにしました。最適化のロジックはtextual inversionと同じで\(w_*\)を次の最適化問題の解として求めることを目指します:
w_* \in \mathop{\arg \min}\limits_w \,\mathbb{E}_{x_0,\, \epsilon\sim{N}(0,\mathrm{I}_d),\, t}
\left[ ||
\epsilon –
\epsilon_\theta(x_t, t, w)
||^2\right].
\]
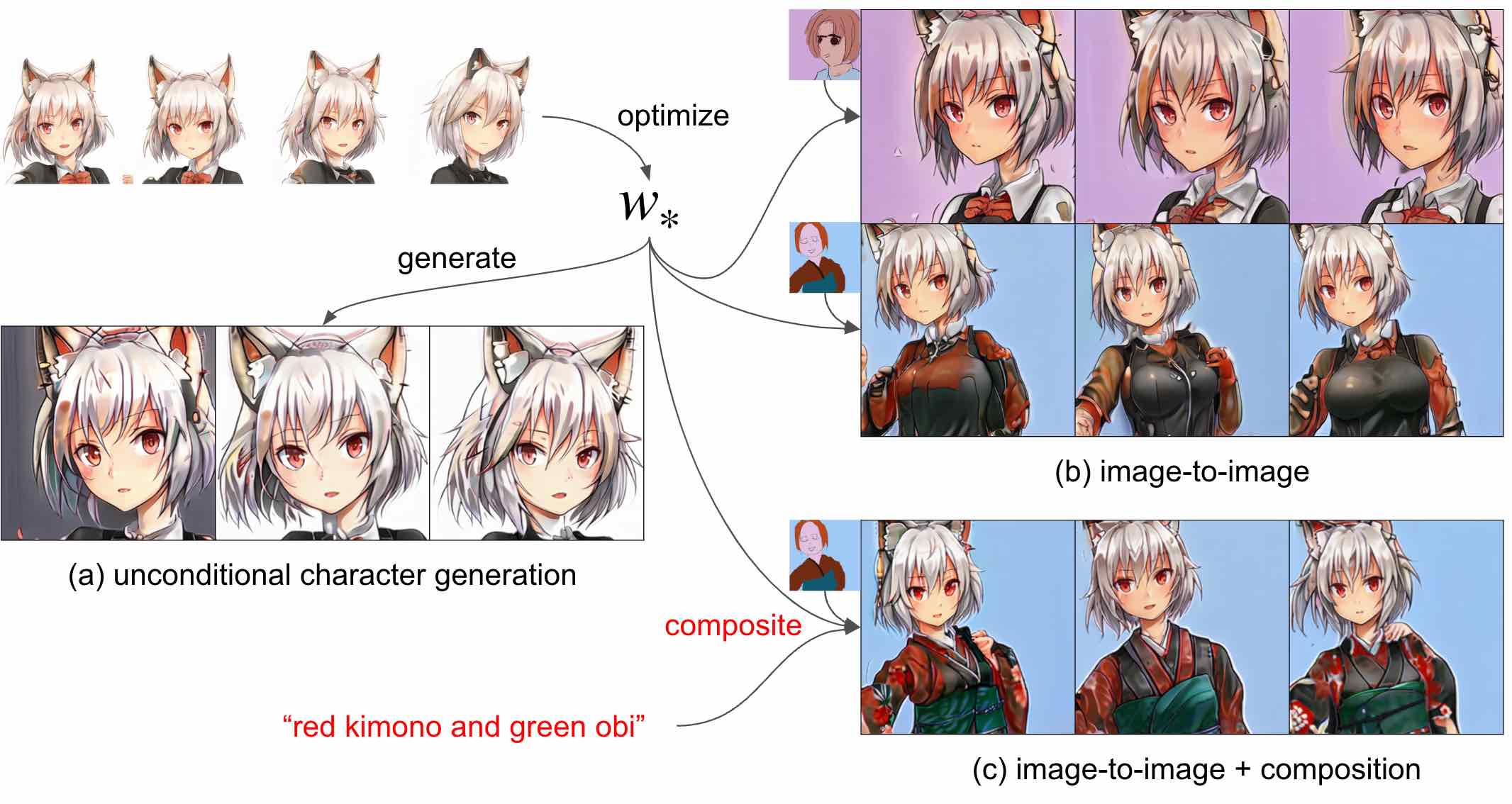
当初はtextual inversionにおいてはTransformerが正則化の役割を強く担っていると考えており、この最適化では過学習が避けられないのではないかとの懸念がありましたが、image-to-image等の生成結果を見ると多様性を条件付けによって追加できていると言えるでしょう。図11にこのアプローチで約10分の最適化で得られたCLIP embedding \(w_*\)を使ってキャラクターを生成した例を示します。
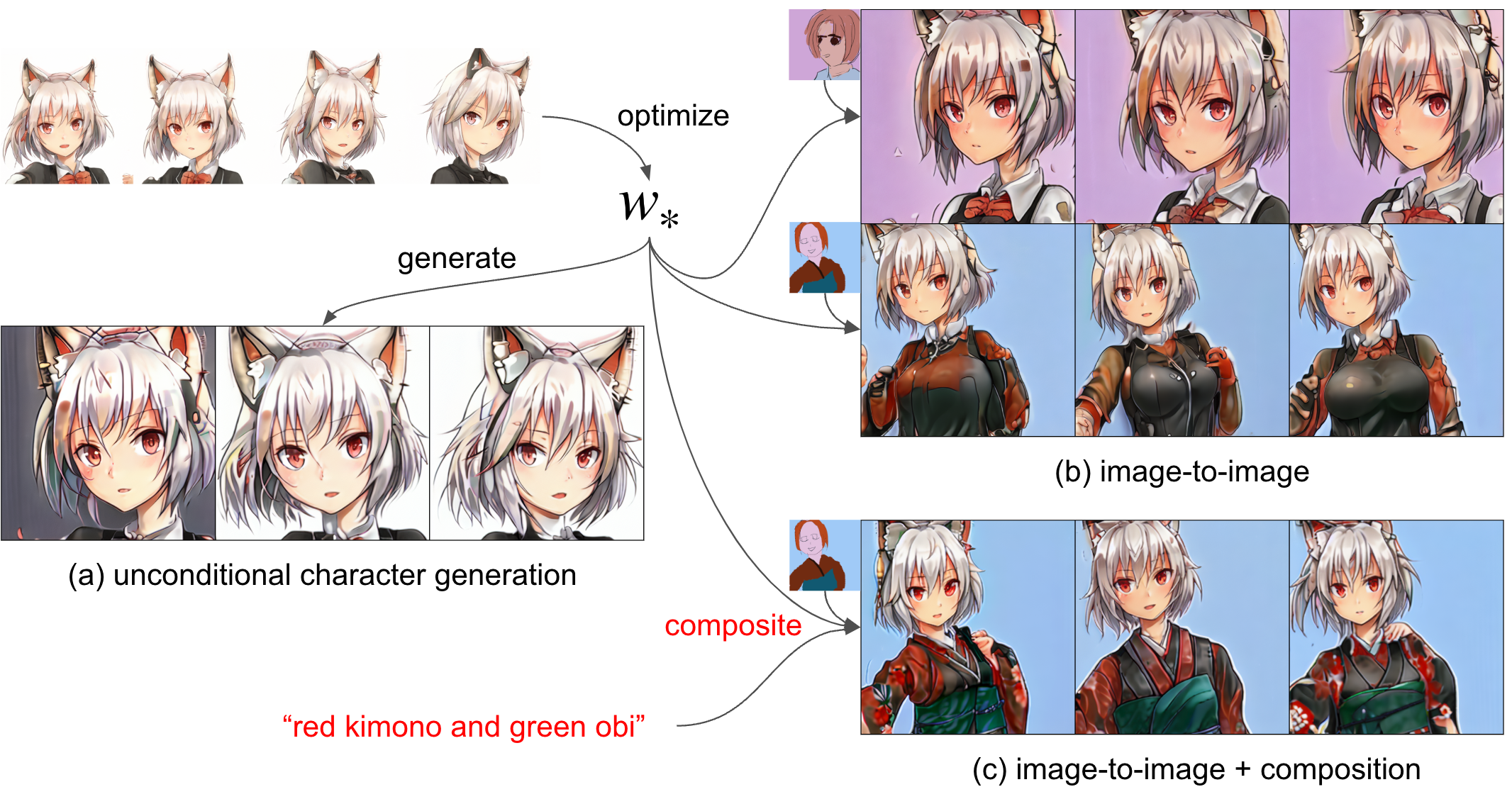
図11:学んだキャラクターのCLIP embeddingを用いた生成例
ここで特筆すべきは、学習の高速化はもちろんですが、顔画像のみで学習してもimage-to-imageでそれ以外が生成できることも挙げられます。特に、Diffusion Modelのところで説明したcompositionの手法を使うことで、うまく認識してくれなかった落書き部分をテキストでの説明を加えて修正することも可能です (図11(c) を参照)。
Compositionによる操作が可能なので、前節で挙げた問題点2 (学習したキャラクターを文章中でうまく操作できない) についてもある程度回避することができます。技術的にはここまでが本インターンシップで取り組んだことになります。次のセクションでこれらの取り組みによりどういったものが生成できるようになったかをもう少しお見せしてこの記事を締めたいと思います。
5. Gallery
5.1 Other characters
そもそもGANで生成したキャラクターであればアイデンティティを保つところに多少の難はあれど連続的に変形することは可能なので、他の人によって作られたキャラクターでも手法の検証を行うことにしました。まずは、アートワークの二次利用をCC-Byライセンス下で許可しているDavid Revoy氏 (二次利用ガイドライン) の作品 Painting studies でのキャラクター顔画像を用いて実験した結果が図12です。表情やメガネの有無などをうまく絵全体の雰囲気を保ったまま合成できていそうです。
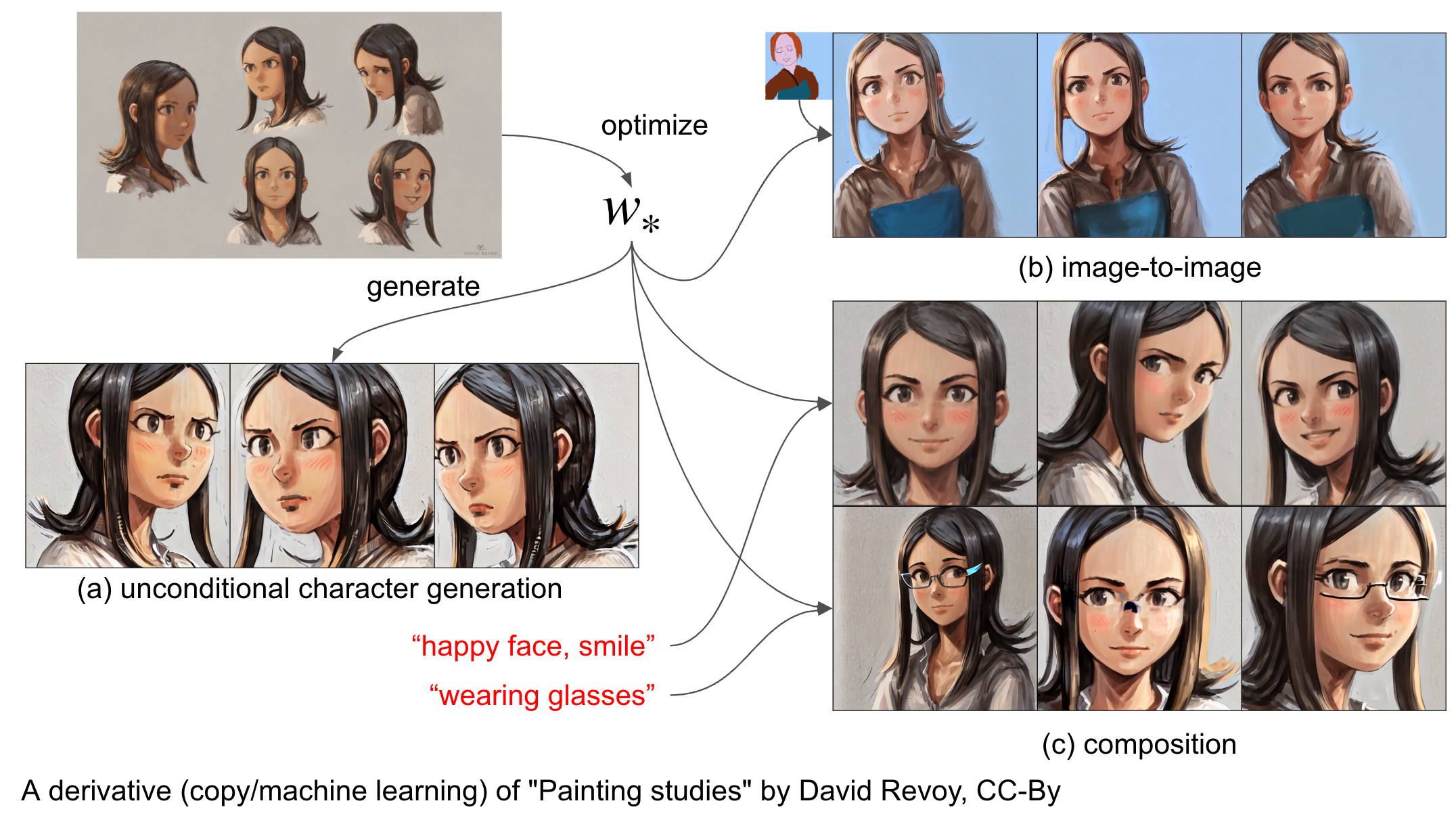
図12:複製 (左上) および機械学習による再生成 (その他):”Painting studies” by David Revoy, CC-By
次に、PFNの線画自動着色サービスPaintsChainer(現Petalica Paint)の公式キャラクター、絵愛ちえな のデフォルメ版イラストを使った学習を行いました。その結果を図13に示します。入力が3枚限りだからか、デフォルメが強くモデルが学んでいる標準的なイラスト分布から外れているからか分かりませんが、前の二つのキャラクターに比べて過学習の傾向が明らかに見て取れます (特に生成されているポーズ)。
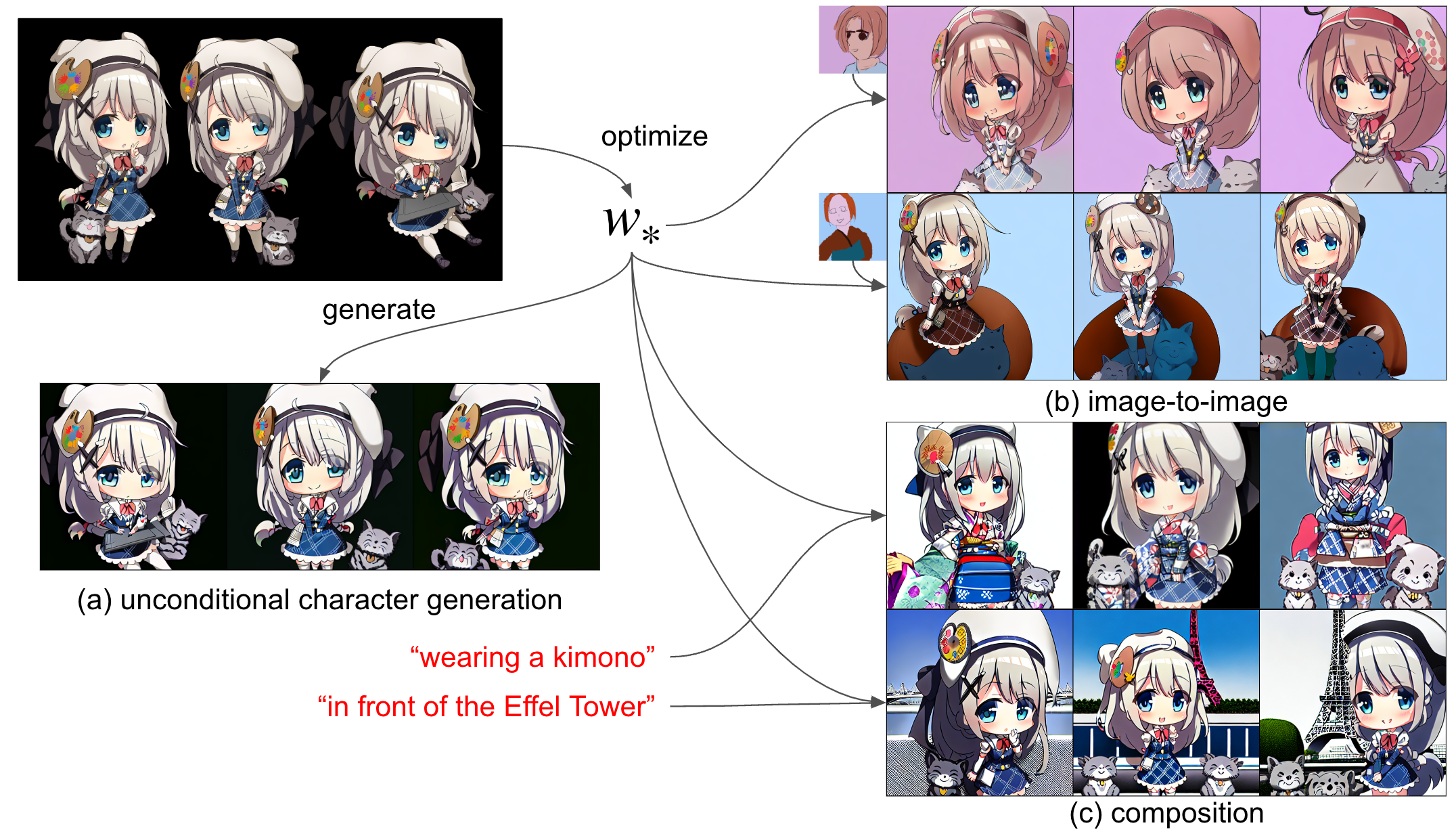
図13:絵愛ちえなの学習および生成例
最後に、当初の目的であった素人の描いたキャラクター、つまり私の描いたものでも学習させてみるべきだろうということで、急遽私が新たなキャラクターをいくつかのアングルから一貫性をもって描き、そのラフと色を塗ったものそれぞれで生成を試してみました。図14および図15に載せておきます。これくらい描き込みの少ないキャラクターなら現時点では最初から描いた方が早い場合も多そうですが (色まで塗る場合は、自分の場合AIにやらせた方が圧倒的に早いです)、描いたことのないアングル・表情等のヒントはそれでも得られそうです。
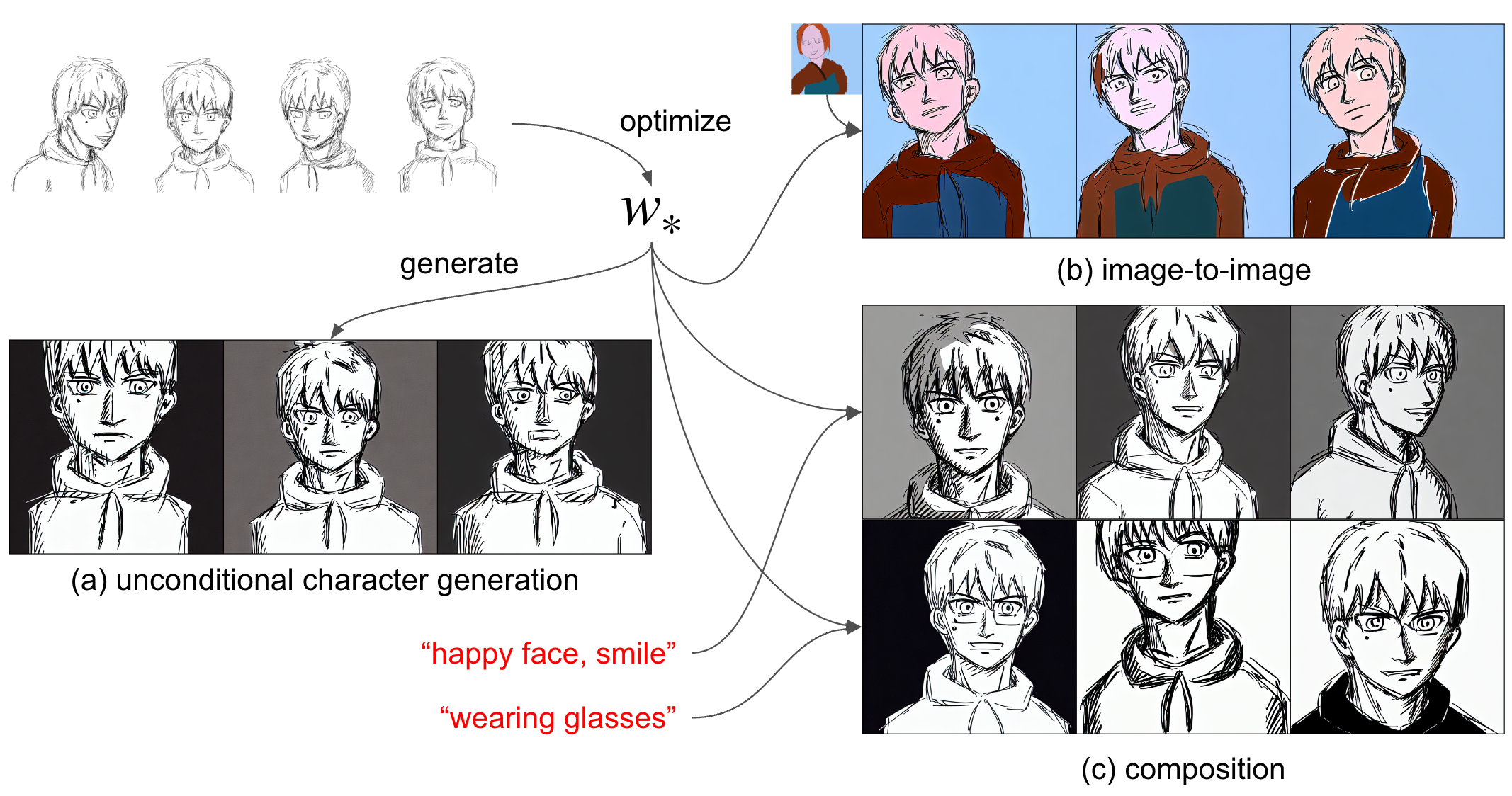
図14:オリジナルのキャラクター (ラフ画) の学習例
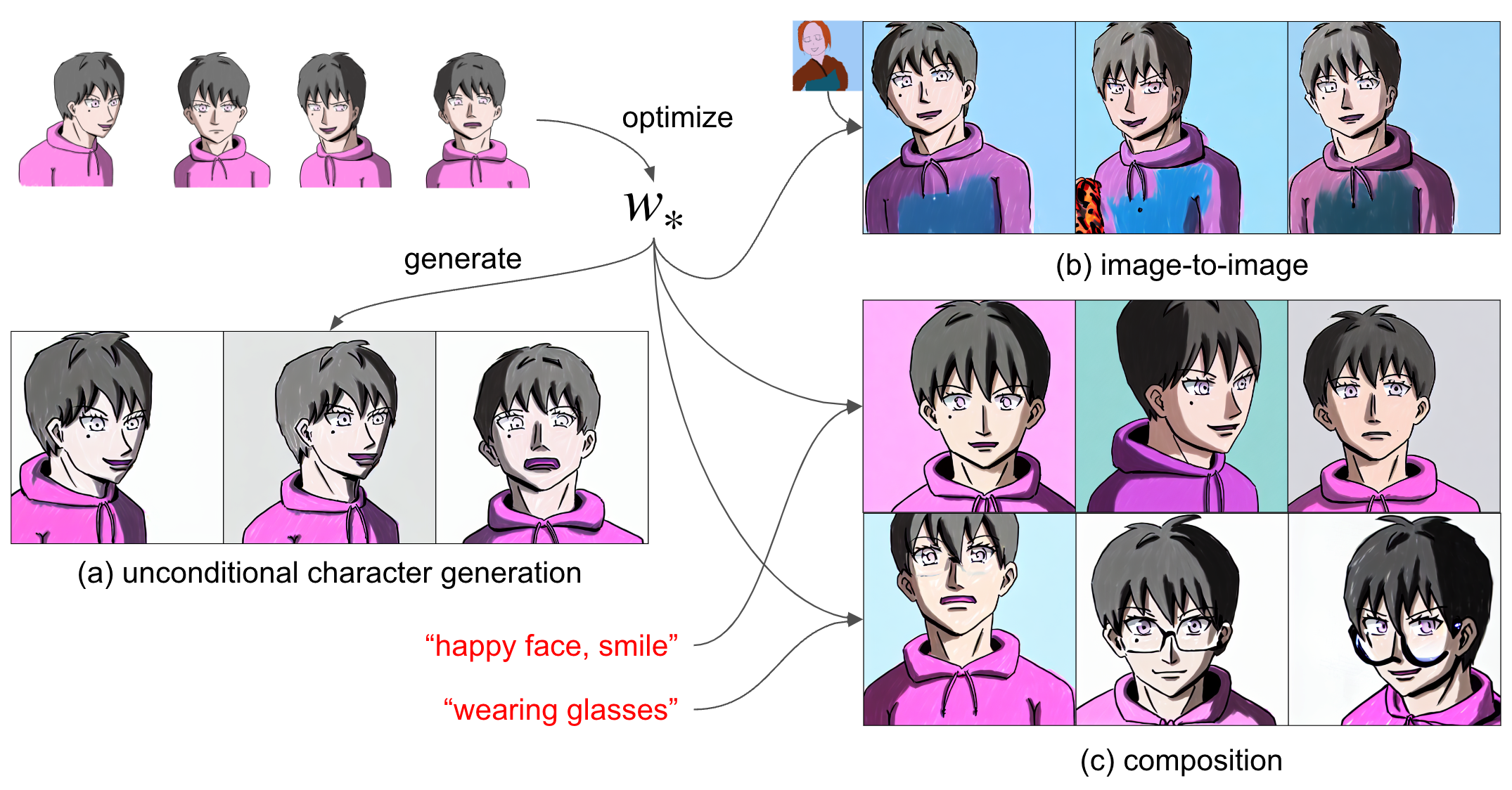
図15:オリジナルのキャラクター (カラー画) の学習例
以上のキャラクターたちの学習は、unconditional generationの結果を見ながら10分〜30分程度で止めて行いました。
5.2 Further generated images
例えば学んだ埋め込みに対して “sad face” という文章との合成をとってやることで、悲しげな表情のイラストが生成されます。

写真を元にしてリアル寄りのキャラクターを生成することももちろん可能です。図6のキャラクターの埋め込みを条件付けに与えています。

他にできる面白いこととして、キャラクターとキャラクターの補間があります。別のキャラクターのCLIP embeddingの内分点を与えることで、それらのキャラクターの「中間」のようなものも作れます。

もちろんこれらのこと一つ一つは、十分なデータがあればGANなどの既存のモデルで達成されてきたことであり、生成物そのものに対する驚きは少ないかもしれません。しかしながら、少ない入力画像からDiffusionという一つのモデルでここまで色々なことが出来るというのは非常に興味深く思えます。
感想
本インターンでは、キャラクター画像数枚からそのキャラクターに対応するベクトル埋め込みを学習し、単なるキャラクターの再生成だけではなくラフスケッチに基づいて生成したり他のテキストによる条件付けとの合成を試したりしました。普段博士課程でやっているじっくりと腰を据えた理論研究に比べ、インターン中に新しい論文を沢山読み、さらに関連研究がインターン中にも世の中で凄い勢いで進んでいくのはなかなか恐ろしくも新鮮な体験でした。その中で既存研究にキャッチアップしそれらを検証し組み合わせることに加え、一定の学習の高速化にも成功しました。ただし過学習が起きてしまったり調整できるパラメータが沢山あったりと、やり残したことも多くあります。
またこういった技術の公開には慎重にならなければなりませんが、一方で本ブログ中でも試していたように、例えばCrypko等で生成したキャラクターが落書きから生成できるようになれば、イラストが描けない人でも自分でこれらのサービスを介して漫画のようなものが作れたりと、クリエイティブな活動の可能性が広がるかもしれません。
二ヶ月弱という短い間でしたが、社員のみなさんのお陰で面白いテーマに集中して取り組むことができ、非常に楽しい経験になりました。特に開発経験のない私を根気強くサポートしてくださったメンターのお二人には頭が上がりません。ありがとうございました。
References
[1] Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., & Chen, M. (2022). Hierarchical text-conditional image generation with clip latents. arXiv:2204.06125.
[2] Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. arXiv:2112.10752 (CVPR 2022).
[3] Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., & Poole, B. (2021). Score-based generative modeling through stochastic differential equations. arXiv:2011.13456 (ICLR 2021).
[4] https://cvpr2022-tutorial-diffusion-models.github.io/
[5] Meng, C., He, Y., Song, Y., Song, J., Wu, J., Zhu, J. Y., & Ermon, S. (2021). SDEdit: Guided image synthesis and editing with stochastic differential equations. arXiv:2108.01073 (ICLR 2021).
[6] Liu, N., Li, S., Du, Y., Torralba, A., & Tenenbaum, J. B. (2022). Compositional Visual Generation with Composable Diffusion Models. arXiv:2206.01714 (ECCV 2022).
[7] Ho, J., & Salimans, T. (2022). Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (short version in NeurIPS 2021 Workshop).
[8] Härkönen, E., Hertzmann, A., Lehtinen, J., & Paris, S. (2020). GANSpace: Discovering Interpretable GAN Controls. arXiv:2004.02546 (NeurIPS 2020).
[9] Shen, Y., Yang, C., Tang, X., & Zhou, B. (2020). InterFaceGAN: Interpreting the Disentangled Face Representation Learned by GANs. arXiv:2005.09635 (CVPR 2020).
[10] Li, M., Jin, Y., & Zhu, H. (2021). Surrogate Gradient Field for Latent Space Manipulation. arXiv:2104.09065 (CVPR 2021).
[11] Shen, Y., Luo, P., Yan, J., Wang, X., & Tang, X. (2018). FaceID-GAN: Learning a symmetry three-player gan for identity-preserving face synthesis. CVPR 2018.
[12] Leimkühler, T., & Drettakis, G. (2021). FreeStyleGAN: Free-view editable portrait rendering with the camera manifold. arXiv:2109.09378 (SIGGRAPH Asia 2021).
[13] Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A. H., Chechik, G., & Cohen-Or, D. (2022). An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion. arXiv:2208.01618.
[14] Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., & Aberman, K. (2022). DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation. arXiv:2208.12242.