Blog
本投稿はPFN2022 夏季国内インターンシップに参加された松岡航さんによる寄稿です。
はじめに
PFN2022年度夏季インターンシップに参加した法政大学情報科学部ディジタルメディア学科3年の松岡航です。大学では学内のサーバ管理をしています。ネットワークやコンテナ技術に興味があり、今回Cluster ServicesチームというPFNの機械学習基盤を開発・運用するチームのインターンシップに参加しました。
背景
良い深層学習モデルを実現するには、モデルの構造や適切な学習率などを変更した多くの試行を行うことが重要です。1回の学習を高速に完了させることで、効率よくこの探索を行うことができます。高速化の方法の1つとして、複数のプロセスを使って学習することで学習を高速化する分散深層学習という手法があります。例えばデータ並列な分散深層学習では、複数のプロセスにデータを分散させて処理することで、一度に多くのデータを使って学習することができます。この学習の更新ステップでは、プロセスが計算した損失関数の勾配をプロセス間で平均して、モデルを更新します。勾配を集約する集団通信は毎反復行われるので、集団通信の性能は分散学習の並列化効率を左右し、通信性能の最適化は重要です。
PFNのKubernetesクラスタではRDMAとSR-IOVを組み合わせて高速な通信を実現しています。
Remote Direct Memory Access (RDMA)
RDMA (Remote Direct Memory Access) は、自ノードのメモリ上にあるデータを他のノードのメモリに、CPUの介入を不要にしてNICが直接読み書きすることによって通信を高速化する技術です。これを用いると、GPU と NIC が直接通信することができるようになります。
PFNのクラスタで利用しているGPUノードには複数のCPU、複数のGPU、複数のNICが搭載されています。例えばMN-2AのGPUノードの場合、1ノードに2 CPU、8 GPU、4 NIC が搭載されています。GPUノードの利用効率を高めるため、1 GPUノードに複数の計算ワークロードを混載して分散学習を行う場合を考えると、1つのPodに割り当てるGPUとNICが限られる場合があります。例えば1つのPodに1 GPU・1 NICを割り当てる場合は、左図のようにNICとGPU間が最短経路で通信できる場合や、右図のように遠回りをする場合が考えられます。
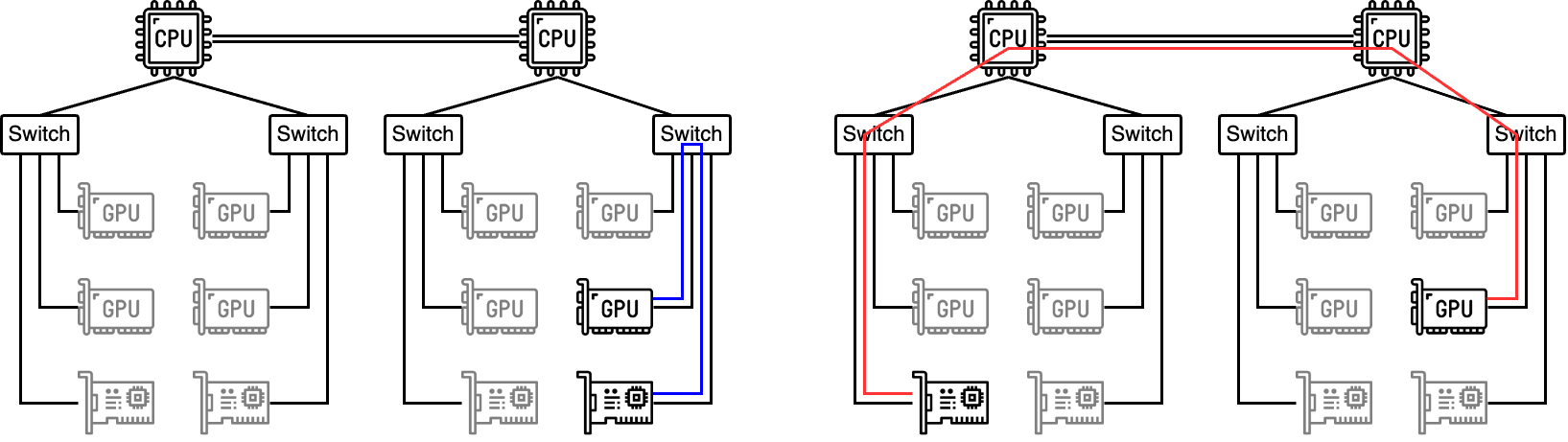
左:GPUとNICが最短経路で通信できる場合、右:GPUとNICの通信が遠回りになる場合
遠回りをする場合には最短経路を通る場合より、ホップ数が増えたり、細いバスを通るためRDMAの性能が悪化します。今回のインターンシップで実際にRDMAの通信速度を計測したところ、左図の場合だと帯域幅が10.5GB/s、右図の場合だと3.5 GB/sという結果が得られました。そのため、左図のように最短経路で通信できるようにNICとGPUを選択する必要があります。
インターンシップで取り組んだ課題
清水さんのブログで紹介されているようにPFNのKubernetesクラスタでは内製のCNI Pluginを使っています。このブログの中では、過去のCNI Pluginの移行の時にできなかったこととして、内製のCNI Pluginをオープンソースで開発されているSR-IOV CNI Pluginに置き換えることが触れられています。今回のインターンシップでは、内製のCNI PluginをSR-IOV CNI Pluginに置き換えた上で、RDMAの通信性能を向上させる方法を検討しました。
SR-IOV CNI Pluginを導入するときにはSR-IOV Network Device Plugin for Kubernetes(以下、SR-IOV Device Plugin)もあわせて導入するのが一般的です。SR-IOV Device Pluginを導入することでノード上のNIC(正確に言うとSR-IOVで仮想化されたVF: Virtual Function)をKubernetesのリソースとして扱えるようになります。例えば、NVIDIA V100を搭載したノードには物理的に4枚のNIC(SR-IOVでいうPF: Physical Function)があり、それぞれのNICから4つの仮想的なNIC (VF)が作られており、mellanox.com/sriov_rdma: 16 のような形でリソースが見えるようになります。RDMAを使いたいPodはこのリソースを要求することになるのですが、この時にできるだけRDMAの通信性能が良くなるGPUとNICの組み合わせを選択できるようにするにはどのようにしたらよいのかという課題に取り組みました。
GetPreferredAllocation APIによる課題の解決
RDMAを行うPodのNICを選択するときには、上の図のようにGPUとPCIeのトポロジのレベルでなるべく近いNICを選ぶのがRDMAの通信性能を向上させるためには望ましいです。
しかしながら、現状のKubernetesの仕組みではこれを実現するのは思ったよりも単純ではありません。KubernetesでPodに割り当てるNICやGPUといったデバイスを選択し決定しているのはkubeletです。kubeletがデバイスを選択する時に使うことのできるトポロジの情報は、device pluginによってkubeletに広告されるNUMAレベルの情報です。NUMAレベルのトポロジ情報はPCIeレベルでのトポロジ情報よりも粗いため、NUMAレベルのトポロジ情報では最適なトポロジは得られません。
例えばNUMAレベルのトポロジ情報では、上の図でいうと右側のCPUに接続されたデバイスと左側のCPUに接続されたデバイスは区別できますが、同じCPUの右側のSwitchに接続されたデバイスと左側のSwitchに接続されたデバイスの区別ができません。そのためRDMAの通信性能の観点では、今回求めている使用するGPUと同一のPCIeスイッチの配下に接続されたNICを選択するのが難しくなっています。
今回のインターンシップでは、PCIeレベルのトポロジを利用可能にする直接的な方法ではなく、device pluginでオプショナルなAPIとして定義されているGetPreferredAllocation APIを使うことによってRDMAの通信性能の観点で望ましいGPUとNICの組み合わせを実現するアプローチを取りました。GetPreferredAllocation APIはkubeletがPodに割り当てるデバイスを決定するときに、NUMAのトポロジ情報以外の追加の情報として、device pluginがなるべく選択して欲しいデバイスの推薦リストを返す機能です。
しかし、GetPreferredAllocationはSR-IOV Device Pluginでは実装が行われていないAPIだったので、このAPIを実装するPull Requestを作成しました。さらに、Pull Requestに含まれているGetPreferredAllocationの実装に加えて、全てのNICを推薦リストとして返すGetPreferredAllocationの実装も行いました。SR-IOV Device Pluginが全てのNICを推薦リストとして返すと、kubeletは全てのNICをPodに割り当てるようになります(正確には、異なるPFに属するVFを1つずつ選ぶことで、1つのPFにVFが偏らないようにしています)。この場合、必ずPodに割り当てられたGPUが接続されたPCIeスイッチと接続されたNICが存在することが保障されます。全てのNICを割り当てると、GPUが接続されているPCIeスイッチと異なる、RDMA通信に使用してほしくないNICも割り当てられることになりますが、RDMA通信ライブラリであるNCCLはGPUと同一のPCIeスイッチに接続されたNICを優先的に使うため、実用上は問題にはなりません。
このようにしてSR-IOV Device PluginにGetPreferredAllocationを実装し、全てのNICが選択されるようにすることでRDMAの通信性能の観点で望ましいGPU-NICの組み合わせを実現できました。また、SR-IOV CNI PluginとSR-IOV Device Pluginを導入することによる副次的な効果として、スケジューラが利用可能なNICの数を認識出来るようになるため、内製CNI Pluginにおいて発生していた利用可能なNICが存在しないノードにPodがスケジュールされCNI Pluginの実行が失敗することによってPodの起動が失敗する問題が解決しました。
まとめ・謝辞
本インターンシップでは、GPU-NIC割り当てを改善することでRDMA速度の高速化を行いました。また、内製のCNI Pluginをオープンソースで開発されているSR-IOV CNI Pluginに移行することで、メンテナンスコストも削減できます。さらにSR-IOV Device Pluginを導入することで、NIC障害などの理由でノードのNICが不足した場合にPodが起動しなくなる問題を解決することもできました。
本インターンシップでは、約1か月半の間に関連技術の調査からコンポーネントの設計、実装などを行いました。その間大変なこともありましたが、メンターの清水さんやサブメンターの上野さんのアドバイスが非常に助けとなりました。ありがとうございました。Cluster Service チームの皆さんからも貴重なコメントをいくつもいただきました。インターン期間中に関わった全ての方に深く感謝を申し上げます。
使用素材
Area
