Blog
本記事は,2022年度PFN夏季インターンシップで勤務された前川隼輝さんによる寄稿です。
はじめに
2022年度夏季インターンに参加させていただいた、名古屋工業大学学部3年の前川隼輝です。今回のインターンでは、NumPy ライクなライブラリである JAX から MN-Core を利用するためのコンパイラ及び周辺ライブラリの開発に取り組みました。
背景
PFNの多くの研究開発では深層学習フレームワークとして PyTorch を利用しています。PyTorch からは CPU や GPU を直接利用することができますが、PFN で開発されているプロセッサである MN-Core を利用する場合は、一度モデルを ONNX 形式として変換する必要があります。最終的に、変換された ONNX は MN-Core 向けコンパイラによりコンパイルされ、MN-Core 上で動作する形式へと変換されます。
ここで、MN-Core 向けコンパイラは入力として ONNX を受け取るため、ONNX に変換できるのであれば PyTorch 以外のライブラリを用いることもできるはずです。
今回のインターンでは、JAX を用いて書かれたプログラムが MN-Core 上で動作することを目標に開発を進めました。JAX とは、Google によって開発されている NumPy のようなライブラリであり、Autograd による自動微分と XLA による高い性能が特徴です。PFN社内にもその JAXの優れた特性を利用した研究開発を行っている方がおり、今後もJAXを使った開発が行われる可能性があるため、MN-Core 上で動作させる対象として選びました。
JAX の仕組み
JAX を用いて書かれたプログラムを MN-Core 上で動作させるためには、そのプログラムを ONNX に変換しなければなりません。そのためには、そもそも JAX は通常どのように CPU や GPU 上で動作しているのかについて知る必要があります。ここでは特に、JIT コンパイルにより XLA が利用されるケースについて簡単に解説します。
JAX で JIT コンパイルを利用する場合は、コンパイルしたい関数を jax.jit() 関数に渡します。例として、MNIST の学習を行うプログラムの一部を プログラム 1. として記載します。
jax.jit() に渡されたプログラムは、まず JAX の中間表現に変換されます。この中間表現は次に XLA の中間表現である XLA HLO に変換され、そしてプロセッサ固有のバックエンド(コードジェネレータ)へと渡されます。様々な中間表現を介しており複雑ですが、これらの表現の各段階でプログラムの変形や最適化が行われることが、高速な実行を可能としています。
プログラム 1. mnist_classifier.py から抜粋・改変
# MNIST Training def loss(params, batch): inputs, targets = batch preds = predict(params, inputs) return -jnp.mean(jnp.sum(preds * targets, axis=0)) init_random_params, predict = stax.serial( Dense(256), Relu, Dense(256), Relu, Dense(10), LogSoftmax ) batches = mnist_data_stream() opt_init, opt_update, get_params = optimizer.momentum(1e-3, 0.9) grad_loss = jit(grad(loss)) # JIT コンパイルを有効化 def update(i, opt_state, batch): grad_losses = grad_loss(get_params(opt_state), batch) return opt_update(i, grad_losses, opt_state) _, init_params = init_random_params(random.PRNGKey(0), (-1, 28 * 28)) opt_state = opt_init(init_params) for step in range(num_batches): opt_state = update(step, opt_state, next(batches))
JAX がどのような XLA HLO に変換されるのかは、Python 側から jax.xla_computation() 関数を呼ぶことで確認することができます。また、XLA HLO はプロセッサ固有のバックエンドへの入力であり、言い換えるとユーザ(Python 側)から確認できる中間表現のうち最も低レベルなものとなっています。
MN-Core 上で動かすために
インターン期間中は、前述した XLA HLO を ONNX に変換するライブラリを主に開発していました。加えて、ユーザが簡単に JAX から MN-Core を利用できるようにするため、jax.jit() 関数にほぼそのまま対応する mnjit() 関数とその周辺ライブラリも開発しました。これによりユーザは、(理想的には)単純に jax.jit() を mnjit() に置き換えるだけで MN-Core を利用できるようになります。
mnjit() は簡単に利用できる関数ですが、その実装は簡単ではありませんでした。インターン期間を通して様々な困難に直面しましたが、その中から2つを紹介します。
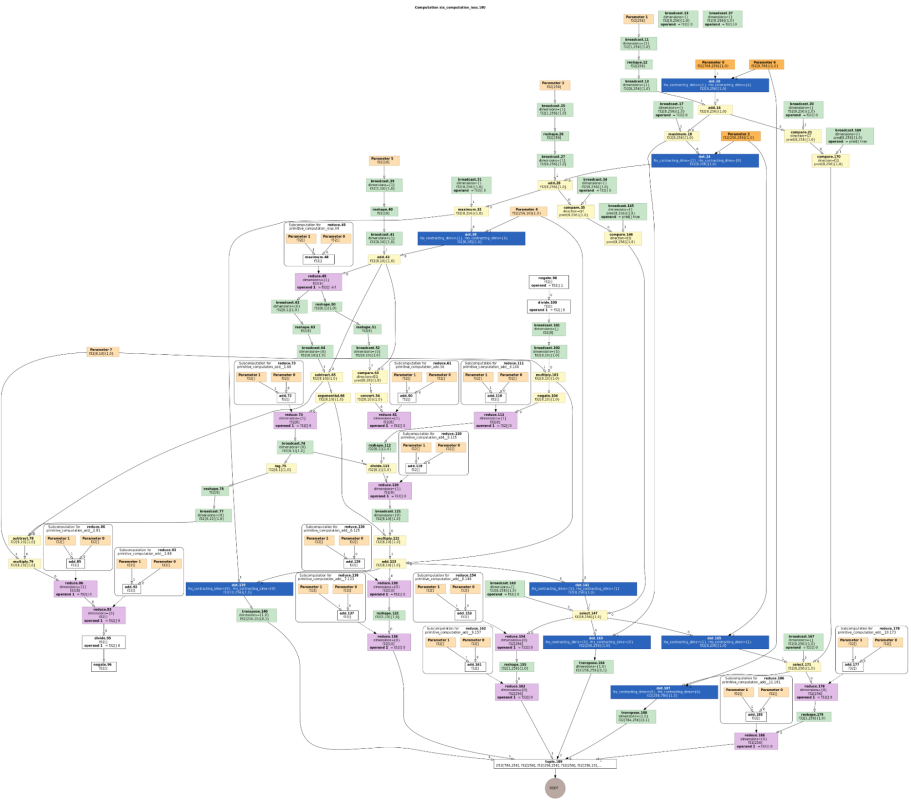
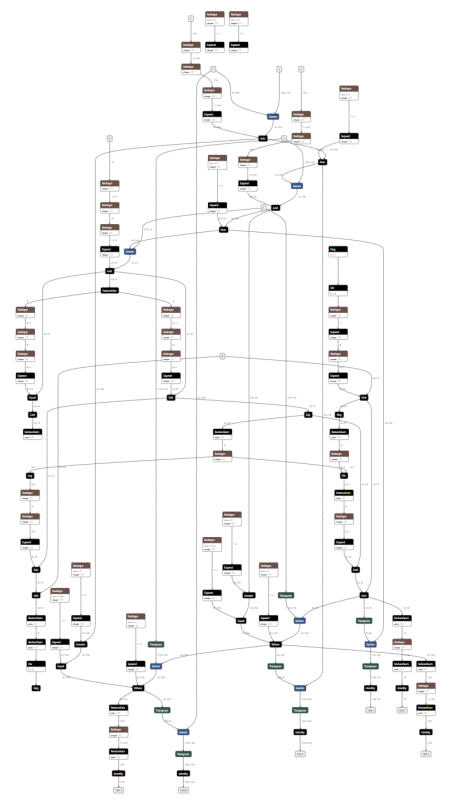
1つ目は、XLA HLO から ONNX に変換することの難しさです。XLA HLO の命令と ONNX の命令を比べると、一対一に対応するものと、そうでないものが存在します。そのため、XLA HLO のグラフに対して何らかのパターンマッチを行い、複数の命令を一つの ONNX の命令に変換しなければならない場合が存在します。その逆で、一つの命令が複数の命令に展開されることもあります。例として、MNIST の学習を行うプログラムで損失関数の勾配を計算している部分の XLA HLO(左) と変換後の ONNX(右)を以下に示します。
また、XLA HLO のセマンティクスはある程度ドキュメントにまとまっているものの、ところどころ説明が難解であったり、命令の挙動が複雑であったりと、その理解は時間のかかるものでした。
 |
 |
2つ目は、ONNX に変換できたとしても MN-Core 上で問題なく動作するとは限らないことです。MN-Core 向けコンパイラがコンパイルできる ONNX にはある程度の制約があるため、変換結果の ONNX が仮に CPU や GPU で動作したとしても、そのまま MN-Core 上で動作するわけではありません。まだ対応していない(MN-Core 上で動作しない) ONNX の命令を使ってはいけませんし、MN-Core 特有の問題が発生すればそれに対処する必要があります。
動作例
ここからは、JAX で書かれたプログラムのうち、実際に MN-Core 上での動作を確認したものを紹介します。動作確認のために選んだプログラムには、深層学習に加えて、JAX ベースのライブラリが多く存在するシミュレーション分野のプログラムも含まれます。JAX は JAX-CFD(数値流体力学)、JAX-MD(分子動力学法)、Brax(剛体物理シミュレーション) などのようにシミュレーションにもよく用いられており、このようなワークロードは今までに MN-Core 上で動作させた例があまりなかったため、シミュレーション分野のタスクにおけるMN-Coreの動作を知る良い機会となりました。
まず試したのは、有名なデータセットである MNIST の学習です。インターンの初期段階は、 MNIST の学習と学習済みモデルによる推論が MN-Core 上で動作することを目標に開発を進めていました。その結果、かなり早い段階で推論は動作し、学習も JAX の提供する Optimizer を用いて動作させることができました。jax.jit() の説明で用いたプログラム(MNIST の学習)の中で、jax.jit() の部分を mnjit() に置き換えるのみで MN-Core を利用できるため、ユーザの負担も最小限です。
深層学習ではないワークロードとしては、JAX-MD と JAX-CFD の公式サンプルプログラムからそれぞれ一つを選び、MN-Core 上で動作させました。単純に mnjit() を使うだけでは上手く動作させることができませんでしたが、どちらのサンプルに関しても十行程度の変更で MN-Core を利用することができました。(これらの変更は mnjit() の機能不足によるものです。)
JAX-MD については Minimization を選びました。用意されていたサンプルの中では最も基本的なもので、系のポテンシャルエネルギーを最小化するシミュレーションとなっています。実行すると、原子に対応する円が大量に表示され、だんだん規則正しい並び方へと揃っていく様子が確認できます。動作させたプログラムの一部を プログラム 2. として記載します。
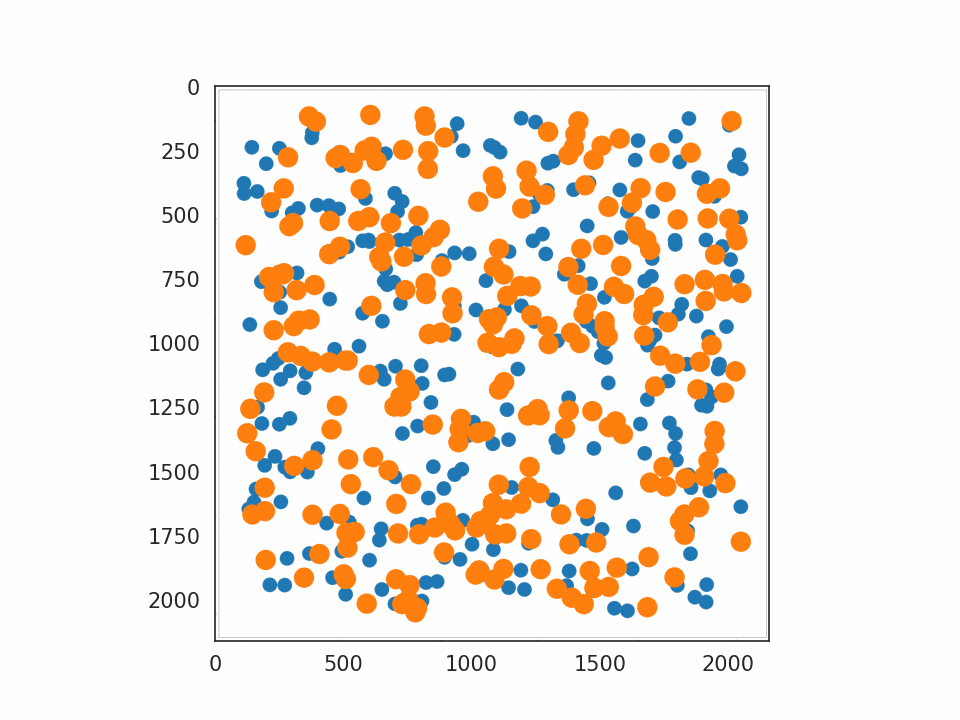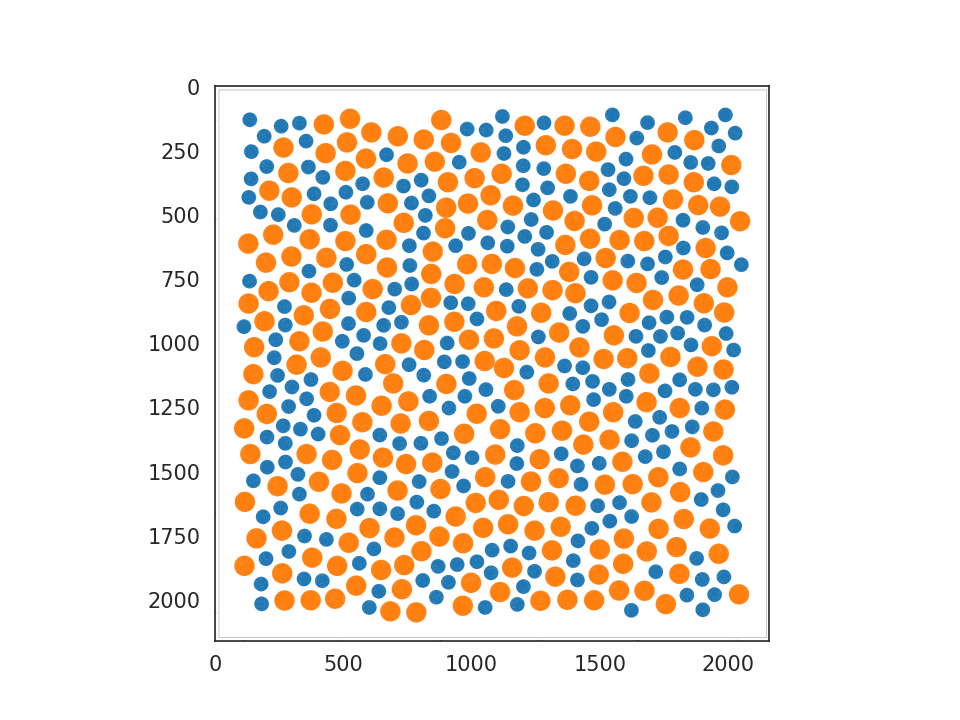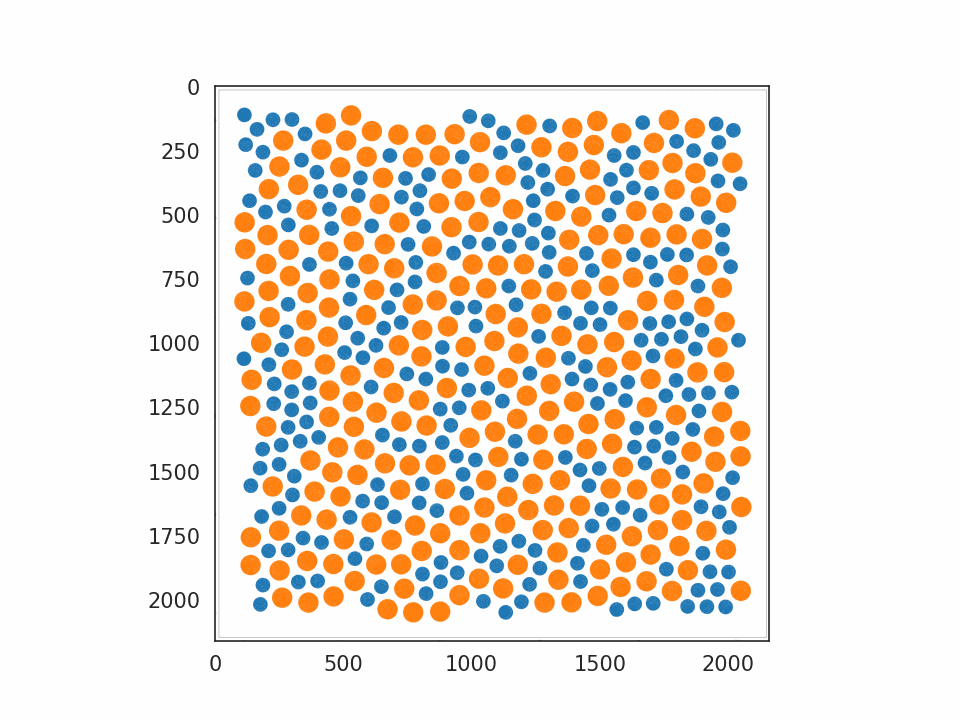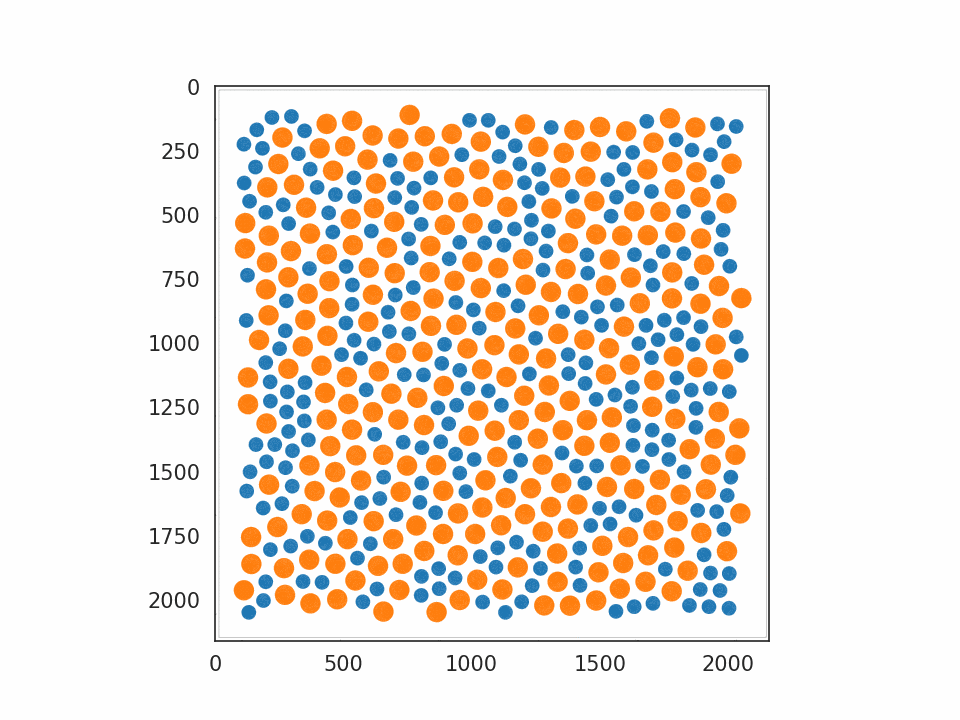
プログラム 2. Minimization から抜粋・改変
from jax_md import energy, minimize
energy_fn = energy.soft_sphere_pair(displacement)
_, fire_apply = minimize.fire_descent(energy_fn, shift)
# For CPU, GPU, Google TPU
fire_apply = jit(fire_apply)
# For MN-Core
fire_apply = mnjit(fire_apply, compile_options={ 'options': 'omitted' })
JAX-CFD については 2D simulation of channel flow を選びました。壁の間を横方向に流れる流体のシミュレーションであり、色が明るい部分は流れが速くなっています。
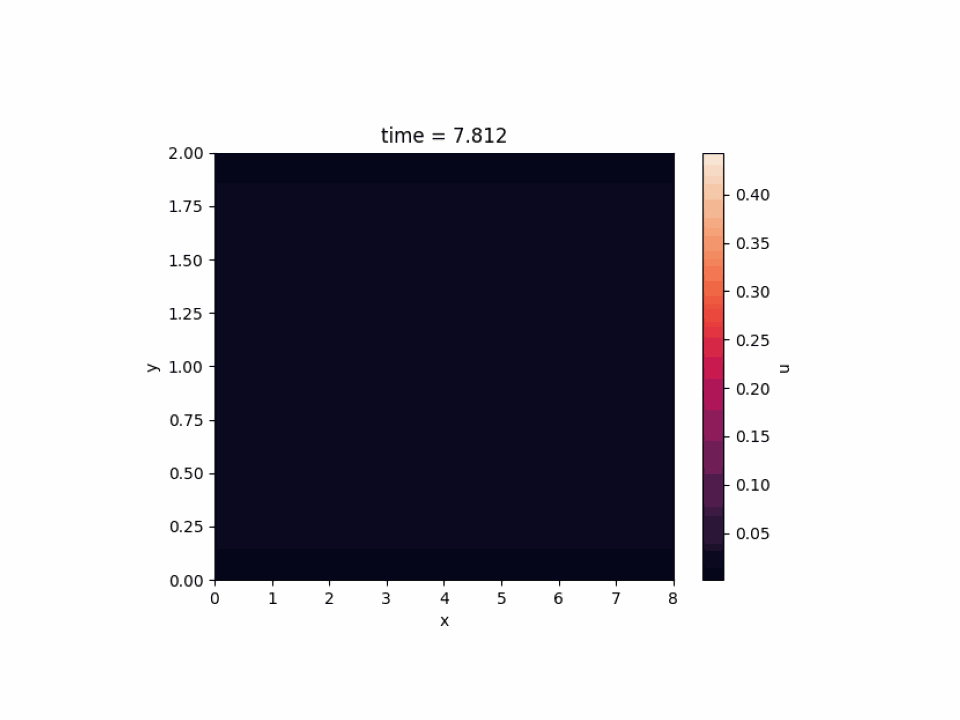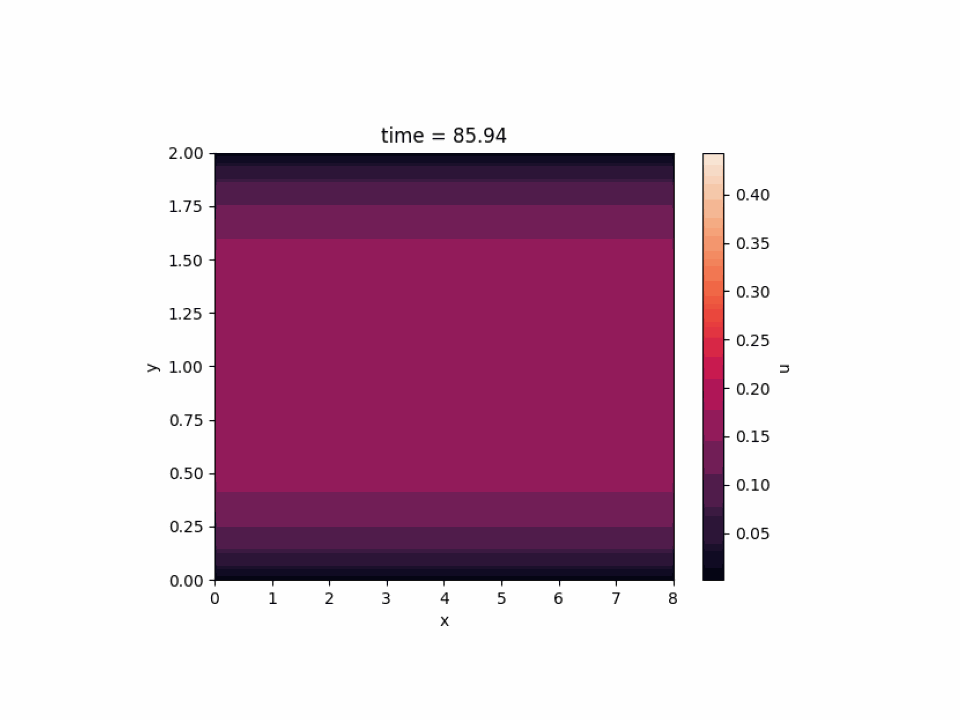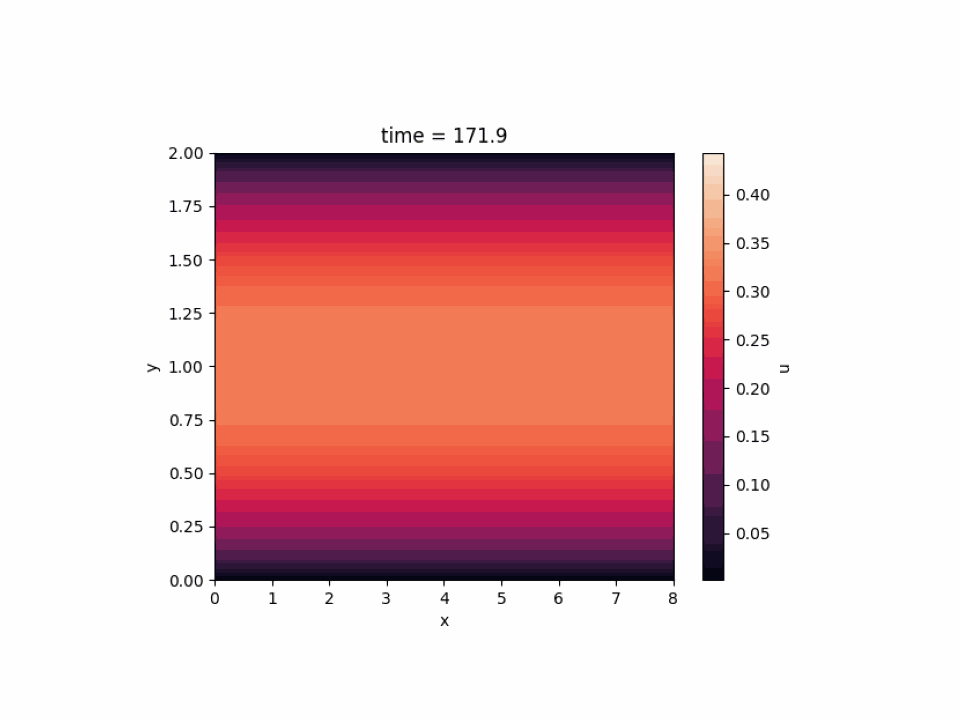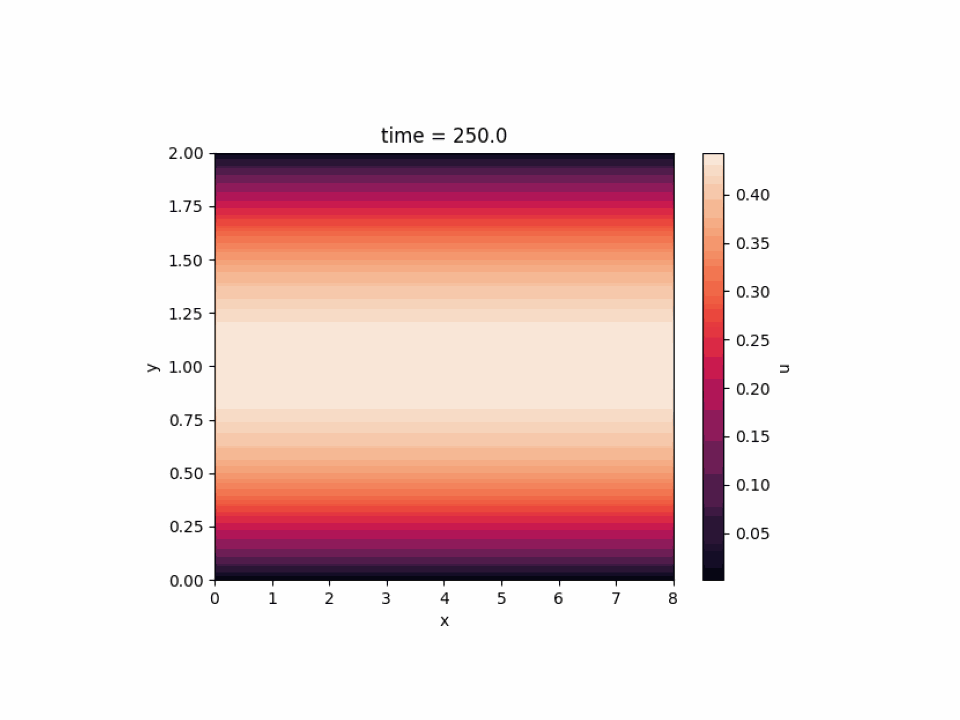
以上のように、深層学習はもちろんのこと、既存のライブラリを用いて深層学習以外のワークロードを MN-Core 上で動作させることができました。MN-Core の新しい使い方を模索できたのではないかと思います。
問題点
動作例を見ていただければわかるように、JAX から MN-Core を利用するという目標は達成することができました。しかし、これは MNIST や選んだシミュレーションの動作を目標に開発していたからであり、現状ではどのようなプログラムでも MN-Core で動作するというわけではありません。また、「動作する」とは言っても、MN-Core の性能を最大限に活かしているわけではないケースが多いです。ここでは、インターン期間中に解決できなかった問題を2つ紹介します。
1つ目は、XLA HLO が効率の悪い ONNX に変換されてしまう問題です。例えば、深層学習でよく用いられる Batch Normalization と呼ばれる操作は XLA HLO にも対応する命令がありますが、必ずしも JAX がその命令を使うわけではなく1、JAX の中間表現の時点で加算や除算などで構成されたグラフに変換されてしまうため、それらをまとめて ONNX の BatchNormalization 命令へと変換することは困難です。パターンマッチを行えば一応可能ではありますが、Batch Normalization に対応するグラフの表現は無数にありますし、JAX のバージョンの違いによってもグラフの形は容易に変化します。これらの理由から、現状の実装では効率の良い ONNX に変換することを諦めています。将来的に、何かしらのアノテーションをユーザに要求することで、高度な変換が可能になる可能性はあります。
2つ目は、mnjit() の使いやすさの問題です。理想的には jax.jit() を mnjit() に置き換えるだけで MN-Core を利用できるようになるのが望ましいですが、これは簡単なことではありません。理想的な mnjit() の実装が難しい理由は複数ありますが、主な理由としては JAX の JIT コンパイル周りの仕組みが複雑であることが挙げられます。JIT コンパイルしたプログラムを効率的に扱う仕組み(JAX Tracer object など)が JAX には実装されているのですが、これを JAX の外側から扱うことがインターン期間中には実現できませんでした。そのため、プログラム中で JAX の組み込み関数のうち特定のものを使ってしまうと、上手く ONNX に変換できなかったり、JAX との連携ができなくなりエラーとなってしまうケースがありました。
また、MN-Core との間でデータを受け渡しするためには jax.numpy.array と torch.tensor を相互に変換する必要があるのですが、この変換が遅く、全体の性能が悪化するという問題もありました。幸いなことに、この問題に関してはインターンの終盤に解決の糸口を教えていただきました。
まとめ・謝辞
今回のインターンでは、JAX で書かれたプログラムを実際に MN-Core 上で動作させ、加えてユーザにとって扱いやすいライブラリを開発しました。これにより、JAX から MN-Core を利用できるようになり、深層学習以外のワークロードを比較的容易に MN-Core 上で試せるようになりました。
5週間という短い期間でしたが、メンター・副メンターの河田さん・西川さん、コンパイラチームの皆さんには本当にお世話になりました。PFVM や MN-Core コンパイラの素早い修正のおかげで、インターン期間中に何度も試行錯誤を繰り返すことができました。この場を借りて御礼申し上げます。
- ^「Batch Normalization と呼ばれる操作は、XLA HLO にはそのまま対応する命令がありません。」となっていましたがこれは誤りでした。2022/09/30に修正しました。



