Blog
2023年5月から8月にかけて、Kaggleコンペ Google Research – Identify Contrails to Reduce Global Warming が開催され、Preferred Networksのメンバー3名: 阿部(@knshnb)、山川(@Yiemon773)、山口(@charmq)からなるチームPreferred Contrailが3位入賞を果たしました。
本コンペでは1,2,3位が飛び抜けたスコアを出していました。後述するように、1位のチームは正解ラベルのずれの問題に気づき、適切に対処することでスコアを大きく伸ばしていました。また、我々も提出によっては2位相当のスコアを出すこともできていたため、ラベルの問題に気づかなかったチームの中ではトップレベルの解法を出すことができたと言えます。
解法はKaggle Discussion上に投稿(リンク)しており、本記事ではコンペの概要と解法の重要だった部分について解説します。
コンペ概要
本コンペのタスクは、与えられた衛星画像に対して飛行機雲のセマンティックセグメンテーションを行うことでした。飛行機雲は地球温暖化に寄与していることが明らかになってきており、飛行機雲検出を自動化することで航空業界の飛行機雲生成回避に貢献するのが本コンペの開催目的です。評価指標はDice係数と呼ばれる、セグメンテーションのタスクで一般的に使われる指標の1つでした。
訓練・テストラベルは人間によってアノテーションされたもので、衛星データとともに、それをアノテータが見るためのash color schemeに変換する方法も与えられ、多くの参加者がそれによって変換された画像を用いていました。また、飛行機雲検出を行いたい時刻のデータの他に、その前後の時刻のデータもラベル無しで与えられることも特徴的でした。
基本的な解法
対象の時刻の画像を入力とし、飛行機雲のセグメンテーションマスクを予測するニューラルネットワークのモデルを訓練するアプローチがベースラインとなりました。以下このアプローチを2Dと呼びます。モデルはU-Netと呼ばれる、2015年に提案されてからいまだに広く使われているエンコーダ・デコーダ形式のアーキテクチャが広く用いられていました。我々もU-Netを採用し、実装にはsegmentation_models.pytorchというライブラリを用いました。このライブラリでは、エンコーダにPyTorch Image Modelsというライブラリの様々な事前学習済みの画像モデルを用いることができます。
やや不思議ですが、セグメンテーションのタスクでは画像の解像度を拡大してからモデルに入力することで精度が向上することがあることが知られています。このコンペでも、与えられるデータの解像度は256×256ですが、拡大してから入力することでスコアが向上することが報告されていました。我々も、512×512に拡大した画像をメインで使用しました。
ピクセルずれについて
本コンペでは、学習の際に回転・反転のdata augmentationを入れるとスコアが悪化することが報告されており、自分たちも気づいていたのですがデータの向きに対するバイアスだと思って特に深追いはしませんでした。ところが、いくつかのチームはこの原因を調査し、ラベルが0.5ピクセル右下にずれていることを発見していました。ポリゴンデータをマスクに変換する前処理の際にこの問題が生じてしまったと推測されています(リンク)。特に、今回は飛行機雲という細長い形状のラベルを予測するタスクであったことから、0.5ピクセルであっても回転によってずれる方向が変わることは精度に大きな影響を与えていたようです。1位・5位・9位のチームはこの問題に適切に対処することで、data augmentationを効果的に機能させモデルの汎化性能を高めることに成功していました。
2.5D U-Net
前後フレームのデータが与えられており、その情報をうまく活用することもこのコンペにおける重要なポイントでした。3Dの入力に対するセグメンテーションを行う場合、最も自然なのはエンコーダとして3D用のモデルを用いることです。我々も3D ResNetを用いてこのアプローチも試しましたが、2Dを超える精度を出すことはできませんでした。この原因としては、今回のタスクはフレーム数が8と少ないこと、フレーム間の時間間隔が比較的長いこと、3Dモデルのメモリ使用量が大きく試行錯誤を繰り返すハードルが高かったことなどが考えられます。
3D画像に対するもう1つのアプローチとして、2.5Dと呼ばれる手法があります。これは、2Dの画像モデルに各フレームの画像を独立に入力し、それらの中間表現を組み合わせて予測を行う手法です。これは3Dモデルの手法に対し、計算量が大きくなりすぎない・3Dよりも研究が活発に行われている2Dのモデルを効果的に活用できるなどのメリットがあります。今回は、U-Netのアーキテクチャにおいて2.5Dの手法を組み込み、2Dでは得られない情報を活用することで精度を大きく上げることに成功しました。
今回我々が設計したアーキテクチャは図のようになります。U-NetのEncoderに対し複数フレームの画像を2.5Dのアプローチで入力し、Decoderに入力する前に中間層で3D Convによりフレーム間の情報を混合・圧縮しています。3D Convの部分では、フレーム数の次元3を、フレーム方向のカーネルサイズが2でパディングが0の3D Conv層を2つ積むことで1まで圧縮しました。
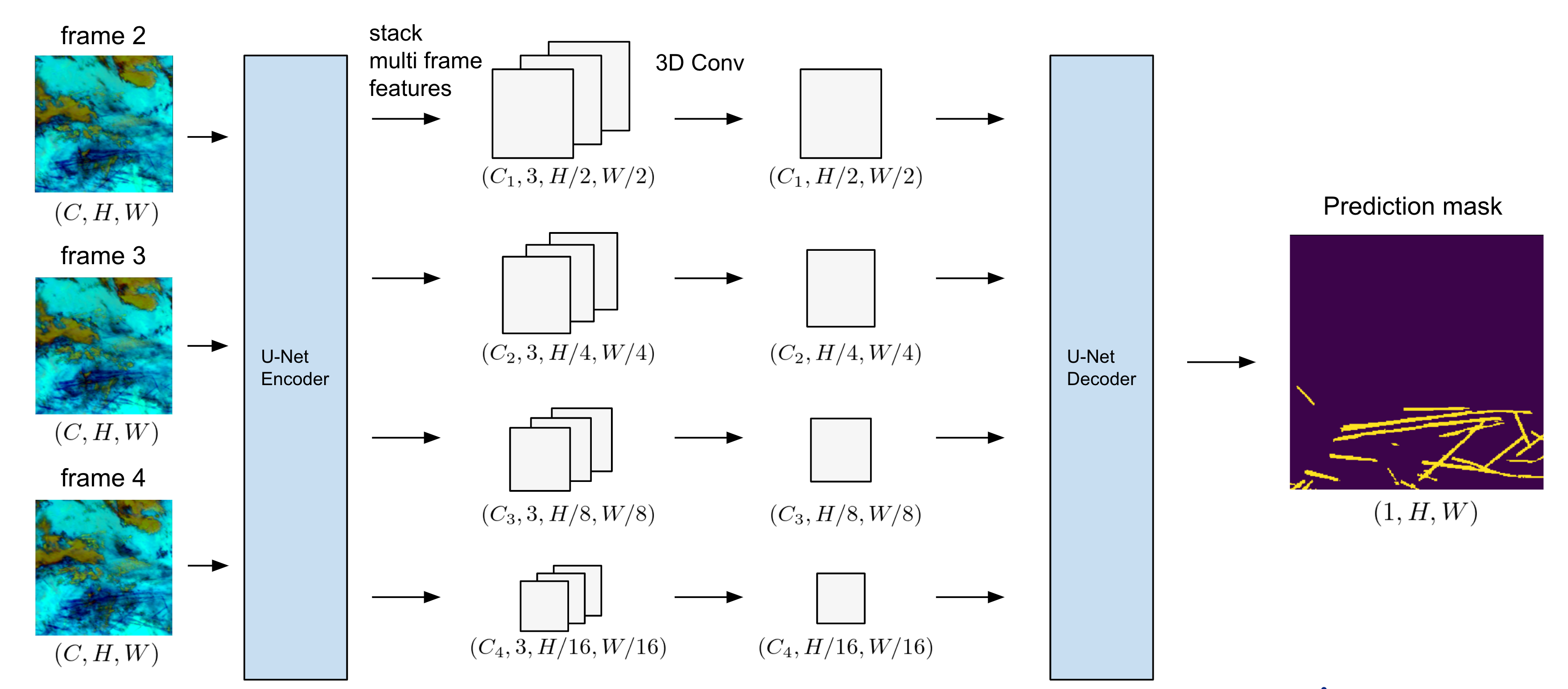
結果的にはシンプルなアーキテクチャですが、レイヤー数やカーネルサイズ、バッチ正規化の有無などによって精度が変わり、小さい画像サイズ・モデルでのたくさんの試行錯誤が重要でした。また、適切なアーキテクチャはパイプラインにも依存し、自分のパイプラインで調整したこのアーキテクチャをチームメンバーにそのまま使ってもらってもそこまで精度が上がらないといったことも起きました。今回複数フレームの使用でスコア向上に成功したチームがあまり多くなかったことは、このあたりの繊細さ原因かもしれません。
ソースコードも公開しているので、より詳細が気になる方は該当部分をご覧ください。
感想
阿部
今回のコンペは優勝を狙っており、また実際に締め切り2日前に順位表で1位に登ることができたので、最終的な結果については非常に悔しく思います。1位の方がデータの不可解な点をしっかり確認して原因究明・対応を行い、しっかり優勝まで持って行っていたのは非常に参考になりました。また、画像セグメンテーションのタスクを扱うのは初めてだったので勉強になりました。計算資源の使用を許可してくださった会社に感謝します。
山川
データの特性の把握、それを踏まえた上での地道なアーキテクチャの模索とパラメータの試行錯誤という基本的なことの大切さを改めて胸に刻むことになったコンペでした。セグメンテーションタスクは初めてでしたが、上記のような基礎動作の重要性はタスクによらないと感じます。
山口
今回のコンペのデータは同一地点で時間のみが異なる画像が複数フレーム存在していたりラベルの与えられ方が特殊であったり、工夫のしどころがたくさんあり楽しく取り組むことができました。非常に惜しい順位に終わってしまいましたが、自分にとってセグメンテーションに本格的に取り組む初めての機会だったのでとても勉強になりました。引き続き様々なタイプのコンペに参加していこうと考えています。



