Blog

2020年8月から11月にかけてkaggle上で Lyft Motion Prediction for Autonomous Vehicles というコンペが開催されました。このコンペではagent(自動車、自転車、歩行者)の軌道を予測し、その正確さを競います。Preferred Networksのメンバー4人がチーム Bumping AIとして参加し、4位に入賞、金メダルを獲得しました。本記事ではこのコンペの概要と我々のソリューションについて紹介します。
以下にコード、Slideのまとめも公開しています。
- Code: https://github.com/pfnet-research/kaggle-lyft-motion-prediction-4th-place-solution
- Slide: https://www.slideshare.net/pfi/kaggle-lyft-motion-prediction-for-autonomous-vehicles-4th-place-solution
コンペの概要について
今回のコンペはスマートフォンアプリによる配車・乗り合いサービスを提供するアメリカ企業Lyft社によってkaggle上で開催されました。このコンペのゴールは自動運転におけるMotion Prediction、すなわち、自身の周りに存在する車たちの軌道を予測することです(図1)。Lyft社は去年にもkaggle上でコンペを開催しており、そのときのタスクはPerception、すなわち、周りの車を検知・認識する3D物体検知でした(図1左側)。
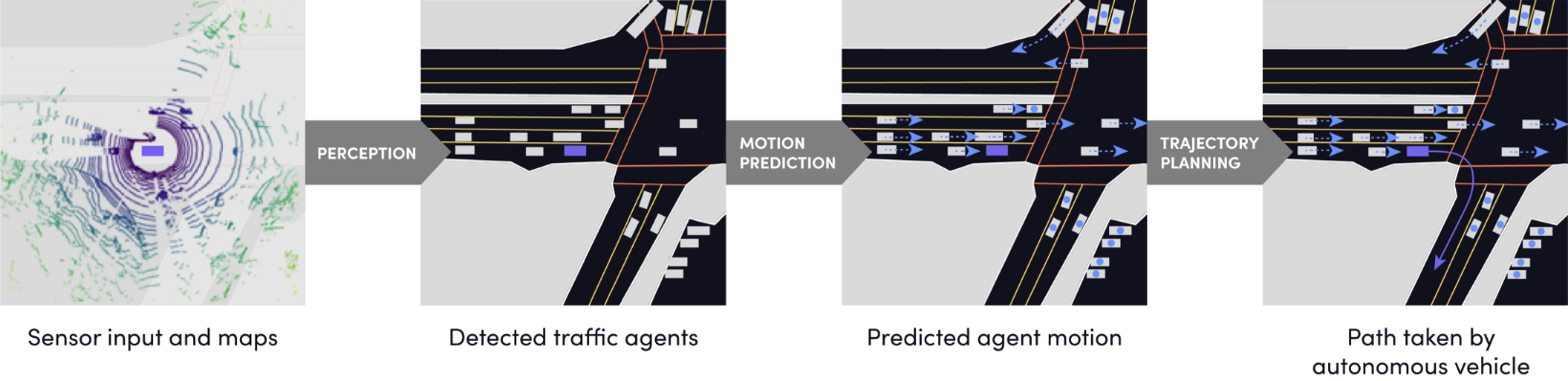
図1 自動運転システムの流れ (image from https://self-driving.lyft.com/level5/data/)
データの内容
利用可能な情報には以下のような種類がありました。
- 物体の種類のラベル(車, 歩行者等)
- 信号の状況
- 道路の状況(歩行者が横断している等)
- 緯度経度、タイムスタンプ
ただし、このコンペでは参加者がこれらの情報を画像に変換する処理を0から実装する必要はなく、Lyft社によって提供されているL5kitというライブラリのRasterizerを利用することで図2のような bird-eye-view 形式(上空から見た様子)の画像に変換することができました。
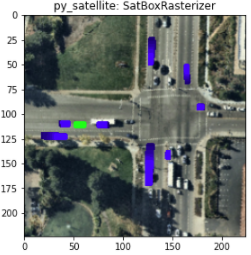
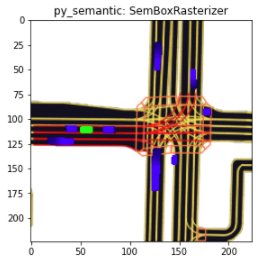
図2 L5kitのRasterizerによって描画された画像の一例。各画像について緑色のagentの軌道を予測するのが目標になる
データの大きさ
データはアメリカ、カリフォルニアにあるLyft本社とその近くの駅の間の道を往復することを繰り返すことで収集されています。訓練データにおける予測対象は約2億件オーダーと大量であったため、この量のデータを効率的に学習することが重要となりました。
- 全体の総時間、総距離: 1118時間、26344km
- データが取られた道の距離: 6.8マイル≒10.9km
- Train(89GB), Validation(11GB), Test(3GB)
- 約191M, 190K, 71K件のagentが予測対象
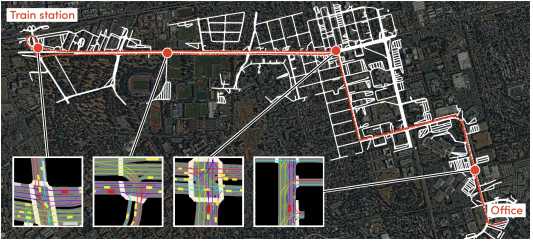
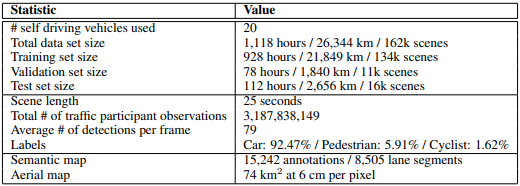
図3 データが収集された地域のマップとデータの総量(images from arXiv:2006.14480)
予測対象と評価指標
本コンペの目標は各agentとその周りの道路環境の過去の情報から着目しているagentの未来の軌道を予測することです。具体的には1フレーム0.1秒として、未来50フレーム分の(x,y)座標を予測するのですが、本コンペではさらに予測値としてconfidenceと共に3つまで軌道を出力することが許されていました。そのため、一つの予測につき50(フレーム数)×2(x,y座標)×3(軌道の数)+3(confidence)=303個の出力を持つことになります。また、入力する過去の総フレーム数は参加者が指定することができ、我々のチームは10フレーム分の情報を入力するモデルを作成しました。データによっては過去の情報が10フレーム分も存在しないということもありました。
次に、このコンペで使われた評価指標について説明します。前述の通り、1つのground truth(軌道)に対して3つの軌道とconfidenceを出力することができます。
- ground truth: $$x_1,\cdots,x_T,y_1\cdots,y_T\ (T=50)$$
- prediction: $$\bar{x}_1^k,\cdots,\bar{x}_T^k,\bar{y}_1^k,\cdots,\bar{y}_T^k,c^k\ (T=50,\ k=1,2,3)$$
ここで、ground truthは予測軌道を平均に持ち、単位行列を分散共分散行列に持つような正規分布をconfidenceを係数として混合したGaussian Mixture Model(GMM)からサンプリングされたものとしてモデル化すると、ground truthの軌道が得られる確率は次のように表現できます。
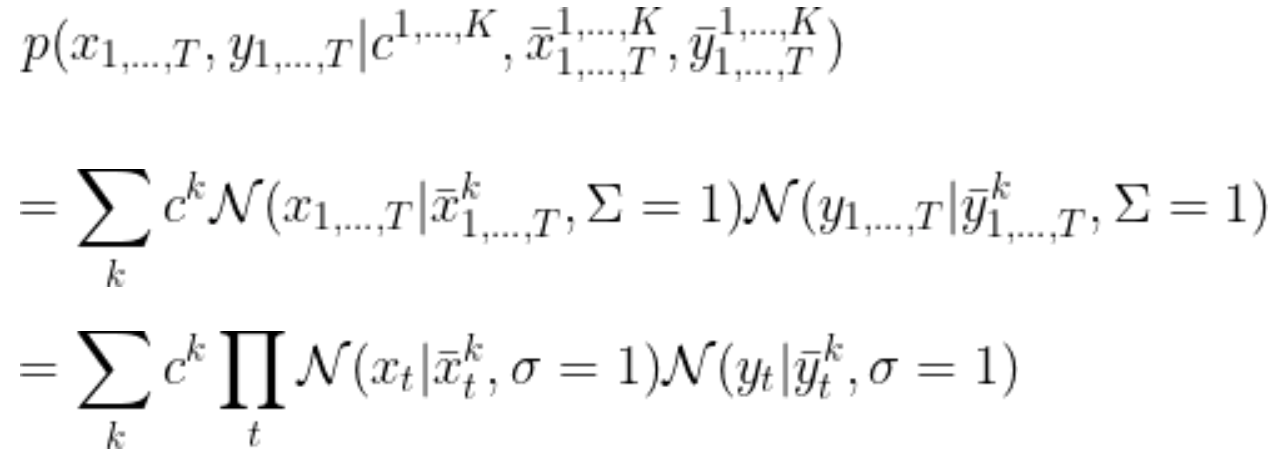
したがって対数尤度関数(の-1倍)は定数部分を無視することで次のように得られます。本コンペではこの対数尤度関数が評価指標として用いられ、leaderboardのスコアはこの式に基づいて計算されました。指数関数の肩には予測値とground truthの二乗誤差が乗ることになるので、予測値が正解と大きく離れているときは指数関数の部分が非常に小さな値を持つことになります。したがって、定性的には3つの予測軌道のうち最も正解に近い軌道によって評価指標の値が決まることになります。
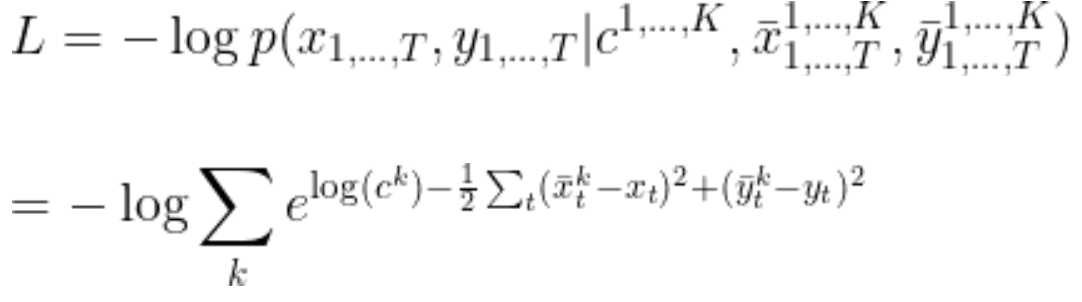
4th Place Solution
損失関数の設定
本コンペはconfidenceと共に3つの軌道を出力するという点で特徴的であり、そのような確率的な振る舞いをどのように予測するかが重要になりました。我々のチームでは評価指標を直接損失関数として設定して学習を行うことによりこれに対処しました。この手法はnotebook Lyft: Training with multi-mode confidence で公開しました。評価指標を直接最適化することで図4のように確率的な振る舞いを上手く表現できていることが分かります。
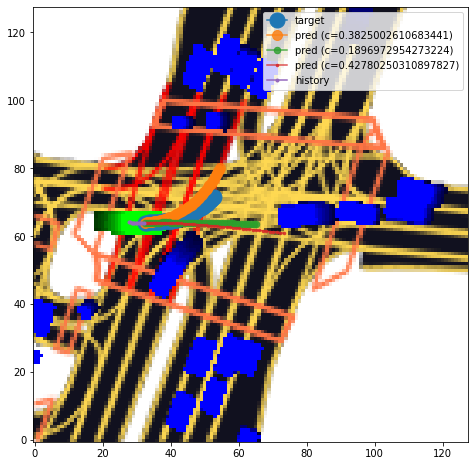
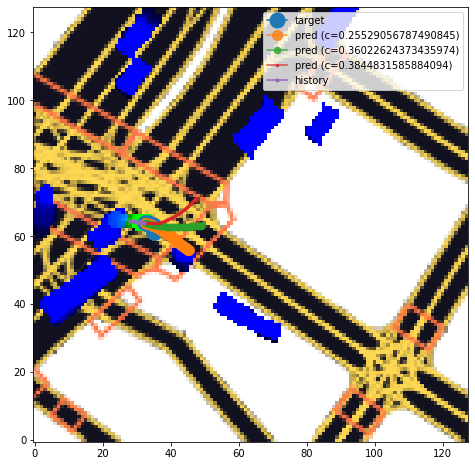
図4 評価指標を損失関数として直接最適化したときの予測の例、1つのモデルが3つの軌道およびconfidenceを同時に予測する。
学習データ
本コンペでは約2億件のAgentという大量の学習データがありましたが、これらをダウンサンプルせず全てを使ってモデルを訓練することでハイスコアを達成することができました。このような大量のデータを現実的な時間で訓練することを次のようなGPU並列によって実現しました。
- torch.distributedを利用
- NVIDIA Tesla V100 GPUを8台並列
- 5日間の学習で1epoch = 960GPU hours / epoch
また、L5kitに実装されているAgentDatasetクラスをそのまま利用すると多くのメモリを消費してしまうため、一部をファイルにキャッシュしておくことでメモリの削減をするなどの工夫を行いました。
Validation Strategy
testデータはchopped datasetという、各レコード間の時間的な重なりによるleakが起きない形式で与えられました。そこで、leaderboardのscoreと手元のvalidationデータのスコアの相関が取れるようにvalidationデータについてもtestデータと同様にchopped datasetに変換して利用しました。このvalidationデータを利用することにより、leaderboardのスコアとvalidationデータに対するスコアが非常に強い相関を持つようになり、信頼度の高いvalidationを行うことが可能となりました。
さらに、validation/testデータの中身を良く観察すると、どのレコードも最低でも10frame以上は未来のframe(future frame)を含み、過去のframe(history frame)を全く含まないものが存在することが分かりました。そこで、学習データにおいてもそのようなレコードのみを利用することにし、validation/testデータに寄せたデータセットで学習を行ました。これはAgentDatasetにおいてmin_frame_future=10,min_frame_history=0とすることで実現できました。この変更を行うとL5kitライブラリからwarningが出力されますが、実際にはスコア向上に大きく寄与し、Public LB:15.874→13.059となりました。
CNN Models
いくつかのアーキテクチャで学習を行ったところ、以下のアーキテクチャにおいて比較的良いスコアを得ることができました。
- ResNet18
- ResNet50
- SEResNeXt50
- ECAResNet18
ResNet18等の比較的小さなアーキテクチャでも良いスコアが出せている印象でした。最終的にはこれらのアーキテクチャをアンサンブルした結果を提出しました。逆に、以下のような比較的大きいアーキテクチャではあまり良いスコアを得ることができませんでした。
- ResNet101
- ResNet152
また、入力画像サイズについては(128,128)と(224,224)での学習をそれぞれ行ったところ(224,224)の方が少しだけ良いスコアが得られたため、最終的には(224,224)での学習を行いました。
学習率スケジューリング
学習率のスケジューリングとしてはexponential decayとcosine annealingの2つで実験を行ました。結果は図5のようになり、cosine annealingの方が良いスコアを得ることができ、Public LB:11.341と改善しました。
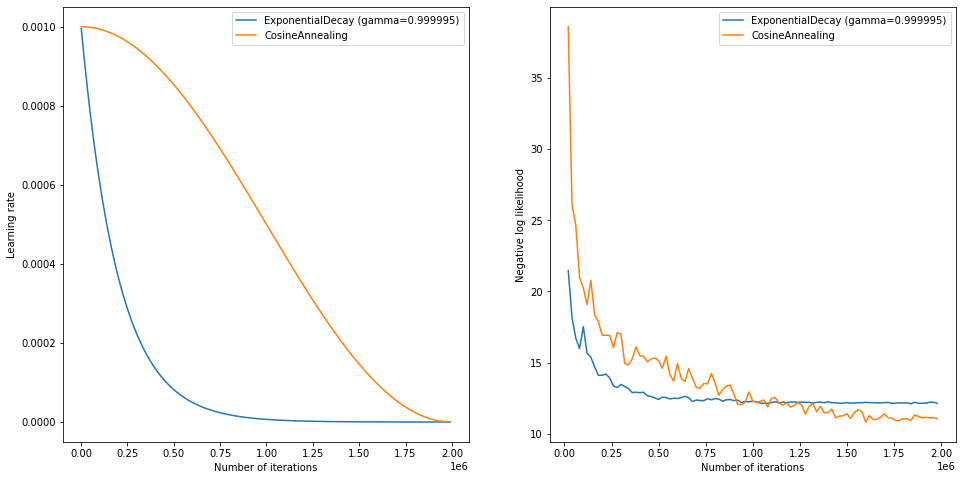
図5 exponential decayとcosine annealingの学習曲線の比較
Augmentation
本コンペにおける画像は自然画像ではなく、L5kitのRasterizerを用いて描画された画像であるため、使用できるaugmentationが限られていました。その中でもcutout, blur, downscaleなどのaugmentationを使った実験を行いました。最終的にはスコアの改善を確認できたcutoutのaugmentationのみを採用しました。
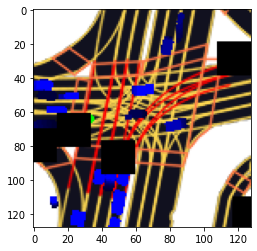
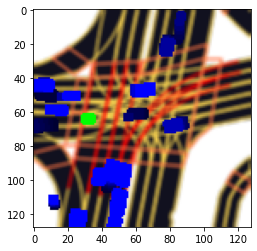
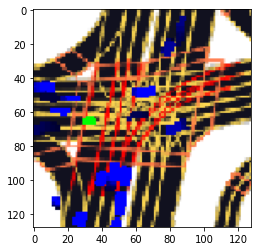
図6 cutout, blur, downscaleのaugmentationを施した入力画像
Best Single Model
ここまでで紹介した方法
- 評価指標を損失関数として直接最適化
- 学習データをダウンサンプルせず全て使って学習
- min_frame_future=10,min_frame_history=0と指定する
- cosine annealingによる学習率の制御
- cutoutによるaugmentation
の全てを合わせたResNet18での学習によりPublic LB:10.846というスコアになり、シングルモデルで賞金圏に入るスコアを達成することができました。また、学習は1 epochで十分でした。
Ensemble
本コンペではconfidenceと共に3つの軌道を出力するため、複数のモデルの出力を単純平均するといった古典的なアンサンブル手法を取ることができませんでした。そこで、我々のチームではGMMとEMアルゴリズムを用いたアンサンブル手法を考案し、さらなるスコア向上に成功しました。ここからはそのアンサンブル手法のアイディアについて説明していきます。
モデルの出力をGMMと同一視する
さて、本コンペにおいて評価指標を定義する際、ground truthを予測値から定義したGMMからのサンプルとしてモデル化したことを思い出します。このアイディアを参考にし、1つのモデルの出力を次のようなn_components=3のGMMと同一視します。
$$f({\bf x}) = \sum_{i=1}^3c_i{\mathcal N}({\bf x}|{\bf x_i},\sigma)$$
ただし、\(c_i\) はconfidenceで \(x_i\)は出力軌道とします。このように考えると、複数のモデルの出力に対応するGMM同士は次のように単純平均を取ることができます。
![]()
以下の手続きによってGMMの平均\(f^{\rm average}({\bf x})\)から複数のモデルをアンサンブルした結果\(f^{\rm ensemble}({\bf x})\)を抽出することができます。
- \(f^{\rm average}({\bf x})\)に従う確率分布から十分量の点をサンプリングする(例:モデルの数×1000)
- サンプルされた点に対してn_components=3としてEMアルゴリズムを実行(sklearn.mixture.GaussianMixtureを利用することができます)
- EMアルゴリズムの実行結果を\(f^{\rm ensemble}({\bf x})\)とする
上述のアンサンブル手法を2つのモデルに適用することで図7のようにlossが改善した例を確認することができました。下図ではmodel1, model2 ともに赤線のground truth にうまく重なる予測軌道はありませんが、Ensemble を行い2つのモデルの”平均的な軌道” を計算することで右側緑色の軌道のような ground truth にうまく重なる予測を生み出すことに成功しています。
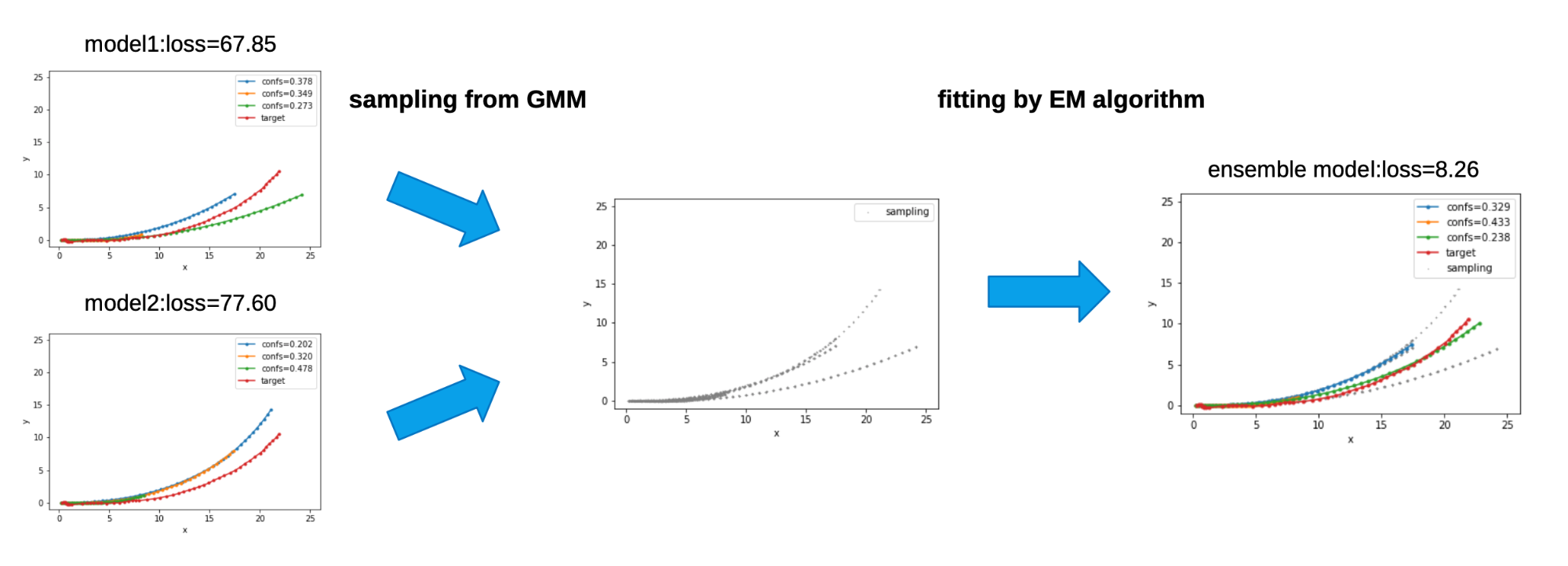
図7 アンサンブルによってlossが改善した例
最終提出
ここまでで説明した手法を用いて様々な実験を行い、最終的には9個のモデルをアンサンブルした結果を提出しました。結果としてPublic/Private LB:10.272/9.475というスコアを得ることができました。
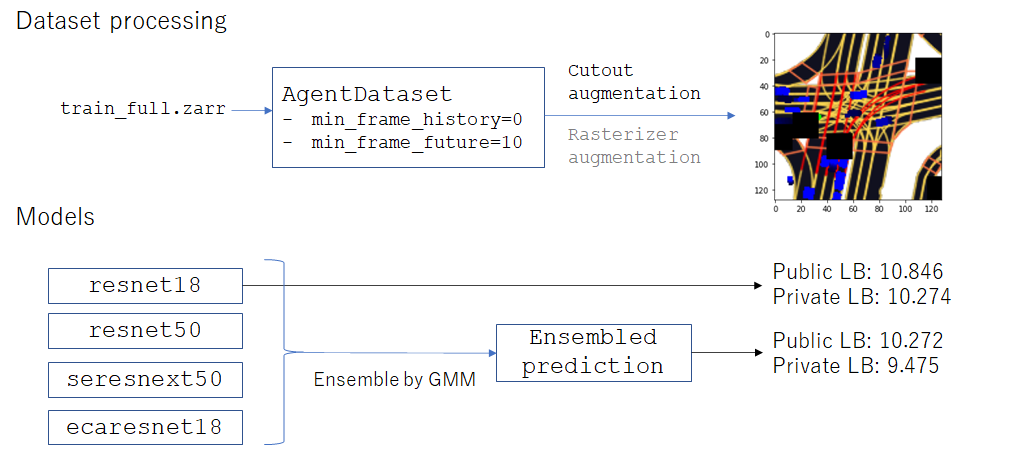
図8 最終提出の内容まとめ
Private LBでは4位という順位でフィニッシュすることができました。
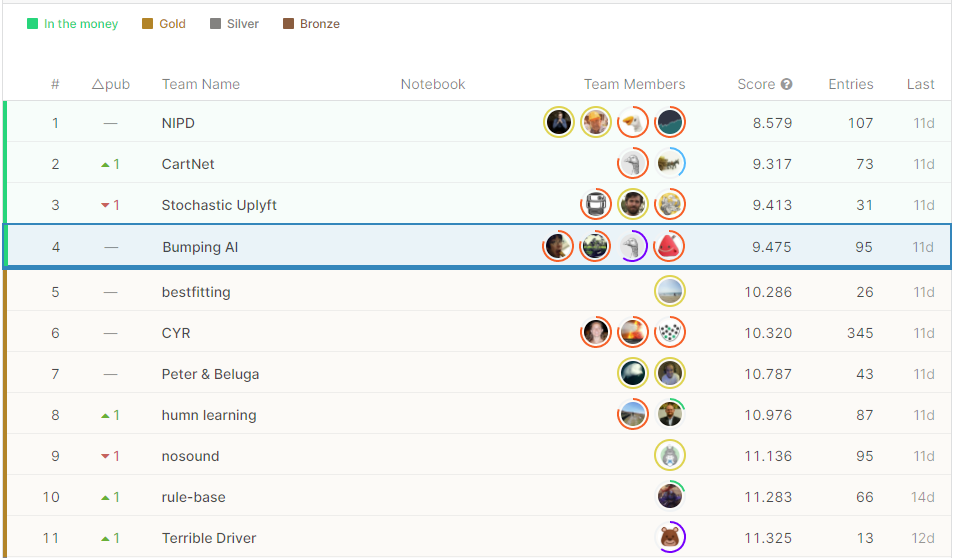
図9 最終的なPrivate LB
おわりに
ここまで、我々のチームの4位解法を紹介しました。最終的なPrivate LBを見ると1位のチームが2位以下のチームに対して大きく差をつけて優勝していることがわかります。1位の解法を見ると、学習の律速になっていた画像のrasterizeの高速化に取り組んでおり、画像サイズなどのハイパーパラメータも我々のチームと異なっていました。rasterizeの高速化により多くの実験を行うことで適切なハイパーパラメータを設定することが重要であったようです。また、我々のチームを含む解法を公開しているほとんどの上位チームがCNNを用いてモデルを作成していましたが、10位の解法ではVecorNetというGraph Neural Networkに基づいたモデルを使用していました。この解法では画像の代わりにベクトル 情報を入力するためrasterizeの必要がなく、非常に高速(GPU hours比で我々のチームのおよそ100倍高速)に学習ができたようです。実際の自動運転のアルゴリズムの中にこのコンペで取り組んだような軌道予測を組み込む際にはCNNよりも推論が速いVectorNetなどのモデルの方が好まれるかもしれません。
3ヶ月のコンペ期間中、我々のチームはかなり長い期間でPublic LB 1位を維持していましたが、コンペ終了間際の数日の間に他のチームに抜かされてしまい悔しい思いをしました。次回のkaggleコンペ参加の際にはより上位を目指していきたいと思います。
