Blog
はじめに
Preferred Networks (PFN) では Kubernetes を使った機械学習基盤を開発・運用しています。本記事では、この基盤においてコンテナイメージのプルを高速化し、ネットワーク転送量を削減するために開発したキャッシュシステム CIRC(サーク)を紹介します。この内容は、2025 年 6 月に日本で初開催された KubeCon + CloudNativeCon Japan 2025 で発表したセッション New Cache Hierarchy for Container Images and OCI Artifacts in Kubernetes Clusters using Containerd をブログ記事にしたものです。発表資料やセッションの録画はリンク先からご覧いただけます。
コンテナイメージのキャッシュシステムが必要な背景
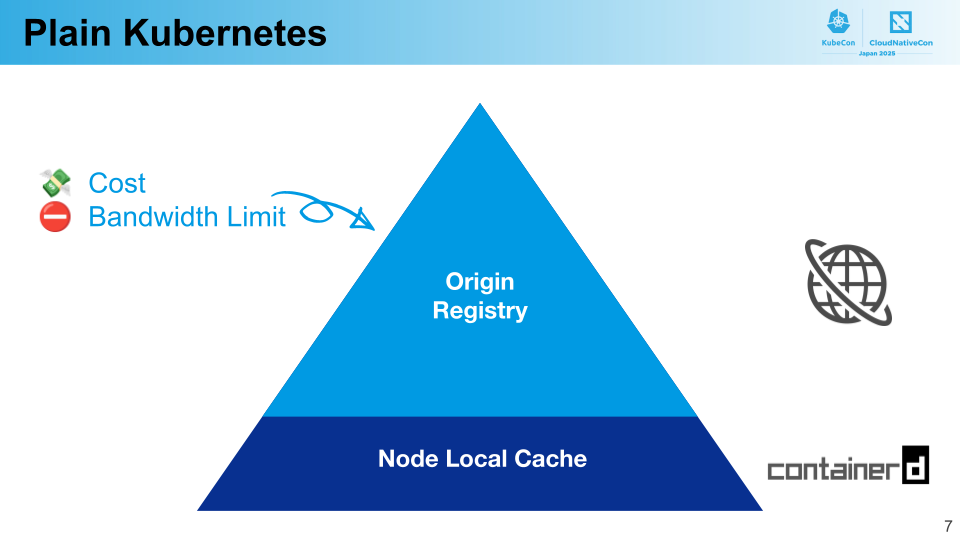
PFN の Kubernetes クラスタは主にオンプレミス環境で構築していますが、コンテナイメージを格納するレジストリはクラウド上のマネージドサービスを使っています。これは、ユーザアカウントの統合管理や、クラスタを含めた様々な環境との相互運用性を重視したためです。
クラスタとコンテナレジストリは離れた環境にあり、その間のネットワーク帯域は限られています。また、クラスタで使われるイメージは機械学習用のライブラリやアクセラレータ用のランタイムを含む大きなサイズのものが多く、圧縮した状態で 20 GB を超えるものもあります。
これらの背景から、以下の課題をかかえていました。
- クラスタからのイメージのプルに時間がかかる
- Pod がノードに割り当てられてからイメージのプルが始まるので、この時間を短縮することでクラスタのリソース使用効率を向上させることができます。
- コンテナイメージの転送によるネットワーク使用量が大きい
- とくに、レジストリからの転送 (egress) が従量課金制であるため、これを削減することが不可欠でした。
CIRC の概要
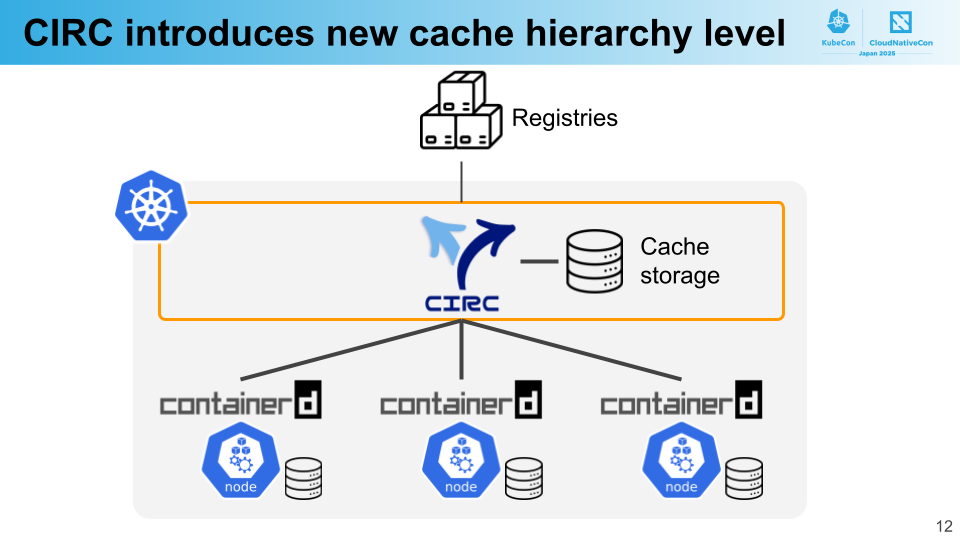
これらの課題を解決するために CIRC を開発しました。CIRC は前身となるソフトウェアを含めるとすでに 5 年以上、現在の形になってからは 2 年ほど運用を続けています。
CIRC はコンテナイメージのために新しいキャッシュ階層を導入します。この追加のキャッシュ階層はクラスタ全体で共有され、キャッシュされたイメージはすべてのノードからのプルで利用可能です。これによって、プレーンな Kubernetes でのノードごとのキャッシュのみの構成と比較して、キャッシュ効率が大きく向上します。
PFN のクラスタではコンテナランタイムに containerd を使っています。containerd がイメージをプルするとき、そのリクエストは CIRC に向かいます。イメージがすでにキャッシュされていれば、CIRC はそれを即座に返し、キャッシュされていなければもとの(オリジン)レジストリからイメージを取得してキャッシュに保存しつつ containerd に返します。
よって、キャッシュが揮発しない限り同じイメージはオリジンから一度だけ取得され、ほとんどのイメージのプルはクラスタ内の高速なネットワークで完結します。
キャッシュのストレージには、PFN で開発した分散キャッシュサービス SCS を使っています。SCS についてはリンク先の記事や KubeCon NA 2024 で紹介しているので、あわせてご覧ください。
- 深層学習のための分散キャッシュシステム – Preferred Networks Research & Development
- KubeCon + CloudNativeCon North America 2024: Distributed Cache Empowers AI/ML Workloads on Kubernetes Cluster – Yuichiro Ueno & Toru Komatsu, Preferred Networks, Inc.
CIRC は OCI Distribution Specicification というコンテナイメージの配布に関するプロトコルにしたがっています。このプロトコルは OCI (Open Container Initiative) によって定められている業界標準で、さまざまなレジストリやクライアントがこれを実装しています。CIRC もこの標準を実装しているので、幅広いオリジンレジストリや containerd の異なるバージョンに対する互換性をもっています。
CIRC の特徴
CIRC は次の 4 つの主要な特徴をもっています。 それぞれ詳しく紹介します。
透過性
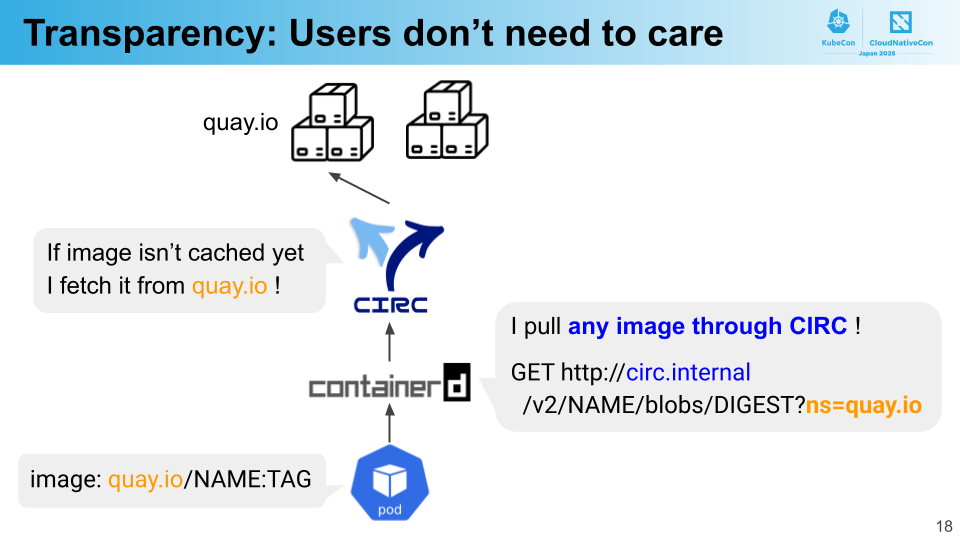
透過性は、ユーザがその存在を意識することなく CIRC の恩恵を受けられることを意味します。具体的には、ユーザによる Kubernetes マニフェストの変更は一切不要であり、Docker Hub や Quay.io などの任意のレジストリに対して CIRC がはたらきます。
これを実現するために、CIRC は containerd の Registry Configuration 機能 を活用しています。この機能では、オリジンレジストリへのイメージプルリクエストを別のサーバに向けることができます。任意のオリジンを対象とするよう設定できるので、すべてのリクエストを CIRC に向かわせることが可能です。
CIRC は containerd からリクエストを受け取ったあと、イメージがキャッシュされていない場合、オリジンから取得しなければなりません。オリジンがどれかをどう識別すればいいのでしょうか?CIRC に静的に設定することも考えられますが、これでは任意のレジストリには対応できません。
この問題は containerd の仕組みを使い解決できます。containerd の Registry Configuration 機能では、設定したサーバに HTTP リクエストを送る際、オリジンのドメインを ns クエリパラメータにセットします。例えば ns=quay.io という値になります。CIRC はこの ns クエリを読むことで、どのレジストリからイメージを取得すべきか識別できます。
このように containerd の機能を活用することで、CIRC の透過性を実現することができました。なお、ns クエリパラメータは OCI Distribution Specification に追加しようという議論が進行中で、containerd は先行して実装しています。仕様に入ることで他のコンテナランタイムでも実装されることが期待できそうです。
マルチテナンシ
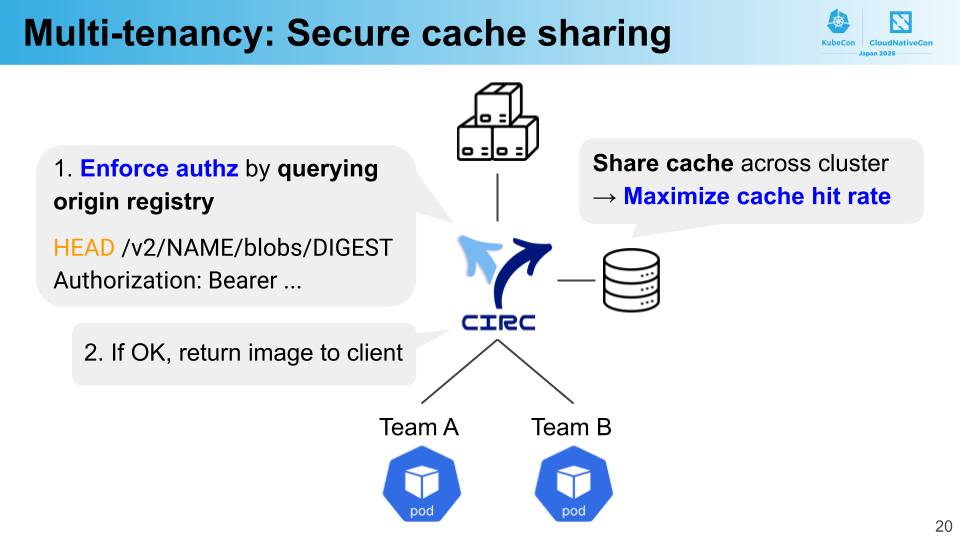
PFN では、さまざまなチームやプロジェクトでクラスタを共有して使っています。CIRC のキャッシュはクラスタ全体で共有されるので、マルチテナント環境ではキャッシュのセキュリティが重要になってきます。もしキャッシュを通して、異なるテナントの本来読む権限がないイメージを読めてしまうと深刻な問題です。
CIRC は認証・認可をおこなうことでセキュアなキャッシュ共有を実現します。CIRC はイメージプルリクエストを受けると、まずユーザがそのイメージを読む権限があるかどうかを検証します。具体的には、HTTP HEAD リクエストをオリジンレジストリに送信することで、権限をもっているかを問い合わせます。その後、許可されていればイメージを返し、そうでなければ 404 Not Found エラーを返します。このようにイメージに対する認証・認可をおこなうことで、CIRC はクラスタ全体でキャッシュを共有して効率を高めつつ、イメージに対するセキュリティを担保しています。
Preheating
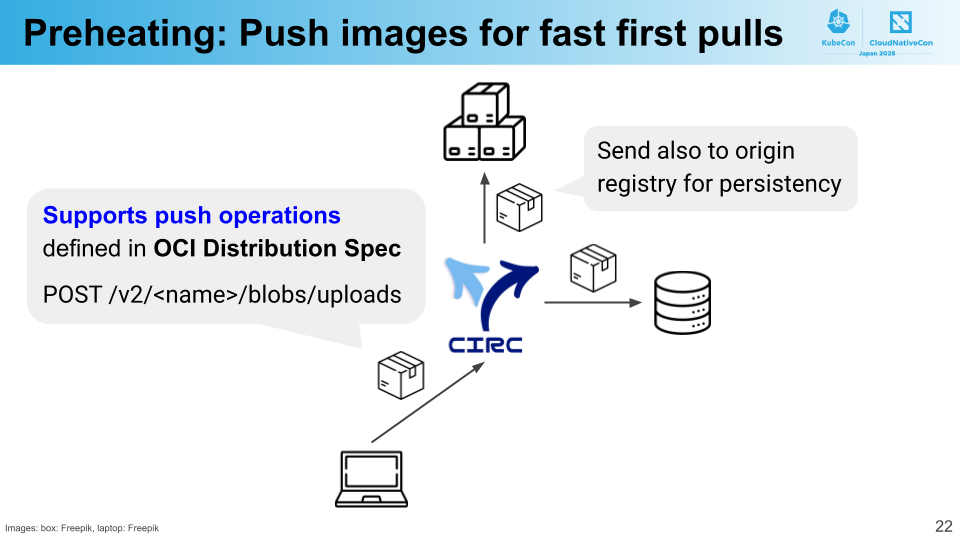
CIRC の導入によりイメージのプルは高速化されましたが、これはイメージがすでにキャッシュされている場合に限ります。新しいイメージを始めて使うときは、一度オリジンレジストリから取得することが必要です。しかし、この一度の取得までもなくせるとしたらどうでしょうか?最初のプルから CIRC により高速化できます。
Preheating(予熱)は、CIRC がイメージのプッシュ操作をサポートすることで、この最適化を実現する機能です。ユーザはイメージをビルドするとき、オリジンレジストリではなく CIRC に直接プッシュできます。CIRC は受け取ったイメージをキャッシュに保存しつつ、同時に永続性のためにオリジンにもアップロードします。イメージがすでにキャッシュに存在するようになるので、ユーザが後にそのイメージをプルするときは、最初のリクエストであっても CIRC から迅速に返すことができます。
イメージのプッシュ操作についても、CIRC は OCI Distribution Specicification にしたがっています。よって、広い範囲のクライアントからイメージをプッシュすることが可能です。
OCI アーティファクトとの互換性
Kubernetes やコンテナランタイムのコミュニティでは、pod が OCI アーティファクトをマウントできる OCI VolumeSource 機能が開発されています。
- VolumeSource: OCI Artifact and/or Image · Issue #4639 · kubernetes/enhancements
- Kubernetes 1.31: Read Only Volumes Based On OCI Artifacts (alpha) | Kubernetes
OCI アーティファクトは任意のコンテンツを OCI イメージの形式で保存したものであり、OCI VolumeSource 機能のユースケースには AI モデルの配布などが含まれています。とくに AI モデルでは数十 GB の巨大なアーティファクトになることがあり、大きい OCI アーティファクトを素早く取得できることが重要になってきます。
CIRC は OCI アーティファクトのプルにも対応しています。これは、CIRC が OCI Distribution Specification にしたがっており、OCI アーティファクトも通常の OCI イメージと同じ形式で保存されコンテナレジストリから配布されるためです。CIRC を利用することで、巨大な OCI アーティファクトも迅速にプルできることが期待できます。
運用上の課題と対策
CIRC を実際に運用していく中でいくつかの課題にあたりました。それらにどう対処したかを紹介します。
ブートストラップ問題
CIRC 自身も Kubernetes クラスタ上の Deployment として動作しているため、クラスタ全体のメンテナンスなどの理由で一時的に CIRC がはたらかない時間があります。このとき、CIRC を起動するために CIRC 自身のコンテナイメージが必要ですが、そのリクエストを受ける CIRC が存在しないというブートストラップ問題が発生します。幸い、containerd の Registry Configuration 機能ではリクエストの転送に失敗した場合、オリジンレジストリにフォールバックします。そのため、CIRC がはたらいていない時間もイメージのプルは進み、いずれ CIRC も起動してキャッシュが利用できるようになります。
しかし、containerd が CIRC への転送に失敗しフォールバックするまでの時間が長いことが確認されました。これにより、CIRC が起動するまでイメージのプルは進むものの、その進み具合が非常に遅いという問題が起こりました。
調べてみると、containerd がフォールバックするまでのタイムアウトが blob ごとに 30 秒でハードコードされていることが判明しました。そこで、このタイムアウト時間を設定できるようにする改善を containerd に提案しました。
この改善はすでに containerd 2.1.0 以降に含まれています。PFN でもこのバージョンを利用しタイムアウトを短く設定することで、CIRC の起動前であってもイメージのプルが実用的な速度で進むようになりました。
Thundering herd 問題
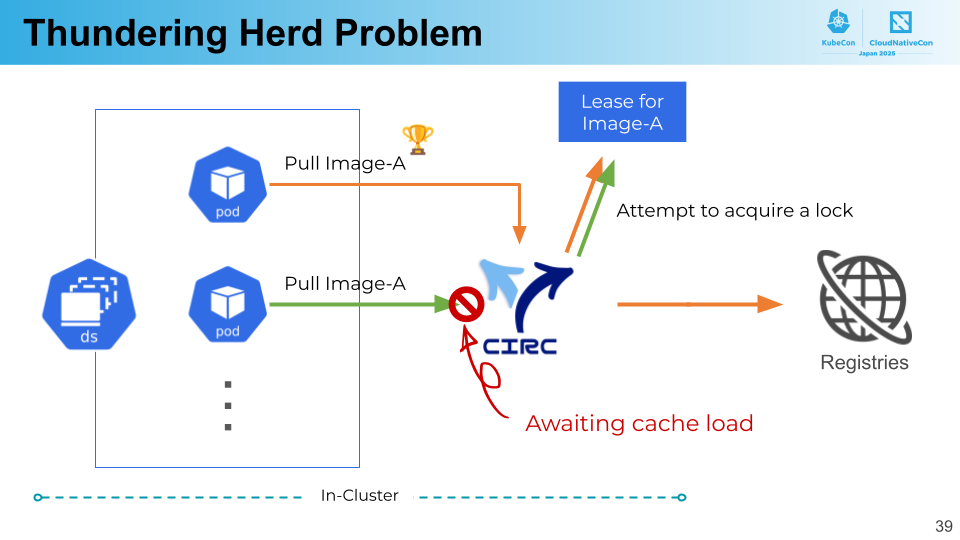
例えば DaemonSet をロールアウトするときなど、同じイメージをプルするリクエストが多数同時に発生することがあります。これらのリクエストは CIRC が受けることになりますが、それらを独立にハンドリングしてしまうと、オリジンレジストリに同じリクエストを同時に複数送ることになり、thundering herd 問題 を起こしてしまいます。これではせっかくのキャッシュを活用できません。
CIRC はこの問題に対処するために、singleflight と呼ばれる並行処理のパターンを利用しています。Singleflight では、同じリクエストを同時に複数受けた場合、そのうち一つを実際に処理し、他のリクエストはその結果を待ち合わせします。これにより、オリジンからのイメージの取得は一度だけで済み、他のリクエストはキャッシュに格納されるのを待って素早く返すことができます。
Singleflight を実装するために、Kubernetes の Lease オブジェクトを利用したリーダ選出をおこなっています。あるイメージをオリジンから取得する CIRC の goroutine をクラスタ内で一つにするために、goroutine 間で Lease オブジェクトのロックを取るという仕組みです。
現実世界での成果
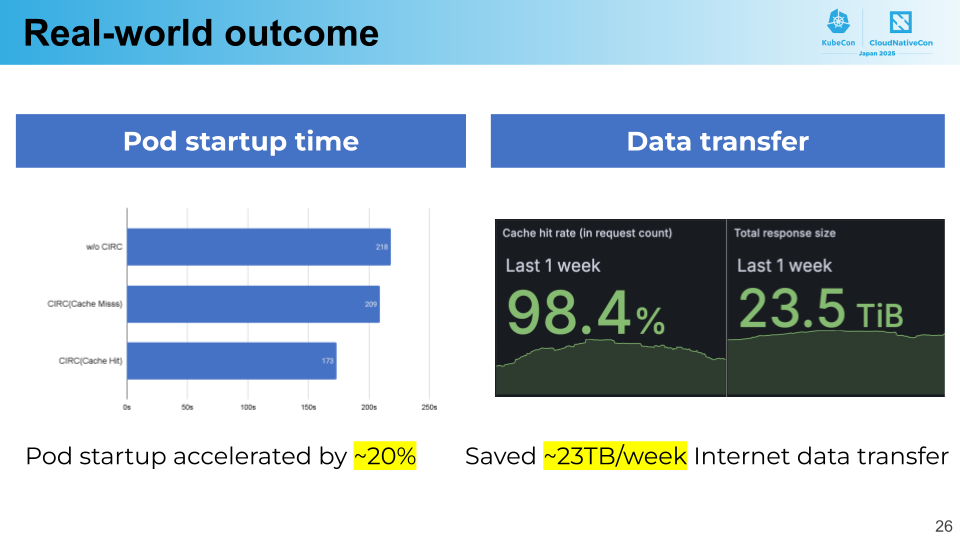
CIRC の導入により PFN のクラスタで実際にどんな成果が得られたか紹介します。まず、pod の起動時間(ノードに割り当てられてからコンテナが開始するまでにかかった時間)が約 20 % 短縮されました。CIRC によりイメージのプルが高速化されたことが寄与しています。透過性のおかげで、ユーザが CIRC の存在を意識することなくこの速度向上を実現できています。
また、オリジンレジストリからクラスタへのデータ転送量は、一週間で約 23 TB 削減されました。CIRC のキャッシュヒット率は 98 % を超えており、これは preheating 機能の貢献も少なからず含まれています。現在は 23 TB ですが、OCI VolumeSource 機能の活用でより効果が得られることを期待しています。
なお、これらの数値は環境やワークロードの特性によって大きく変動することにご注意ください。
まとめ
Kubernetes クラスタ向けのコンテナイメージのキャッシュシステム CIRC を紹介しました。CIRC の導入により、クラスタとコンテナレジストリが離れている環境において、イメージのプルにかかる時間を短縮し、ネットワーク転送量を削減することができました。
CIRC の開発とその成果は、containerd の機能や OCI による標準化の上に成り立っています。これらのコミュニティの努力がなければ CIRC は実現不可能でした。 PFN では、今後もコンテナや Kubernetes コミュニティへの貢献や連携を続けていきます。
機械学習プラットフォームチームでは、一緒に OSS に貢献したり、大規模な機械学習基盤の開発・運用をしたりする仲間を募集しています!カジュアル面談は こちら からお申し込みいただけます。また、他にも以下のポジションの採用を行っています。ご興味のある方は、ぜひお気軽にご連絡ください!
Area
Tag