Blog
概要
医療分野での大規模言語モデル(LLM)活用への期待が高まる中、「LLMは臨床記録の誤りを正しく検出・訂正できるのか」という問いは、安全性確保のために不可欠です。今回、日本語医療AIの安全性評価における重要なマイルストーンとして、MedRECT(Medical Reasoning Benchmark for Error Correction in Clinical Texts)ベンチマークを開発・公開しました。主要な成果は以下の3点です。
- 日本語臨床記録における誤り検出・訂正に特化した初の包括的ベンチマークを構築しました。誤りの種類として、診断、モニタリング/管理、身体的所見、処置、投薬などを網羅しています。
- reasoning能力を有するモデルが誤り検出・訂正において一貫して優位であることを検証しました。
- 私たちの開発したPreferred-MedRECT-32Bは、先行研究の医師2人のスコアと比較して誤りを含む文の抽出・訂正で優れた性能を示しました。
ベンチマークとモデル、より詳細をまとめた論文は以下で公開しています。
- ベンチマーク(MedRECT)
https://github.com/pfnet-research/medrect - モデル(Preferred-MedRECT-32B)
https://huggingface.co/pfnet/Preferred-MedRECT-32B
(注意:本モデルは研究目的で開発されたものであり、実際の診療目的での使用はお控えください。) - 論文(MedRECT: A Medical Reasoning Benchmark for Error Correction in Clinical Texts
https://arxiv.org/abs/2511.00421
本稿はパートタイムエンジニアの岩瀬直人さんの寄稿です。
MedRECTベンチマークの開発背景、データ構築の自動化手法、最新LLMによる評価結果、そして医療AI実用化に向けた展望について解説します。
はじめに
はじめまして、名古屋大学医学部5年の岩瀬直人と申します。2025年7月より、Preferred Networks(PFN)にパートタイムエンジニアとして所属し、医療ドメインにおける大規模言語モデル(LLM)の安全性評価に関する本研究に取り組んできました。医学生として臨床実習を経験する中で、「AIが医療現場で本当に役立つためには何が必要か」という問いに向き合い、特に医療AIの安全性と信頼性の評価基盤の重要性を実感してきました。
医療過誤は米国において主要な死因の一つとされており[1]、臨床推論の失敗がその主要因となっています。LLMは臨床意思決定を支援する画期的な可能性を秘めていますが、その推論プロセスの不透明性と信頼性が大きな課題です。LLMが正しい結論に至っても、その論理が誤っている場合[2,3]や、人間の診断の誤りと同様の認知バイアス(アンカリング、確証バイアスなど)を再現してしまう可能性が指摘されています[4]。
このような医療過誤や臨床推論の失敗を防ぐために、LLMには何が求められるでしょうか。
試験問題では測れない臨床能力
近年、LLMは米国医師国家試験(USMLE)などの試験で高得点を獲得しています[5,6]。日本語医療分野でも、PFNが開発したPreferred-MedLLM-Qwen-72Bが日本医師国家試験(JMLE)で平均431.2点を達成しGPT-4oを上回る最高水準を記録するなど[7]、また他の研究ではCross-lingual能力の実証など[8]顕著な成果が報告されています。しかし、多肢選択式問題(MCQA)での成功は患者安全に直結する実践的能力を保証するものではありません。一方、複雑な臨床タスクのための標準化された高品質ベンチマークは不足しており、医療ドメインに特化したLLMの厳密な評価と開発が妨げられてきました[9,10]。
実臨床では、診断プロセス、治療方針の決定、患者との対話などといった臨床情報が、日々大量に記録され処理されます。こうした医療現場においてLLMが真に患者安全に貢献するためには、記録された臨床文書の中の矛盾や誤りを検出・訂正する能力が不可欠です。MCQAは医学知識の想起を評価する上で一定の価値がありますが、実臨床で求められるような高度な臨床推論能力を測る上では間接的な代理指標に過ぎません。臨床推論の失敗による医療過誤を防ぐためには、このような実践的な能力を正しく評価する新しいベンチマークが必要です。
英語圏中心の評価とスケーラビリティの課題
英語圏では、MEDECベンチマーク[11,12]がMEDIQA-CORR 2024 Shared Taskを通じて、臨床記録の誤り訂正能力を評価する基盤となる手法を提案しました。MEDECは、海外の医師国家試験由来のデータセット(MedQA[13]など)を基に、5種類の臨床的な誤りの検出と訂正に関する初の公開ベンチマークです。日本語では、IgakuQA[14]などの試験問題ベースのベンチマークが存在しますが、誤り検出・訂正に特化したベンチマークは存在しませんでした。
しかし、MEDECには2つの重要な制約があります。第一に、英語のみに焦点を当てているため、LLMの臨床推論能力が異なる言語・文化的文脈でどう転移するかという重要な問いが未解決のままでした。第二に、そのサンプル作成プロセスは医療アノテーターによる手動の注釈づけ(MCQAから臨床記録形式への変換、誤りの注入、品質保証)に依存しており、規模の拡大が困難です。
MedRECTは、これら両方の課題に対処します。先進的なLLMを用いてベンチマーク作成パイプライン全体を自動化する手法を導入することで、日本語版の作成だけでなく、他言語でも類似のベンチマークを自動化して作成することが可能です。
それでは、MedRECTの具体的な内容を見ていきましょう。
MedRECTとは
タスク定義
MEDECに倣い、臨床記録の誤り検出・訂正を3つの段階的サブタスクに分解します。
- 誤り検出(Error Detection):臨床記録に誤りが含まれるかを判定する二値分類
- 誤りを含む文抽出(Error Sentence Extraction):誤りを含むテキストに対し、誤りを含む具体的な文を文番号で特定し、文番号のExact Matchで正誤判定
- 誤り訂正(Error Correction):誤りを含むテキストに対し、誤った文の訂正版を生成
この分解により、モデル能力の詳細な評価が可能となり、誤り検出・訂正パイプラインにおける具体的な弱点を特定できます。なお、後半2つのサブタスクは誤りを含む臨床記録サンプルにおいてのみ実施します。
MedRECTデータの例
臨床記録は文番号を付与した形式でLLMに入力され、モデルは誤りを含む文の番号と訂正した文を出力させることで3つのサブタスクを同時に実行します。なお、誤りがないと判断する場合は”CORRECT”と出力させます。以下の例では、誤りを含む文は太字で強調し、直下に訂正例を併記します。
例1|診断の誤り
- 日齢20の男児が哺乳量低下と発熱を主訴に母親に連れられ来院した。
- 在胎39週3日、体重3,120gで出生した。
- 昨日から哺乳量減少が持続し、本日38.6°Cの発熱が認められた。
- 身体所見:顔色不良、大泉門膨隆、易刺激性を認めた。
- 血液検査:赤血球412万、Hb 12.1g/dL、Ht 36%、白血球25,000(桿状核15%/分葉核65%/単球10%/リンパ球10%)、血小板15万。
- 生化学:血糖98mg/dL、Na 136mEq/L、K 4.5mEq/L、Cl 100mEq/L、CRP 13.8mg/dL。
- 脳脊髄液:細胞数4,200/mm³(単核球22%/多形核球78%)、蛋白80mg/dL、糖5mg/dL。
- 検査所見からPseudomonas aeruginosa起因の髄膜炎が強く示唆された。
訂正例:8. 検査所見から GBS(Streptococcus agalactiae)起因の髄膜炎が強く示唆された。
Pseudomonas aeruginosa(緑膿菌)は院内感染や易感染性背景での発症が多いとされますが、こうした情報はこの臨床記録にはなく、また出生早期の健康新生児に典型的でもありません。適切な推定起因菌は、まずGBSなどを挙げるのが普通です。
例2|手技・介入の誤り
- 82歳女性、膵癌肝転移による緩和ケア病棟入院中。1週間前より食欲低下と食事摂取量減少が進行中。体重変化なし。
- 意識状態は清明。身長150cm、体重36kg。
- バイタルサイン:体温36.2℃、脈拍80/分・整、血圧108/58mmHg。
- 身体所見:皮膚ツルゴール低下、口腔内衛生不良かつ乾燥、腹部平坦・軟、下腿浮腫なし。
- 血液所見:赤血球320万、Hb 9.2g/dL、Ht 30%、白血球8,200、血小板23万。
- 生化学所見:総蛋白5.8g/dL、アルブミン2.8g/dL、AST 24U/L、ALT 28U/L、尿素窒素28mg/dL、クレアチニン1.0mg/dL。
- 栄養サポートチームは栄養補給目的での胃瘻造設を提案した。
- 主治医に計画を説明し同意を得る方針とした。
訂正例:7. 栄養サポートチームは非侵襲的な栄養管理法を優先的に検討するとした。
終末期患者では、侵襲的手技は苦痛を増やしQOLを損なうことがあり、短期間の摂食低下に対する胃瘻造設提案は不適切の可能性が高いと考えられます。まずは脱水の補正、疼痛や悪心などの症状の緩和、口腔ケア、嗜好に合わせた経口摂取支援などを優先的に検討することが合理的です。
また、これらの例とは異なり、誤った文を含まない正しい臨床記録サンプルもデータセットには含まれています。
データセット統計
MedRECTは日本語版(MedRECT-ja)と英語版(MedRECT-en)で構成されます。
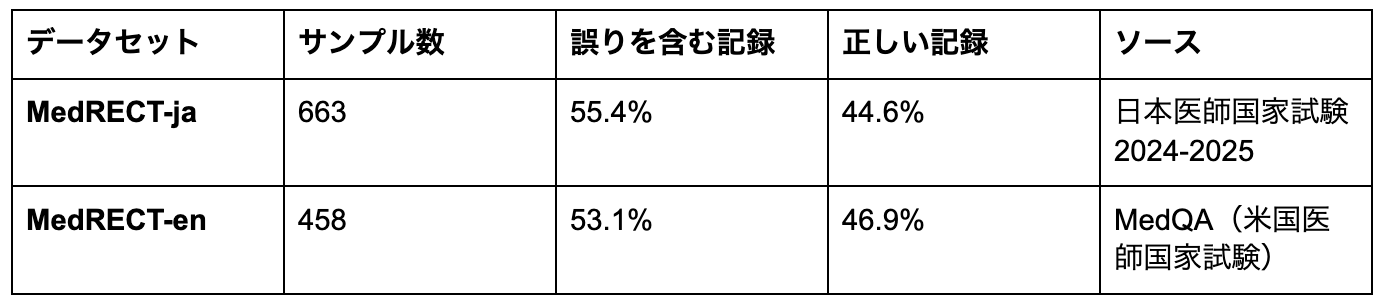
両データセットの誤りを含む記録と正しい記録の比率は類似しており、Cross-lingual評価をする上で妥当と考えられます。
誤りの種類の分布は異なる臨床文脈とソース手法を反映しています。MedRECT-jaは診断(21.0%)、モニタリング・管理(21.5%)、身体所見(19.6%)のようなバランスの取れた分布を示し、日本の臨床現場における検査文化を反映していると考えられます。一方、MedRECT-enは診断の誤り(40.3%)と投薬選択(28.8%)が支配的で、ソースのMedQAの出題パターンを反映しています。
評価指標
各サブタスクに対し、以下の評価指標を採用しました。
- 誤り検出:F1スコア(二値分類)
- 文抽出:正解率(文番号のマルチクラス分類)
- 誤り訂正:ROUGE-1、BERTScore、BLEURT、およびそれらの算術平均
MEDIQA-CORR 2024の評価プロトコルに従い、文抽出は真値で誤りを含むサンプルのみで計算し、誤り訂正メトリクスは予測と真値の両方が誤りの存在を示すサンプルのみで計算します。
次に、このベンチマークをどのように構築したかを説明します。
MedRECTの構築パイプライン
以下の図は、MedRECT-jaとMedRECT-enの構築パイプライン全体を示しています。
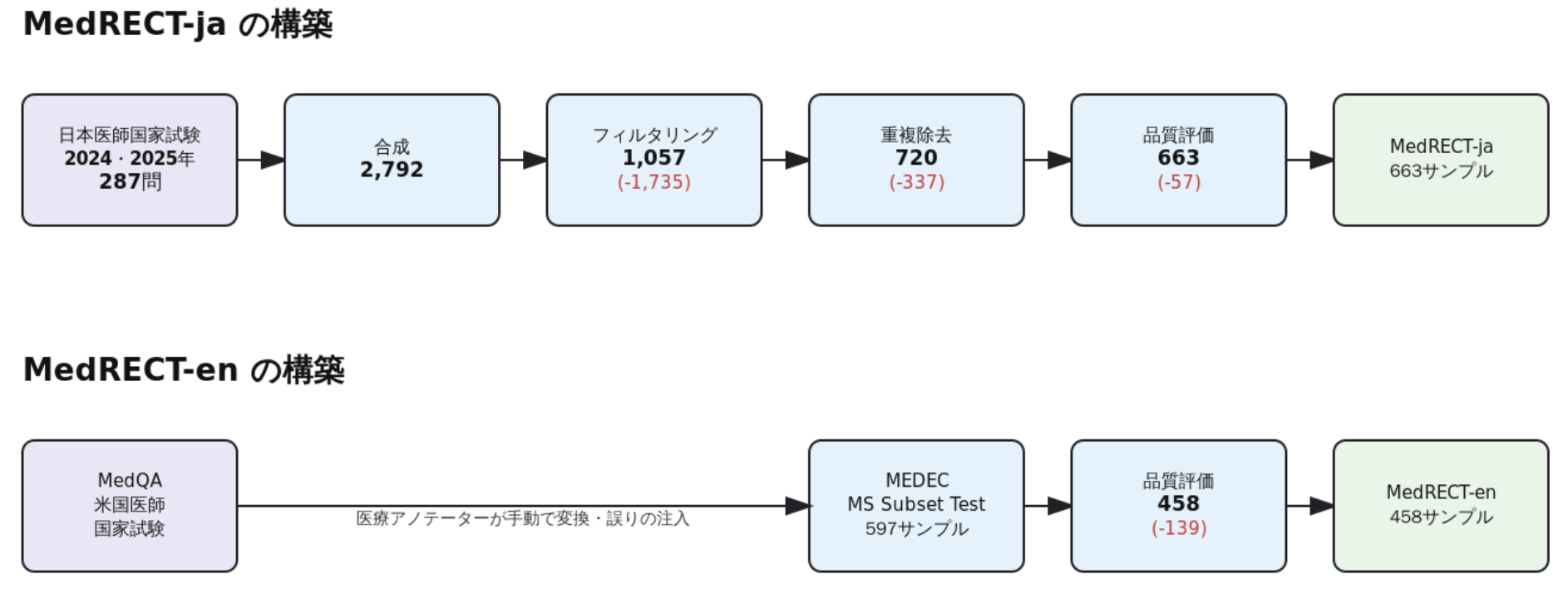
図1: MedRECTベンチマーク構築パイプライン。MedRECT-jaは4段階(合成→フィルタリング→重複除去→品質評価)、MedRECT-enはMEDECに品質評価を適用。赤字は各段階で除去されたサンプル数。
MedRECT-jaは、日本医師国家試験(JMLE 2024・2025)の症例問題287問をソースとし、以下の4段階で構築しました。(1) LLMによる臨床記録形式への自動変換と誤りの注入(287問→2,792サンプル)、(2) 複数モデルによる難易度ベースのフィルタリング(→1,057サンプル)、(3) 重複除去(→720サンプル)、(4) LLM-as-a-Judgeによる最終品質スクリーニング(→663サンプル)。
MedRECT-enは、MEDEC MS Subset Test(MedQA由来、597サンプル)に対し、同様のLLM-as-a-Judgeによる品質スクリーニングを適用し、458サンプルの高品質データセットを構築しました。
従来のMEDECでは医療アノテーターによる手動の注釈づけが必要でしたが、本研究では最新の多様なLLMを活用してパイプライン全体を自動化しました。この手法により、再現可能かつスケーラブルなベンチマーク構築が可能となり、他言語や異なる医療文脈への展開が容易になります。詳細な構築手順は論文を参照してください。
それでは、このベンチマークを用いた評価結果を見ていきましょう。
評価結果
評価モデル
複数の最新LLMを評価しました。
- reasoningモデル:GPT-5[17]、o3[18]、Claude Sonnet 4[19]、gpt-oss-120b/20b[20]、Qwen3-32B(think)[16]、Preferred-MedRECT-32B
- non-reasoningモデル:GPT-4.1、DeepSeek-V3-0324[21]、Qwen3-32B(no-think)[16]
reasoningモデルは内部で明示的な推論プロセスを経て最終応答を出力します。OpenAIのreasoningモデル(GPT-5、o3、gpt-oss)は、総出力トークンのうちどのくらいをreasoningに割り当てるかというreasoning effortパラメータが指定可能です。今回の評価ではGPT-5とo3にAPIデフォルトのmediumを使用し、gpt-ossは全3段階(high/medium/low)で評価しました。Claude Sonnet 4は拡張思考(Extended Thinking)を有効化するthinkingパラメータを持ち、今回の評価時に有効化しました。Qwen3-32Bはthinkとno-thinkモードの両方を提供し、同一アーキテクチャ内でのreasoningの有無による直接比較を可能にします。Preferred-MedRECT-32Bは、Qwen3-32Bをベースモデルとして、LoRA[22]を用いたFine-tuningによって私たちが開発したreasoningモデルです。
評価プロンプト
評価には0-shotプロンプティングを用いました。MedRECT-jaで用いた0-shot-jaは以下のとおりです。
あなたは臨床テキストの正確性をレビューする医学専門家です。テキストにはエラーがないか、または正確に1つの医学的エラーが含まれています。
治療、診断、管理、または因果関係に関連する医学的エラーを特定し、修正してください。
出力形式:
– エラーなしの場合:`CORRECT`
– エラー発見の場合:`文番号: 修正された文`
重要:結果のみを出力してください。説明、分析、追加のテキストは含めないでください。{sentences}
MedRECT-enで用いた0-shot-enは、これをそのまま英訳したプロンプトです。
MedRECT-jaでの性能評価
表1は、最新LLMのMedRECT-ja(日本語ベンチマーク)における包括的な性能比較を示しています。
表1: MedRECT-jaにおける性能評価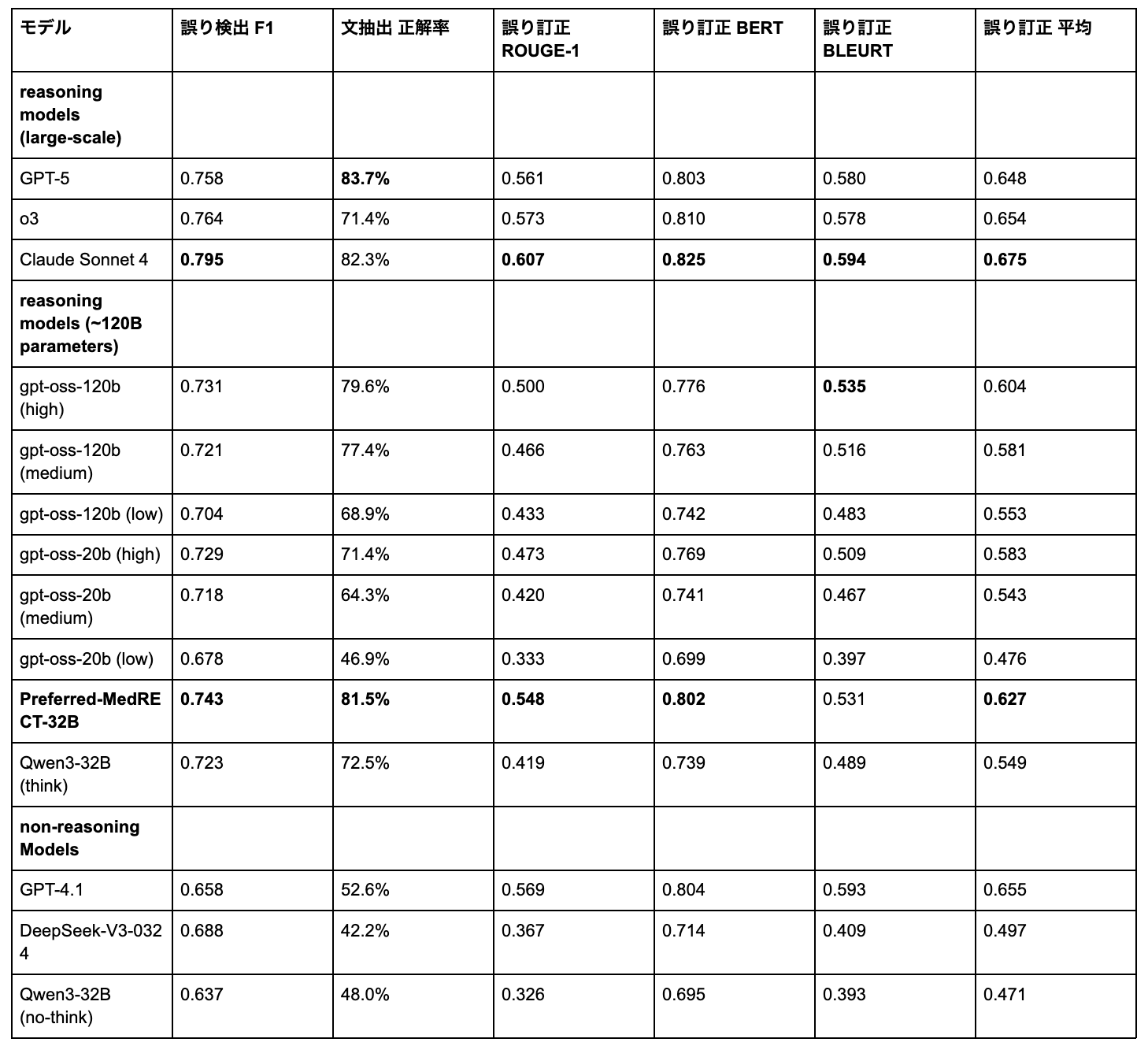
MedRECT-jaにおいて、Claude Sonnet 4が大規模モデル中で最高の総合性能(訂正平均スコア0.675)を達成し、特に誤り検出(0.795 F1スコア)と誤り訂正指標で優れた能力を示しています。
計測したモデルのうち~120Bパラメータのモデルでは、Preferred-MedRECT-32Bが最高性能(訂正平均スコア0.627)を達成し、ベースモデル(Qwen3-32B think)と比較して大幅な性能向上を示しています(0.627 vs. 0.549、14.2%の相対改善)。日本語での文抽出正解率81.5%は、gpt-oss-120bを含む他の同クラスモデルを上回る結果です。
文抽出正解率ではモデル間で最も大きな性能差が見られ、42.2%(DeepSeek-V3-0324)から83.7%(GPT-5)まで幅広く分散しています。
reasoningが誤り検出の鍵
興味深いことに、reasoningモデルが一貫して高い性能を示しました。これは複数のモデルファミリーで確認され、臨床記録の誤り訂正における明示的な推論プロセスの重要性が明らかになりました。異なる推論努力レベルのgpt-ossモデル、Qwen3-32B think vs. no-thinkモードの比較から、この傾向が確認できます。
特にMedRECT-jaでのQwen3-32B think vs. no-thinkの直接比較は劇的な性能差を明らかにしました。誤り検出ではF1スコアが0.723→0.637(13.5%の相対改善)、文抽出では正解率が72.5%→48.0%(51.0%の相対改善)、誤り訂正では平均スコアが0.549→0.471となりました。
全ケースで、強化されたreasoningが誤り検出、文抽出、訂正タスクにわたって性能を一貫して向上させました。Claude Sonnet 4はこの原則を体現し、全評価モデル中で最高の誤り検出F1スコア(0.795)を達成しつつ、日本語での文抽出でも82.3%の高性能を維持しました。加えて、reasoningモデルの重要な利点として推論プロセスの可視化があります。ブラックボックスモデルとは異なり、「なぜその判断をしたか」を段階的に示すことができるため、医療現場での信頼構築や、医師がAIの判断を検証し適切に活用するための基盤となります。
誤りを含む文の特定が最大の課題
MedRECT-jaの評価結果を見ると、モデル間で文抽出正解率に大きな差があることがわかりました(42.2%〜83.7%)。これは、臨床記録内の誤った文を正確に特定することが、誤り訂正において最も困難なタスクであることを示しています。誤りの有無を判定する二値分類よりも、臨床的な文脈の中で誤りの位置を正確に特定する方が、より高度な理解が必要だと言えます。
ここでもreasoningモデルの優位性は明らかで、文抽出正解率で一貫してnon-reasoningモデルを上回る結果となりました(reasoningモデル: 71.4%〜83.7% vs. non-reasoningモデル: 42.2%〜52.6%)。複雑な医療テキスト内で正確に誤り位置を特定するには、明示的な推論プロセスが特に重要であることがわかります。
興味深いことに、いわゆるプロプライエタリモデル(GPT-5: 83.7%、Claude Sonnet 4: 82.3%)でさえ完璧には至りませんでした。臨床文脈内の誤り位置特定の複雑さは、最先端のLLMでも継続的な課題となっています。
Cross-lingual性能評価
表2は、MedRECT-ja(日本語)とMedRECT-en(英語)のベンチマーク間で体系的な性能差を示しています。
表2: MedRECT-jaとMedRECT-enのCross-lingual性能比較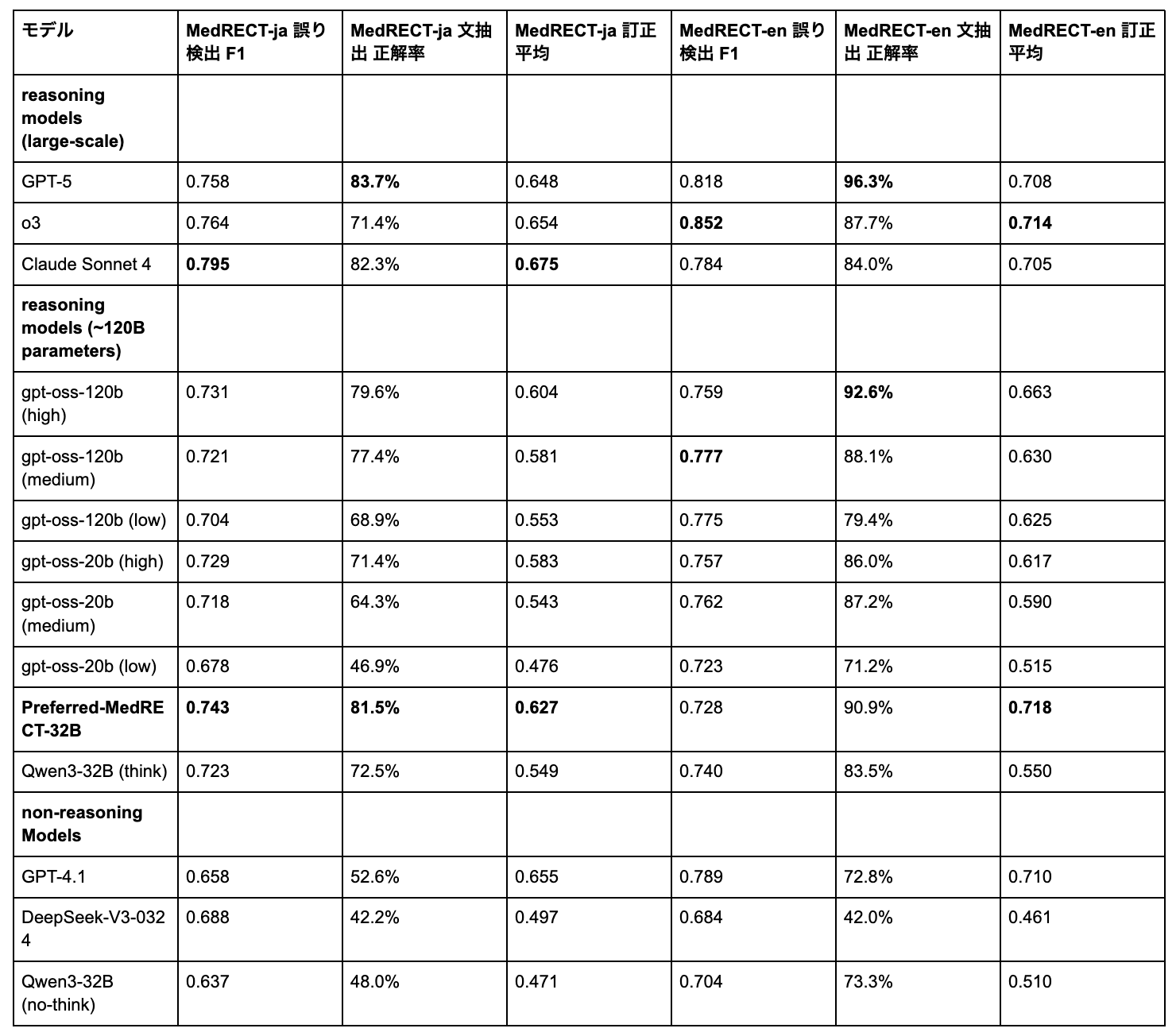
ほとんどのモデルは英語でより良い性能を示しましたが、中でもPreferred-MedRECT-32Bが英語で特に優れた性能を示しました(MedRECT-en: 0.718 vs. MedRECT-ja: 0.627、差分+0.091、30.5%の相対改善)。主に日本語医療データで訓練されたにもかかわらず、英語の訂正平均スコア0.718はプロプライエタリモデルに匹敵する水準に達しています。
Cross-lingual性能パターンはサブタスクによって大きく異なります。文抽出正解率が最大の言語特異的変動を示し、GPT-4.1などのモデルが実質的な差を示しました(日本語52.6% vs. 英語72.8%)。一方、誤り検出F1スコアはより一貫したCross-lingual性能を示し、Claude Sonnet 4(日本語0.795 vs. 英語0.784)、GPT-5(日本語0.758 vs. 英語0.818)、o3(日本語0.764 vs. 英語0.852)など、比較的小さなギャップでした。
Fine-tuningの効果
Preferred-MedRECT-32Bは、両言語にわたって実質的な性能向上を示しましたが、特に英語で大きな改善が見られました。
日本語(MedRECT-ja)では、平均スコアが0.549から0.627へ向上し(14.2%の相対改善)、誤り検出F1が0.723→0.743、文抽出正解率が72.5%→81.5%となりました。
一方、英語(MedRECT-en)では、平均スコアが0.550から0.718へと大きく向上し(30.5%の相対改善)、Preferred-MedRECT-32Bは英語で特に優れた性能(0.718 vs. 日本語0.627)を達成しました。主に日本語医療データで訓練されたにもかかわらず、英語の文抽出正解率は90.9%に達しています。
この結果は興味深いものです。日本語訓練データが英語の2倍以上(5,538 vs. 2,439サンプル)であるにもかかわらず、英語でより大きな改善効果を示したのです。これは、日本語臨床シナリオから学習した医療推論パターンが、英語の誤り訂正能力向上に効果的に転移する可能性を示唆しています。
これらの発見は、医療現場への実用化にどのような意味を持つのでしょうか。
実臨床への道筋
医師との比較
Preferred-MedRECT-32Bは元のMEDECベンチマーク(英語)において医師と比較して一部のサブタスクで優れた性能を達成しました。
表3: 元のMEDECベンチマーク(英語)での医師との比較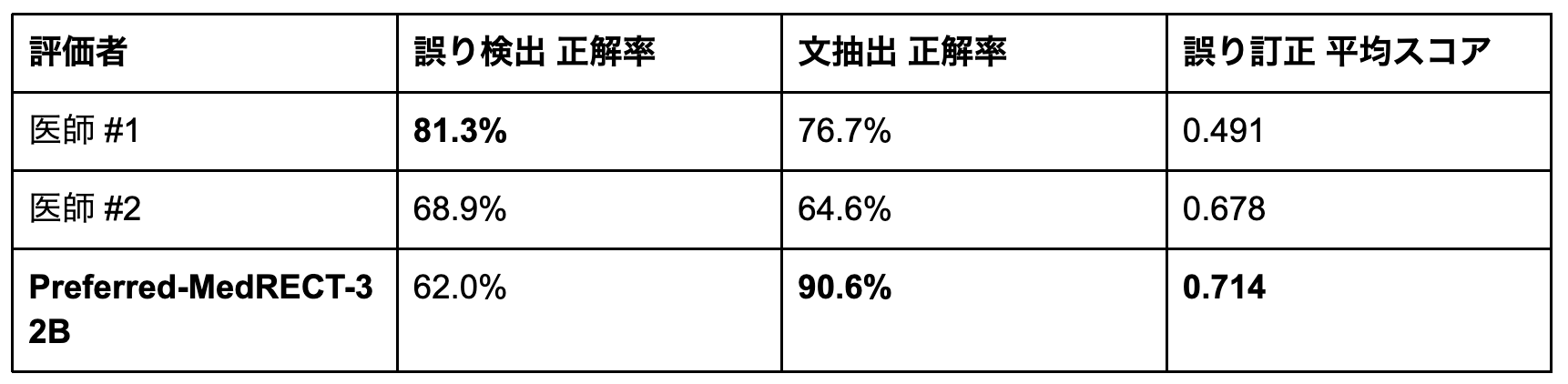
※ 元のMEDECベンチマーク MS Subset Test(英語、597サンプル)での評価
Preferred-MedRECT-32Bは、文抽出正解率で90.6%を達成し、医師#1の76.7%、医師#2の64.6%を大きく上回りました。誤り訂正でも平均スコア0.714を達成し、医師#1の0.491、医師#2の0.678を上回っています。
ただし、誤り検出では医師より低い正解率(62.0% vs. 81.3%/68.9%)を示しました。これはより感度の高い検出による偽陽性の増加が原因です(誤りが存在しないサンプルに対する誤検出が多い)。
定性的な分析
定量的な指標の改善だけでなく、定性的な分析からも臨床的に重要な能力向上が確認できました。以下の表は、3つの代表的サンプルにおける各モデルの訂正結果を示しています。
表4: 代表サンプルにおける各モデルの誤り訂正結果
評価凡例:✓ 完全正解 / △ 部分正解 / × 失敗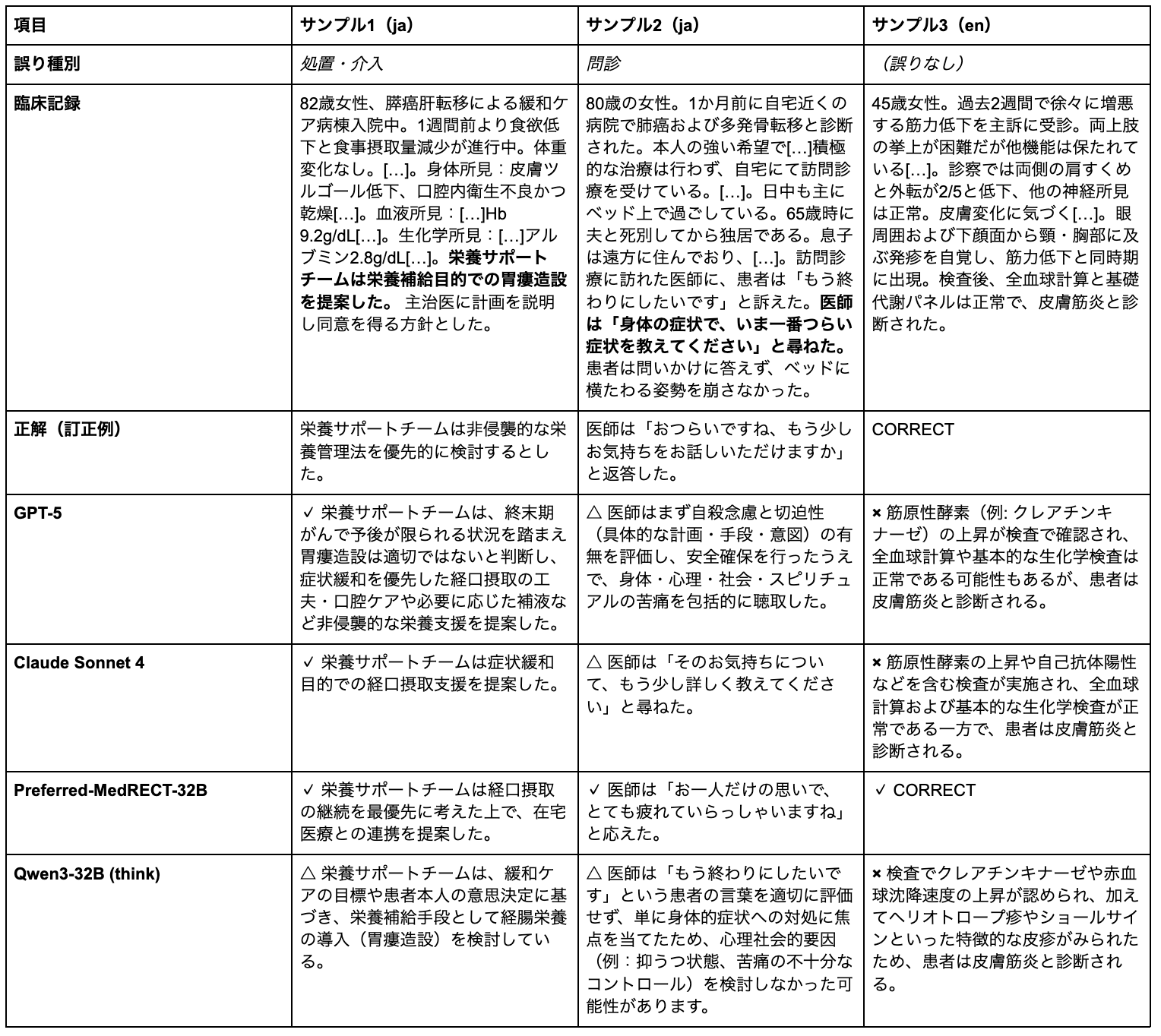
注記1: 臨床記録中の太字は誤りを含む文。[…]は中略。 注記2: サンプル3はMedRECT-enのサンプルであり、臨床記録、モデルのレスポンスは本記事にて和訳されている。
サンプル1
82歳の終末期膵癌患者に対し、栄養サポートチームが胃瘻造設を提案したケースです。緩和ケアの文脈では、侵襲的処置よりも患者の快適性を優先すべきであり、非侵襲的な栄養管理法の検討が適切です。
GPT-5とClaude Sonnet 4は非侵襲的アプローチを提案できていますが、Preferred-MedRECT-32Bはより具体的に「経口摂取の継続を最優先」と明記し、緩和ケアの本質を捉えた訂正を行いました。ベースQwen3-32Bは依然として胃瘻造設を検討しており、緩和ケアの理念を十分に理解できていません。
サンプル2
終末期肺癌患者が「もう終わりにしたい」と訴えた際、医師が身体症状について尋ねる応答は共感的理解に欠けています。
GPT-5は理知的に自殺リスク評価を優先し、Claude Sonnet 4は患者の気持ちについて尋ねますが、いずれも温かみと共感性に欠け、部分正解にとどまりました。一方、Preferred-MedRECT-32Bは「お一人だけの思いで、とても疲れていらっしゃいますね」と、患者の孤独感と感情状態を認識した上で共感的な応答をしました。これは、Fine-tuningが単なる臨床知識を超えて、患者中心のコミュニケーション能力を向上させることを示しています。
サンプル3
皮膚筋炎の診断が既に正確になされているケースです。複数のモデル(GPT-5、Claude Sonnet 4、ベースQwen3-32Bを含む)が、既に正確な診断テキストを誤りとして誤検出し、「elevated muscle enzymes」などの不要な検査所見の追加を提案しました。
Preferred-MedRECT-32Bのみが「CORRECT」と正しく識別し、訂正不要と判断できています。このパターンは実用展開上の重要な課題を示しています。過度に誤り検出をすることで、医療従事者にチェックの負担を課し、臨床ワークフローに組み込んだ際のシステムの有用性を低下させる恐れがあります。
実用化への展望
本研究で得られた知見は、本記事の冒頭で提起した「推論プロセスの不透明性と信頼性」という課題に取り組み、実臨床での誤り検出・訂正のシステムを実現する道筋を示しています。
第一に、reasoningモデルの推論プロセス可視化は、医療現場での信頼構築の基盤となります。ブラックボックスな判断ではなく、「なぜその箇所を誤りと判断したか」を段階的に示すことで、医師がAIの提案を適切に検証し、協働できる環境を実現できます。第二に、Preferred-MedRECT-32Bが医師を上回る誤り文抽出・訂正性能を示したことは、臨床記録のレビューを支援する実用的なアシスタントとしての可能性を実証しています。第三に、主に日本語データで訓練されたモデルが英語でも優れた性能を示したことは、多言語展開の可能性を示唆しています。さらに、本研究で確立した自動化されたベンチマーク構築パイプラインは、継続的な性能改善とモニタリングを可能にし、長期的な安全性担保の基盤となります。
実用化に向けては、医師の判断を置き換えるのではなく、臨床記録のレビューを支援する提案型の意思決定支援として機能させるのが有力です。例えば一案として、電子カルテの機能として組み込み、推論根拠を明示しながら誤りの候補を指摘し、医師が適切に検証できる仕組みが考えられます。実装にあたっては、段階的な検証を経て安全性を確認すること、医療従事者のワークフローを妨げない設計が重要となります。
私は医学生として臨床実習の中で、「情報の小さな行き違い」が治療方針の決定の遅れにつながる場面を何度も目にしてきました。MedRECTは、そうした綻びを静かに、しかし確実に見つけて埋めるための第一歩です。AIが診断を置き換えるのではなく、臨床の当たり前を少しずつ堅牢にし、患者安全の底上げに貢献する。本研究で示した知見を基盤に、そのような未来の実現に向けて、これからも一歩ずつ前進していきたいと考えています。
本研究の限界
本研究にはいくつかの限界があります。第一に、データセットの規模は日本医師国家試験問題の利用可能性により制約されています。直近2年分(2024・2025)の800問中、症例設定を含まない大半の短文知識問題は使用できず、さらに画像問題、計算問題などを除外した結果、287の症例設定を含む問題のみが利用可能と判断されました。第二に、誤りの自動合成アプローチは実際の臨床実践で遭遇する医療過誤や臨床推論の失敗の多様性を完全には表現していない可能性があります。第三に、データセットの構築パイプラインが複数段階で特定モデル(合成にDeepSeek-R1-0528とQwen3-235B-A22B-Thinking-2507、難易度ベースフィルタリングにQwen3-32Bを含む11の検証モデル、品質スクリーニングにGemini 2.5 Pro)に依存しています。これによりベンチマークにモデル特有のバイアスを導入してしまう可能性があります。第四に、3種類の訂正評価のメトリクスはある程度包括的ですが、訂正品質の評価において専門家の臨床判断を完全に代替することはできません。最後に、本研究はテキストベースの臨床記録のみに焦点を当てており、実際の臨床現場において一般的な画像、表、その他の視覚要素を含むマルチモーダルには対応していません。
おわりに
本記事では、日本語と英語の臨床記録における誤り検出・訂正能力を評価する初のベンチマークMedRECTを紹介しました。本研究で得られた知見が、医療過誤や臨床推論の失敗を防ぎ、患者安全に真に貢献する医療AIの実現への第一歩となることを願っています。
最後に、本研究を指導してくださったメンターの岩澤さん、奥山さんに深く感謝いたします。また、計算環境を提供してくださったPFNの計算クラスタチームの皆さまにも御礼申し上げます。
参考文献
[1] Makary, M. A., & Daniel, M. (2016). “Medical error—the third leading cause of death in the US”. BMJ, 353. https://www.bmj.com/content/353/bmj.i2139
[2] Turpin, M., et al. (2023). “Language models don’t always say what they think: unfaithful explanations in chain-of-thought prompting”. arXiv preprint arXiv:2305.04388. https://arxiv.org/abs/2305.04388
[3] Lyu, Q., et al. (2023). “Faithful Chain-of-Thought Reasoning”. Proceedings of IJCNLP-AACL 2023, pp. 305-329. https://aclanthology.org/2023.ijcnlp-main.20/
[4] Saposnik, G., et al. (2016). “Cognitive biases associated with medical decisions: a systematic review”. BMC Medical Informatics and Decision Making, 16(138). https://bmcmedinformdecismak.biomedcentral.com/articles/10.1186/s12911-016-0377-1
[5] Gilson, A., et al. (2023). “How Does ChatGPT Perform on the United States Medical Licensing Examination?”. JMIR Med Educ, 9, e45312. https://mededu.jmir.org/2023/1/e45312
[6] Singhal, K., et al. (2023). “Large Language Models Encode Clinical Knowledge”. Nature, 620, 172-180. https://doi.org/10.1038/s41586-023-06291-2
[7] Kawakami, W., et al. (2025). “Stabilizing Reasoning in Medical LLMs with Continued Pretraining and Reasoning Preference Optimization”. arXiv preprint arXiv:2504.18080. https://arxiv.org/abs/2504.18080
[8] Sukeda, I. (2024). “Development and bilingual evaluation of Japanese medical large language model within reasonably low computational resources”. arXiv preprint arXiv:2409.11783. https://arxiv.org/abs/2409.11783
[9] Jiang, J., et al. (2024). “JMedBench: a benchmark for evaluating Japanese biomedical large language models”. arXiv preprint arXiv:2409.13317. https://arxiv.org/abs/2409.13317
[10] 岩澤 諄一郎, 大野 健太 (2025). “日本語医療大規模言語モデルの進展と課題”. 人工知能, 40 巻, 5 号, p. 726-734. https://doi.org/10.11517/jjsai.40.5_726
[11] Ben Abacha, A., et al. (2025). “MEDEC: a benchmark for medical error detection and correction in clinical notes”. arXiv preprint arXiv:2412.19260. https://arxiv.org/abs/2412.19260
[12] Ben Abacha, A., et al. (2024). “Overview of the MEDIQA-CORR 2024 Shared Task on Medical Error Detection and Correction”. Proceedings of the 6th Clinical Natural Language Processing Workshop, pp. 596-603. https://aclanthology.org/2024.clinicalnlp-1.57/
[13] Jin, D., et al. (2020). “What disease does this patient have? A large-scale open domain question answering dataset from medical exams”. arXiv preprint arXiv:2009.13081. https://arxiv.org/abs/2009.13081
[14] Kasai, J., et al. (2023). “Evaluating GPT-4 and ChatGPT on Japanese Medical Licensing Examinations”. arXiv preprint arXiv:2303.18027. https://arxiv.org/abs/2303.18027
[15] DeepSeek-AI. (2025). “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning”. arXiv preprint arXiv:2501.12948. https://arxiv.org/abs/2501.12948
[16] Yang, A., et al. (2025). “Qwen3 Technical Report”. arXiv preprint arXiv:2505.09388. https://arxiv.org/abs/2505.09388
[17] OpenAI. (2025). “GPT-5 System Card”. https://cdn.openai.com/gpt-5-system-card.pdf
[18] OpenAI. (2025). “OpenAI o3 and o4-mini System Card”. https://cdn.openai.com/pdf/2221c875-02dc-4789-800b-e7758f3722c1/o3-and-o4-mini-system-card.pdf
[19] Anthropic. (2025). “System Card: Claude Opus 4 and Claude Sonnet 4”. https://www-cdn.anthropic.com/6d8a8055020700718b0c49369f60816ba2a7c285.pdf
[20] OpenAI. (2025). “gpt-oss-120b & gpt-oss-20b Model Card”. arXiv preprint arXiv:2508.10925. https://arxiv.org/abs/2508.10925
[21] DeepSeek-AI. (2025). “DeepSeek-V3 Technical Report”. arXiv preprint arXiv:2412.19437. https://arxiv.org/abs/2412.19437
[22] Hu, E. J., et al. (2021). “LoRA: Low-Rank Adaptation of Large Language Models”. arXiv preprint arXiv:2106.09685. https://arxiv.org/abs/2106.09685
Area
