Blog

MN-Coreランタイムとは何か
MN-Core™コンパイラチームの河田 旺です。このブログではMN-Coreソフトウェアスタックの中のランタイム部分について紹介します。なお、本稿では単に「MN-Core」と書いた場合はMN-Core 1、MN-Core 2を含むMN-Coreシリーズを指します。
MN-Coreソフトウェアスタックは大きくコンパイラとランタイムの2つに分けることができます。このうちコンパイラはONNXファイルを入力としMN-Coreの命令列を生成するコンポーネントであり、ランタイムはコンパイラが生成した命令列と入力データをMN-Coreに転送し、計算結果を得るコンポーネントです。コンパイラ、ランタイム、ユーザのプログラムを図にすると次のようになります。
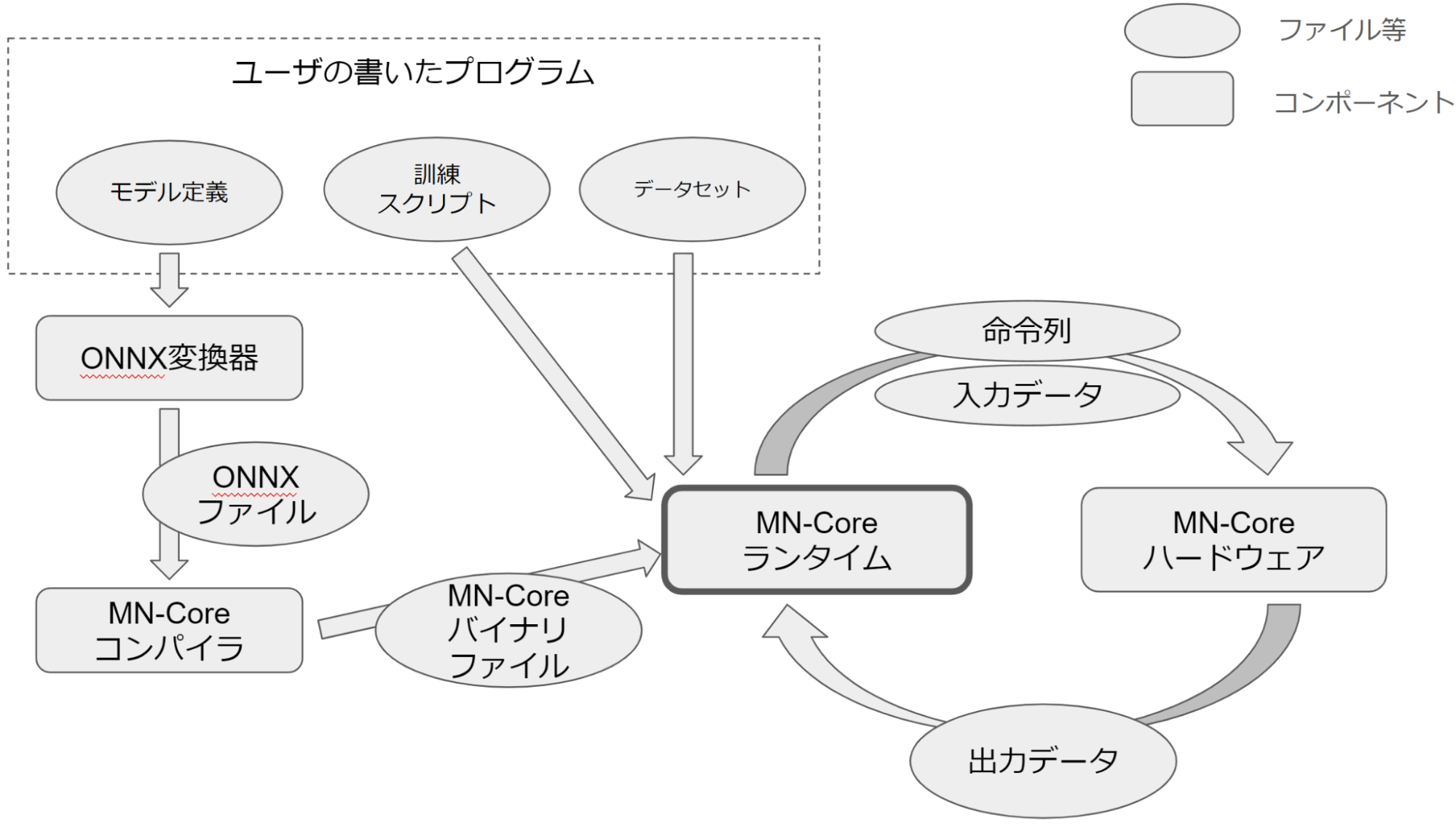
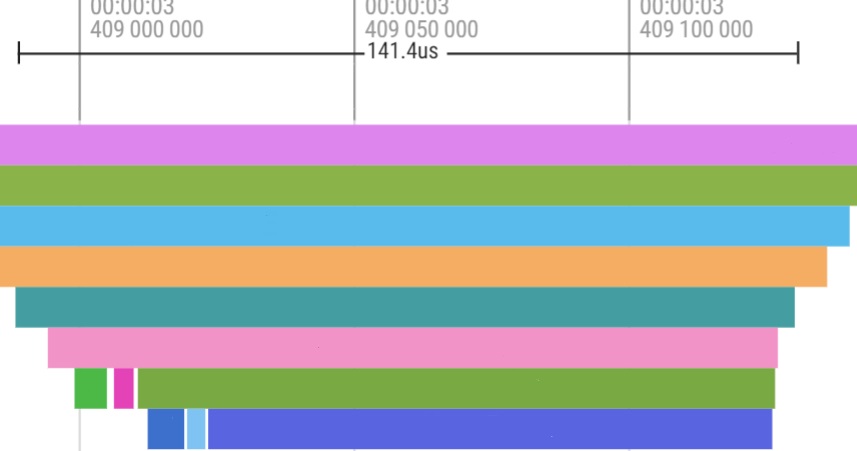
ランタイムはコンパイラとは性質が大きく異なります。コンパイラは性能の良い命令列を出力するために20時間以上かけることもありますが、ランタイムは100us~1msオーダで動作することが求められます。これは、例えば機械学習ワークロードの場合、コンパイラはトレーニングループが回る前に一度だけ動くのに対し、ランタイムはトレーニングループが一回回るたびに動き、計100万回以上動くという違いがあるためです。下は一ヶ月ほど前に高速化していたランタイムのとあるパートの様子です。横方向が時間の経過を表し、縦方向は関数呼び出しの深さを表しています。
MN-Coreランタイムの構成
MN-Coreランタイムは大きく3レイヤに分けることができます。
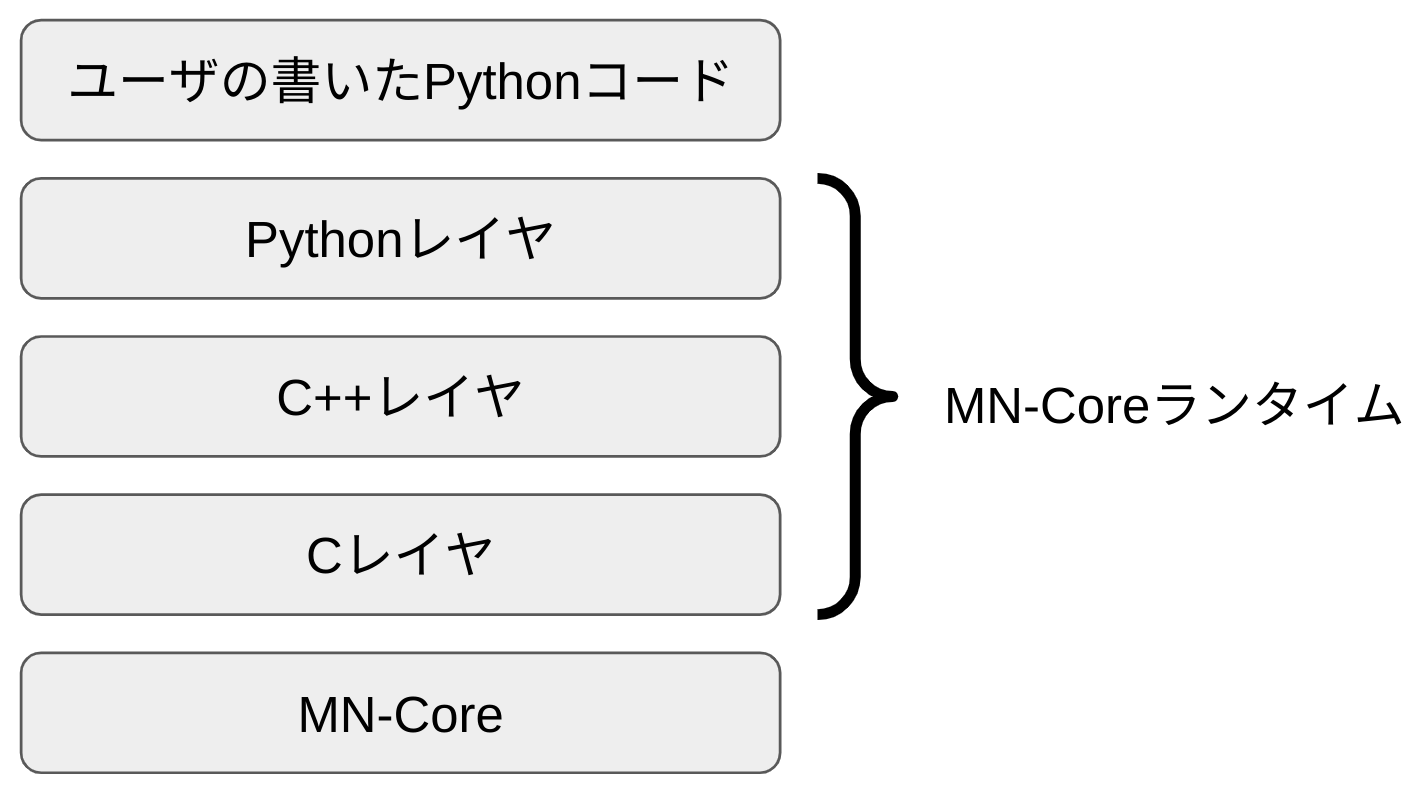
最もユーザに近いレイヤはPythonで書かれたレイヤです。このPythonレイヤは開発者にMN-Coreを簡単に使ってもらえるようにするために存在します。CPU/GPUとMN-Coreとの間の移行コストを最小化するように設計しており、理想的な場合、デバイスを指定している”cpu”を”mncore”に書き換えるだけでMN-Coreで動作するようになります。
Pythonのひとつ下のレイヤはC++で書かれています。このC++レイヤの目的はMN-Coreの機能を単純化したAPIに抽象化し、また、MN-Core 1とMN-Core 2の違いを吸収することです。C++レイヤはMN-Coreランタイムの3つのレイヤの中でも最も複雑かつ大規模なものです。
MN-Coreランタイムの3レイヤのうち最も下にあるのは、Cで書かれたLinux カーネルモジュールとユーザ空間で動作するそのラッパライブラリです。このCレイヤはMN-CoreをLinuxのデバイスファイルに変換し、それを使いやすくラップしています。Cレイヤよりも下はハードウェアしかありません。
MN-CoreのハードウェアがMN-Coreランタイムの設計に及ぼす影響
ここからはMN-CoreランタイムのMN-Coreならでは工夫を紹介します。先程も述べたようにランタイムの中で最も大規模なのはC++レイヤであり、このレイヤにMN-Coreを使いやすく抽象化する工夫が詰め込まれています。
MN-Core 1を抽象化する上で扱いが難しいものの一つが、PCIeバスから命令を供給し続けなければ動かないという仕様です。MN-Core 1にはプログラミングカウンタやプログラムを保持する記憶装置が無く、デバイスはホストから流し込まれてきているプログラムを実行しては捨てています。これは分岐命令が無くすべてのProcessor Elementが完全に同じ命令で動くMN-Coreだからこそ可能な仕様であり、ハードウェアを単純化しソフトウェアからの柔軟な制御を可能にしています。
一方、この命令供給はMN-Coreが命令を消費する以上の速度で行う必要があり、命令供給が間に合わなかった場合はMN-Coreがストールして実行効率が落ちてしまいます。先日発表されたMN-Core 2はMN-Core 1に比べて更に必要な命令供給の帯域が大きかったため、実際に命令供給の遅れによるストールが発生し、CPU がビジー状態のときだけ何故か実行効率が出ない、というバグに悩まされました。幸いにもこのバグは命令をコピーするロジックの改善で修正できましたが、MN-Coreらしいとても興味深いバグでした。
更に機械学習ワークロードを動かすためには、命令列だけでなく入力データを供給し、出力結果をデバイスから回収する必要があります。当然、入力データは命令列よりも先に供給し、出力結果は命令列の実行後に回収しなければなりません。これらの処理の間の順序関係を整合させるにはMN-Coreの同期機構を駆使する必要があります。また、これらのMN-Core上での処理以外にも入力データの前処理などのホストだけで完結する処理もあり、これらすべての間に順序関係があります。
この順序関係を保って数多の処理を行うために、ランタイムにはMN-Core上での処理とホスト上での処理を一貫して扱えるOpen CL likeなイベントAPIが存在しフル活用されています。このイベントAPIはマルチスレッド下で十分な速度を出すために実装上の様々な工夫がなされています。
MN-Coreランタイムに関わる面白さ
最後に、MN-Coreランタイムに関わる面白さについて少し述べます。
ランタイムの面白さは文字通り眼の前のMN-Coreの実機を自分で動かすことができる点にあります。先日MN-Core 2の試用クラスタを訪問する機会があったのですが、このクラスタに命令列やデータを流しているプログラムを思い浮かべながら見ると感慨深いものがありました。下は命令列が流れているMN-Core 2の様子です。

まとめ
MN-Coreコンパイラが生成した命令列と入力データをMN-Coreに転送し、計算結果を得るMN-Coreランタイムについて紹介しました。ランタイムにはまだまだおもしろい部分があり、特にMN-CoreのためのバイナリフォーマットやイベントAPIの詳細についてはまた別途、紹介する予定です。これらの話題に興味がある方はぜひ、MN-Core向けのコンパイラエンジニア に応募してください。
関連記事へのリンク
