Blog
本記事は、2022年夏季インターンシッププログラムで勤務された灘洋太郎さんによる寄稿です。
導入
MN-CoreTMはPreferred Networksで開発されている深層学習アクセラレータです。
本プロセッサは演算を高速かつ高効率で行うことに特化しており、ニューラルネットワークに加え物理シミュレーション等にも活躍の場を広げています。その一方で、ソフトウェアが制御する要素は数多く、その自由度とそれに伴う困難に対応するため、コンパイラの改良は日々行われています。
PFN・神戸大学共同開発の深層学習用プロセッサーMN-Core™を用いた重力多体計算に関する研究と電力評価で、神戸大学の遠藤克浩先生が電子情報通信学会 集積回路研究会のグリーン高度計算科学賞を受賞されました。おめでとうございます🎊https://t.co/KUXfuNXLWL
— Preferred Networks (@PreferredNetJP) September 16, 2022
MN-Coreの特徴
今回のインターンシップでは、MN-Coreのコンパイラから最適化ヒントを出力する機能を開発しました。本記事では、その特徴について説明します。
MN-Coreの特徴として、コンパイル時にハードウェアの挙動の大半が決定されることがあります。これは、現在主流のアーキテクチャと異なり、MN-Coreでは静的に命令をスケジュールするためです。つまり、各サイクルごとにどのようなデータ転送や演算が行われるかは、全てコンパイル時に決定されます。これによって動的スケジューリングに必要なハードウェア機構を省き、高い電力効率を達成しています。
このような静的スケジューリングが可能なのは、MN-Coreが以下の特徴を持つためです。
- 条件分岐を持たない
- メモリと演算器の間にキャッシュ構造を持たない。その代わり、演算器の近くに大量のSRAMを搭載している
MN-Coreの入力プログラムは、MN-Core上の処理を抽象的に表したDSLを用いて記述されます。命令スケジューリングの際には、この入力プログラム中の処理を実行順に並べて機械語命令列を生成します。この並べ替えは、処理間のデータ依存や、ハードウェア資源の競合(ハザード)といった制約を考慮して行われます。
モチベーション
今回のインターンでは、「命令スケジューリング中に、コンパイラがどのような判断をして命令列を並べているか」という情報を、わかりやすい形でプログラマに提示し、最適化に役立ててもらうことを目指しました。現状では、スケジューリング過程の詳細を知るためには、複雑なコンパイラ中間表現を直接観察する以外の手段がありませんでした。
実装
これを達成するため、以下の二つの機能をMN-Coreコンパイラに実装しました。
- 命令スケジューリングの過程で発生したハザードの詳細をログに出力
- 最適化可能なパターンを自動で発見し、最適化ヒントとして出力
また、これらのログ・ヒントがプログラム中のどこに対応しているのかを表示する機能も実装しました。具体的には、ログ・ヒントに対応する
- 入力プログラム中の箇所
- コンパイル後に出力される機械語命令列中の箇所
を、ログ・ヒントと併せて出力しました。この機能により、入力プログラム中のどこに問題があって、どのような出力命令列になってしまっているのか、ということが簡単にわかるようになりました。
加えて、これらの機能が高速に動作するように、似た命令列・ハザードを自動でグループ化する機能も追加しました。先述の通りMN-Coreには条件分岐が存在しないため、ループは全てコンパイラによってアンロールされます。このため、機械語命令中に似た命令列が何度も繰り返し出現することがあります。このような命令列を一つのグループにまとめ、ログ出力や最適化可能なパターンの検知をグループごとに一回のみ行うことで、ログやヒント出力が軽量に行えるようになりました。
さらにログ出力の際には、出現頻度の高い種類のハザードから順に表示するようにしました。これにより、性能への影響が大きいハザードを簡単に見つけることができます。
結果

出力されるログ・ヒント(図1)
図1に、実装したログ・ヒント出力の例を示しました。上から順に、ハザードの出現頻度・ハザードを起こした入力プログラムの位置・不足していたハードウェア資源・ハザードを起こした機械語命令・最適化ヒント、が表示されています。この例はConvolutionと呼ばれるレイヤ実装のもので、ローカルメモリ(LM)から読み出し(RL)、2種の処理(E1 / E2)を行い、またローカルメモリへ書き戻す(WL)処理中に発生したハザードに関するものです。
この場合で不足しているハードウェア資源はSRAMのポート数であり、書き込みに使用している間は読み出しが行えないため、後続の命令はその書き込みが完了するまで待機する必要があります。このようなパイプライン中のバブルを図示したものが図2です。図中の相対アドレス軸は各種メモリのアドレス遷移を意味しています。
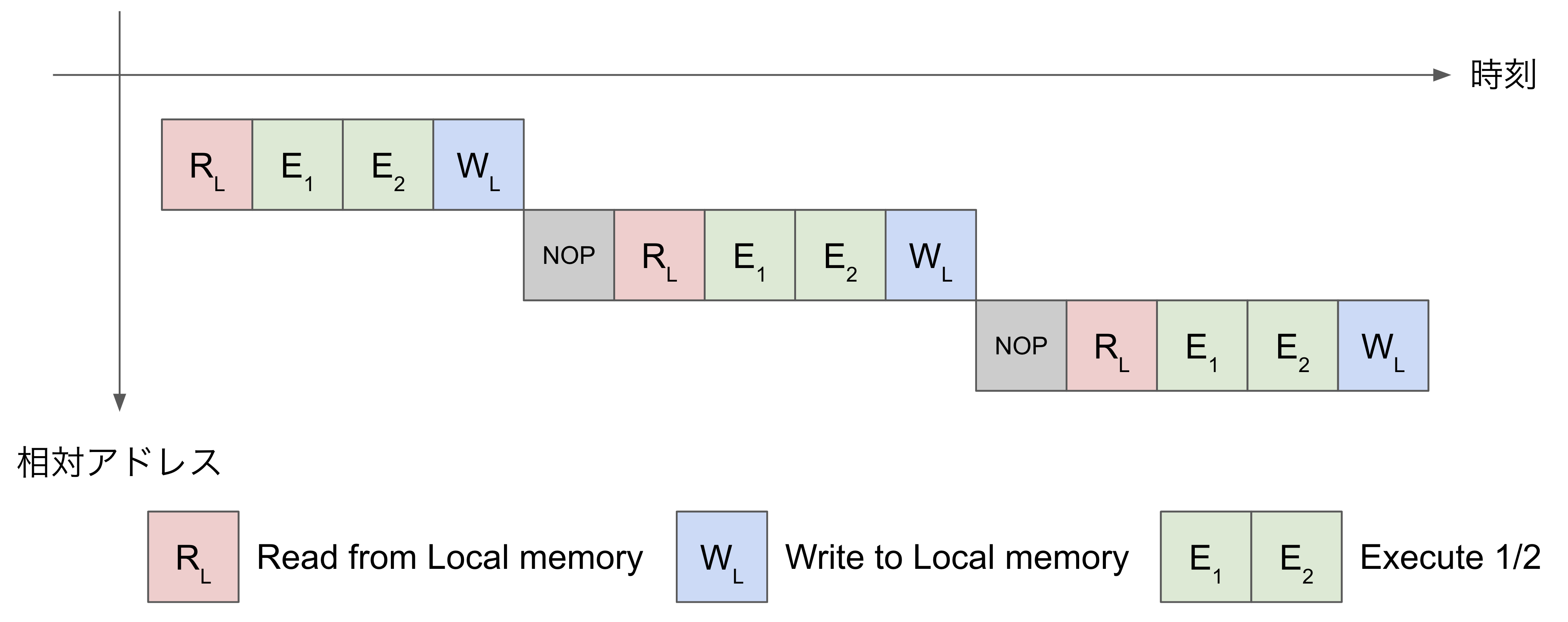
改善前のパイプライン処理(図2)
ここで最適化ヒントを見ると “To delay the write, convert ti to GRF” とあります。これはE1の処理内容を一時的にレジスタファイル(GRF)へ書き出し(WR)、E2は改めてレジスタファイルから読み出して(RR)から処理すると良い、という旨を意味しています。これを実装すると図2のパイプラインが改善されて図3のパイプラインとなり、バブルを取り除くことによる命令列の短縮(=実行時間の短縮)が達成されます。
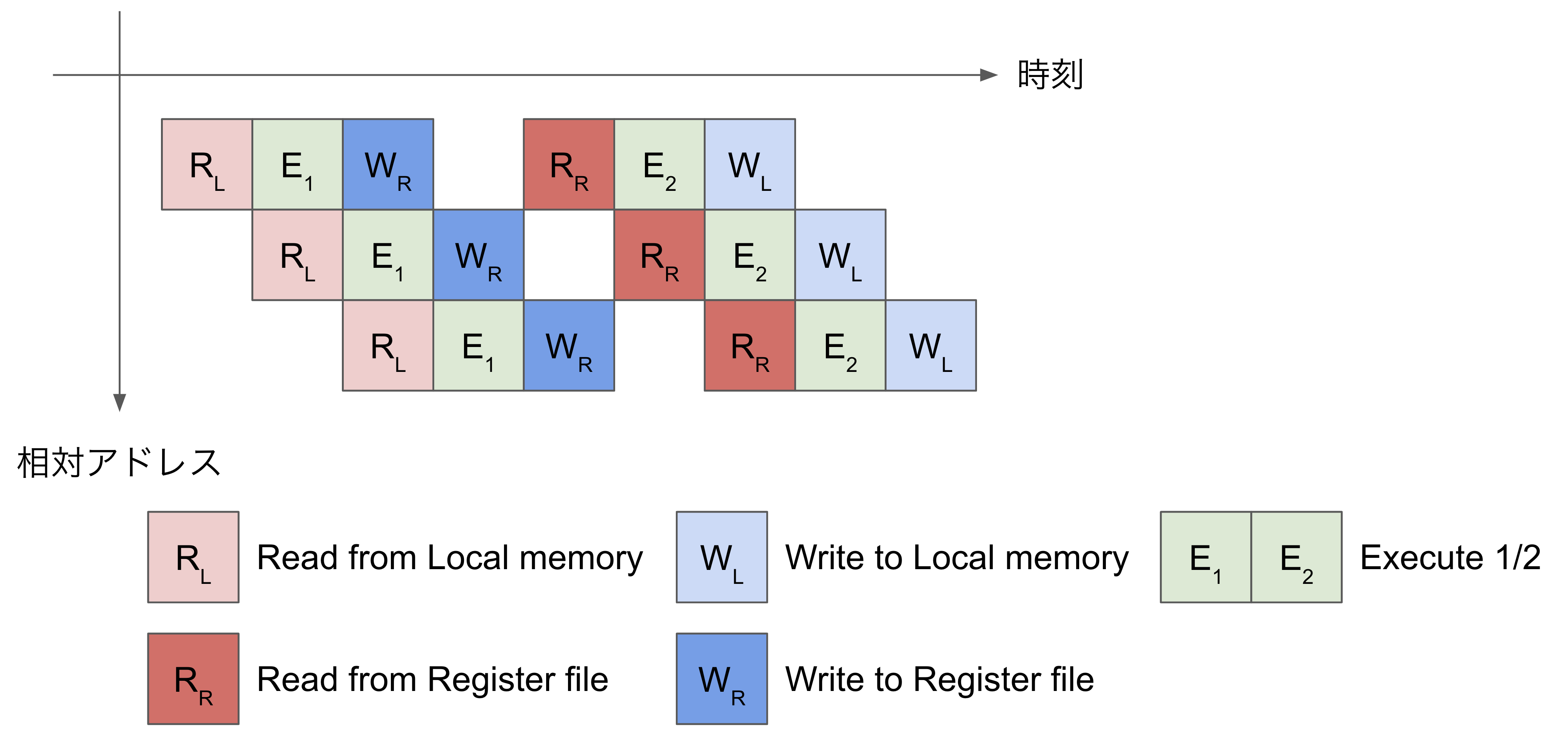
改善後のパイプライン処理(図3)
ここで登場したレジスタファイルはポート数がローカルメモリと比較して多く、一時的に計算結果を置いて複数の処理を行う際に利点があります。その代わりに容量がローカルメモリと比較して少ないという欠点があり、プログラマが適切に使い分ける必要があります。また、この最適化ヒントに沿った実装は追加のレジスタファイルを消費することになるため、前後のコードと消費量についてバランスを取る必要があります。後述する、本成果を最適化ヒントに留めている理由の一つです。
最後に改善前(図2)と改善後(図3)に相当するアセンブリ列は図4のようになります。一部オペランド・オペコードは説明中の変数に置き換えています。局所的ではありますが、このように実行にかかる時間は73ステップから48ステップに短縮し、3割強の高速化が達成されました。

改善前後のアセンブリ列(図4)
将来の展望
【結果】セクションで述べたように、実装したログ・最適化ヒントは実際に性能向上に役立つことが実証されました。今後はこういったヒントを活かして、既存のプログラムの最適化可能な箇所を見つけたり、新規に実装するプログラムをより高速なものにしていくことができます。
また、メモリ書き込みを遅らせるなどの改善案が見つかった時点で、ヒントという形ではなく実際に最適化に組み込むことが出来れば、今後はより完結な記述で高速なプログラムが出力できるはずです。しかし、上述したように前後とのメモリ消費の兼ね合いなどから、改善案の実装が大局的に見て常に良い変更であることを保証するのは難しく、今後の課題です。
感想
以前から気になっていたMN-Coreを触ることができ、大変楽しかったです。また、チップやソフトウェアスタックを色々と見せていただいたのですが、これら全てを自社で用意しているのは本当に途方もないことなんだなぁと実感しました。
末筆にはなりますが、メンター・副メンターをやってくださった樋口さん、押川さんにはとてもお世話になりました。僕は普段CPUアーキテクチャ周りの研究をやっており、アクセラレータは触ったことがなかったのですが、丁寧なメンタリングのおかげでつつがなくインターンを終えることができました。この場をお借りして、お礼申し上げます。
Area



