Blog
ハイパーパラメータ自動最適化フレームワーク「Optuna」のベータ版を OSS として公開しました。この記事では、Optuna の開発に至った動機や特徴を紹介します。
![]()
ハイパーパラメータとは?
ハイパーパラメータとは、機械学習アルゴリズムの挙動を制御するパラメータのことです。特に深層学習では勾配法によって最適化できない・しないパラメータに相当します。例えば、学習率やバッチサイズ、学習イテレーション数といったようなものがハイパーパラメータとなります。また、ニューラルネットワークの層数やチャンネル数といったようなものもハイパーパラメータです。更に、そのような数値だけでなく、学習に Momentum SGD を用いるかそれとも Adam を用いるか、といったような選択もハイパーパラメータと言えます。
ハイパーパラメータの調整は機械学習アルゴリズムが力を発揮するためにほぼ不可欠と言えます。特に、深層学習はハイパーパラメータの数が多い傾向がある上に、その調整が性能を大きく左右すると言われています。深層学習を用いる多くの研究者・エンジニアは、ハイパーパラメータの調整を手動で行っており、ハイパーパラメータの調整にかなりの時間が費やされてしまっています。
Optuna とは?
Optuna はハイパーパラメータの最適化を自動化するためのソフトウェアフレームワークです。ハイパーパラメータの値に関する試行錯誤を自動的に行いながら、優れた性能を発揮するハイパーパラメータの値を自動的に発見します。現在は Python で利用できます。
Optuna は次の試行で試すべきハイパーパラメータの値を決めるために、完了している試行の履歴を用いています。そこまでで完了している試行の履歴に基づき、有望そうな領域を推定し、その領域の値を実際に試すということを繰り返します。そして、新たに得られた結果に基づき、更に有望そうな領域を推定します。具体的には、Tree-structured Parzen Estimator というベイズ最適化アルゴリズムの一種を用いています。
Chainer との関係は?
Optuna は Chainer を含む様々な機械学習ソフトウェアと一緒に使うことができます。
Chainer は深層学習フレームワークであり、Optuna はハイパーパラメータの自動最適化フレームワークです。例えば、Chainer を用いたニューラルネットの学習に関するハイパーパラメータを最適化する場合、Chainer を用いるユーザーコードの一部に Optuna からハイパーパラメータを受け取るコードを書くことになります。それを Optuna に渡すことによって、Optuna が自動的に何度もそのユーザーコードを呼び出し、異なるハイパーパラメータによりニューラルネットの学習が何度も行われ、優れたハイパーパラメータが自動的に発見されます。
社内では Chainer と共に用いられているユースケースがほとんどですが、Optuna と Chainer は密結合しているわけではなく、Chainer の以外の機械学習ソフトウェアとも一緒に使うことができます。サンプルとして、Chainer の他に scikit-learn, XGBoost, LightGBM を用いたものを用意しています。また、実際には機械学習に限らず、高速化など、ハイパーパラメータを受け取って評価値を返すようなインターフェースを用意できる幅広いユースケースで利用可能です。
なぜ Optuna を開発したのか?
ハイパーパラメータの自動最適化フレームワークとして、Hyperopt, Spearmint, SMAC といった有名なソフトウェアが既に存在しています。そんな中でなぜ Optuna を開発したのでしょうか?
複数の理由やきっかけがありますが、一言で言うと、我々の要求を満たすフレームワークが存在せず、そして既存のものよりも優れたものを作るアイディアがあったからです。また、実際には、機能面だけではなく品質面でも、既存のフレームワークにはレガシーなものが多く、不安定であったり環境によって動作しなかったり修正が必要だったりという状況でした。
Optuna の特徴
Define-by-Run スタイルの API
Optuna は Define-by-Run スタイルの API を提供しており、既存のフレームワークと比較し、対象のユーザーコードが複雑であっても高いモジュール性を保ったまま最適化を行うことを可能とし、またこれまでのフレームワークでは表現出来なかったような複雑な空間の中でハイパーパラメータを最適化することもできます。
深層学習フレームワークには Define-and-Run と Define-by-Run という 2 つのパラダイムが存在します。黎明期は Caffe など Define-and-Run のフレームワークが中心でしたが、PFN の開発した Chainer は Define-by-Run のパラダイムを提唱し先駆けとなり、その後 PyTorch が公開され、TensorFlow も 2.0 では eager mode がデフォルトになるなど、今では Define-by-Run のパラダイムは非常に高く評価されており、標準的にすらなろうとする勢いです。
Define-by-Run のパラダイムの有用性は、深層学習フレームワークの世界に限られたものなのでしょうか?我々は、ハイパーパラメータ自動最適化フレームワークの世界でも同様の考え方を適用できることに気づきました。この考え方の下では、全ての既存のハイパーパラメータ自動最適化フレームワークは Define-and-Run に分類されます。そして Optuna は Define-by-Run の考え方に基づき、既存のフレームワークと大きく異なるスタイルの API をユーザに提供しています。これにより、ユーザプログラムに高いモジュール性を持たせたり複雑なハイパーパラメータ空間を表現したりといったことが可能になりました。

学習曲線を用いた試行の枝刈り
深層学習や勾配ブースティングなど、反復アルゴリズムが学習に用いられる場合、学習曲線から、最終的な結果がどのぐらいうまくいきそうかを大まかに予測することができます。この予測を用いて、良い結果を残すことが見込まれない試行は、最後まで行うことなく早期に終了させてしまうことができます。これが、Optuna のもつ枝刈りの機能になります。
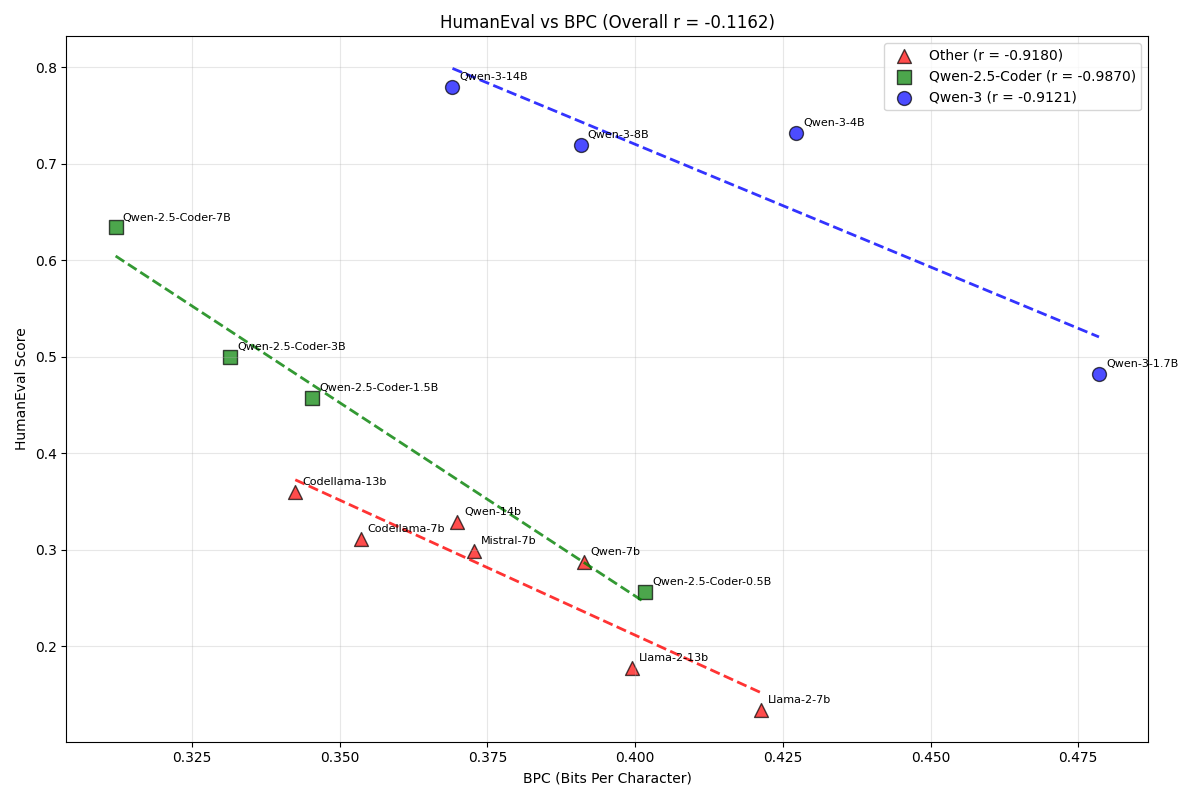
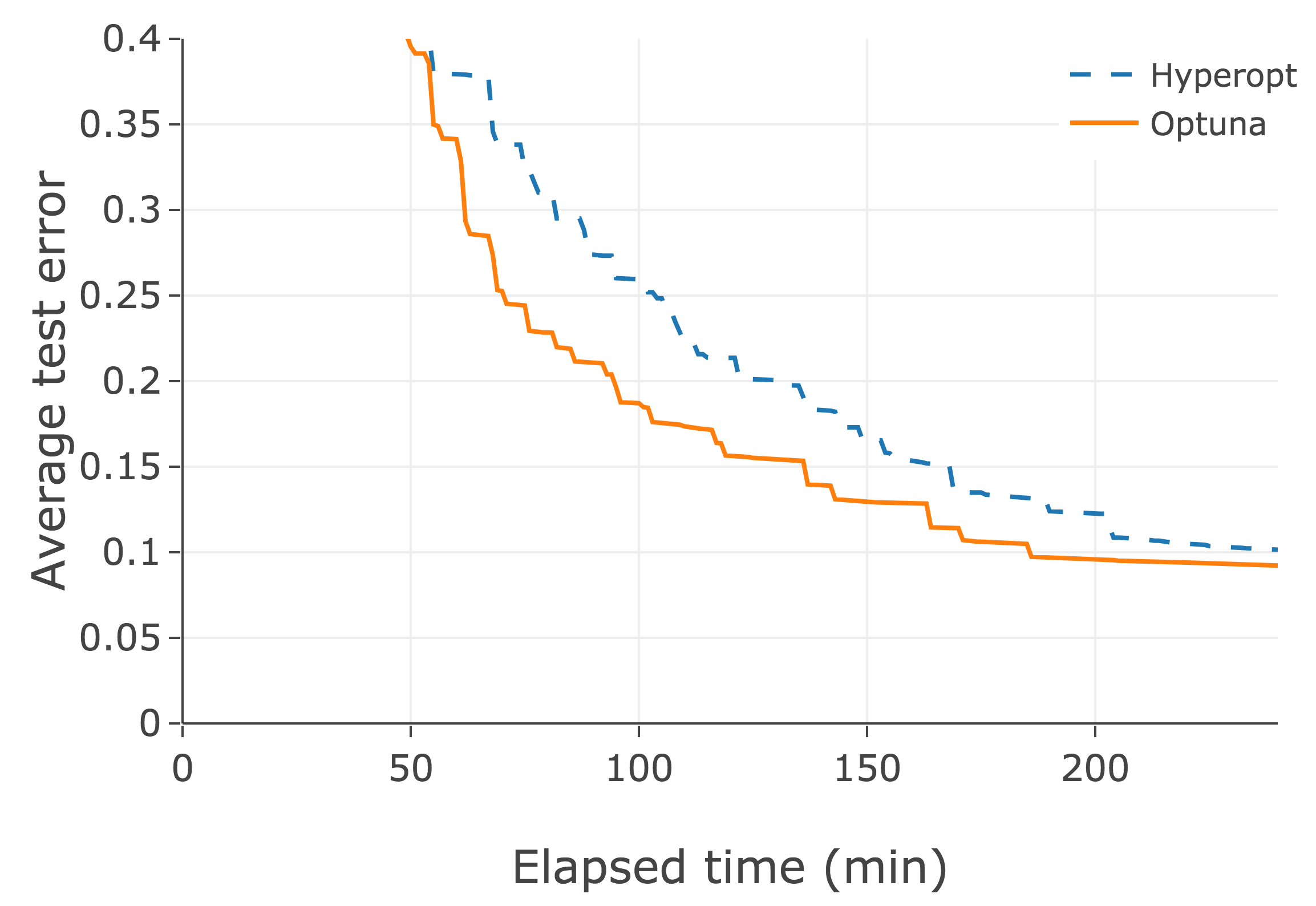
Hyperopt, Spearmint, SMAC 等のレガシーなフレームワークはこの機能を持ちません。学習曲線を用いた枝刈りは、近年の研究で、非常に効果的であることが分かっています。下図はある深層学習タスクでの例です。最適化エンジン自体は Optuna も Hyperopt も TPE を用いており同一であるものの、枝刈りの機能の貢献により、Optuna の方が最適化が効率的になっています。
並列分散最適化
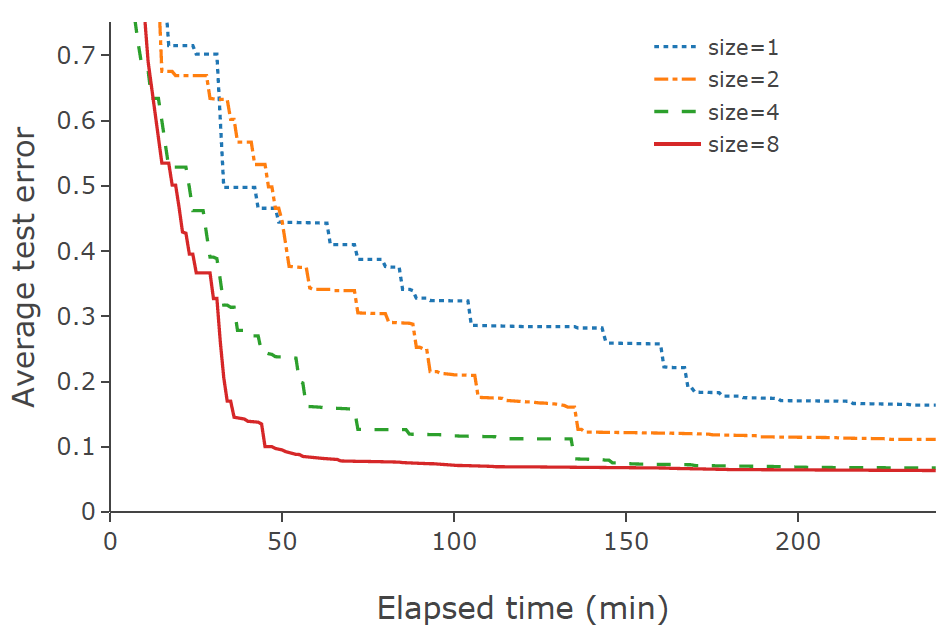
深層学習は計算量が大きく一度の学習に時間がかかるため、実用的なユースケースでのハイパーパラメータの自動最適化のためには、性能が高く安定した並列分散処理を簡単に使えることが必要不可欠です。Optuna は複数ワーカーを用いて複数の試行を同時に行う非同期分散最適化をサポートします。下図のように、並列化を用いることで最適化は更に加速します。下図はワーカー数を 1, 2, 4, 8 と変化させた場合の例ですが、並列化により最適化がさらに高速化されていることが確認できます。
また、Chainer の分散並列化拡張である ChainerMN との連携を容易にする機能も用意されており、最適化対象の学習自体が分散処理を用いるような場合にも Optuna を簡単に使うことができます。これらの組み合わせにより、分散処理が含まれた目的関数を並列に分散実行するようなこともできます。
ダッシュボードによる可視化(実装中)
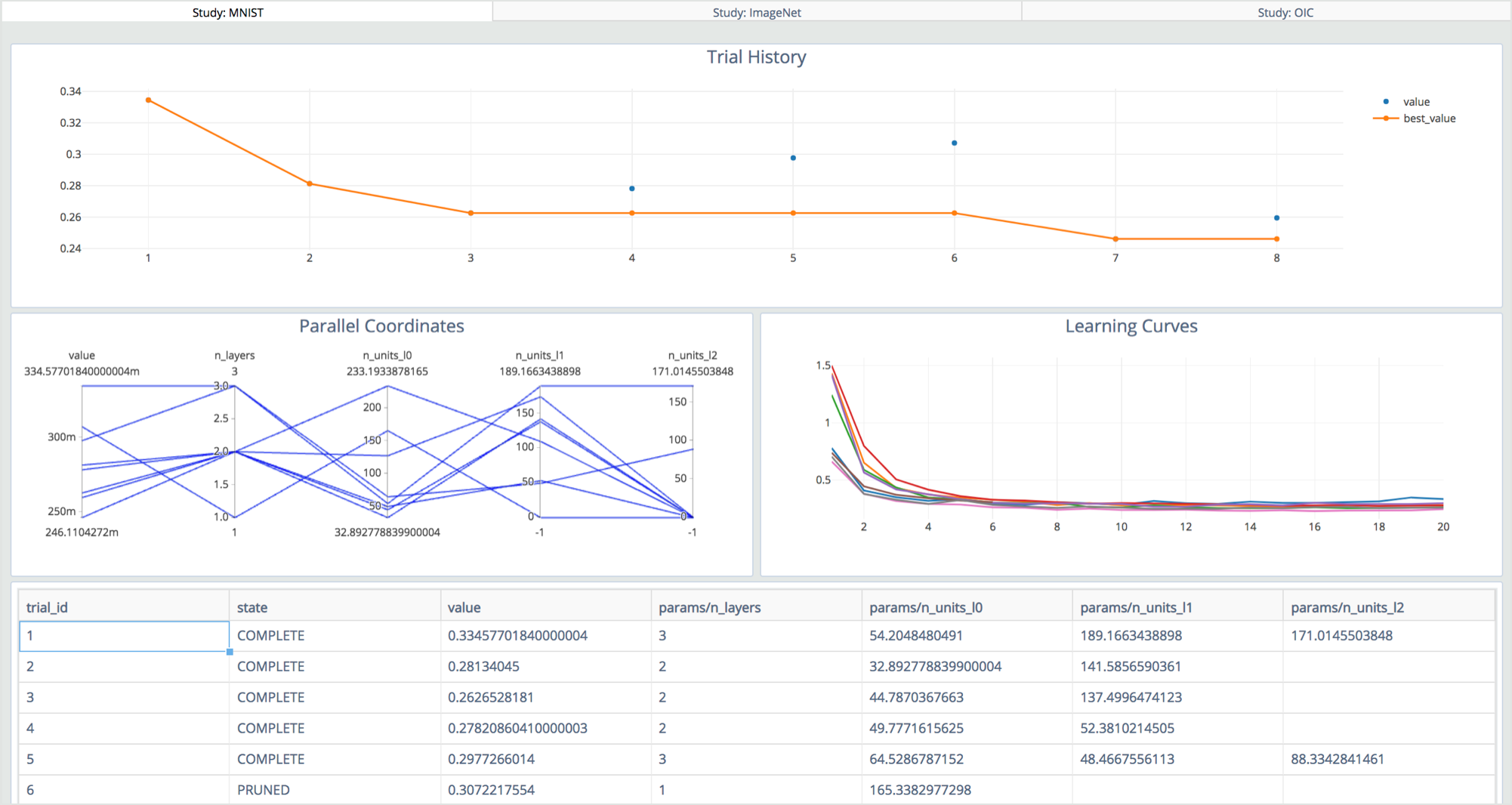
最適化の過程を見たり、実験結果から有用な知見を得たりするために、ダッシュボードを用意しています。1 コマンドで HTTP サーバが立ち上がり、そこにブラウザで接続することで見ることができます。また、最適化過程を pandas の dataframe 等で export する機能もあり、それらを用いてユーザがシステマチックに解析を行うこともできます。
終わりに
Optuna は既に複数の社内プロジェクトで活用されています。例えば、今夏準優勝を果たした Open Images Challenge 2018 でも用いられました。今後も活発に開発は続けられ、完成度の向上と先進的な機能の試作・実装の両方を精力的に進めていきます。現段階でも他のフレームワークと比較し Optuna を利用する理由は十分存在すると我々は考えています。お試し頂きお気づきの点があれば忌憚のないフィードバックを頂ければ幸いです。
先日開催された第 21 回情報論的学習理論ワークショップ (IBIS’18) では、弊社でのインターンシップにおける成果であるハイパーパラメータ自動最適化に関する研究を 2 件発表しました。これらは Optuna を実際に利用している中で出てきた問題意識に基づいており、成果はいち早く Optuna に組み込むことを目指して取り組んでいます。こういった技術により Optuna を更に優れたものとしていければと考えています。
我々の目標は、深層学習関連の研究開発をできるだけ加速することです。ハイパーパラメータの自動最適化はそのための重要なステップとして取り組んでいますが、他にも既にニューラルアーキテクチャー探索や特徴量の自動抽出といった技術に関しても取り組みを開始しています。PFN では、こういった領域や活動に興味を持ち一緒に取り組んでくれるメンバーをフルタイム・インターンで募集しています。