Blog
Preferred Networks(以下PFN)の子会社のPreferred Elements(以下PFE)では2月より1,000億(100B)パラメータ規模のLLM、「PLaMo-100B」の開発を行ってきました。このPLaMo-100Bの開発に関して、5月に事前学習部分はひと段落したので、今回の記事ではこのモデルの事前学習部分に関して紹介します。
この「PLaMo-100B」の開発は経済産業省が主導する国内の生成AIの開発力を強化するためのプロジェクト「GENIAC(Generative AI Accelerator Challenge)」のもと、NEDO(国立研究開発法人新エネルギー・産業技術総合開発機構)の助成事業に採択され、計算資源の提供支援を受けて実施しました。
PLaMo-100Bの事前学習の概要
学習済みモデルを元に日本語データなどで追加学習を行うLLMは多くの成功を収めています。こうしたアプローチは大量の計算資源を投入した事前学習で獲得した知識や能力を効果的に利用でき、少量の投入計算資源で優れたモデルを作ることができます。その一方、事前学習時にどのような学習データを使ったのかは不明であったり制御することができません。どのようなデータを使ってどのように学習したのかを制御できるようになることは、今後、LLMが重要な用途で使われていく上で重要な要素となります。こうしたことからLLMの開発においてPFEではデータ収集、事前学習から全て自社で行っています。
今回開発したPLaMo-100Bの事前学習モデルでは、日本語と英語の両方のテキストデータを合計2T token学習しました。学習データに関しては基本的に公開データセットに加えて、独自に作成したデータなどを含めて学習し、JGLUEのような日本語ベンチマークで高い精度を達成することを目指して開発しました。
このPLaMo-100Bの事前学習モデルと簡単に指示学習した暫定版の指示学習済みモデル、あといくつかのモデルに関して、日本語の評価としてJaster、 英語の評価としてMMLUの結果を以下に示します。
ベンチマーク評価結果
| Jaster (4-shot, average)* | MMLU (5-shot, acc)** | 備考 | |
|---|---|---|---|
| PLaMo-13B | 0.325 | 0.248 | PFE社内で測定 |
| PLaMo-13B-Instruct-NC | 0.274 | 0.258 | PFE社内で測定 |
| tokyotech-llm/Swallow-70b-hf | 0.685 | 0.658 | PFE社内で測定 |
| tokyotech-llm/Swallow-70b-instruct-v0.1 | 0.705 | 0.669 | PFE社内で測定 |
| abeja/Mixtral-8x7B-Instruct-v0.1 語彙拡張継続学習(学習途中モデル) | 0.685 | – | ABEJAのブログ参照 |
| abeja/Mixtral-8x7B-Instruct-v0.1 語彙拡張継続学習差分マージ(学習途中モデル) | 0.708 | – | ABEJAのブログ参照 |
| GPT-3.5 turbo | 0.656 | – | GENIAC 内での Weights & Biases による評価値 |
| GPT-4 turbo | 0.772 | – | GENIAC 内での Weights & Biases による評価値 |
| PLaMo-100B | 0.678 | 0.603 | PFE社内で測定 |
| PLaMo-100B (指示学習済み、5/13 暫定版) | 0.712 | 0.569 | PFE社内で測定 |
*: GENIACで評価に使われるllm-leaderboard (g-leaderboardブランチ) を使用
**: Language Model Evaluation Harnessを使用
PLaMo-100Bは以前開発したPLaMo-13Bよりもモデルサイズが大きくなっている、学習token数が増えている、学習データの質が向上しているなど様々な要因でスコアが上昇しました。
また、事前学習モデルは指示学習を行う前のモデルであるため、うまく指示に従わず、精度が低くなるケースがあります。このため、指示学習を行うことでスコアが上がることを確認するために、指示学習を簡単に行った評価結果も示しました。この結果、Jasterの4-shotに関してはスコアが上昇して、GPT-3.5 turbo、 Swallow-70bなどよりも高いスコアに達することを確認できました。
なお、MMLUは同じサイズの他モデルと比べて性能が劣っています。この理由の一つとして、以前は学習データとしてよく使われていたBooks3を、今回の学習では知的財産権や著作権侵害の疑いがあるとして使っていないことが挙げられます。こうしたデータは教科書データなどを含んでおりMMLUスコア向上に貢献していますが、本開発ではスコア改善よりも、権利侵害の可能性がある学習データは使わないという方針をとっています。
より詳しい評価方法に関してはAppendixに記載してあります。
このPLaMo-100Bの事前学習部分の開発に関して、この記事では大きく学習データとモデルの学習について以降で紹介していきます。
事前学習に使用したデータセット
PLaMo-100Bでは前半1.5T token、後半0.5T tokenと分けて学習を行いました。おおよそ以下のような比率で学習を行い、前・後半で学習データセットの比率を変えています。
事前学習に用いたデータセットの言語別比率(英語にはプログラミング言語を含む)
| 学習token | 1.5T | 0.5T |
|---|---|---|
| RefinedWeb | 42% | 17% |
| その他英語データセット | 28% | 33% |
| CommonCrawl由来の 日本語データセット |
18% | 46% |
| その他日本語データセット | 12% | 4% |
英語データセットは1.3T token、日本語データセットは0.7T tokenが事前学習で必要となります。特に日本語データセットは、十分に質が高いといえるものを公開データセットから集めるのは難しいと考えました。そこでCCNetやRefinedWebと同様に、CommonCrawlがアーカイブするウェブクロールされたデータから日本語データセットを作成しました。
日本語データセットの作成
もともとCommonCrawl由来のデータセットはCCNetをベースに作成していましたが、後半の0.5 T tokenの部分で利用する日本語データに関しては、ゼロから前処理の実装し、2017年から2024年中の20 dumpを処理し約460B tokenのデータセットを作成しました。
ゼロから実装した理由は大きく分けると2点です。
- CCNetが処理しているWETファイルではHTMLやMarkdownなどが持つ構造化された情報を得られないため、WARCファイルを処理したい
- 知見がたまり、ゼロベース実装でも効率的にデータセット作成ができる確度が上がった
処理パイプラインはRefinedWebやSwallow Corpusを参考に、WARCフォーマットで保存されているraw archived dataを以下の流れで処理しました。
- WARCファイルをダウンロードしながら、日本語のHTMLおよびテキストファイルを抽出する
- 抽出したデータがHTMLの場合はMarkdownに変換する
- llm-jp corpus filterを使い、全文書をフィルタリング
- MinHashを用いて全dumpについて重複除去
- データセットとして読み出せるように均等サイズにre-sharding
CommonCrawlは数GiB程度に分割されおり、MinHashを除き完全並列化が可能です。今回は1000並列で各処理を行い、1つの分割あたり1-3までの工程は約30時間、4が約24時間、5が数時間程度で構築しました。
モデルの学習安定化
モデルを安定して学習することはLLMの事前学習において重要な課題の1つと言えます。LLMの学習では、モデルが大きくなるほど学習が不安定になることが知られています [PaLM]。
PLaMo-100Bの事前学習では、モデルアーキテクチャ、損失関数の2点の工夫でこの課題に取り組みました。
今回の事前学習においてこれらの取り組みがどの程度意味があったかは不明です。実際の学習では学習が不安定になることなく事前学習が終わりましたが、これが以下に述べる取り組みの効果なのか、そもそも学習が不安定にはならない設定だったのかは切り分けができていないためです。切り分けのためには今回の学習と同じ規模の学習をもう一度行う必要があり、現実的ではないと考えています。
一方、事前の動作確認ややり直しが難しい大規模な事前学習において、予防的な取り組みをすることは必須であったと考えています。
QK Normalization
PLaMo-100BのアーキテクチャはLlama2、Llama3とほぼ同じです。
ここにQK Normalizationを学習安定化のための変更として取り入れました。既存研究において、attentionの計算を安定化させる効果があるとされています。
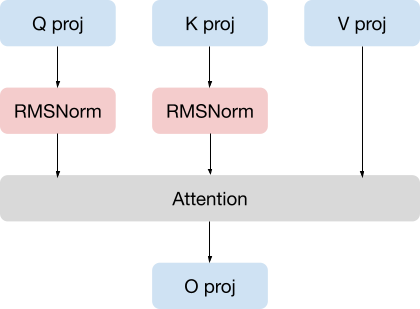
QK NormalizationつきのSelf Attentionレイヤ
自社クラスタで行った予備実験では、QK Normalizationはモデルの性能を落とさないことを確認できました。
token間でのinteractionの前に正規化層をいれることにより学習が安定化するという報告は他の論文 (Jamba、Chameleon など) でもされており、大規模なモデルでは一般的な手法になる可能性がありそうです。
Z Lossの追加
損失関数では、z lossを追加しました。これはsoftmax cross entropyの数値安定性を確保するためのloss関数です。QK Normalization同様、既存研究において学習を安定化させる効果があるとされています。
z lossの式としては以下の通りです。
\[L(x)=\left(\log\left(\sum_{i=0}^{C} \exp(x[i])\right)\right)^2\]
QK Normmalization同様、モデルの性能を落とさないことを自社クラスタの実験で確認できました。もともとの目的である学習安定化の効果は不明ですが、z lossによる悪影響は今の所確認できていません。
また、z lossは学習の状態を確認するmetricとしても役立っています。何らかの理由 (バグなど) で学習がうまくいかない時、他の損失関数やdownstream taskの結果よりもz lossの値の変化のほうが大きいことが多く、試行ごとの結果のブレなのかどうかの判断がz lossは容易だったためです。
効果がなかった設定
最終的に学習安定化のために導入した手法2つを紹介しましたが、他の手法も試しました。
ここでは、試したものの効果がなかった、あるいは逆効果だったものを紹介します。
Parallel Layers
PLaMo-13Bの時には、高速化を考慮した工夫としてparallel layersを導入していました。これは昨年時点ではparallel layersの有無で性能差がほぼ見られなかったためです。
しかし、開発を進めるにつれて、parallel layersを導入することによるモデル性能の劣化が目立つようになりました。そのため、PLaMo-100Bでは通常のtransformerの構造をとることとしました。

Embeddingの正規化
いくつかの論文 (8-bit Optimizerなど) では、埋め込み層 (embedding) の出力を正規化により、学習が安定化したりLLMの性能が向上したと報告されています。
我々も検証しましたが、
- perplexityの点では若干の性能向上が見られる
- decodeを必要とするタスク (JSQuADなど) で性能の劣化が見られる
という一長一短の結果となりました。decodeによる単語生成はinstruction tuningの領分であり事前学習ではperplexityの方を重視するという考え方もありえますが、リスクが大きいと考え今回の学習では採用しませんでした。
Sequence Length Warmup
学習の高速化やモデル性能向上の観点でsequence length warmupが有効であるという報告がされています (https://speakerdeck.com/iwiwi/stability-ai-japanniokeruda-gui-mo-yan-yu-moderunoyan-jiu-kai-fa など)。
sequence length warmupは学習前半は学習データの系列長を短くし、学習が進むにつれて徐々に文章を長くしていく手法です。
これについて検証したところ、ほぼ効果がないという結論になりました。
論文を精査すると、sequence length warmupはlarge batch problemを解消する手段であり、モデルが大きくなるとbatch sizeを大きくしても問題なく学習できる (Scaling Law for Neural Language Models) ので我々の設定では意味がなかったのだと考えられます。
事前学習の高速化
我々がPLaMo-100Bの事前学習をはじめた2024/2時点では、H100を使用した100BクラスのLLMの学習事例は存在しませんでした。
H100を使用して学習する場合、A100を利用する時には気にならなかった細かいオーバーヘッドが問題になることが予想されます。H100は非常に高い計算速度 (FLOP/s) をだせるアクセラレータであるため、計算が律速とならない部分が相対的に時間がかかるようになるためです。
今回、様々な取り組みを行い学習速度の向上に努めました。この中にはFP8 TensorCoreを効率よく利用するなど公開されている情報を元にした一般的な取り組みもありますが、実際に学習をしないとわからなかったこともいくつかありました。
ここでは、そのような一般的でないものについて2つ紹介します。
Zero Bubbleの採用
100Bモデルの学習のため、3D parallelism ([Megatron-LM]) を利用しました。3D parallelismはでデータ並列 (data parallelism) 及び2つのモデル並列 (tensor parallelism・pipeline parallelism) を組み合わせることで大規模なモデルの学習を実現する手法です。
Pipeline Parallelismでは、zero bubbleを採用しました。pipeline parallelismは一部のGPUが処理をできない時間 (bubble) がありこれが計算効率を低下させることがしられていますが、zero bubbleは理想的にはこのbubbleを0にすることができます。

一般的なPipeline parallelismの実行 (Zero Bubble)
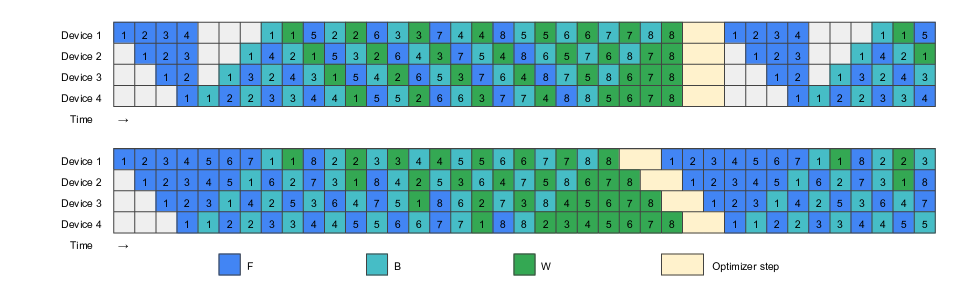
Zero Bubbleによる実行 (Zero Bubble)
ただし、zero bubbleで導入された投機的なパラメータ更新については採用していません。理由は以下の2つです。
- 1 iterationの境目がpython scriptで曖昧になりデバッグがむずかしくなること
- gradient clippingが常にかかっており、投機実行がうまくいくiterationがほとんどなかったこと
後者については、論文における結果と食い違っています。論文中ではgradient clippingが適用されることは稀であると報告されていました。この差は論文と我々との間のモデルサイズの違いによるものと考えています。
lm-head (単語予測のためのLinear層) の数値精度
PLaMo-100BをはじめとするLLMはTransformer Blockの繰り返しで構成されますが、最後に次の単語を予測するためのlinear層が必要です。huggingfaceのtransformersで利用できるモデルではlm_headという名前で呼ばれることが多いレイヤです。
当初、学習高速化のためにこのレイヤもFP8で計算するようにしていました。
しかし、train lossの点ではほぼ問題なかったものの、後続のベンチマークタスクの性能が悪いという問題がみつかりました。
小規模な実験設定で調査していくと、前述のz lossの値がFP8を使うことで非常に高くなっていることがわかり、lm_headはFP8で計算してはいけないことが判明しました。
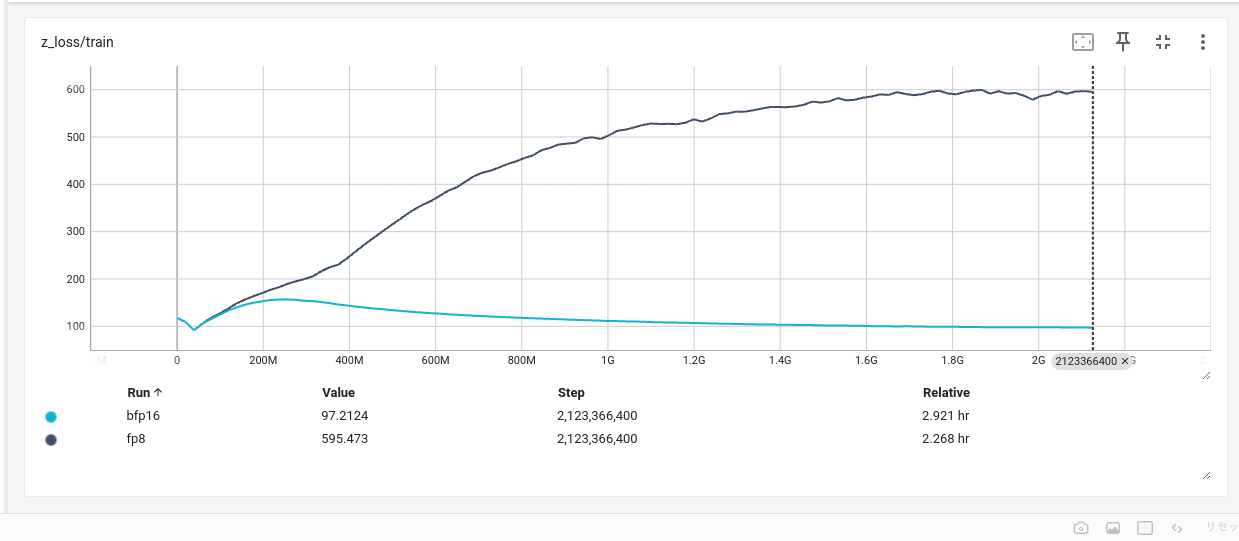
lm_headでbfloat16を使った時とfp8を使ったときのz lossの差
事前学習の高速化による結果
上記のような最適化の結果、PLaMo-100Bでは 540TFLOP/s/GPU 程度の計算速度を達成しました。H100のFP8における理論速度 1979 TFLOP/sの約27 %にあたります。
使用するGPU数などが違うため単純な比較はできませんが、Llama3やmosaiclmのベンチマークと比較しても遜色ない性能と言えると考えています。
最後に
今回はPLaMo-100Bの事前学習の部分について紹介しました。現在はこの事前学習モデルに対して、指示学習や画像や音声のマルチモーダルモデルの開発、1Tパラメータ規模のモデルの検証準備などをしています。今後もいくつか記事を公開する予定です。また、今回開発したPLaMo-100Bに関しては何等かの形でモデルの重みを公開することを検討しています。
仲間募集中
PFN/PFEでは今後もLLMの開発を継続して行っていきます。開発は今回紹介した以外にも多岐に渡ります。我々はこれらの課題に情熱をもって挑戦していく仲間を募集しています。
これらの仕事に興味がある方はぜひご応募よろしくお願いします。
https://www.preferred.jp/ja/careers/
Appendix
今回評価に使ったJasterとMMLUについて簡単に説明します。
今回は日本語の評価として、GENIACで評価に使われるllm-leaderboard (g-leaderboardブランチ) のJasterの4-shotの平均を示しています。これはGENIACの評価で使われているものの一部をそのまま示した形になります。GENIACではJasterの0-shotやMT-Benchなども評価で使われていますが、これらは指示学習を全くしていない事前学習モデルでは精度が著しく低くでてしまうため、この記事ではJasterの4-shotのみを示しました。
また、英語に関して良く使われるベンチマークの一つであるMMLUの結果を示しました。MMLUもGENIACでも評価に使われているのですが、GENIACの評価の設定と一般的なMMLUの評価と条件が全く違うので、今回は良く使われるMMLUの条件に合わせて評価しました。MMLUの評価にはLLMの評価で良く使われる Language Model Evaluation Harness の5-shotで評価しました。
Area
Tag



