Blog
Preferred Networks(以下PFN)グループ会社のPreferred Elements(以下PFE)では2024年10月から2025年4月に実施されたGENIAC 第2期において、最終的に31Bのモデルからpruningと知識蒸留を活用して作った8Bモデルを開発しました。この記事では過去のGENAIC 第2期におけるPLaMo 2の事前学習の取り組みのまとめということで、過去の記事で紹介したもののうち、一部再度紹介しつつ、最終的な8BモデルであるPLaMo 2.1 8Bの結果について紹介します。
上記にあるように、この開発は経済産業省及び国立研究開発法人新エネルギー‧産業技術総合開発機構(NEDO)が実施する、国内の生成AIの開発力を強化するためのプロジェクト「GENIAC(Generative AI Accelerator Challenge)」の支援を受けて実施しました。
モデルアーキテクチャ
LLMのモデルアーキテクチャは、学習の安定性、学習・推論における効率、モデルの性能など様々な能力に影響する重要な要素です。論文などにおいて様々なアーキテクチャの変更が提案され、そのなかでもRMSNormやGrouped Query Attention (GQA) などは広く採用されるものになりました。
以前のバージョンであるPLaMo 100BではTransformerをベースとしたアーキテクチャを採用しました。これは、2024年現在でもオープンなLLMのほとんどはTransformerをベースとしており、学習速度、達成できる性能などの面で最も成功確率が高いアーキテクチャであるためです。
一方で、Transformerは系列長が長くなる際の推論に問題があることが知られています。学習時の系列長を超えた推論をするには工夫が必要であること、そもそも系列長が長くなるとメモリ消費が大きくなり推論ができないあるいは遅くなること、の2点が特に大きな問題となっています。
今回この問題に対処するために、我々はSambaをベースとしたアーキテクチャにすることで、主に後者の問題に対処することとしました。SambaはMambaとsliding window attentionを組み合わせたモデルアーキテクチャで、以下の特徴があります。
1. 学習時の系列長を超えても、推論・生成が破綻せずに行える
2. 系列長が伸びてもメモリ消費や計算量が増加しない
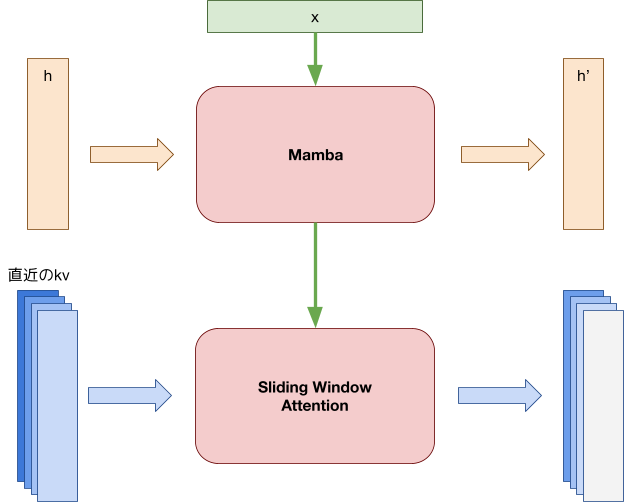
図1: Sambaのアーキテクチャ。MambaとSliding Window Attentionを重ねる。
学習データ
PLaMo 2では、以前開発したPLaMo-100Bで活用してきた英語および日本語データセットに加え、様々な手段で合成データセットを開発しモデル性能の改善を図っています。学習に利用した代表的なデータセットについて順番に紹介します。
Web コーパス
PLaMo 2の開発では一般的な日本語と英語の知識を習得するために、Webに由来するデータセットを採用しています。どちらの言語もCommonCrawlをベースとしており、英語はオープンデータセットを中心に、日本語データセットはPLaMo 100Bから一貫し、フィルタリングや重複除去などを自社で実施しました。
この日本語のデータセットのフィルタリングに関しては、fineweb-eduやdatacomp-lmなどの英語ベースの研究に基づき、以下のフィルタリングによりデータセットを新たに開発しています。
- fineweb-eduのような教育的価値におけるフィルタリング
- Webデータをカテゴライズしdown sampling
いずれも指示学習済みPLaMo-100Bによるアノテーションデータから軽量モデルを作成し、軽量モデルによるフィルタリングを行って、PLaMo 2の学習に利用しています。
1の手法によって教育的価値に頼ったデータセットによって想定外の性能劣化を引き起こしにくくなるよう、2の手法で1が失った知識を補完することを期待しています。
Web由来のコーディングデータ
コーディング性能を上げるための既存データとしては、HuggingFace 等で公開されているデータセットや、Web から抽出したデータなどを使用しました。
Web からのデータ抽出では、PLaMo 100B の日本語データセットと同様に、CommonCrawl のデータを前処理することでコードに関連の深いと考えられるデータを抽出しています。今回は、次のような方法を取りました。
- フィルタリングによる非関連データの除去: CommonCrawl データに含まれるすべての HTML をパースしてテキストを抽出するのはコストがかかるため、簡単なフィルタを使ってコードに関連する可能性が低いと思われるデータを除去します。具体的には、コードデータを示すのに良く使われる <pre> <code> タグを含まないようなデータを除去しました。
- フィルタを通過したデータをテキスト (Markdown) に変換
- fasttext モデルによりデータがコードデータかどうかを分類: このモデルは、予め LLM によりラベルを付けたデータにより学習しました。
合成データ
Phi-4をはじめ、多くのLLMの学習において一部の学習データで、LLMなどを活用した合成データが活用されるようになってきました。
PLaMo 2の開発では主に高品質な日本語データの拡充のための翻訳と言い換え、コーディング、数学のデータで合成データを活用しました。これらについて順に説明します。
翻訳/言い換え
Wikipediaのように日本語の高品質なデータはあるものの、そのデータの規模は英語に比べて小さいという問題があります。このような問題に対して我々は以下の二つの手法を用いました。
- 高品質な英語データをLLMによって翻訳して高品質な日本語データを作る
- 高品質な日本語データを言い換えをする
言い換えに関しては既存の手法を参考にLLMを用いた簡単なスタイルやQAのスタイルに変換するpromptなど複数のpromptを用いて言い換えと、Self-Tuningを用いたルールベースによる言い換えデータを作成しました。
また、元となるデータは翻訳データの場合は英語のwikiデータなど複数の品質の高いと考えられるデータを活用しました。
また、言い換えに関しては日本語のwikiデータに対して実施をしました。
このLLMによる翻訳や言い換えには高い日本語性能を誇るPLaMo 100Bを活用しました。
既存データを活用したコーディングデータの生成
既存のコードデータを LLM により加工することでデータ生成を行いました。具体的には、LLM によってコードデータにコメントを付けたり、コードの意味をなるべく保ちつつ LLM によって言い換えたデータを生成させたりしました。
例えば、次のような Python コードを考えます。
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("input", type=str)
parser.add_argument("--first-n-lines", type=int)
args = parser.parse_args()
with open(args.input, "r") as f:
lines = []
for line in f.readlines():
lines.append(line.rstrip())
if args.first_n_lines:
lines = lines[:args.first_n_lines]
lines.sort()
print("\n".join(lines))
このコードを LLM に与えることで、次のような説明文が得られます。
This Python script reads a file specified by the user, optionally limits the number of lines read, sorts those lines, and prints them. It uses the `argparse` module to handle command-line arguments for the input file and the number of lines to consider. The script reads the file, strips newline characters from each line, optionally truncates the list to the specified number of lines, sorts the remaining lines, and prints them joined by newline characters.
この説明文から再度コードを生成させることで、次のようなコードが得られます。このようにして、より理解しやすく学習に有用なコードデータを生成できると考えられます。
import argparse
def main():
# Set up argument parser
parser = argparse.ArgumentParser(description='Read a file, optionally limit the number of lines, sort them, and print.')
parser.add_argument('file', type=str, help='The input file to read')
parser.add_argument('-n', '--lines', type=int, default=None, help='The number of lines to consider (optional)')
# Parse command-line arguments
args = parser.parse_args()
try:
# Read the file
with open(args.file, 'r', encoding='utf-8') as file:
lines = file.readlines()
# Strip newline characters
lines = [line.rstrip('\n') for line in lines]
# Optionally limit the number of lines
if args.lines is not None:
lines = lines[:args.lines]
# Sort the lines
lines.sort()
# Print the sorted lines joined by newline characters
print('\n'.join(lines))
except FileNotFoundError:
print(f"Error: The file '{args.file}' was not found.")
except Exception as e:
print(f"An error occurred: {e}")
if __name__ == '__main__':
main()
プロンプトに基づくコーディングデータの生成
Phiでは、そのタイトルにもあるように、教科書的なデータを生成させて学習に使用することで LLM の性能を向上させています。我々も、同様に品質の良いデータを大量に生成することを試みました。方法としては主にMagicoderの手法に倣いました。
Magicoder の手法では、プロンプトの一部にコードの抜粋を含めることで、多様なデータを生成できるようにしています。
Magicoder では主に問題・解答がペアとなるデータ (instruction data) を作成していますが、教科書的データや通常のソフトウェアのようなコードデータも生成させるために、プロンプトを変更した生成も実施しました。
加えて、ランダムに選んだ「トピック」となる単語をプロンプトに含めることで、より多様な設定でのデータが生成できるようにしました。
他にも、生成させたデータをもとにより複雑なデータを作らせる、といった試みも行いました。
また、Nemotron-4では、LLM を使ってあるテーマにまつわる重要なトピック(例えば「Python の学習」というテーマなら、構文やライブラリといったトピックが考えられます)を取り出すという方法が提案されています。我々も、これに倣ったデータ生成を一部で取り入れました。
数学データの生成
数学データの合成データを作るには、既存の数学データをシードデータとして利用し、LLMを活用して生成を行いました。
このシードデータとしてはGSM8kとLilaを利用しました。また、データ生成は以下の2段階で生成を実施しました。
- シードデータから新しい問題を生成
- 生成した問題に対して回答と回答に至る思考過程の生成
この問題などの生成には今回はPhi-3.5を利用しました。
学習済weightの活用
PLaMo 2の学習においては、すでに学習したモデルの重みを使うことで学習tokenを抑えつつ性能を上げることを目指しました。
小さいモデルの重みを使って大きいモデル(31Bなど)を初期化するweight-reusingと、大きいモデルを小さいモデル(8Bなど)の学習に使うpruningの2つを併用しています。
weight-reusing
weight reusingは、より小さなDNNモデルの重みを使って大きなDNNモデルの初期値を決める手法です。LLMにおいては、NeurIPSのPhi-2の発表において、Phiシリーズでの利用が紹介されています。
事前に小規模な学習で検証したところ、weight reusingにより大きな性能向上が確認できました。weight reusingをすることで学習初期のtrain lossの下がりが大幅に改善されており、学習後半でもtrain lossはランダムな初期値よりも良くなっています。各種downstream taskの性能でも改善が見られました。
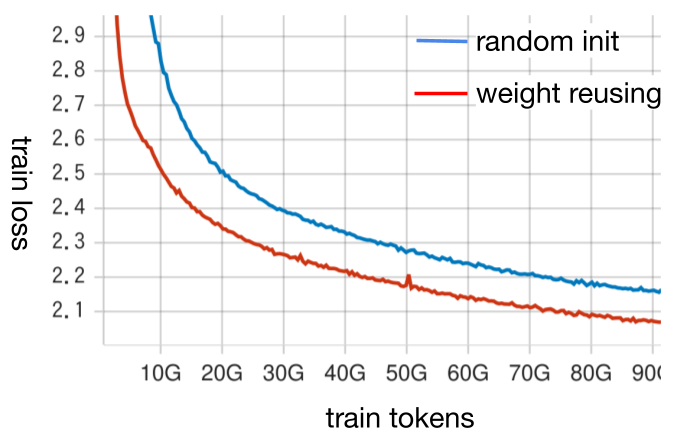
図2: weight reusingの実験時のtrain loss。青が8Bモデルをランダムな初期値から学習した場合、赤がweight reusingを使った初期値から学習した場合。
一般にこのような手法は、学習を長くしていくと効果が小さくなっていく、あるいは逆効果となることが予想されます。
しかし、LLMにおいては学習を長くするための計算資源が膨大であるため、weight reusingの効果があるケースの方が多いだろうと考えています。
pruning
pruningは学習済みのDNNモデルの重みのうち重要なものをのみを残すことで、効率よく高性能かつ小サイズなDNNモデルを得る手法です。LLMにおいてはLlama3.2がpruningによって、1Bモデルを作っています。
我々はMinitronの手法をベースにしたpruningを行いました。この手法は、structural pruningと再学習 (retraining) を組み合わせたものです。pruningの処理が比較的軽量、pruningによりアーキテクチャが変化しないので作ったモデルが使いやすい、といった理由から採用しました。
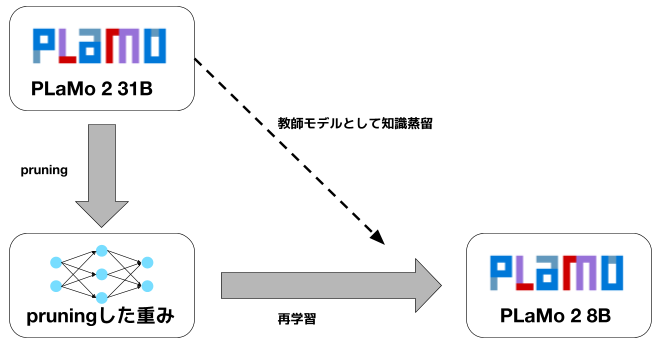
図3: pruingの概要。PLaMo 2 31Bをpruningして初期重みを作った後、知識蒸留を組み合わせた再学習を実施
この手法では、まず元のモデルから重要な重みのみを残すpruningを行い、後に元のモデルを教師とした知識蒸留 (knowledge distillation)によって再学習を行います。
知識蒸留では一般的なKL距離を利用した損失関数を利用していますが、メモリ消費量の削減のため、教師のlogitsは上位128 tokenのみを使うようにしました。PLaMo 2のtokenizerは語彙数が100K個あり、対応するlogitをすべて保持するとメモリ消費量が非常に大きくなりますが、上位128個のみにすることで大幅にメモリ消費量を抑えることができました。
教師のlogitが不正確になることによる知識蒸留の効果の低下のリスクもありますが、事前検証において上位128個のみをもちいても効果が大きく変わることはないことが確かめられたため、メモリ消費量を重視しました。
実験
比較対象のモデル
比較対象のモデルとしては日本語データが含まれたデータを学習した同レベルのpretrainモデルである、Qwen/Qwen3-8B-Base、tokyotech-llm/Llama-3.1-Swallow-8B-v0.2、sbintuitions/sarashina2-7bと比較しました。これに加えて全バージョンのPLaMo 100BとPLaMo 2シリーズからpruningや知識蒸留なしで学習した8B, 31Bを比較に加えました。
評価に利用したベンチマーク
JMMLU, MMLU
JMMLUに関しては公開されているtestデータの各項目の5つのサンプルをランダムに選び、few shotの入力として利用しました。評価はLanguage Model Evaluation HarnessのMMLUのコードを改良して実施しました。
また、MMLUのような選択問題に関してはpromptで性能が大きく変化することが知られています。今回は選択肢をLLMに入力し、A,B,C,Dの選択肢を答えさせる方法(Language Model Evaluation HarnessのMMLUにおけるdefaultのprompt)を利用しました。
JHumanEval, HumanEval+
コーディングのベンチマークとしてはHumanEval+とJHumanEvalを利用しました。利用したpromptはApendixに示します。
pfgen-bench
pfgen-benchは日本語の文章生成性能評価ベンチマークです。ベンチマークのスコアは0から1の値を取るようになっており、数値が高いほど良い日本語の文章が生成できていることを示します。
wmt20
wmt20 はStability AIのlm-evaluation-harnesを修正し、評価指標としてwmt22-comet-daを利用して測定しました。このwmt22-comet-daは0から1の値を取り、数値が1に高いほど翻訳精度が高いということを示している指標になっています。
各ベンチマークの結果
各ベンチマークの結果を以下に示します。
表1: JMMLU, MMLUの結果
| モデル | JMMLU (5 shot, acc) | MMLU (5 shot, acc) |
| Qwen/Qwen3-8B-Base | 0.714 | 0.765 |
| tokyotech-llm/Llama-3.1-Swallow-8B-v0.2 | 0.600 | 0.622 |
| sbintuitions/sarashina2-7b | 0.400 | 0.425 |
| pfnet/plamo-100b | 0.575 | 0.603 |
| PLaMo 2 8B | 0.572 | 0.573 |
| PLaMo 2 31B | 0.672 | 0.681 |
| PLaMo 2.1 8B | 0.635 | 0.635 |
表2: JHumanEval, HumanEval+の結果
| モデル | JHumanEval(0-shot, pass@1) | HumanEval+(0-shot, pass@1) |
| Qwen/Qwen3-8B-Base | 0.604 | 0.585 |
| tokyotech-llm/Llama-3.1-Swallow-8B-v0.2 | 0.232 | 0.201 |
| sbintuitions/sarashina2-7b | 0.128 | 0.128 |
| pfnet/plamo-100b | 0.268 | 0.220 |
| PLaMo 2 8B | 0.463 | 0.463 |
| PLaMo 2 31B | 0.488 | 0.555 |
| PLaMo 2.1 8B | 0.372 | 0.463 |
表3: pfgen-benchの結果
| モデル | pfgen-bench |
| Qwen/Qwen3-8B-Base | 0.560 * |
| tokyotech-llm/Llama-3.1-Swallow-8B-v0.2 | 0.702 * |
| sbintuitions/sarashina2-7b | 0.646 * |
| pfnet/plamo-100b | 0.747 * |
| PLaMo 2 8B | 0.753 * |
| PLaMo 2 31B | 0.817 |
| PLaMo 2.1 8B | 0.725 |
* https://github.com/pfnet-research/pfgen-bench から引用
表4: wmt20の結果
| モデル | wmt20 (4-shot, en → ja, wmt22-comet-da) | wmt20 (4-shot, ja → en, wmt22-comet-da) |
| Qwen/Qwen3-8B-Base | 0.879 | 0.815 |
| tokyotech-llm/Llama-3.1-Swallow-8B-v0.2 | 0.900 | 0.820 |
| sbintuitions/sarashina2-7b | 0.891 | 0.805 |
| pfnet/plamo-100b | 0.899 | 0.819 |
| PLaMo 2 8B | 0.901 | 0.814 |
| PLaMo 2 31B | 0.907 | 0.826 |
| PLaMo 2.1 8B | 0.905 | 0.821 |
PLaMo 2.1 8BのJMMLUとMMLUの結果をみると、日本で開発された同レベルのサイズのsarashina2-7bとtokyotech-llm/Llama-3.1-Swallow-8B-v0.2と比べるとPLaMo 2.1 8Bのほうがより高いスコアを達成できています。これに加えて、昨年開発した10倍以上巨大なPLaMo 100Bと比べてほぼ同レベルのスコアを達成することができました。これは昨年のPLaMo 100Bの開発以降に作成したデータがより高品質なものであったため達成できたことであると考えています。
一方、Qwen/Qwen3-8B-BaseとPLaMo 2 8Bの結果を比較すると、MMLUだけでなく、JMMLUでもQwen/Qwen3-8B-Baseのほうが高いスコアになっています。これはJMMLUで必要な知識に関しては、言語に依存するところが小さいため、英語や中国語で高いスコアを達成することができるQwen/Qwen3-8B-Baseであれば高い精度が達成できるためであると考えられます。
コードに関してもMMLUとJMMLUと同じような関係が見られ、Qwen/Qwen3-8B-BaseとPLaMo 2.1 8Bの結果を比較すると、HumanEval+だけでなく、JHumanEvalでもQwen/Qwen3-8B-Baseのほうが高いスコアになっています。このことからコードを生成する能力は、言語に依存するところが小さいため、英語や中国語で高いスコアを達成することができるQwen/Qwen3-8B-Baseであれば高い精度が達成できるためであると考えられます。
次にpfgen-benchの結果についてです。PLaMo 2.1 8Bは、pfgen-benchでPLaMo-100Bと同等の性能を示しており、優れた日本語の生成能力を持つことがわかります。また、同サイズのモデルと比較しても高い性能を発揮しています。
日本語固有の知識 (JMMLU 日本問題)
JMMLUには日本問題という、MMLUからの翻訳ではない問題があります。熟語、公民、日本地理、日本史の4タスクからなるこれらの問題は、英語ではあまり問われることのない日本語固有の知識・問題が集まっています。
これらJMMLU 日本語問題の性能を通して、各モデルの日本語固有知識について見ていきます。
表5: JMMLUから日本問題を抜粋
| モデル | 平均 | 熟語 | 公民 | 日本地理 | 日本史 |
| Qwen/Qwen3-8B-Base | 0.79 | 0.93 | 0.85 | 0.86 | 0.52 |
| tokyotech-llm/Llama-3.1-Swallow-8B-v0.2 | 0.87 | 0.97 | 0.89 | 0.91 | 0.71 |
| sbintuitions/sarashina2-7b | 0.67 | 0.73 | 0.73 | 0.54 | 0.66 |
| pfnet/plamo-100b | 0.85 | 0.94 | 0.87 | 0.86 | 0.74 |
| PLaMo 2 8B | 0.85 | 0.97 | 0.87 | 0.85 | 0.71 |
| PLaMo 2 31B | 0.90 | 0.97 | 0.92 | 0.93 | 0.78 |
| PLaMo 2.1 8B | 0.87 | 0.95 | 0.89 | 0.91 | 0.75 |
PLaMo 2.1 8Bは、JMMLUの日本問題においてもPLaMo-100Bとほぼ同等以上の性能を発揮しています。PLaMo 2ではデータセットとして英語データの翻訳データを使っていますが、これらによって日本語固有の知識が忘れられる・失われるということがなかったことがわかります。
同サイズのモデルで比較すると、Qwen/Qwen3-8B-Baseとsarashina2-7bよりPLaMo 2.1 8Bのほうが性能が高く、Llama-3.1-Swallow-8Bとは同レベルの精度となっています。
Qwen/Qwen3-8B-BaseとPLaMo 2.1 8Bの差は日本語での学習量の違いに起因すると考えられます。sarashina2-7bとの差が何に起因するかは不明ですが、JMMLU全体での性能差が日本問題でも現れているのかもしれません。
pruningの効果
pruningの効果やメリットを、PLaMo 2 8BとPLaMo 2.1 8Bなどを比較しつつ見ていきます。
以下に学習に使った計算量 (FLOPs) とJMMLUのベンチマークにおける性能をまとめました。また、参考として31Bモデルも載せています。なお、PLaMo 2.1 8Bの学習計算量には元となったPLaMo 2 31Bの学習計算量は含めていません。
表: 学習計算量とモデル性能
| 学習token数 | 学習計算量
[10^18 FLOPs] |
JMMLU
(default(5 shots, acc) |
|
| PLaMo 2 8B | 6T token | 288000 | 0.572 |
| PLaMo 2.1 8B | 500B token | 55000 * | 0.672 |
| PLaMo 2 31B | 2T token | 372000 | 0.635 |
* pruning元であるPLaMo 2 31Bの学習計算量を除き、8B自体の学習に必要な計算量と蒸留する際に利用する31Bの推論の計算量を含めた値
PLaMo 2.1 8Bは、3つのなかで最も少ない学習計算量でありながら、pruningなどなしのPLaMo 2 8Bよりも高い性能を発揮しています。
このため、pruningと再学習は必要な学習計算量の観点では優れた手法であると言えそうです。なお、pruningするためには元となるモデルが必要であり、この学習にはPLaMo 2 8Bよりも大きな計算資源を利用しています。しかし、性能の高い大きなモデルはpruningをするしないに関わらず必要であり、pruningのための計算資源から抜いて考えることは不自然ではないと考えています。
このpruningの効率の良さは、モデルを小さくする上で特に重要です。モデルサイズが一定の時、学習token数を増やしていってもいずれ性能向上がほとんどみられなくなることが知られています 。pruningと再学習を利用することで短いtoken数で高い性能を発揮できるということは、この問題を緩和して、モデルサイズを変えずに高い性能のモデルを学習できる可能性があると言えそうです。
また、事前学習全体で見てもpruningにはメリットがあると考えています。
使用するGPUなどの要件によって使いたいLLMのサイズは変わってきます。例えば、ともかく良い性能のモデルが必要であれば巨大なモデルを使うことになりますし、エッジデバイスでの利用を考えるとより小さいモデルが適していることが多いはずです。
このため、LLMの事前学習では、いくつかのモデルのバリエーションを作ることが求められます。従来はこの要求を満たすために大規模な学習を複数種類独立して流す必要がありました。似通った大規模な実験を複数流すことは事前学習に必要な計算資源を大きく増加させてしまいます。
今回紹介したpruningによって、無駄なく効率的に高い性能の事前学習モデルのバリエーションを用意できるようになりました。
終わりに
今回は、GENIAC 第2期における事前学習の取り組みについて紹介しました。
今後も事前学習についての取り組みを順次公開できればと考えています。
仲間募集
PFN/PFEでは今後もLLMの開発を継続して行っていきます。開発は今回紹介した以外にも多岐にわたります。我々はこれらの課題に情熱をもって挑戦していく仲間を募集しています。
これらの仕事に興味がある方はぜひご応募よろしくお願いします。
Appendix
JMMLUのdefaultにおけるprompt
JMMLUのdefaultで利用したpromptは以下の通りです。
選択問題 問題: 48以上88以下=?以上11以下が成り立つ数を求めよ。 A. 6 B. 11 C. 8 D. 5 回答: A … 問題: ペレスさんは5日間で合計40マイルを運転した。毎日同じ距離を走った。ペレスさんは毎日何マイルを運転したか。 A. 5 B. 7 C. 8 D. 9 回答:
JMMLUのcontinuationにおけるprompt
JMMLUのcontinuationで利用したpromptは以下の通りです。
選択問題 問題: 48以上88以下=?以上11以下が成り立つ数を求めよ。 回答: 6 … 問題: ペレスさんは5日間で合計40マイルを運転した。毎日同じ距離を走った。ペレスさんは毎日何マイルを運転したか。 回答:
MMLUのdefaultにおけるprompt
MMLUのdefaultで利用したpromptは以下の通りです。
The following are multiple choice questions (with answers) about elementary mathematics. The population of the city where Michelle was born is 145,826. What is the value of the 5 in the number 145,826? A. 5 thousands B. 5 hundreds C. 5 tens D. 5 ones Answer: A … What is the value of p in 24 = 2p? A. p = 4 B. p = 8 C. p = 12 D. p = 24 Answer:
MMLUのcontinuationにおけるprompt
MMLUのcontinuationで利用したpromptは以下の通りです。
The following are multiple choice questions (with answers) about elementary mathematics. The population of the city where Michelle was born is 145,826. What is the value of the 5 in the number 145,826? Answer: 5 thousands … What is the value of p in 24 = 2p? Answer:
JHumanEvalの評価方法
promptは https://huggingface.co/datasets/kogi-jwu/jhumaneval のpromptをそのまま利用しました。
例を以下に示します。
from typing import List
def has_close_elements(numbers: List[float], threshold: float) -&gt; bool:
"""リストnumbersの中に、与えられたthresholdより近い2つの数値が存在するか判定する
&gt;&gt;&gt; has_close_elements([1.0, 2.0, 3.0], 0.5)
False
&gt;&gt;&gt; has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3)
True
"""
また、LLMのコードの生成は以下のものでも止まるようにしました
[ "\nclass", "\ndef", "\n#", "\n@", "\nprint", "\nif", "\n```", "&lt;file_sep&gt;", "\nimport", "\nfrom"]
HumanEval+
promptはhttps://huggingface.co/datasets/evalplus/humanevalplus のpromptをそのまま利用しました。
例を以下に示します。
from typing import List
def has_close_elements(numbers: List[float], threshold: float) -&gt; bool:
""" Check if in given list of numbers, are any two numbers closer to each other than
given threshold.
&gt;&gt;&gt; has_close_elements([1.0, 2.0, 3.0], 0.5)
False
&gt;&gt;&gt; has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3)
True
"""
また、LLMのコードの生成は以下のものでも止まるようにしました。
[ "\nclass", "\ndef", "\n#", "\n@", "\nprint", "\nif", "\n```", "&lt;file_sep&gt;", "\nimport", "\nfrom"]
WMT20のprompt
wmt20の評価はhttps://github.com/Stability-AI/lm-evaluation-harness/tree/jp-stable のものと同じものを利用しました。具体的にはen → jaは以下のようなpromptになります。
English phrase: Ford Motor and Volkswagen have said they will spend billions of dollars to jointly develop electric and self-driving vehicles. Japanese phrase: フォード・モーターとフォルクスワーゲンは、電気自動車と自動運転車の共同開発に数十億ドルを投資する予定だと発表している。 … English phrase: Dozens of fundraising coffee mornings are taking place across Scotland on Friday. Japanese phrase:
pfgen-bench の評価設定
評価設定はhttps://github.com/pfnet-research/pfgen-bench のものをそのまま利用しています。



