Blog
先日発表されたPLaMo翻訳は、8Bサイズという比較的小規模のモデルでありながら品質の高い翻訳を可能にします。今回はこのPLaMo翻訳を用いて、弊社が開発を主導するハイパーパラメータ最適化フレームワークOptunaの日本語公式ドキュメントを作成しました。
本記事では、PLaMo翻訳の紹介とOptuna日本語公式ドキュメントを生成する技術的なアプローチの共有、見つかった利点や今後の課題について解説します。
PLaMo翻訳の紹介
PLaMo翻訳は、PLaMo 2.1 8Bサイズのモデルをベースに翻訳用途に特化させたLLMです。デモサイトにてお試しいただける他、Hugging Faceにて学習済みモデルを公開しています。
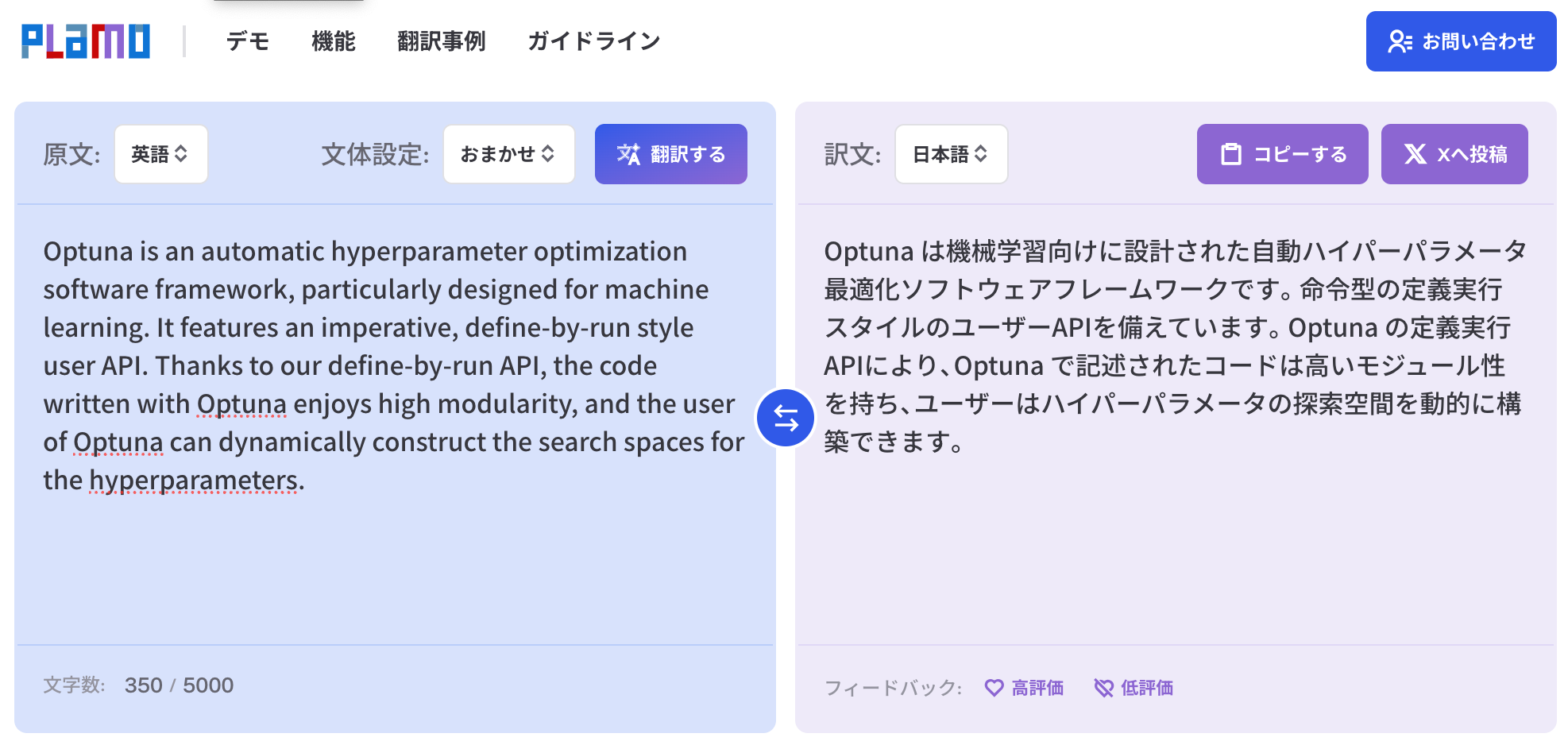
将来的にはAPIの提供も予定しており、幅広いユースケースにご活用いただけます。詳細は、下記リンクをご確認ください。
日本語の翻訳に特化した大規模言語モデルPLaMo翻訳を発売 – 株式会社Preferred Networks
日本語版Optuna公式ドキュメントについて
今回我々はハイパーパラメータ最適化フレームワークOptunaの公式ドキュメントを、PLaMo翻訳を用いて英語から日本語に翻訳しました。成果物はこちらのURLより確認できます。
PLaMo翻訳によって、コンテキストを踏まえた自然な訳文が生成されています。一部手直しが必要な箇所や残されている課題もありますが、少ない労力で日本語ドキュメントを用意することができました。なお今回の取り組みはあくまで試作・検証段階にあり、長期的な運用フローが固まっていないことから今後のOptunaのアップデートへの追従は保証されない点にご注意ください。

日本語ドキュメントURL:https://docs-ja.optuna.org
Optunaの公式ドキュメントは、SphinxというPython製のドキュメンテーションツールを用いて生成、マークアップ言語にはreStructuredTextを採用しています。SphinxにはGNU gettextを用いた国際化の仕組みが標準機能として存在しますが、我々はその仕組みを使用していません。
GNU gettextを用いてドキュメントを翻訳する場合、マークアップ文書から抽出されたメッセージ単位で.poファイル(Portable Objectファイル)を生成し、その中に訳文を記述します。ただし.poファイルは通常1文単位でメッセージを管理し、文書構造や前後の文脈が限定的にしか把握できないため、自然で一貫性のある翻訳文を生成する難易度が上がります。そこで我々はreStructuredTextやPythonファイルを直接PLaMo翻訳に与えるアプローチを取りました。
Sphinxドキュメントの技術的なアプローチの詳細
Optunaの公式ドキュメントは主に次の3つのファイル群から構成されています。
- reStructuredTextで記述されたドキュメントの各種ページ (GitHub: docs/source/**.rst)
- APIリファレンスを生成するために収集されるソースコード内のdocstring (GitHub: optuna/**.py)
- チュートリアルページに埋め込まれるサンプルコード (GitHub: tutorial/**.py)
当初はAPIリファレンスを日本語に翻訳するため、OptunaのソースコードをそのままPLaMo翻訳に与えていました。しかし、Pythonの構文が一部壊れるケースや、docstringだけでなく例外メッセージやログメッセージも日本語に翻訳してしまいチュートリアルの実行結果が変わってしまうなどの問題が発生しました。特に翻訳モデルがどこまで翻訳すべきか(ログや例外メッセージを翻訳するか)というのは用途次第で期待される挙動が変わってしまう問題です。そういった翻訳モデルの制御は現時点では対応できないことから別のアプローチを考えることにしました。
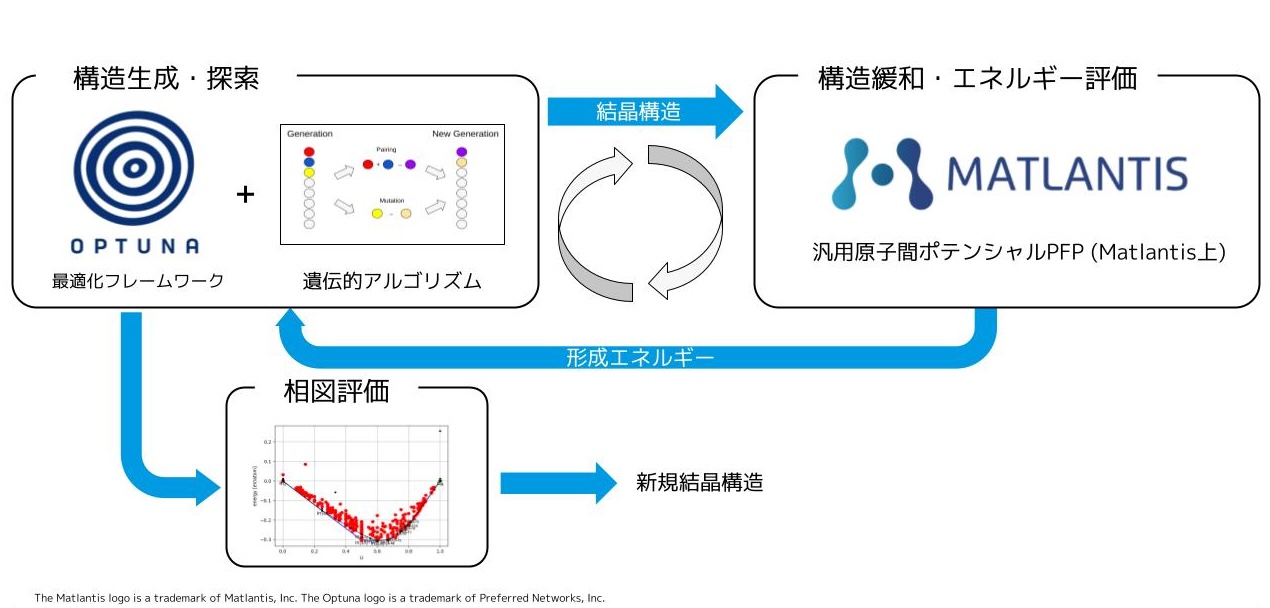
Sphinxが前述したファイル群を入力として受け取ってからHTMLファイルをビルドするまでの、全体の処理の流れの概略図を図1に示します。Sphinxのautodoc拡張は、Optunaソースコード内のdocstringをもとにrstファイルを内部で生成します。これらの中間rstファイルを取り出し、PLaMo翻訳で英→日翻訳を実行、翻訳済みの中間rstファイルを差し込むことでAPIリファレンスの日本語翻訳を実現します。

図1. Sphinxドキュメントのビルドの流れの概略図。Optunaソースコード内のdocstringやチュートリアルのサンプルコードは内部的にrstファイルに変換され、HTMLに変換される。
SphinxリポジトリのGitHub Issueにある通り、現状のSphinx autodoc拡張の実装では中間rstファイルを取り出す仕組みがなかったため、簡単なパッチを作成し使用しました (パッチは非常にアドホックな実装となっているため今後upstreamに反映するにはAPIの見直しが必要となっています)。
チュートリアル用のPythonファイルについては、PLaMo翻訳モデルにそのまま与えても概ね期待通りの出力が得られました。ファイル数が少なく仮に壊れた箇所があったとしても手作業での修正が十分に現実的であることからPythonファイルをそのまま翻訳しています。
Sphinxが標準で提供するGNU gettextベースの翻訳と比較した際の欠点としまして、今回のアプローチでは言語切替ボタンなどの利用が出来なくなってしまう点にご注意ください。
PLaMoによる翻訳結果
一般的な翻訳のユースケースと比べて、Optuna公式ドキュメントを日本語に翻訳するにはいくつかの難しい点があります。
まずreStructuredTextというマークアップ言語は、Markdownに比べてインデント等のルールに厳しく、知名度や利用事例が少ないためかLLMが正しく扱えず構文を壊してしまうことがあります。またOptuna固有の概念である「Study」や「Trial」は、しばしば「研究」や「試行」のように日本語に翻訳されてしまい、直訳してしまうと意味がうまく伝わりません。実際にこれらの問題はPLaMo翻訳でも発生しました。
上記のような問題に対処するため、翻訳モデルの学習データセットに新たなデータを追加しました。これは自社で翻訳モデルをつくる大きな利点の1つです。実際に改善前のPLaMo翻訳が生成した結果を図2、改善後のPLaMo翻訳が生成した結果を図3に示します。

図2. 改善前の翻訳モデルを用いた日本語翻訳結果
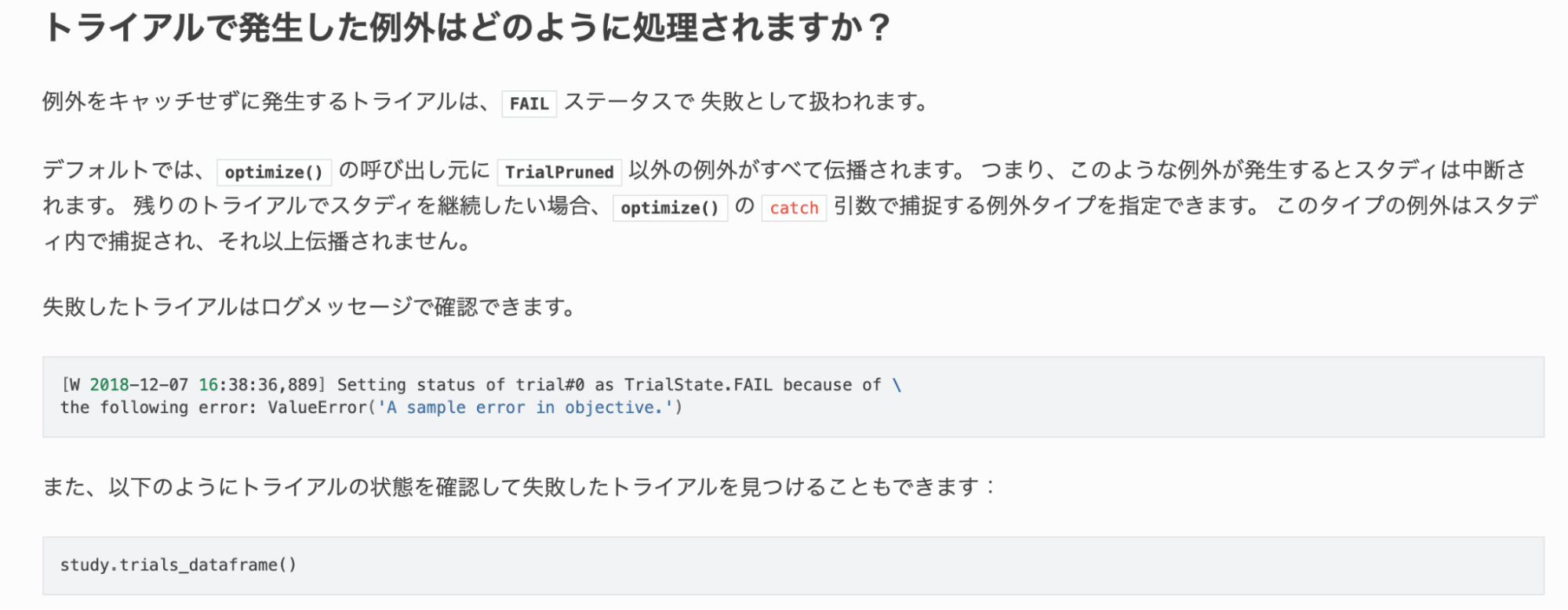
図3. 改善後の翻訳モデルを用いた日本語翻訳結果
図2に示した改善前の翻訳モデルも一見それなりに翻訳できているように見えますが、「試行からの例外」のようにOptuna固有の概念であるTrialが「試行」と翻訳されてしまい意味がよく掴めません。またコードブロック内のログメッセージが翻訳されてしまうなどの問題も見つかります。図3に示した改善後のモデルの出力ではこれらの問題が修正されています。
今後の課題として、図4に示すように一部のページではreStructureTextの構文が崩れるケースが残っています。reStructuredTextはスペースの有無などに厳しくこのような失敗が残っていますが、これらの問題は継続的なモデルの改善で十分に解決が可能であると考えています。

図4. reStructuredTextの構文が崩れるケース
おわりに
今回PLaMo翻訳モデルを用いて、Optuna公式ドキュメントの日本語翻訳を実施しました。一部reStructuredTextの構文が崩れ手作業での修正が必要な箇所もありましたが、全体として非常に少ない労力で自然に読める日本語ドキュメントを用意することができました。
みなさんのプロジェクトでもPLaMo翻訳をご活用いただけますと幸いです。ビジネスでの利用は問い合わせフォームからお問い合わせください。ライセンスについてはPLaMo Community Licenseの紹介記事を参照ください。PLaMo翻訳で日本語情報の充実や日本からの発信が加速できればと考えています。