Blog
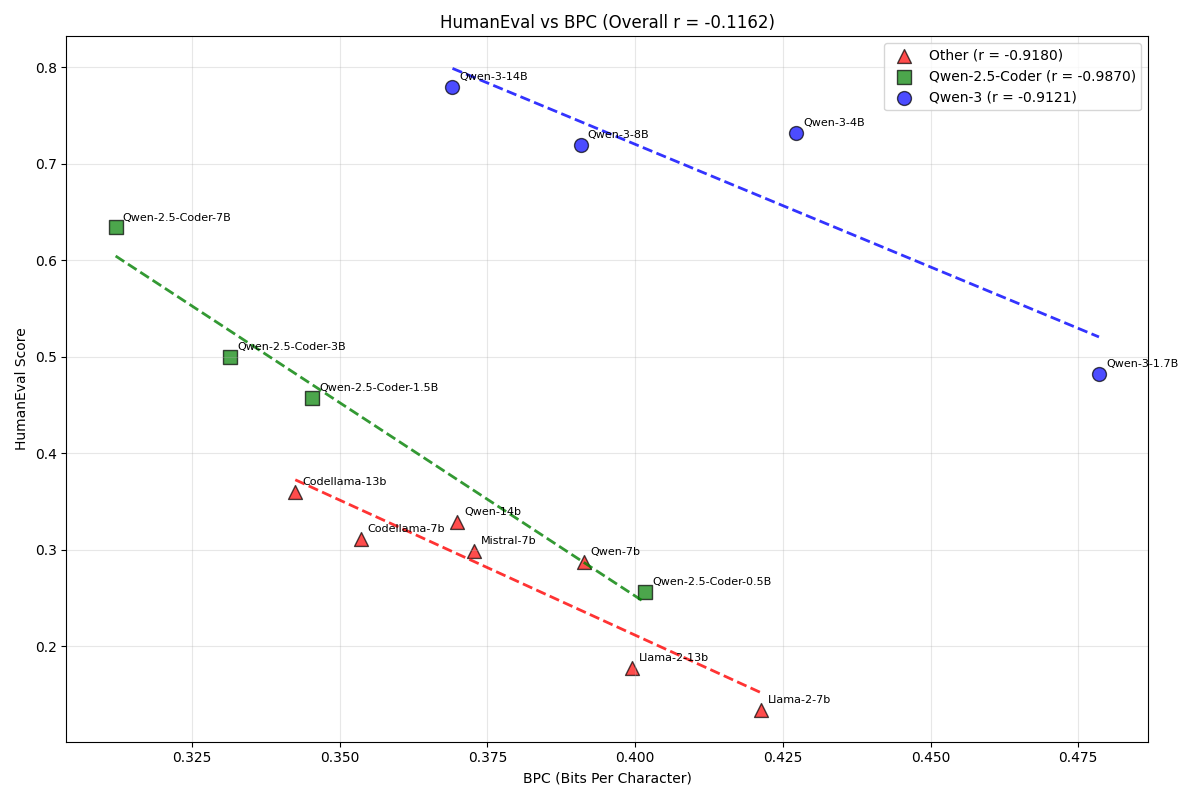
Preferred Networksの子会社のPreferred Elements(以下PFE)では7月から約1ヶ月の間、1兆 (1T) パラメータ規模のLLMの事前学習について検証を行っていました。今回の記事ではこの取り組みとその結果について紹介します。
この検証は経済産業省が主導する国内の生成AIの開発力を強化するためのプロジェクト「GENIAC(Generative AI Accelerator Challenge)」のもと、NEDO(国立研究開発法人新エネルギー・産業技術総合開発機構)の助成事業に採択され、計算資源の提供支援を受けて実施しました。
超巨大モデル学習の目的
今回の取り組みは、超巨大な (1Tクラスの) DNNモデルを学習できるかを確認することを目的としています。そもそもなぜこの検証をしたのかについての説明から始めようと思います。
LLMの事前学習では、学習に利用したデータセットの量とパラメータ数が多いほど高い性能を発揮するというscaling lawが成り立つことが報告されています (Scaling Law for Neural Language Models)。
scaling lawに基づくと、超巨大モデルを学習すればそれだけ高い性能が得られると期待できます。しかし、その分学習に必要な計算量も大きくなるのが問題となり実際に学習を行うのは困難です。
一方、昨年末頃からLLMではMixture of Experts (MoE) とよばれるアーキテクチャの活用が進んできています (Mixtral など)。MoEは入力ごとに計算に利用するパラメータを変えることで、計算量を抑えながらパラメータを増やす手法です。
我々はMoEを活用することで超巨大モデルの学習の可能性がでてくるのではないかと考えました。例えばPLaMo-100BをベースにMoEを活用してパラメータを10倍にした場合、理想的には1TクラスのモデルをPLaMo-100Bと同程度の計算資源で学習できることになります。
しかし、このようなクラスの学習について公開されている情報は多くありません。昨年末から今年にかけて公開されたLLMだと、grok-1 やDeepSeek-v2 が最大規模のMoEですが、これらは200B ~ 300Bパラメータクラスであり、今回の我々の目標とは数倍の差があります。論文などで学習方法などについて報告されているDNNで最大規模のものはおそらくSwitch Transformer-C です。これは約1.6Tパラメータのモデルですが、数年前の論文・手法であり
- Transformerの構造が現在主流のものとは異なること
- 現在のGPU (H100) 上で効率よく実行するのが困難と予想されること
といった理由でそのまま適用できるわけではありません。
そのため、1Tパラメータクラスの事前学習を実際に行い、期待通りに性能の良いモデルの学習が可能なのか、あるいは想定していなかった課題がみつかるのかを今回調査しました。
検証項目としては、大きく学習速度とモデルの性能の2つを考えました。MoEの採用などによって実効効率がどの程度低下するかは実際に学習する上で非常に重要と言えます。実効効率がでなければ結局学習に必要な計算資源 (GPU時間) が大きくなり、MoEなしのモデルを学習するのと変わらなくなってしまいます。また、モデルの性能は超巨大モデルを学習する一番の目的なのでこちらも当然重要です。
ただし、今回の検証の中ではモデルの性能については十分な検証が行えるところまでたどりつきませんでした。このあと紹介するように1Tクラスのモデルの事前学習はまだ学習時点で解決しなければいけない問題が多い状況にあると言えます。
事前学習の設定
まずは今回行った事前学習の設定を説明します。学習に使うソフトウェアなどはPLaMo-100Bのときとほぼ同じものを使っています。
モデルとしてはPLaMo-100Bをベースに主に
- 1Tパラメータでのモデル並列がやりやすいようにレイヤ数などを調整
- MoEによってMLP部分を12倍のパラメータを持つようにアーキテクチャを変更
- DeepSeek MoEを参考にshared expertを導入
の変更を行い、1Tパラメータクラスのモデルとしました。MoEの手法については結果とあわせて記述します。
データセットはPLaMo-100Bの学習の後半で使ったものとほぼ同じものを利用し、100B tokenの学習としました。
100Bというtoken数はここ数年のLLMの学習としては非常に短い規模ですが、限られた期間で1Tクラスの事前学習を検証することが主目的であるため、この程度の規模に抑え試行錯誤できる時間を増やすほうが良いと判断しました。
検証結果
ここからは実験結果について説明していきます。最初に概要を紹介したあと、見つかった課題や解決方法について詳細を説明します。
今回の検証では、train lossの発散などの致命的な問題を起こすことなく、1TパラメータクラスのLLMを学習することに成功しました
この学習の実現のため、1) メモリ消費量の削減、2) MoEの学習安定化、の2つの課題に対処する必要がありました。これら2つについてはこのあとそれぞれ詳述します。
一方で、学習速度の向上、モデルの性能が期待どおりのものであるかの検証、については不十分なものに終わってしまいました。これらについては、今回の検証でわかったこと・確認できたところまでを紹介します。
メモリ消費量の削減
まずはメモリ消費量の削減について詳しく説明していきます。
LLMは非常に大量のパラメータを持つため、LLMの学習ではGPUメモリの使用量は重要な要素です。3D parallelism やZeRO のようなメモリ消費量を削減する効果を持つ手法が提案され、活用されています。PLaMo-100Bの学習でもこれらの手法を利用しました。
しかし、1Tクラスの学習の場合このような手法を使ってもメモリ消費量が問題となります。
今回は400GPUを使って1Tクラスのパラメータの学習を行いました。H100 GPUは1台あたり80GBのメモリを積んでいるので、総メモリ量は32 TBです。一方、LLMによく使われるAdamW optimizerはパラメータ1つあたり12byteの状態を記録する必要があります (ZeRO)。したがって、1Tクラスのモデルを学習するにはoptimizerのためのメモリだけで12TB必要ということになります。
GPUメモリは計算時の一時領域など他にも多くの使用用途があることを考えると、optimizerだけで37.5%のメモリを使ってしまうのは大きな制約となってしまいます。
そこで、FP8-LM や8-bit Optimizers を参考に、optimizer stateをより低精度で持つことでこの問題に対処しました。これによりoptimizerに使用するメモリを4~5TB程度まで削減することができ、他の用途 (activationの保存など) にメモリを多く使うことができるようになりました。
MoEの学習安定化
次にMoEの学習安定化について説明します。
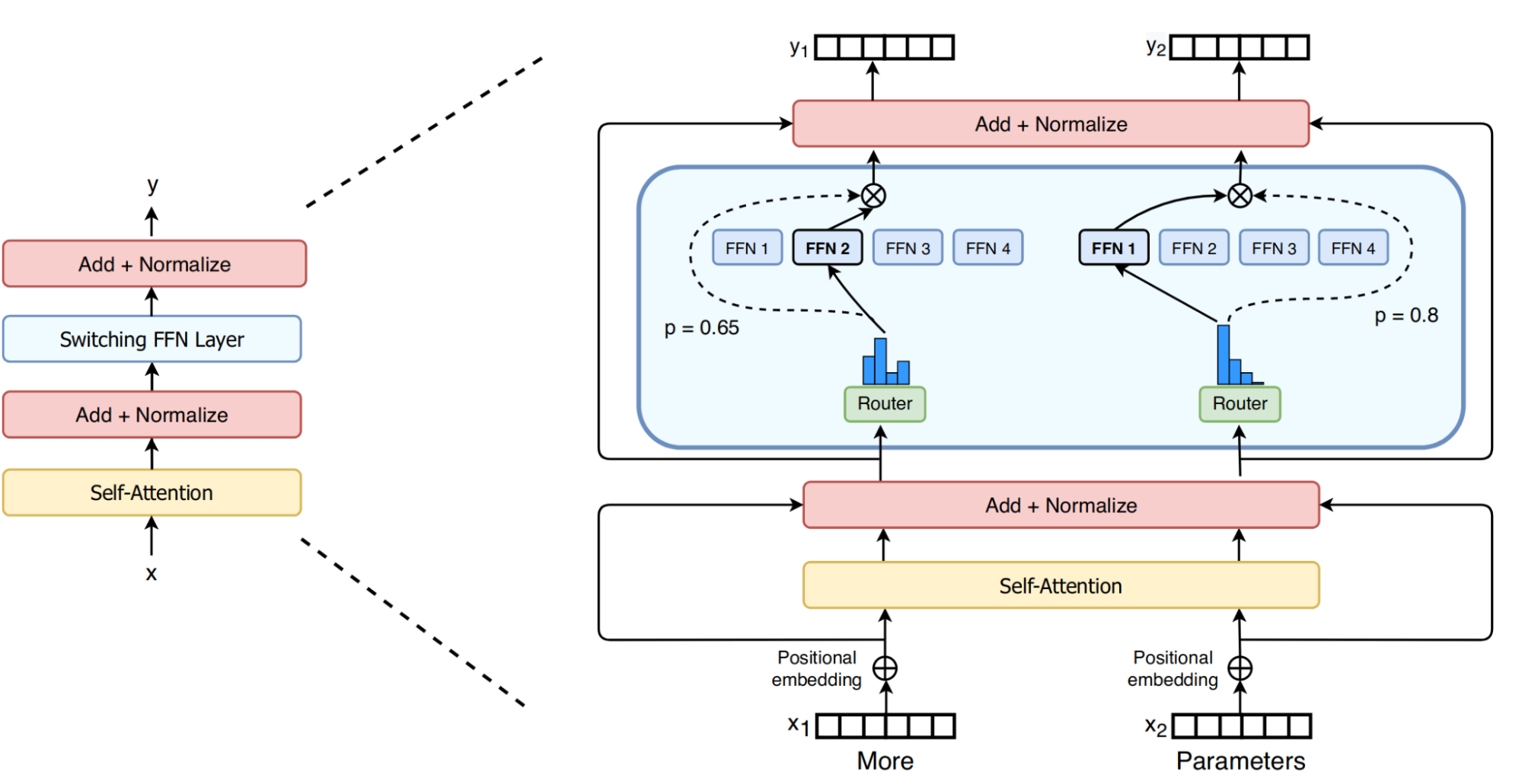
図1: Mixture of Expert (Switch Transformersより)
当初我々はSwitch Transformers のような現在一般的なMoEを使って1Tクラスのモデルを作りました。このモデルでは上の図のように、小さいDNN (Router) でtokenがどのexpert (TransformerのMLP/FFNレイヤ) に割り当てるかを決め、割り当てられたexpertが計算を行います。学習では、routerとexpertの重みを同時に最適化します。
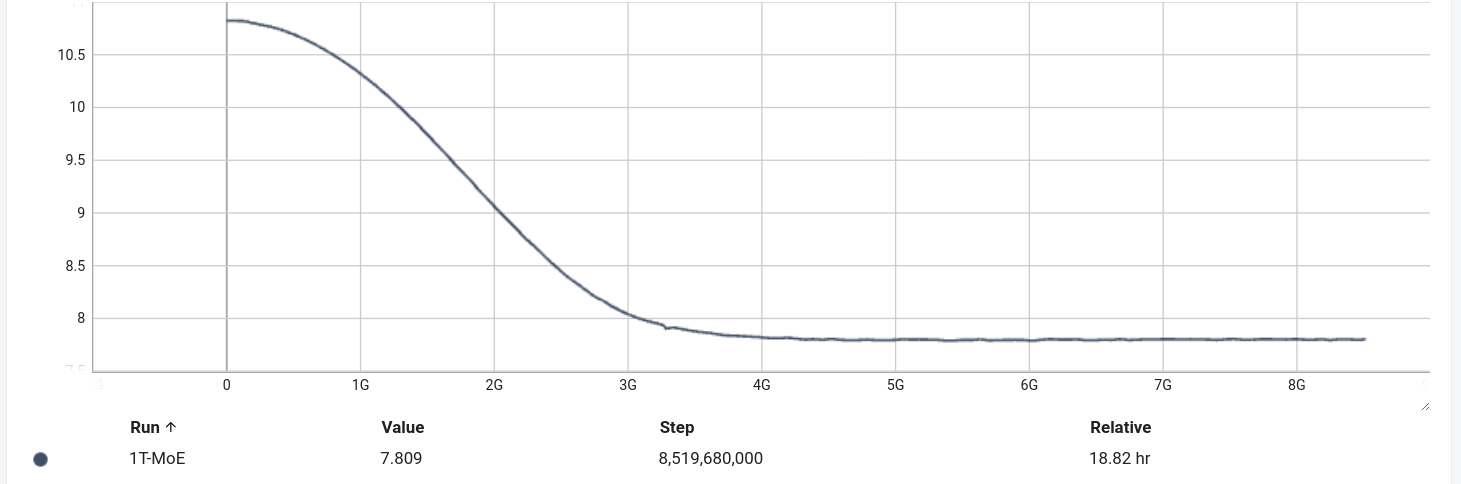
図2: MoEのlearning curve
図2はこの手法を利用した1Tモデルを学習したときのtrain lossの挙動です。一見普通のlearning curveにも見えますが、train lossが7.8程度とLLMのtrain lossとしてはかなり高い値から下がらなくなっています。
詳しく学習中の挙動を見ていくと、routerの学習がうまくいかず、常におなじexpertを割り当てていることがわかりました。routerは各expertに均等にtokenを割り当てるように学習されることが理想で、MoEのloss関数にはこのような割り当てを促すための項 (load balancing loss) が入っています。
しかし、1Tパラメータモデルでは常に特定のexpertを割り当てるように学習されてしまっていました。結果、実際に使われているパラメータが少なくなっている、計算効率向上のために過剰に割り当てが偏った場合一部のtoken処理をskipする (token dropping)、といった問題が発生し、train lossが下がらなくなっていたと考えられます。
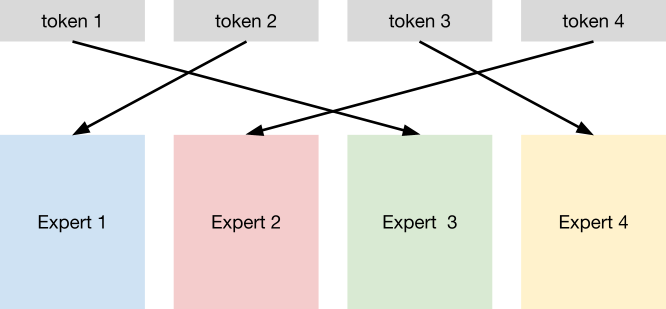
図3: 理想的にroutingされた場合。各Expertに均等にtokenが割り当てられ、全expertが同じ個数のtokenを処理する。
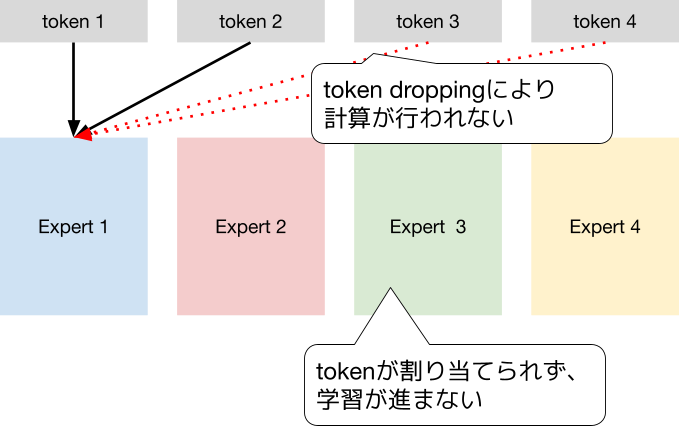
図4: 1Tパラメータの学習で起きた状況。全tokenが特定のexpertに割り当てられてしまう
小規模 (~30Bパラメータ程度) の実験ではうまく学習できていたため、割り当ての学習に失敗した原因は
- transformerの層が深すぎること
- expert 1つあたりのパラメータが多くなり、1つのexpertでかんたんな問題なら解けてしまうようになったこと
の2つなどが考えられます。詳細な原因はまだわかっていませんが、詳細な調査をこのクラスの学習で行うのは様々な点で困難です。より小さな再現ケースを作ることが原因究明の次のステップになると考えています。
今回はこの問題を回避するため、Hash Layers へのアーキテクチャの移行を決めました。Hash Layersはexpertの割り当てを学習によらずhash関数で決めるため、このような問題は発生しないはずだと考えました。
図5はhash layerを使った時と通常のMoEでのtrain lossをプロットしています。最終的なtrain lossは1.57程度で、hash layerを使う場合は通常のMoEよりlossがはるかに小さくなっていることがわかります。
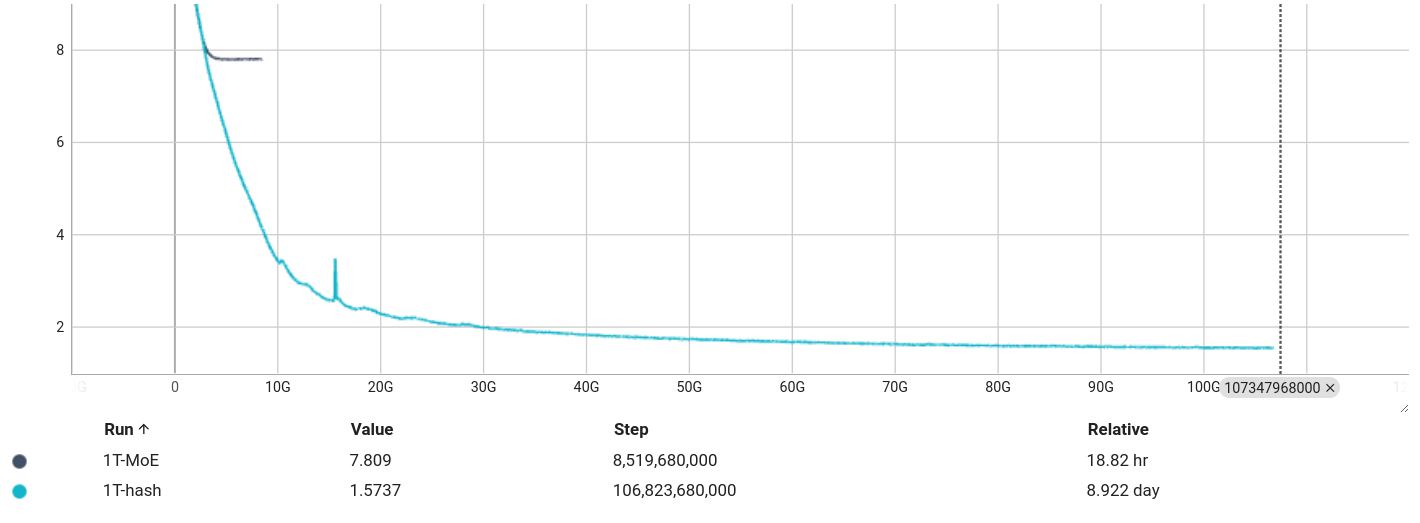
図5: hash layerを利用した際のlearning curve
hash layer以外の選択肢として、
- load balancing lossの係数をあげる
- よりsparseなモデルとする
- Expert Choice Routing を利用する
という方針も考えられます。
1はtokenの割り当てを均等にするための項の影響を大きくするというもので、試しましたがこれは効果がありませんでした。
2はオリジナルのSwitch Transformersに近い2048 expertのような設定としてモデルを大きくする方法です。3はtokenの割り当て不均衡を解消するHash Layersとは別の手法です。2と3については、学習速度などの観点で今回使用しませんでした。
学習速度
続いて、学習速度について紹介します。
1Tパラメータの学習での実効効率は約220 TFLOP/s/GPUでした。PLaMo-100Bのときは約540 TFLOP/s/GPUほどでていたので半分以下になっています。
この速度低下はMoEが通常のTransformerよりメモリアクセス量が多いアルゴリズムであることに起因すると考えています。
MoEは計算量 (FLOPs) を増やさずパラメータを増やして性能を上げる手法ですが、実際の計算においては計算量だけでなくメモリアクセスの量も速度を決める重要な要素です。計算量に対するメモリアクセスが多すぎる場合、そちらが律速となり計算量を減らしても単純には実行時間が変わらないというようになっていきます。
計算量に対するメモリアクセスを減らす方法としてはバッチサイズを増やすというのが最も一般的で、これは保存すべきactivationのメモリ消費を増やすことに繋がります。前述の通り、巨大モデルの学習ではGPUメモリの消費量も大きな問題なので、バッチサイズを増やすのは簡単ではありません。
再計算 などによるメモリ消費の削減手法を事前に準備して学習を開始しましたが、今回の取り組みではバッチサイズを十分大きくすることができませんでした。再計算方法の最適化が甘かったこと、モデル並列との組み合わせで性能を出しきれなかったこと、などが要因と考えています。
超巨大MoEの学習を実用的なものとするためには、この点に関する開発・最適化が重要と言えます。
モデルの性能
最後に今回学習したモデルの性能についての調査結果を紹介します。
モデルの性能について、train lossのscalingを調査しました。同じ条件 (100B token) で1B、3B、13Bのモデルを学習し、train lossを両対数のグラフにプロットしました。
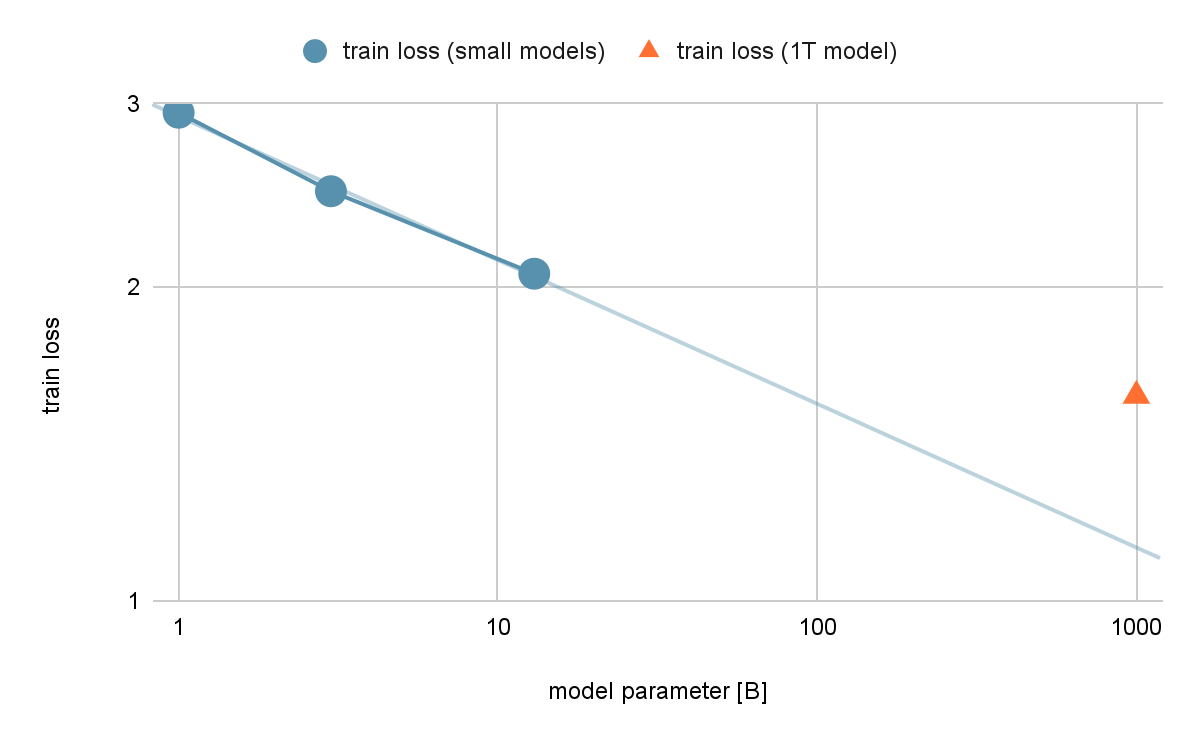
図6: 学習後のtrain lossとモデルサイズ
scaling law によればこのときtrain lossは直線にのるはずですが、結果をみると1Tパラメータのものはより小さい規模の実験結果から予測するよりもtrain lossが悪化しています。
ただし、予測に使う点が3点しかないので予測の信頼性が高くないことには注意が必要です。より小さい規模の実験を多数行いフィッティングを正確に行うことが望ましいですが、実験にかかる時間や他の検証との優先順位などから、最低限の実験にとどめました。
1Tクラスのモデルの性能が予測よりも悪い原因はいくつか考えられます。
1つの候補は、1Tモデルというモデル規模と比較して学習token数が100B tokenでは少なすぎるという可能性です。ただ、learning curveを見る限り学習の後半はtrain lossの低下が落ち着いていて、学習序盤という状況ではないように見えます。
もう1つの可能性として、MoE自体パラメータを増やすには工夫が必要であるという可能性もありえると考えています。MoEにおけるscaling lawを調査した論文では、モデルが大きくなるにつれてMoEのアーキテクチャにも工夫をしないとscaling lawが成り立たないという実験結果が報告されています。
論文ではExpert Choice Routing、我々はHash LayersとMoEのアーキテクチャは違いますが、同様の現象が起きている可能性があると考えています。一方で論文で効果があったとされるアーキテクチャの工夫は実効効率を下げることが予想され、計算速度とモデル性能のバランスが取れる設定をみつける必要がありそうです。
なお、今回の検証ではtrain loss以上の指標の確認 (downstream taskなど) は優先度を下げて行いませんでした。これは、超巨大モデルのMoEにおけるモデルアーキテクチャは改善の必要があることがわかり、今詳しく検証してもモデルアーキテクチャの変更により状況が変わる可能性があると考えたためです。
最後に
1TパラメータクラスのLLMの事前学習について、検証結果を紹介しました。
この規模のMoEでは規模を大きくして初めて起こった問題が多く、より学習時間を伸ばしてモデルを学習するためにはさらなる開発が必要ということがわかりました。今回取り上げたような問題を扱っている論文は我々の知る限りなく、LLMの事前学習において重要な知見を得られたと思います。
一方、Nemotron-4-340b やllama3.1 などここ数ヶ月で公開された超巨大モデルはどれもMoEの使用をやめており、そもそもMoEによる巨大モデルの実現という方針自体、見直す必要があるのかもしれません。
仲間募集中
PFN/PFEでは今後もLLMの開発を継続して行っていきます。今回紹介したのは非常に実験的な取り組みですが、開発はそれ以外にも多岐に渡ります。我々はこれらの課題に情熱をもって挑戦していく仲間を募集しています。
これらの仕事に興味がある方はぜひご応募よろしくお願いします。
Area