Blog
1.内容紹介
はじめまして。PFNでSummer Internship 2017に続き、アルバイトをしている東京大学の西浦です。現在は駒場2キャンパスの先端研で神経科学・循環器系の数理モデルの研究をしています。
さて、2017年の春頃、DeepMindから”Emergence of Locomotion Behaviours in Rich Environments”[1]という論文が公開され、その動画が話題になりました。しかし、この論文では公開されている情報が限られており(深層学習分野でよくあることなのですが)、実験環境の設定、ネットワークの構成や学習に必要なパラメータで不明なものが多く、論文の結果を再現するためには不明な部分を推定するために多くの組み合わせを試す必要がありました。そのため、このような実験の再現は深層学習の実践的な知識と学習のための大規模なリソースが必要とされ、個人で行うのはなかなか難しいと思います。今回はその論文をChainer FamilyのひとつであるChainerRLを利用して再実装し追試を行い、その結果として様々な知見が得られましたのでご報告させていただきます。
Emergence of Locomotion Behaviors in Rich Environmentsの元動画
2.元論文の概要
強化学習のパラダイムは、原理的には単純な報酬のみから複雑な振る舞いを学習することができるようになっています。しかし実際は、意図した振る舞いを学習させるためには、報酬関数を慎重にチューニングすることが一般的です。この論文では、報酬はなるべく直感的な構成で固定してしまい、学習に使う環境(タスク)を様々な種類用意して、エピソードごとにランダムにその環境を変更するというアプローチが採用されています。これにより、様々な環境に対してロバストで、複雑な行動を獲得させようということをモチベーションに実験が行われています。
アルゴリズムとしては、方策勾配法(Policy Gradient)をベースにして、現在の方策に近い方策へと徐々に更新していくProximal Policy Optimization(PPO)[3]を用いています。PPOは論文公開当時では一番性能の良い強化学習のアルゴリズムだったのでそれが採用されていて、論文には同じく性能のよいTrust Reigion Policy Optimization(TRPO)[4]との比較もされています。
3.アルゴリズム、実験手法の解説
前提知識
まず強化学習のフレームワークについて説明します。強化学習では環境とエージェントというのがあり、エージェントが環境に対して行動をし、環境はそれを受けてエージェントに対して観測と報酬を返すという枠組みになっています。エージェントは、報酬に基づいて行動を決定するためのルール「方策(Policy)」を学習していきます。この論文では、ロボットなど連続値の行動を扱いやすい方策勾配法を採用しています。方策勾配法ではActor-Criticモデルという、エージェントをActor(行動器)とCritic(評価器)でモデル化し、例えばそれぞれをニューラルネットワークで表現します。また、エージェントがActor-Criticモデルだと、例えば、Actorのネットワークを決定しているパラメータが方策に該当します。Criticは、現在の方策の元である状態がどれだけの価値を持つかを表す価値関数(ある状態以降の報酬の期待値に割引率をかけたものが一般的)でモデル化されます。
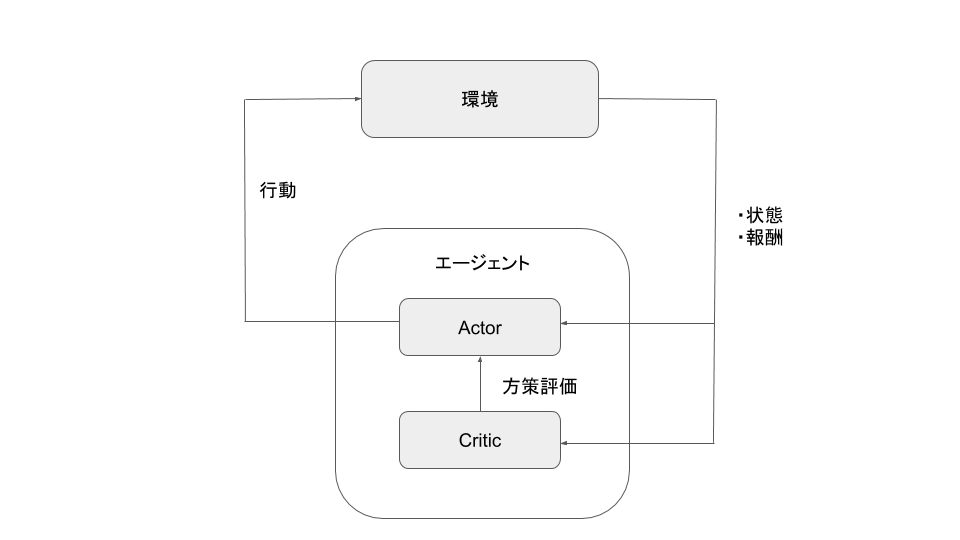
実験環境としては、物理エンジンのMuJoCo [2]と強化学習のフレームワークであるOpenAI Gym [5]を用いています。代表的なものとしては、Planar walker(またはWalker2d)と呼ばれる二次元平面内でエージェントに二足歩行を行わせるモデルが挙げられます。Planar walkerの場合、それぞれのエージェントは各関節を曲げるトルクにより行動を表現することになります。また、エージェントが環境から受けとる観測は、大きく内部状態と外部状態に分けられ、各関節の角度、角速度、位置、接触、トルクセンサ情報などを内部情報、地形の高さ情報を外部情報として受け取っています。報酬はPlanar walkerの場合だと以下のように設計されており、基本的には前に進むと報酬がもらえ、それに加えて姿勢のペナルティー(負の報酬)などが含まれています[1]。

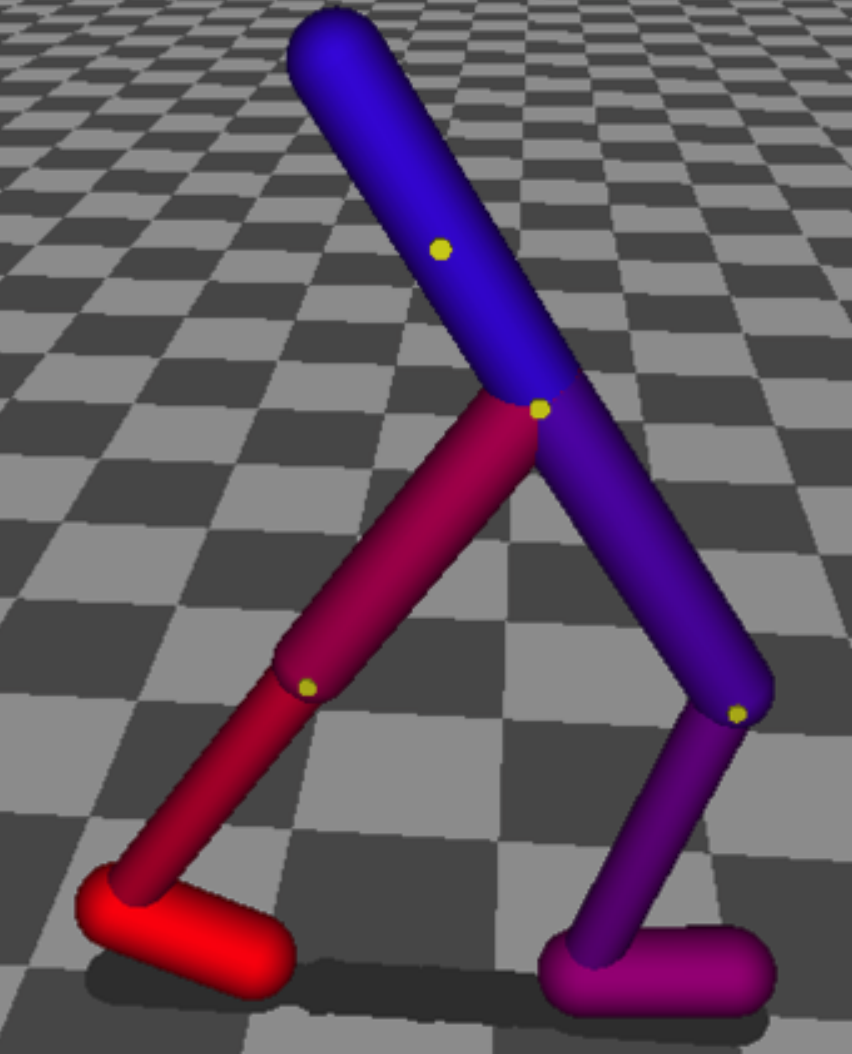
Planar walker [4]
今回追試したアプローチでは、方策を決定するネットワークは内部状態と外部状態を別々に処理して最後に合わせて処理して、行動の次元個分、平均と分散の組を指定した正規分布を確率的方策としてを出力する構成になっています。
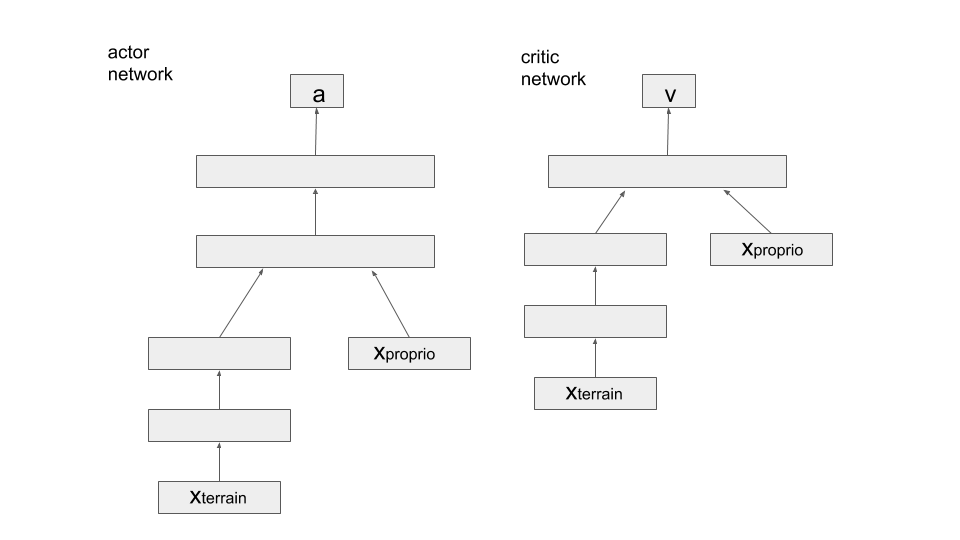
アルゴリズム
ここで、追試で使ったTRPOとPPOの二つのアルゴリズムについて解説します。まず、ベースになっている方策勾配法は、目的関数(原則としては現在の方策による期待値を用いる)を方策のパラメータに関して微分し、得られた勾配方向にパラメータを更新する方法です。目的関数を計算するために、現在の方策で行動して、その系列データを貯めること(一般化方策反復)を行います。しかし、方策の更新には慎重になる必要があり、一度方策が劣化してしまうと、それから後に得られるサンプル系列も悪化してしまい、持ち直すのが難しくなるという問題があります。
そこでTRPOは、方策の更新に制限をかけながら更新していきます。具体的には、KLダイバージェンスを使って信頼領域(trust region)を定義して、その信頼領域を超えないように、制約条件つきの最適化問題を解くことにより方策のパラメータを更新します。これにより方策の分布として大きな変化を抑制することができて、方策の大きな劣化を防ぐことができます。TRPOが二回微分を計算するので、計算量が多いことを踏まえ、PPOはTRPOの制約条件を目的関数に含めて非厳密化することで、TRPOより単純で軽い計算量でそれなりの性能を発揮するアルゴリズムになっています。
具体的には、方策を \(T * N\) time steps走らせて(Nはスレッドの数)集めた \(s_t\) ,\(a_t\), \(r_t\) を用いて \(A_t\)(アドバンテージ)を計算し、\(L^{CLIP} \)を前の方策と新しい方策の比率を \(\pm \epsilon\) 内にクリップして勾配方向にパラメータを更新していきます。方策のネットワークと価値関数のネットワークでパラメータを共有する(最後の出力層のみそれぞれのパラメータを使う)なら、方策と価値関数のネットワークを独立に更新できないので、目的関数に価値関数の誤差項を加え、探索の幅を増やしたければ、エントロピーボーナスを加えることもあります。(最終的な目的関数は \(L^{CLIP+VF+S} \))ここで登場するアドバンテージとは、収益(報酬の期待値)からベースラインを引いたもので、勾配の推定値の分散を減らすためのテクニックです。それぞれの計算式を以下に示します[3]。
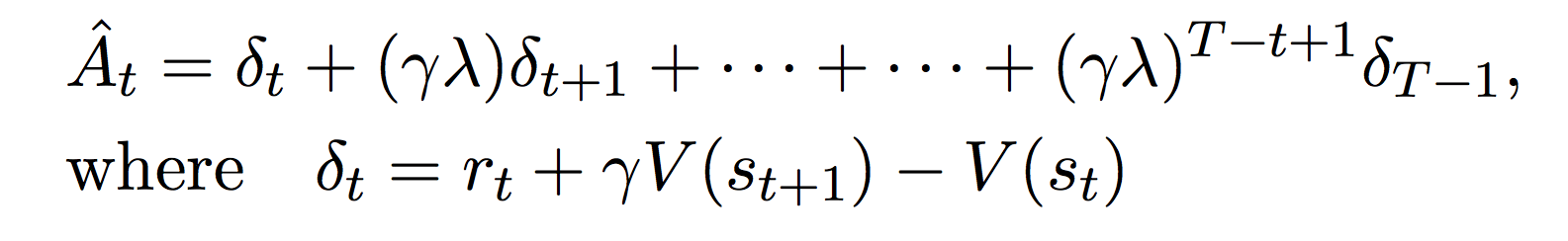
![]()
![]()
![]()
元論文ではPPOをさらに分散版にしたものを使っています。追試としては、PPOで方策ネットワークと状態価値関数にLSTMを含んだものと、TRPOを用いましたが、1スレッドの場合では、TRPOの方がかなり性能がよかったです。したがって、以下の結果は全てChainerRLのTRPOで学習させた結果となります。
実験手法
追試としては2通りの環境で訓練しました。一つ目は元論文の動画に近い3種類のタスクがある環境で、もう一つは地形の凸凹の状態がランダムに変わるものです。
元論文に近い環境では、Planar Walkerを①箱を飛び越えるタスク、②穴を飛び越えるタスク、③浮いている板を避けるタスクの3種類の環境で順番に訓練した後、3種類の環境(タスク)がランダムにエピソードごとに切り替わる環境で訓練します。
地形の凸凹の状態がランダムに変わる環境では、エピソードごとにすべての地形が変わる中で訓練します。
4.結果
学習し始めのエピソードごとにランダムに地形が変わる中で試行錯誤している様子
学習後歩いている動画
こちらでは、学習初期段階からランダムに地形を変更していたためか、とにかく脚を高く上げて、どんな障害物でも越えられるような動きになってしまったようです。

動画に示した歩行行動を獲得するまでの学習曲線を上に示します。10,000ステップごとに10エピソード走らせて評価を行なっており、青のrewardは10エピソードの平均累積報酬で、上下の灰色の線は10エピソード内での最小値最大値になっています。200万ステップほどで収束していることが分かります。
元論文に近い環境で学習後歩いている様子
障害物によって頭を下げたり、ジャンプする高さが変わったり、動きが変わっていることが見て取れます。一つ目と二つ目の動画ではPlanar walkerの関節の減速比のパラメータが違っていて、このような微妙な差でも獲得される動きに違いが出てしまいます。
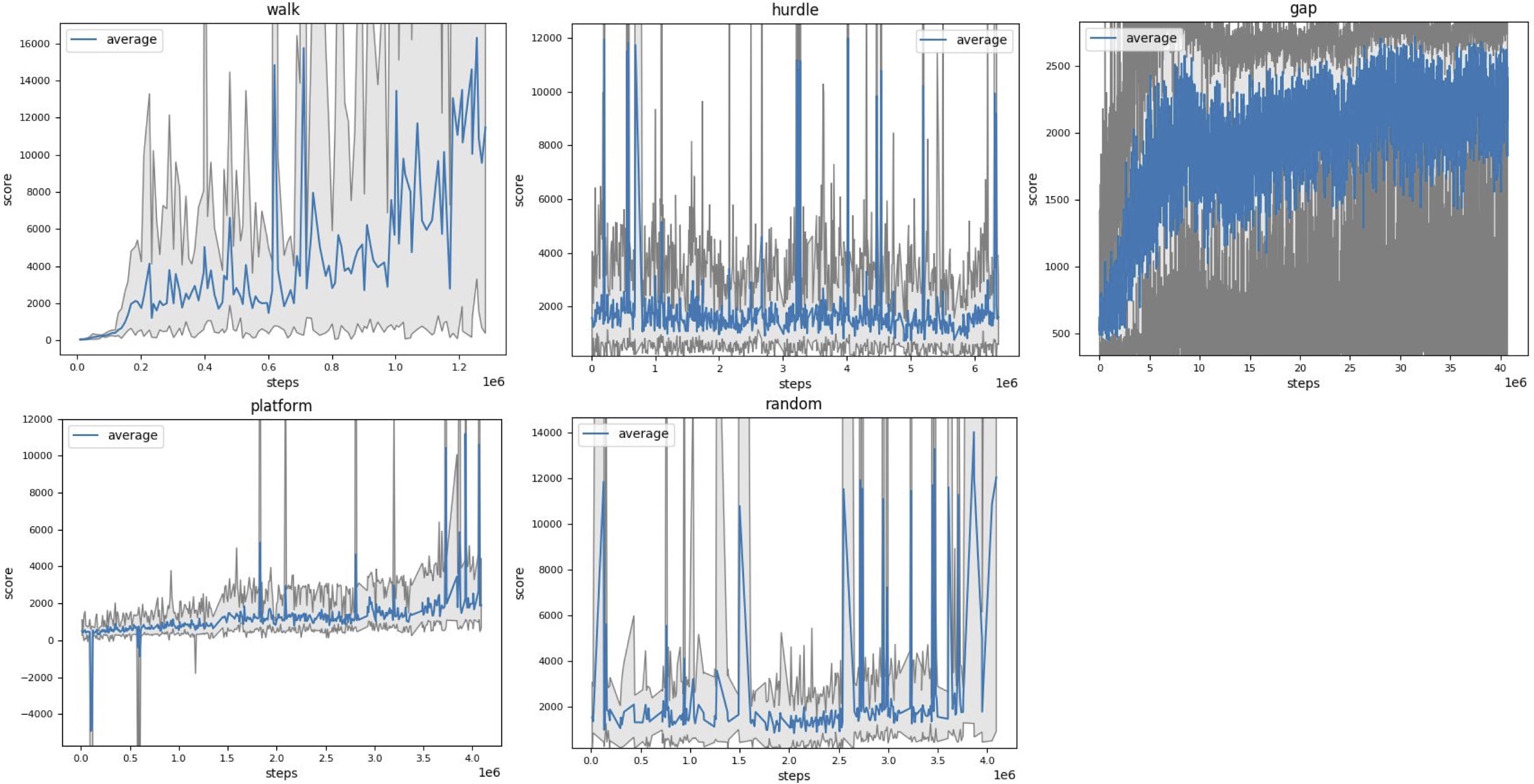
動画に示した歩行行動を獲得するまでの学習曲線を上に示します。歩く動作は120万ステップほど、穴を飛び越える動作は800万ステップほど、浮いている板を避ける動作は400万ステップほどで学習が収束していることが分かります。
タスクによって報酬の平均がそこまで変動していないものもあり、歩く動作を獲得した状態から箱を飛び越える動作の獲得にはそれほど学習が必要ではないが、箱を飛び越える動作を獲得した状態から穴を飛び越える動作を獲得するのと、箱を飛び越える動作を獲得した状態から浮いている板を避ける動作を獲得するためにはかなり学習が必要であることが分かります。
元論文では適切に実験設定が考えられていて、カリキュラムラーニングになっていたために、タスクに応じて行動をうまく切り替えられるようになっていましたが、ただ単に地形やタスクをランダムに変えるだけでは、どんな環境にも対応するような方策を獲得してしまうようです。
5.考察
問題点の一つに、初期条件を注意深く設定しないと意図した学習結果になりづらいという問題があります。今回の場合も初期の状態変数の分散や、地面とMuJoCoのモデル(Planar walkerなど)との高さ方向の相対的な位置は学習の様子をみながら調整することが必要でした。具体的に注意した点としては以下のような点が挙げられます。
- ある程度初期状態に分散がないと、分散の範囲で実現できる行動になってしまう。(逆に分散が大きすぎても学習がうまく進まないことがある)
- 環境をリセットした時に何ステップ分フレームをスキップしてから指令を出し始めるか、によって獲得されるモーションが変わってくる。(例えばMuJoCo環境内で、完全に地に足が着いてから指令値を出すようにした、など)
- 歩行を獲得させる場合、学習の過程で最初に獲得されるのはその場に立っているという方策なので、初期位置の周辺はなるべく平らな方がよさそう。
その他にも、下記の記事[6]に現状の深層強化学習の課題はよくまとまっているので、ぜひ読んでいただきたいです。(方策を更新していくために特定のアルゴリズムを採用しても、報酬関数、方策を表現するネットワークのパラメータなどは自分で任意に決定する必要があり、設定する報酬によって獲得される方策がかなり変わってしまうという問題など。)
失敗例の動画
けんけんを獲得している動画(初期化した時の相対的な高さの問題で、片足を前に出す方策を獲得できなかった例、初期状態の分散はうまくいった例と同じ)
6.PFNインターンの感想
ある仮説を検証するのに、「ある実験系でやってみて上手く行かなければもっと単純化した系でやってみる。」という、研究の基礎的なプロセスの体験ができたのはとてもよかったです。また、ロボティクス関係の様々な研究を知ることができ、そこで研究している人たちとの繋がりができたのは一番大きな収穫だったかもしれません。最後に、情報交換の重要性も強く意識することができました。有名なライブラリやパッケージの使い方(インストールで苦戦するものなど)や、こういう手法を試したけどいまいちだった、ハイパーパラメータの情報など、公開されていなけど実験をしていく中では欠かせない情報などを共有できる環境が、とてもありがたいなと感じました。
元論文の情報が結構少なく、なかなか学習が進まず進捗が出ずに精神的に辛い時期もありましたが、様々な方に積極的に相談するようになってからは比較的スムーズに乗り切ることができたように思います。最後になりましたが、ご指導いただいてるメンターの皆様をはじめ、社員の方々に感謝を表して報告を終わらせていただきたいと思います。
参考文献
[1] “Emergence of Locomotion Behaviours in Rich Environment” https://arxiv.org/abs/1707.02286v2
[2] MuJoCo advanced physics simulation http://mujoco.org/
[3] “Proximal Policy Optimization Algorithms” https://arxiv.org/abs/1707.06347
[4] “Trust Reigion Policy Optimization” https://arxiv.org/abs/1502.05477v5
[5] OpenAI Gym https://gym.openai.com/docs/
[6] “Deep Reinforcement Learning Doesn’t Work Yet” https://www.alexirpan.com/2018/02/14/rl-hard.html



