Blog
数式が正しく表示されない場合は、こちらのリンクから再読込をお試しください。
みなさんはじめまして。Preferred Networksの2017夏季インターンに参加し、現在アルバイトをしている上野裕一郎です。普段は東京工業大学でHigh-Performance Computingに関する研究を行っており、分散・並列計算に興味があります。
今回は、分散深層学習を行う際に使用されるAllReduceという通信パターンについて調査・実装・評価を行いましたので、それについてご説明いたします。
分散深層学習とは
現在、ディープニューラルネットワークを用いた学習には長い時間がかかることが知られています。そして、様々な種類のモデルや、大量のデータを組み合わせて学習を試すためには、学習にかかる時間を短縮する必要があります。そのために、多数のプロセスに分散して計算を行うことで、学習にかかる時間を短縮することを目的とするのが分散深層学習です。分散深層学習の詳細については、Preferred ResearchのChainerMN 公開に関する記事[1] をご参照ください。
弊社では、深層学習の研究開発や関連技術の迅速な実用化のために、スーパーコンピュータ MN-1 を運用しています。これは、民間企業のプライベートな計算環境としては国内最大級で、NVIDIA(R)製 Tesla(R) P100 GPUを1,024基、Mellanox(R) InfiniBand FDRを搭載しています。これを用いて、ImageNetの画像分類データセットを利用したResNet-50の学習を15分で完了することができました[2]。
しかし、このような多数のGPUを用いて効率的に計算を行うのは多くの困難が伴います。そのうちの1つとして、データ並列型分散深層学習において、GPU同士の通信にかかる時間がボトルネックとなっていることが挙げられます。
分散深層学習では、どのような通信が発生し、なぜ時間がかかるのか、もう少し詳しくご説明します。
分散深層学習におけるAllReduceの重要性
データ並列型分散深層学習では、異なるデータでモデルのパラメータでの損失関数の勾配を求めたあと、プロセス間で勾配の平均を求め、求めた平均を得られた勾配とみなして、モデルに適用を行います。この勾配の平均を求める操作として、多対多の通信を行う集団通信アルゴリズム:AllReduceが用いられています。
このとき、最もよく用いられているのが、NVIDIA社が提供しているNCCL[3] (NVIDIA Collective Communications Library)です。NCCLは、並列・高性能計算の分野の標準であるMPIと比較して、圧倒的に高速な通信を実現しています。前述のImageNet15分実験においても、NCCLが実現する高速通信は、記録の達成には不可欠なものでした。現在、ChainerMNでデータ並列型分散深層学習を実行するにあたっては、NCCLは必須のライブラリとなっています。
さて、NCCLの高い性能の秘密はどこにあるのか、社内でも多くのリサーチャーやエンジニアが興味を持ちました。今回は、実験的にAllReduce通信プログラムを作成し、最適化することによって、NCCLの性能にどこまで迫れるかを試してみました。
AllReduceのアルゴリズム
では、分散深層学習のスループットに大きな影響を与えるAllReduceについて詳しく見ていきます。
AllReduceとは、すべてのプロセスが持っている配列データを集約(Reduce)したうえで、すべてのプロセスがその結果を等しく取得する操作です。まず、総プロセス数を \(P\), そして、それぞれのプロセスには\(1\)から\(P\)までの番号\(p\)がついているとします。そして、各プロセス\(p\)が長さ\(N\)の配列\(A_{p}\)を持っているとしましょう。さらに、プロセスpが持つi番目のデータを \(A_{p,i}\) とします。このとき、最終的に得られる配列を \(B\)とすると、
$$ B_{i}~~=~~A_{1,i}~~Op~~A_{2,i}~~Op~~…~~Op~~A_{P,i} $$
となります。ここで、\(Op\) は2項演算子で、SUM(合計)、MAX/MIN(最大値/最小値)などがよく用いられます。つまり、ここでいう集約(Reduce)とは、配列の要素 \(A_{p,i}\) を、\(p=1,…,P\)までの全プロセスにわたって \(Op\)を用いて畳み込み計算することになります。分散深層学習においては損失関数の勾配の平均が必要であるため、勾配の要素ごとにSUMを用いて合計を計算します。以降では、集約操作に用いる演算はSUMだと仮定します。図1に、\(P=4\), \(N=4\)のAllReduceを実行する模式図を示しています。
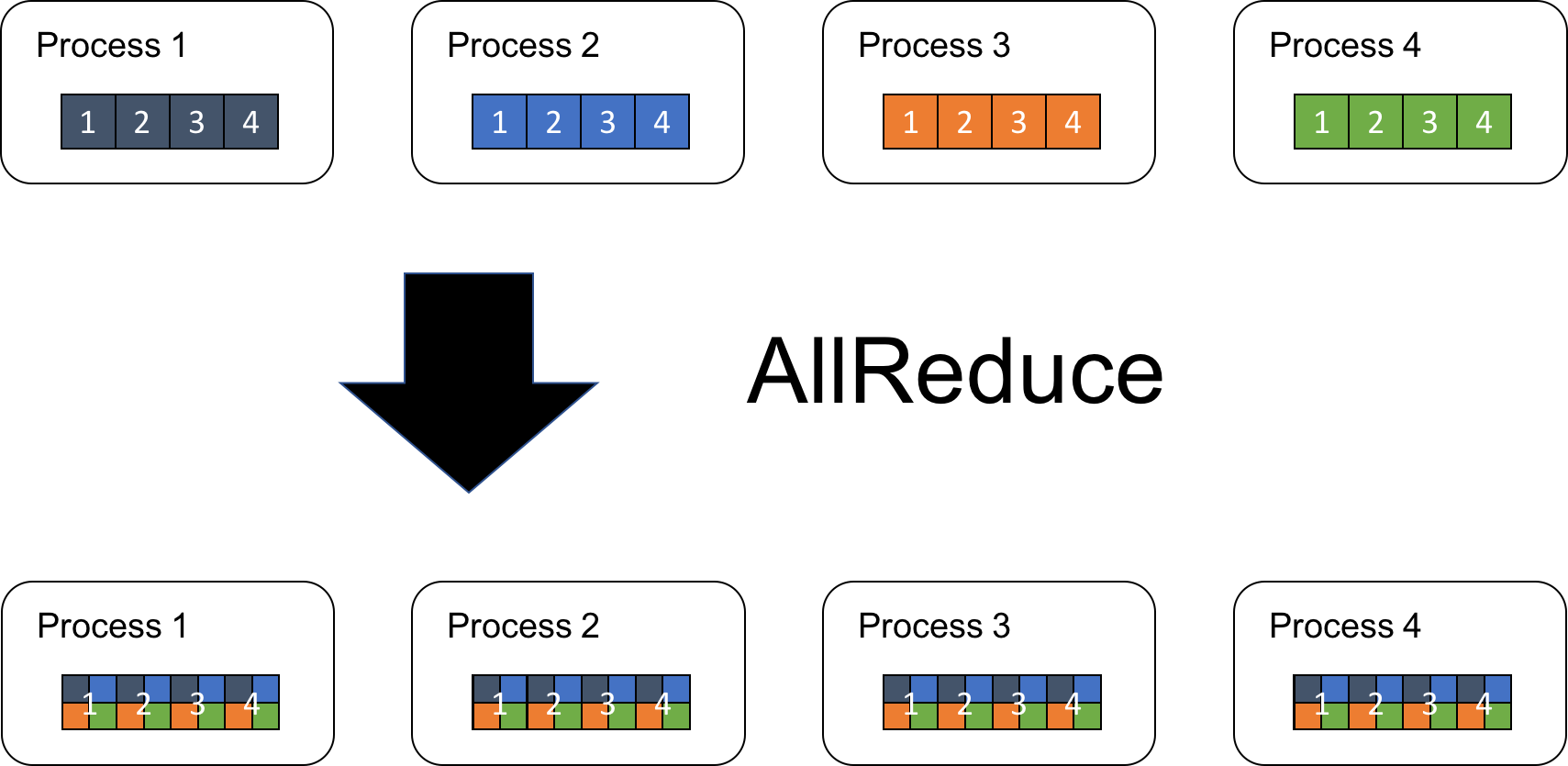
このようなAllReduce処理を実装する方法として、複数の方法が考えられます。
例えば、最も単純な方法として、代表となるプロセスを1つ決め、そこに全ての配列を集め、そのプロセスが全てのReductionを行い、計算結果を全プロセスに配布する、というアルゴリズムを考えることができます。しかし、このアルゴリズムは、プロセス数が増えると代表プロセスの通信量、Reduceの計算量、メモリ使用量がそれに比例して増え、処理量に不均衡があります。
このようにプロセス間の処理量に不均衡が存在しないよう、うまく通信や計算を全てのプロセスに分散させたアルゴリズムが提案されています。代表的なものとして以下のものが挙げられます。
- Ring-AllReduce
- Rabenseifnerのアルゴリズム[4]
本稿では、Ring-AllReduceアルゴリズムについて紹介します。NCCLも、Ring-AllReduceを用いて実装されています[5]。
Ring-AllReduce
まず、総プロセス数を\(P\), そして、それぞれのプロセスには\(1\)から\(P\)までの番号がついているとします。そして、各プロセスが図2のようにリングを構成するとしましょう。
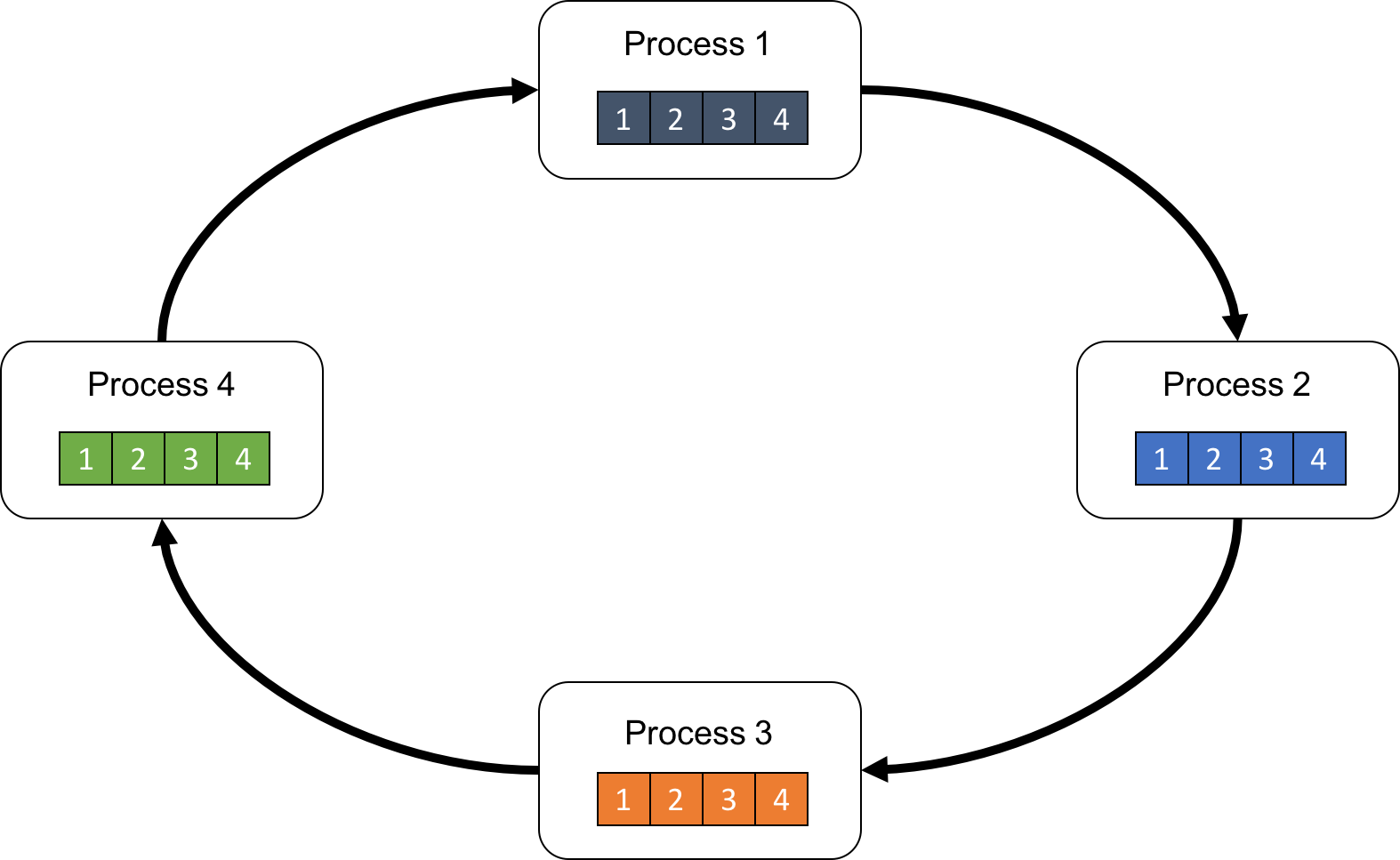
ここで、プロセスpに着目して処理の流れを見ていきます。
まず、プロセスpは、自分の配列をP個に分割し、この分割された配列のp個目をチャンク[p]と表記するとします。そして、プロセスpは、チャンク[p]を次のプロセスp+1に送信します。この時、同時にプロセスp-1はチャンク[p-1]の送信を行っているので、プロセスpはこれを受信することができます(図3)。
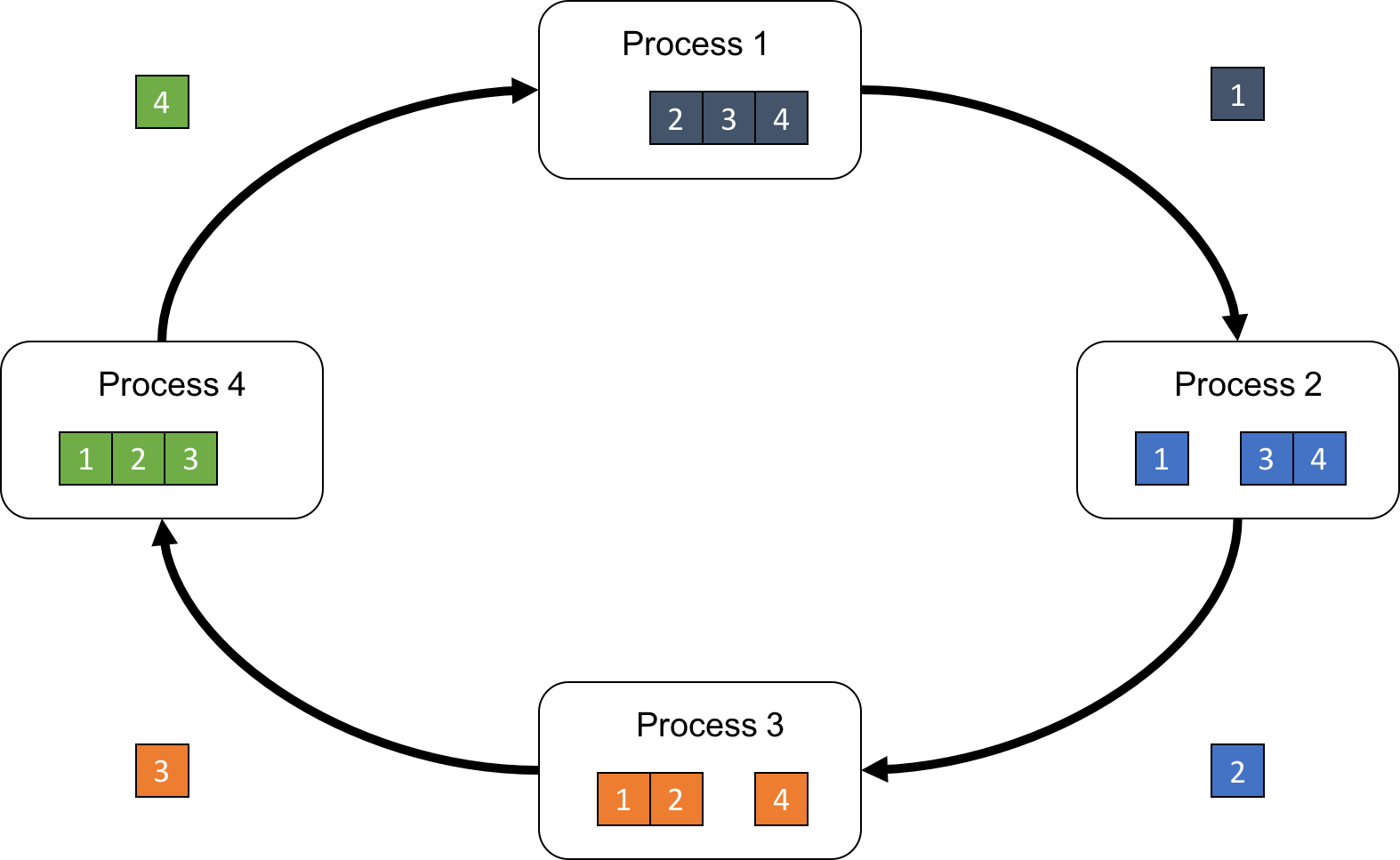
そして、プロセスpは、受信したチャンクに自分のチャンク[p-1]を足し込み(Reduceし)、計算結果を次のプロセスに転送します(図4)。
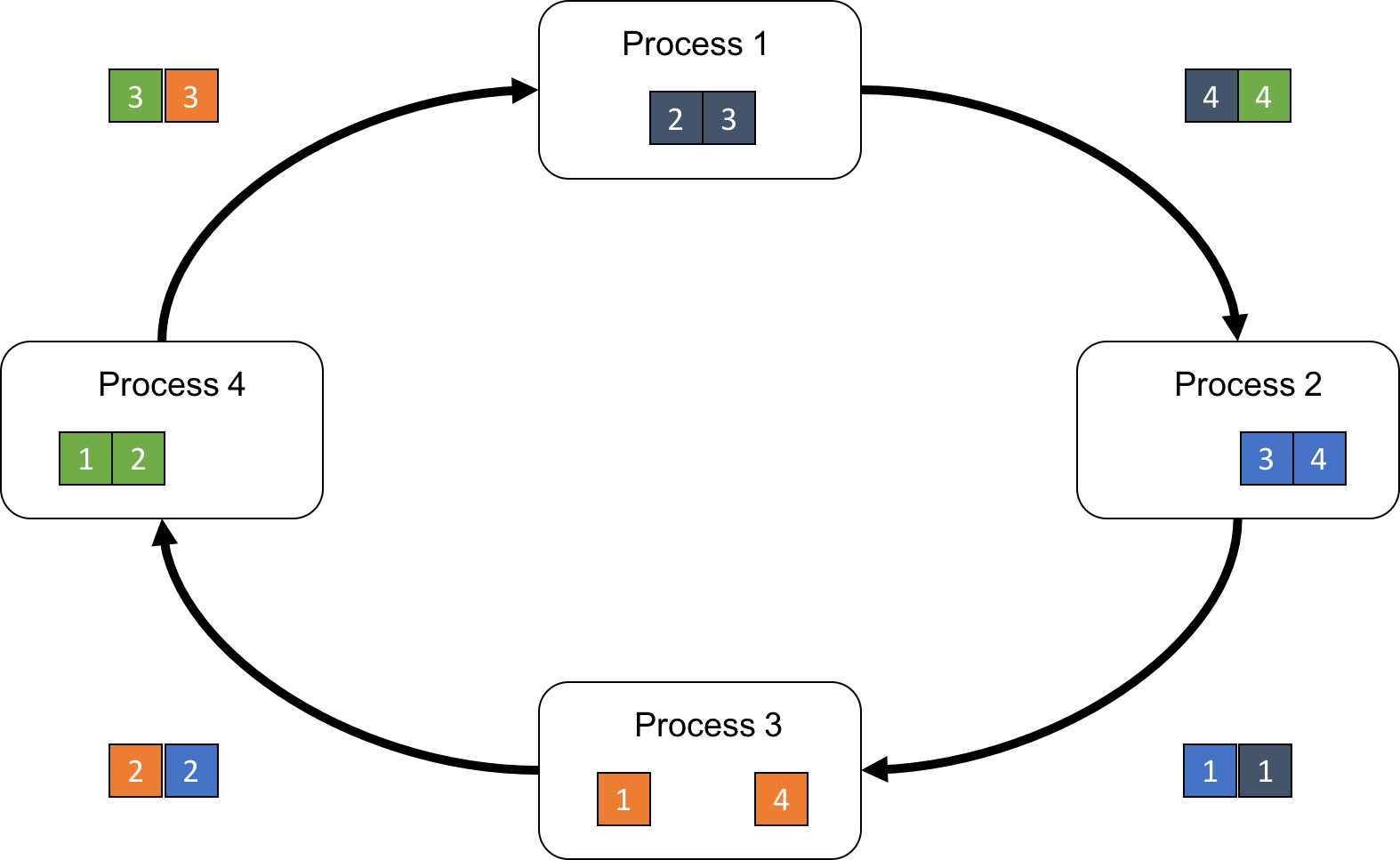
これをP-1ステップ繰り返すことで、それぞれのプロセスが、Reduce済みのチャンクを1つ手に入れることができます(図5)。
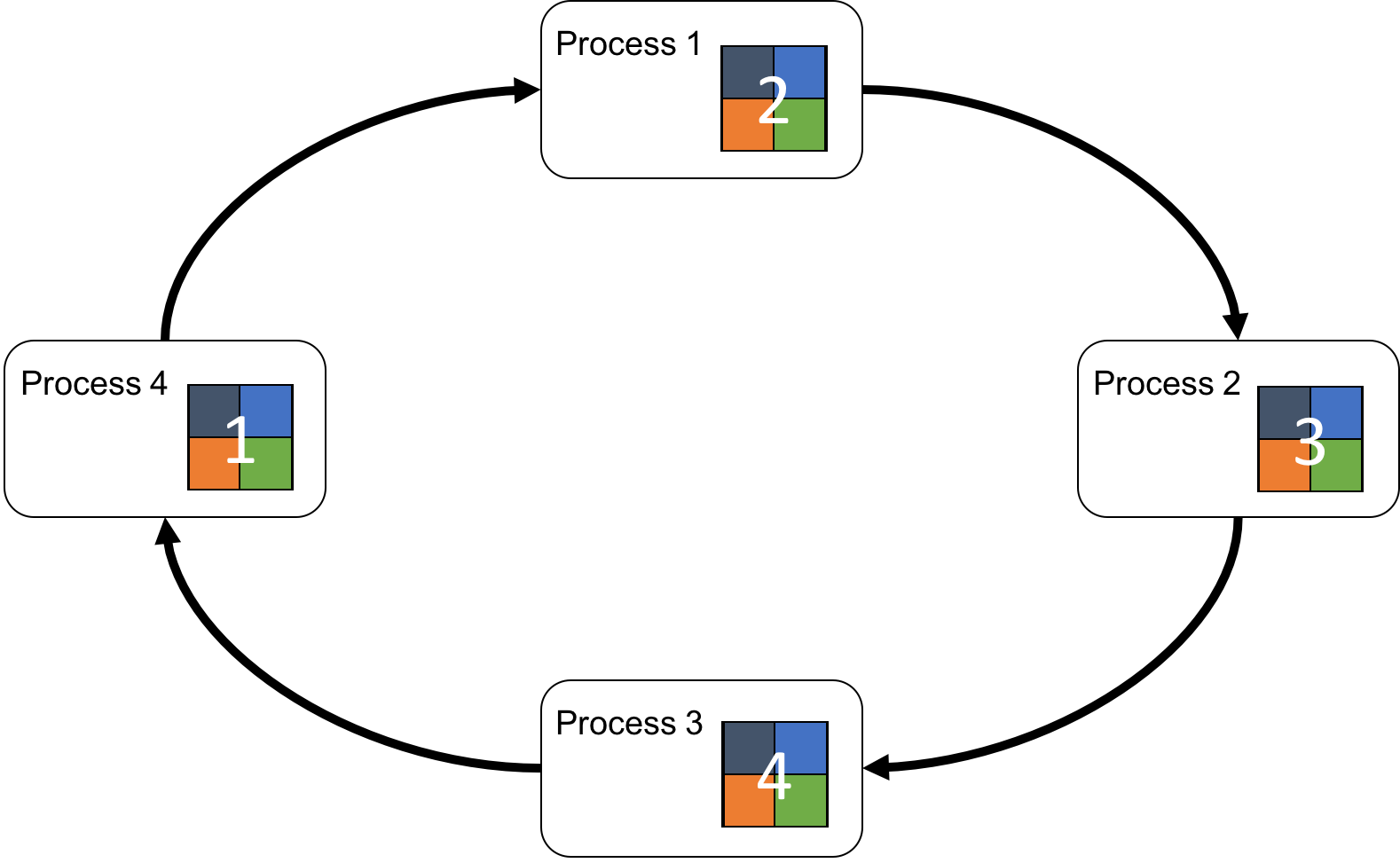
言い換えれば、各々のプロセスが、リングの上をまわるチャンクに、自分のチャンクを少しずつ足しこんでいきます。そして、チャンクがリングに沿って全プロセスを1度ずつ訪問した時点で、そのチャンクは、全てのプロセスのチャンクの集約の結果になっています。つまり、最終的には、それぞれのプロセスが、チャンクごとの集約の結果を1つ保持していることになります。
そして、それぞれのプロセスが持つ集約済みチャンクを、さらにリング上で一周回すことで、全てのプロセスが集約済みチャンクを全て取得でき、AllReduceが完了したことになります。
では、このアルゴリズムの通信量を、先程挙げた単純なアルゴリズムと比較してみましょう。
単純なアルゴリズムの場合、代表プロセスが受信するデータの量は、代表プロセスでない全てのプロセスからデータを受信する必要があるので、\((P-1) * N\)となります。その後、代表プロセスでない全てのプロセスにデータを送信する必要があります。これは、Pに対して代表プロセスの受信量が比例しています。
対して、Ring-AllReduceにおける1プロセスあたりの送信(受信)したデータの量は、以下のように求めることができます。最初に、P個に分割した配列をReduceしながらP-1回送信しました。そして、全プロセスにそのReduce済みチャンクを配布するために、P-1回送信しました。よって、1プロセスあたりの送信量はこの合計である \(2(P-1)/P * N\)となり、1プロセスあたりの送信量はPに関して定数であることが分かりました。
よって、2つのアルゴリズムを比べると、Ring-AllReduceは代表プロセスに集中していた送信・受信量を各プロセスにうまく分散させたアルゴリズムになっていることが分かります。このような特徴から、多くのAllReduceの実装でRing-AllReduceアルゴリズムが用いられています。
実装と最適化
Ring-AllReduceのアルゴリズムそのものは、GPU対GPUの通信を行う送受信関数を用いれば、簡単に実装することができます。Baidu社によるbaidu-allreduce[6]は、MPIのライブラリ上で実装済みの MPI_Send, MPI_Recv関数を用いてこれを実現しています。
今回は、MPIではなく、InfiniBandを直接扱うことができるInfiniBand Verbsを用いて実装し、より進んだ最適化を試みました。まず、InfiniBand、GPU、CPUのそれぞれのハードウェアリソースのアイドル時間を可能な限り削減して性能を引き出すために、アルゴリズムの処理をRegistration, Send, Reduction, Receive, Deregistrationなどのステージに分割し、パイプライン化を行っています。ここで、Registration, Deregistrationは、メモリ領域をDMAを用いて転送する際に必要な前処理、後処理を表しています。これらは、MPIを用いて実装すると、 分割してパイプラインに組み込むことができません。
さらに、配列を分割したものであるチャンクを、パイプラインの粒度をより細かくするために更に分割しました。また、メモリ確保は低速であることが知られているので、メモリプールを導入してコストを隠蔽しています。
性能評価
本稿で実装したプロトタイプ(PFN-Proto)の性能を、他の既存実装(詳細は付録に記載)と比較しました。比較対象を、スーパーコンピュータで広く用いられている通信ライブラリであるOpen MPI[7]、Baidu社によるbaidu-allreduce[6]、NVIDIA社によるNCCL[3]です。
なお、今回の我々のプロトタイプ実装は、ノード間通信に焦点を当てて開発しており、ノード内でのGPU間のDMA通信や共有メモリを使った通信最適化は実装されていません。実験では、1ノードに1プロセスを実行する条件でのみ測定しています。また、Open MPIについては、最新シリーズであるバージョン3.xではGPU Directに関係するバグがあり、弊社内ではまだ導入していないため、2.1.3を測定対象としています。
総プロセス数を8として、1ノードに1プロセスを起動することとし、256MBの配列のAllReduceをそれぞれ10回ずつ実行して測定を行いました。実験環境は、MN-1を用いています。実験環境の詳細は付録「実験環境」をご参照ください。図6に性能評価の結果を示します。
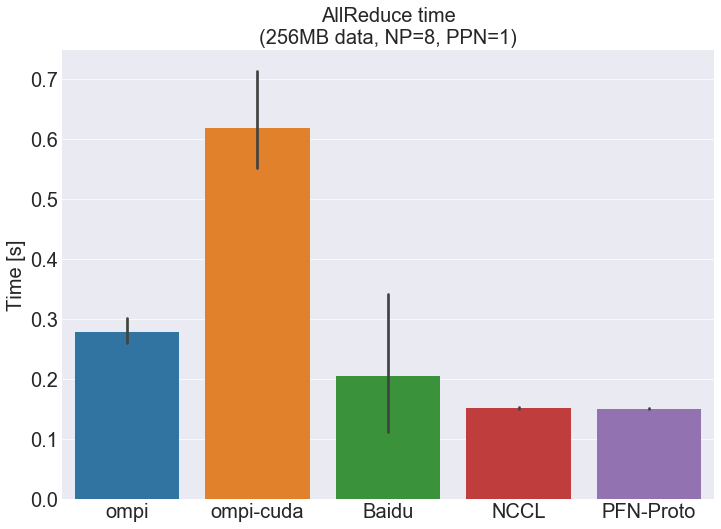
この棒グラフは実行時間を示しており、低いほうが良い結果を示します。各棒は、それぞれのライブラリの10回の実行時間の中央値、エラーバーは実行時間の95%信頼区間を表しています。各実装の名前の意味、バージョンなどは、付録「比較対象ソフトウェア」をご参照ください。
まず、実行時間の中央値について見てみましょう。一番右側に示されているPFN-Protoが、最も高い性能を示しています。これは、ompi, ompi-cuda, Baidu, NCCLと比較して、それぞれ約82%, 286%, 28%, 1.6% 高速となっています。なお、グラフ上には示されていませんが、10回試行中の最速は、baidu-allreduceで0.097 [s] となりました。
次に、実行時間の分布について見てみましょう。中央値を基準にした実行時間の最大値と最小値は、PFN-Protoが +/-3%、NCCLが+/- 6%以内に収まっています。一方、baidu-allreduceは最大値が中央値の7.5倍という大きな数字となりました。これは、初回実行時に大幅に時間がかかるためです。なお、初回の試行を除いた最大値も中央値の+9.6%となっており、依然としてNCCLおよびPFN-Protoよりもばらつきが大きいことがわかります。
MPI、およびMPIをベースにした実装でこのように性能にばらつきが出る原因としては、MPIが内部で行っているメモリ領域の扱い方に関連していると推測しています。MPIは、InfiniBandによる送受信に必要となるメモリ領域の確保とRegistrationなどを抽象化したインターフェイスを提供しています。これにより、Ring-AllReduceの実装から、それらの発生タイミングを精密に制御することができないため、性能にばらつきが出ると考えられます。
関連研究
今回は、分散深層学習の中のAllReduce操作の高速化についてご説明しました。それ以外にも、分散深層学習の通信部分を高速化する方法として様々なものが考えられています。例えば、
- 勾配の送受信を1イテレーション遅延させて、Forward, Backwardと通信をオーバーラップする方法(例:ChainerMNにおけるDouble Buffering[8])
- データの浮動小数点精度を下げることによって通信量を削減する方法(例:ChainerMNにおけるFP16通信[8])
- 勾配の値の重要度によって送受信するデータを間引いて通信量を削減する方法[9]
などがあります。特に、InfiniBandを持たないような環境(例えばAWS)では、このようなテクニックを用いることで学習を高速化することができます。
まとめ
本記事では、分散深層学習を支える技術である、AllReduceという通信パターン、特にRing-AllReduceという通信アルゴリズムについて説明しました。
そして、このアルゴリズムを実装し、今回の実験環境・実験条件では、NCCLと同等の性能まで最適化することができました。そのためには、InfiniBand Verbsを使用し、徹底的なパイプライン化を行うことが必要であったことが分かりました。これにより、高いハードウェアの性能と並行性を十分に活用することができました。これからも、より高速で、高い信頼性を持つ通信にはどのようなアルゴリズムやチューニングが最適か、調査・開発を進めていきたいと考えています。
ただし、今回の実装は、社内のクラスタを使用して開発・最適化しており、社内のクラスタのみに最適化された実装になっている可能性があります。それに対してNCCLは、幅広い環境で安定して利用できる高速な集団通信ライブラリであり、依然として、NVIDIA製GPUを用いて分散深層学習を行うためには、NCCLを使用するべきであると考えています。
謝辞
最後に、インターンの頃からメンターの方々やチームの方々には手厚いサポートをしていただきながら、大量の計算資源のもとでプロジェクトを進めることができており、非常に貴重な経験をさせていただいています。本当にありがとうございます。
おまけ:メンターより
上野さんのインターンシップメンターを務めています、PFN 大規模分散計算チームの福田(@keisukefukuda) です。今回は、NCCLの高い通信性能はどのように実現されているのだろうか?という疑問からスタートした実験的なプロジェクトでしたが、上野さんの高い技術力によってNCCLに近い性能を出すことに成功しました。
PFNでは、機械学習/深層学習そのものの研究だけでなく、ソフトウェアからハードウェアまで、広い分野で研究開発を進めています。
HPC・高性能計算に興味を持っている学生の皆さんは、ぜひ来年のPFNインターンシップへの応募をご検討ください(このブログ記事の公開時点では、残念ながら2018年の夏季インターンの募集は終わってしまいました)。
また、もちろん中途・新卒の人材募集も通年で行っています。興味のある方はぜひご検討ください!PFNの人材募集のページはこちら https://www.preferred-networks.jp/ja/jobs です。
参考文献
[1] 分散深層学習パッケージ ChainerMN 公開
[2] Akiba, et al., “Extremely Large Minibatch SGD: Training ResNet-50 on ImageNet in 15 Minutes”
[3] NVIDIA Collective Communications Library
[4] Rabenseifner, “Optimization of Collective Reduction Operations”, ICCS 2004
[5] Jeaugey, “Optimized Inter-GPU Collective Operations with NCCL”, GTC 2017
[6] baidu-allreduce
[7] Open MPI
[8] ChainerMNのクラウド環境向け新機能とAWSにおける性能評価
[9] Tsuzuku, et al., “Variance-based Gradient Compression for Efficient Distributed Deep Learning”, In Proceedings of ICLR 2018 (Workshop Track)
付録
比較対象ソフトウェア
| Implementation | Version | Note |
|---|---|---|
| MPI (ompi) | Open MPI 2.1.3 | CPUメモリからCPUメモリへの転送 (他の実装はすべてGPUメモリからGPUメモリへの転送) |
| CUDA-aware MPI | Open MPI 2.1.3 | |
| baidu-allreduce (baidu) | A customized version of baidu-allreduce, based on commit ID 73c7b7f | https://github.com/keisukefukuda/baidu-allreduce |
| NCCL | 2.2.13 |
実験環境
- Intel(R) Xeon(R) CPU E5-2667 x 2
- Mellanox(R) ConnectX(R)-3 InfiniBand FDR (56Gbps) x 2
- NVIDIA(R) Tesla(R) P100 GPU (with NVIDIA Driver Version 375.20)
Tag



