Blog
本記事は、PFNのインターンシップを経て現在はアルバイトとして勤務されている松本直樹さんによる寄稿です。
PFN における分散キャッシュシステム
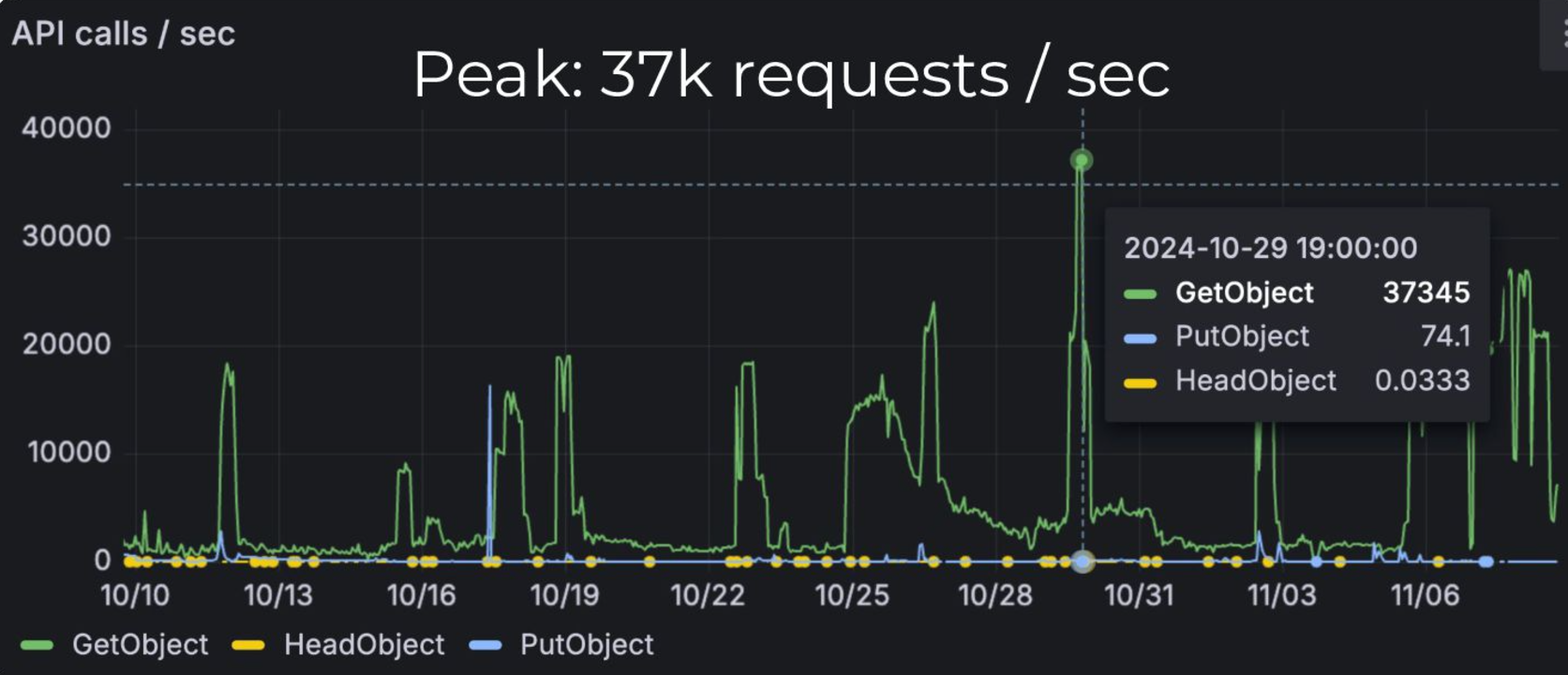
PFN では深層学習におけるデータセット読み込みやコンテナイメージ配布を高速化するために、独自の分散キャッシュシステムであるSimple Cache Service (SCS) を提供しています(深層学習のための分散キャッシュシステム – Preferred Networks Research & Development)。SCSは、GET, PUT のシンプルな HTTP API を持ち、Kubernetes クラスタ上にデプロイされた Pod上のPython をはじめとする種々のアプリケーションから容易に利用することができます。2023年のデプロイ以降、2年に渡る運用で生じた種々の問題(詳細は上記ブログをご参照ください)を解決し、ピーク時 37k req/s, データ量にして 75.1 GiB/s のリクエストを処理しています。
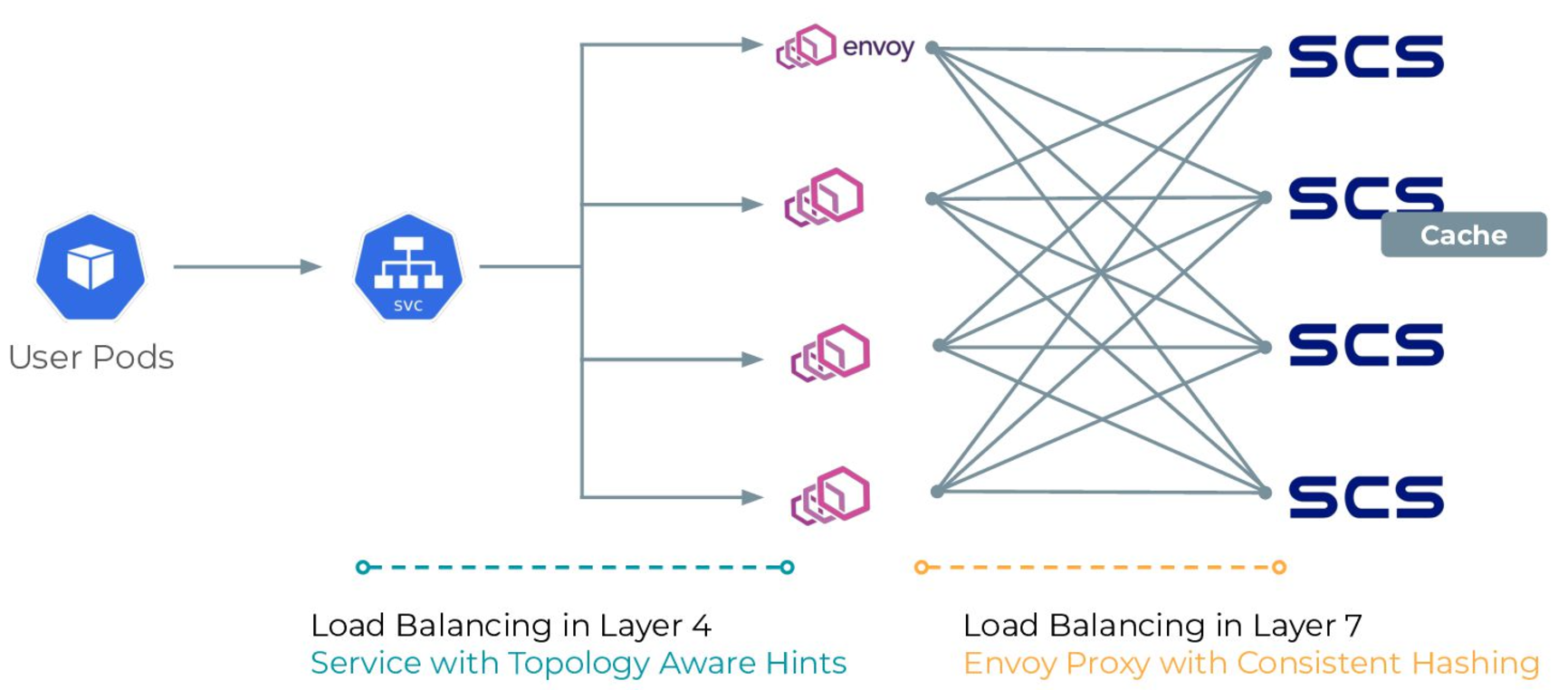
SCS は “shared nothing architecture” を設計思想として持ち、シンプルな実装とプロファイリングによるチューニングにより数100us ~ 数ms でのキャッシュデータ提供を可能にしています。全体のアーキテクチャにおいても、Kubernetes の Service と Envoy Proxy を活用した L4, L7 での負荷分散により、単一障害点を持たず、ノードの追加に応じて容易にスケールできるスケーラビリティを持ちます。
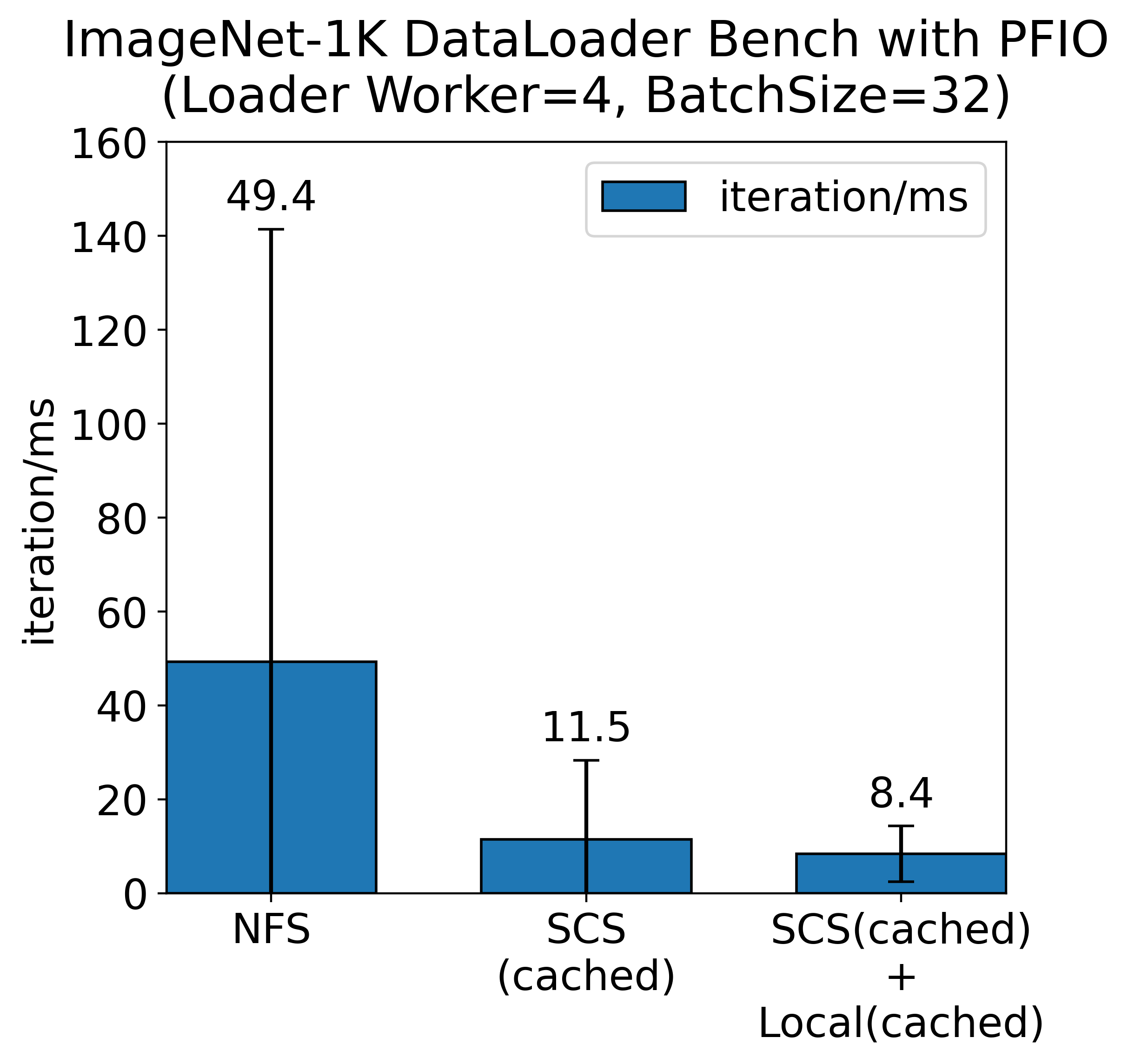
深層学習をはじめとする実際のワークロードにおいても、PFN が開発しているI/Oの抽象化ライブラリである PFIO 等と SCS を組み合わせることでデータセットの読み込みを高速化することができます。ImageNet-1K を用いたデータローダーのベンチマークにおいてはデータの読み込みを4倍程度高速化し、限られた GPU 資源をより効率的に活用することができます。
すでに SCS は多くの用途で活用される一方、性能改善の余地も存在します。本記事では、SCS の Node サーバーに対して行った改良事例を紹介します。
SCS Node の概要
SCS では、Envoy が SCS Node サーバーに対してリクエストを振り分けるアーキテクチャになっています。SCS Node は、内部に オブジェクトの管理を担う sqlite3 や、ストレージの使用量を一定に抑えるための LRU (Least Recently Used) 用のモジュールが存在します。
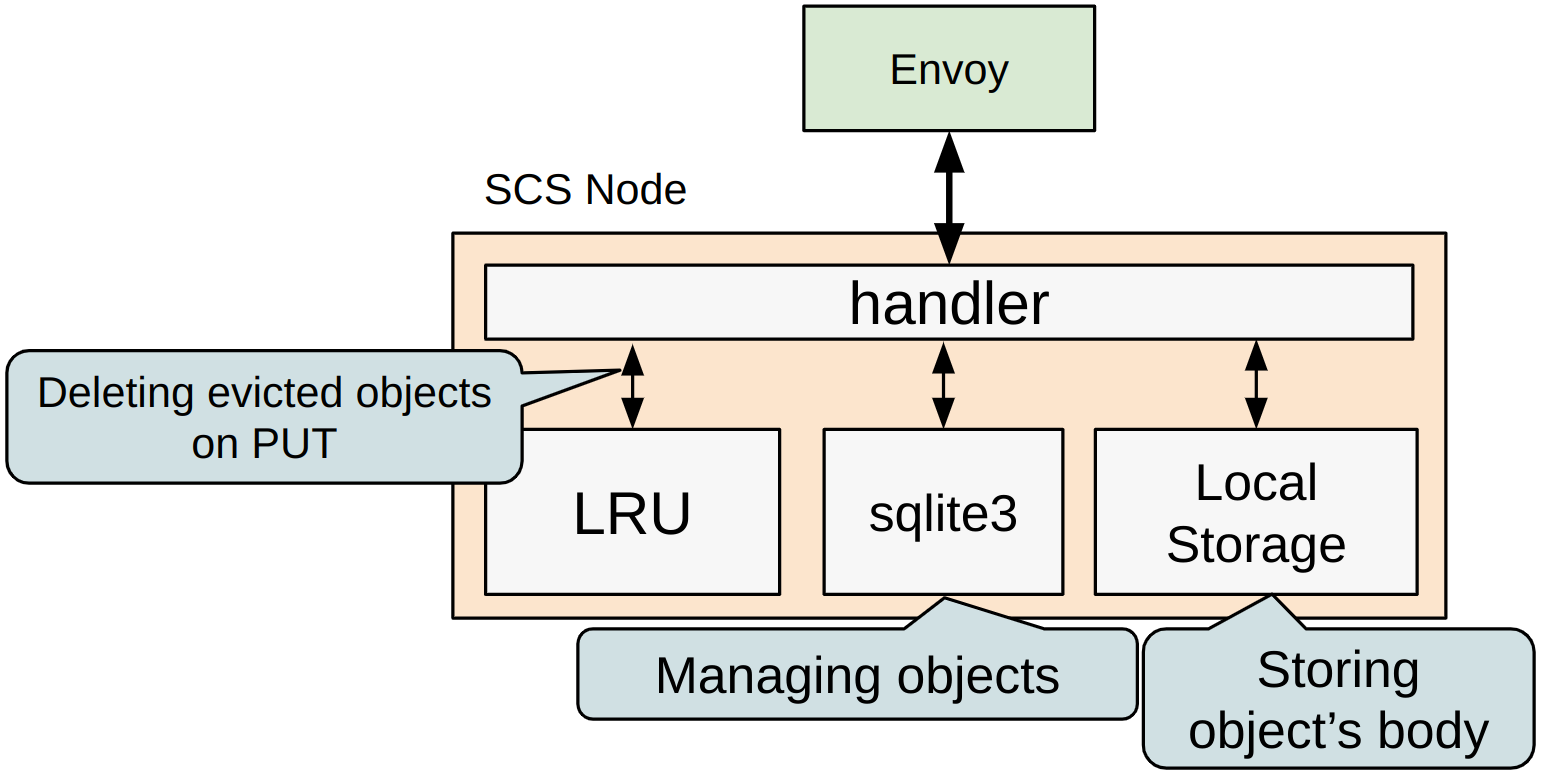
sqlite3 は SCS Node が保持するすべてのオブジェクトを管理し永続化も担います。オブジェクトの実体はノードローカルの高速ストレージにおいて保持します。LRU モジュールはキャッシュの中心となる「容量の制限を超えないように古いオブジェクトを消す」機能を提供し、PUT 時に制限を超えた古いオブジェクトを削除する仕組みになっています。
SCS Node は、オブジェクトがPUTされる度に LRU と sqlite3 に対してオブジェクトの管理情報を作成、追加する処理を行います。sqlite3 は 変更操作時にデータベースファイル全体でロックを取る という仕様上、INSERT, UPDATE の処理は並列で行うことができず、PUT の処理性能のボトルネックとなりCPUのコアを使い切れないなどの問題を引き起こしてしまいます。また、SCS Node 内部でも、オンメモリで管理情報をキャッシュする機構は大きなロックを取らざるを得ない部分が存在し、同様の問題をはらんでいます。今回は、この問題に対する改善を行いました。
シャーディングによる性能改善
SCS Node は単一のノードローカルストレージを想定して設計されていますが、今後複数のノードローカルストレージや、更に高速なストレージの利用を考慮し、今回はシャーディングによる処理ロジックの分離および並列化による改良を行いました。これにより、オブジェクト管理に関するボトルネックが解消され、さらなる性能が得られることが期待されます。
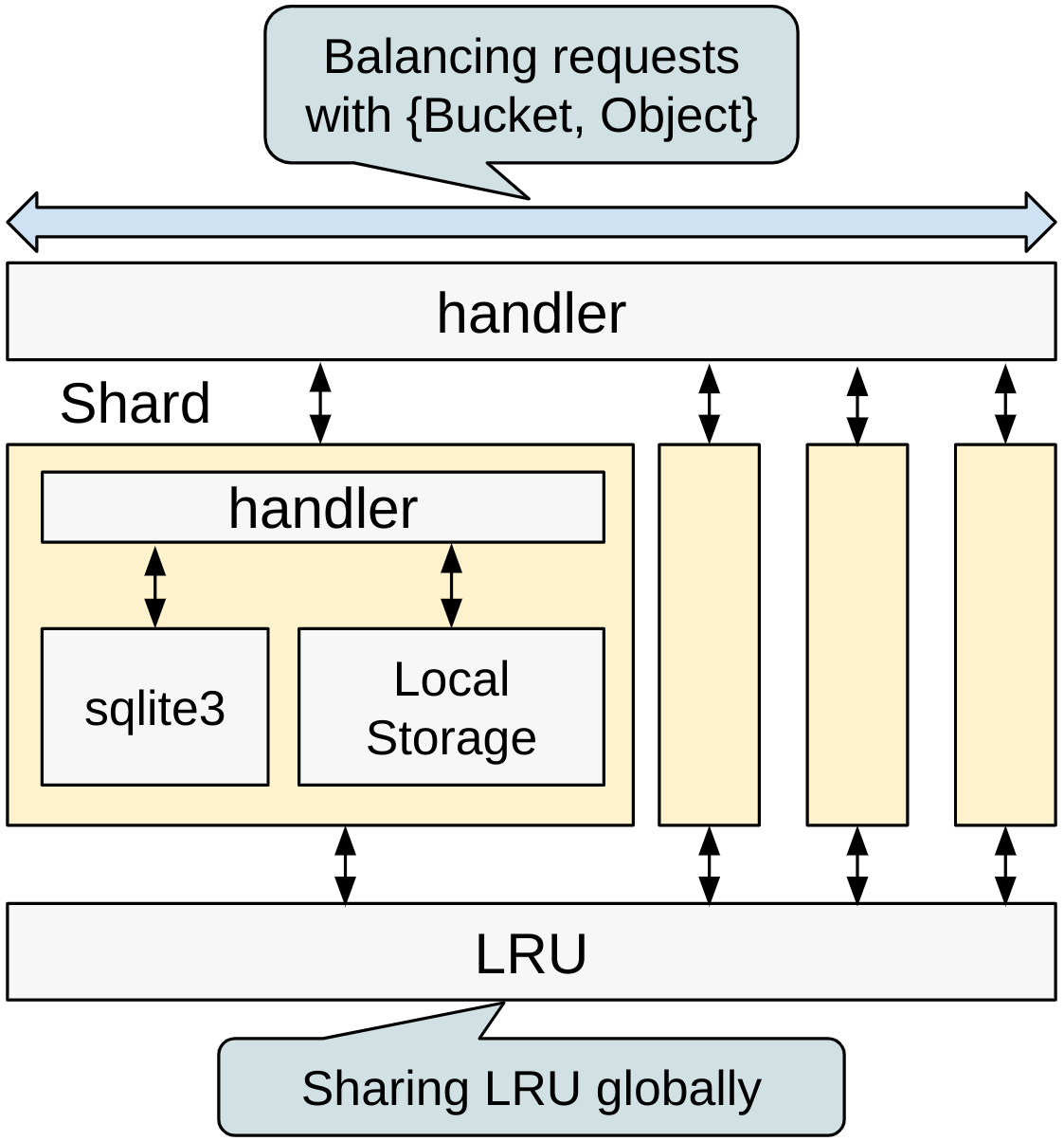
改良された SCS Node では、シャーディングに伴い、オブジェクトを管理するインスタンス(Shard)を複数個持ちます。それぞれのインスタンスは独立した sqlite3 DBを持ち、インスタンス間で競合が発生する可能性を排除しています。また、各ローカルストレージを独立したディレクトリで管理するため、複数のストレージを使いたい場合についても容易に対応できます。
オブジェクトの管理はインスタンス毎に行いますが、LRU についてはノードグローバルに容量を管理するため、グローバルに共有して扱うことにしました。各インスタンスから LRU に対して同時に操作が走るため、内部ではロックによる制御を行っています。性能面ではLRUで律速する可能性がありますが、後述する性能評価に示すとおり、現時点では十分に高速であるため、今回は問題ないものとしています。複数のストレージを使う場合など、ストレージ単位で容量を管理できる場合は、LRU をグローバルに共有せず、ローカルで扱うようにしても良いかもしれません。
性能評価
シャーディングによりもたらされる性能の改善について評価しました。
Shard 数に応じた性能の変化
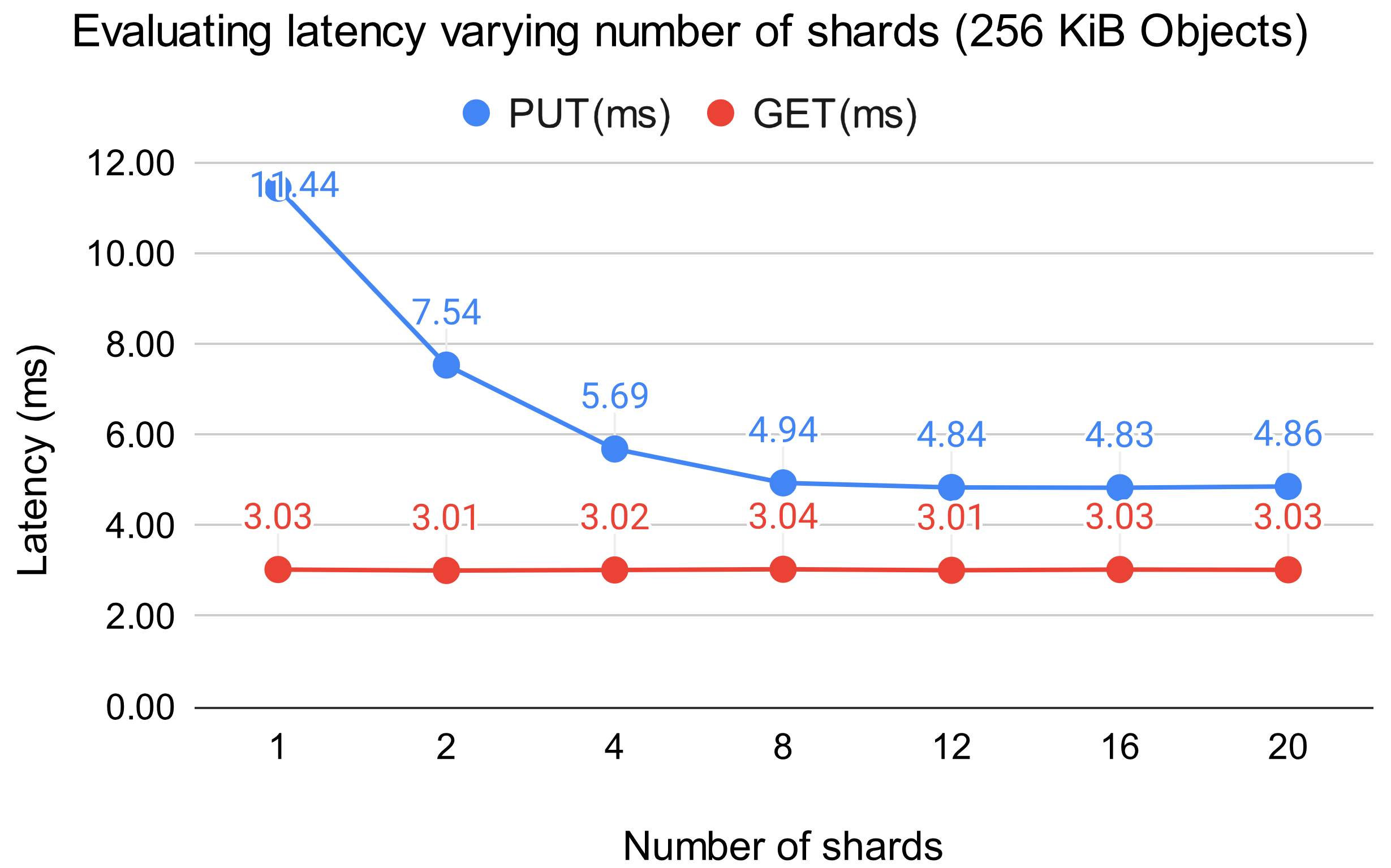
まず、Shard の数を変化させた場合について計測しました。ベンチマーク対象の SCS Node には CPU を 8 コアを割り当てています。ベンチマーカーとしては、256KiB のオブジェクトを20クライアントが並列で指定されたメソッド(PUT もしくは GET) に応じて処理を行うプログラムを用いています。
結果は以下の図のようになっています。Shard 数が 8 になるまでにかけて、PUT の性能が大きく改善していることがわかります。これは、問題として想定していた sqlite3 のロックやオンメモリデータの管理における Write ロック競合が起こりにくくなったためと考えられます。一方で、Shard 数がコア数を超えるとレイテンシの減少が頭打ちになっています。これは十分に並列数を使い切れているためと考えられます。GET については、sqlite3 でもロックを取らず、オンメモリなデータ管理においても Write ロックを取らない設計となっていたため殆ど性能への影響はありませんでした。
クライアントを模擬した合成ベンチマーク
より実用的なベンチマークを行うために、複数のオブジェクトサイズかつPUT, GET を同時に行うベンチマークを行いました。実際のクライアントでは、GET したときに 404 Not Found を受け取るとキャッシュ対象のオブジェクトを PUT します。合成ベンチマークでは、その挙動を組み込んだベンチマーカーを使用します。候補となるオブジェクトのサイズは 256KiB, 1MiB, 4MiB, 16MiB, 128MiB となっています。LRU の制限は 40GiB、通常時のPUTとGET比率は PUT:GET = 1:99 としました。各オブジェクトサイズに対応するクライアントを 5 個、計 25 個のクライアントで並列にリクエストを流し計測を行いました。
計測については、LRUでの溢れが発生しない場合と発生する場合について計測しました。溢れが生じる場合においては、各クライアントがオブジェクトを GET しますが、LRU によりキャッシュから削除されていた場合、再度オブジェクトを PUT を行います。LRU の上限容量は 40GiB で、PUTするデータ量としては約43GiB(各種オブジェクト x 300 個)となっています。
改良前の現在の SCS Node (SCS-cur) と改良後の SCS Node (SCS-shard) におけるレイテンシの比較は下図のとおりです。
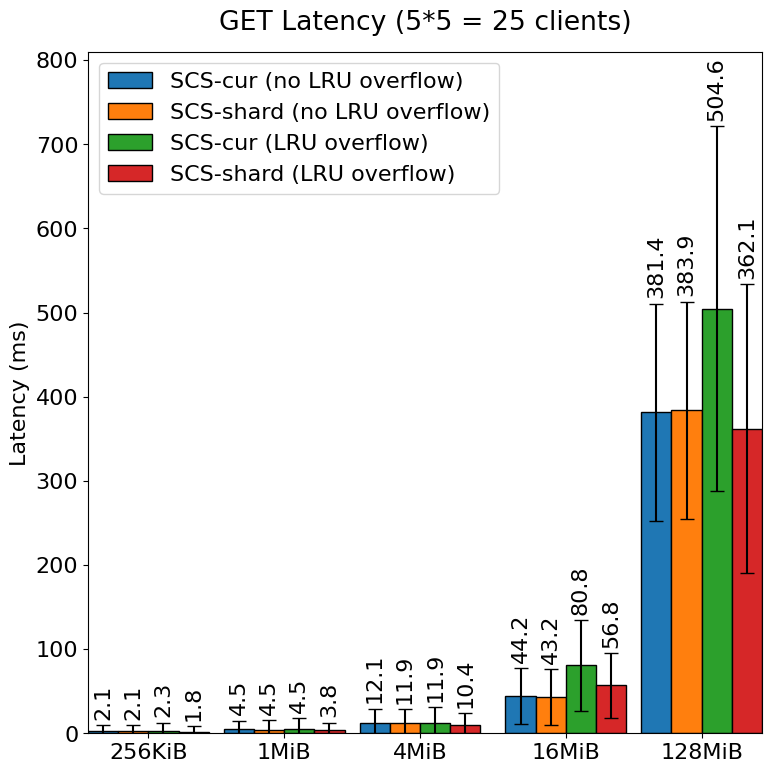
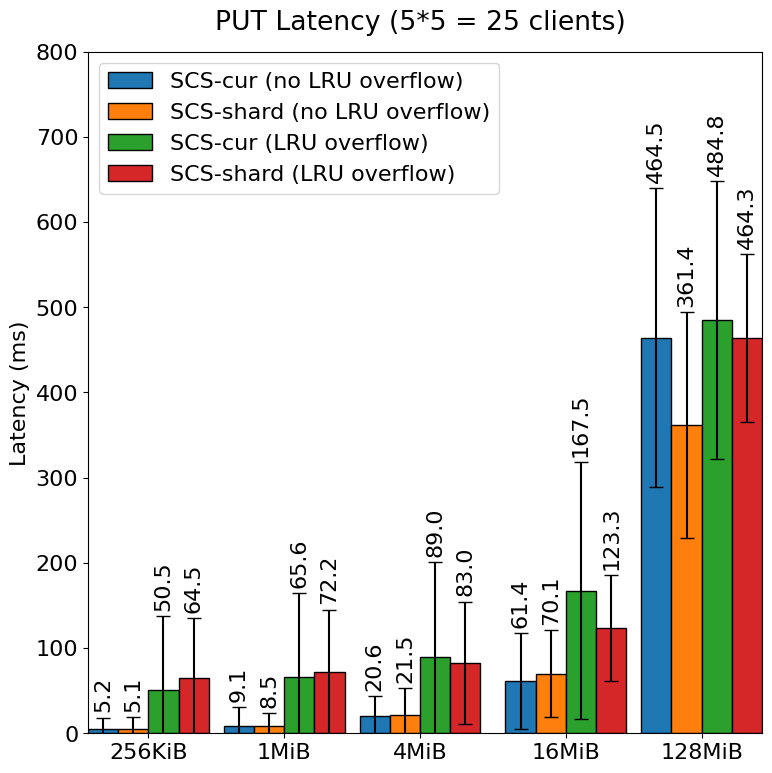
LRU での溢れが発生する場合において、現在の SCS Node でも改良後の SCS Node でも全体の性能は悪化する傾向にあることがわかります。しかし、改良後の SCS Node では現 SCS に比べて GET 全体や大きいオブジェクトに関する PUT については性能劣化がほぼない、ないしは現 SCS Node に比べて、レイテンシの平均値や分散と言った観点について性能の劣化が抑えられていることがわかります。LRU の溢れを処理するとき内部的には Write ロックをとる必要があるため他の GET や PUT の処理に影響を与えていた部分が、シャーディングを行うことによりその影響を軽減できたものと考えられます。
PUT において特に小さいオブジェクトの性能が大幅に劣化した問題の原因としては、LRU から溢れたオブジェクトの削除が PUT の処理内で同期的に行われていることや、スラッシングに相当する現象によりディスク性能の上限に引っかかっているなどが考えられます。SCS 改良後 (LRU 溢れあり) ベンチマーク時のオブジェクトの更新(オブジェクトの保存や削除)速度は 2 GiB/s に到達し、扱うオブジェクトサイズ次第では、一般的な NVMe SSD の性能の上限に達している可能性があります。
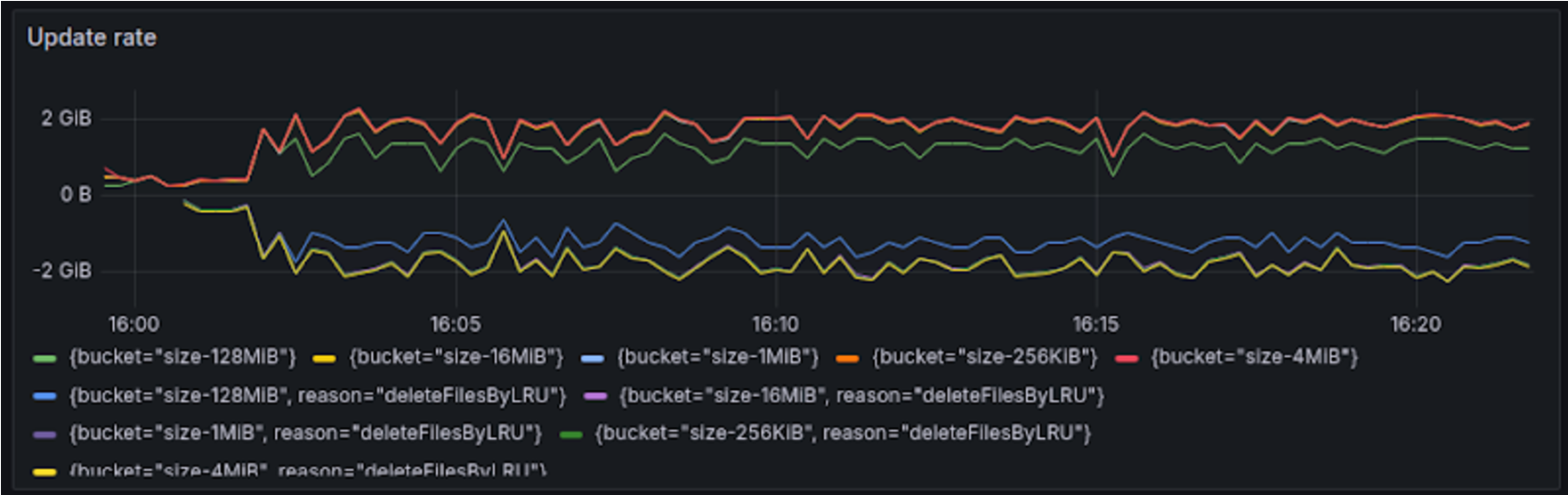
シャーディングにより一定の性能改良は得られたものの、LRU 溢れ発生時における小さいオブジェクト(256KiB, 1MiB) の PUT ついては改良後も依然として溢れが生じない場合に比べて10 倍近くの性能差があり、あらゆるオブジェクトをキャッシュする SCS においてはクライアント側の処理が詰まり性能劣化の問題となります。今後も引き続き改善に取り組みます。
LRU のスケーラビリティ
LRU はShard 間でグローバルに共有されているため、Shard 数、つまり並列数が増えたときの性能への影響が懸念されます。この懸念についても評価を行いました。PUT は Insert、GET は Access に対応し、ベンチマーク中の PUT:GET比は 1:9 としました。また、LRU の上限件数は1000万件とし、あらかじめ1000万個分のオブジェクトエントリを追加した状態、つまり初回の Insert でキャッシュからの溢れが生じるが起こる状態でベンチマークを行いました。
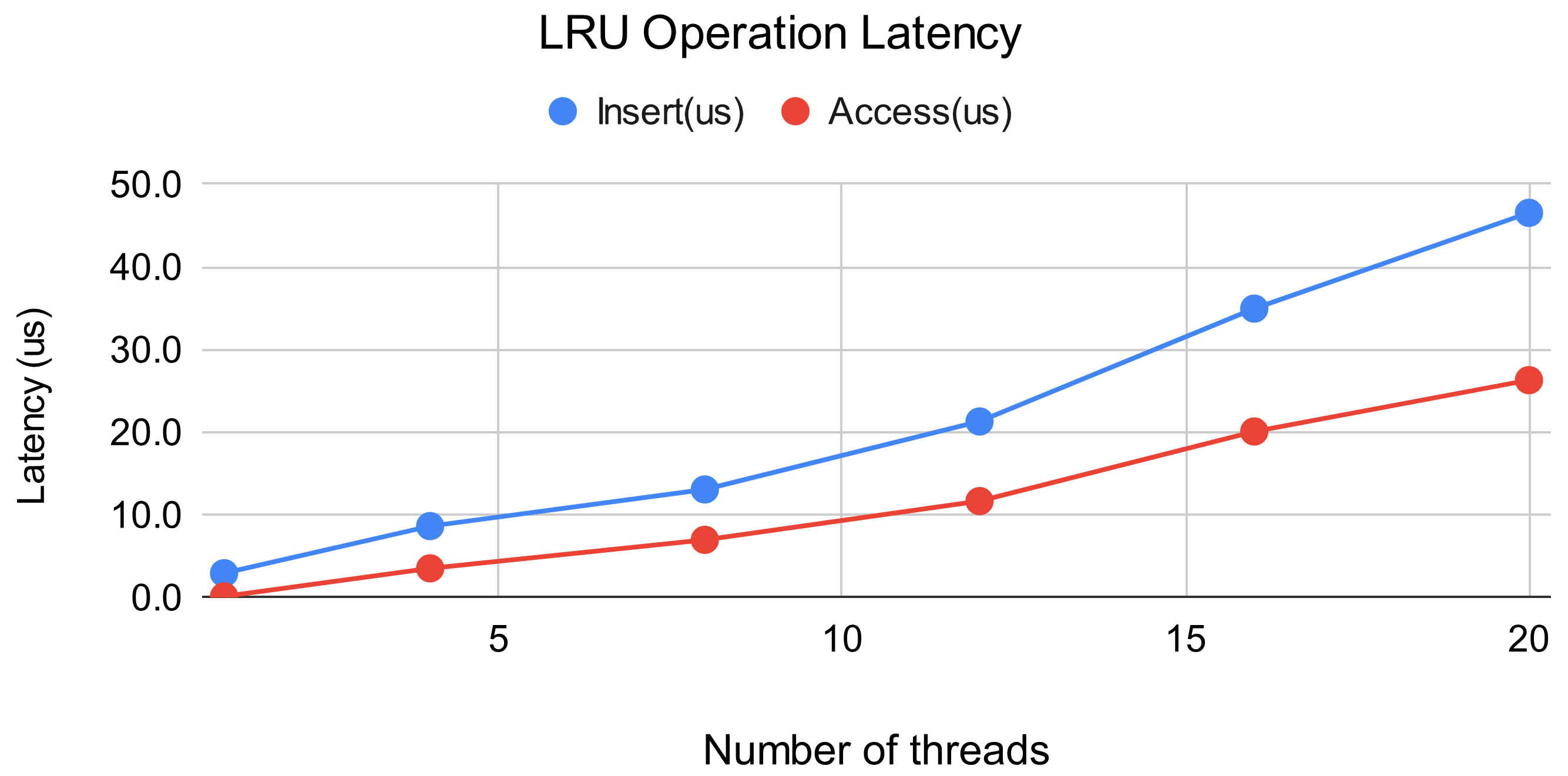
結果より、並列数が増加するにつれてほぼ比例して Insert, Access ともに遅延が増加していることがわかります。並列数の増加に比して PUT, GET の性能にも影響が出ることが考えられますが、PUT, GET 全体のレイテンシが数msである一方、LRU におけるレイテンシは数十us であることから、全体への影響は無視できるものと考えられます。
実ワークロードでの比較: PFIO を用いた深層学習
PFIO は PFN が開発しているI/Oの抽象化ライブラリです。PFIO は Zip で圧縮されたデータセットを取り扱えるだけでなく、ローカルのストレージや HTTP 経由 のAPI (つまり、分散キャッシュシステム)でデータセットをキャッシュする機能を提供しています。今回は、PFIO を用いてデータセット ImageNet-1K に含まれる訓練用の画像データ約128万枚をロードするために要する時間を比較しました。なお、データセット全体は Zip ファイルとして保持され、1枚あたりの画像サイズは約 120 KiB となっています。
データセットのオリジンは NVMe SSD で構成された NFS サーバーに配置し、それぞれ SCS を用いたキャッシュの有無に応じて 1 iteration に要した時間を比較しました。データセットの読み込みには PyTorch DataLoader を用いて Dataset を実装し、読み込みワーカー数 4、バッチサイズ 32 で比較しました。なお、モデルの訓練自体は行わず、データの読み出しのみを行った時の所要時間を比較しています。
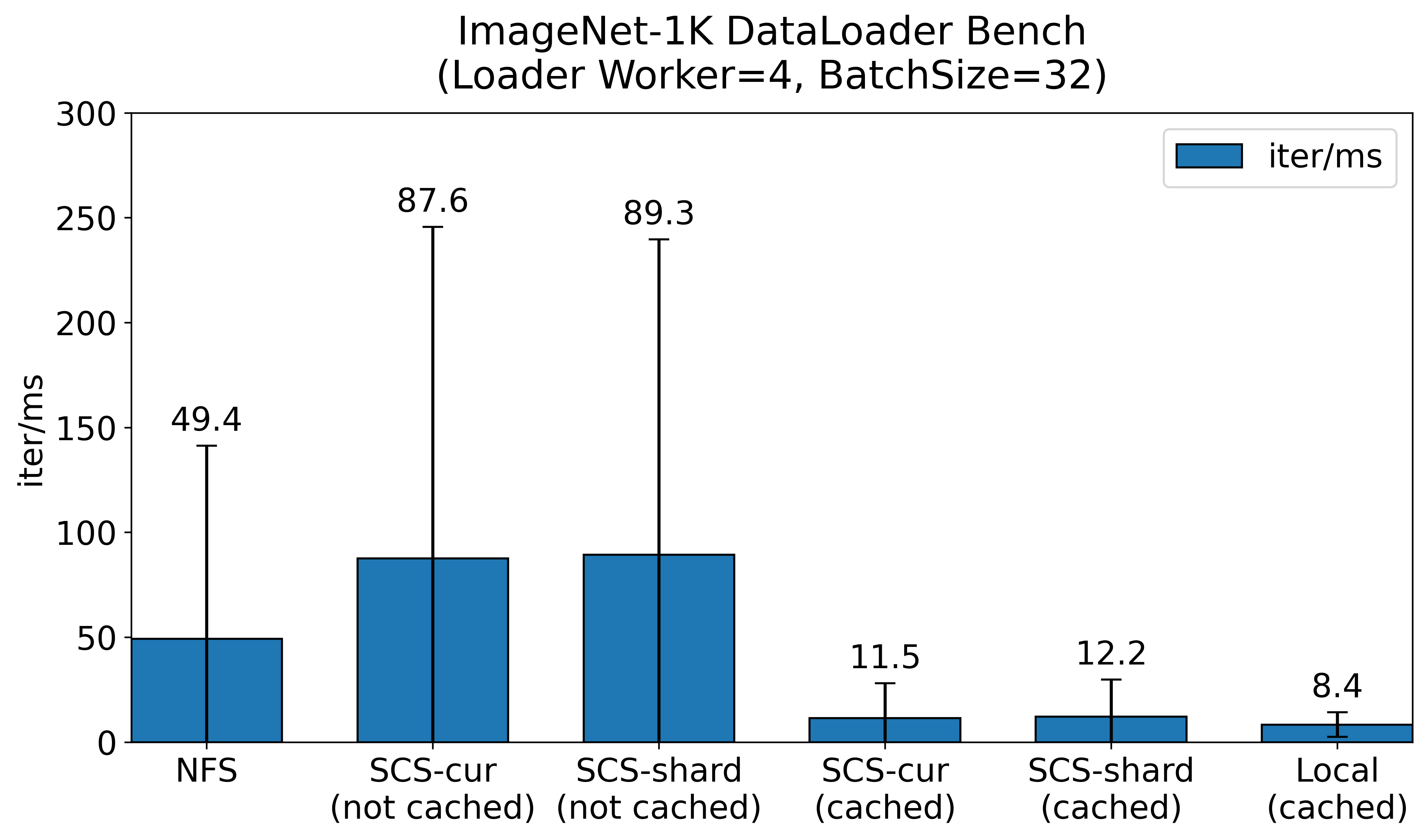
NFS サーバー単体では平均で 50ms 近く要し、ベンチマーク中 NFS サーバーは 1GiB/s 前後のトラフィックが流れていました。
SCS を用いた場合では、キャッシュされていない場合、90ms とおよそ2倍近い時間を要していることが分かります。これは、SCS に対する GET のレスポンスが 404 Not Found となると、 NFS サーバーから対応するデータを取得し、その後 SCS に対して PUT をするため、NFS よりも時間が多くかかる結果となりました。データセットの1エポックを回し全てを SCS にキャッシュし終えた後、SCS のキャッシュにヒットした場合は約 12 ms と NFS サーバー比で 4 倍程度高速にデータを取得できていることが分かります。ResNet-50 で 32 画像を NVIDIA V100 で訓練する場合で数十msかかります。I/O と計算のoverlapを考えると、I/Oが数十msを超えるとI/Oによる GPU の待ちが発生します。SCS でキャッシュに当たった場合は、このような待ちが発生することはなくなります。
以上の結果より、最も理想的な場合はローカルにキャッシュが存在する場合ですが、分散学習や学習用の Pod を再スケジュールされてノードが変わった場合等、ローカルのキャッシュを活用できない場合は多々あります。SCS を用いることで、ローカルのキャッシュと比べても大きな性能劣化なしにクラスタ全体で共有されたキャッシュを活用でき、データロードの高速化やデータセットを保持するNFS サーバーやオブジェクトストレージ等のストレージへの負担を軽減することができます。SCS は前述したとおり単一のボトルネックを持たないアーキテクチャであるため、大規模な分散学習においても高い性能をもたらすことが期待されます。
改良前後では、大きな改善は見られませんでした。逆にわずかながらではありますが性能が落ちる結果となった点については、今回用いた計測環境は共用の環境であるためその影響によりベンチマークに誤差が生じている可能性もあります。また、今回の改善は SCS への PUT の高速化に寄与するものであり、キャッシュヒットしなかった場合のレイテンシには、SCSへのPUTと、NFS からの読み込み時間を含んでいるため、改善がベンチマーク結果に現れづらいことにも注意する必要があります。実際のワークロードが動く環境で改良後の SCS Node を展開し、その効果を測定することは今後の課題とします。
まとめ
深層学習におけるデータセット読み込みやコンテナイメージ配布を高速化を高速化する仕組みとして、PFN では Simple Cache Service (SCS) を提供しています。SCS の性能は深層学習等の種々のデータを取り扱う処理の性能に大きな影響を持つため、できる限り短いレイテンシで大量のリクエストをさばくことが求められます。今回の記事では、性能改良の取り組みとして SCS を構成するノードにおけるシャーディングの事例を取り上げ、PUT 性能が大きく改善したことを紹介しました。また、SCS の具体的なユースケースとして、PFIO を用いた例と改良が与えた性能への影響についても紹介しました。今後も深層学習ワークロードやクラスタ内の各種サービスを高速化するキャッシュサービスである SCS の改良に引き続き取り組んでいきます。
Area
