Blog
本記事は、2021年度PFN夏季インターンシップで勤務された渡辺貴史さんによる寄稿です。
こんにちは、2021年インターンシップとして参加させて頂きました、東京大学大学院修士1年の渡辺貴史です。大学院では、身体拡張分野の研究に取り組んでいます。
今回のPFNインターンでは、マイコン環境で機械学習モデルを動作させるという課題に取り組みました。具体的には、学習済み機械学習モデルを渡すとコンパイルやバリデーションまでをコマンド1つで行ってくれるという機能を社内ツールであるPFVMに追加しました。
背景
PFNでは、PFVMを活用し機械学習モデルを様々なデバイスで動作させています。PFVMは、モデルをデバイスで実行可能な形にし、さらに実行時の性能が向上するように最適化を行います。
様々なデバイスへの適用例として、PFNのブログでも事例がいくつか紹介されています。
本テーマでは、これまでPFVMが実行環境として扱っていなかったマイクロコントローラ(マイコン)への対応を行いました。マイコンのような、安価である代わりに計算リソースが限られたデバイスにおいても、十分な速度と精度で機械学習モデルを動作させることができれば、エッジデバイスの選択肢が大きく広がります。マイコンでは既存のフレームワークやライブラリが充実しておらず、特にPyTorchで学習したモデルをマイコンで動作させるためのフローは確立されていません。様々な動作実績を持つPFVMの枠組みに則ってこれを実現することにより、社内の多くの人がマイコン固有のノウハウを持たずとも他デバイス同様に開発を進めることができるようになります。
今回はONNXをサポートしたツールが公開されているSTMicroelectronics社のマイコンを対象として開発を行いました。
実装

上図はONNXの入力から実行までの全体の流れです。① ONNXモデルの変形、② コード生成とコンパイル、③ マイコンへの書き込み及び実行と続きます。これらを全て1つのコマンドにまとめ、ONNXモデルを引数として実行まで通して行うソフトウェアを開発しました。
PFVMでは従来、推論の高速化のため冗長な表現を置換する処理と、使用するオペレータやそのオプションを実行環境に合わせて調整する処理を行っていました。まずこれらの処理をマイコンに合わせて調整しました。また、コードサイズやメモリ使用量を削減するための8bit量子化を行う処理を追加しました。
ツールへの適合
STMマイコンで機械学習モデルの推論を行うためのツールとして、 STMicroelectronics社が公開するX-CUBE-AIを用いました。このツールはONNXを入力としてC言語のコードを生成してくれる非常に便利なツールです。しかし、すべてのONNXモデルに対応しているわけではなく、細かい仕様などを把握し、問題を回避するようにモデルを修正する必要があります。ベンダーツール特有の問題としてエラーの詳細を得にくいことなどがあり、仕様の把握には時間がかかりましたが、発見した問題についてはPFVMを用いて自動で修正できるようにしました。
8bit 量子化
メモリやコードサイズの制約が極めて厳しいマイコン環境において、量子化は有効な手段です。多くの機械学習モデルは32bitや64bitの浮動小数点数で表現されており、これを8bitに圧縮して格納・演算を行うことによって、使用するメモリ領域を大幅に削減することが可能です。今回はX-CUBE-AIに合わせて、Convolutionの重みをsymmetric int8、入力をasymmetric int8とする静的量子化を行いました。
結果
コマンド一つでONNXモデルをマイコン上で実行しバリデーションするまでの一連の流れを自動で行うツールを開発することができました。USBでマイコンを接続しておけば、GPUなどの環境と同じインタフェースで実行時間などの計測を行うことができます。
開発したツールを用いて、実際のマイコン上での動作検証を行いました。検証には、Nucleo STM32H7A3ZI-Q (RAM 1.18MB, Flash 2MB, 280MHz)を用いました。
MNIST
基本的なタスクとして、手書き文字認識クラス分類問題であるMNISTを分類するための3層の全結合層からなるニューラルネットワークモデルを動かしました。

実行時間は1枚あたり10.8 ms で、100枚のテストケースに対する正解数は87枚でした。エラー率は13%の計算になります。元のモデルがエラー率1.1%なので、大幅な精度低下については今後の課題です。
Freespace Segmentation
次に、要求リソースの大きいモデルとして、画像中から障害物のない床の領域を割り出すFreespace Segmentationを動かしました。量子化後のRAM使用量が980 KiB、Flash使用量が311.40 KiB になっています。動作しているモデルは、PFNの持つ技術であるOptuNASを用いて探索されたモデルになります。(詳しくはこちらをご覧ください。)
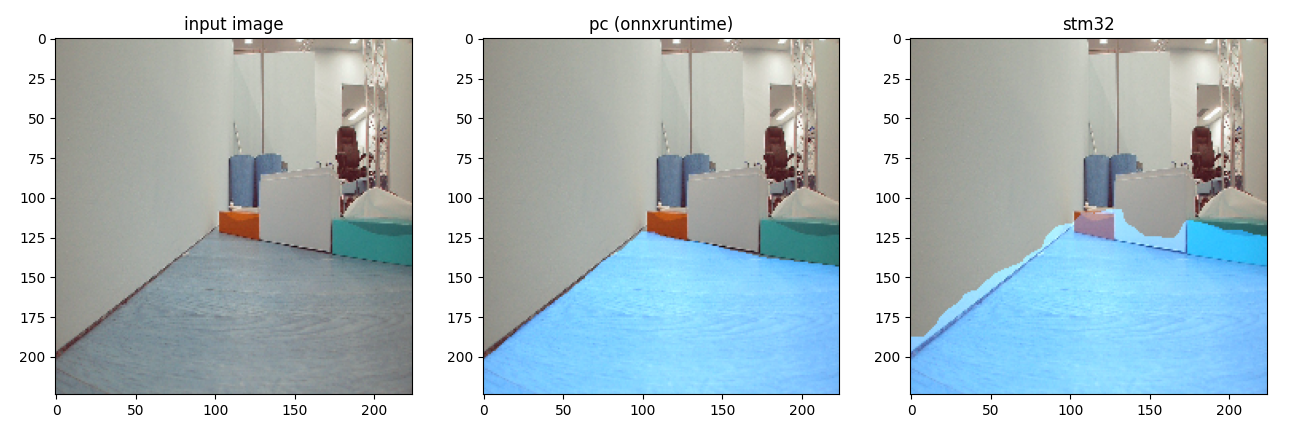
上に示す図は左から、入力画像、元のモデルのPCでの出力、量子化済みモデルのマイコンでの出力となっています。実行時間はPCのCPU実行(i7-1165G7 @ 2.80GHz, 並列なし)で12 ms で、マイコンでは2214 ms となりました。
コマンドとして一連の動作をまとめたことにより、NAS(Neural-network Architecture Search)によって探索されたモデルをスムーズに実行できるようになりました。この他にも、PFVMと連携してバリデーションなどを行う各種のツールをマイコン向けに適用できるようになりました。
今後の課題
今回動かしたMNISTやFreespace以外のモデルの中には、X-CUBE-AIが対応していないオペレータを含むものも存在します。PFVMでは通常、ツールがサポートしている部分グラフをツールに任せ、それ以外は自前のランタイムで実行しますが、マイコン環境では既存のランタイムが使えず、あらたに実装する必要があります。
また、現在はONNXモデルの変形のみでツールの制約に合致するようにモデルの調整を行っていますが、モデル設計あるいはNASなどのモデル探索の時点で制約を考慮するといったことも考えています。
まとめ
興味のあった機械学習という分野と、自分の持つマイコンの知識を掛け合わせた、大変面白いテーマでした。根気のいる作業もありましたが、非常に良い経験になりました。
