Blog
本稿は、自動車技術会誌「自動車技術」Vol.75 No.4(2021年4月1日発行)への著者の寄稿を、自動車技術会の許諾を得て転載したものです。
1. Software 2.0
深層学習が目覚ましい発展を遂げて、画像認識や音声認識などの人工知能の分野で新しい応用分野を切り開いている。一方で、人工知能というよりも、新しいプログラミングパラダイムとして深層学習に注目している人たちがいる。テスラ社の人工知能およびオートパイロット部門のディレクタであるAndrej Karpathy は、2017 年11 月に書いたブログの中で、「ニューラルネットワークは新しい識別器というだけではない。われわれがソフトウェアを開発するためのまったく新しい方法なのだ」と述べている(1)。これを彼はSoftware 2.0と呼んでいる。
1940 年代にストアードプログラム方式の電子計算機が発明されて以来、ソフトウェアとは「与えられた仕様を満たす実行可能な命令ステップ列を人間が書き下す」ことによって開発されてきた。初期には機械命令を直接書くことによって、FORTRAN やCOBOL などの高級言語が発明されてからは、それらの抽象的な実行文をコンパイラによって機械語に翻訳することによって、さらにはオブジェクト指向やさまざまなライブラリ、フレームワークによって、と抽象度は上がってきたが、「機械が実行可能な命令ステップ列を人間が書き下す」というプログラミングのスタイルは、基本的にはずっと変わっていない。
それを、深層学習が根本から変えようとしている。深層学習は、与えられた入出力事例集合(訓練データセット)を模倣するような深層ニューラルネットワーク(DNN)を、ほぼ自動的に構成する(このプロセスを訓練と呼ぶ)。このように、仕様を入出力の事例で与え、それを満たすプログラムを自動的に導くようなプログラミングを帰納的プログラミングと呼ぶ。帰納的プログラミングは、工数のかかるコーディングを自動化する試みとして、過去にも何度か試みられてきた。例えば、ソフトウェア工学の分野で最近注目を浴びている自動プログラムリペアは、あるテストケースに失敗する(バグのある)プログラムに対して、そのプログラムの一部を変更することで、テストに通るプログラムを探索する手法である。しかし、あるテストケースに対して、プログラムのどこを変更すればよいのかを見極めるのが難しく、やみくもな探索を行うとその効率が悪いのが問題だった。 深層学習における訓練においては、ある入出力事例に対して、DNN の振る舞いが期待と異なると、確率的勾配法という手法を用いて、どのパラメータをどの方向にどの程度調節すればより誤差の小さな出力が得られるか、を計算することができる。パラメータ数が極めて多い(数百万から数億のパラメータは珍しくない)ので、それなりに時間はかかるが、やみくもな探索を行うよりははるかに効率的である。
一方で、深層学習はパラメータ数が多いので、さまざまな多次元非線形関数を近似することができる。大規模なデータの蓄積と計算機の性能向上が深層学習を可能にし、それによって、帰納的プログラミングが歴史上初めて、実用的にも使えるプログラミングスタイルとして浮かび上がってきた。人間のプログラムが計算ステップを書き下すのではなく、機械が膨大な空間から仕様を満たすプログラムを探してくる、それがSoftware 2.0と呼ばれるものの正体だ。
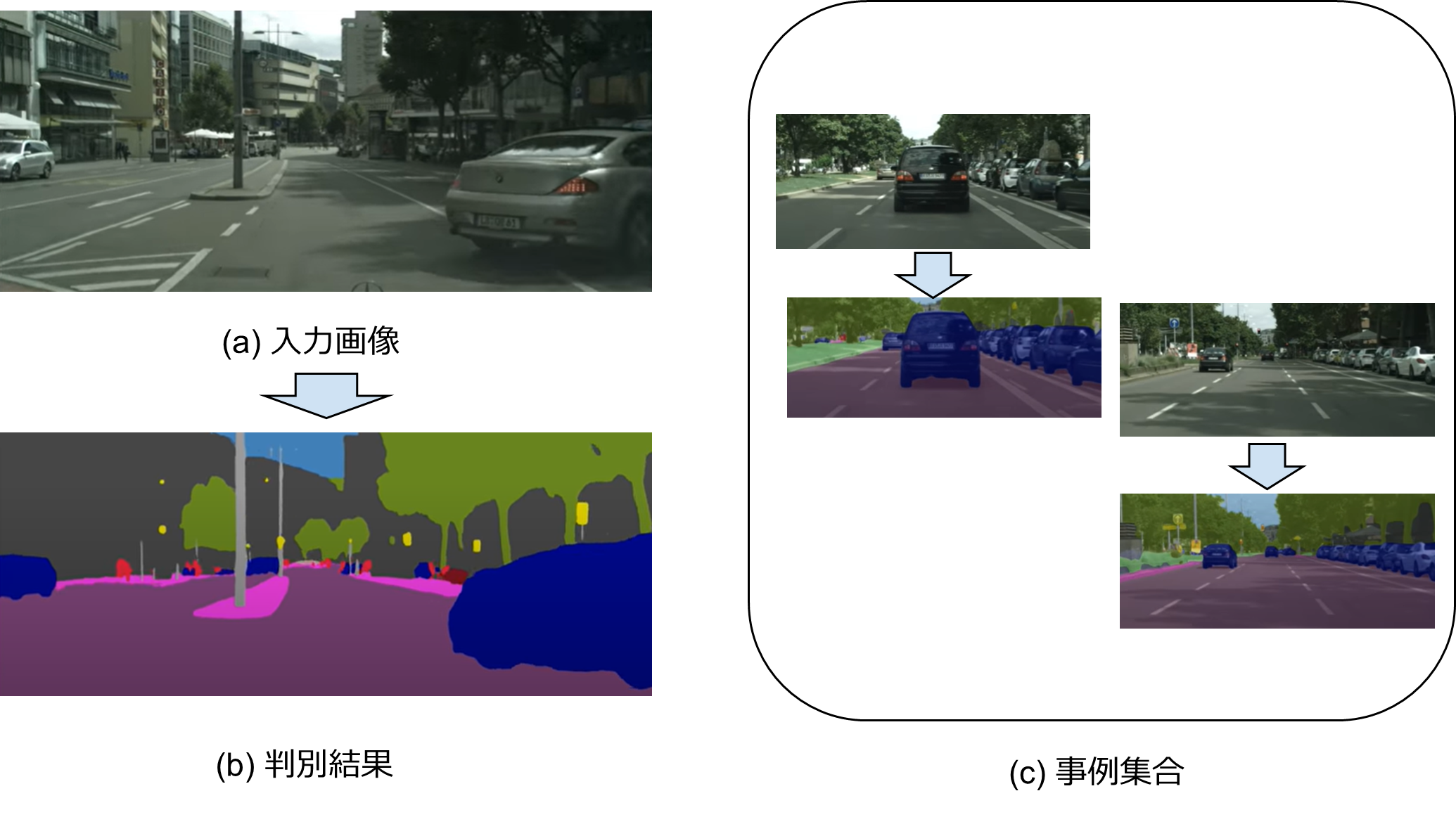
教師あり学習の例(自動運転の画像認識)。(a)入力画像。(b)判別結果。紫は車道面、ピンクは歩道など、各画素ごとに判別している。(c)訓練に使われた事例集合。教師信号としては、人手で各画素の正解ラベルを塗りつぶして作成したもの。出典:CityScape データセット
入出力の事例から、それを模倣する関数を導くことを、機械学習の分野の言葉では「教師あり学習」と呼ぶ。例えば、図1 は自動運転のための画像認識を深層学習で行う例を示している。(a)という入力画像に対して、(b)に示すように各ピクセルの認識結果を路面(紫)、歩道(ピンク)、他車(青)などのように判別する。この関数を導くための事例集合(c)は、実際の走行で得られた画像データに対して、人手で正解を与える(アノテーションと呼ぶ)ことで作成したものである。
図1 の画像認識ソフトウェアを、今までのSoftware 1.0の手法で開発するとしたら、どのようになるだろうか。そこには、仕様をどのように定義するか、という問題がある。Software 1.0では、プログラムの仕様を厳密に与える必要がある。上記の画像認識の場合「ある画素が車道面であるのは、入力画像がどのような条件の場合か」を厳密に指定しなければならない。そうでなければ、ある入力に対して出力が得られたとき、それが「正しい出力であるか」を判定できないためだ。
統計学の立場からいえば、深層学習は、扱うパラメータの数が何桁も違うが、考え方としては統計的モデリングと呼ばれるもの、すなわち入出力の統計的な関係を求めることに等しい。統計的モデリングにおいては、入出力事例に確率的なばらつきがあることを前提とする。このため、得られた関数(統計の言葉でいえばモデル)が事例のすべてを正確に再現することは求めない。その代わり、事例とモデルとの統計的な誤差量(例えば平均2乗誤差)を最小化することを求める。
このように深層学習に基づくSoftware 2.0では、
- 仕様を事例の形で与える。このため、厳密な仕様が書きにくいソフトウェア(画像認識など)の開発も可能となる。
- 与えられた事例集合によって、できあがったソフトウェアに確率的なゆらぎがあり、出力は常にある誤差を含んだものになる。「100%正しい結果が得られる」ようなソフトウェアは原理的に作れない。
という特徴があり、今までのソフトウェア開発の考え方を大きく変える必要がある。
本稿では、Software 2.0における課題として、品質・説明可能性・要求開発の3 点を取り上げて解説し、Software 2.0普及への工学的取組みとして、日本ソフトウェア科学会機械学習工学研究会の活動を紹介する。
2. 品質
2.1 Software 2.0の品質の評価
ソフトウェアの品質特性として最も重要なものは、仕様通りに正しく実装されているか、という機能性である。それ以外にも、信頼性、効率性、保守容易性、セキュリティなどの品質特性もあるが、ここではまず機能性に絞って議論しよう。通常のソフトウェアにおける機能性とは、仕様からの逸脱がないことである。逸脱が一つでもあれば、それはバグのあるソフトウェアであり、機能性を満たさない。すなわち、Software 1.0 における最もシンプルな意味での機能性とは、真か偽の2 値で現される。
一方、Software 2.0 においては、厳密な仕様の代わりに、訓練データが与えられる。訓練データは通常、入力空間のすべてを覆いつくすことはできないので不完全(ある入力に対する正しい出力の値を決めることができないことがある)であり、かつ確率的なばらつきを考慮するので矛盾した事例(同じ入力に対して異なる出力の事例がある)も含む。このため、Software 2.0 において機能性を評価するためには、あらかじめ用意された評価用の入出力事例集合(ここでは評価データセットと呼ぶ)に対して、それらの事例の出力の平均2乗誤差などを用いる(2)。
Software 2.0 の開発においては、評価データセットと訓練データセットを明確に区別し、評価データセットは開発者に見えないようにしておくことが極めて重要である。開発者が評価データセットを見てしまえば、開発者にはそれに合わせてシステムをチューニングしたい、というインセンティブが働き、それを開発者が意識しているかいないかにかかわらず、評価データセットに過適合したシステムになりやすい。評価データセットを開発者から見えないようにするためには、開発者とは独立な第三者機関が評価を行う、あるいは評価を自動化する、などの方策が考えられる。
なお、訓練データセットと評価データセットは、同じデータソースから無作為抽出するのが基本だが、必ずしもそれが良いとは限らない。例えば、予測モデルにおいては、予測時点での未来の情報が訓練データセットに紛れ込むことを防ぐため、ある時点より前のデータで訓練し、その時点以降のデータで評価する、ということがよく行われる。また、安全性に関わるなど重要な事例を、評価セットに重点的に配置する、ということも行われる。
2.2 品質のモニタリング
Software 2.0 では、訓練データセットを模倣する振る舞いをするので、訓練データセットに現れるデータ点に近い入力に対しては良い近似をする(これを内挿と呼ぶ)が、訓練データセットにまったく現れない、稀な入力に対しては出力がばらつく(これを外挿と呼ぶ)。このため、実行時に入力の確率分布が変化すると、精度が落ちてくる。これをコンセプト・ドリフトと呼ぶ。商品の売上予測のような応用例では、季節要因や消費者の好みの変化、新製品の投入などにより、コンセプト・ドリフトが激しく、数カ月ごとに再訓練を行うことが多い。工場における機械の故障予測など、比較的安定した応用領域でも、さまざまな要因によりコンセプト・ドリフトが起きるので、今使われているモデルが期待通りの品質(精度)を保っているか、常にモニタリングをしておくことが必要である。
2.3 Software 1.0 とSoftware 2.0 の混合
Software 2.0 では、 機能性を「評価データセットからのサンプルに対して出力の誤差がε以下」のような形で与えるが、安全性に関わるシステムなどにおいては、「確率は低くても絶対に出てほしくない出力」がある場合がある。そのような場合、システム全体を厳密な仕様に基づくSoftware 1.0 モジュールと、事例に基づくSoftware 2.0 モジュールとの組み合わせで構成する必要がある。
このようなハイブリッドな構成としては、①Software 1.0 モジュールが入力を監視していて、訓練データセットの分布から逸脱した入力が来た場合には、Software 1.0 による計算にフォールバックする、② Software 2.0 モジュールの出力をSoftware 1.0 モジュールが監視していて、厳密な仕様を逸脱している場合には介入する、などのパターンがある。 より高度な組み合わせ例としては、 碁で世界チャンピオンを破ったAlphaGo がある。AlphaGo は深層学習を使ってはいるが、碁のルールに従わない手は打たない。それはAlphaGoがSoftware 1.0 による木探索アルゴリズムを根幹に据えているからである。深層学習は、木探索のどの枝を先に探索するか、というガイドに使っているのみである。このように機能性(厳密な仕様)はSoftware 1.0 で、非機能性(性能など)はSoftware 2.0 で行う、というハイブリッドなソフトウェアが今後増えていくだろう。
2.4 Software 2.0 の品質ガイドライン
Software 2.0 の品質をどのように担保するか、のためのガイドライン策定の動きが加速している。国内では、AI プロダクト品質保証コンソーシアムが「AI プロダクト品質保証ガイドライン」を公開している(3)。また、産業技術総合研究所が「機械学習品質マネジメントガイドライン」(4)を策定し、それに基づいて経済産業省が「プラント保安分野AI 信頼性評価ガイドライン」(5)を公開するなど、分野ごとの品質ガイドライン策定の動きも活発化している。
3. 説明可能性
深層学習はブラックボックスなので、説明可能性に問題がある、という議論をよく聞く。ここでは、説明を事象の説明(ある入力に対してその出力が得られたときに、それはなぜか)、性質の説明(このシステムは一般にどのような性質をもつか)、意思決定の説明(誰がどのような理由でシステムの企画・開発・運用におけるそれぞれの意思決定を行ったか)に分けて考える。
3.1 事象の説明
事象の説明とは、システムからある出力が出てきたときに、それがなぜか、を問うものであり、局所的な説明・処理の説明と呼ばれることもある。前出の画像認識システムに対してある入力画像を与えたとき、ある画素が道路面であると出力されたとする。これはなぜだろうか。その画素を道路面と判断した根拠を説明できるだろうか。
現在のDNN は、デジタル計算機の上に実装されているので、使った訓練データセット、ハイパーパラメータ、乱数初期値、入力画像を与えれば、まったく同じ結果を返すはずであり、その過程はコンピュータのビット操作の単位まで落とし込めば、完全に追うことが原理的には可能である。これは確かにその出力が得られた完全な論理的因果関係を示したものであるが、これを生身の人間が見てもまったく理解できないだろう。これでわかるのは、「説明」とは、説明を受ける側の認知能力に応じた、相対的な概念であるということだ。
Gilpin らによれば、事象の説明は解釈可能性と完全性という二つの相反する要求を満たさなければならない(6)。深層学習、特に画像認識の領域において、完全ではないがより解釈可能性のある説明の手法がいくつか提案されている。一つは、入力画像のどの画素が、結果により大きな影響を与えていたかを分析することによって、説明を行うものだ。図2 は、画像認識においてシベリアンハスキー犬をオオカミと誤認識されたのは、背景に映った雪が大きな影響を与えた、という解釈に結びつく説明方法である。もう一つは、予測の根拠となった訓練データは何か、を示すもので、そのために、訓練データセットから個別のデータを除いたモデルを作り、予測がどの程度変化するかを調べるものである。これらはいずれも、機械的に生成された表現を人間が解釈することによって説明を助けるものであるが、当該の出力が得られた要因は他にも無数にあり、完全な説明とはいえないことがわかるだろう。

図2 判別結果が入力画素のどの部分に注目して得られたかを表示することで事象の説明を行う例。(a) 入力画像。シベリアンハスキー犬だが、間違えてオオカミと判別された。(b) 判別に重要な影響を与えた画素。このことから、背景に雪が写っていたことが、オオカミと混同されたと考えられる。出典: Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. “”Why should I trust you?” Explaining the predictions of any classifier.” Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining (2016)
3.2 性質の説明
性質の説明は、入力にかかわらずシステムがもつ性質(ソフトウェア工学では不変量とも呼ばれる)の説明であり、大域的な説明あるいは表現の説明とも呼ばれる。
性質の説明の一つのやり方は、できあがったDNN がさまざまな入力に対してどのように反応するかを観察することによって説明を行う方法であり、典型的には2 章で議論した評価用セットによる品質評価がこれにあたる。あるいは、画像認識DNN において、ネコの画像によく反応するニューロンがある場合に、これはネコを認識する能力をもつDNN である、という解釈を行う。
性質の説明のもう一つのやり方は、システムがどのようなプロセスで設計されたかを示すことによって、そのシステムの性質を明らかにしようとするものである。前出の自動運転用画像認識DNN は、ドイツの市街地における訓練データセットを用いて訓練したものであった。このため、ドイツの市街地において良い精度をもつモデルであることが推量できる。あるいは、Software 1.0と2.0 の両方をもつシステムのレベルでは、例えばAlphaGo の場合「システムの設計上、許されない手を打つことはない」という性質を説明することができる。
3.3 意思決定の説明
事故が起きた場合、事象の説明はその事故の因果チェーンを示すことができるが、その事故の責任を誰が負うべきか、というアカウンタビリティを説明することはできない。アカウンタビリティは「説明責任」と訳されることが多いが、これは「説明をする義務」ではなく、「結果に対して責めを負うべき義務」のことである。意思決定の説明とは、アカウンタビリティを明らかにするため、システムの企画・設計・運用に関わる意思決定に関して、① 誰が、② 何を意図して、③ 何を予見して、その意思決定を行ったかを明らかにすることである。
何らかの有用性をもつシステムが100%安全であるということはあり得ない。有用性をもつということはわれわれの社会に何らかの影響をもつということであり、それは常に正の影響と負の影響をもつ。自動車は効率的に人や貨物を運ぶという有用性をもつが、同時に事故を引き起こす。システムを企画・設計・運用する際のさまざまな意思決定は、多かれ少なかれ、有用性と悪影響とのトレードオフに関する意思決定であるといえる。その際、どのような悪影響を予見していたか、それと有用性とのトレードオフをどの点に設定したか、を明らかにしておくことが意思決定の説明のために必要である。近年、Software 1.0 の開発においてはGitHub などのリポジトリを使うことが多いが、変更に際して必ずその意図を記録する、というプラクティスが普及しつつある。同様の仕組みが、Software 2.0 の開発においても必要であろう。
4 要件と仕様
ソフトウェアに限らずすべての人工物(システム)には、それが満たしてほしいと思う期待値(要件)があり、またその期待値を満たすために定義する振る舞い、がシステムの具体的な仕様である。Software 2.0 では仕様は事例集合の形で与えられ、それ以降は訓練によってほぼ自動的にシステムが作られる。したがって、仕様(事例集合)が要件を正しく反映していることが極めて重要である。 図3 は模型自動車を使った自動運転の例である。この模型自動車は、深層強化学習によって訓練されている。そこで使われる事例は、シミュレータ上での模擬運転によって生成されていて、指定された方向に進めば報酬を受け取り、衝突するとペナルティを受け取る。

図3 深層強化学習による、模型自動車の自動運転の例。銀色の車は深層強化学習を用いて、訓練されたもの。 出典: Preferred Networks
このシステムで、完全な安全性を求めて衝突時のペナルティを無限大に設定すると、動かない車になってしまう。別の仮想的な例では、知的なロボットに対して「コーヒーをもってきて」と命令すると、ロボットは階下の珈琲店へ行き、並んでいる客を撃ち殺してコーヒーをもってくる(7)。これらはどちらも、要件(期待値)を曖昧にしたために、期待と異なる振る舞いをするシステムができてしまった例である。自動運転の場合、車が動くという効用と安全性のバランスを明示的に指定する必要がある。ロボットの場合、「人を傷つけてはならない」という、人にとっては当たり前の常識を、明示的に教える必要がある。
このように、顧客あるいは社会の期待値と、実際のシステムの振る舞いのずれを、アラインメント問題(8)と呼ぶことがある。Software 1.0 では、プログラマが暗黙の常識を知っていて、常識に反する振る舞いをしないようにコーディングしていたため、この問題があまり注目を浴びることはなかった。Software 2.0 では、仕様から実装までを機械が探索によって自動的に行うため、仕様が要件(期待値)を正しく反映していないと、期待に反するシステムができてしまう危険がある。
アラインメント問題が特に大きな注目を浴びている領域に、公平性や差別の問題がある。2015年7 月、Google Photos の新しいタグ付け機能で、黒人カップルが写っている写真に「ゴリラ」というタグ付けがされたと報道され(9)、大きな話題になった。Software 2.0 ではこのようなアラインメント問題があるため、Software 2.0 の研究者・開発者は常に社会の価値観に目を配らなければならない。このため、Software 2.0 に関わる倫理的指針についての議論が盛んである。例えば、内閣府は2018 年12 月に「人間中心のAI 社会原則」を発表した。そこでは、人間の尊厳、多様性・包摂性、持続可能性という三つの価値を尊重すべき、としている。
5. 機械学習工学
Software 2.0 には大きな可能性があるとともに、品質・説明可能性・要件と仕様のずれなど、今までのソフトウェアにはない課題があることを述べてきた。機械学習分野での権威の一人であるカルフォルニア大学バークレイ校のMichael Jordan教授は、2019 年4 月のブログで、建設の世界で土木工学があるように、機械学習の分野でも工学的ディシプリンが必要だ、と述べている(10)。われわれは普段、車を運転している際に、橋が落ちたりトンネルが崩壊したり、ということを心配することはないだろう。それは、橋やトンネルの構築の裏には、土木工学という膨大な知識体系があり、それを信頼しているからである。しかし、土木工学は安全性を100%保証するものではない。確かに、材料理論、構造理論、荷重理論などの理論はあるが、それらが実際の橋やトンネルの安全性を100%保証するものではない。土木工学には安全性係数というものがあり、それは理論で計り知れない部分を、「ここまでマージンを見込めば社会的に受容されるだろう」という経験則を定量化したものである。
ソフトウェアについても同様な議論が成立する。伝統的なSoftware 1.0 において、1960 年代に始まったソフトウェア工学は、FORTRAN のような高級言語、モデル駆動開発のような方法論、要求工学のようなノウハウを確立することによって、常にある程度のバグがあるにもかかわらず、ソフトウェアが社会的に認められることに貢献してきた。Software 2.0 に対しても、同様に工学が必要であることは論をまたない。日本ソフトウェア科学会では、Software 2.0 の工学的ディシプリンを体系化することを目的に、2019 年に「機械学習工学研究会」を立ち上げた。同年5 月のキックオフシンポジウムでは500 名を超える参加者があり、その後毎年の夏合宿、2 回の国際会議主催など、活発に活動を続けている。
新しい技術が社会に受容されるには、工学的熟成が必要であると考える。新しいソフトウェアの作り方であるSoftware 2.0 の工学的な知識体系が整備され、またその可能性と限界が社会によく理解され、役立っていくことを望んでやまない。
参考文献
(1) Andrej Karpathy: Software 2.0
(2) 回帰モデルの場合。判別モデルの場合には,混同行列やそれをスカラ化した数値(F 値など)が用いられる。
(3) AIプロダクト品質保証ガイドライン 2020.08版 AIプロダクト品質保証コンソーシアム(QA4AIコンソーシアム)編
(4) 産総研: 機械学習品質マネジメントガイドラインを公開 (2020/06/30)
(5) 『プラント保安分野 AI 信頼性評価ガイドライン』 石油コンビナート等災害防止3省連絡会議
(6) L. H. Gilpin, et al.: Explaining Explanations: An Overview of Interpretability of Machine Learning, 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), IEEE, 2018, p. 80─ 89
(7) この例は、2017 年の人工知能国際会議の招待講演で、Stuart Russellが使ったものである。
(8) Brian Christian: The Alignment Problem: Machine Learning and Human Values (2020)
(9) グーグル、黒人を誤って「ゴリラ」とタグ アルゴリズムの限界か – WSJ
(10) Michael Jordan: Artificial Intelligence — The Revolution Hasn’t Happened Yet