Blog
Introduction
2019年にChainerとChainerRLの開発が停止された後、ChainerRLの後継としてPFRL開発が継続されています。PFN社内ではPFRLに対する分散強化学習の研究もすすめております。このブログでは、実アプリケーションを通して、PFNにおける分散強化学習への取り組みを紹介します。
分散深層学習がなぜ必要か
強化学習(Reinforcement Learning,RL)は、教師あり学習、教師なし学習と並んで、機械学習の3大ジャンルの一つとして知られています。強化学習では、エージェント(またはアクターと呼ばれます)が環境(Environment)を探索して、経験(exprience)を集め、それを使ってモデルを学習し、学習したモデルを使ってまた新たな経験を集めることを繰り返します。教師あり学習と違い、強化学習は明示的なラベルを持つデータセットを必要とせず、動的に探索空間を探索することによって、学習しながら並行してデータセットを生成すると言えます。
機械学習を使って難しいタスクに取り組むとき、1つの有効な方法として、学習を高速化するために計算資源をスケールアウトさせるというものがあります。強化学習の性質上、学習のための計算資源をスケールアウトさせるには2つの方法が考えられます。
1つは、モデルの訓練部分をスケールアウトして、並列化することによって高速化する方法です。大量の経験を長時間にわたって訓練しなければいけないときに有効です。これは、他のタスク(画像分類の教師あり学習など)と同じです。
2つ目は、環境の探索をスケールアウトさせることです。強化学習は、複雑な現実環境でのタスクによく使われ、その1つの例はロボットハンドの操作です [6]。このようなタスクでは、環境は物理ベースのシミュレーターとなり、計算が重くシミュレーションに時間がかかることが多くあります。この場合、仮にモデルの訓練部分を複数のGPUを用いて高速化させたとしても、経験の生成がモデル訓練に追いつかず、そこがボトルネックになり、GPUがアイドル状態になって、全体の高速化につながりません。多くの場合GPUは計算機の中でも最も高価なパーツですから、そのような計算資源の無駄遣いは避ける必要があります。また、このようなシミュレーターはCPUでしか動かないことがほとんどですから、計算に用いるCPUを増やす必要があります。最終的に、訓練用のGPUと環境用のCPUの両方を最大限に有効活用できるバランスを見つけて調整する必要があります。
PFNでの分散強化学習のへの取り組みの歴史
PFNは、ロボット操作などの強化学習タスクに取り組んできました。IROS 2020においては、“Distributed Reinforcement Learning of Targeted Grasping with Active Vision for Mobile Manipulators” [1] という論文を発表しました。この論文では、強化学習のアプリケーションを128GPUと1024CPU コアまでスケールアウトさせた結果が掲載されています。
PFNによる強化学習コミュニティへの貢献としては、フレームワークの開発があります。かつて、PFNは深層学習フレームワークであるChainerファミリーを開発していました。 我々の論文[1]は、ChainerMNとChainerRLを用いたものでした。
2019年、PFNはChainerの開発を停止し、開発環境をPyTorchへ移行することを発表しました。ChainerRLのコンポーネントはPyTorchへ移植され、PFRLとして開発が継続されています。このライブラリは、再現性のある研究をサポートし、包括的なアルゴリズムの実装済みコードと、新しいアルゴリズムを開発しやすい柔軟性を念頭において開発されています。
PFRLについての詳細は、PFNのブログポスト Introducing PFRL: A PyTorch-based Deep RL Library | by Prabhat Nagarajan | PyTorch [5] をご覧ください
分散深層学習の設計と実装
背景
既に述べたように、既存のファイルからすべてのデータを読み取ることができる従来の機械学習とは異なり、強化学習は次の学習エポックの経験を生成しながら学習しています。このような特性は、モデルの訓練プロセス以外に、強化学習の新たなボトルネックを生みます。もう一度、強化学習をスケールアウトさせる時の課題を整理しましょう。
- 遅い環境(アクター):一部の重い環境の場合、環境の探索を担当するアクターと呼ばれるコンポーネントによる経験の生成が非常に遅くなる可能性があります。
- 遅い訓練:生成された経験が多くなるか、モデルが大きくなると、訓練時間が長くなります。
画像分類などの教師あり学習のスケーリングは遅い訓練のほうに重点を置いており、多くの研究は複数のGPUを使用して遅い訓練問題を解決しています。たとえば、PyTorchのDistributedDataParallelなどです。一方、強化学習(特にon-policyのアルゴリズム)は、学習エポックを開始する前に、十分な量の経験が生成されるのを待つ必要があります。アクターが遅い場合、GPUの待ち時間(イテレーションの間隔)が大きくなり、学習エポックと全体的な学習時間を長くする恐れがあります。さらに、ほとんどのアクターはCPUで実行されるため、CPUとGPUの間の計算能力の相違により、このような重い訓練はより困難になります。したがって、今回の実験では、並列アクターで遅いアクター問題を解決することに重点をおくことにします。
並列アクター&リモートアクター
遅い訓練の場合に訓練のワークロードを複数のGPUに分散するのと同様に、遅い環境の場合は、複数のアクターを追加することで、問題に取り組みます。PFRLでは、Pipeなどのプロセス間通信を用いた並列アクター(ここでは便宜上「ローカルアクター」と呼びます)が利用可能です。しかし、訓練用のGPUの速度とアクター用のCPUの速度のバランスを保つためには、物理的な1台の計算機に搭載されているより多いCPUが必要になることがあります。環境のシミュレーターが重い場合は特にそうですし、また訓練自体のためにもCPUが必要でもあるからです。PFRLのローカルアクターでは、一つの物理ノードに搭載されているCPU数を超える環境シミュレーターが必要な場合は、それ以上に増やすことができません。
この問題を解決するために、我々のシステムでは、gRPCを用いて物理ノードを超えてアクターを追加できるシステムを実装しています。ここでは便宜上、このアクターのことを「リモートアクター」と呼びます。リモートアクターは、gRPCを介して、訓練用プロセスとの間に、下記の2種類の通信をします:
- 訓練プロセスから定期的に新しいモデルを受け取ります
- 生成された経験を訓練プロセスに送信します
リモートアクターを使用することで、単一ノードのリソースに制限されることなく、アクターの数を自由に増やすことができます。
PFN分散強化学習システムの概要
PFNでの分散強化学習の概要を紹介します。 PFNでは、計算リソースをKubernetesで管理するため、KubernetesとDocker上に分散型強化学習環境を構築します。以下は、分散型強化学習システムの概要です。
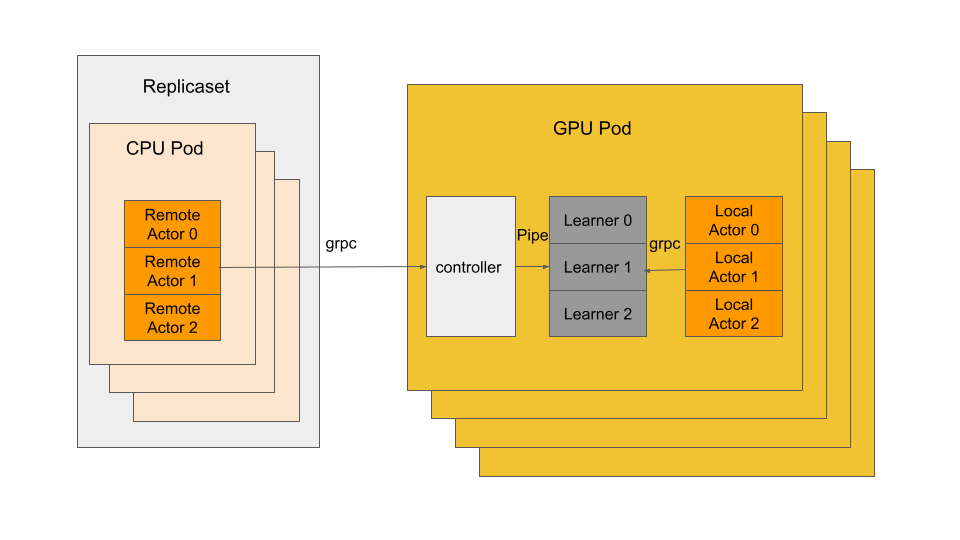 システム全体の概要
システム全体の概要
我々のシステムには、下記の3種類のプロセスがあります:
- アクタープロセス:CPUで実行され、指定された環境とモデルから経験を生成します。アクターには2つのタイプがあり:ローカルアクターは、学習プロセスと同じポッドに配置されます;リモートアクターは、別のCPU podに配置され、gRPCを介して学習プロセス/コントローラーに接続しています。
- 学習プロセス:アクターから経験を収集し、その経験でモデルを更新します。分散データ並列学習の場合、すべての学習プロセスは PyTorch DistributedDataParallelを介してつながっています。
- コントローラー:リモートアクターが接続するための各GPUポッドのゲートウェイとして機能しています。コントローラーは、同じGPUポッドに複数の学習プロセスがいる場合のワークロードのバランスを取る役割もおこないます。
Application performance evaluation case study
アプリケーション例:分子生成タスク
ここでは、分子生成と呼ばれるタスクを取り上げます。分子の構造を生成するタスクは、創薬やマテリアルサイエンスにおいて重要です。そのようなタスクは、探索空間が離散で、しかも事前にラベル付きのデータを準備することもできません。また、You [2] によれば、探索空間は 10^23 を大きく超えると想定されています。このようなタスクに機械学習を適用する場合、強化学習は重要な選択肢となります。
先行研究としては、 You [2] があり、分子生成のタスクに強化学習のアルゴリズムの1つであるPPOを適用したものです。本項では、このアルゴリズムを社内で独自に実装した強化学習アプリケーションを、gRPCとKubernetesを用いてスケールアウトさせる実験をおこないます。また、それ以外の関連した文献として、[3], [4] なども参考にしています。
実験
アクターの並列処理の有効性を示すための実験として、分散学習をサポートするように分子生成アプリケーションの社内実装を改造し、すべての実験は、元の実装と同じパラメーターを使用して行っています。分散学習の結果となる精度については、元の実装と比較し、許容可能なエラー範囲内で良好な精度を達成していることを確認しています。
今回は、PFNの内部クラスターMN-2(学習ジョブ)とMN-3(リモートアクタージョブ)上で実行しました。
MN-2仕様
| 名前 | MN-2 |
| CPU | Intel(R) Xeon(R) Gold 6254 CPU x2@ 3.10GHz 36 cores |
| メモリー | 384G |
| GPU | NVIDIA Tesla V100 SXM2 x 8 |
| ネットワーク | 100GbE x 4 |
MN-3仕様
| 名前 | MN-3 |
| CPU | Intel(R) Xeon(R) Platinum 8260M CPU x2@ 2.40GHz 48 cores |
| メモリー | 384G |
| ネットワーク |
100GbE x 4 |
スケーラビリティ実験
この実験では、並列アクターの有効性を検証し、アクターを追加することによって、時間あたりの経験の生成と処理の速度が向上することを示します。分子生成の社内実装では、on-policyのアルゴリズムであるPPOを利用しているため、アクターは学習プロセスと並行して実行できません(on-policy、off-policyの違いについてはここでは述べません)。しかし、アクター用の計算資源を追加すると、モデルの更新後に経験を蓄積する速度が上昇するため、更新の間隔が短くなり、全体の実行時間が短縮されます。訓練用GPU1つに対してアクター用CPUの個数を様々に変化させ、計算リソースの最適バランスを見つけるため、単一のGPUで学習を実行し、アクターの数をスケールアウトしています。各アクターに一つのCPUコアを割り当て、物理ノードのCPU数以上のCPUは、ネットワークで接続されたCPU計算ノード上に起動したアクター用PodがGPUプロセスを通信を行います。
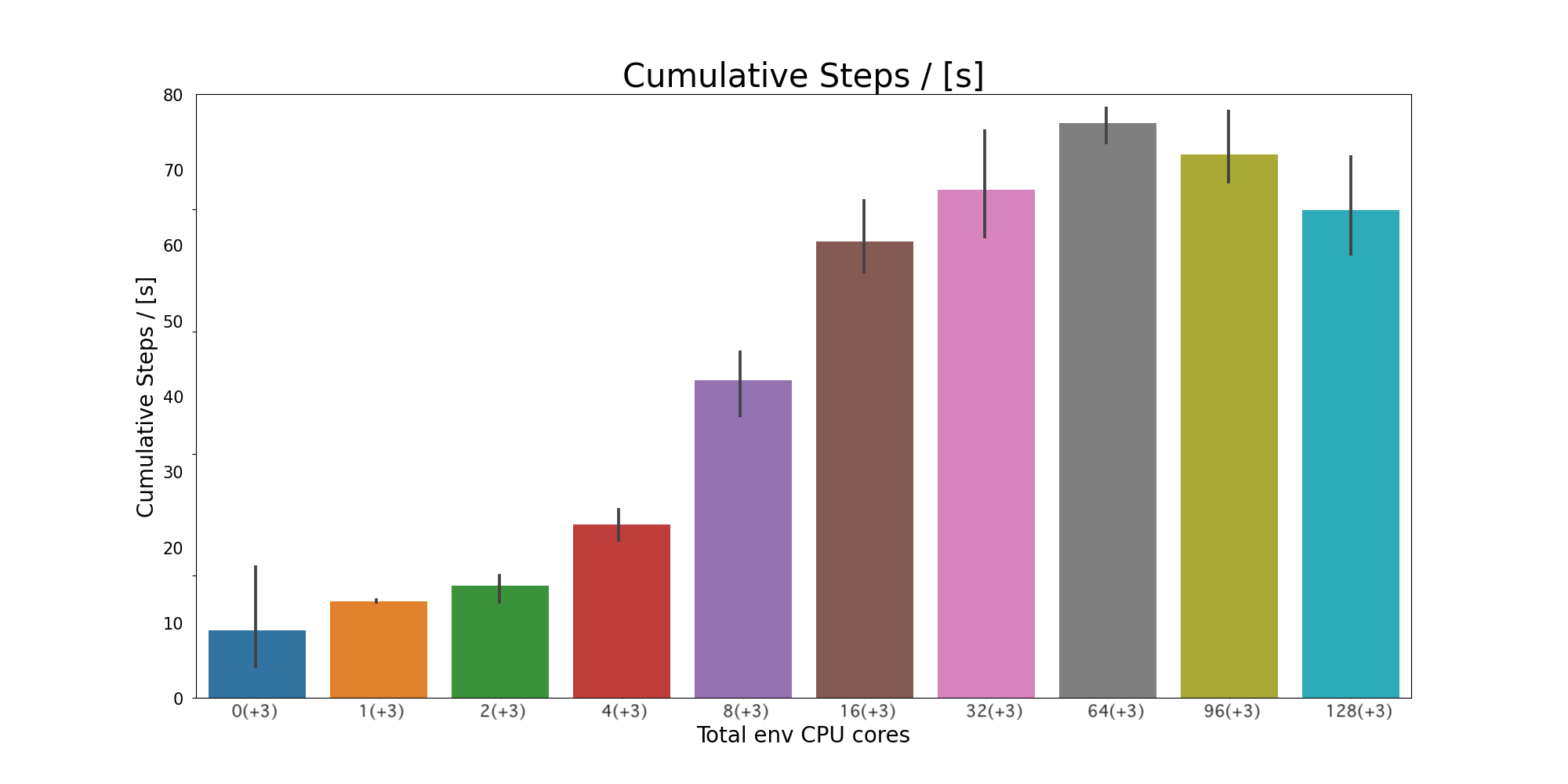 一つの訓練プロセス(GPU)に対して、環境(CPU)を増やした時のスケーラビリティを示しています。Cumulative steps/[s]は1秒間あたりに学習できた経験の数を示しています
一つの訓練プロセス(GPU)に対して、環境(CPU)を増やした時のスケーラビリティを示しています。Cumulative steps/[s]は1秒間あたりに学習できた経験の数を示しています
上のグラフは、この実装をスケールアウトさせた結果を示しています。Y軸は、”Cumulative Stpes per second” で、これは1秒間あたりに学習できた経験の数を示しています(higher is better)。X軸は、アクターのために使用したCPUの合計を示しています。なお、強化学習は、乱数シードによって結果や性能が大きく異なる可能性があるので、今回は4個のシードの平均をとっています。
また、並列化効率については、”3”〜”19” 程度までは良好なスケーリングとなっており、その後は徐々に低下し始めることが確認されました。さらに、”67”からは,1秒間あたりに学習できた経験の数が下がり始めていることがわかります。今回の実験で並列化した部分は経験を生成している部分で、学習部分は今回の実験では並列化していません。アムダールの法則から、全体の実行時間を、並列化していない部分より短縮することは不可能です。さらに、並列数を増やすと並列化のオーバーヘッドによって性能が劣化していくと考えられます。
結論
このブログ記事では、PFNで行われている、分散強化学習をスケールアウトさせる手法と実装についてご紹介しました。環境となるシミュレーターの計算が遅いような時に、PFRLとgRPC通信を組み合わせ、アクター(環境)をスケールアウトし、On-policyなアルゴリズムであるPPOをスケールアウトさせる実験を紹介しました。
参考文献
- [1] Y. Fujita, K. Uenishi, A. Ummadisingu, P. Nagarajan, S. Masuda, and M. Y. Castro, “Distributed Reinforcement Learning of Targeted Grasping with Active Vision for Mobile Manipulators,” IROS, 2020. Link
- [2] J. You, B. Liu, R. Ying, V. Pande, J. Leskovec, “Graph Convolutional Policy Network for Goal-Directed Molecular Graph Generation” NIPS, 2018. Link
- [3] E.Wijmans, A. Kadian, A. Morcos, S. Lee, I. Essa, D. Parikh, M. Savva, D. Batra, “DD-PPO: Learning Near-Perfect PointGoal Navigators from 2.5 Billion Frames” Link
- [4] “Massively Large-Scale Distributed Reinforcement Learning with Menger”
- [5] Introducing PFRL: A PyTorch-based Deep RL Library | by Prabhat Nagarajan | PyTorch
- [6] D. Kalashnikov , A. Irpan , P. Pastor , J. Ibarz , A. Herzog , E. Jang , D. Quillen , E. Holly , M. Kalakrishnan, V. Vanhoucke, S. Levine, “QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation”, CoRL 2018. Link
