Blog
はじめに
エンジニアの上野です。機械学習プラットフォームチームという、PFNの機械学習基盤を開発・運用するチームに所属して、日々基盤の改善や新機能の開発を進めています。
本記事ではPFNにおけるアクセラレータ間通信に関して、必要性や使用されている技術について概説します。また、今年構築した NVIDIA H100 GPU と 400 GbE を搭載した生成AI向けの機械学習クラスタについて、構築中に発生したインターコネクトに関するトラブルと、その解決までの道筋について紹介します。この内容は、2024/10/28 の MPLS Japan 2024「GenAI/HPCネットワークのパフォーマンス計測とデバッガビリティ」セッションにて発表した「PFN におけるアクセラレータ間通信の実際」をブログ化したものです。発表資料はこちらで公開しています。
深層学習から分散深層学習へ
アクセラレータ間通信のモチベーションとして、分散深層学習に用いられる集団通信 (Collective Communication) について紹介します。
分類問題の設定
分類問題を例にして、深層学習に現れる計算について紹介します。
以下のものを定義します:
- データセット \((\boldsymbol{x}, t)\)
- \(\boldsymbol{x}\): 入力データ
- \(t\): 正解ラベル
- 損失関数 \(l(t, y)\)
- 正解ラベル\(t\)と推論結果\(y\)の距離
- ニューラルネットワーク \(y = f(\boldsymbol{x}; \boldsymbol{\theta}) \)
- \(\boldsymbol{\theta}\): ニューラルネットワークのパラメータ
深層学習の1反復では、以下を計算します:
- Forward 計算
- データセットからいくつかサンプルを抽出して、ミニバッチ化したものについて、誤差を計算する
- \( L = \sum l(t, f(\boldsymbol{x}; \boldsymbol{\theta})) \)
- Backward 計算
- 誤差 \(L\) をパラメータ \( \boldsymbol{\theta} \) で微分する
- \( \frac{\partial L}{\partial \boldsymbol{\theta}} = \sum \frac{\partial}{\partial \boldsymbol{\theta}} l(t, f(\boldsymbol{x}; \boldsymbol{\theta})) \)
- Update 計算
- Backward で求めた誤差 \(L\) の パラメータでの微分(勾配)を使って、パラメータを更新する
この反復を繰り返すことで、データセットにフィットしたニューラルネットワークモデルを得ることができます。
データ並列型分散深層学習 (Distributed Data Parallel Deep Learning)
これらの計算の高速化を考えると、一番単純には \( \sum \) の項 \( \frac{\partial}{\partial \boldsymbol{\theta}} l(t, f(\boldsymbol{x}; \boldsymbol{\theta})) \) をそれぞれ並列に計算して、あとから足し合わせればよいことが分かります。このシンプルな考え方を適用したのがデータ並列型分散深層学習です。
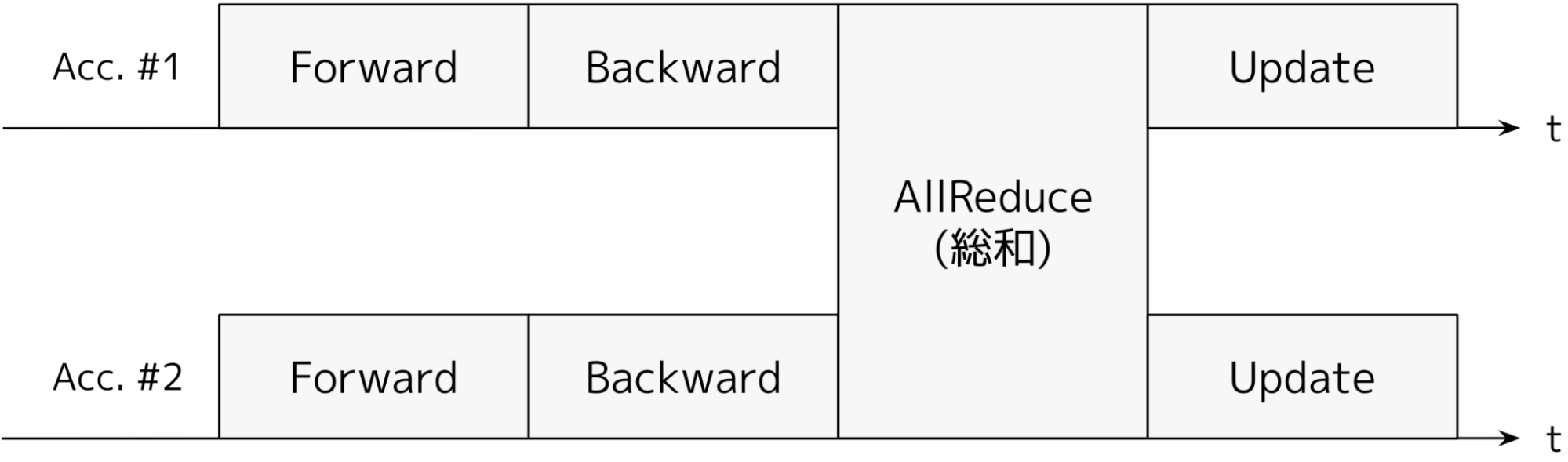
図1: データ並列型分散深層学習の1反復(アクセラレータ数=2)
図1にデータ並列型分散深層学習の1反復を示しました。Forward と Backward は各アクセラレータごとに異なる入力を使っています。AllReduce によって、異なる入力データを与えたときの誤差の勾配を合計して、プロセス数で割り、全体の勾配の平均を得て、パラメータを更新します。すべてのアクセラレータで、同一の勾配を使ってパラメータを更新するため、すべてのアクセラレータでパラメータは常に等しくなります。
LLMにおける分散深層学習
LLM (Large Language Model) では、多数のパラメータを扱う必要があります。ここまでに説明したデータ並列型分散深層学習では、メモリ消費を減らすことができないため、なにか他のメモリ消費を減らす手法が必要です。計算とメモリ消費を両方分散できるような他の並列化手法をいくつかご紹介します。
Fully Sharded Data Parallel (FSDP), ZeRO [1]
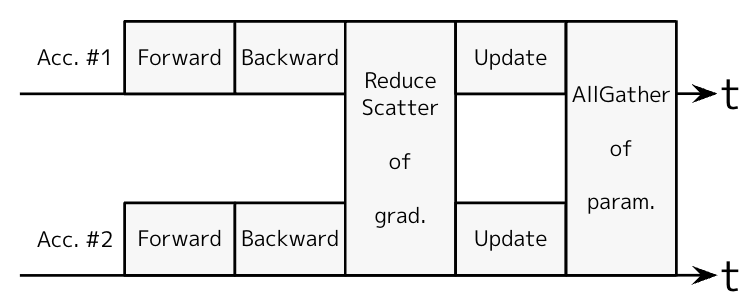
図2: FSDPの1反復(アクセラレータ数=2)
FSDP は、データ並列化を拡張したものです。図2に FSDP の1反復を示します。従来のデータ並列化でパラメータのAllReduceをしていましたが、これを勾配のReduce-ScatterとパラメータのAllGatherの2つに分割します。図2の場合、勾配をReduce-Scatterすると、Acc. #1は勾配の合計の前半、Acc. #2は勾配の合計の後半を得ます。そのあと、Updateをそれぞれのアクセラレータで前半と後半で分担して行います。このとき使用するパラメータの最適化手法によっては、パラメータ数に比例する optimizer state と呼ばれる中間状態を保存する必要があります。FSDP の場合、Update がアクセラレータで分散されて行われているため、optimizer state を分散して持つことができ、アクセラレータ1つあたりのメモリ消費を減らすことができます。Update後に、パラメータをAllGatherしてパラメータの全体を得ます。(さらに通信量を増やしてメモリ消費を減らす方法がこの論文で紹介されているので、興味がある方は見てみてください)
パイプライン並列 (Pipeline Parallel) [2]
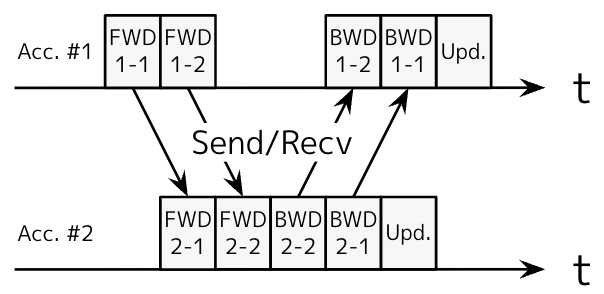
図3: パイプライン並列の1反復(アクセラレータ数=2, パイプラインステージ数=2)
パイプライン並列は、モデルを時間方向に複数のパイプラインステージで分割して計算を分担する並列化手法です。図3にパイプライン並列の1反復を示します。ステージをまたぐところで、必要なデータをアクセラレータ間で通信して、ForwardとBackwardの計算が成立するようにします。このとき、自分が担当するパイプラインステージに関する情報だけを各アクセラレータが保持しておけばよいので、メモリ消費を削減できます。
図では、パイプライン上に計算が実行されていない時間(バブル)が大きく見えますが、これはパイプラインに流し込むマイクロバッチの数をうまく調節すると緩和できます。
テンソル並列 (Tensor Parallel) [3]
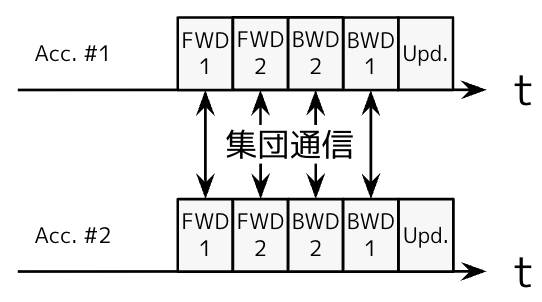
図4: テンソル並列の1反復(アクセラレータ数=2, テンソルの分割数=2)
テンソル並列は、モデル中のそれぞれのレイヤを分割してアクセラレータが担当するものです。図4にテンソル並列の1反復を示します。入力データに対してパラメータを作用させますが、それを分散行列積などで計算するなどうまく工夫して通信量を抑えることができます。この分散行列積では、AllReduceを利用します。
必要な集団通信の変化
LLM以前は、高速なAllReduceさえあれば効率的なデータ並列型分散深層学習を実現できました。しかし、LLMの分散学習を効率的に行うためには、AllReduceだけではなくSend/RecvやReduce-Scatter/AllGather などの集団通信パターンも必要になり、よりアクセラレータ間通信に求められる要求は高いものになってきています。本記事では触れていませんが、アクセラレータそれ自体の演算能力も高くなっているため、必要な通信帯域幅もより広くなってきています。
アクセラレータ間通信を支える技術
このような高速かつ多様なアクセラレータ間通信を実現するために、ハードウェアからソフトウェアまで様々なレイヤで工夫が凝らされています。その一端を紹介します。
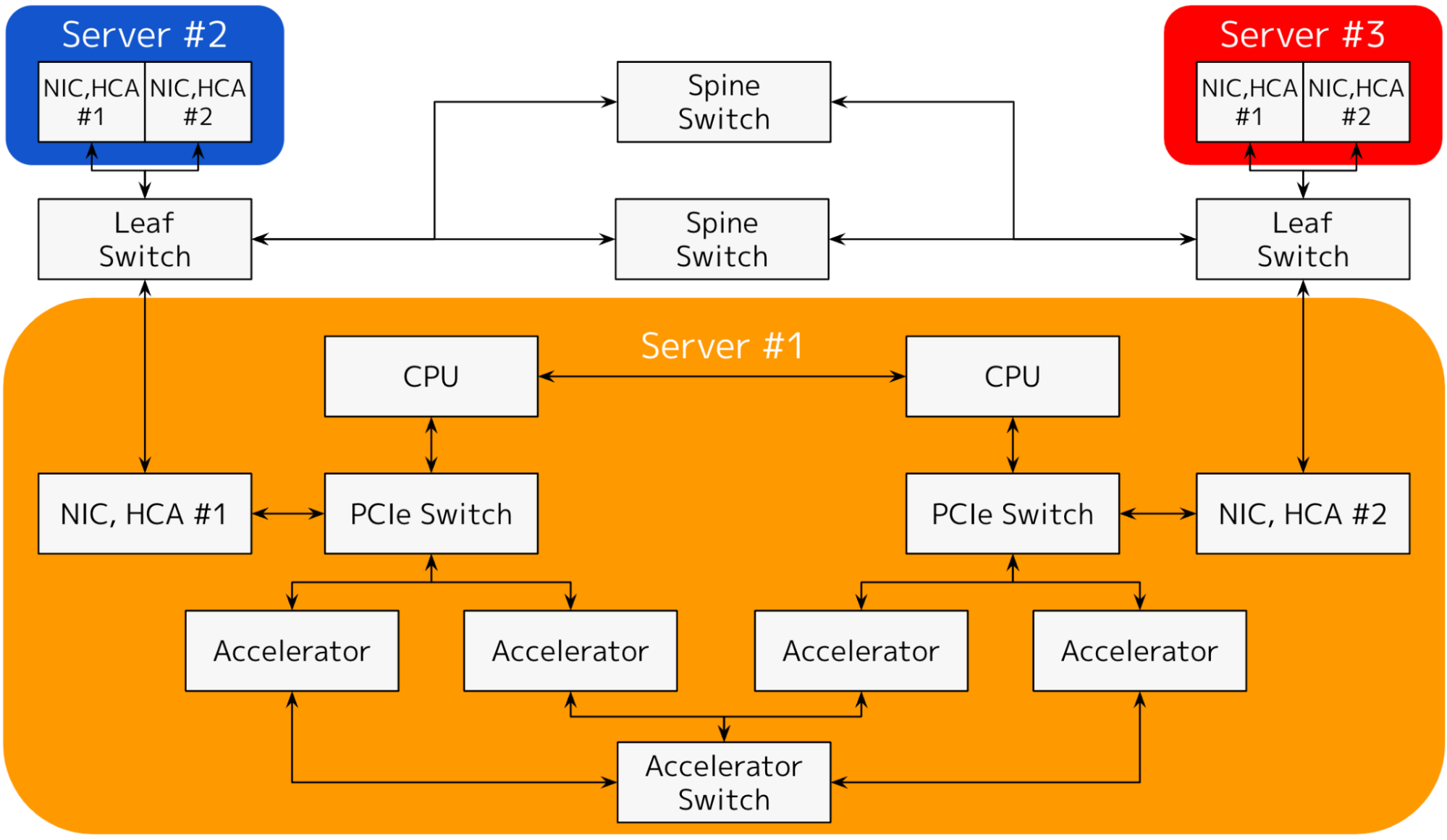
図5: 3ノードのアクセラレータ搭載クラスタ(1ノード: 2CPU, 2 PCIe Switch, 2 NIC)
図5に3ノードのアクセラレータを搭載したクラスタを示します。Server #1, #2, #3 はすべて同じ構成のサーバ(ノード)で、#2, #3 は略記しました。#1 を見ると、1ノードに2つのCPU, 2つのPCIe Switch, 4つのアクセラレータとその専用リンク, 2つのNICが搭載されていることが分かります。このように、現代のアクセラレータ搭載の計算機は大変複雑で高性能なシステムになっています。
チップ間通信
NVIDIA GPU の場合、NVLink と呼ばれるチップ間通信インターフェースが搭載されています。図5では、Accelerator から Accelerator Switch に伸びる線と、Accelerator Switch に対応します。NVLink はいまのところ、世代が進むたびにリンク数や帯域が増えています。ノード内のGPUが少ない場合はそれぞれが直結され、8 GPU 搭載サーバなど大きなシステムはNVLink Switch を搭載し、どの GPU を組み合わせた利用でも高速なチップ間通信を実現します。ソフトウェア開発者から見ると、NVLink の存在はうまく抽象化されています。メモリコピーを行う際にNVLink がある場合は自動的に活用され、なければ PCI Express 経由で転送されます。
ノード間通信
PFNでは、ノード間通信の技術として Ethernet (RoCE v2)を利用しています。RoCE v2は、InfiniBand と同様に Remote Direct Memory Access を実現するための仕組みです。InfiniBand は専用のファブリックを利用するのに対し、RoCE v2 は Ethernet を利用して通信します。
一般に、ノード内の高速なデータ転送ではDirect Memory Access (DMA) が使われます。ホストメモリやデバイスからNICに対してDMAすると、NIC が Ethernet, IP, UDP, InfiniBand のヘッダをつけて RDMA に変換して別ノードに転送します。そして、受け取った NIC がヘッダを外して DMA に戻します。このように、NIC が DMA と RDMA を載せ替えて、別のサーバのメモリに直接データを送信します。
これを実現する InfiniBand のために作られた API があります。RoCE v2でも同様にこれを利用して通信できます。代表的なものをいくつか紹介します:
- ibv_reg_mr()
- memory pinning と呼ばれる、特定のメモリ領域がスワップアウトされないようにする処理を行い、今後の通信に備える処理
- ibv_post_send(), ibv_post_recv()
- memory pinning された領域に対する通信命令を queue に積む処理
- ibv_poll_cq()
- completion queue を poll して、先に積んでおいた通信命令が完了しているかを確認する処理
ソフトウェアの面から見るとInfiniBand と RoCE v2 はうまく抽象化されていますが、実際の InfiniBand と Ethernet の間には違いがあります。例えば InfiniBand は、クレジットベースのフローコントロールを適用して、パケットが落ちないロスレスな通信を実現しています。対して Ethernet はロッシーなネットワークであり、言い換えるとパケットが落ちることがあります。RoCE v2では、InifiniBand のヘッダをつけて Ethernet のフレームとして転送されるため、パケットが落ちてしまっては困りそうです。
これを解決するため、RoCE v2 では DCQCN (Data Center Quantized Congestion Notification)という方法を使って、ロスレスネットワークを実現しています。DCQCN は、ECN と PFC を組み合わせたものです。
ECN、明示的な輻輳通知と呼ばれる方法では、ネットワークが輻輳しているときにネットワーク上のスイッチがパケットの特定ビットを立てることで、輻輳が発生していることをそのパケットの受信側に通知します。輻輳を実際に起こしているのは送信側の転送ペースが早すぎる為なので、受信側が送信側に対して CNP (Congestion Notification Packet)と呼ばれるパケットを送ることで、輻輳が通知されたことを伝えます。CNPを受け取った受信側は、送信ペースを下げることで、輻輳を回避します。
しかしECNだけを使った方法では、輻輳を通知するために一度受信側を介してやりとりをする必要があるため、どうしても通知までに時間がかかってしまい、輻輳がよりひどくなってパケットを落としてしまう可能性をぬぐいきれません。そこで、PFC (Priority-based Flow Control) は、キュー単位での pause により、パケットを落とす前に送信を早急に止めて、パケットドロップを回避します。ECNとPFCを併用することで、回避できる輻輳は事前に回避しつつ、短い pause 時間でロスレスネットワークを実現できます。
アクセラレータ・NIC間通信
アクセラレータとNICの間の通信技術にも、特筆すべきものがあります。アクセラレータとNICは異なるベンダーが開発することもあり、どのようにしてベンダニュートラルに直接の通信をサポートしているのでしょうか。
InfiniBand の場合、Peer Memory Directと呼ばれる技術が使われています。これは、ベンダごとに異なるメモリの扱い方をうまく抽象化する技術です。
使い方を簡単に説明します:
- まず、カーネル空間で ib_register_peer_memory_client() 関数を使って、デバイスごとの Peer Memory Client を登録しておきます。
- 実際にユーザがメモリ領域を転送できる状態にするため、ibv_reg_mr()関数を使って memory pinning を行おうとします。そのとき、ホストメモリではないものを登録しておこうとすると、既に登録された Peer Memory Client を順に問い合わせ、対応する Client がいるかどうかを確かめます。無事見つけることができれば、その Client が memory pinning を行います。この Client は、デバイスベンダが開発しているので、きちんとデバイス固有の方法で正しく memory pinning を行うことができます。
- 実際にユーザが登録済みのメモリ領域を転送するため、ibv_post_send() や ibv_post_recv() で転送要求を queue に積むと、DMA を行うために必要な DMA アドレスを調べる必要が出てきます。Peer Memory Client はこの時にも呼び出され、デバイス固有の方法で DMA アドレス を取得できます。
これにより、デバイスとNICの間のDMAが実現されます。この方法は InfiniBand に限ったもので、デバイスベンダが InfiniBand のために個別に Peer Memory Client を実装する必要があり、煩雑ではあります。この問題を解決する方法としてLinux Kernel の DMA-BUF 機能があり、InfiniBand や NVIDIA GPU driver は Peer Memory Direct から DMA-BUF への移行を進めています。
Peer Memory Direct を使う上で、ハマりやすいいくつかの注意点を合わせてご紹介します:
-
当該デバイスのための Peer Memory Client を正しくロードしているか?
- Peer Memory Client (もしくは DMA-BUF)なしには、NIC と デバイスメモリの間で直接DMAできません。NVIDIA の場合は nvidia_peermem など、正しいものを事前にロードしておく必要があります。
-
PCIe Switch は DMA の折り返しができるように正しく設定されているか?
- ある PCIe Switch の下に、NICとデバイスが接続されているとします。このとき、PCIe Switch で折り返して NIC と デバイスで直接通信するのが最も高速です。しかし、セキュリティ機能である Access Control Service が有効になっていると、ホストのRoot Complex で折り返してアクセス制御を行い再度 PCIe Switch に転送するため、セキュリティが担保されている環境では無駄にホストと PCIe Switch の間の帯域を消費し、通信帯域も下がってしまいます。VMを利用しないなどIOMMUによるアイソレーションを必要としない場合は安全に無効にできます。
-
NIC とデバイスの affinity がよくなるように、NIC とデバイスが選択されているか?
- また、PCIe Switch での折り返しができるような相性の良い NIC とデバイスの選択も重要です。これが正しく選ばれていないと、無駄にホストの Root Complex で折り返しになってしまったり、ソケットをまたいだ通信が発生してしまったりします。
- Kubernetes クラスタにおける同様の事例を弊社ブログ「KubernetesクラスタにおけるGPU-NIC割り当ての改善によるRDMAの高速化」で紹介していますので、こちらもご興味があればご参照ください。
集団通信アルゴリズム
AllReduce集団通信
勾配の総和を求めたりテンソル並列を実装する際に、AllReduceと呼ばれる集団通信パターンは非常に重要です。NVIDIA 製の集団通信ライブラリが実装しているAllReduceの集団通信アルゴリズムとしては、Ring[4] や Tree[5] のアルゴリズムがあります。
Ring-AllReduce は弊社ブログ「分散深層学習を支える技術:AllReduceアルゴリズム」で紹介させていただきましたが、本記事でも簡単に紹介します。図6に、4プロセスで長さ4の配列をRing-AllReduceする例を示します。
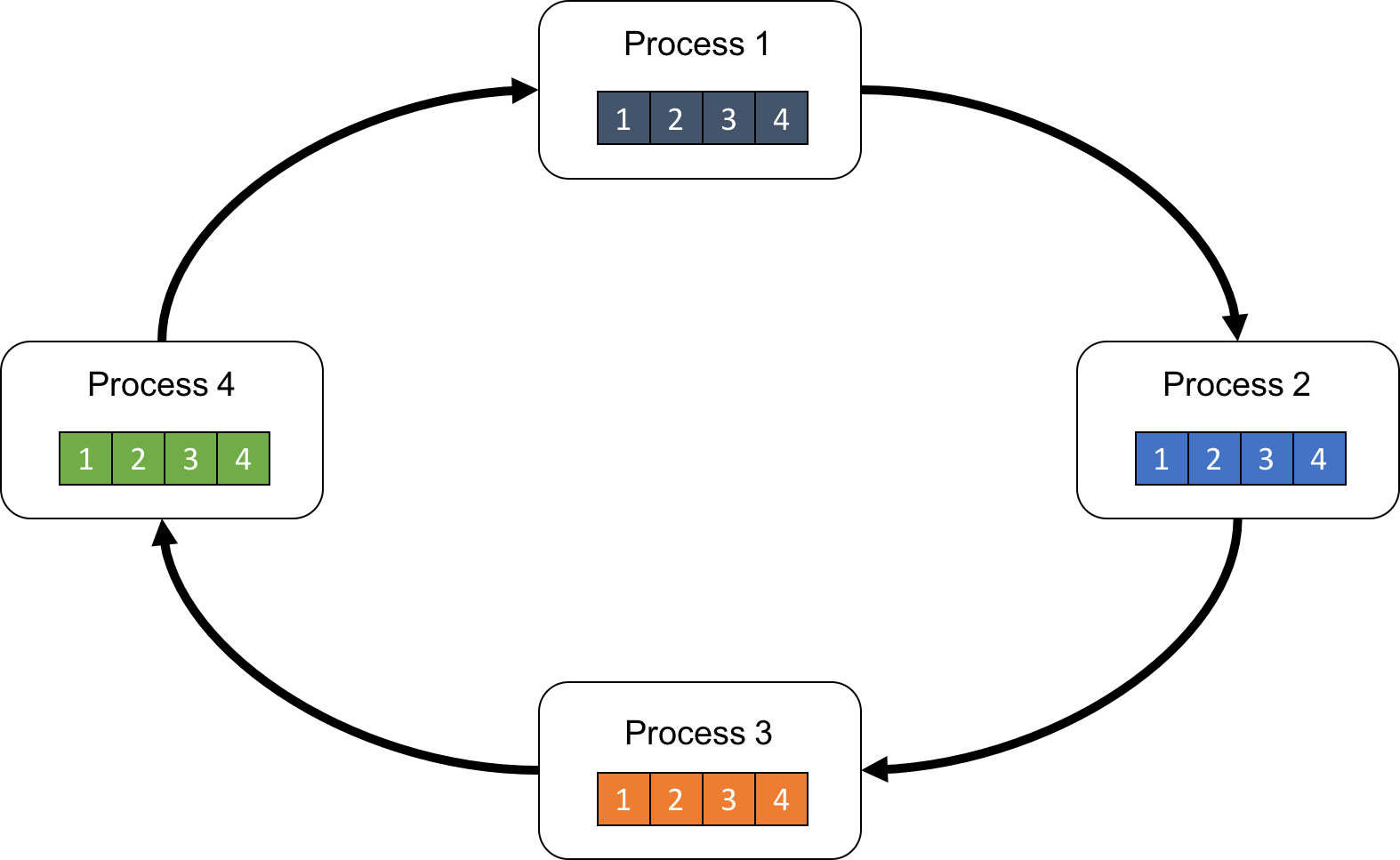
図6: 長さ4の配列のRing-AllReduce のために4プロセスをリング状に並べた例
Ring-AllReduce は以下の2つのステップで実装されます:
- Reduce-Scatter
- 今、総和を求めたい配列をリング状に回しながら加算していくステップです。各プロセスが、バスケットを一周ずつ回し、流れてきたバスケットに入っているデータを取り出し、加算し、またバスケットに戻して次のプロセスに渡すようなイメージです。
- AllGather
- この加算が終わったバスケットを一周回して、全員でバスケットの中身を確認するステップです。
既に本記事の中に名前が出ましたが、Reduce-Scatter や AllGather は単独でも利用できる集団通信パターンです。Reduce-Scatter は総和結果を分散して持つ、AllGather は分散して持っているデータを全員に配る、という振る舞いになります。
この Ring アルゴリズムは、各プロセスが1受信相手・1送信相手と通信すればよく、rank のずれを1つに抑えられ、様々なネットワークトポロジにおいて効率的に動作します。ただし、数百アクセラレータ以上での集団通信など、リングが長すぎて1周に時間がかかる場合は Tree アルゴリズムの方が効率的に動作します。どちらが効率的に動作するかは、通信レイテンシと帯域幅を使って記述するパフォーマンスモデリングで予測できます。
実際の計算機クラスタへの適用
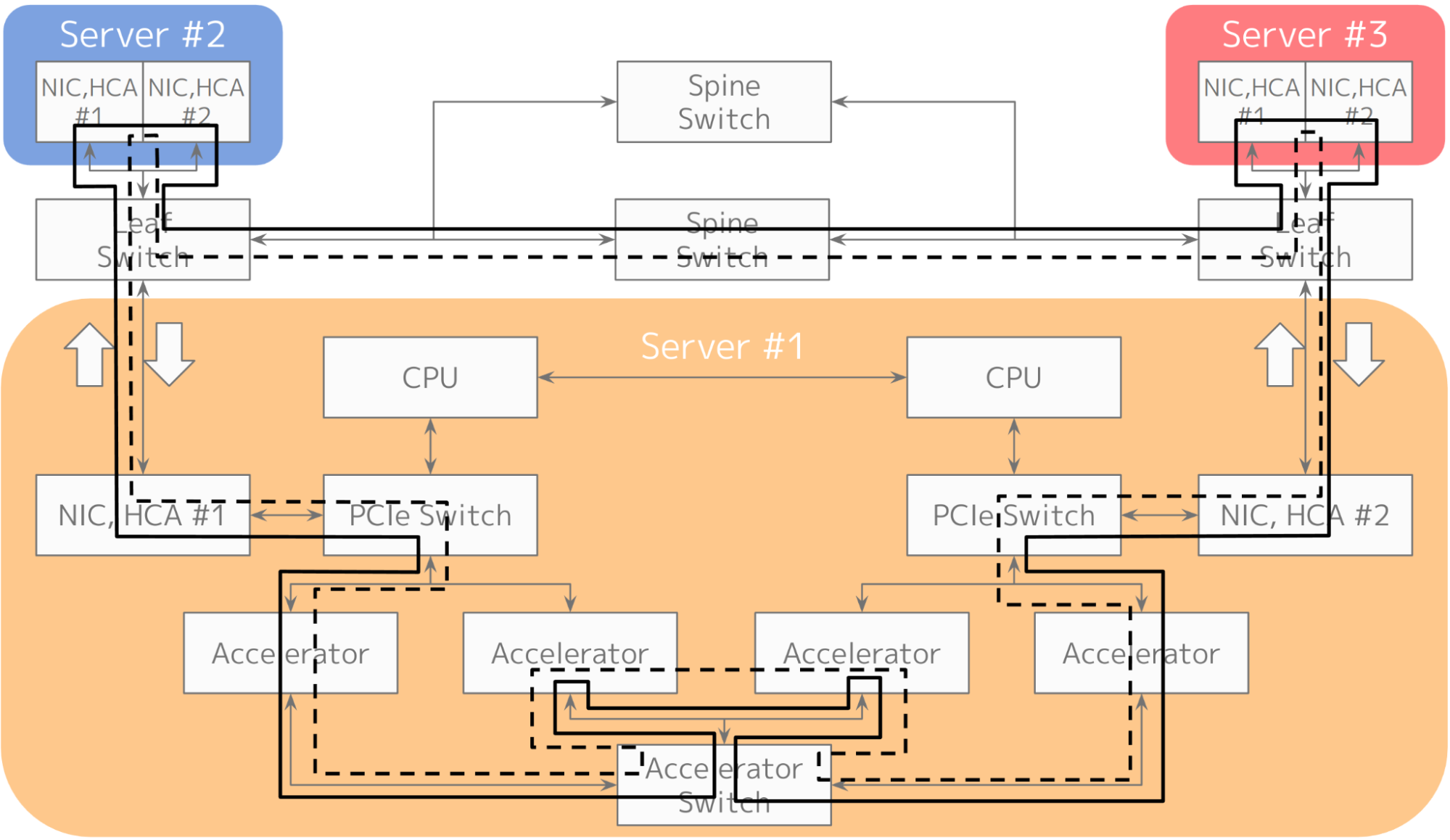
図7: Ring-AllReduceを計算機クラスタに当てはめた例。NICの全二重通信帯域を活用するため、Ring数を2とした。
実際に Ring-AllReduce をクラスタに当てはめた例を図7に示します。図のように、ノード内の4つのアクセラレータをアクセラレータスイッチを経由して順に訪問してReductionして、NICを経由して別のノードにリングをつないでいます。図では、NICの全二重帯域を活用するために外回りと内回りのリングを逆向きに重ねています。アクセラレータスイッチを通る回数を数えると、アクセラレータスイッチとアクセラレータの間の接続はNICやPCI Expressの2倍の帯域で設計する必要があることがわかります。
集団通信ライブラリ
集団通信ライブラリは集団通信アルゴリズムを実装していて、NICの枚数や専用のチップ間通信の有無などを考慮して、適切にアルゴリズムの選択とトポロジの設計をする役割があります。NVIDIA 製 の集団通信ライブラリ NCCL も同様に、ハードウェアを検出してリングトポロジを自動で決定する機能が実装されています。しかし、ユーザの設定ミスや、想定されていない特別なハードウェア上での利用、高度な並列化手法を採用して複数のコミュニケータを作り複雑な通信をする、など様々な条件が重なると、最適でない通信をしてしまうこともあります。ここではいくつかのトラブルシューティングの方法を紹介します:
-
NCCL_DEBUG=INFO 環境変数を使って、NCCLのハードウェア検出機能が想定通り動いているかを確認する
- きちんと InfiniBand デバイスをすべて認識しているか、GPUDirect RDMA が動作しているか、など性能に関わる重要な機能が正しく認識されているかを確認できます。
-
正しい通信アルゴリズムが選択されているかを確認する
- プロファイラを使ったり、アルゴリズムに関するログを有効にすると通信に使っているアルゴリズム(Ring/Tree, 低レイテンシカーネル)が使われているかを確認できます。
- 選択が適切でない場合は、環境変数の設定や tuner を実装して上書きできます。
-
実現された性能が想定通りかを確認する
- nccl-testsに実装されている busbw という値で、実際の通信時間からアルゴリズムに関する寄与を取り除いた実際の経路上での通信帯域幅を確認できます(Ring-AllReduceでは2周Ringを通るために2より少し小さい数で割る必要がある…などの調整)。この値から、集団通信に性能改善の余地があるかどうかを検証できます。
H100クラスタ構築でのトラブルシューティング事例
PFN とその子会社の Preferred Elements では、生成AIの学習をするための計算機クラスタとして、さくらインターネットさまの「高火力 PHY」を利用して Kubernetes クラスタ を構築しました。Kubernetes クラスタの構築自体については Cloud Native Days Summer 2024 にて「生成AI向け機械学習クラスタ 構築のレシピ 北海道石狩編」として紹介しています。
このクラスタは以下の特徴があります:
-
高性能なGPUサーバ
-
NVIDIA H100 Tensor コア GPU x 8 搭載
- 80 GB VRAM / GPU
-
NVIDIA H100 Tensor コア GPU x 8 搭載
- ベアメタルで低オーバーヘッド
-
インターコネクト(広帯域ロスレスネットワーク)
- 400 Gbps x 4 (RoCEv2 対応)
- シャーシスイッチ Arista Networks 7800R3
このクラスタは高速なインターコネクトと最新世代のNVIDIA GPUを兼ね揃えており、大規模言語モデル学習に向いています。しかし、これを使って実際に学習を開始したところ、いくつかの問題が発生しました。
- パイプライン並列化を実施するため、複数の NCCL コミュニケータを作って通信すると、NCCL が自動選択する NIC が偏ってしまい通信性能が出ない。
- AllGather の集団通信性能が安定せず、カタログスペック通りの通信性能を達成することもあれば、4分の1程度まで遅いこともある。Tree-AllReduce では概ね良好であった。
- InfiniBand のタイムアウトエラーが頻発し、長時間の学習を行えない。
NCCL が自動選択するNICが偏り、性能が出ない問題
この問題については、NCCLの自動選択の問題であるためいくつかのワークアラウンドを考えましたが、それぞれの方法について大きなコードの修正が必要になったり最適でない通信になるため、より抜本的な解決が必要でした。まずはノード内の PCIe トポロジに限って調査を進めました。
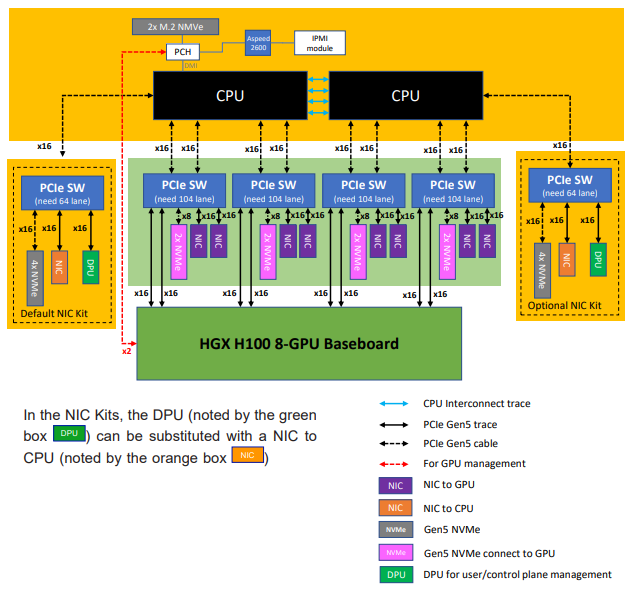
図8: Supermicro SYS-821GE-TNHR のドキュメント
図8に、サーバベンダが提供するドキュメントを示します。この構成では、サーバには4つの PCIe Switch が搭載されており、各 PCIe Switch には 2つの GPU が搭載されていると記載されています。このサーバでは各 PCIe Switch には 2つの NIC を搭載できますが、今回の環境はサーバあたり 4 NIC となっており、実際には PCIe Switch につき 1 NIC が搭載されています。
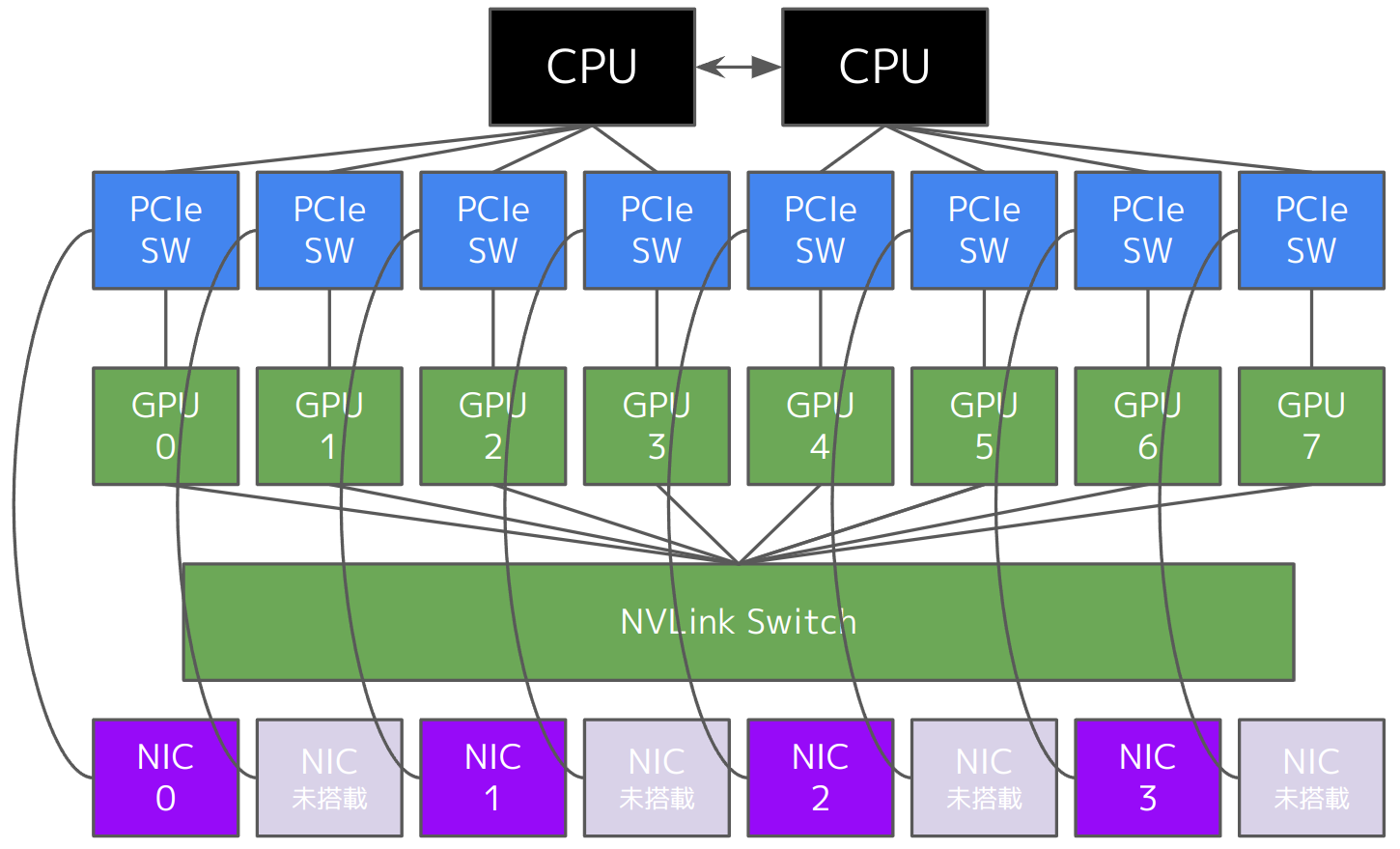
図9: 実際に nvidia-smi で確認した認識状況
図9に、nvidia-smi コマンドで確認した認識状況を示します。サーバのドキュメントと比べると、PCIe Switch の数が 8個と異なった仕様になっていることが分かります。このような構成になっていると、奇数番目のGPU (1,3,5,7) については、NIC と通信する際に CPU の Root Complex を経由してしまい、通信性能が著しく悪化します。また、ある GPU に対し相性の良い NIC を自動選択するロジックも、パイプライン並列のためコミュニケータを複数作ると正しく動作せず、同じ NIC が使われてしまいます。
これを改善するにはいくつかの方法があります。最も単純な方法は、NIC とインターコネクトに追加投資をして、ノードあたりのNIC数を8枚に増やすことです。しかし、今回必要な通信帯域を検討すると NIC 4枚、計 1600 Gbps で十分であったことから、追加投資なしに改善する方法を検討しました。PCIe Switch について調査すると、物理的にはドキュメントの通り4つの PCIe Switch が搭載されているものの、それぞれが論理的に分割されていて計 8 つとして認識されていることが分かりました。この論理的な分割をやめることができれば、例えば NIC 0 と GPU 0, GPU 1 が同一の PCIe Switch に収容されるようになるため、CPU を経由せず通信できます。サーバベンダさまの協力を得て、これを実現するPCIe Switchのファームウェアをリリースしていただき、これを適用して問題が解決しました。
AllGather 性能が安定しない問題、InfiniBand 通信がタイムアウトする問題
これらの問題については、そもそもどこの問題であるかを切り分けることができていませんでした。ノード内にも PCIe リンク速度や NVLink の省電力機能など疑わしいものがいくつかありますし、インターコネクトスイッチも今回初めて利用しているものでした。まず切り分けとして、図10 のようにネットワーク構成を変更してもらうことで、ノード内に問題があるか、ノード間に問題があるかを調査しました。通常の構成では、GPU サーバの4つのNICは同一のインターコネクトスイッチに収容されています。切り分け構成では、これらの NIC をレールごとに直結して、インターコネクトスイッチを介さない rail-optimized topology[6] を実現しました。
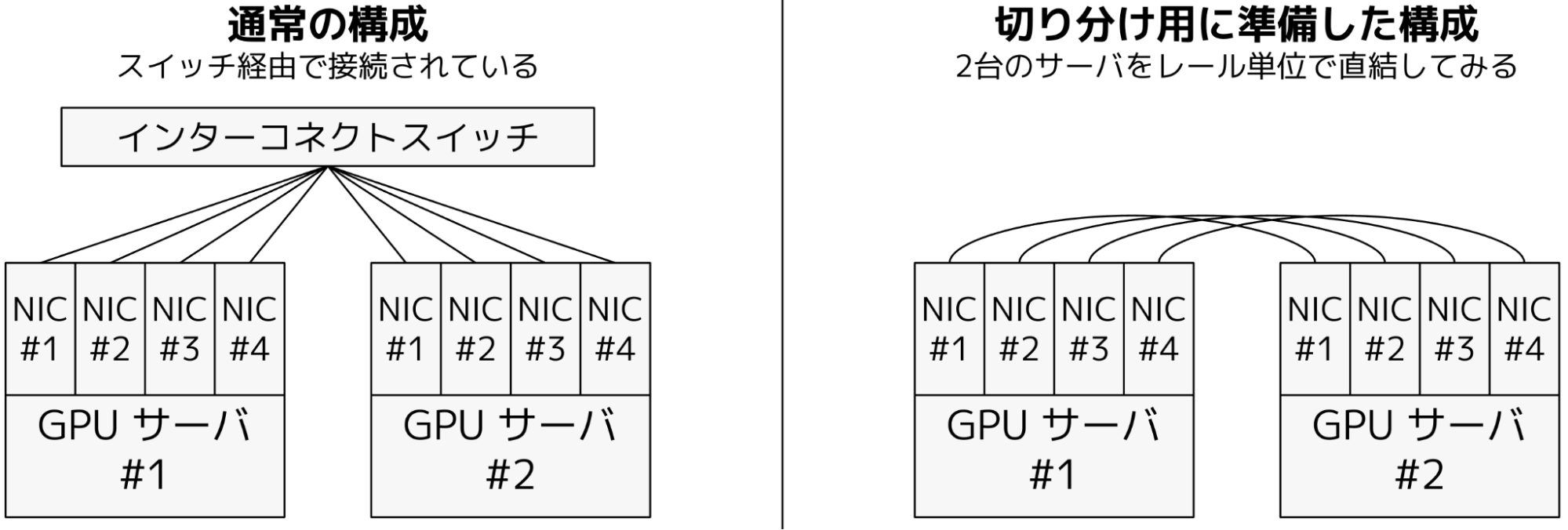
図10: 切り分けのためのネットワーク構成
この構成で問題となる通信を流してみたところ、切り分け構成では問題が改善していることが分かりました。そこで、インターコネクトスイッチになんらかの問題があると考え、スイッチベンダさまのご協力を要請しました。ベンダさまには、シャーシスイッチ内部のファブリックを介したクレジット管理に関する修正コンフィグをリリースしていただき、こちらを適用して問題が解決しました。
まとめ
本記事では、PFNにおけるアクセラレータ間通信の実際をお伝えするため、そのモチベーションから、使っているテクノロジ、日々行っているトラブルシューティングまでを紹介させていただきました。高速なアクセラレータ間通信は様々な技術の上に実現されており、正しく動かなければ計算機クラスタの大規模利用ができなくなってしまう、非常に重要な技術です。正しく動かすことはとても難しいですが、地道な技術の理解とエンドツーエンドでのデバッグにより、今回発生した問題を解決できました。
このような、「機械学習プラットフォーム全体のパフォーマンスを支える研究開発をハードウェアとソフトウェア両面の知見を活かして取り組む」ことに興味がある方がいらっしゃいましたら、ズバリな Job Description がありますのでこちらからご確認ください。また、本記事では触れることができませんでしたが、MN-Core 向けのアクセラレータ間通信についての検討も日々進めております。ほかにもいくつかの領域ごとの Job Description を準備させていただいておりますので、合わせてこちらからご覧ください。
謝辞
本記事で紹介させていただきました、H100 クラスタのインターコネクト性能が安定しない問題につきましては、以下のみなさまのご協力で無事解決できました。
-
さくらインターネット株式会社 さま
- 定期的な情報共有、切り分け協力、ベンダさまとの連携などのご協力をいただきました。
-
Super Micro Computer, Inc. さま
- PCIe Switch の修正版ファームウェアを提供いただきました。
-
Arista Networks, Inc. さま
- クレジット管理に関するコンフィグを提供いただきました。
ありがとうございました。
参考文献
- Rajbhandari, S., Rasley, J., Ruwase, O., & He, Y. (2020, November). Zero: Memory optimizations toward training trillion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis (pp. 1-16). IEEE.
- Huang, Y., Cheng, Y., Bapna, A., Firat, O., Chen, D., Chen, M., … & Wu, Y. (2019). Gpipe: Efficient training of giant neural networks using pipeline parallelism. Advances in neural information processing systems, 32.
- Shoeybi, M., Patwary, M., Puri, R., LeGresley, P., Casper, J., & Catanzaro, B. (2019). Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053.
- Patarasuk, P., & Yuan, X. (2009). Bandwidth optimal all-reduce algorithms for clusters of workstations. Journal of Parallel and Distributed Computing, 69(2), 117-124.
- Sanders, P., Speck, J., & Träff, J. L. (2009). Two-tree algorithms for full bandwidth broadcast, reduction and scan. Parallel Computing, 35(12), 581-594.
- Wang, W., Ghobadi, M., Shakeri, K., Zhang, Y., & Hasani, N. (2024, August). Rail-only: A Low-Cost High-Performance Network for Training LLMs with Trillion Parameters. In 2024 IEEE Symposium on High-Performance Interconnects (HOTI) (pp. 1-10). IEEE.
Area
